2026년, 전체 코드 커밋의 41%가 이미 AI의 도움을 받아 생성되고 있습니다. 하지만 AI가 작성한 코드의 결함률은 인간이 작성한 코드보다 1.7배나 높습니다. 코드 생성 속도는 점점 빨라지지만, 코드 리뷰의 생산성은 이를 따라가지 못해 2026년에는 약 40%의 품질 격차가 발생할 것으로 예상됩니다.
AI 코드 리뷰는 이제 '할 것인가 말 것인가'의 문제가 아니라 '어떻게 잘할 것인가'의 문제입니다. 이번 글에서는 검증된 7가지 모범 사례를 소개하고, 왜 Claude Opus 4.6과 Sonnet 4.6이 현재 코드 리뷰에 가장 적합한 AI 모델인지 심층 분석해 보겠습니다.
핵심 가치: 이 글을 통해 AI 코드 리뷰의 전체 워크플로우를 익히고, 팀의 코드 품질을 높이기 위해 가장 적합한 모델을 선택하는 방법을 배우게 될 것입니다.
AI 코드 리뷰의 현주소: 왜 지금 주목해야 하는가
2026년 코드 리뷰가 직면한 과제
| 과제 | 데이터 | 영향 |
|---|---|---|
| AI 코드 비중 급증 | 커밋의 41%가 AI 보조 생성 | 리뷰 수요 폭증 |
| AI 코드 결함률 | 인간 코드 대비 1.7배 높음 | 더욱 엄격한 리뷰 필요 |
| 품질 격차 | 2026년 40% 발생 예상 | 리뷰 생산성이 생성 속도를 못 따라감 |
| 보안 위험 | AI 코드의 45%가 OWASP Top 10 취약점 포함 | 보안 리뷰의 시급성 증대 |
| 제안 채택률 | AI 제안 16.6%, 인간 제안 56.5% | AI 리뷰 품질 개선 필요 |
AI 코드 리뷰 vs 인간 코드 리뷰
AI는 인간 리뷰어를 대체하는 것이 아니라, 인간의 리뷰 역량을 강화하기 위해 존재합니다. AI 코드 리뷰를 도입한 팀들은 다음과 같은 성과를 보고합니다:
- 리뷰 시간 40-60% 단축
- 결함 검출률 향상 — 특히 보안 취약점과 경계 조건에서 탁월
- 코드 스타일 일관성 대폭 개선
하지만 AI 리뷰에도 명확한 한계는 있습니다:
- ❌ 비즈니스 마감 기한과 프로젝트 맥락 이해 불가
- ❌ 레거시 시스템의 과거 타협점 파악 불가
- ❌ 리뷰 결과에 대한 최종 책임 불가
- ❌ 팀 내 지식 전수 및 멘토링 불가
🎯 최적 전략: AI가 1차 스캔(스타일, 버그, 보안)을 수행하고, 인간이 최종 판단(아키텍처, 의도, 리스크)을 내리는 방식입니다. APIYI(apiyi.com) 플랫폼을 통해 Claude Opus 4.6 또는 Sonnet 4.6의 API를 호출하면, 기존 CI/CD 프로세스에 AI 코드 리뷰를 빠르게 통합할 수 있습니다.
AI 코드 리뷰를 위한 7가지 베스트 프랙티스
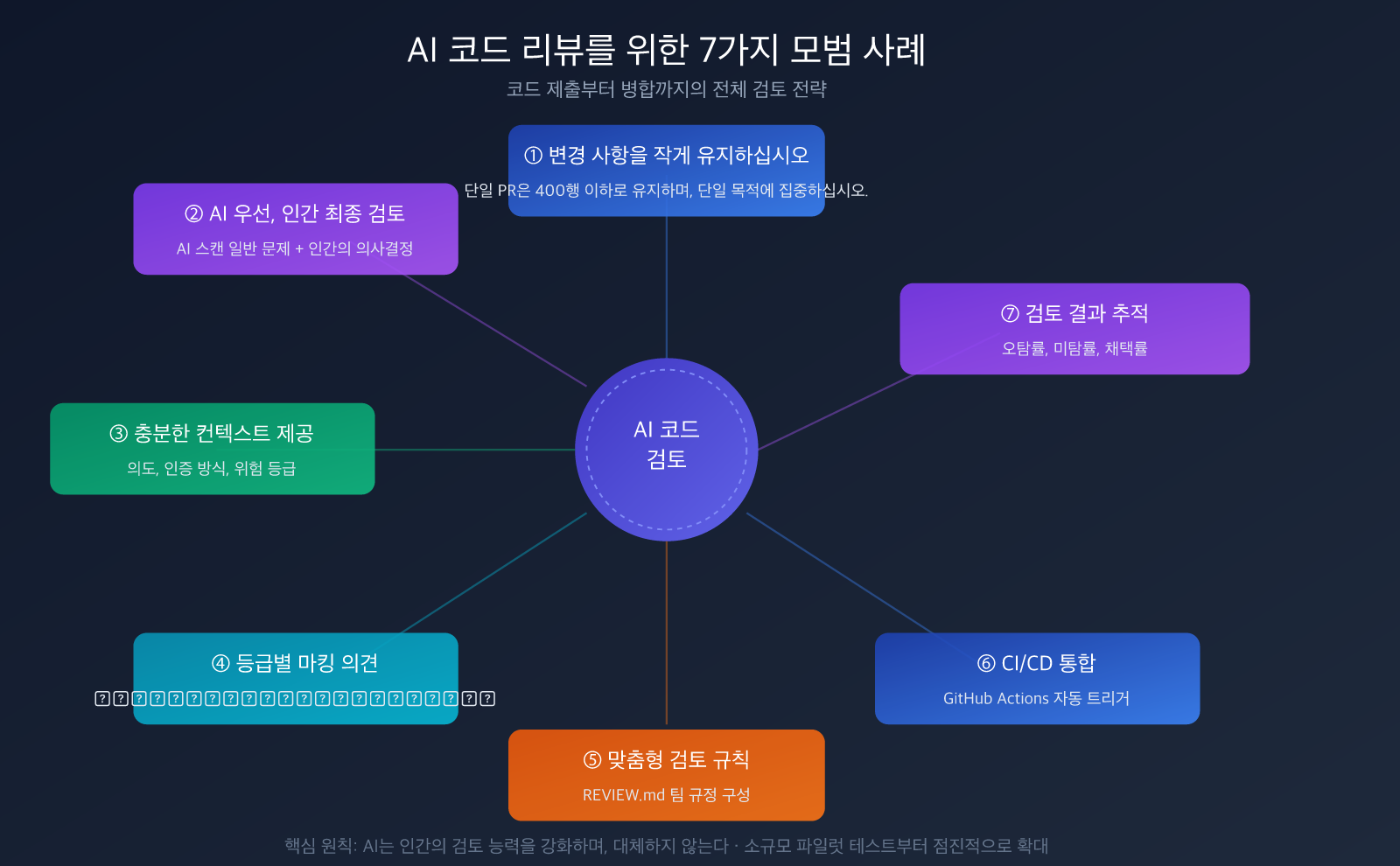
실천 1: 변경 사항을 작고 집중적으로 유지하기
AI 리뷰어는 diff가 1,000줄을 넘어가면 일관성을 크게 잃습니다. Claude Opus 4.6이 100만 토큰의 컨텍스트 윈도우를 갖추고 있더라도, 대규모 변경보다는 소규모 변경의 리뷰 품질이 훨씬 뛰어납니다.
구체적인 방법:
- 단일 PR은 200~400줄 이내로 유지
- 대규모 리팩토링은 논리적으로 독립된 여러 개의 PR로 분할
- 각 PR은 한 가지 목적만 수행
실천 2: AI 선행, 인간 최종 심사
가장 효과적인 워크플로우는 '2단계 리뷰' 모델입니다:
코드 커밋 → AI 자동 리뷰 (1차)
↓
문제 표시 + 심각도 분류
↓
인간 리뷰어가 고위험 영역에 집중 (최종 심사)
↓
병합 또는 반려
AI는 모든 일반적인 문제(스타일, 명명, 데드 코드, 단순 버그)를 스캔하고, 인간은 다음 사항에 집중합니다:
- 아키텍처의 타당성
- 비즈니스 로직의 정확성
- 보안 관련 핵심 결정
- 성능 영향 평가
실천 3: 충분한 컨텍스트 제공
AI 리뷰어에게 더 많은 정보를 줄수록 리뷰 품질은 높아집니다. PR 설명에 다음 내용을 포함하는 것을 추천합니다:
## 변경 의도
이 변경을 수행한 이유를 1~2문장으로 간략하게 설명해 주세요.
## 검증 방식
- [ ] 단위 테스트 통과
- [ ] XX 시나리오에 대한 수동 테스트 완료
- [ ] 성능 저하 없음
## 위험 등급
낮음/중간/높음 + 설명
## AI 보조 선언
이번 변경 사항 중 XX 부분은 AI가 생성했으므로, 해당 내용을 중점적으로 검토해 주시기 바랍니다.
## 인공 집중 영역
`src/auth/` 디렉토리 내의 권한 로직 변경 사항을 중점적으로 확인해 주세요.
```markdown
### 실습 4: 등급별 리뷰 의견 마킹
AI 리뷰에서 흔히 발생하는 문제는 "너무 많은 노이즈"입니다. 스타일 제안과 치명적인 버그가 뒤섞여 있어 개발자가 중요한 피드백을 놓치게 되죠.
**권장하는 심각도 마킹**:
| 마킹 | 의미 | 처리 방식 |
|------|------|----------|
| 🔴 **Bug** | 병합 전 반드시 수정해야 할 결함 | 병합 차단 |
| 🟡 **Nit** | 수정하면 좋지만 병합을 막지는 않는 사소한 문제 | 선택적 수정 |
| 🟣 **Pre-existing** | 이번에 도입된 것이 아닌 기존 문제 | 기록하되 병합 차단 안 함 |
| 💡 **Suggestion** | 개선 제안 | 논의 후 결정 |
Claude Code의 기본 코드 리뷰 기능은 이미 이러한 등급 시스템(Red/Yellow/Purple)을 구현하고 있습니다.
### 실습 5: 리뷰 규칙 커스터마이징
범용적인 AI 리뷰는 팀의 규격에 맞지 않을 수 있습니다. 설정 파일을 통해 리뷰 동작을 커스터마이징해 보세요:
```markdown
# REVIEW.md (프로젝트 루트 디렉토리에 배치)
## 필수 확인 사항
- 모든 데이터베이스 쿼리는 매개변수화된 문(parameterized statement)을 사용해야 함
- API 엔드포인트는 반드시 인증 미들웨어를 포함해야 함
- 모든 사용자 입력은 검증을 거쳐야 함
건너뛰어도 좋은 것들
- CSS 클래스 명명 스타일 (prettier로 자동 포맷팅 완료)
- import 정렬 (ruff로 자동 처리 완료)
- 주석 언어 (중문/영문 모두 가능)
팀 약속
- 상속보다는 조합(Composition)을 우선시합니다.
- 에러 처리는 Result 패턴을 사용합니다.
- 로그 레벨: 비즈니스 이벤트는 INFO, 디버깅은 DEBUG를 사용합니다.
# GitHub Actions 예시
name: AI 코드 리뷰
on:
pull_request:
types: [opened, synchronize]
jobs:
ai-review:
runs-on: ubuntu-latest
steps:
- uses: anthropics/claude-code-action@v1
with:
anthropic_api_key: ${{ secrets.ANTHROPIC_API_KEY }}
review_mode: "auto"
또한 API를 통해 직접 Claude 모델을 호출하여 맞춤형 리뷰를 수행할 수도 있습니다:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 통합 인터페이스
)
diff_content = open("pr_diff.patch").read()
response = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "system", "content": """당신은 숙련된 코드 리뷰 전문가입니다.
다음 코드 변경 사항을 분석하고 심각도에 따라 분류해 주세요:
- 🔴 Bug: 반드시 수정해야 함
- 🟡 Nit: 수정 권장
- 💡 Suggestion: 개선 제안
각 문제에 대해 구체적인 줄 번호와 해결 방안을 제시하세요."""},
{"role": "user", "content": f"다음 코드 변경 사항을 리뷰해 주세요:\n\n{diff_content}"}
],
max_tokens=8192
)
print(response.choices[0].message.content)
실습 7: 리뷰 효과 추적
AI 코드 리뷰는 배포 후 끝나는 것이 아닙니다. 다음과 같은 핵심 지표를 지속적으로 추적해야 합니다:
- 오탐률 (False Positive Rate): AI가 표시한 문제 중 실제 문제인 비율
- 미탐률 (False Negative Rate): 배포 후 발견된 버그 중 AI가 놓친 비율
- 채택률: 개발자가 실제로 AI의 제안을 수용한 비율
- 리뷰 시간 변화: 인간 리뷰어의 평균 리뷰 시간이 감소했는지 여부
💡 도입 제안: 팀에서 AI 코드 리뷰를 처음 시작한다면, 중요도가 낮은 경로의 PR부터 시범 운영하는 것을 추천합니다. APIYI(apiyi.com)를 통해 Claude Sonnet 4.6을 호출하여 초기 테스트를 진행해 보세요. 비용은 Opus의 5분의 1 수준이면서 리뷰 품질은 Opus와 비슷하여, 가성비가 가장 뛰어난 시작 방법입니다.
Claude Opus 4.6 및 Sonnet 4.6을 코드 리뷰에 추천하는 이유
수많은 AI 모델 중에서도 Claude 4.6 시리즈는 코드 리뷰 환경에서 독보적인 강점을 보여줍니다.
Claude 4.6 모델 핵심 사양 비교
| 사양 | Claude Opus 4.6 | Claude Sonnet 4.6 |
|---|---|---|
| 모델 ID | claude-opus-4-6 |
claude-sonnet-4-6 |
| 출시일 | 2026년 2월 5일 | 2026년 2월 17일 |
| 컨텍스트 윈도우 | 100만 토큰 (베타) | 100만 토큰 (베타) |
| 최대 출력 | 128K 토큰 | 64K 토큰 |
| SWE-bench Verified | 81.42% | 79.6% |
| 가격 (입력/출력) | 100만 토큰당 $5/$25 | 100만 토큰당 $3/$15 |
| 적합한 상황 | 복잡한 아키텍처 검토, 보안 감사 | 일상적인 PR 검토, 스타일 체크 |
| APIYI 가격 | 더 저렴함 | 더 저렴함 |
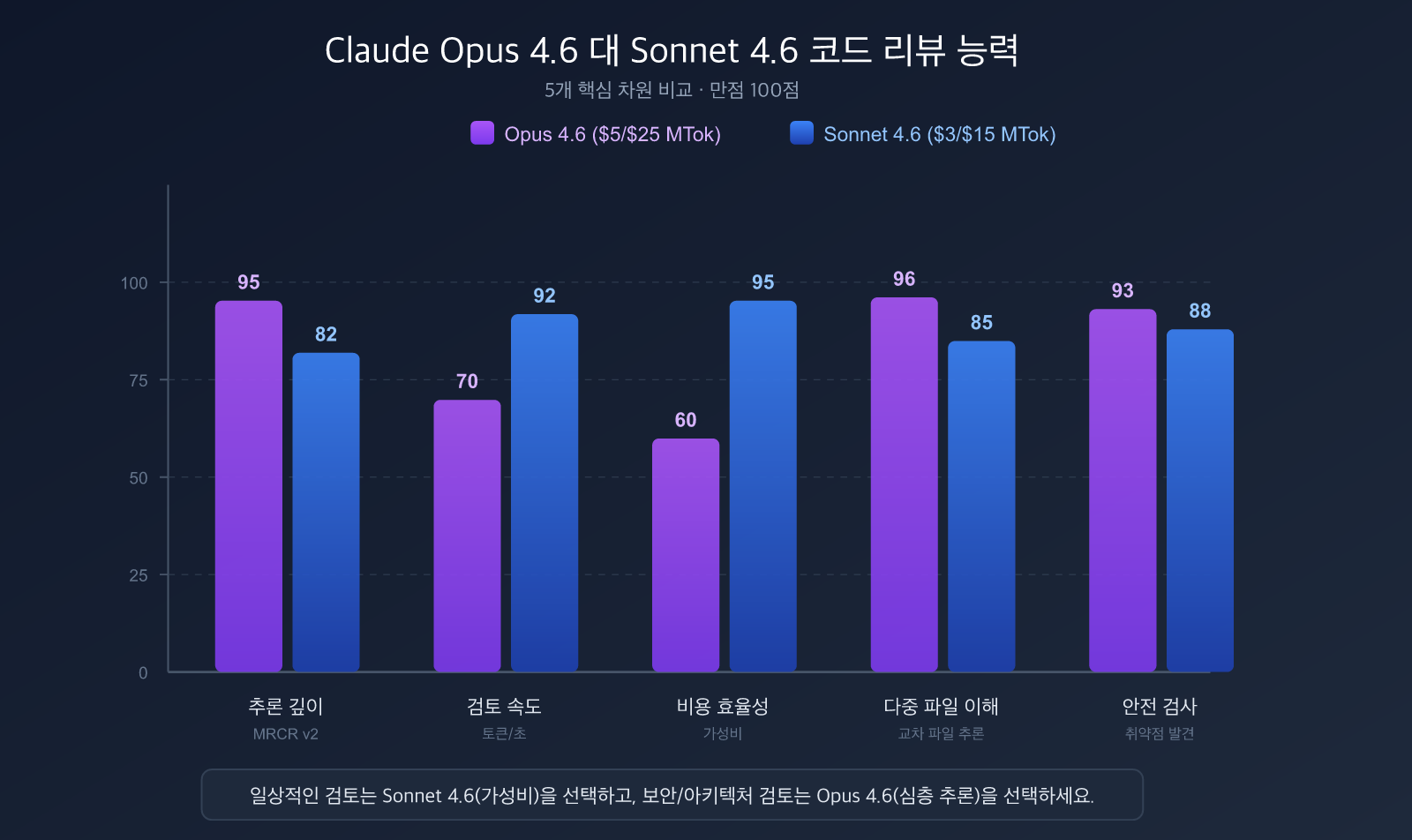
강점 1: 100만 토큰 컨텍스트 윈도우
코드 리뷰에서 가장 중요한 기술적 강점입니다.
대규모 프로젝트의 PR은 수십 개의 파일을 포함할 수 있습니다. 기존 AI 모델은 컨텍스트 윈도우 제한 때문에 코드를 잘라내야 했고, 이로 인해 AI가 전체 맥락을 파악하지 못하는 문제가 있었습니다.
Claude 4.6의 100만 토큰 컨텍스트는 다음을 한 번에 처리할 수 있습니다:
- 전체 PR diff (보통 수백~수천 줄)
- 관련 파일의 전체 코드 (import 체인, 호출된 함수 등)
- 의존성 그래프 및 타입 정의
- 테스트 파일 및 설정 파일
- 프로젝트 README 및 아키텍처 문서
이제 AI가 숙련된 개발자처럼 전체 맥락을 완벽하게 이해하고 리뷰할 수 있습니다.
강점 2: 최고 수준의 파일 간 추론 능력
코드 리뷰의 진짜 가치는 문법 오류를 찾는 것이 아니라, 파일 간의 논리적 문제를 발견하는 데 있습니다.
Claude Opus 4.6은 MRCR v2(다중 파일 검색 및 추론) 테스트에서 **76%**의 점수를 기록했습니다(Sonnet 4.5는 18.5%). 덕분에 다음과 같은 상황에서 탁월한 성능을 발휘합니다:
- A 파일의 인터페이스 수정 사항이 B 파일의 호출부와 동기화되지 않은 경우
- 데이터 흐름이 입구부터 데이터베이스까지 이어지는 전 과정에서 검증이 누락된 경우
- 동시성 환경에서의 경쟁 상태(Race Condition) 식별
실제 사례: 테스트 중 Claude Opus 4.6은 2,400줄 규모의 데이터베이스 마이그레이션 PR에서 경쟁 상태를 발견했습니다. 이는 마이그레이션 도중 중단될 때만 발생하는 롤백 로직 결함으로, 자동화 테스트로는 잡아내기 어려운 영역이었습니다.
강점 3: 적응형 사고 깊이 (Adaptive Thinking)
Claude 4.6은 adaptive thinking 모드를 도입했습니다. AI가 문제의 복잡도에 따라 스스로 "얼마나 깊게 생각할지" 결정합니다.
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 통합 인터페이스
)
response = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "system", "content": "이 코드 변경 사항의 보안 문제를 검토해 주세요."},
{"role": "user", "content": diff_content}
],
# Claude 4.6 적응형 사고: 간단한 문제는 빠르게, 복잡한 문제는 깊이 있게 분석
extra_body={"thinking": {"type": "adaptive"}}
)
- 간단한 스타일 문제 → 빠르게 판단하여 토큰 절약
- 복잡한 동시성 또는 보안 문제 → 심층 추론을 통해 상세 분석 제공
강점 4: 전통적인 도구를 뛰어넘는 보안 취약점 탐지
연구에 따르면, Claude 급의 LLM은 보안 코드 리뷰에서 기존 정적 분석 도구보다 훨씬 뛰어난 성능을 보입니다.
| 비교 항목 | Claude (LLM) | CodeQL (기존 SAST) |
|---|---|---|
| 탐지 취약점 수 | 55개 | 27개 |
| 미지 취약점 발견 | 4개의 제로데이 취약점 | 0개 |
| 탐지 카테고리 | 주입, 인증, 데이터 유출, 암호화 등 10개 이상 | 패턴 매칭 기반 |
| 언어 지원 | 모든 프로그래밍 언어 | 특정 언어 |
| 오탐 필터링 | AI 자동 필터링 | 수동 필터링 필요 |
Claude가 탐지 가능한 보안 취약점 유형:
- SQL/명령어/LDAP/XPath/NoSQL 주입
- 인증 및 권한 부여 결함
- 하드코딩된 키, 민감한 데이터 로그
- 취약한 암호화 알고리즘, 부적절한 키 관리
- 경쟁 상태 (TOCTOU)
- 안전하지 않은 기본 설정, CORS
- 역직렬화 RCE, pickle/eval 주입
- XSS (반사형, 저장형, DOM 기반)
강점 5: 비용 효율성
Sonnet 4.6은 Opus 4.6 가격의 1/5 수준이지만, SWE-bench 성능 차이는 1~2% 포인트에 불과합니다.
추천 모델 선택 전략:
| 상황 | 추천 모델 | 이유 |
|---|---|---|
| 일상적인 PR 검토 | Sonnet 4.6 | 가성비 최고, Opus와 유사한 품질 |
| 보안 핵심 코드 | Opus 4.6 | 가장 깊은 추론, 고위험 문제 완벽 차단 |
| 대규모 리팩토링 검토 | Opus 4.6 | 파일 간 추론 능력 최강 |
| 스타일 및 규격 체크 | Sonnet 4.6 | 단순 작업에 Opus는 과함 |
| CI/CD 자동 검토 | Sonnet 4.6 | 비용 제어 가능, 매 커밋마다 실행 적합 |
🚀 선택 팁: Anthropic 공식 가이드는 "기본적으로 Sonnet 4.6을 사용하고, 가장 깊은 추론이 필요할 때만 Opus 4.6으로 업그레이드하라"고 권장합니다. Claude Code 내부 테스트에서 개발자들은 이전 세대 Sonnet 4.5보다 70%, 심지어 이전 플래그십인 Opus 4.5보다 59% 더 높은 선호도를 보였습니다. APIYI(apiyi.com)를 통해 두 모델 모두 더 저렴한 가격으로 이용해 보세요.
완벽한 AI 코드 리뷰 워크플로우
워크플로우 개요
개발자 PR 제출
↓
AI 자동 리뷰 트리거 (Sonnet 4.6)
↓
┌─── 저위험 변경 ──→ AI가 Nit로 표시 후 자동 통과
│
├─── 중위험 변경 ──→ AI가 문제 표시, 사람이 빠르게 확인
│
└─── 고위험 변경 ──→ Opus 4.6으로 업그레이드하여 정밀 리뷰
↓
보안 전문가 최종 수동 검토
↓
병합 또는 반려
코드 예시: 커스텀 AI 리뷰 시스템 구축하기
import openai
import subprocess
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 통합 인터페이스
)
def get_pr_diff(pr_number):
"""PR의 diff 내용을 가져옵니다"""
result = subprocess.run(
["gh", "pr", "diff", str(pr_number)],
capture_output=True, text=True
)
return result.stdout
def review_code(diff, risk_level="medium"):
"""위험 수준에 따라 리뷰 모델을 선택합니다"""
model = "claude-opus-4-6" if risk_level == "high" else "claude-sonnet-4-6"
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": REVIEW_PROMPT},
{"role": "user", "content": f"다음 변경 사항을 리뷰하세요:\n\n{diff}"}
],
max_tokens=8192
)
return response.choices[0].message.content
# 사용 예시
diff = get_pr_diff(123)
review = review_code(diff, risk_level="high")
print(review)
전체 리뷰 프롬프트 템플릿 보기
REVIEW_PROMPT = """당신은 풍부한 경험을 갖춘 시니어 소프트웨어 엔지니어로서 코드 리뷰를 수행하고 있습니다.
## 리뷰 중점 사항
1. **논리적 정확성**: 코드가 의도한 기능을 구현했는가? 경계 조건이 누락되지 않았는가?
2. **보안성**: 인젝션, XSS, CSRF, 하드코딩된 키 등 보안 위험이 존재하는가?
3. **성능**: N+1 쿼리, 불필요한 메모리 할당, 블로킹 작업이 있는가?
4. **유지보수성**: 명명 규칙이 명확한가? 복잡도가 적절한가? 중복 코드가 있는가?
5. **에러 처리**: 예외 상황이 적절하게 캡처되고 처리되는가?
6. **동시성 안전**: 경쟁 상태(Race Condition)나 데드락 위험이 있는가?
출력 형식
심각도 수준에 따라 분류하여 출력하세요:
🔴 반드시 수정 (Bug/Security)
- [파일명:행 번호] 문제 설명
- 영향: …
- 수정 제안: …
🟡 수정 권장 (Nit)
- [파일명:행 번호] 문제 설명
- 제안: …
💡 개선 제안 (Suggestion)
- [파일명:행 번호] 개선 사항
- 설명: …
코드 품질이 우수하여 발견된 문제가 없다면 "검토 통과, 발견된 문제 없음"이라고 명확히 밝혀주세요.
출력을 위해 존재하지 않는 문제를 지어내지 마세요.
💰 비용 최적화: APIYI(apiyi.com)를 통해 Claude 3.5 Sonnet 모델을 호출하여 코드 검토를 진행하면 공식 대비 훨씬 저렴하게 이용할 수 있습니다. 플랫폼은 Opus와 Sonnet 모델 간의 유연한 전환을 지원하며, PR의 위험 수준에 따라 가장 가성비 좋은 모델을 자동으로 선택할 수 있습니다.
AI 코드 검토의 한계와 주의사항
반드시 알아야 할 5가지 한계
- 재현율 약 50%: LLM이 발견한 취약점은 보통 실제 문제(정밀도 약 80%)인 경우가 많지만, 기존 취약점의 절반 정도는 놓칠 수 있습니다.
- 프롬프트 인젝션 위험: AI 검토 도구가 신뢰할 수 없는 PR을 처리할 때 인젝션 공격을 받을 위험이 있습니다.
- 컨텍스트 사각지대: AI는 프로젝트의 비즈니스 배경, 팀원의 역량, 과거의 의사결정 과정을 이해하지 못합니다.
- 비용 누적: 모든 커밋마다 검토를 트리거하면 커밋 빈도가 높은 저장소의 경우 비용이 많이 발생할 수 있습니다.
- 과도한 의존 위험: 팀원들이 점차 수동 검토의 엄격함을 소홀히 할 수 있습니다.
회피 전략
| 한계 | 회피 방안 |
|---|---|
| 높은 누락률 | AI 검토 + 수동 검토 이중 보장 |
| 프롬프트 인젝션 | 신뢰할 수 있는 출처의 PR만 검토 |
| 컨텍스트 부족 | REVIEW.md에 프로젝트 배경 정보 제공 |
| 높은 비용 | 일상적인 검토는 Sonnet, 핵심 경로에는 Opus 사용 |
| 과도한 의존 | "AI 제안 + 인간의 의사결정" 제도 구축 |
자주 묻는 질문 (FAQ)
Q1: AI 코드 리뷰가 인간의 리뷰를 완전히 대체할 수 있나요?
아니요, 그렇지 않습니다. AI 코드 리뷰는 '대체'가 아닌 '보완'의 개념입니다. AI는 패턴화된 문제(코드 스타일, 흔한 버그, 알려진 취약점 패턴)를 찾아내는 데 탁월하지만, 비즈니스 의도나 아키텍처 결정에 따른 트레이드오프, 팀 협업 과정의 암묵적 지식까지 이해하기는 어렵습니다. 가장 좋은 방법은 AI가 1차 스캔을 수행하고, 인간이 최종 판단을 내리는 것입니다. APIYI(apiyi.com)를 통해 Claude 4.6 모델을 호출하여 AI 리뷰 프로세스를 빠르게 구축하고, 인간 리뷰어는 더 가치 있는 작업에 집중할 수 있도록 해보세요.
Q2: 코드 리뷰를 위해 Opus 4.6과 Sonnet 4.6 중 무엇을 선택해야 할까요?
대부분의 상황에서는 Sonnet 4.6을 추천합니다. SWE-bench 성능은 Opus보다 1~2%p 낮지만, 비용은 5분의 1 수준입니다. 보안이 중요한 코드, 대규모 아키텍처 리팩토링, 깊이 있는 파일 간 추론이 필요한 경우에만 Opus 4.6으로 업그레이드하는 것이 좋습니다. APIYI(apiyi.com)를 이용하면 필요에 따라 두 모델을 유연하게 전환할 수 있습니다.
Q3: AI 코드 리뷰 비용은 대략 어느 정도인가요?
Claude Code의 기본 리뷰 기능은 PR 크기와 코드베이스 복잡도에 따라 회당 평균 $15~$25가 소요됩니다. API를 통해 자체 리뷰 시스템을 구축할 경우, 비용은 토큰 사용량에 따라 달라집니다. Sonnet 4.6을 기준으로 500줄 규모의 PR(입력 약 2,000 토큰 + 출력 약 1,000 토큰)을 리뷰할 때 약 $0.02가 발생합니다. APIYI(apiyi.com)를 통하면 더욱 합리적인 가격으로 이용할 수 있습니다.
Q4: AI 코드 리뷰의 효과는 어떻게 평가하나요?
다음 4가지 핵심 지표를 추적하는 것을 추천합니다: (1) 오탐률(False Positive Rate) – AI가 지적한 문제 중 실제 문제의 비율; (2) 누락률(False Negative Rate) – 배포 후 발견된 버그 중 AI가 지적하지 않은 비율; (3) 채택률 – 개발자가 AI의 제안을 실제로 수용한 비율; (4) 리뷰 시간 변화 – 인간 리뷰어의 평균 리뷰 시간이 감소했는지 여부. 초기 2개월 동안은 매주 검토하는 것이 좋습니다.
Q5: AI 코드 리뷰를 빠르게 시작하려면 어떻게 해야 하나요?
가장 쉬운 3단계 방법입니다: (1) APIYI(apiyi.com)에 가입하여 API 키를 발급받습니다; (2) Sonnet 4.6을 사용하여 최근 PR 하나를 테스트로 리뷰해 봅니다; (3) 효과를 확인한 후 CI/CD 자동화 연동 여부를 결정합니다. 비핵심 경로의 코드부터 시범적으로 시작하여 점진적으로 전체로 확대해 보세요.
요약: AI 코드 리뷰는 팀 효율성을 높이는 배가기(Multiplier)입니다
AI 코드 리뷰는 선택이 아닌, 2026년 소프트웨어 개발 팀의 필수 역량입니다. Claude Opus 4.6과 Sonnet 4.6은 100만 토큰의 컨텍스트 윈도우, 81% 이상의 SWE-bench 점수, 적응형 사고 및 강력한 보안 탐지 능력을 갖추어 현재 코드 리뷰 분야에서 최선의 선택지입니다.
모델 선택 가이드:
- 일상적인 리뷰: 가성비 최고의 Sonnet 4.6을 기본으로 사용하세요.
- 보안/아키텍처 리뷰: 타협 없는 추론 깊이가 필요할 때 Opus 4.6으로 업그레이드하세요.
APIYI(apiyi.com)를 통해 Claude 4.6 전 시리즈를 빠르게 연동하고, 최적의 비용으로 팀의 AI 코드 리뷰 역량을 구축해 보세요.
참고 자료
-
Anthropic 공식: Claude Opus 4.6 및 Sonnet 4.6 출시 공지
- 링크:
anthropic.com/news
- 링크:
-
Claude Code 코드 리뷰 문서: 네이티브 리뷰 기능 사용 가이드
- 링크:
code.claude.com/docs/en/code-review
- 링크:
-
Claude Code Security Review: 오픈소스 보안 리뷰 GitHub Action
- 링크:
github.com/anthropics/claude-code-security-review
- 링크:
-
AI 코드 리뷰 모범 사례 2026: 업계 종합 분석
- 링크:
verdent.ai/guides
- 링크:
-
IRIS 연구 논문: LLM 보조 정적 분석 취약점 탐지
- 링크:
arxiv.org
- 링크:
작성자: APIYI Team | AI 기반 소프트웨어 개발의 모범 사례를 탐구합니다. Claude 4.6 전체 모델 시리즈의 API 키와 기술 지원이 필요하시면 APIYI(apiyi.com)를 방문해 주세요.