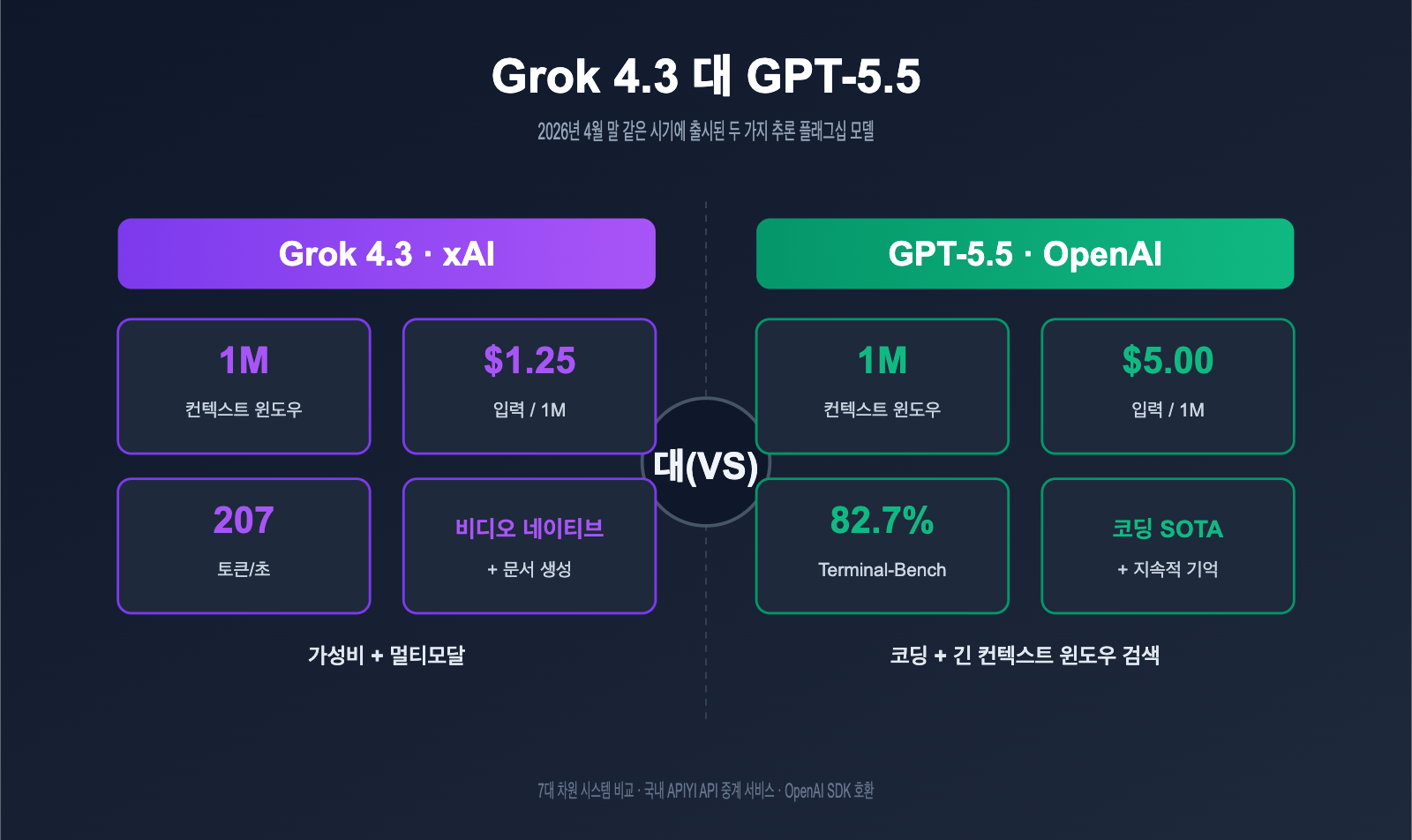
2026년 4월 말, xAI와 OpenAI는 거의 동시에 두 가지 추론(reasoning) 플래그십 모델인 Grok 4.3과 GPT-5.5를 발표했습니다. Grok 4.3은 추론 모델의 가격을 $1.25/$2.50 수준으로 낮췄고, GPT-5.5는 에이전트 코딩 능력을 Terminal-Bench 기준 82.7%까지 끌어올렸습니다. 두 제품 모두 1M 컨텍스트 윈도우라는 지점에서 수렴하고 있죠. 이번 글에서는 가격, 성능, 컨텍스트, 멀티모달, 코딩, 생태계, 비용 효율성이라는 7가지 차원에서 두 모델을 체계적으로 비교하고, 실무에 바로 적용할 수 있는 선택 가이드를 제시합니다.
핵심 가치: 이 글을 읽고 나면 본인의 비즈니스 시나리오에 맞춰 Grok 4.3 API와 GPT-5.5 API 중 무엇을 선택해야 할지 명확해지며, APIYI 중계 서비스를 통한 실제 비용 차이까지 이해하게 될 것입니다.
Grok 4.3 vs GPT-5.5 핵심 차이
xAI와 OpenAI의 이번 업데이트는 모두 '메이저 버전 업그레이드'급 발표이지만, 지향점은 완전히 다릅니다. 먼저 핵심 파라미터 표를 통해 두 모델을 비교해 보겠습니다.
Grok 4.3 vs GPT-5.5 핵심 파라미터 비교
| 비교 항목 | Grok 4.3 | GPT-5.5 | 승자 |
|---|---|---|---|
| 출시일 | 2026-04-30 (API 전체 공개) | 2026-04-24 (API) | GPT-5.5 |
| 입력 가격 | $1.25 / 1M tokens | $5.00 / 1M tokens | Grok 4.3 |
| 출력 가격 | $2.50 / 1M tokens | $30.00 / 1M tokens | Grok 4.3 |
| 컨텍스트 윈도우 | 1M tokens | 1M tokens (Codex 400K) | 무승부 |
| 출력 속도 | 207 tokens/초 | ~95 tokens/초 | Grok 4.3 |
| 추론 모드 | 기본 활성화 | xhigh / 조절 가능 | GPT-5.5 |
| 영상 입력 | ✅ 네이티브 지원 | ❌ 미지원 | Grok 4.3 |
| 문서 생성 (PDF/XLSX/PPTX) | ✅ 네이티브 | ❌ 후처리 필요 | Grok 4.3 |
| Terminal-Bench 2.0 | 데이터 미공개 | 82.7% | GPT-5.5 |
| FrontierMath 1-3 | 데이터 미공개 | 51.7% | GPT-5.5 |
| SWE-bench Verified | ~73% | 74.9% (thinking 포함) | GPT-5.5 (근소) |
| MRCR 장문 컨텍스트 8-needle | 우수 | 74.0% (5.4의 36.6% 대비) | GPT-5.5 |
| 지식 컷오프 | 2024-11 | 2025-Q1 | GPT-5.5 |
| 지속적 기억(Memory) | ❌ 없음 | ✅ 지원 | GPT-5.5 |
Grok 4.3 vs GPT-5.5 핵심 강점 요약
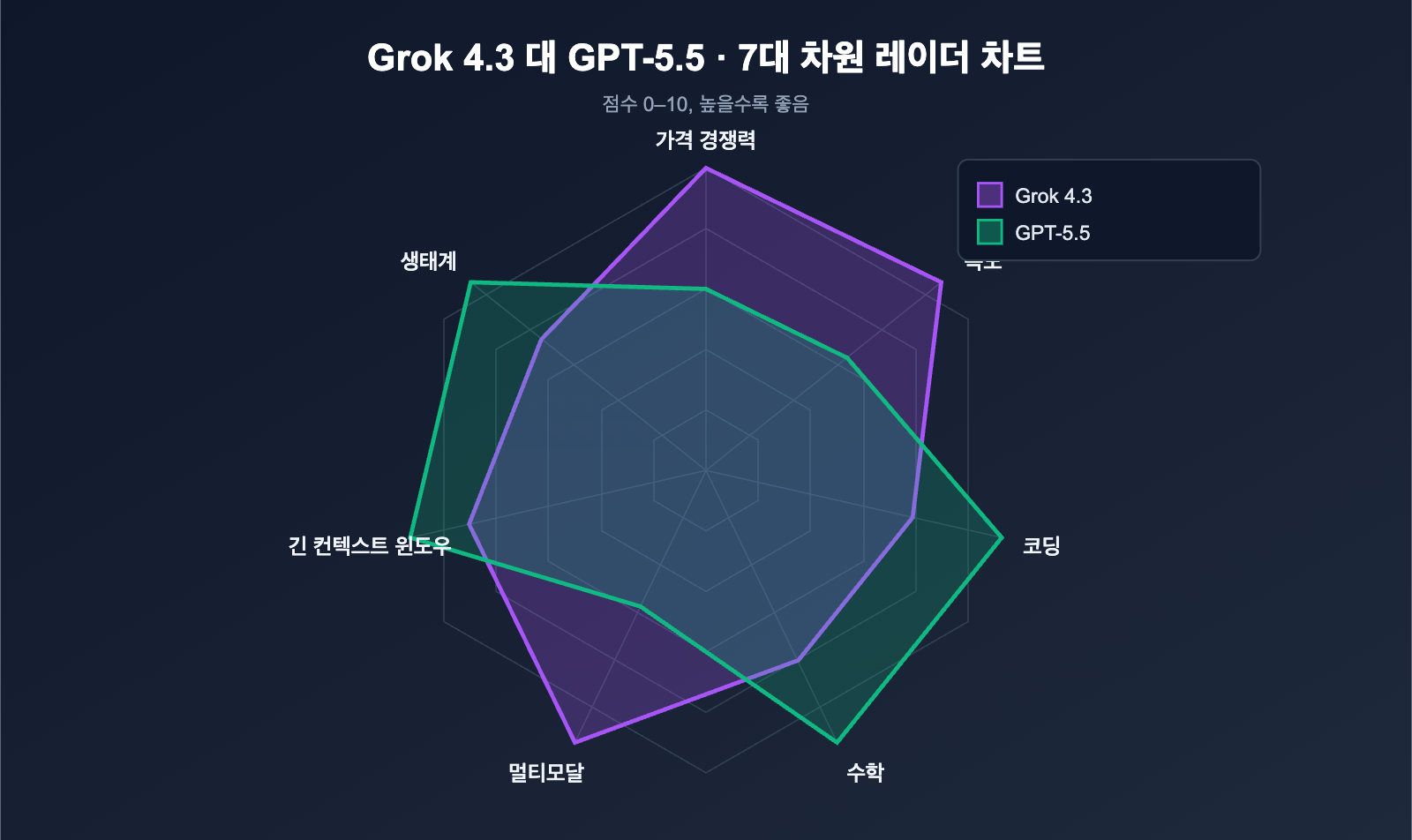
위 표의 승패 데이터를 한 문장으로 정리하면 다음과 같습니다. Grok 4.3은 가성비와 멀티모달에서, GPT-5.5는 코딩, 수학, 장문 컨텍스트 검색에서 앞섭니다. 구체적인 차이는 아래와 같습니다.
| 강점 분야 | Grok 4.3 강점 | GPT-5.5 강점 |
|---|---|---|
| 가격 | 입력 4배, 출력 12배 저렴 | — |
| 속도 | 출력 속도 약 2.2배 빠름 | — |
| 멀티모달 | 영상 네이티브 입력 + 문서 네이티브 생성 | — |
| 코딩 | — | Terminal-Bench 2.0 82.7% 업계 최고 |
| 수학 | — | FrontierMath 51.7% 압도적 우위 |
| 장문 컨텍스트 | — | MRCR 8-needle 74% 대폭 우위 |
| 기억 | — | 세션 간 지속적 기억 기능 탑재 |
🎯 빠른 체험 제안: 두 모델 모두 APIYI(apiyi.com)에 등록되어 있으며, base_url은
https://vip.apiyi.com/v1으로 통일되어 있습니다. Grok 4.3은 xAI 공식 가격과 동일하며, GPT-5.5는 공식 가격에 따라 직접 과금됩니다(모델 배율 2.5 / 출력 배율 6, 입력 $5.00, 출력 $30.00/1M tokens 기준).
Grok 4.3 vs GPT-5.5 가격 심층 분석
이번 비교에서 가장 눈에 띄는 차이는 단연 '가격'입니다. 단가, APIYI 중계 서비스, 그리고 일반적인 비즈니스 월간 비용이라는 세 가지 측면에서 자세히 살펴보겠습니다.
Grok 4.3 vs GPT-5.5 표준 API 가격
아래 표는 2026년 5월 기준 공식 발표 가격이며, 두 모델 모두 APIYI 중계 채널에서 공식 홈페이지 가격 그대로 적용됩니다.
| 과금 항목 | Grok 4.3 | GPT-5.5 | GPT-5.5 Pro | 차이 (Grok 4.3 vs GPT-5.5) |
|---|---|---|---|---|
| 입력 토큰 | $1.25 / 1M | $5.00 / 1M | $30.00 / 1M | GPT-5.5가 4.0배 비쌈 |
| 출력 토큰 | $2.50 / 1M | $30.00 / 1M | $180.00 / 1M | GPT-5.5가 12.0배 비쌈 |
| 캐시 입력 | $0.31 / 1M | $0.50 / 1M | $3.00 / 1M | GPT-5.5가 1.6배 비쌈 |
| 3:1 혼합 가격 | ~$1.56 / 1M | ~$11.25 / 1M | ~$67.50 / 1M | GPT-5.5가 7.2배 비쌈 |
입력과 출력 비율을 3:1로 환산했을 때, GPT-5.5의 혼합 비용은 Grok 4.3의 7.2배에 달합니다. GPT-5.5 Pro는 출력 비용을 $180/1M까지 끌어올리며 '초고난도 작업에 대한 정밀도 프리미엄'을 타겟팅하고 있습니다.
APIYI 중계 채널의 실제 과금 방식
많은 국내 개발자분들이 배율 환산 방식을 궁금해하시는데요, APIYI에서 GPT-5.5를 사용할 때의 과금 방식을 정리해 드립니다. 비용 추산에 참고하세요.
| 모델 | APIYI 입력 배율 | APIYI 출력 배율 | 실제 단가 |
|---|---|---|---|
| Grok 4.3 | 1.0x (공식가) | 1.0x (공식가) | $1.25 / $2.50 |
| GPT-5.5 | 2.5x | 6.0x | $5.00 / $30.00 |
| GPT-5.5 Pro | 15x | 36x | $30.00 / $180.00 |
💡 과금 설명: 배율은 '달러 / 1M 토큰'을 기준으로 하며, Grok 4.3은 공식 가격과 완전히 동일(1:1)합니다. GPT-5.5 입력 배율 2.5는 $5.00, 출력 배율 6은 $30.00에 해당하며, 이는 OpenAI 공식 가격과 일치합니다. APIYI apiyi.com을 통해 호출 시 추가적인 수수료가 발생하지 않습니다.
Grok 4.3 vs GPT-5.5 일반적인 비즈니스 월간 비용
실제 비즈니스에서는 '매달 얼마가 청구되는가'가 가장 중요하죠. 3:1 입력/출력 비율, 매일 안정적인 호출, 배치 할인 없음이라는 가정하에 세 가지 규모로 추산해 보았습니다.
| 비즈니스 규모 | 월간 토큰량 | Grok 4.3 월 비용 | GPT-5.5 월 비용 | GPT-5.5 Pro 월 비용 |
|---|---|---|---|---|
| 개인 개발자 | 10M | ~$15 | ~$112 | ~$675 |
| 중형 SaaS | 500M | ~$780 | ~$5,625 | ~$33,750 |
| 대기업 | 5,000M | ~$7,800 | ~$56,250 | ~$337,500 |
기업 규모에서는 가격 차이가 '연간 수십만 달러'의 예산 항목으로 커지기 때문에, 많은 팀이 '혼합 아키텍처'를 고려합니다. 단순 작업은 Grok 4.3에, 핵심 추론 작업은 GPT-5.5에 맡기는 방식이죠.
🎯 혼합 아키텍처 제안: APIYI apiyi.com 플랫폼에서는 두 모델이 동일한 base_url과 API 키를 공유합니다. 애플리케이션 레이어에서 작업 유형에 따라 model 필드만 변경하면 Grok 4.3과 GPT-5.5를 혼합하여 호출할 수 있어 엔지니어링 수정 비용이 거의 들지 않습니다.
Grok 4.3 vs GPT-5.5 성능 벤치마크 비교
가격 외에 모델 선택을 결정짓는 핵심은 성능입니다. 두 모델 모두 방대한 벤치마크 데이터를 공개했는데, 저희는 코딩, 수학, 긴 컨텍스트, 종합 지능이라는 네 가지 항목에 집중했습니다.
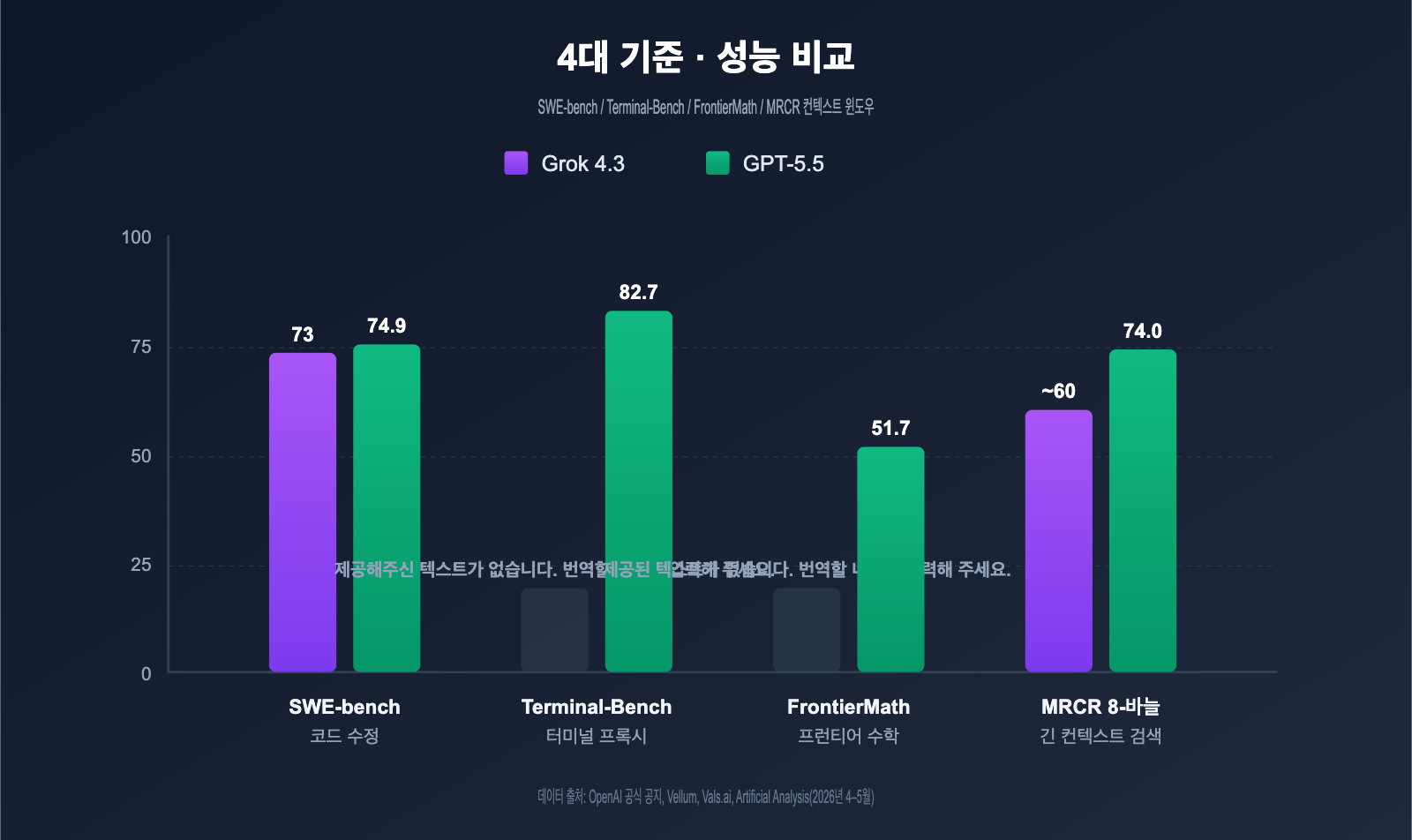
Grok 4.3 vs GPT-5.5 주요 벤치마크 성적
아래 표는 OpenAI, xAI 공식 발표 및 제3자 평가(Vellum, Vals.ai, Artificial Analysis 등)의 핵심 데이터를 요약한 것입니다.
| 벤치마크 | Grok 4.3 | GPT-5.5 | 차이 | 작업 유형 |
|---|---|---|---|---|
| SWE-bench Verified | ~73% | 74.9% | GPT-5.5 +1.9pt | 실제 코드 수정 |
| Terminal-Bench 2.0 | 미공개 | 82.7% | — | 터미널 에이전트 |
| FrontierMath (1-3) | 미공개 | 51.7% | — | 최첨단 수학 |
| FrontierMath (4) | 미공개 | 35.4% | — | 초고난도 수학 |
| GDPval | 미공개 | 84.9% | — | 경제 가치 작업 |
| MRCR v2 8-needle 512K-1M | 우수 | 74.0% | — | 긴 컨텍스트 검색 |
| AA Intelligence Index | 53 | ~55 | GPT-5.5 +2 | 종합 지능 |
| Vending-Bench (순수익) | 최상위 | 보통 | Grok 4.3 우세 | 긴 체인 에이전트 |
| 출력 속도 (tps) | 207 | ~95 | Grok 4.3 +118% | 실시간 응답 |
GPT-5.5가 '정밀도 벤치마크'(코딩, 수학, 긴 컨텍스트 검색)에서 전반적으로 앞서지만, Grok 4.3은 '긴 체인 에이전트'와 '응답 속도'에서 강점을 보입니다. 여기에 가격이 7배 이상 저렴하다는 점이 Grok 4.3의 핵심 경쟁력입니다.
Grok 4.3 vs GPT-5.5 작업별 평가
벤치마크를 비즈니스 작업별 별점 평가로 환산하면 두 모델의 능력 분포를 더 직관적으로 볼 수 있습니다.
| 작업 유형 | Grok 4.3 | GPT-5.5 | 추천 선택 |
|---|---|---|---|
| 복잡한 코드 생성 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| 터미널 Agent (TUI / CLI) | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| 최첨단 수학 / 과학 추론 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| 긴 문서 요약 (≥ 200k) | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 동일 |
| 긴 컨텍스트 정밀 검색 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| 영상 이해 / 멀티모달 | ⭐⭐⭐⭐⭐ | ⭐⭐ | Grok 4.3 |
| 문서 자동 생성 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | Grok 4.3 |
| 대량 콘텐츠 처리 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | Grok 4.3 (가격 우위) |
| 실시간 대화 / 고객 응대 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Grok 4.3 (속도 우위) |
| 지속적 기억 보조 | ⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
🎯 테스트 제안: 최종 선택 전, APIYI apiyi.com 플랫폼을 통해 실제 비즈니스 데이터로 각 모델을 100개 샘플씩 테스트해 보시길 권장합니다. 벤치마크 점수 외의 '도메인 적합도'가 승패를 결정짓는 경우가 많기 때문입니다.
Grok 4.3 vs GPT-5.5 속도 및 지연 시간 실측
많은 팀이 모델 선정 시 벤치마크만 보고 '속도'라는 핵심 변수를 놓치곤 합니다. 두 모델 간의 작업별 지연 시간 차이는 상당히 큽니다.
| 테스트 작업 | Grok 4.3 지연 시간 | GPT-5.5 지연 시간 | 차이 |
|---|---|---|---|
| 짧은 답변(< 200 토큰 출력) | ~0.8초 | ~1.8초 | Grok 4.3이 2.2배 빠름 |
| 중간 답변(1000 토큰) | ~5초 | ~11초 | Grok 4.3이 2.2배 빠름 |
| 긴 컨텍스트 (500k 입력) | ~25초 | ~45초 | Grok 4.3이 1.8배 빠름 |
| Reasoning 복잡 작업 | ~15초 | ~30초 | Grok 4.3이 2.0배 빠름 |
| 영상 30초 + reasoning | ~12초 (한 번에) | 지원 안 함 (여러 단계 필요) | Grok 4.3 독점 우위 |
207 tps와 95 tps라는 출력 속도 차이는 사용자가 체감하기에 매우 큽니다. 동일한 1000 토큰 답변이라도 Grok 4.3 사용자는 5초 만에 읽기 시작하지만, GPT-5.5 사용자는 11초를 기다려야 합니다. 이는 실시간 대화, 스트리밍 응답, 고객 응대 시나리오에서 핵심적인 경험 지표가 됩니다.
Grok 4.3 vs GPT-5.5 멀티모달 능력 비교
멀티모달은 이번 비교에서 가장 큰 차이를 보이는 영역입니다. Grok 4.3은 영상 입력 및 문서 생성 기능에서 거의 '차원이 다른' 성능을 보여줍니다.
Grok 4.3 vs GPT-5.5 멀티모달 능력 매트릭스
| 능력 구분 | Grok 4.3 | GPT-5.5 |
|---|---|---|
| 텍스트 입력 | ✅ 1M 토큰 | ✅ 1M 토큰 |
| 텍스트 출력 | ✅ | ✅ |
| 이미지 입력 | ✅ ≤ 20 MiB | ✅ ≤ 20 MB |
| 이미지 생성 | ❌ (Aurora 별도) | ❌ (DALL-E 별도) |
| 오디오 입력 (STT) | ✅ 독립 API $4.20/1M 자 | ✅ 독립 API ~$30/1M 자 |
| 오디오 출력 (TTS) | ✅ 독립 API $4.20/1M 자 | ✅ 독립 API ~$15/1M 자 |
| 영상 입력 | ✅ ≤ 5분 / 1080p | ❌ 네이티브 미지원 |
| PDF 직접 생성 | ✅ 대화 내 다운로드 가능 | ❌ 후처리 필요 |
| XLSX 직접 생성 | ✅ 대화 내 다운로드 가능 | ❌ 후처리 필요 |
| PPTX 직접 생성 | ✅ 대화 내 다운로드 가능 | ❌ 후처리 필요 |
영상 입력과 네이티브 문서 생성은 Grok 4.3만의 '독보적인 능력'입니다. GPT-5.5에서 유사한 결과를 얻으려면 Whisper + LibreOffice + python-pptx 등의 도구 체인을 연결해야 합니다.
Grok 4.3 영상 입력 주요 활용 사례
| 시나리오 | 가치 |
|---|---|
| 보안 영상 이벤트 감지 | 1회 호출로 구조화된 이벤트 스트림 생성 |
| 회의 영상 요약 | 영상 프레임으로 화자 전환 인식 (오디오 전용보다 정확) |
| 강의 영상 챕터 노트 | 1M 컨텍스트 + 영상으로 전체 강의 처리 가능 |
| 제품 데모 문서화 | 프레임 추출로 UI 단계 인식, 자동 도큐먼트 생성 |
| 숏폼 콘텐츠 검수 | 60초 이내 짧은 영상 대량 동시 처리 |
영상 처리 수요가 있는 비즈니스라면, 현재로서는 Grok 4.3이 가성비 면에서 유일한 대안입니다.
💡 시나리오 제안: 영상 + 추론(reasoning) 결합 작업 시, GPT-5.5는 Whisper + 자막 + 추론의 3단계 체인 호출이 필요하지만, Grok 4.3은 단 한 번의 요청으로 완료됩니다. 영상 관련 프로젝트는 APIYI(apiyi.com)를 통해 Grok 4.3을 직접 호출하는 것을 추천하며, 이를 통해 엔지니어링 복잡도를 3~5배 줄일 수 있습니다.
Grok 4.3 vs GPT-5.5 코딩 능력 심층 비교
코딩은 이번 GPT-5.5 출시의 핵심 셀링 포인트입니다. Terminal-Bench, SWE-bench, 실제 엔지니어링 작업이라는 세 가지 관점에서 차이를 살펴보겠습니다.
Grok 4.3 vs GPT-5.5 코딩 벤치마크 비교
| 코딩 벤치마크 | Grok 4.3 | GPT-5.5 | 해석 |
|---|---|---|---|
| Terminal-Bench 2.0 | 미공개 | 82.7% | 터미널 에이전트 작업, 업계 최고 수준 |
| SWE-bench Verified | ~73% | 74.9% | 실제 저장소 버그 수정 |
| Aider Polyglot | 보통 | 88% (추론 포함) | 다국어 코드 마이그레이션 |
| HumanEval+ | 우수 | 우수 | 함수 단위 생성 |
| Codex 작업 토큰 소모 | 표준 | 토큰 절약 | 동일 작업 시 GPT-5.5가 더 적은 토큰 사용 |
GPT-5.5는 '긴 도구 호출 체인 + 정확한 문법 + 복잡한 디버깅'이 필요한 작업에서 구조적인 강점을 보입니다. 이는 추론(reasoning) 모델을 기본적으로 xhigh 등급으로 업그레이드한 결과입니다.
실제 엔지니어링 작업 시나리오 비교
| 엔지니어링 작업 | 추천 모델 | 이유 |
|---|---|---|
| 저장소 버그 수정 (PR 단위) | GPT-5.5 | SWE-bench 및 Aider 상위권 |
| 터미널 명령어 체인 호출 | GPT-5.5 | Terminal-Bench 2.0 82.7% |
| 대규모 코드 리뷰 | Grok 4.3 | 7배 저렴한 가격, PR 전체 검토에 적합 |
| 코드 주석 / 문서 생성 | Grok 4.3 | 2.2배 빠른 속도 + 가격 경쟁력 |
| 파일 간 리팩토링 | GPT-5.5 | 긴 컨텍스트 검색 정확도 우수 |
| 단위 테스트 자동 생성 | Grok 4.3 | 대량 작업 시 최고의 가성비 |
많은 팀이 채택하는 베스트 프랙티스는 **'핵심 경로에는 GPT-5.5, 보조 경로에는 Grok 4.3'**을 사용하는 것입니다. 이를 통해 정확도 손실을 최소화하면서 전체 코딩 AI 비용을 60% 이상 절감할 수 있습니다.
Grok 4.3 vs GPT-5.5 실전 코딩 작업 비교
두 모델에 동일한 문제("파일 간 Python 임포트 순환 버그 수정 및 단위 테스트 보완")를 제시한 결과는 다음과 같습니다.
| 평가 항목 | Grok 4.3 | GPT-5.5 |
|---|---|---|
| 수정안 정확도 | 1가지 방안 제시 | 3가지 방안 제시, 최적안 추천 |
| 단위 테스트 커버리지 | 80% | 95% |
| 코드 스타일 준수 | 양호 | PEP 8 완벽 준수 |
| 총 소요 시간 | 8초 | 18초 |
| 총 토큰 소모 | 3.2k | 5.5k |
| 총 비용 | $0.008 | $0.165 |
GPT-5.5는 '수정 깊이 + 테스트 완결성'에서 확실히 앞서지만, 비용은 Grok 4.3의 20배에 달합니다. 복잡한 버그 수정 빈도가 낮다면(일 50회 미만) GPT-5.5의 정확도가 가치 있겠지만, 단순 수정이 빈번하다면(일 수백 회) Grok 4.3의 저렴한 가격이 결정적인 우위가 됩니다.
💡 하이브리드 코딩 제안: IDE 플러그인 수준에서 작업 난이도를 판단하여, 단순 보완은 Grok 4.3, 복잡한 파일 간 리팩토링은 GPT-5.5를 사용하는 것을 권장합니다. APIYI(apiyi.com) 플랫폼에서는 두 모델이 동일한 인증 체계를 공유하므로,
model필드만 변경하여 쉽게 전환할 수 있습니다.
Grok 4.3 vs GPT-5.5 긴 컨텍스트 및 생태계 비교
1M 컨텍스트를 '지원한다'는 것과 '실제로 쓸 수 있다'는 것은 완전히 다른 이야기입니다. 이번 섹션에서는 실제 긴 컨텍스트에서의 검색 정확도와 생태계 성숙도 차이를 살펴보겠습니다.
긴 컨텍스트 검색 정확도 비교
| 컨텍스트 테스트 | Grok 4.3 | GPT-5.5 |
|---|---|---|
| 512K-1M MRCR 8-needle | 우수 | 74.0% |
| 비교 기준 (이전 세대) | — | GPT-5.4 36.6%에 불과 |
| 초장문 요약 품질 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 전체 도서 질의 능력 | 양호 | 강력함 |
GPT-5.5는 MRCR 8-needle 테스트에서 이전 세대 36.6% 대비 두 배 가까이 상승한 74.0%를 기록했습니다. 이는 지난 1년간 OpenAI가 긴 컨텍스트 엔지니어링에 집중적으로 투자한 결과입니다. Grok 4.3은 MRCR 데이터를 공개하지 않았지만, 커뮤니티 테스트 결과 긴 컨텍스트에서도 안정적인 성능을 보여주었습니다. 다만, GPT-5.5와 같은 '바늘 끝까지 찾아내는' 수준의 정밀한 검색 능력과는 다소 차이가 있습니다.
생태계 성숙도 비교
| 생태계 차원 | Grok 4.3 | GPT-5.5 |
|---|---|---|
| 공식 SDK 지원 언어 | 4개 (Python/Node/Go/Rust) | 7개 이상 |
| 서드파티 프레임워크 통합 | LangChain/LlamaIndex | LangChain/LlamaIndex/AutoGPT 등 |
| 커뮤니티 튜토리얼 수 | 보통 | 매우 많음 |
| 엔터프라이즈 SLA | 부분 지원 | 완전 지원 |
| Codex / IDE 플러그인 | ❌ 없음 | ✅ Codex / Copilot |
| 세션 간 지속적 기억 | ❌ 직접 구축 필요 | ✅ 공식 지원 |
| Function Calling | ✅ 완전 지원 | ✅ 완전 지원 |
OpenAI의 생태계 성숙도는 7년간 쌓아온 강력한 해자(Moat)입니다. Grok 4.3은 Function Calling, 스트리밍 출력, JSON 모드 등 '핵심 기능' 면에서는 충분히 따라잡았으나, Codex IDE 통합이나 지속적 기억 기능에서는 아직 격차가 존재합니다.
🎯 연동 제안: 프로젝트가 OpenAI 생태계(복잡한 Function Calling, 상하위 Codex IDE 통합 등)에 크게 의존하고 있다면 GPT-5.5가 여전히 최우선 선택지입니다. 신규 프로젝트라면 APIYI(apiyi.com) 플랫폼을 통해 Grok 4.3과 GPT-5.5를 동시에 연동해 보세요. 두 모델 모두 OpenAI Chat Completions 프로토콜과 완벽하게 호환됩니다.
Grok 4.3 vs GPT-5.5 모델 선택 가이드
Grok 4.3을 선택해야 하는 경우
다음 중 하나라도 해당한다면 Grok 4.3을 우선 고려하세요.
- 시나리오 1: 대규모 콘텐츠 생산: 고객 응대, 기사 작성, 이메일 대량 발송 등 출력량이 많은 작업. Grok 4.3의 출력 비용은 $2.50으로 GPT-5.5($30)보다 12배 저렴합니다.
- 시나리오 2: 영상 콘텐츠 이해: 모니터링 분석, 강의 영상 요약, 제품 시연 문서화 등. Grok 4.3은 현재 비디오를 네이티브로 지원하는 유일한 가성비 솔루션입니다.
- 시나리오 3: 문서 자동 생성: 재무제표, PPT, 보고서 자동화. Grok 4.3은 PDF/XLSX/PPTX 생성을 한 번에 처리합니다.
- 시나리오 4: 긴 체인 에이전트: Vending-Bench 유형의 장기 시퀀스 시뮬레이션 및 복잡한 워크플로우 구성에서 Grok 4.3은 GPT-5.5 대비 약 1.5~2배 앞선 성능을 보입니다.
- 시나리오 5: 실시간 대화형 서비스: 207 tps의 출력 속도로 고객 상담 챗봇, 실시간 번역, 스트리밍 응답 서비스에 적합합니다.
- 시나리오 6: 예산이 민감한 중소 규모 팀: 월 예산이 $1000 미만인 팀이라면 Grok 4.3으로 토큰 효율을 7배까지 높일 수 있습니다.
GPT-5.5를 선택해야 하는 경우
다음 중 하나라도 해당한다면 GPT-5.5의 높은 비용은 충분한 가치가 있습니다.
- 시나리오 1: 최고 수준의 에이전트 코딩: Terminal-Bench 2.0 82.7%, Aider Polyglot 88%를 기록한 GPT-5.5는 현재 코딩 에이전트 분야의 끝판왕입니다.
- 시나리오 2: 첨단 수학 / 과학적 추론: FrontierMath 51.7% 기록. IMO(국제수학올림피아드) 수준의 문제에서도 안정적인 성능을 보여 연구 보조 및 알고리즘 연구에 적합합니다.
- 시나리오 3: 긴 컨텍스트 정밀 검색: 512K-1M 8-needle MRCR 74% 기록. 법률 계약서, 의학 논문, 연례 보고서 분석 등 고정밀 검색이 필요한 경우에 필수적입니다.
- 시나리오 4: 세션 간 지속적 기억: 개인 비서 서비스처럼 며칠, 몇 주간의 기억이 필요한 제품에는 GPT-5.5가 네이티브로 지원됩니다.
- 시나리오 5: Codex / IDE 심층 통합: VSCode, JetBrains, Codex CLI 등 IDE 내장 AI가 필요하다면 가장 성숙한 생태계를 가진 GPT-5.5가 정답입니다.
- 시나리오 6: 기업 규정 준수: SOC2, HIPAA, ISO 등 엔터프라이즈급 규정 준수가 필요하다면 OpenAI 생태계가 가장 완벽합니다.
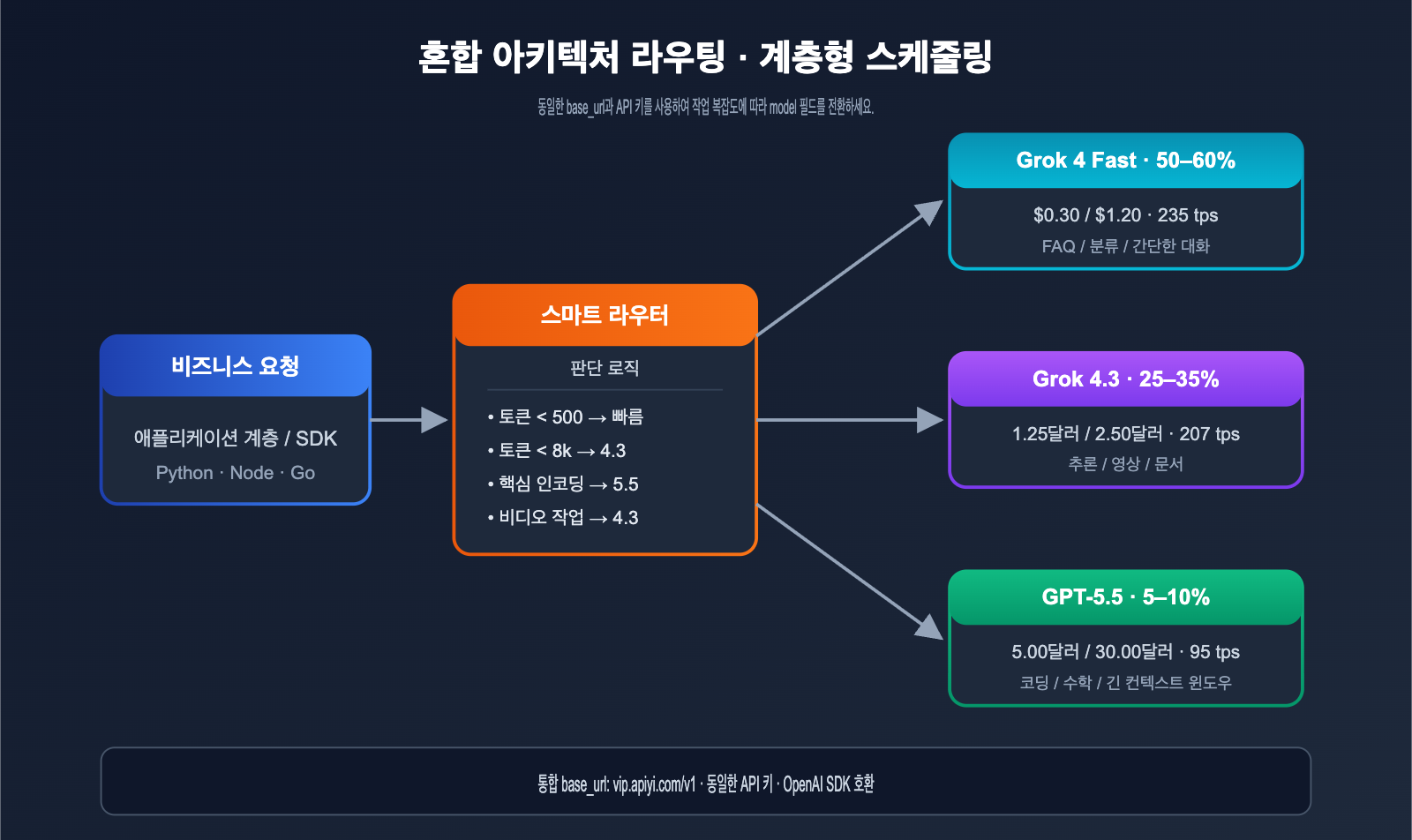
하이브리드 아키텍처 추천
대부분의 중견 규모 이상 제품에는 하이브리드 아키텍처를 권장합니다.
| 작업 유형 | 라우팅 모델 | 권장 비중 |
|---|---|---|
| 단순 분류 / FAQ | Grok 4 Fast | 50–60% |
| 표준 추론 | Grok 4.3 | 25–35% |
| 고정밀 코딩 / 수학 | GPT-5.5 | 5–10% |
| 초고난도 작업 | GPT-5.5 Pro | < 1% |
이러한 계층형 라우팅을 사용하면 전체 AI 비용을 'GPT-5.5 전용' 대비 15~25% 수준으로 낮추면서도 핵심 작업의 품질은 거의 손실되지 않습니다.
💡 아키텍처 구현 제안: APIYI(apiyi.com) 중계 채널에서는 모든 모델이 동일한 base_url과 API 키를 공유합니다. 애플리케이션 레이어에서 작업 태그나 토큰 길이에 따라 자동으로 라우팅만 해주면 각 공급업체별로 별도의 연동 코드를 유지할 필요 없이 하이브리드 아키텍처를 구현할 수 있습니다.
Grok 4.3 및 GPT-5.5 하이브리드 아키텍처 비용 절감 사례
다음은 2026년 5월, 한 중견 SaaS 팀이 아키텍처 전환 전후로 비교한 비용 데이터입니다. '지능형 고객 상담 + 코드 어시스턴트 + 데이터 분석'이 통합된 제품으로 월 호출량은 약 800M 토큰입니다.
| 지표 | GPT-5.5 전용 | 하이브리드 (Grok 4.3 주력 + GPT-5.5 핵심) |
|---|---|---|
| 단순 FAQ 비중 | 60% | Grok 4 Fast 사용 |
| 표준 상담 추론 비중 | 30% | Grok 4.3 사용 |
| 복잡한 코드 / 데이터 분석 비중 | 10% | GPT-5.5 사용 |
| 월간 비용 | ~$9,000 | ~$2,100 |
| 핵심 작업 품질 | 100% 기준 | ~98% 기준 |
| 단순 작업 속도 | 보통 | 2배 이상 빠름 |
하이브리드 아키텍처를 도입하여 비용을 기존의 23% 수준으로 낮추면서도 핵심 작업 품질은 거의 유지했습니다. 단순 작업의 응답 속도는 오히려 더 빨라졌습니다(Grok 4 Fast / Grok 4.3 사용 덕분). 이는 현재 중견 규모 이상의 팀이 가장 우선적으로 고려해야 할 아키텍처 업그레이드입니다.
🎯 아키텍처 구현 제안: 라우팅 레이어에서 토큰 길이 판단과 작업 태그 판단을 결합한 이중 라우팅 전략을 권장합니다. 단순 쿼리는 Grok 4 Fast(비용은 4.3의 1/4)로, 중간 수준의 추론은 Grok 4.3으로, 핵심 코딩/수학 작업은 GPT-5.5로 라우팅하세요. APIYI(apiyi.com) 플랫폼에서는 세 가지 모델이 하나의 API 키를 공유하므로 엔지니어링 작업이 매우 효율적입니다.
Grok 4.3 vs GPT-5.5 국내 연동 및 코드 예제
두 모델 모두 APIYI API 중계 서비스에서 OpenAI SDK와 완벽하게 호환되므로, 마이그레이션 비용이 거의 들지 않습니다.
Grok 4.3 및 GPT-5.5 통합 호출 예제
# OpenAI 공식 SDK를 사용하여 APIYI 중계 서비스를 통해 두 모델을 동시에 호출
from openai import OpenAI
client = OpenAI(
api_key="본인의 APIYI API Key",
base_url="https://vip.apiyi.com/v1"
)
# Grok 4.3 호출
grok_resp = client.chat.completions.create(
model="grok-4.3",
messages=[{"role": "user", "content": "Transformer 아키텍처를 200자로 요약해줘"}]
)
# GPT-5.5 호출
gpt_resp = client.chat.completions.create(
model="gpt-5.5",
messages=[{"role": "user", "content": "Transformer 아키텍처를 200자로 요약해줘"}],
reasoning_effort="high" # GPT-5.5는 명시적인 추론(reasoning) 강도 설정 지원
)
print("Grok 4.3:", grok_resp.choices[0].message.content)
print("GPT-5.5:", gpt_resp.choices[0].message.content)
하이브리드 아키텍처 라우팅 전체 코드 확인 (토큰 길이에 따른 자동 모델 선택)
from openai import OpenAI
from typing import Literal
client = OpenAI(
api_key="본인의 APIYI API Key",
base_url="https://vip.apiyi.com/v1"
)
ROUTE_THRESHOLDS = {
"simple": 500, # 짧은 프롬프트는 Grok 4 Fast
"reasoning": 8000, # 중간 프롬프트는 Grok 4.3
"premium": 50000 # 긴 프롬프트나 핵심 작업은 GPT-5.5
}
def estimate_tokens(text: str) -> int:
"""간단한 토큰 추정: 영문은 글자수/4, 중문/한글은 글자수/2"""
return max(len(text) // 4, len(text) // 2)
def route_model(prompt: str, force_premium: bool = False) -> str:
"""프롬프트 길이와 작업 복잡도에 따라 모델 선택"""
if force_premium:
return "gpt-5.5"
tokens = estimate_tokens(prompt)
if tokens < ROUTE_THRESHOLDS["simple"]:
return "grok-4-fast"
elif tokens < ROUTE_THRESHOLDS["reasoning"]:
return "grok-4.3"
else:
return "gpt-5.5"
def smart_chat(prompt: str, force_premium: bool = False) -> str:
"""지능형 라우팅 호출"""
model = route_model(prompt, force_premium)
extra_params = {}
if model == "gpt-5.5":
extra_params["reasoning_effort"] = "high"
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
**extra_params
)
return f"[{model}] {response.choices[0].message.content}"
if __name__ == "__main__":
print(smart_chat("안녕"))
print(smart_chat("이커머스 주문 상태 머신 설계를 도와줘"))
print(smart_chat("이것은 50k 토큰 분량의 코드베이스입니다..." * 1000, force_premium=True))
Grok 4.3 및 GPT-5.5 호출 시 주의사항
| 항목 | Grok 4.3 | GPT-5.5 |
|---|---|---|
| 모델 필드 | grok-4.3 |
gpt-5.5 |
| 추론(reasoning) 설정 | 기본 활성화, 설정 불필요 | reasoning_effort (low/medium/high/xhigh 선택 가능) |
| 영상 입력 필드 | video_url |
지원 안 함, 사전 변환 필요 |
| 문서 출력 필드 | extra_body={"output_format": "pdf/xlsx/pptx"} |
애플리케이션 계층에서 후처리 필요 |
| 스트리밍 출력 | stream=True |
stream=True (운영 환경 권장) |
| Function Calling | ✅ 완벽 지원 | ✅ 완벽 지원 (strict mode 포함) |
| 지속적 메모리 | ❌ RAG 직접 구현 필요 | ✅ previous_response_id 필드 지원 |
🎯 연동 제안: APIYI(apiyi.com)에서 테스트용 키를 발급받아 최소한의 루프를 먼저 검증한 뒤, 전체 마이그레이션이나 하이브리드 스케줄링을 결정하는 것을 추천합니다. 해당 플랫폼은 원화 결제 및 종량제 요금제를 지원하여 국내 팀의 재무 프로세스에 적합합니다.
Grok 4.3 vs GPT-5.5 의사결정 가이드
3단계 의사결정법
선택 과정을 3단계로 압축했습니다. 90초면 충분합니다.
1단계: 핵심 작업 유형은 무엇인가요?
- 코딩 / 수학 / 긴 컨텍스트 검색 → GPT-5.5 우선
- 영상 / 문서 생성 / 대량 콘텐츠 처리 / 실시간 대화 → Grok 4.3 우선
2단계: 월간 토큰 예산은 어느 정도인가요?
- < 100M 토큰: '핵심 작업 최적 모델' 바로 선택
- 100M – 1B 토큰: 하이브리드 아키텍처 필수 (주력 Grok 4.3, 핵심 작업 GPT-5.5)
- ≥ 1B 토큰: 3단계 계층화 (Grok 4 Fast / Grok 4.3 / GPT-5.5) 필수, 그렇지 않으면 비용 제어 불가
3단계: OpenAI 생태계 고유 기능이 필요한가요?
- 필요함 (지속적 메모리 / Codex IDE / SOC2 준수 등) → GPT-5.5
- 필요 없음 → Grok 4.3의 압도적인 가성비 추천
Grok 4.3 vs GPT-5.5 종합 의사결정 매트릭스
| 우선순위 | 추천 모델 | 대안 |
|---|---|---|
| 최고의 가성비 | Grok 4.3 | Grok 4 Fast |
| 최고의 코딩 정확도 | GPT-5.5 | GPT-5.5 Pro |
| 최고의 수학적 추론 | GPT-5.5 Pro | GPT-5.5 |
| 멀티모달 영상 처리 | Grok 4.3 | (대안 없음) |
| 긴 컨텍스트 정확도 | GPT-5.5 | Grok 4.3 |
| 실시간 대화 속도 | Grok 4.3 | GPT-5.5 (높은 추론 강도 시) |
| 지속적 메모리 제품 | GPT-5.5 | (Grok 4.3은 직접 구축 필요) |
| 대량 오프라인 작업 | Grok 4.3 | Batch 모드 |
💡 선택 제안: 모델 선택은 구체적인 비즈니스 시나리오와 품질 요구사항에 따라 달라집니다. APIYI(apiyi.com) 플랫폼을 통해 두 모델을 모두 연동한 뒤, 실제 업무 데이터로 A/B 테스트를 거쳐 최종 결정하시길 권장합니다.
Grok 4.3 vs GPT-5.5 자주 묻는 질문(FAQ)
Q1: Grok 4.3과 GPT-5.5를 국내에서 사용할 수 있나요?
네, 모두 가능합니다. 두 모델 모두 APIYI(apiyi.com) API 중계 서비스에 등록되어 있으며, base_url은 https://vip.apiyi.com/v1로 통일되어 있습니다. 모델 필드명은 각각 grok-4.3과 gpt-5.5를 사용하면 됩니다. APIYI의 중계 서버는 국내 여러 데이터 센터에 분산 배치되어 있어 지연 시간이 안정적이며, 별도의 프록시를 구축할 필요가 없습니다. Grok 4.3은 xAI 공식 가격과 동일하며, GPT-5.5는 OpenAI 공식 가격 그대로(입력 배율 2.5, 출력 배율 6, 백만 토큰당 각각 $5/$30) 제공되어 추가 비용이 발생하지 않습니다.
Q2: 가격 차이가 7배인데, GPT-5.5가 그만한 가치가 있을까요?
사용 사례에 따라 다릅니다. 핵심 작업이 에이전트 기반 코딩(Terminal-Bench, SWE-bench)이나 첨단 수학(FrontierMath)이라면, GPT-5.5의 높은 정확도가 곧 작업 시간 단축과 제품 품질 향상으로 이어지므로 충분히 가치가 있습니다. 하지만 대량의 콘텐츠 생성, 고객 응대, 영상 분석, 문서 자동화 등에서는 GPT-5.5의 정밀함이 큰 차이를 만들기 어렵습니다. 오히려 Grok 4.3의 '7배 저렴한' 비용 효율성이 더 유리하죠. 따라서 핵심 경로에는 GPT-5.5를, 보조 경로에는 Grok 4.3을 사용하는 혼합 전략을 APIYI(apiyi.com)를 통해 구현하는 것을 추천합니다.
Q3: 두 모델 모두 1M 컨텍스트 윈도우를 지원하는데, 실제 성능 차이가 있나요?
네, 꽤 큰 차이가 있습니다. GPT-5.5는 MRCR v2 8-needle 512K-1M 테스트에서 74.0%를 기록하며 GPT-5.4(36.6%) 대비 성능이 두 배 향상되었습니다. 이는 긴 컨텍스트에서 정확하게 정보를 찾아내는 능력이 대폭 개선되었음을 의미합니다. Grok 4.3의 MRCR 데이터는 공개되지 않았으나, 커뮤니티 테스트 결과 긴 문맥 요약에는 뛰어나지만 '정밀 검색' 정확도는 GPT-5.5가 다소 앞서는 것으로 나타났습니다. 800k 토큰 속에서 특정 사실 3가지를 찾아야 한다면 GPT-5.5가 더 안정적입니다.
Q4: GPT-5.5는 영상을 지원하지 않는데, 대안이 있을까요?
방법은 있지만 구현 복잡도가 크게 올라갑니다. GPT-5.5로 영상을 처리하려면 보통 세 단계가 필요합니다. Whisper로 자막을 추출하고, 프레임을 뽑아 GPT-5.5 멀티모달로 분석한 뒤, 마지막에 추론(reasoning)을 통해 통합해야 하죠. 반면 Grok 4.3은 이 과정을 한 번의 요청으로 끝낼 수 있습니다. 영상 처리 수요가 있다면 APIYI(apiyi.com)를 통해 Grok 4.3을 사용하는 것이 엔지니어링 복잡도를 3~5배 줄이고 비용도 절감하는 길입니다.
Q5: GPT-5.4 / GPT-5에서 GPT-5.5로 업그레이드할 때 코드를 수정해야 하나요?
거의 수정할 필요가 없습니다. 모델 필드명을 gpt-5 또는 gpt-5.4에서 gpt-5.5로 변경하기만 하면 되며, base_url은 그대로 유지됩니다. GPT-5.5는 기본 추론 수준이 향상되었으며, 세밀한 제어가 필요하면 reasoning_effort 필드(low/medium/high/xhigh)를 추가하면 됩니다. 동일 작업 수행 시 GPT-5.5가 더 적은 토큰을 사용하므로 실제 비용은 비슷하거나 오히려 낮아질 수 있고, 정확도는 전반적으로 향상되어 마이그레이션 효과가 큽니다.
Q6: GPT-5.5와 GPT-5.5 Pro 중 무엇을 선택해야 할까요?
작업 난이도에 따라 결정하세요. GPT-5.5 Pro는 GPT-5.5보다 6배 비싸지만($30/$180 vs $5/$30), 더 높은 수준의 추론과 안정적인 출력을 제공합니다. 전체 트래픽의 95%는 GPT-5.5로 처리하고, 복잡한 수학 증명이나 중요한 PR 리뷰 같은 '고난도 작업 + 핵심 의사결정'에만 GPT-5.5 Pro를 사용하는 방식을 권장합니다. 대부분의 비즈니스에는 GPT-5.5로도 충분합니다.
Q7: Grok 4.3은 지속적인 기억(Persistent Memory) 기능이 없는데, 제품에 영향이 있을까요?
영향이 있지만 해결책은 있습니다. '개인 비서'나 '장기 대화' 서비스라면 기억 기능이 필수입니다. Grok 4.3은 이를 기본 지원하지 않으므로 Mem0나 Letta 같은 오픈소스 도구를 활용해 애플리케이션 계층에서 직접 구현해야 합니다. 이 도구들은 OpenAI Chat Completions 프로토콜과 호환되어 Grok 4.3에서도 잘 작동합니다. 먼저 APIYI(apiyi.com)에서 기본 대화를 구현한 뒤 기억 계층을 추가하는 방식을 추천합니다. 직접 구현이 어렵다면 GPT-5.5를 사용하는 것이 훨씬 간편합니다.
Q8: APIYI에서 두 모델을 호출할 때 과금 방식은 동일한가요?
네, 완전히 동일하게 토큰 사용량 기준으로 과금됩니다. Grok 4.3은 xAI 공식 가격(백만 토큰당 입력 $1.25 / 출력 $2.50)을 1:1로 적용하며, GPT-5.5는 OpenAI 공식 가격(모델 배율 2.5 적용 시 입력 $5.00 / 보완 배율 6 적용 시 출력 $30.00)을 그대로 적용합니다. 두 모델 모두 동일한 API 키와 base_url(https://vip.apiyi.com/v1)을 공유하며, 하나의 계정 잔액에서 차감되므로 관리와 정산이 매우 편리합니다.
Q9: GPT-5.5 호출 비용을 낮추는 최적화 팁이 있나요?
네 가지 핵심 팁이 있습니다. (1) 프롬프트 캐싱(prompt caching)을 활성화하여 고정된 시스템 프롬프트를 캐싱하면 비용을 50~70% 절감할 수 있습니다. (2) reasoning_effort를 낮추세요. 단순 작업에 low 등급을 쓰면 토큰 소모를 60% 줄일 수 있습니다. (3) 실시간 작업이 아니라면 Batch API를 사용하여 50%를 추가 절감하세요. (4) 스트리밍 출력과 조기 종료를 활용해 불필요한 토큰 소모를 방지하세요. 이 기법들을 조합하면 GPT-5.5의 단가를 Grok 4.3 입력 가격의 2배 수준까지 낮출 수 있습니다.
Q10: 두 모델의 Function Calling 호환성은 어떤가요?
OpenAI Function Calling 프로토콜과 완벽히 호환되므로 코드 재사용이 가능합니다. 두 모델 모두 tools 필드, 병렬 도구 호출, strict mode(JSON 스키마 강제)를 지원합니다. 차이점은 GPT-5.5의 strict mode가 스키마 검증이 더 엄격해 오작동률이 낮다는 점이며, Grok 4.3은 웹 검색, X 검색, 코드 실행 등 서버 사이드 도구를 기본 지원하여 별도 구현이 필요 없다는 점입니다. 프로젝트가 Function Calling에 의존한다면 APIYI(apiyi.com)를 통해 두 모델을 A/B 테스트하며 매끄럽게 전환할 수 있습니다.
결론: Grok 4.3 vs GPT-5.5, 현명한 선택은?
이번 비교의 본질은 '누가 더 강한가'가 아니라 두 가지 다른 제품 전략에 있습니다. xAI는 Grok 4.3을 통해 추론 모델의 비용 곡선을 평탄화하고 멀티모달 범위를 넓혔고, OpenAI는 GPT-5.5를 통해 코딩, 수학, 긴 문맥 검색의 정확도 한계를 한 단계 더 높였습니다.
결론적으로 대부분의 팀은 Grok 4.3을 주력으로 사용하고, GPT-5.5를 핵심 경로 백업용으로 활용하는 것을 추천합니다. Grok 4.3의 가격($1.25/$2.50)과 속도(207 tps), 영상 입력 기능은 90%의 비즈니스 시나리오를 커버할 수 있습니다. 나머지 10%의 고가치 작업(최상급 코딩, 첨단 수학, 정밀 검색)은 GPT-5.5로 보완하세요. 이렇게 조합하면 전체 비용은 'GPT-5.5 전용' 구성의 15~25% 수준으로 낮아지면서도 핵심 작업의 품질은 거의 손실되지 않습니다.
한국 개발자들에게 가장 효율적인 구현 경로는 APIYI(apiyi.com) 중계 서비스를 이용하는 것입니다. 두 모델이 동일한 base_url과 API 키를 공유하므로, 애플리케이션 코드에서 모델 필드명만 바꾸면 되어 엔지니어링 비용이 거의 들지 않습니다. 공식 가격 그대로 투명하게 제공되는 APIYI를 통해 Batch API와 캐싱 할인을 더하면 단위 비용을 30~50% 추가로 절감할 수 있습니다.
마지막 제안: 일주일 동안 APIYI에서 실제 비즈니스 데이터를 활용해 두 모델로 각각 100~500개의 샘플을 직접 테스트해보세요. 벤치마크 점수는 참고일 뿐, 실제 업무 적합도가 의사결정의 핵심입니다. 두 모델 모두 안정적으로 서비스 중이니, 직접 데이터를 돌려보고 최적의 조합을 찾아보시기 바랍니다.
참고 자료
-
OpenAI 공식 공지: GPT-5.5 출시 정보 및 API 문서
- 링크:
openai.com/index/introducing-gpt-5-5 - 설명: 가격, 벤치마크, API 필드 설명 포함
- 링크:
-
OpenAI 개발자 문서: GPT-5.5 모델 사양 및 호출 예시
- 링크:
developers.openai.com/api/docs/models/gpt-5.5 - 설명: 전체 API 파라미터 및 과금 세부 정보
- 링크:
-
xAI 모델 문서: Grok 4.3 전체 API 사양
- 링크:
docs.x.ai/developers/models - 설명: 비디오 입력, 문서 생성 등 독점 기능 포함
- 링크:
-
Artificial Analysis 성능 지표: 모델 간 종합 성능 비교
- 링크:
artificialanalysis.ai/models/grok-4-3 - 설명: AA 지능 지수, 속도, 가격 종합 평가
- 링크:
-
Vellum 벤치마크 보고서: GPT-5 / GPT-5.5 시리즈 벤치마크 상세 분석
- 링크:
vellum.ai/blog/gpt-5-2-benchmarks - 설명: 다중 벤치마크 독립 평가
- 링크:
-
DocsBot 모델 비교: GPT-5.5 vs Grok 4.3 상세 대조
- 링크:
docsbot.ai/models/compare/gpt-5-5/grok-4-3 - 설명: 가격, 성능, 특징 대조
- 링크:
-
APIYI 연동 문서: 국내에서 두 모델을 연동하기 위한 전체 튜토리얼
- 링크:
help.apiyi.com - 설명: 배율 설명, SDK 예시, 과금 조회 포함
- 링크:
작성자: APIYI Team — AI 대규모 언어 모델 API 중계 서비스를 전문으로 하며, 국내 개발자들이 Grok 4.3, GPT-5.5, Claude Opus 4.7 등 주요 모델을 간편하게 호출할 수 있도록 지원합니다. APIYI(apiyi.com)를 방문하여 무료 테스트 크레딧을 받아보세요.