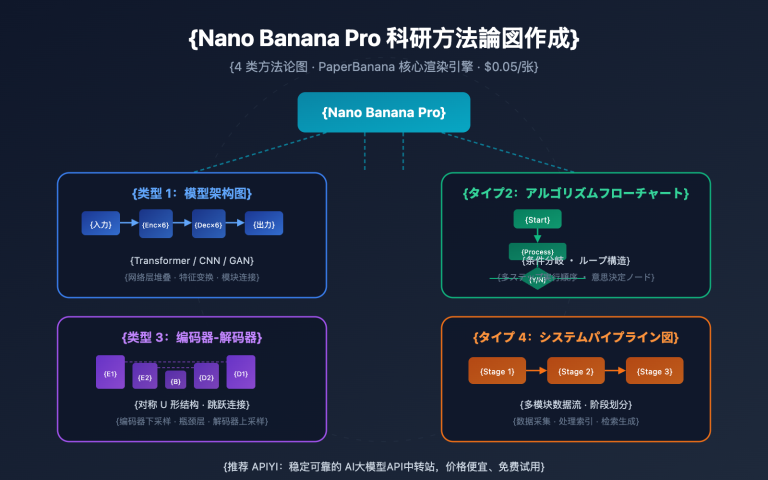
著者注:PaperBananaがいかにしてピクセル画像ではなく実行可能なMatplotlibコードを生成することで、学術統計グラフを制作し、数値幻覚問題を完全に排除しているかを詳しく解説します。棒グラフ、折れ線グラフ、散布図など7種類のチャートを網羅しています。
学術論文における統計グラフは、実験の核心的な結論を担っています。棒グラフの高さ、折れ線グラフのトレンド、散布図の分布など、すべてのデータポイントが正確無比でなければなりません。しかし、DALL-EやMidjourneyのような汎用画像生成器で統計グラフを作成しようとすると、常に致命的な問題がつきまといます。それが、数値幻覚(Numerical Hallucination)です。棒の高さと目盛りが一致しない、データポイントがずれる、軸ラベルが誤っている——こうした「見た目は正しいがデータが間違っている」グラフが論文に掲載されれば、取り返しのつかない結果を招きます。
核心となる価値: この記事を読み終える頃には、PaperBananaがなぜ画像生成ではなくコード生成を選択して学術統計グラフを作成するのか、その理由を理解できるでしょう。また、7種類の統計グラフのMatplotlibコード生成方法を習得し、Nano Banana Pro APIを通じて低コストで数値幻覚ゼロの学術データ可視化を実現する方法を学ぶことができます。
Nano Banana Pro 研究用統計図の核心ポイント
| ポイント | 説明 | 価値 |
|---|---|---|
| ピクセルではなくコード生成 | PaperBananaは直接画像をレンダリングするのではなく、実行可能なMatplotlibコードを生成します | 棒の高さ、データポイント、座標軸が100%数学的に正確です |
| 数値的ハルシネーションを完全に排除 | コード駆動により、各データポイントの数値が元のデータと完全に一致することを保証します | 「見た目は正しいがデータが間違っている」という致命的な問題を根絶します |
| 7種類のチャートを網羅 | 棒グラフ、折れ線グラフ、散布図、ヒートマップ、レーダーチャート、円グラフ、マルチパネル図 | 論文の統計図ニーズの95%以上をカバー |
| 240個のChartMimicテスト | 標準ベンチマークで、生成されたコードの実行可能性と視覚的な一致を検証済み | ブラインド評価で72.7%の勝率、折れ線/棒/散布図/マルチパネルを網羅 |
| 編集可能かつ再現可能 | 出力されたPythonコードで色、注釈、フォントを自由に調整可能 | 再生成の必要がなく、そのまま出版レベルまでブラッシュアップ可能 |
なぜ研究用の統計図を画像生成で作成してはいけないのか
従来のAI画像生成モデル(DALL-E 3やMidjourney V7など)は、研究用の統計図を作成する際に根本的な欠陥を抱えています。それは、チャートを「データ」に基づいて描画するのではなく、「ピクセル」としてレンダリングしてしまう点です。
つまり、モデルが棒グラフを生成する際、[85, 72, 91, 68] といった数値に基づいて棒の高さを計算するのではなく、「棒グラフのように見える」視覚的なパターンに従ってピクセルを埋めているに過ぎないのです。
その結果、数値的ハルシネーション(幻覚)が発生します。棒の高さがY軸の目盛りと一致しない、データポイントが実際の位置からずれる、あるいは軸ラベルが文字化けしたり誤ったりするといった問題です。PaperBananaの評価では、画像生成モデルを直接使用して統計図を作成した場合、「数値的ハルシネーションと要素の重複」が最も頻繁に見られる忠実度のエラーでした。
PaperBananaは全く異なる戦略を採用しています。統計チャートに対して、VisualizerエージェントはNano Banana Proの画像生成機能を呼び出すのではなく、実行可能なPythonのMatplotlibコードを生成します。この「コード優先」のアプローチは、数値的ハルシネーションを根本から排除します。なぜなら、コードが正確な数学的計算に従ってデータと視覚要素を紐付けるからです。
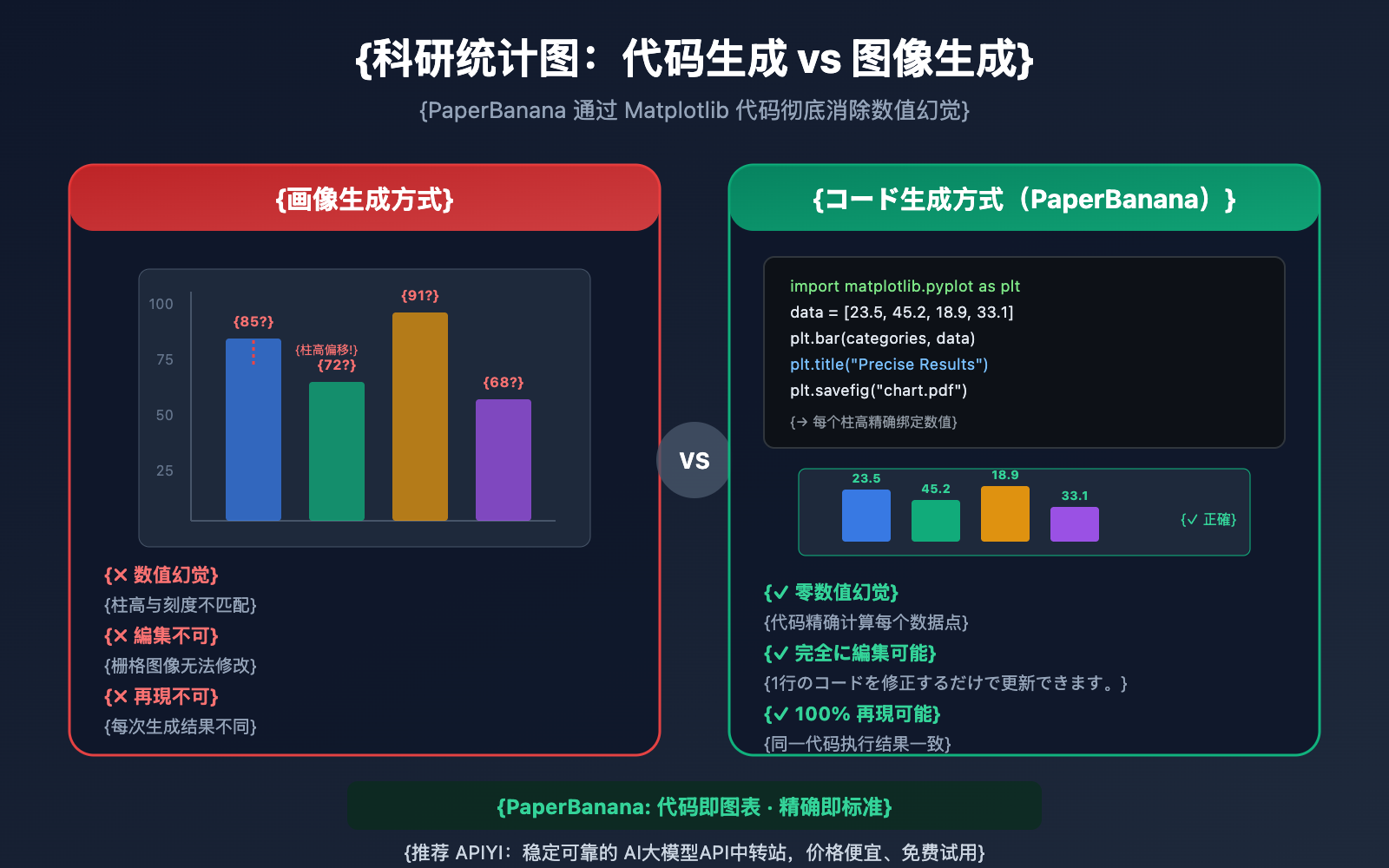
数値幻覚問題の徹底解説
科研統計図における数値幻覚とは何か
数値幻覚(Numerical Hallucination)とは、AI画像生成モデルが統計図表を作成する際、生成された視覚的要素が実際のデータと一致しない現象を指します。具体的な症状には以下のようなものがあります。
- 棒グラフの高さのズレ: 棒グラフのバーの高さが、Y軸の目盛り値と対応していない
- データポイントのドリフト: 散布図内の点が、正しい (x, y) 座標から外れている
- 目盛りの誤り: 座標軸の目盛り間隔が不均等、または数値のラベルが間違っている
- 凡例の混乱: 凡例の色が実際のデータシリーズと一致しない
- ラベルの文字化け: 座標軸ラベルにスペルミスや文字の重なりが生じる
数値幻覚の根本原因
汎用的な画像生成モデルの訓練目標は「視覚的にリアルな画像を生成すること」であり、「データとして正確な図表を生成すること」ではありません。モデルがプロンプト内の「棒グラフ、数値 [85, 72, 91, 68]」という指示を受け取ったとき、数値からピクセル単位の高さへの数学的なマッピングを構築するのではなく、訓練セットに含まれる大量の棒グラフの「視覚的パターン」に基づいて、それらしい外見を生成しているに過ぎません。
| 問題の種類 | 具体的な現象 | 発生頻度 | 深刻度 |
|---|---|---|---|
| 棒グラフの高さのズレ | バーの高さが数値と一致しない | 極めて高い | 致命的:実験の結論が変わる |
| データポイントのドリフト | 散布図の点が正しい座標から外れる | 高い | 致命的:データの歪曲 |
| 目盛りの誤り | 座標軸の目盛りが不均等 | 高い | 深刻:読者を誤導する |
| 凡例の混乱 | 色とシリーズが一致しない | 中程度 | 深刻:データの区別が不能 |
| ラベルの文字化け | 文字の重なりやスペルミス | 中程度 | 中程度:可読性に影響 |
PaperBanana のコード生成方式がいかにして数値幻覚を排除するか
PaperBanana の解決策はシンプルかつ徹底しています。科研統計図に対しては、画像を生成するのではなく、コードを生成するのです。
PaperBanana の Visualizer エージェントが統計図表のタスクを受け取ると、図表の説明を実行可能な Python Matplotlib コードに変換します。このコード内では、各バーの高さ、各データポイントの座標、各座標軸の目盛りはすべて数学的な計算によって正確に決定されます。これはニューラルネットワークによる「推測」ではありません。
このコード優先のアプローチには、もう一つの重要な付加価値があります。それは編集可能性です。受け取るのは修正不可能なラスタ画像ではなく、クリーンな Python コードです。色、フォント、注釈、凡例の位置を自由に調整でき、さらには元のデータを修正して再実行することも可能です。これは、ジャーナルの査読段階での修正依頼において非常に実用的です。
🎯 技術アドバイス: PaperBanana のコード生成能力の基盤は大規模言語モデルによって駆動されています。APIYI(apiyi.com)を通じて Nano Banana Pro などのモデルを直接呼び出し、Matplotlib コードを生成することも可能です。プラットフォームは OpenAI 互換インターフェースをサポートしており、1回あたりの呼び出しコストは極めて低く抑えられています。
Nano Banana Pro による科研統計図 7 種のコード生成
PaperBanana は、240 個の ChartMimic ベンチマークケースにおいてコード生成方式の有効性を検証しました。これには折れ線グラフ、棒グラフ、散布図、マルチパネル図などの一般的なタイプが含まれます。以下に、7 種類の科研統計図の完全なプロンプトテンプレートとコード例を示します。
第 1 種:棒グラフ(Bar Chart)
棒グラフは論文で最も頻繁に使用される図表の一つで、異なる条件下での実験結果を比較するために用いられます。
import matplotlib.pyplot as plt
import numpy as np
# 実験データ
models = ['GPT-4o', 'Claude 4', 'Gemini 2', 'Llama 3', 'Qwen 3']
accuracy = [89.2, 91.5, 87.8, 83.4, 85.1]
colors = ['#3b82f6', '#10b981', '#f59e0b', '#ef4444', '#8b5cf6']
fig, ax = plt.subplots(figsize=(8, 5))
bars = ax.bar(models, accuracy, color=colors, width=0.6, edgecolor='white')
# 数値ラベルの追加
for bar, val in zip(bars, accuracy):
ax.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.5,
f'{val}%', ha='center', va='bottom', fontsize=10, fontweight='bold')
ax.set_ylabel('Accuracy (%)', fontsize=12)
ax.set_title('Model Performance Comparison on MMLU Benchmark', fontsize=14)
ax.set_ylim(75, 95)
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
plt.tight_layout()
plt.savefig('bar_chart.pdf', dpi=300, bbox_inches='tight')
plt.show()
第 2 種:折れ線グラフ(Line Chart)
折れ線グラフは時間や条件に伴う変化の傾向を示し、学習曲線やアブレーション実験に適しています。
import matplotlib.pyplot as plt
import numpy as np
epochs = np.arange(1, 21)
train_loss = 2.5 * np.exp(-0.15 * epochs) + 0.3 + np.random.normal(0, 0.02, 20)
val_loss = 2.5 * np.exp(-0.12 * epochs) + 0.45 + np.random.normal(0, 0.03, 20)
fig, ax = plt.subplots(figsize=(8, 5))
ax.plot(epochs, train_loss, 'o-', color='#3b82f6', label='Train Loss', linewidth=2, markersize=4)
ax.plot(epochs, val_loss, 's--', color='#ef4444', label='Val Loss', linewidth=2, markersize=4)
ax.set_xlabel('Epoch', fontsize=12)
ax.set_ylabel('Loss', fontsize=12)
ax.set_title('Training and Validation Loss Curves', fontsize=14)
ax.legend(fontsize=11, frameon=False)
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
plt.tight_layout()
plt.savefig('line_chart.pdf', dpi=300, bbox_inches='tight')
plt.show()
第 3 種:散布図(Scatter Plot)
散布図は、2つの変数間の相関関係やクラスタ分布を示すために使用されます。
第 4 種:ヒートマップ(Heatmap)
ヒートマップは、混同行列、アテンション重み行列、相関係数行列の表示に適しています。
第 5 種:レーダーチャート(Radar Chart)
レーダーチャートは多次元の能力比較に用いられ、モデルの総合評価でよく見られます。
第 6 種:円グラフ/ドーナツグラフ(Pie/Donut Chart)
円グラフは構成比率を示し、データセットの分布やリソース配分の分析に適しています。
第 7 種:マルチパネル複合図(Multi-Panel)
マルチパネル図は、複数のサブプロットを1つの図(Figure)にまとめたもので、論文で最も一般的な複合図表形式です。
| 図表の種類 | 適用シーン | 重要な Matplotlib 関数 | 主な用途 |
|---|---|---|---|
| 棒グラフ | 離散的な比較 | ax.bar() |
モデル性能比較、アブレーション実験 |
| 折れ線グラフ | 傾向の変化 | ax.plot() |
学習曲線、収束分析 |
| 散布図 | 相関・クラスタ | ax.scatter() |
特徴分布、埋め込みの可視化 |
| ヒートマップ | 行列データ | sns.heatmap() |
混同行列、アテンション重み |
| レーダーチャート | 多次元比較 | ax.plot() + polar |
モデル総合評価 |
| 円グラフ | 比率構成 | ax.pie() |
データセットの分布 |
| マルチパネル図 | 複合的な表示 | plt.subplots() |
Figure 1(a)(b)(c) など |
💰 コストの最適化: APIYI(apiyi.com)を通じて大規模言語モデルを呼び出し Matplotlib コードを生成することで、画像生成よりもはるかに低いコストで運用できます。約50行の Matplotlib コードを生成するコストはわずか 0.01 ドル程度であり、コードは繰り返し修正・実行が可能なため、APIを再呼び出しする必要もありません。また、オンラインツールの Image.apiyi.com を使用して可視化効果を素早く検証することをお勧めします。
Nano Banana Pro 研究用統計グラフ・クイックスタートガイド
シンプルな例:AIで正確な棒グラフのコードを生成する
以下は、APIを通じて大規模言語モデルを呼び出し、データに基づいてMatplotlibのコードをAIに自動生成させる最も簡単な方法です。
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # APIYI 統一インターフェースを使用
)
response = client.chat.completions.create(
model="gemini-2.5-flash",
messages=[{
"role": "user",
"content": """Generate publication-ready Python Matplotlib code for a grouped bar chart.
Data:
- Models: ['Method A', 'Method B', 'Method C', 'Ours']
- BLEU Score: [32.1, 35.4, 33.8, 38.7]
- ROUGE-L: [41.2, 43.8, 42.1, 47.3]
Requirements:
- Grouped bars with distinct colors (blue and green)
- Value labels on top of each bar
- Clean academic style, no top/right spines
- Title: 'Translation Quality Comparison'
- Save as PDF at 300 dpi
- Figsize: (8, 5)"""
}]
)
print(response.choices[0].message.content)
研究用統計グラフ・コード生成ツールの完全版を表示
import openai
from typing import Dict, List, Optional
def generate_chart_code(
chart_type: str,
data: Dict,
title: str,
style: str = "academic",
figsize: str = "(8, 5)",
save_format: str = "pdf"
) -> str:
"""
使用 AI 生成科研统计图的 Matplotlib 代码
Args:
chart_type: 图表类型 - bar/line/scatter/heatmap/radar/pie/multi-panel
data: 数据字典,包含标签和数值
title: 图表标题
style: 风格 - academic/minimal/detailed
figsize: 图表尺寸
save_format: 导出格式 - pdf/png/svg
Returns:
可执行的 Matplotlib Python 代码
"""
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # APIYI统一接口
)
style_guide = {
"academic": "Clean academic style: no top/right spines, "
"serif fonts, 300 dpi, tight layout",
"minimal": "Minimal style: grayscale-friendly, thin lines, "
"no grid, compact layout",
"detailed": "Detailed style: with grid, annotations, "
"error bars where applicable"
}
prompt = f"""Generate publication-ready Python Matplotlib code.
Chart type: {chart_type}
Data: {data}
Title: {title}
Style: {style_guide.get(style, style_guide['academic'])}
Figure size: {figsize}
Export: Save as {save_format} at 300 dpi
Requirements:
- All data values must be mathematically precise
- Include proper axis labels and legend
- Use colorblind-friendly palette
- Code must be executable without modification
- Add value annotations where appropriate"""
try:
response = client.chat.completions.create(
model="gemini-2.5-flash",
messages=[{"role": "user", "content": prompt}],
max_tokens=2000
)
return response.choices[0].message.content
except Exception as e:
return f"Error: {str(e)}"
# 使用示例:生成模型性能对比柱状图
code = generate_chart_code(
chart_type="grouped_bar",
data={
"models": ["GPT-4o", "Claude 4", "Gemini 2", "Ours"],
"accuracy": [89.2, 91.5, 87.8, 93.1],
"f1_score": [87.5, 90.1, 86.3, 92.4]
},
title="Model Performance on SQuAD 2.0",
style="academic"
)
print(code)
🚀 クイックスタート: 研究用統計グラフのコード生成には、APIYI (apiyi.com) プラットフォーム経由でAIモデルを呼び出すのがおすすめです。Gemini、Claude、GPTなど、高品質なMatplotlibコードを生成できる多様なモデルに対応しています。登録すると無料枠がもらえ、5分で最初の統計グラフのコードが作成できます。
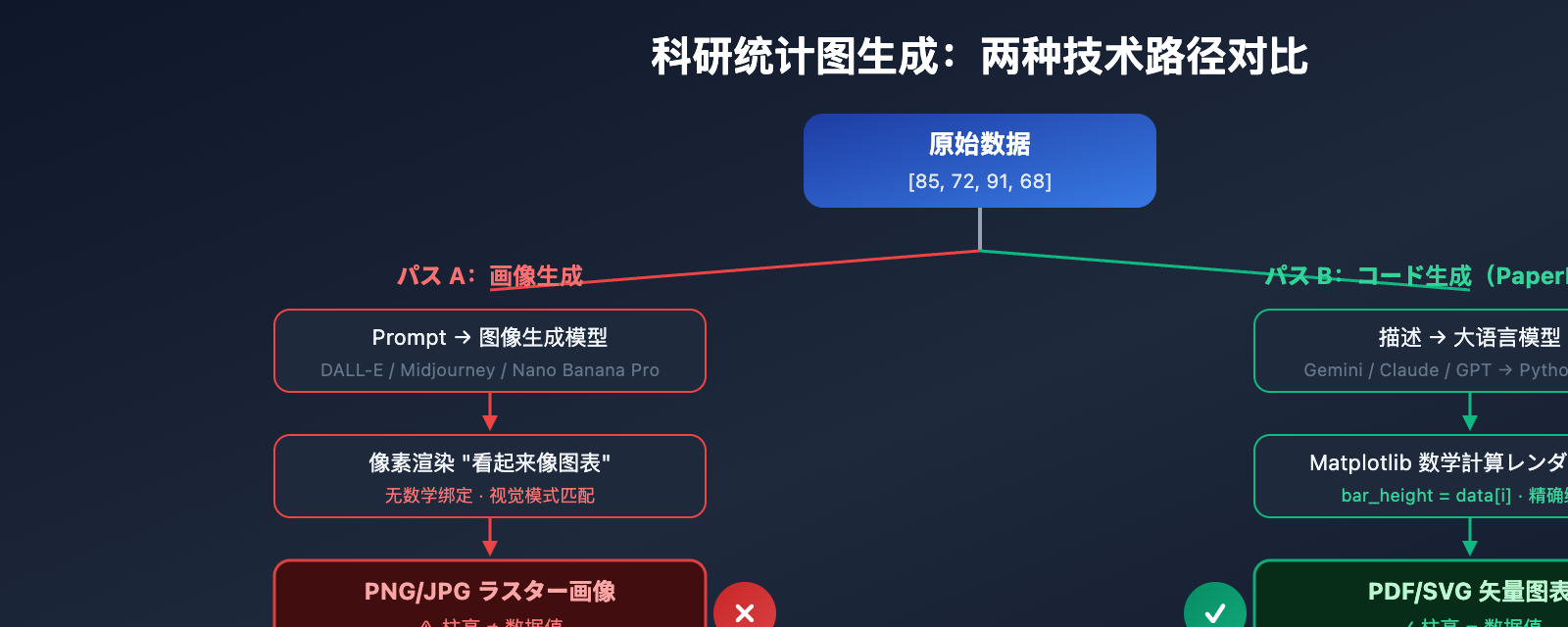
コード生成 vs 画像生成:研究用統計グラフの品質比較
なぜPaperBananaは、研究用統計グラフのシーンにおいてNano Banana Proの画像生成機能をあきらめ、コード生成を採用したのでしょうか?以下の比較データがすべてを物語っています。
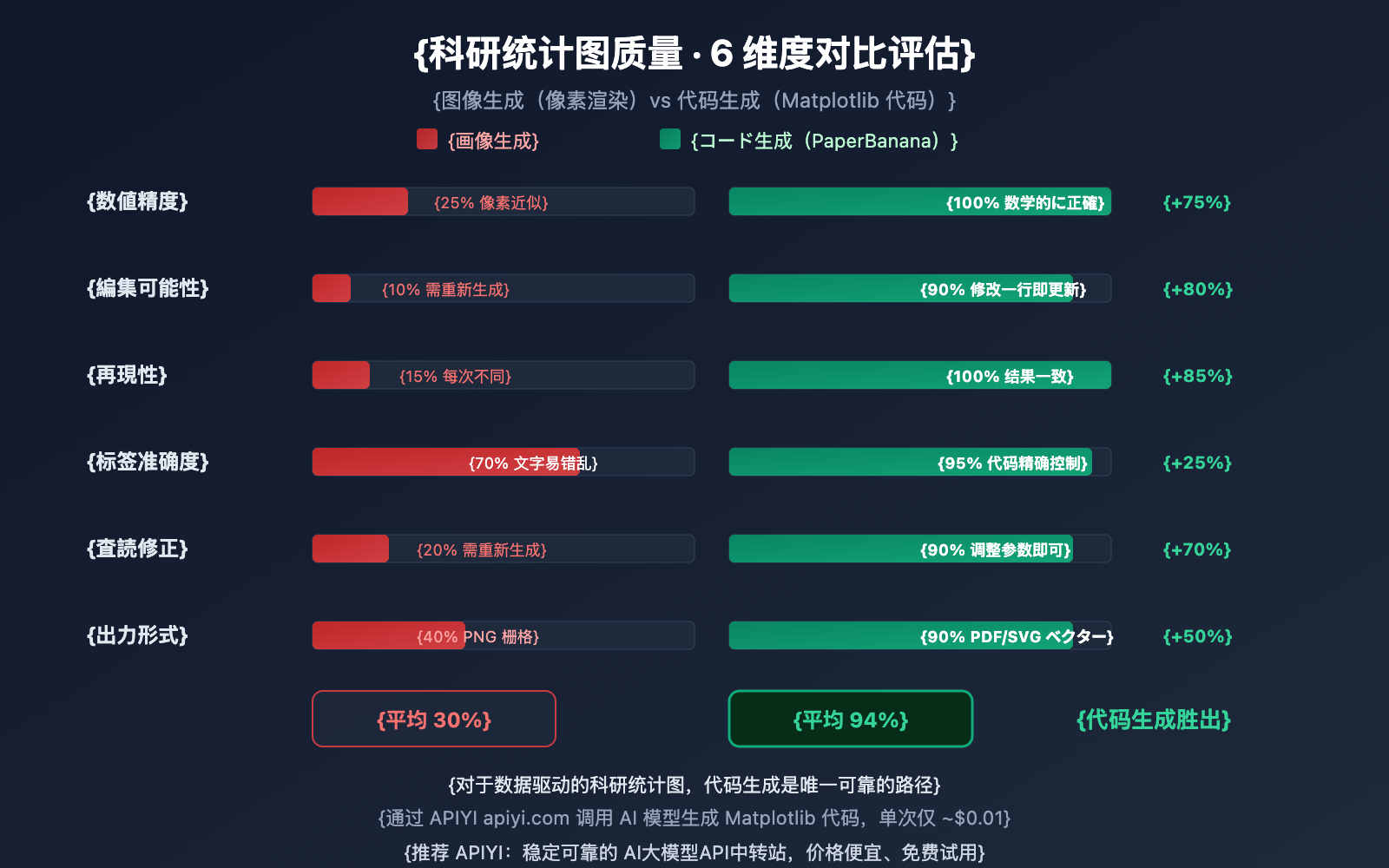
画像生成方式の問題点
Nano Banana Pro、DALL-E 3、Midjourneyなどを使用して研究用統計グラフを直接生成する場合、モデルはピクセルを用いて「グラフのように見える画像」を「描こう」とします。見た目は良いかもしれませんが、以下の問題はほぼ避けられません。
- 数値が不正確: 棒の高さと実際のデータとの間に数学的な紐付けがありません。
- 編集不可: 出力はラスター画像であり、個別のデータポイントを修正することはできません。
- 再現性がない: コードを再実行して全く同じグラフを得ることができません。
- ラベルの間違い: 軸のラベルにスペルミスや数値の誤りが発生しやすいです。
コード生成方式の利点
PaperBananaのコード生成方式は全く異なります。
- 数学的紐付け: すべての視覚要素はコード内の数値によって正確に計算されます。
- 編集可能: コードを1行変更するだけで、色、ラベル、データを更新できます。
- 再現性: 同じコードをどの環境で実行しても、結果は完全に一致します。
- 査読に強い: 査読者から図の修正を求められた際も、コードのパラメータを調整するだけで済みます。
| 比較次元 | 画像生成(Nano Banana Pro等) | コード生成(PaperBanana方式) |
|---|---|---|
| 数値の正確性 | 低:ピクセル近似、ハルシネーションあり | 高:数学的に正確、ハルシネーションなし |
| 編集可能性 | なし:ラスター画像のため修正不可 | 強:コード修正で即座に更新可能 |
| 再現性 | 低:生成のたびに結果が異なる | 高:コード実行結果が常に一致 |
| ラベルの正確性 | 中:テキスト正確率 約78-94% | 高:コードでテキストを正確に制御 |
| 査読修正 | 図全体を再生成する必要がある | パラメータを調整して再実行するだけ |
| 出力形式 | PNG/JPG ラスター画像 | PDF/SVG/EPS ベクター画像 |
🎯 選択のアドバイス: 正確な数値を表示する必要がある研究用統計グラフ(棒グラフ、折れ線グラフ、散布図など)には、コード生成方式を強くお勧めします。図表が視覚的なコンセプト(手法の概念図、アーキテクチャ図など)を主とする場合は、Nano Banana Proの画像生成機能が適しています。APIYI (apiyi.com) プラットフォームを通じて、画像生成モデルとテキスト生成モデルの両方を柔軟に使い分けることができます。
Nano Banana Pro 研究用統計グラフのプロンプトエンジニアリング術
AIに高品質なMatplotlibコードを生成させる鍵は、プロンプトの構造化にあります。ここでは、検証済みの5つの核心的なテクニックを紹介します。
テクニック 1:データを明示的に与える
AIにデータを「捏造」させてはいけません。プロンプト内で、ラベル、数値、単位を含む完全なデータ値を明確に提供してください。
✅ 正解: Data: models=['A','B','C'], accuracy=[89.2, 91.5, 87.8]
❌ 不正解: Generate a bar chart comparing three models
テクニック 2:学術的なスタイルの制約を指定する
学術論文の図表には厳格なレイアウト要件があります。プロンプトで以下の制約を明確にしましょう:
- 上部と右側の枠線を削除(
spines['top'].set_visible(False)) - フォントサイズの階層:タイトル 14pt、軸ラベル 12pt、目盛り 10pt
- カラーユニバーサルデザイン(色覚多様性への配慮、赤と緑の組み合わせを避けるなど)
- 300dpi以上のPDF/EPS形式での出力
テクニック 3:数値ラベルの追加を要求する
棒グラフの上に正確な数値ラベルを追加することで、読者が座標軸を参照せずにデータを読み取れるようにします。これは「視覚的な曖昧さ」を排除する重要な手段でもあります。
テクニック 4:実行可能性を指定する
生成されたコードが「修正なしで直接実行できる」ことを明確に要求します。これにより、AIは必要なすべてのimport文、データ定義、保存コマンドを含めるようになります。
テクニック 5:査読時の修正に備えて柔軟性を持たせる
データ定義とスタイルパラメータをコードの上部に分けて配置するようAIに要求することで、後からの迅速な修正が容易になります。
| テクニック | 核心となるポイント | コード品質への影響 |
|---|---|---|
| 1 | データを明示的に与える | データの捏造を排除し、正確性を確保 |
| 2 | 学術スタイルの制約 | ジャーナルのレイアウト要件に適合 |
| 3 | 数値ラベル | グラフの可読性を向上 |
| 4 | 実行可能性 | コードをそのまま利用可能 |
| 5 | パラメータの分離 | 査読時の修正効率が倍増 |
🎯 実践アドバイス: 上記の5つのテクニックを組み合わせて、あなた専用の標準プロンプトテンプレートを作成しましょう。APIYI(apiyi.com)を通じて異なるモデルを呼び出し、繰り返し試行することで、自身の研究分野に最適なコードスタイルを見つけることができます。プラットフォームは Gemini、Claude、GPT などの複数モデルの切り替えに対応しており、生成効果の比較に便利です。
よくある質問
Q1: PaperBanana のコード生成方式は、画像生成よりも遅いですか?
正反対です。通常、コード生成の方が高速です。50〜80行程度のMatplotlibコードの生成にはわずか2〜5秒しかかかりませんが、画像生成には10〜30秒を要します。さらに重要なのは、コード生成後はローカルで実行や修正を繰り返すことができ、修正のたびにAPIを呼び出す必要がない点です。APIYI(apiyi.com)を通じて大規模言語モデルを呼び出してコードを生成する場合、1回あたりのコストは約$0.01であり、画像生成の$0.05よりも大幅に安価です。
Q2: 生成される Matplotlib コードの品質はどうですか?大幅な修正が必要ですか?
PaperBananaの240個のChartMimicベンチマークテストにおいて、生成されたPythonコードはいずれも直接実行可能であり、視覚的な出力も元の記述と一致していました。実際の使用では、通常、配色やフォントなどのスタイルパラメータを微調整するだけで済みます。コード生成の品質においては、APIYI(apiyi.com)プラットフォームを通じて Claude や Gemini モデルを呼び出すことをお勧めします。これらのモデルはコード生成能力において特に優れています。また、オンラインツールの Image.apiyi.com でも効果を素早くプレビューできます。
Q3: AIを使って研究用統計グラフのコード生成を素早く始めるには?
以下のクイックスタート手順をお勧めします:
- APIYI(apiyi.com)にアクセスしてアカウントを登録し、APIキーと無料テストクレジットを取得します。
- 実験データ(モデル名、指標の数値など)を準備します。
- 本記事のプロンプトテンプレートを使用し、データを実際のデータに置き換えます。
- APIを呼び出してMatplotlibコードを生成し、ローカルで実行して結果を確認します。
- ジャーナルの要求に合わせてスタイルパラメータを微調整し、PDFとして書き出します。
まとめ
Nano Banana Pro における学術統計グラフのコード生成手法の要点は以下の通りです:
- ピクセルよりもコードを優先: PaperBanana は、学術統計グラフに対して画像レンダリングではなく Matplotlib コード生成を採用しており、数値的ハルシネーション(もっともらしい嘘)を根本から排除します。
- 7 種類のグラフを網羅: 棒グラフ、折れ線グラフ、散布図、ヒートマップ、レーダーチャート、円グラフ、マルチパネル図に対応し、論文のデータ可視化におけるあらゆるニーズを満たします。
- 編集可能かつ再現可能: 出力されたコードは自由に修正でき、正確に再現可能です。査読時の修正も、グラフを再生成するのではなく、パラメータを調整するだけで済みます。
- 5 つのプロンプトテクニック: 明示的なデータ、学術的制約、数値ラベル、実行可能性、パラメータの分離。これらにより、高品質で実用的なコード生成を保証します。
学術統計グラフに求められる厳格な正確性を前に、「コードこそがグラフである」という考え方は唯一の信頼できる道です。AI を活用して Matplotlib コードを生成することで、AI の効率性を享受しながら、コードの正確性を維持するという「両得」が実現します。
AI による学術統計グラフのコード生成を素早く体験するには、APIYI (apiyi.com) がおすすめです。プラットフォームでは無料枠や複数のモデル選択を提供しています。また、オンラインツールの Image.apiyi.com で効果をプレビューすることも可能です。
📚 参考文献
⚠️ リンク形式の説明: すべての外部リンクは
資料名: domain.comの形式で記載しています。コピーして利用いただけますが、SEO 評価の流出を防ぐためクリック可能なリンクにはなっていません。
-
PaperBanana プロジェクトページ: 公式リリースページ。論文とデモが含まれます。
- リンク:
dwzhu-pku.github.io/PaperBanana/ - 説明: PaperBanana における統計グラフコード生成の核となる原理と評価データを確認できます。
- リンク:
-
PaperBanana 論文: arXiv プレプリント全文。
- リンク:
arxiv.org/abs/2601.23265 - 説明: コード生成 vs 画像生成の技術的選択と ChartMimic ベンチマークテストについて深く理解できます。
- リンク:
-
Matplotlib 公式ドキュメント: Python データ可視化ライブラリ。
- リンク:
matplotlib.org/stable/ - 説明: AI が生成したグラフコードを理解・修正するための Matplotlib API リファレンスです。
- リンク:
-
Nano Banana Pro 公式ドキュメント: Google DeepMind モデルの紹介。
- リンク:
deepmind.google/models/gemini-image/pro/ - 説明: メソドロジー図(手法図)のシーンにおける Nano Banana Pro の画像生成能力について確認できます。
- リンク:
-
APIYI オンライン作図ツール: コード不要のグラフプレビュー。
- リンク:
Image.apiyi.com - 説明: AI が生成する学術統計グラフの効果を素早くプレビューできます。
- リンク:
著者: APIYI Team
技術交流: コメント欄であなたの学術統計グラフ用プロンプトテンプレートや Matplotlib のテクニックをぜひ共有してください。最新の AI モデル情報は APIYI (apiyi.com) 技術コミュニティで発信しています。