著者注:GPT-5.4がGPT-5.3 Instantのリリースからわずか2日後に発表された背景を深く分析。OpenAI、Anthropic、Googleの三強競争の構図と、GPT-5.4の差別化された立ち位置を解説します。
3月3日、OpenAIはGPT-5.3 Instantをリリースしました。わずか2日後の3月5日、GPT-5.4が正式に登場しました。同じ企業が3日間で2つの重要モデルを発表する——この背景には一体何があったのでしょうか?
答えは、計画の混乱ではなく、緻密に設計された階層化戦略と、AnthropicのClaude Opus 4.6およびGoogleのGemini 3.1 Proからの激しい競争です。
核心的な価値: この記事を読むことで、GPT-5.4の真の立ち位置、GPT-5.3 Instantとの役割分担の論理、そして現在のAI三強争覇が開発者に与える実際の影響を理解できるようになります。

GPT-5.4 リリースの背景にある5つの核心的理由
| 理由 | 核心的な論理 | 競合相手 |
|---|---|---|
| Claude Opus 4.6 のプログラミング優位性への対抗 | Opus 4.6 の SWE-Bench 80.8% リードに対し、OpenAI は応答が必要 | Anthropic |
| Gemini 3.1 Pro の推論能力への追撃 | Gemini の GPQA 94.3%、ARC-AGI 77.1% による推論分野での支配に対抗 | |
| 階層化プロダクトラインの確立 | Instant は日常を担当、5.4 は専門を担当し、計算リソースの無駄を回避 | 内部戦略 |
| 企業市場の獲得 | 金融プラグイン、Excel 統合による高額課金企業顧客への狙い | 業界全体 |
| 月次更新ペースの維持 | シグナル: OpenAI エコシステムへの投資は継続的に価値を生む | 市場の信頼 |
GPT-5.4 リリースの理由その1:Anthropic と Google の挟み撃ち
2026年2月は、OpenAIにとって暗黒の時期の一つでした。Claude Opus 4.6はプログラミング分野でSWE-Bench 80.8%という業界最高スコアを獲得し、MMMU-Pro視覚推論では85.1%を達成しました。ほぼ同時期に、GoogleのGemini 3.1 Proは、GPQA 94.3%という大学院レベルの推論スコアと、$2/$12という超低価格設定で二重の圧力をかけました。
さらに追い打ちをかけるように、OpenAIは国防総省との協力に関する決定をめぐる論争により、約150万人のユーザーを失ったと報じられました。一方、Anthropicは同様の協力を公開で拒否したことで評判を高めました。
GPT-5.4は、このような背景のもとで緊急リリースされたのです——OpenAIは、物語の主導権を取り戻すのに十分な強力な技術的ブレークスルーを必要としていました。
GPT-5.4 リリースの理由その2:階層化戦略の完成
GPT-5.3 InstantとGPT-5.4は互いに代替するものではなく、OpenAIのプロダクト階層化戦略における2つの重要な駒です:
- GPT-5.3 Instant は、日常会話(メール、翻訳、質疑応答)の80%を処理し、コストを極限まで抑えます。
- GPT-5.4 Thinking は、ユーザーが深い推論を必要とするときに自動的に切り替わります。
- GPT-5.4 Pro は、企業レベルの究極の正確性を求めるニーズに向けられています。
- GPT-5.3 Codex は、エージェント型プログラミングに特化しています。
この階層化により、ChatGPTは必要に応じて計算リソースを割り当てることができます——単純な会話ではフラッグシップの計算能力を浪費せず、複雑なタスクのみでGPT-5.4を呼び出します。
🎯 開発者へのアドバイス: この階層化戦略はAPIユーザーにも同様に適用できます。日常タスクにはGPT-5.3 Instantでコストを削減し、複雑なタスクにはGPT-5.4で品質を保証します。すべてのモデルはAPIYI apiyi.comの統一インターフェースを通じて呼び出せ、コードを変更することなくワンクリックで切り替えられます。
GPT-5.4 の5つのコア優位性を詳しく解説
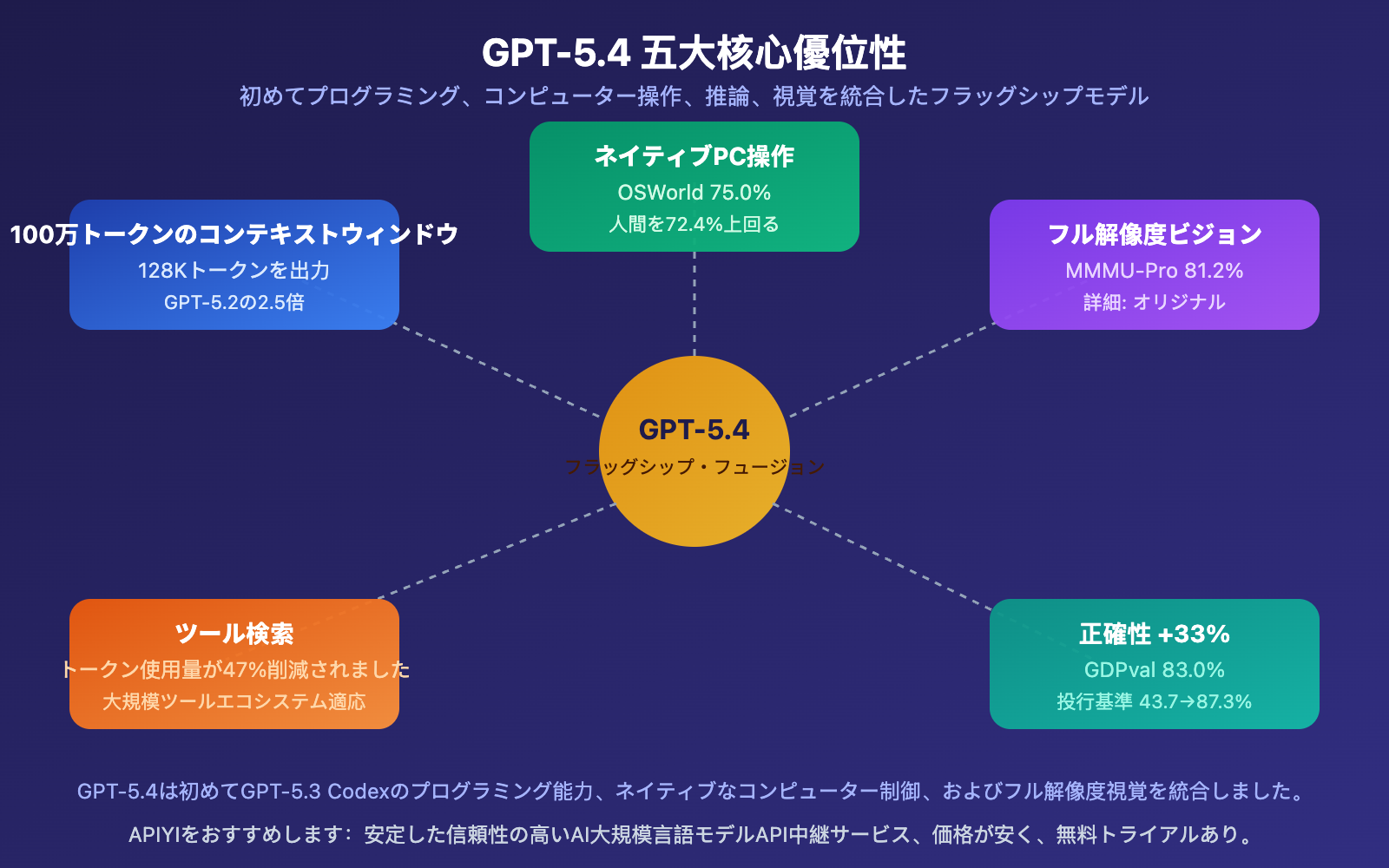
GPT-5.4 優位性その1:ネイティブなコンピュータ操作(最大の差別化要因)
GPT-5.4は、OpenAI初のネイティブなコンピュータ操作能力を内蔵した汎用モデルです。スクリーンショットから画面内容を認識し、キーボードやマウスの指令を発行して、異なるアプリケーション間で複雑なワークフローを完了することができます。
OSWorldデスクトップナビゲーションテストでは、GPT-5.4が 75.0% の成功率を達成——人間の72.4%というベースラインを直接上回り、GPT-5.2の47.3%を大きく引き離しました。これは、GPT-5.4がコンピュータ操作において、すでに大多数の人々よりも正確であることを意味します。
GPT-5.4 優位性その2:金融業界への深い統合
これは見落とされがちですが、ビジネス価値の非常に高い差別化の方向性です。GPT-5.4は同時に以下をリリースしました:
- ChatGPT for Excel / Google Sheets(ベータ版):スプレッドシートに直接組み込み
- 金融データ統合:Moody's、MSCI、Third Bridge、Dow Jones Factivaにアクセス可能、FactSetも近日公開予定
- 再利用可能なスキル:利益予測、比較分析、DCFモデル、投資メモなどの金融業務テンプレート
OpenAI内部の投資銀行ベンチマークテストでは、GPT-5.4 + Thinkingモードのパフォーマンスが43.7%から 87.3% まで急上昇しました。
GPT-5.4 優位性その3:ツール検索の革新
従来の方法では、モデルはすべてのツール定義を一度に受け取る必要があり、大量のトークンを消費していました。GPT-5.4のツール検索(Tool Search)メカニズムにより、モデルは必要に応じてツール定義を検索できるようになりました——結果として、トークン使用量が 47%減少 し、正確性は変わりません。
多くのカスタムツールを持つ企業開発者にとって、これはコストが直接半減することを意味します。
🎯 試用アドバイス: GPT-5.4のツール検索とコンピュータ操作能力は、実際のシナリオで体験して初めてその差を実感できます。APIYI apiyi.com で登録して無料枠を取得し、あなたのワークフローにおけるGPT-5.4のパフォーマンスを迅速に検証することをお勧めします。
GPT-5.4 と GPT-5.3 Instant 選定ガイド
| 比較項目 | GPT-5.3 Instant | GPT-5.4 | 選択アドバイス |
|---|---|---|---|
| モデル ID | gpt-5.3-chat-latest | gpt-5.4 | — |
| 位置付け | 日常会話のデフォルトモデル | 専門業務のフラッグシップモデル | タスクの複雑さに応じて選択 |
| コンテキストウィンドウ | 400K | 1,000K | 超長文書は5.4を選択 |
| コンピュータ操作 | ❌ | ✅ ネイティブサポート | 自動化には5.4を選択 |
| 視覚処理 | 標準 | フル解像度 | 高精度画像は5.4を選択 |
| 幻覚制御 | 26.8%削減 | エラー率33%低下 | 両方とも改善あり |
| 入力価格 | ~$0.30/M | $2.50/M | 日常会話は5.3を選択 |
| 出力価格 | ~$1.20/M | $15.00/M | コスト重視は5.3を選択 |
| 推論レベル | 標準 | 5段階調整可能 | 深い分析は5.4を選択 |
| 金融プラグイン | ❌ | ✅ Excel/Sheets | 金融シナリオは5.4を選択 |
一言でまとめると: GPT-5.3 Instantはあなたの「迅速なアシスタント」(安い、速い、十分な機能)であり、GPT-5.4はあなたの「専門的なアドバイザー」(強力、万能、精密)です。両者は衝突せず、必要に応じて呼び出してください。
🎯 コスト最適化アドバイス: 日常タスクの80%にGPT-5.3 Instantを使用し、複雑なタスクの20%にGPT-5.4に切り替えます。APIYI apiyi.com の統一インターフェースを介して呼び出すことで、モデルの切り替えはパラメータを1つ変更するだけでよく、他のコードを修正する必要はありません。
AI三強争いにおけるGPT-5.4の競争力分析

GPT-5.4の競争力分析 核心結論
現在のAI三強はそれぞれ得意分野があり、すべてのベンチマークテストで勝利するモデルは存在しません:
| シナリオ | 推奨モデル | 理由 |
|---|---|---|
| 専門知識業務(レポート、PPT、文書) | GPT-5.4 | GDPval 83.0% 業界最高 |
| デスクトップワークフローの自動化 | GPT-5.4 | OSWorld 75.0% 人間を超える |
| プロダクションレベルのコード修正 | Claude Opus 4.6 | SWE-Bench 80.8% 業界最高 |
| 科学研究と深い推論 | Gemini 3.1 Pro | GPQA 94.3% 業界最高 |
| コストに敏感な汎用シナリオ | Gemini 3.1 Pro | $2/$12 最低価格設定 |
| 超長文ドキュメント処理 | Gemini 3.1 Pro | 2M 最大コンテキスト |
| 日常会話と翻訳 | GPT-5.3 Instant | ~$0.30/M 極めて低コスト |
| 高精度な視覚理解 | Claude Opus 4.6 | MMMU-Pro 85.1% 最高 |
業界内での共通認識はますます明確になってきています:マルチモデルルーティング戦略(タスクタイプに応じて最適なモデルを自動選択)こそが最適解です。
🎯 マルチモデル戦略の提案: APIYI apiyi.com は、GPT-5.4、Claude Opus 4.6、Gemini 3.1 Pro などの主要モデルの統一インターフェース呼び出しをサポートしています。model パラメータを変更するだけで、異なるモデル間で切り替えることができ、100米ドル以上のチャージで10%のボーナスが付与されます。
GPT-5.4 API クイックスタート
最小限のサンプル
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# GPT-5.4 標準呼び出し
response = client.chat.completions.create(
model="gpt-5.4",
messages=[{"role": "user", "content": "競合製品の価格戦略を分析する"}]
)
print(response.choices[0].message.content)
マルチモデルルーティング呼び出しの例を見る
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def smart_route(task: str, complexity: str = "low") -> str:
"""タスクの複雑さに基づいてモデルを自動選択"""
model_map = {
"low": "gpt-5.3-chat-latest", # 日常会話、最低コスト
"medium": "gpt-5.4", # 専門作業
"high": "gpt-5.4", # 深い推論(reasoning 追加可)
}
model = model_map.get(complexity, "gpt-5.3-chat-latest")
params = {
"model": model,
"messages": [{"role": "user", "content": task}],
}
if complexity == "high":
params["reasoning"] = {"effort": "high"}
response = client.chat.completions.create(**params)
return response.choices[0].message.content
# 日常タスク → GPT-5.3 Instant(低コスト)
print(smart_route("この文章を英語に翻訳してください", "low"))
# 専門タスク → GPT-5.4(高機能)
print(smart_route("この第4四半期決算報告書のリスク要因を分析してください", "medium"))
# 深い推論 → GPT-5.4 + high reasoning(高精度)
print(smart_route("この数学的証明を導出してください", "high"))
推奨: APIYI apiyi.com でアカウント登録すると、APIキーと無料枠を取得できます。GPT-5.4の価格はOpenAI公式サイトと同期しています(入力$2.50/M、出力$15.00/M)。100米ドル以上チャージすると10%ボーナスが付与されます。
よくある質問
Q1: GPT-5.3 Instant は GPT-5.4 に置き換えられますか?
いいえ。両者の位置づけは全く異なります。GPT-5.3 Instantは日常会話用のデフォルトモデル(極めて低コスト)であり、GPT-5.4は専門作業用のフラッグシップモデル(極めて強力)です。ChatGPTはタスクの複雑さに基づいて適切なモデルに自動的にルーティングします。APIユーザーには、日常タスクには5.3 Instantを、複雑なタスクには5.4を使用することをお勧めします。
Q2: GPT-5.4 は Claude Opus 4.6 や Gemini 3.1 Pro よりも優れていますか?
シナリオによります。GPT-5.4は専門作業(GDPval 83%)とコンピュータ操作(OSWorld 75%)でリードしています。Claude Opus 4.6はプログラミング(SWE 80.8%)と視覚推論(MMMU 85.1%)でリードしています。Gemini 3.1 Proは科学的推論(GPQA 94.3%)とコストパフォーマンスでリードしています。APIYI apiyi.com を通じて、実際のシナリオで比較テストを行うことをお勧めします。
Q3: APIYI を通じて複数のモデルを同時に使用するにはどうすればよいですか?
APIYI apiyi.com は統一されたOpenAI互換インターフェースを提供しており、すべての主要モデルは1つのAPIキーで共通利用できます。リクエスト内の model パラメータを変更するだけです:
gpt-5.3-chat-latest→ GPT-5.3 Instantgpt-5.4→ GPT-5.4claude-opus-4-6→ Claude Opus 4.6
100米ドル以上チャージすると10%ボーナスが付与されます。登録すればすぐに呼び出しを開始できます。
まとめ
GPT-5.4 リリースの背景にある核心的なロジック:
- 階層化戦略、代替ではない: GPT-5.3 Instant が日常会話の80%(極めて低コスト)を担当し、GPT-5.4 が専門作業の20%(極めて強力な能力)を担当。両者は競合ではなく、補完関係にあります。
- 競争に駆られた高速イテレーション: Anthropic Claude Opus 4.6 がプログラミングで先行し、Google Gemini 3.1 Pro が推論とコストパフォーマンスで先行する状況が、OpenAI にコンピュータ操作と企業金融統合という差別化された突破口を取らせました。
- 単一の最強モデルは存在しない: GPT-5.4 は5つのベンチマークで勝利、Gemini は4つ、Claude は3つで勝利。複数モデルのルーティングこそが最適な戦略です。
開発者にとって最も賢明な戦略は、シーンに応じてモデルを選択することです:日常タスクには GPT-5.3 Instant でコスト削減、専門作業には GPT-5.4 で品質確保、プログラミングには Claude、推論には Gemini を使用します。
APIYI apiyi.com を介してすべての主要モデルに統一アクセスすることをお勧めします。100米ドル以上のチャージで10%ボーナス、1つのAPIキーで全モデルを呼び出し、切り替えは1つのパラメータを変更するだけです。
📚 参考資料
-
OpenAI GPT-5.4 公式発表: GPT-5.4 リリース詳細、コア能力、モデル仕様
- リンク:
openai.com/index/introducing-gpt-5-4/ - 説明: コンピュータ操作、ツール検索、金融統合などの新機能を理解する
- リンク:
-
GPT-5.4 vs Opus 4.6 vs Gemini 3.1 Pro 詳細比較: 全次元ベンチマークテスト、価格設定、シーン分析
- リンク:
digitalapplied.com/blog/gpt-5-4-vs-opus-4-6-vs-gemini-3-1-pro-best-frontier-model - 説明: 最も包括的な三強比較、12項目のベンチマークテストデータを含む
- リンク:
-
NxCode GPT-5 モデル選定ガイド: GPT-5.2 vs 5.3 vs 5.4 の完全な選定アドバイス
- リンク:
nxcode.io/resources/news/openai-gpt-5-model-guide-which-to-use-2026 - 説明: OpenAIモデルファミリー内で選択を行う必要がある開発者に適しています
- リンク:
-
VentureBeat GPT-5.4 レポート: コンピュータ操作と金融プラグインの詳細レポート
- リンク:
venturebeat.com/technology/openai-launches-gpt-5-4-with-native-computer-use-mode-financial-plugins-for - 説明: ChatGPT for Excel や Moody's/MSCI などの金融データ統合の詳細を理解する
- リンク:
著者: APIYI 技術チーム
技術交流: コメント欄での議論を歓迎します。詳細な資料は APIYI docs.apiyi.com ドキュメントセンターをご覧ください。