Bagi kreator konten di Xiaohongshu, bagian paling melelahkan bukanlah menulis caption, melainkan membuat gambar. Sebuah gambar sampul harus memuat judul, subjudul, nilai jual, merek, dan elemen dekoratif. Kepadatan informasinya setara dengan infografis. Jika harus menggunakan Canva untuk menyusun tata letak, Figma untuk desain, dan Photoshop untuk penyuntingan, prosesnya bisa memakan waktu hingga 2 jam.
gpt-image-2, yang diluncurkan oleh OpenAI pada April 2026, mengubah situasi ini sepenuhnya. Model ini tidak hanya meningkatkan akurasi rendering teks dalam gambar hingga di atas 95%, tetapi juga untuk pertama kalinya memiliki kemampuan Agentic berupa "pencarian daring + penalaran untuk pembuatan gambar". Jika Anda meminta, "Buat gambar perbandingan warna iPhone 17 terbaru", model ini akan mencari data resmi terlebih dahulu, lalu menghasilkan infografis berdensitas tinggi yang mencakup model, warna, dan parameter yang akurat.
Artikel ini akan membahas metodologi lengkap pembuatan konten Xiaohongshu menggunakan gpt-image-2, mulai dari analisis kemampuan inti hingga alur kerja 5 langkah praktis, serta templat petunjuk dan FAQ, untuk membantu Anda memangkas waktu pembuatan gambar dari 2 jam menjadi 5 menit.
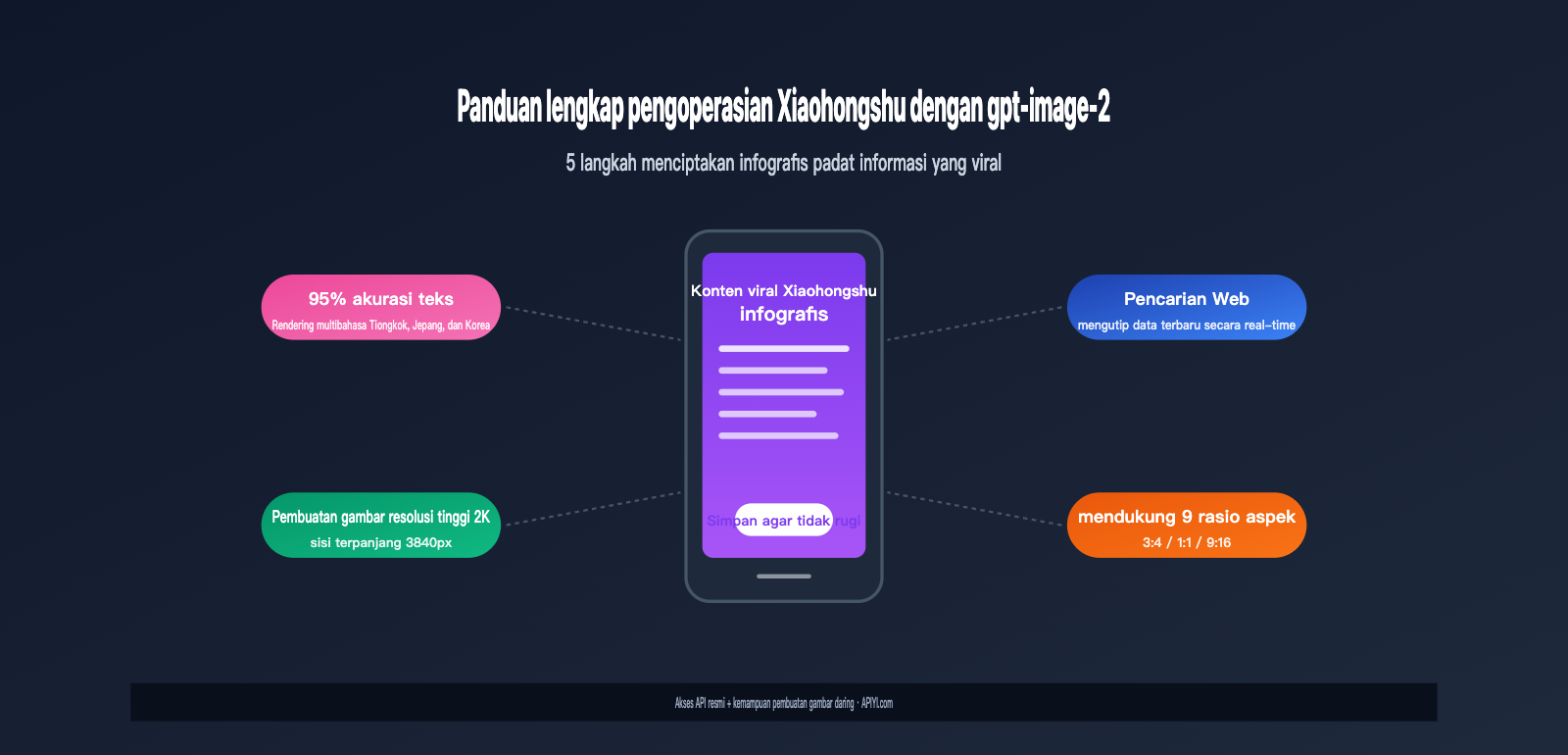
Mengapa kemampuan kreasi gpt-image-2 untuk Xiaohongshu begitu menonjol
Sebelum gpt-image-2, kreator Xiaohongshu yang menggunakan AI untuk membuat gambar menghadapi tiga masalah utama: rendering teks yang tidak akurat, ketidakmampuan menampung kepadatan informasi, dan keterlambatan informasi terkini. Sampul yang viral biasanya membutuhkan lapisan teks sebanyak 50-100 karakter, sementara model lama (termasuk gpt-image-1 dan Midjourney v6) sering menghasilkan teks dengan kesalahan ketik, goresan yang hilang, atau karakter yang berubah bentuk, sehingga hampir tidak bisa digunakan secara langsung.
gpt-image-2 mengubah situasi ini secara total melalui tiga terobosan teknologi. Pertama, peningkatan menyeluruh pada mesin rendering teks. Menurut pengujian resmi OpenAI, model ini mencapai akurasi rendering fidelitas tinggi di atas 95% untuk karakter non-Latin seperti Mandarin, Jepang, Korea, Hindi, dan Bengali, bahkan stabil dalam skenario ukuran huruf kecil, permukaan melengkung, dan tata letak yang padat.
Kedua adalah arsitektur Agentic Reasoning. gpt-image-2 adalah model gambar pertama di industri yang memiliki siklus penalaran lengkap "berpikir → mencari → menghasilkan → memverifikasi", yang secara proaktif merencanakan komposisi, mencari referensi, dan mengevaluasi kualitas sebelum gambar dibuat.
Ketiga adalah pengetahuan daring bawaan. Saat membuat gambar yang melibatkan produk terbaru, logo merek, tokoh, atau peristiwa populer, model ini dapat mencari informasi di internet secara real-time, alih-alih bergantung pada data usang sebelum batas waktu pelatihan (Desember 2025).
💡 Rekomendasi Platform: Jika ingin merasakan langsung kemampuan pembuatan gambar daring gpt-image-2, Anda bisa menggunakan model gpt-image-2-all yang disediakan oleh platform APIYI (apiyi.com). Ini adalah versi yang diakses melalui reverse engineering dari ChatGPT versi web resmi, yang secara default mengaktifkan pencarian daring tanpa perlu konfigurasi parameter tambahan, sangat cocok untuk skenario pembuatan konten Xiaohongshu yang membutuhkan "aktualitas informasi".
Analisis 3 Dimensi Kemampuan Utama gpt-image-2 untuk Xiaohongshu
Untuk memahami mengapa gpt-image-2 sangat cocok untuk Xiaohongshu, kita perlu membedah kesesuaian kemampuannya dengan format konten di platform tersebut. Tabel berikut membandingkan peningkatan kemampuan gpt-image-2 dibandingkan generasi sebelumnya (gpt-image-1) dalam skenario utama Xiaohongshu.
| Dimensi Kemampuan | gpt-image-1 | gpt-image-2 | Nilai untuk Skenario Xiaohongshu |
|---|---|---|---|
| Rendering Teks Mandarin | 60-70% akurat, sering salah tulis | 95%+ akurat, stabil untuk teks melengkung | Langsung digunakan untuk judul sampul & infografis |
| Jumlah Output Sekali Jalan | 1 gambar | 1-10 gambar opsional | Hasilkan 9 gambar carousel utuh sekaligus |
| Resolusi Maksimal | 1024×1024 | 2K (sisi terpanjang 3840px) | Memenuhi kebutuhan sampul HD rasio 3:4 |
| Dukungan Rasio Aspek | 3 jenis | 9 jenis (termasuk 3:4) | Sangat pas dengan rasio foto utama Xiaohongshu |
| Pengetahuan Internet | Tidak ada | Pencarian Web bawaan | Referensi produk & tren terbaru akurat |
| Penalaran Gambar | Tidak ada | Penalaran Agen (Agentic Reasoning) | Tata letak infografis kompleks otomatis |
Keunggulan Kemampuan gpt-image-2 #1: Rendering Infografis Kepadatan Tinggi
"Infografis", "kartu informasi", dan "gambar edukasi" di Xiaohongshu adalah jenis konten dengan interaksi tinggi. Ciri khasnya adalah memuat 80-150 kata per gambar, serta memerlukan hierarki, skema warna, dan ikon yang jelas. Peningkatan gpt-image-2 dalam skenario ini berasal dari tiga detail:
Pertama, gradien ukuran huruf. Model dapat memahami instruksi hierarki seperti "judul utama 60pt + subjudul 32pt + isi teks 18pt", sehingga rasio ukuran huruf dalam hasil generate sangat stabil.
Kedua, kontrol ruang kosong (white space) tata letak. Dengan Agentic Reasoning, model akan melakukan "tata letak virtual" sebelum mulai menggambar, guna menghindari teks yang berhimpitan atau terpotong di bagian tepi.
Ketiga, kombinasi ikon dan teks. Model dapat menyisipkan ikon yang ditentukan (✓, ★, →, lencana angka, dll.) di posisi yang diinginkan, memastikan kesejajaran antara ikon dan teks.
Keunggulan Kemampuan gpt-image-2 #2: Pengetahuan Internet Menjamin Akurasi
Ini adalah kemampuan gpt-image-2 yang paling sering diremehkan. Pengetahuan model AI tradisional dibatasi oleh data pelatihan. Saat Anda memintanya menghasilkan konten seperti "perbandingan warna iPhone 17 terbaru", "peringkat merek kopi 2026", atau "tren kecantikan terkini", kemungkinan besar ia akan mengarang informasi yang salah.
Dalam tahap "berpikir" internal, gpt-image-2 akan menilai apakah tugas tersebut memerlukan informasi eksternal. Jika perlu, ia akan memicu pencarian web secara otomatis dan mengintegrasikan data nyata yang ditemukan (parameter produk, bentuk logo, warna resmi) ke dalam proses pembuatan gambar. Ini berarti kreator Xiaohongshu dapat dengan percaya diri menggunakannya untuk konten perbandingan produk, rekomendasi barang baru, dan edukasi merek tanpa khawatir akan "halusinasi" AI.
🎯 Saran Akses API: Untuk menggunakan fitur internet gpt-image-2, Anda memerlukan platform layanan proksi API yang mendukung kemampuan API penuh. Kami merekomendasikan akses melalui APIYI di api.apiyi.com untuk model
gpt-image-2-all. Model ini berasal dari kanal reverse resmi, sudah dilengkapi kemampuan pencarian web secara default, dan harganya lebih bersahabat dibandingkan API resmi langsung, sangat cocok bagi kreator konten yang memproduksi gambar secara massal.
Keunggulan Kemampuan gpt-image-2 #3: Multi-Rasio & Output Multi-Gambar
Rasio standar untuk foto utama Xiaohongshu adalah 3:4 (vertikal), rasio 1:1 cocok untuk kartu informasi, dan 9:16 untuk sampul video pendek. gpt-image-2 secara native mendukung 3 rasio ini (beserta 1:1, 2:3, 3:2, 4:3, 4:5, 16:9, 21:9, total 9 jenis), tanpa perlu proses crop tambahan.
Yang lebih penting, gpt-image-2 mendukung pembuatan 1-10 gambar dalam satu permintaan. Panjang postingan gambar Xiaohongshu terbaik adalah 6-9 foto (mendapatkan bobot algoritma tertinggi). Kreator dapat meminta model untuk membuat satu rangkaian carousel lengkap berdasarkan tema yang sama sekaligus, sehingga gaya visualnya tetap konsisten.
Matriks Adaptasi Tipe Konten Xiaohongshu untuk gpt-image-2
Tipe konten yang berbeda di Xiaohongshu memiliki kebutuhan gambar yang berbeda pula. Tabel berikut membantu Anda menentukan tingkat kecocokan dan parameter yang direkomendasikan untuk gpt-image-2 dalam setiap format konten.
| Tipe Konten | Rasio Rekomendasi | Jumlah Gambar | Kepadatan Teks | Kecocokan gpt-image-2 | Kualitas Rekomendasi |
|---|---|---|---|---|---|
| Infografis Edukasi | 3:4 | 6-9 | Tinggi (80-150 kata/gambar) | ⭐⭐⭐⭐⭐ | high |
| Kartu Ulasan Produk | 3:4 | 6-9 | Sedang (40-80 kata/gambar) | ⭐⭐⭐⭐⭐ | high |
| Gambar Langkah Tutorial | 3:4 | 4-9 | Sedang (50-100 kata/gambar) | ⭐⭐⭐⭐⭐ | medium-high |
| Visualisasi Data | 3:4 / 1:1 | 1-3 | Tinggi (100+ kata/gambar) | ⭐⭐⭐⭐⭐ | high |
| Rekomendasi Kuliner/Fashion | 3:4 | 6-9 | Rendah (fokus pada tag) | ⭐⭐⭐⭐ | medium |
| Sampul Vlog | 9:16 | 1 | Sedang (fokus pada judul) | ⭐⭐⭐⭐ | high |
| Meme/Lelucon | 1:1 | 1 | Rendah | ⭐⭐⭐ | low-medium |
Dari tingkat kecocokannya, terlihat bahwa gpt-image-2 paling unggul dalam konten informatif dengan kepadatan teks sedang hingga tinggi, yang justru merupakan tipe konten dengan "tingkat simpan" tinggi yang disukai oleh algoritma Xiaohongshu. Berdasarkan bobot algoritma CES resmi Xiaohongshu, tindakan menyimpan bernilai 1 poin, sama pentingnya dengan menyukai (like), sementara komentar dan berbagi masing-masing bernilai 4 poin. Konten infografis, tutorial, dan ulasan memiliki tingkat simpan yang jauh lebih tinggi karena "nilai praktisnya", sehingga mendapatkan lebih banyak trafik organik dalam distribusi algoritma.
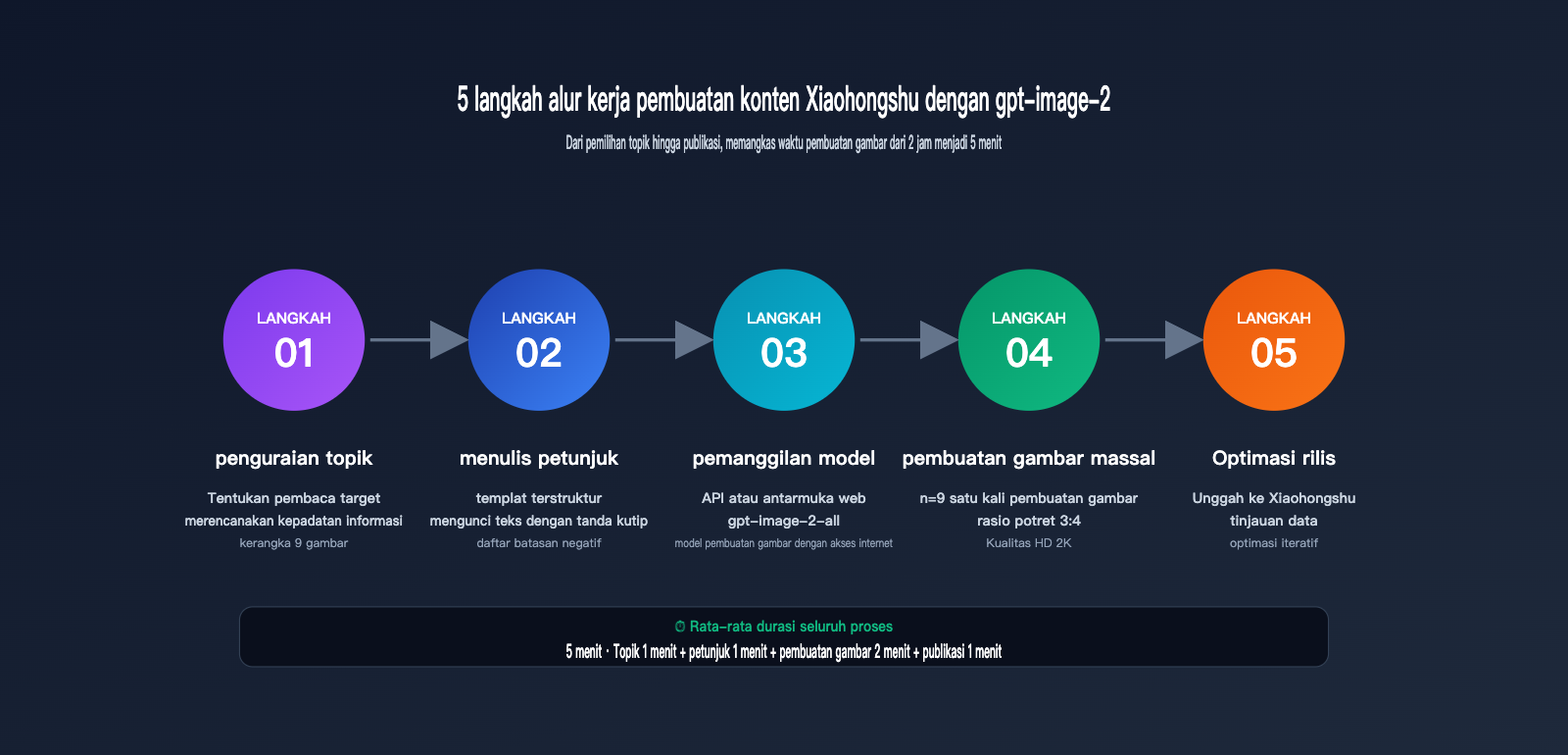
Alur Kerja 5 Langkah Pembuatan Konten Gambar Xiaohongshu dengan gpt-image-2
Mari masuk ke tahap praktik. Alur lengkap pembuatan gambar Xiaohongshu dengan gpt-image-2 dibagi menjadi 5 langkah, di mana setiap langkah memiliki teknik yang dapat digunakan kembali.
Langkah 1: Bedah Topik dan Perencanaan Kepadatan Informasi
Sebelum membuka gpt-image-2, luangkan waktu 5 menit untuk membedah topik. Catatan infografis Xiaohongshu yang baik harus menjawab tiga pertanyaan:
- Siapa target pembacanya (Pemula / Lanjutan / Pengambil Keputusan)
- Berapa banyak informasi inti (3 poin / 5 poin / 7 poin)
- Berapa banyak informasi per gambar (Satu gambar satu opini / Satu gambar perbandingan)
Contoh: Membuat catatan "Perbandingan Alat AI Drawing 2026", bisa dibagi menjadi 9 gambar: 1 sampul + 1 tabel ringkasan + 5 pengenalan alat (satu alat per gambar) + 1 kesimpulan rekomendasi + 1 ajakan bertindak (CTA). Kontrol informasi inti setiap gambar di bawah 80 kata.
Langkah 2: Menulis Prompt gpt-image-2 yang Terstruktur untuk Xiaohongshu
Penulisan Prompt gpt-image-2 memiliki struktur resmi yang direkomendasikan: Latar Belakang/Skenario → Subjek → Detail Kunci → Konten Teks → Batasan Gaya. Agar gambar Xiaohongshu yang dihasilkan stabil dan dapat digunakan, ada 4 aturan utama:
- Teks bahasa Mandarin yang harus muncul wajib dibungkus dengan tanda kutip Mandarin 「」 atau tanda kutip Inggris "", agar model dapat merender dengan presisi.
- Tentukan hierarki ukuran font secara eksplisit dalam Prompt (misalnya "Judul utama 64pt tebal, subjudul 28pt").
- Gunakan kata kunci seperti "high-fidelity", "ultra-detailed", "crisp typography" untuk meningkatkan detail.
- Cantumkan batasan negatif (seperti "no watermark, no extra text, no duplicate words") untuk menghindari penambahan elemen yang tidak perlu.
Langkah 3: Memanggil API gpt-image-2 untuk Menghasilkan Gambar
Jika Anda memiliki kemampuan dasar pemanggilan API, Anda dapat menggunakan antarmuka standar OpenAI untuk memanggil gpt-image-2 secara langsung. Berikut adalah contoh kode minimalis untuk menghasilkan sampul Xiaohongshu rasio 3:4:
from openai import OpenAI
client = OpenAI(
api_key="your_apiyi_key",
base_url="https://api.apiyi.com/v1"
)
response = client.images.generate(
model="gpt-image-2-all",
prompt='Sampul infografis gaya Xiaohongshu, rasio 3:4 vertikal, judul utama 「2026 AI Drawing Tools TOP 5」 64pt putih tebal, subjudul 「Wajib lihat, simpan sekarang」 28pt abu-abu muda, menampilkan 5 thumbnail Logo alat di tengah, latar belakang gradasi merah muda ke ungu, high-fidelity typography, crisp text, no watermark',
size="1024x1536",
quality="high",
n=1
)
print(response.data[0].url)
📌 Penjelasan konfigurasi base_url: Kode di atas menggunakan APIYI
api.apiyi.com/v1sebagai titik akses. Nama modelgpt-image-2-alladalah versi resmi yang mendukung pencarian internet secara default. Pengguna umum juga dapat menggunakan model standargpt-image-2(tanpa pencarian internet) dengan harga yang lebih terjangkau.
Langkah 4: Menghasilkan 9 Gambar Carousel Secara Batch
Jumlah gambar terbaik untuk catatan Xiaohongshu adalah 6-9 gambar. Jika Anda menulis Prompt satu per satu secara manual, efisiensinya terlalu rendah. Parameter n pada gpt-image-2 mendukung 1-10, sehingga Anda bisa menghasilkan 9 gambar sekaligus.
Namun, ada satu trik di sini: Jangan biarkan model menghasilkan 9 gambar yang tidak saling terkait, tetapi pandulah dengan Prompt untuk menghasilkan "gambar seri". Contoh:
response = client.images.generate(
model="gpt-image-2-all",
prompt='''Hasilkan satu set 9 gambar carousel edukasi Xiaohongshu yang koheren, rasio 3:4 vertikal,
latar belakang ungu tua seragam + teks putih, tema "5 Rumus Prompt Wajib untuk Pemula AI Drawing",
Gambar 1: Halaman sampul, judul 「Wajib Pelajari AI Drawing」 subjudul 「5 Rumus Prompt」,
Gambar 2-6: Setiap gambar memperkenalkan satu rumus, nomor urut 01-05 di bagian atas, nama rumus di tengah, penjelasan 30 kata di bawah,
Gambar 7: Tabel perbandingan rumus,
Gambar 8: Tampilan contoh praktik,
Gambar 9: Halaman ajakan mengikuti, teks 「Jangan lupa like dan simpan」 ''',
size="1024x1536",
quality="high",
n=9
)
Langkah 5: Tidak bisa coding? Gunakan alat web imagen.apiyi.com
Jika Anda adalah kreator konten murni tanpa pengalaman Python atau pemanggilan API, Anda bisa melewati tahap coding. Kami merekomendasikan penggunaan imagen.apiyi.com, alat berbasis web yang membungkus berbagai model gambar utama seperti gpt-image-2, Nano Banana, dan Seedream. Alat ini menyediakan antarmuka formulir yang mudah digunakan, mendukung pemilihan rasio, kontrol jumlah gambar, dan unduhan batch. Anda bisa menguasainya dalam 5 menit.
🎨 Saran pemilihan alat: Untuk kreator murni, kami sarankan menggunakan alat web imagen.apiyi.com secara langsung—tidak perlu menulis kode, tidak perlu konfigurasi API, cukup pilih model (disarankan gpt-image-2 atau gpt-image-2-all) dan rasio (3:4) untuk mulai menghasilkan. Untuk studio yang membutuhkan otomatisasi batch, disarankan untuk memanggil API melalui APIYI apiyi.com, yang dapat diintegrasikan ke alat SaaS atau tabel Feishu milik Anda sendiri.
Pustaka Template Petunjuk (Prompt) Viral Xiaohongshu gpt-image-2
Berikut adalah 6 template petunjuk yang telah teruji dan mencakup jenis konten paling populer di Xiaohongshu. Semua template telah dioptimalkan untuk instruksi rendering teks, sehingga Anda bisa langsung menyalin dan mengganti konten di dalam kurung 【】 dengan topik Anda.
Template 1: Kartu Edukasi Pengetahuan (Kepadatan Informasi Tinggi)
Kartu edukasi gaya Xiaohongshu, rasio 3:4 vertikal,
Bar judul atas: latar belakang ungu tua, judul bahasa Mandarin tebal putih 「【Judul utama Anda, maks 15 karakter】」 ukuran 56pt,
Subjudul 「【Deskripsi nilai singkat, maks 20 karakter】」 ukuran 24pt ungu muda,
Area konten tengah: 5 poin bernomor, setiap poin berisi lencana angka + judul + penjelasan 30 karakter,
Bawah: Tombol CTA merah muda 「Simpan agar tidak hilang」,
Skema warna: Ungu tua #2D1B69, merah muda cerah #FF6B9D,
high-fidelity Chinese typography, crisp text rendering, no watermark, no duplicate text
Template 2: Kartu Perbandingan Produk
Kartu perbandingan produk Xiaohongshu, rasio 3:4 vertikal, latar belakang putih,
Atas: Dua gambar produk kiri dan kanan + nama produk 「【Produk A】」 vs 「【Produk B】」,
Tengah: Tabel perbandingan 5 baris, setiap baris berisi nama dimensi + skor A + skor B,
Skor ditampilkan menggunakan ikon 5 bintang (★),
Bawah: Kesimpulan rekomendasi 「Rekomendasi keseluruhan: 【Nama Produk】」,
Font tajam dan jelas, garis tabel 1px abu-abu muda, judul utama tebal 48pt,
high-fidelity, ultra-detailed, no extra elements
Template 3: Gambar Langkah Tutorial
Diagram langkah tutorial Xiaohongshu, rasio 3:4 vertikal, latar belakang krem hangat,
Judul utama atas 「【Topik】Selesai dalam 3 menit」 hitam tebal 56pt,
Tengah: 3 blok langkah disusun vertikal,
Setiap blok: Angka langkah besar di kiri (01/02/03), judul langkah di kanan + penjelasan 25 karakter,
Bawah: Gambar hasil akhir + teks 「Selesai!」,
Gaya ilustrasi gambar tangan, warna aksen oranye hangat,
crisp typography, clear hierarchy, no watermark
Template 4: Gambar Visualisasi Data
Kartu data Xiaohongshu, rasio 3:4 vertikal, latar belakang gradasi biru tua,
Judul atas 「【Topik Data】Data terbaru 2026」 putih 52pt,
Tengah: 1 angka besar utama 「【Angka Kunci】」 menempati 40% tinggi layar,
Di bawah angka: Penjelasan sumber data 12pt biru muda,
Bagian tengah bawah: 3 baris data tambahan, setiap baris berisi ikon + data + penjelasan singkat,
Bawah: CTA warna terang 「Bagikan ke rekan kerja」,
Skema warna: Gradasi biru tua #0F172A ke #1E40AF, teks kontras tinggi putih,
high-fidelity typography, crisp small text, no extra words
Template 5: Gambar Daftar Tips (Cheat Sheet)
Sampul daftar tips Xiaohongshu, rasio 3:4 vertikal,
Atas: Bar horizontal hijau neon, teks tebal hitam 「【Angka】 buah 【Topik】」 60pt,
Subjudul 「Koleksi pribadi blogger, langsung contek setelah baca」 24pt,
Tengah: 【Angka】 item daftar, setiap item berisi ikon ✓ + nama item,
Tata letak padat namun dengan ruang kosong yang pas, gradasi ukuran font jelas,
Bawah: Bingkai merah muda + teks 「Lihat daftar lengkap di slide berikutnya」,
Gaya: Modern minimalis, tata letak gaya Notion,
high-fidelity Chinese text, crisp icons, no decorative noise
Template 6: Skenario Khusus Pembuatan Gambar Terhubung Internet (Khusus gpt-image-2-all)
Kartu rekomendasi produk baru Xiaohongshu, rasio 3:4 vertikal,
Topik: Memperkenalkan 【Nama produk terbaru, contoh: iPhone 17 Pro Max】,
Harap cari secara online warna resmi terbaru, parameter kunci, dan tanggal rilis produk tersebut,
Atas: Gambar render tampilan asli produk,
Tengah: Nama produk + 3 poin keunggulan utama (warna/kapasitas/harga),
Bawah: Copywriting rekomendasi 「Layak dibeli? Putuskan setelah membaca ini」,
Gaya: Minimalis ala Apple, latar belakang putih,
high-fidelity, accurate product details from web search, no fictional specs
💡 Tips Penggunaan Template: Semua template di atas telah dioptimalkan untuk rendering teks bahasa Mandarin. Disarankan untuk menggunakan
quality="medium"saat pertama kali mencoba untuk memastikan tata letak sudah benar, baru kemudian beralih kequality="high"untuk hasil akhir guna menghemat biaya 30-40%. Untuk produksi massal, disarankan menggunakan APIYI (apiyi.com) karena stabilitas dan kecepatannya lebih baik daripada koneksi langsung.
Perbandingan Kemampuan gpt-image-2 vs Alat Desain Tradisional
Banyak kreator bertanya: dengan adanya Canva, Figma, dan Photoshop, mengapa harus beralih ke gpt-image-2? Tabel berikut membandingkan efisiensi keempat alat tersebut dalam skenario utama operasional Xiaohongshu.
| Dimensi Perbandingan | gpt-image-2 | Canva | Figma | Photoshop |
|---|---|---|---|---|
| Waktu pembuatan per gambar | 30 detik-1 menit | 15-30 menit | 30-60 menit | 1-2 jam |
| Waktu 9 gambar carousel | 5 menit (n=9) | 3-4 jam | 4-6 jam | 8+ jam |
| Rendering teks Mandarin | 95%+ akurat | 100% (input manual) | 100% (input manual) | 100% (input manual) |
| Kemampuan eksplorasi kreatif | Tinggi (AI generate) | Sedang (pustaka template) | Rendah (mulai dari nol) | Rendah (mulai dari nol) |
| Pengetahuan internet | ✅ Bawaan | ❌ | ❌ | ❌ |
| Hambatan belajar | Rendah (bisa tulis Mandarin) | Rendah | Sedang | Tinggi |
| Biaya bulanan | $5-30 (sesuai pemakaian) | $12.99 langganan | $15 langganan | $22.99 langganan |
| Skenario yang cocok | Produksi massal, infografis | Penggunaan template | Kolaborasi tim | Edit gambar komersial |
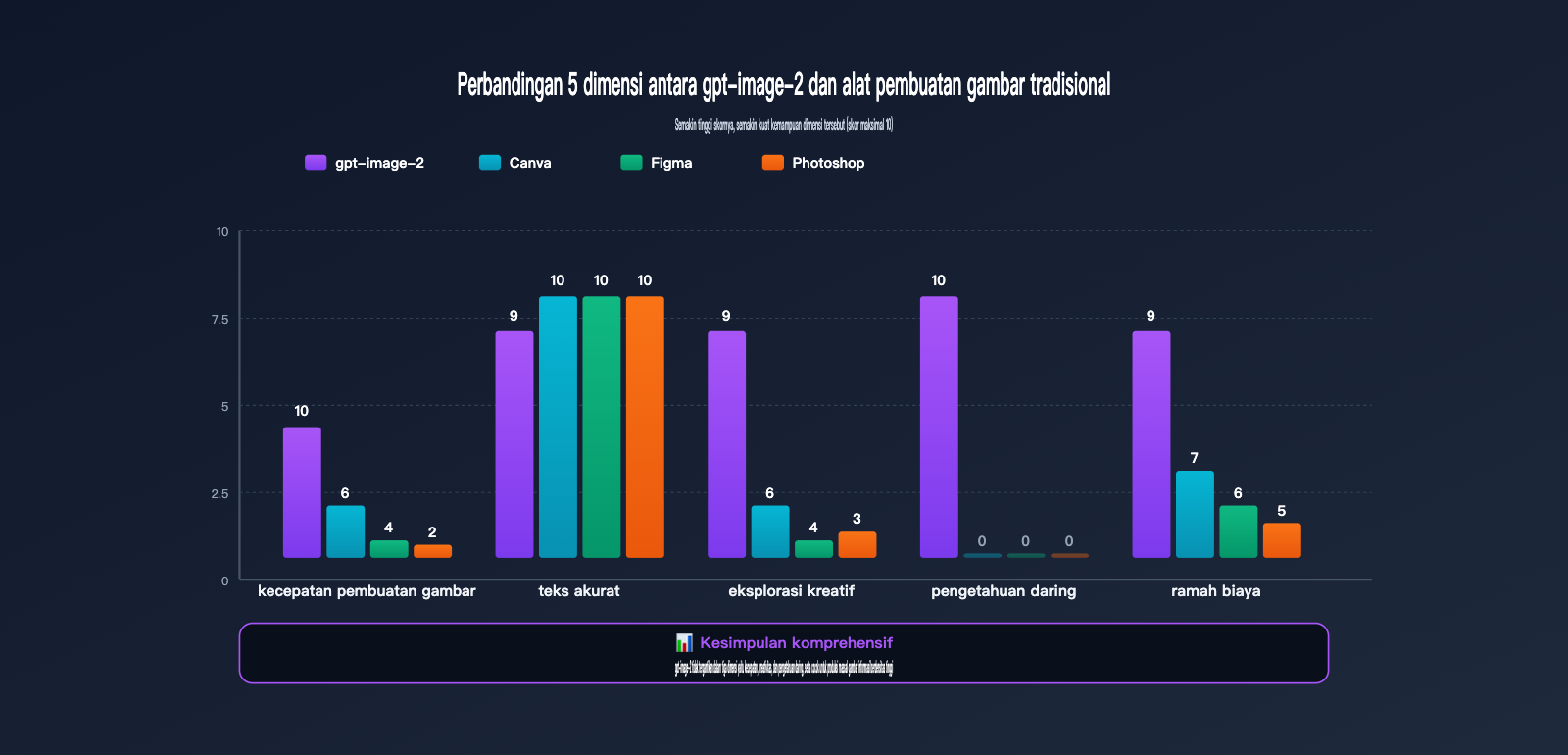
Dari tabel perbandingan di atas, terlihat bahwa gpt-image-2 tidak bertujuan untuk menggantikan Canva/Figma, melainkan mencakup skenario baru: kombinasi "eksplorasi kreatif + produksi massal + pengetahuan internet". Jika akun Xiaohongshu Anda perlu memposting 3-5 konten secara stabil setiap minggu, gpt-image-2 dapat memangkas waktu produksi gambar dari 8-10 jam menjadi kurang dari 1 jam.
FAQ Pertanyaan Umum Operasional Xiaohongshu dengan gpt-image-2
Q1: Apakah teks bahasa Mandarin pada gambar Xiaohongshu yang dihasilkan gpt-image-2 benar-benar tidak akan salah?
Berdasarkan pengujian, tingkat akurasinya di atas 95%. OpenAI secara eksplisit menyebutkan dalam blog resmi mereka bahwa gpt-image-2 adalah model "polyglot" (multibahasa) yang memiliki peningkatan signifikan pada karakter non-Latin seperti Mandarin, Jepang, dan Korea. Namun, ada dua hal yang perlu diperhatikan: Pertama, teks bahasa Mandarin dalam petunjuk (prompt) harus diapit dengan tanda kutip (misalnya: "teks di sini"), jika tidak, model mungkin akan memprosesnya berdasarkan "pemahaman" alih-alih "penyalinan"; Kedua, karakter yang jarang digunakan dan aksara tradisional mungkin masih bisa salah, disarankan untuk memeriksa kembali teks penting sebelum mengirimkannya.
Q2: Berapa biaya untuk menghasilkan satu gambar Xiaohongshu ukuran 3:4 dengan gpt-image-2?
Berdasarkan harga resmi, satu gambar berkualitas tinggi ukuran 1024×1536 (3:4) berharga sekitar $0,20-$0,25. Jika Anda membuat konten carousel 9 gambar, biayanya sekitar $1,8-$2,3 (setara dengan 13-17 RMB). Melalui akses layanan proksi API APIYI (apiyi.com), harganya biasanya lebih murah, mendukung pembayaran dalam mata uang RMB, dan menyediakan faktur, sehingga cocok untuk kreator domestik yang melakukan produksi massal.
Q3: Bagaimana cara menggunakan fitur "pembuatan gambar dengan akses internet" pada gpt-image-2?
Fitur akses internet diaktifkan secara default di versi web ChatGPT (mode Thinking), sedangkan di sisi API, Anda perlu menggunakan varian model yang mendukung akses internet. Saat memanggil model gpt-image-2-all melalui APIYI (apiyi.com), pencarian internet diaktifkan secara default—Anda hanya perlu menyebutkan informasi nyata yang perlu dicari dalam petunjuk (seperti "rilis terbaru", "warna resmi", atau "parameter asli"), dan model akan secara otomatis memicu pencarian web serta mengintegrasikan hasil pencarian ke dalam proses pembuatan gambar.
Q4: Saya tidak bisa coding, apakah saya bisa menggunakan gpt-image-2 untuk Xiaohongshu?
Tentu saja bisa. Kami merekomendasikan penggunaan alat web imagen.apiyi.com. Anda tidak perlu konfigurasi API atau lingkungan Python. Cukup pilih model (gpt-image-2 atau gpt-image-2-all) pada formulir web, isi petunjuk, pilih rasio (3:4) dan jumlah gambar, lalu klik buat. Alat ini mendukung antarmuka bahasa Mandarin, unduhan massal, dan manajemen riwayat, sehingga sangat cocok untuk kreator konten murni.
Q5: Apakah gambar Xiaohongshu yang dihasilkan gpt-image-2 akan dibatasi (limit) karena dianggap "buatan AI"?
Saat ini, pihak resmi Xiaohongshu tidak memiliki aturan pembatasan publik terhadap "gambar buatan AI", dan inti dari penilaian algoritma adalah tingkat interaksi (like, simpan, komentar, bagikan, pengikut). Selama gambar Anda memiliki kepadatan informasi yang tinggi dan bernilai bagi pembaca, Anda secara alami akan mendapatkan umpan balik data yang positif. Disarankan untuk mencantumkan sumber gambar dalam teks konten (misalnya: "dibuat dengan bantuan AI") untuk meningkatkan transparansi konten.
Q6: Berapa banyak gambar yang bisa dihasilkan gpt-image-2 dalam satu kali proses?
Untuk sisi API, satu permintaan dapat menghasilkan hingga 10 gambar (n=10), sedangkan di ChatGPT versi web maksimal 8 gambar. Untuk skenario carousel 9 gambar di Xiaohongshu, sisi API dapat menyelesaikannya dalam satu kali proses, dengan efisiensi yang jauh lebih tinggi dibandingkan model lainnya. Namun perlu diingat, semakin besar nilai n, semakin lama waktu antrean dan pemrosesan. Disarankan untuk mengatur tugas asinkron saat melakukan produksi massal.
Q7: Antara gpt-image-2, Nano Banana Pro, dan Seedream, mana yang lebih cocok untuk Xiaohongshu?
Singkatnya: gpt-image-2 cocok untuk konten dengan "kepadatan informasi tinggi + banyak teks" (infografis, kartu ulasan, grafik data), Nano Banana Pro cocok untuk "skenario kreatif + konsistensi karakter" (cerita berseri, narasi multi-gambar), dan Seedream cocok untuk "estetika oriental + rendering bahasa Mandarin" (Hanfu, gaya tradisional Tiongkok, lukisan tinta). Ketiga model tersebut dapat dicoba di imagen.apiyi.com, disarankan untuk melakukan pengujian A/B sebelum menentukan model utama.
Q8: Bagaimana cara membuat gaya dari beberapa gambar yang dihasilkan gpt-image-2 tetap konsisten?
Tiga teknik utama: Pertama, gunakan n=9 untuk menghasilkan sekaligus, model akan secara otomatis menjaga konsistensi gaya; Kedua, kunci palet warna dalam petunjuk (misalnya: "gunakan warna ungu #2D1B69 + merah muda #FF6B9D secara konsisten"); Ketiga, kunci struktur tata letak (misalnya: "semua gambar menggunakan judul di atas + konten di tengah + CTA di bawah"). Jika Anda memerlukan konsistensi karakter/skenario yang lebih kuat, Anda dapat mempertimbangkan untuk menggunakan fitur pengeditan multi-gambar gpt-image-2 yang berbasis pada gambar referensi.
Kesimpulan: 3 Logika Dasar Menggunakan gpt-image-2 untuk Xiaohongshu
Sampai di sini, kita dapat menyimpulkan 3 logika dasar dalam pembuatan konten Xiaohongshu dengan gpt-image-2:
Pertama, anggap pembuatan gambar sebagai "desain produk" bukan "melukis". Agentic Reasoning pada gpt-image-2 membuatnya lebih seperti "desainer yang bisa berpikir". Semakin petunjuk Anda menyerupai dokumen kebutuhan desain (tujuan yang jelas, hierarki informasi, batasan visual), maka hasil yang dikeluarkan akan semakin akurat.
Kedua, jadikan "kepadatan informasi" sebagai senjata pembeda. Algoritma Xiaohongshu memberikan penghargaan pada konten dengan tingkat simpan yang tinggi, dan esensi dari tingkat simpan yang tinggi adalah "nilai guna". Terobosan gpt-image-2 dalam rendering teks dan tata letak memungkinkan Anda membuat "infografis berdensitas tinggi" yang tidak bisa dibuat oleh templat Canva biasa. Ini adalah jalur terbaik bagi akun baru untuk menyalip kompetitor.
Ketiga, manfaatkan "pengetahuan internet" untuk aktualitas konten. Untuk konten yang melibatkan produk terbaru, peristiwa hangat, atau data resmi, pastikan untuk menggunakan model yang mendukung akses internet seperti gpt-image-2-all guna menghindari kesalahan informasi yang dibuat oleh AI.
🚀 Saran Tindakan: Jika Anda berencana memasukkan gpt-image-2 ke dalam alur kerja Xiaohongshu, kami sarankan untuk memulai dari dua pintu masuk—kreator murni dapat memulai dari alat web imagen.apiyi.com, Anda bisa menghasilkan gambar pertama dalam 3 menit; studio dengan kemampuan teknis dapat mengakses model gpt-image-2-all melalui APIYI (api.apiyi.com) untuk membangun lini produksi massal. Kedua pintu masuk mendukung pembuatan gambar dengan akses internet, dengan harga yang terjangkau, cocok untuk penggunaan skala besar oleh tim kreatif domestik.
Menguasai gpt-image-2 tidak akan membuat konten Xiaohongshu Anda viral dalam semalam, tetapi alat ini dapat mengurangi biaya waktu dalam tahap pembuatan gambar hingga 90%, sehingga Anda dapat mencurahkan lebih banyak energi pada pemilihan topik, pemolesan teks, dan manajemen interaksi—hal-hal yang benar-benar memengaruhi data Anda. Inilah nilai terbesar alat AI bagi kreator konten.
Penulis Artikel: Tim Teknis APIYI — Fokus pada integrasi API Model Bahasa Besar AI dan pengembangan alat pembuatan konten. Kunjungi apiyi.com untuk mendapatkan lebih banyak evaluasi model, templat petunjuk, dan panduan pengembangan.