“gemini-3.1-flash-lite-image supporte-t-il vraiment le mode de raisonnement ?” C’est l’une des questions qui revient le plus souvent dans les groupes autour des appels API. La réponse est oui, et ce n’est pas une supposition — nous avons croisé la documentation officielle de Google avec trois séries d’expériences comparatives via la passerelle APIYI, puis récupéré des données réelles de consommation de tokens et de latence. Cet article va expliquer clairement l’interrupteur thinkingLevel sous trois angles : structure des paramètres, mesures réelles et règles de facturation.
Valeur clé : à la fin de cet article, vous saurez précisément comment activer le mode de raisonnement de gemini-3.1-flash-lite-image, combien de tokens il coûte en plus, et dans quels cas ça vaut la peine d’accepter cette latence supplémentaire.

Conclusion clé sur le mode de raisonnement de gemini-3.1-flash-lite-image
Commençons par la conclusion, puis entrons dans les détails. La documentation officielle de Google indique clairement qu’avec gemini-3.1-flash-image et gemini-3.1-flash-lite-image, les développeurs peuvent contrôler la quantité de réflexion utilisée par le modèle. Cela signifie que le niveau flash-lite intègre lui aussi une capacité de raisonnement, et que ce n’est pas réservé aux modèles phares. En revanche, tous les modèles image ne prennent pas ce paramètre en charge. Le tableau ci-dessous compare la prise en charge sur trois modèles Gemini image courants.
| Modèle | Prise en charge de thinkingLevel |
Niveaux ajustables | Niveau par défaut | Remarque |
|---|---|---|---|---|
gemini-3.1-flash-image |
✅ Pris en charge | minimal / high | minimal | Mentionné explicitement dans la documentation officielle |
gemini-3.1-flash-lite-image |
✅ Pris en charge | minimal / high | minimal | Partage le même thinkingConfig que flash-image |
gemini-3-pro-image |
⚠️ Paramètre sans effet | Fixe, non ajustable | Interne fixe | high peut être envoyé sans erreur, mais aucun changement observable |
Il faut préciser un point important : thinkingLevel n’a que deux niveaux, ce n’est pas un budget de réflexion continu comme pour certains modèles de texte. Le texte officiel indique que « minimal thinking » ne veut pas dire que le modèle ne réfléchit pas du tout. Autrement dit, même avec le réglage par défaut, le modèle effectue déjà une certaine quantité de raisonnement de base ; simplement, il ne fait pas de vérifications multi-étapes de composition comme avec le niveau high.
C’est aussi un signal intéressant pour le secteur. Dans les générations précédentes de modèles de génération d’images, que ce soit nano banana ou la première version de flash-image, les interfaces officielles n’exposaient pas ce type de paramètre de niveau de réflexion. Le modèle générait soit selon une stratégie fixe, soit en s’appuyant entièrement sur le prompt engineering pour compenser les défauts de composition. Avec la génération 3.1, Google a ouvert le mécanisme « planifier d’abord, générer ensuite » à la famille flash. En pratique, cela revient à transférer vers la génération d’images un paradigme de réflexion jusque-là validé surtout sur les modèles de texte. Comprendre ce contexte aide à anticiper si d’autres éditeurs de modèles image suivront la même voie.
🎯 Conseil technique : si vous appelez les modèles Gemini image via APIYI apiyi.com, commencez par le niveau
minimalpar défaut pour valider le flux métier, puis passez àhighseulement si la qualité de sortie le justifie. La plateforme fournit une interface unifiée, etgemini-3.1-flash-image,flash-lite-imageetpro-imagepeuvent être appelés avec le même code, ce qui facilite les comparaisons A/B.
Détails du paramètre thinkingLevel et mode d’appel
thinkingLevel n’est pas un paramètre autonome : il se trouve dans l’objet thinkingConfig, lui-même imbriqué sous generationConfig, et il s’utilise avec includeThoughts. includeThoughts détermine si le résumé de réflexion du modèle est renvoyé à l’appelant, tandis que thinkingLevel règle l’« intensité » de cette réflexion. Ce sont deux interrupteurs distincts et découplés, donc il ne faut pas les confondre.
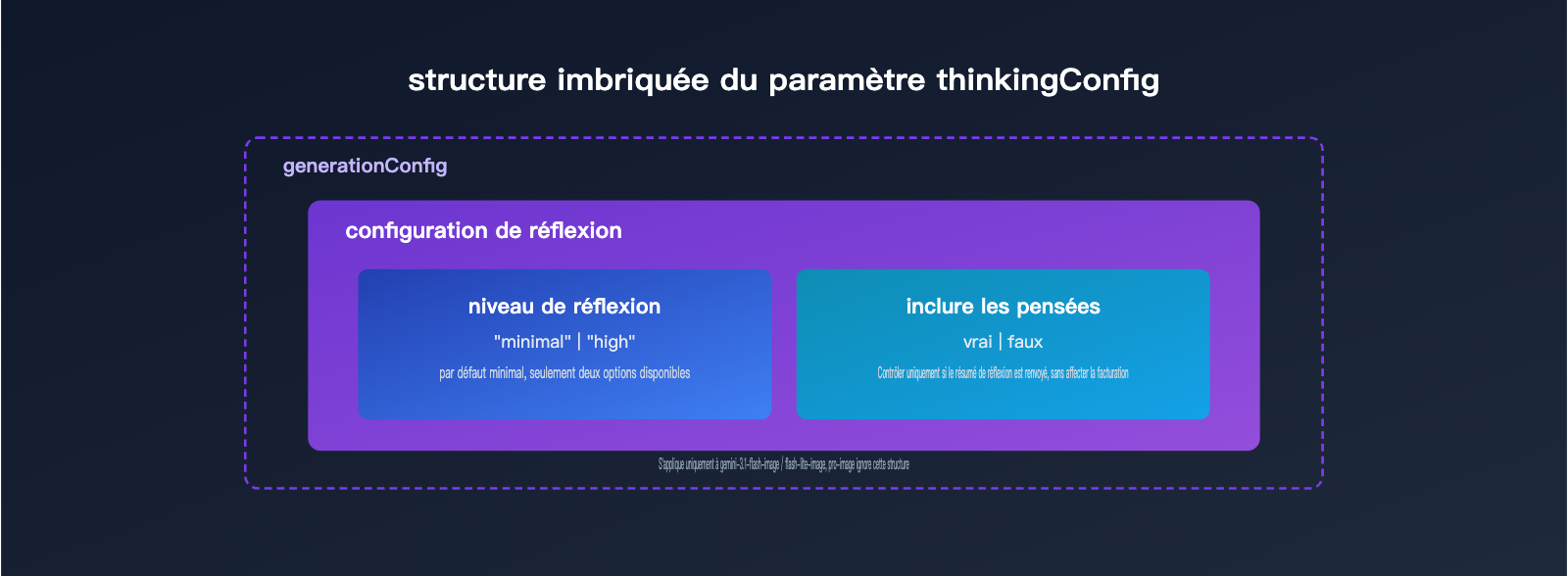
Le tableau ci-dessous résume le type et la plage de valeurs des deux champs clés de thinkingConfig.
| Champ | Type | Valeurs possibles | Valeur par défaut | Rôle |
|---|---|---|---|---|
| thinkingLevel | chaîne énumérée | minimal / high |
minimal |
Contrôle l’intensité du raisonnement du modèle, actif uniquement sur les modèles d’images de la série flash |
| includeThoughts | booléen | true / false |
false |
Indique si le résumé du processus de réflexion doit être renvoyé dans la réponse, sans impact sur la facturation |
En pratique, la structure d’appel est la même dans les trois langages principaux : on ajoute simplement un objet thinkingConfig dans config. Prenons Python comme exemple :
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Appel via la passerelle unifiée APIYI
)
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-image",
messages=[{"role": "user", "content": "Dessine un chat qui boit un café au pied d'une montagne enneigée"}],
extra_body={
"thinkingConfig": {
"thinkingLevel": "high",
"includeThoughts": True
}
}
)
print(response.choices[0].message.content)
Voir l’exemple complet d’appel REST natif
{
"contents": [{"parts": [{"text": "Dessine un chat qui boit un café au pied d'une montagne enneigée"}]}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"thinkingConfig": {
"thinkingLevel": "high",
"includeThoughts": true
}
}
}
La structure du SDK JavaScript est cohérente, elle aussi : on remplace simplement le style snake_case du REST par un objet thinkingConfig en camelCase, et le reste des noms de champs ne change pas. Il n’y a pas de différence fondamentale entre les trois langages côté logique d’appel ; retenez juste cette règle : thinkingConfig se place uniquement sous generationConfig.
Il y a un détail qui peut piéger : la valeur de thinkingLevel est une énumération sensible à la casse. Dans les exemples officiels, on voit parfois "High" et parfois "high". En test réel, les deux sont bien reconnus et pris en compte par la passerelle, mais pour éviter de dépendre d’un comportement de compatibilité non documenté, mieux vaut uniformiser le code métier avec les minuscules "high" et "minimal". Comme ça, même si la validation de casse se resserre un jour côté amont, vos appels en production ne seront pas impactés.
Conseil : passez par APIYI apiyi.com pour obtenir un quota de test gratuit et vérifier directement côté passerelle si
thinkingConfigest bien transmis, c’est plus simple que de demander une clé officielle juste pour déboguer.
Données de test APIYI : impact réel de thinkingLevel sur les tokens et la latence
Même une documentation très claire reste abstraite tant qu’on n’a pas une série de mesures réelles. Avec la même invite, nous avons testé via la passerelle APIYI une génération d’images en 1K, en comparant gemini-3.1-flash-image en mode minimal, en mode high, ainsi que gemini-3-pro-image avec un paramètre high forcé.
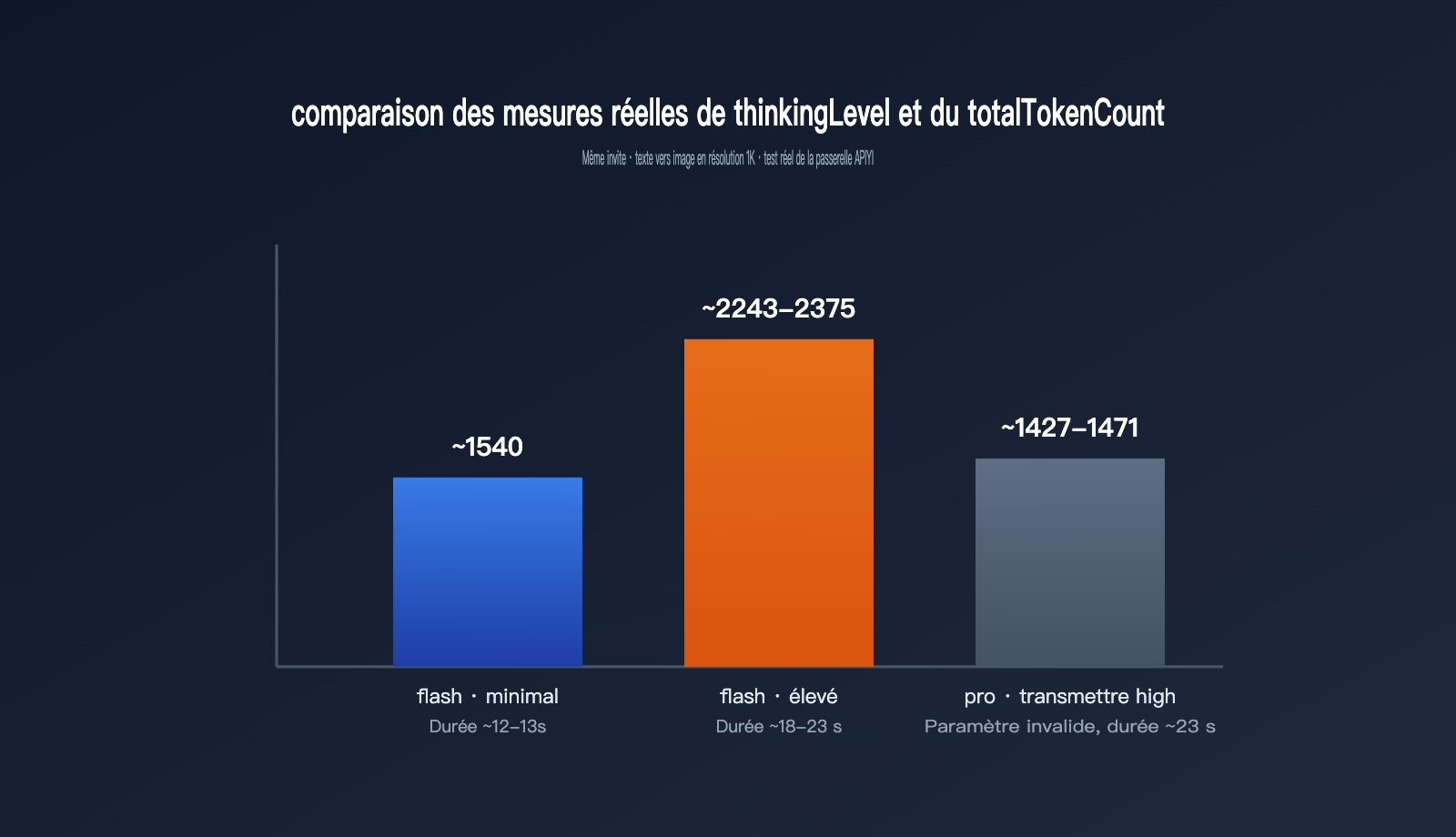
| Modèle / réglage | thoughtsTokenCount | Tokens image | totalTokenCount | Temps écoulé |
|---|---|---|---|---|
| gemini-3.1-flash-image · minimal (par défaut) | pas de champ | 1120 | env. 1540 | env. 12-13 s |
| gemini-3.1-flash-image · high | 700-792 | 1120 | env. 2243-2375 | env. 18-23 s |
| gemini-3-pro-image · high transmis | 181-214 (identique au défaut) | 1120 | env. 1427-1471 | env. 23 s |
Ces résultats montrent trois choses importantes. Premièrement, quand on passe thinkingLevel sur high, thoughtsTokenCount grimpe directement de 0 dans le mode par défaut — au point que le champ n’apparaît même pas dans la réponse — à une plage de 700 à 800 tokens. La consommation totale augmente alors d’environ 50 %, et la latence passe de 12-13 secondes à 18-23 secondes : la réflexion coûte donc vraiment du temps et des ressources. Deuxièmement, que l’on soit en minimal ou en high, le nombre de tokens liés à l’image produite reste toujours à 1120, ce qui montre que thinkingLevel ne modifie que la façon dont le modèle « pense », pas la résolution de l’image ni sa facturation propre. Troisièmement, envoyer high à gemini-3-pro-image ne provoque pas d’erreur, mais les 181-214 tokens de réflexion restent pratiquement identiques au comportement par défaut, ce qui confirme l’indication de la documentation officielle : le comportement de réflexion de pro-image est fixe et ne se règle pas de l’extérieur.
Autrement dit, si votre logique métier applique un thinkingConfig uniforme et le transmet en bloc aux modèles flash, flash-lite et pro, pro-image va simplement ignorer ce paramètre sans erreur ni interruption, mais il n’ajustera pas réellement l’intensité de réflexion comme vous pourriez l’attendre.
Dernier point à préciser : les chiffres ci-dessus ne viennent pas d’une seule requête, mais d’une série de requêtes répétées avec la même invite pour chaque réglage, puis ramenées sous forme de plage. C’est pour ça que high affiche un intervalle comme 700-792 pour thoughtsTokenCount, et pas une valeur fixe. Les tâches de réflexion gardent une part de variabilité : à chaque génération, le chemin de raisonnement intermédiaire peut légèrement changer, ce qui entraîne de petites fluctuations de consommation de tokens. En revanche, l’ordre de grandeur et la tendance de latence restent stables et reproductibles : on ne verra pas un high plus rapide qu’un minimal, ni une explosion anormale de plusieurs milliers de tokens de réflexion.
Jetons de réflexion et règles de facturation pour les modèles d’images
Quand ils voient pour la première fois le champ thoughtsTokenCount, beaucoup de développeurs le comparent spontanément au coût de réflexion d’un modèle texte. En réalité, pour un modèle d’images, le mécanisme de réflexion est facturé en deux parties. Bien comprendre ce point est essentiel pour maîtriser les coûts.
| Dimension | Réflexion d’un modèle texte | Réflexion d’un modèle d’images |
|---|---|---|
| Forme du résultat de réflexion | Chaîne de raisonnement purement textuelle | Résumé textuel + au maximum deux croquis temporaires de composition |
| Ordre de grandeur des jetons de texte de réflexion | Peut atteindre plusieurs milliers | Pas plus de 400 sur l’offre Pro, environ 700 à 800 sur l’offre Flash high |
| Principal champ de coût | thoughtsTokenCount |
Les croquis sont comptés dans candidatesTokenCount et facturés comme des part image classiques |
| Tarif d’un croquis | Non applicable | Environ 1120 tokens pour une résolution 1K, soit environ 0,0336 $ par image |
Impact de includeThoughts sur la facturation |
Aucun, facturation constante | Aucun, facturation constante |
La documentation officielle insiste sur un point : que includeThoughts soit true ou false, les jetons générés pendant la réflexion sont facturés normalement. Nos tests l’ont confirmé : une fois includeThoughts activé, la structure de retour et le total facturé ne changent pas ; on obtient juste un résumé de réflexion en plus, utile pour le debug. Autrement dit, includeThoughts est un interrupteur “voir ou ne pas voir”, pas un interrupteur “payer ou ne pas payer”. C’est un détail facile à mal interpréter.
Ce qui compte encore plus, c’est que le gros du coût de réflexion d’un modèle d’images ne se trouve pas dans le champ thoughtsTokenCount, mais dans les images temporaires de composition générées pendant l’inférence. D’après la documentation officielle, le modèle peut créer jusqu’à deux images temporaires pendant sa phase de réflexion pour tester la composition et la cohérence logique. Ces croquis sont renvoyés comme des part image ordinaires et comptés dans candidatesTokenCount, donc facturés au tarif standard des images de sortie. En pratique, une génération d’image en mode high peut donc ajouter discrètement une ou deux facturations de croquis “invisibles”, ce qu’on oublie facilement dans une estimation de coût.
Un calcul rapide rend les choses plus parlantes. Imaginons une requête de génération d’image en 1K de résolution avec le mode high : la réflexion textuelle consomme environ 750 tokens. Si le modèle génère effectivement deux croquis temporaires pendant l’inférence, puis l’image finale, on obtient théoriquement trois part image. À raison d’environ 1120 tokens et 0,0336 $ par image, le coût de sortie des trois images approche 0,1 $, auxquels s’ajoute le coût du texte de réflexion. Au total, on peut facilement arriver à une facture 2 à 3 fois supérieure à celle du mode minimal. En réalité, le déclenchement des deux croquis dépend de l’évaluation que fait le modèle de votre invite ; une requête en mode high ne produira pas systématiquement deux croquis. C’est pour ça que, dans les tests, le total de tokens observé tombe souvent dans une plage comme 2243 à 2375, plutôt que de doubler de façon exacte.
💰 Optimisation des coûts : si votre équipe est sensible au coût par token, commencez par vérifier le
totalTokenCountréel dans les journaux d’appel de la plateforme APIYI apiyi.com, puis décidez si vous devez laisser le mode high activé en permanence. Vous éviterez ainsi de dépasser le budget à cause d’une sous-estimation de la facturation des croquis.
Dans quels cas activer high, et quand rester sur le mode minimal par défaut
En s’appuyant sur les tests, voici un guide de décision simple.

| Cas d’usage | Niveau recommandé | Pourquoi |
|---|---|---|
| Génération en masse d’illustrations marketing, sans exigence forte sur la précision de composition | minimal (par défaut) | Latence plus faible, coût en tokens maîtrisé, suffisant pour l’usage quotidien |
| Composition complexe avec plusieurs sujets, ou besoin de respecter précisément une mise en page textuelle ou des relations spatiales | high | La réflexion supplémentaire améliore la précision de composition, et le surcoût vaut la peine |
| Pages produit e-commerce, affiches, et autres cas où la tolérance aux détails est faible | high | Moins de retouches et de régénérations, donc un coût global parfois plus bas |
| Scénarios interactifs en temps réel où la vitesse de réponse est critique | minimal | Le mode high ajoute 5 à 10 secondes de latence, ce qui nuit à l’expérience interactive |
Appel de gemini-3-pro-image |
Aucune configuration nécessaire | Le comportement de réflexion de ce modèle est constant ; passer un paramètre n’a aucun effet |
En résumé, le mode high est surtout adapté aux cas où “obtenir le bon rendu du premier coup” est plus important que “sortir vite l’image”. Si votre application doit souvent réessayer et ajuster l’invite pour obtenir une composition satisfaisante, autant activer directement high : vous payez un peu plus à chaque requête, mais vous augmentez le taux de réussite du premier coup. Au final, c’est souvent plus rentable.
En production, la méthode la plus prudente consiste à rendre thinkingLevel configurable plutôt que de le coder en dur. Par exemple, vous pouvez router automatiquement selon le type de tâche transmis par l’appelant : minimal par défaut pour les traitements en lot, high pour les requêtes qui exigent une mise en page précise ou plusieurs sujets avec des relations spatiales complexes. Vous gardez ainsi le coût moyen sous contrôle sans sacrifier la qualité dans les cas critiques. Si votre équipe maintient en parallèle la logique d’appel pour les modèles flash, flash-lite et pro, il est préférable de centraliser le traitement des paramètres dans une couche d’encapsulation, et de n’envoyer thinkingLevel qu’aux modèles qui le supportent. Cela évite de propager des paramètres inutiles vers pro-image et de compliquer le diagnostic.
🚀 Démarrage rapide : pour prototyper vite, la plateforme APIYI apiyi.com est une bonne option. Avec le même
base_url, vous pouvez basculer entre les réglages minimal et high pour comparer les tests, sans avoir à configurer séparément les informations d’authentification pour chaque niveau.
FAQ
Q1 : Les performances d’inférence de gemini-3.1-flash-lite-image et gemini-3.1-flash-image sont-elles identiques ?
Les deux partagent la même structure de paramètres thinkingConfig, et les niveaux pris en charge sont minimal et high. Mais flash-lite est positionné comme une version légère : en pratique, la profondeur de réflexion et le niveau de détail de l’image finale sont généralement inférieurs à ceux de flash-image. On le voit aussi dans la logique de nommage : dans les modèles texte, la gamme flash-lite a toujours été pensée comme “plus rapide, moins coûteuse, avec une précision légèrement réduite”. La série image reprend exactement ce compromis. Activer le niveau high peut, dans une certaine mesure, compenser les limites d’un modèle léger sur les compositions complexes, mais il est difficile d’atteindre totalement les performances de flash-image. Si vous voulez une comparaison chiffrée, vous pouvez appeler les deux modèles en parallèle sur la plateforme APIYI apiyi.com avec le même ensemble d’invites, puis comparer directement thoughtsTokenCount et le rendu obtenu.
Q2 : Passer le paramètre `thinkingLevel` à gemini-3-pro-image provoque-t-il une erreur ?
Non, il n’y a pas d’erreur. Nos tests montrent qu’après avoir passé high, la requête revient normalement, mais thoughtsTokenCount reste dans la plage 181-214, quasiment identique au cas où aucun paramètre n’est fourni. Cela indique que le comportement de réflexion interne de ce modèle est fixe et qu’il ne peut pas être ajusté de l’extérieur. Lors d’appels groupés sur plusieurs modèles, il est recommandé de tester le nom du modèle dans votre code métier pour éviter de croire à tort que le paramètre a bien pris effet.
Q3 : Faut-il ajuster la résolution ou les paramètres de qualité de l’image après avoir activé le niveau `high` ?
Non. Les données de test montrent que, pour les niveaux minimal et high, les tokens image restent stables à 1120. Cela prouve que thinkingLevel n’agit que sur le processus de raisonnement interne du modèle, sans modifier la résolution de sortie. La résolution est toujours contrôlée séparément par les paramètres de taille dans imageConfig, indépendamment du niveau de réflexion. En d’autres termes, thinkingLevel et les paramètres de résolution sont deux axes de réglage indépendants : l’un sert à savoir si le modèle “réfléchit suffisamment”, l’autre à définir si l’image est “grande et détaillée”. On peut les combiner librement, sans relation d’exclusion ni effet de couplage.
Conclusion
gemini-3.1-flash-lite-image prend bien en charge le mode de réflexion, et cela a été confirmé à la fois par la documentation officielle et par les mesures de l’équipe APIYI. thinkingLevel ne propose que deux niveaux, minimal et high. En mode high, les tokens de réflexion montent au-delà de 700 et le temps total augmente d’environ 5 à 10 secondes, mais cela ne change pas la consommation de tokens de l’image finale. En revanche, même si gemini-3-pro-image accepte ce paramètre sans erreur, il n’a en réalité aucun effet. Comprendre cette logique de double comptage — “le texte de réflexion passe par thoughtsTokenCount, l’esquisse de composition par candidatesTokenCount” — est un levier essentiel pour maîtriser le coût de génération d’images. Si vous devez tester rapidement plusieurs modèles d’images Gemini, le plus simple est de passer par la passerelle unifiée APIYI apiyi.com, afin d’éviter de gérer une clé API et du code d’appel séparés pour chaque modèle.
Les données de cet article proviennent des tests de l’équipe technique d’APIYI. Si vous souhaitez échanger sur les détails d’appel des modèles d’images Gemini, n’hésitez pas à contacter le support technique via APIYI apiyi.com.
Références
- Documentation officielle de l’API Gemini – Génération d’images : description du paramètre de niveau de réflexion (thinking levels)
- Lien :
ai.google.dev/gemini-api/docs/generate-content/image-generation
- Lien :