Le 6 mai 2026, xAI a envoyé un e-mail officiel à tous ses utilisateurs d'API intitulé « Grok 4.3 release and xAI API model retirement ». Ce message contenait deux informations cruciales pour les développeurs : Grok 4.3 est désormais disponible via l'API, tandis que 8 anciens modèles (dont grok-4-fast, grok-4-0709, grok-3, grok-code-fast-1 et grok-imagine-image-pro) seront retirés le 15 mai 2026 à 12h00 PT. Derrière cet e-mail se cache non seulement une mise à jour majeure, mais aussi un compte à rebours de 9 jours pour effectuer la migration.
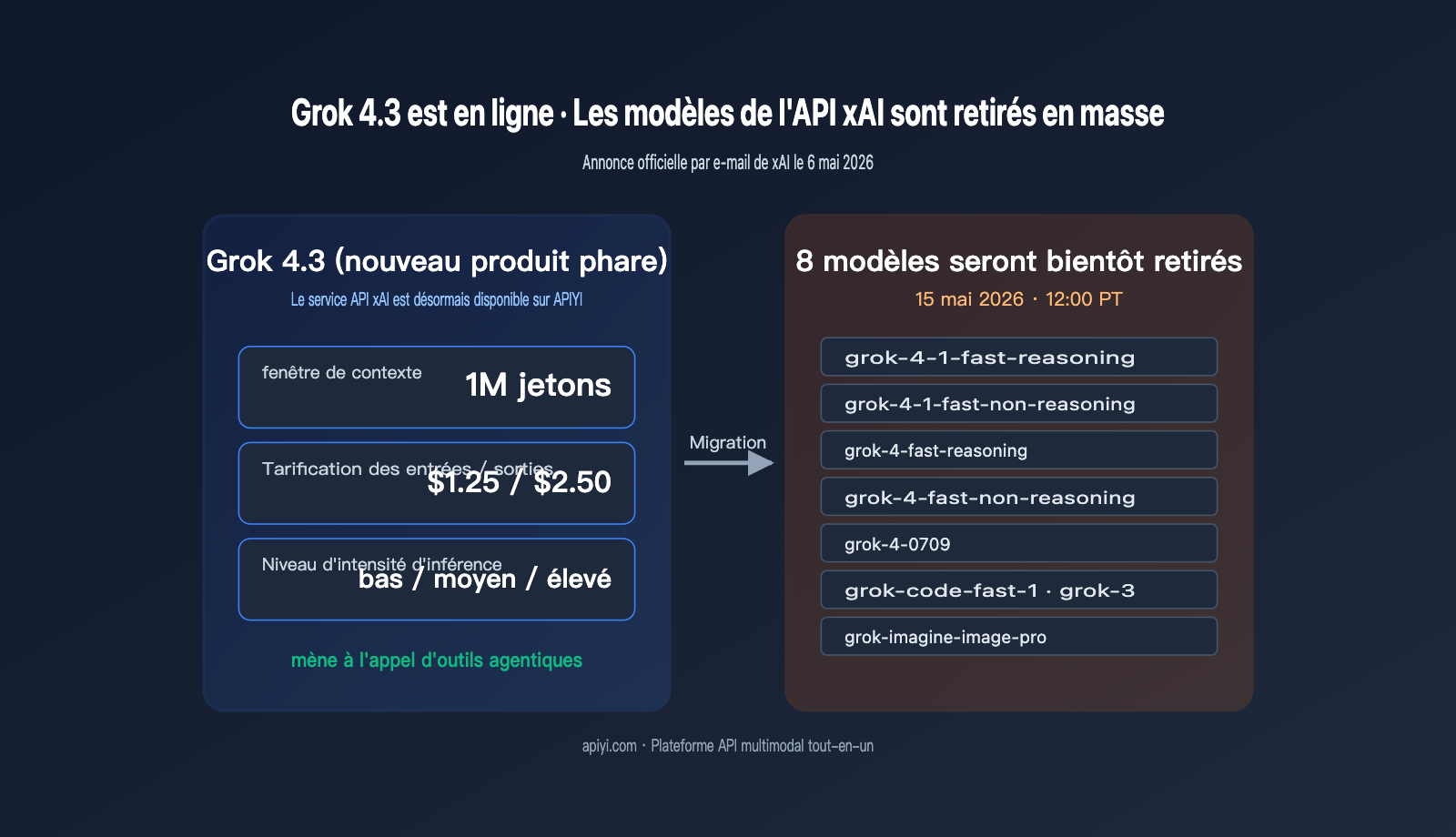
Ce qui mérite le plus l'attention dans cette version de Grok 4.3, ce n'est pas seulement son nom, mais sa fenêtre de contexte de 1M de jetons, sa tarification (1,25 $ / 2,50 $ pour les entrées/sorties) et ses trois niveaux d'intensité de raisonnement ajustables. Cette grille tarifaire place Grok 4.3 en concurrence directe avec les modèles de raisonnement grand public comme Gemini 3.1 Pro et GPT-5.4, tout en conservant l'avantage habituel de xAI en termes de débit de jetons. Nous recommandons aux équipes dépendant de la gamme Grok d'effectuer des tests d'intégration dès que possible via la plateforme APIYI (apiyi.com). Grâce à une interface compatible avec OpenAI, le coût de migration lors du basculement entre plusieurs modèles est réduit au minimum.
Analyse complète des spécifications et de la tarification de Grok 4.3
Grok 4.3 est le modèle phare de nouvelle génération que xAI qualifie dans son e-mail de « modèle le plus rapide et le plus intelligent que nous ayons jamais construit ». Il se classe en tête des classements pour l'appel d'outils par des agents et le suivi d'instructions, se positionnant comme un modèle phare polyvalent couvrant le code, les agents et le raisonnement complexe. En termes de spécifications, Grok 4.3 étend la fenêtre de contexte de 256K (époque Grok 4) à 1M de jetons, au même niveau que Gemini 3 Pro et Claude 4.7, ce qui permet d'intégrer en une seule fois des bases de code complètes ou de longs documents techniques.
Le tableau ci-dessous résume les paramètres clés de Grok 4.3 sur l'API xAI, basés sur l'e-mail officiel de xAI et les tests tiers d'Artificial Analysis.
| Paramètre | Valeur pour Grok 4.3 | Remarques |
|---|---|---|
| Fenêtre de contexte | 1 000 000 jetons | Entrée + sortie partagées |
| Tarif entrée | 1,25 $ / 1M jetons | 50 % moins cher que GPT-5.4, égal à Gemini 3.1 Pro |
| Tarif sortie | 2,50 $ / 1M jetons | Réduction d'environ 83 % par rapport aux 15 $ de l'époque Grok 4 |
| Intensité de raisonnement | 3 niveaux : low / medium / high | Contrôle du budget de raisonnement profond via paramètres |
| Modalités d'entrée | Texte + Image | Prise en charge de la compréhension visuelle |
| Modalités de sortie | Texte | Pas de génération d'image directe |
| Appel d'outils | Appel de fonction natif | Prise en charge de la sortie structurée et des appels parallèles |
| Vitesse de sortie | Env. 207 jetons/s | Testé par Artificial Analysis |
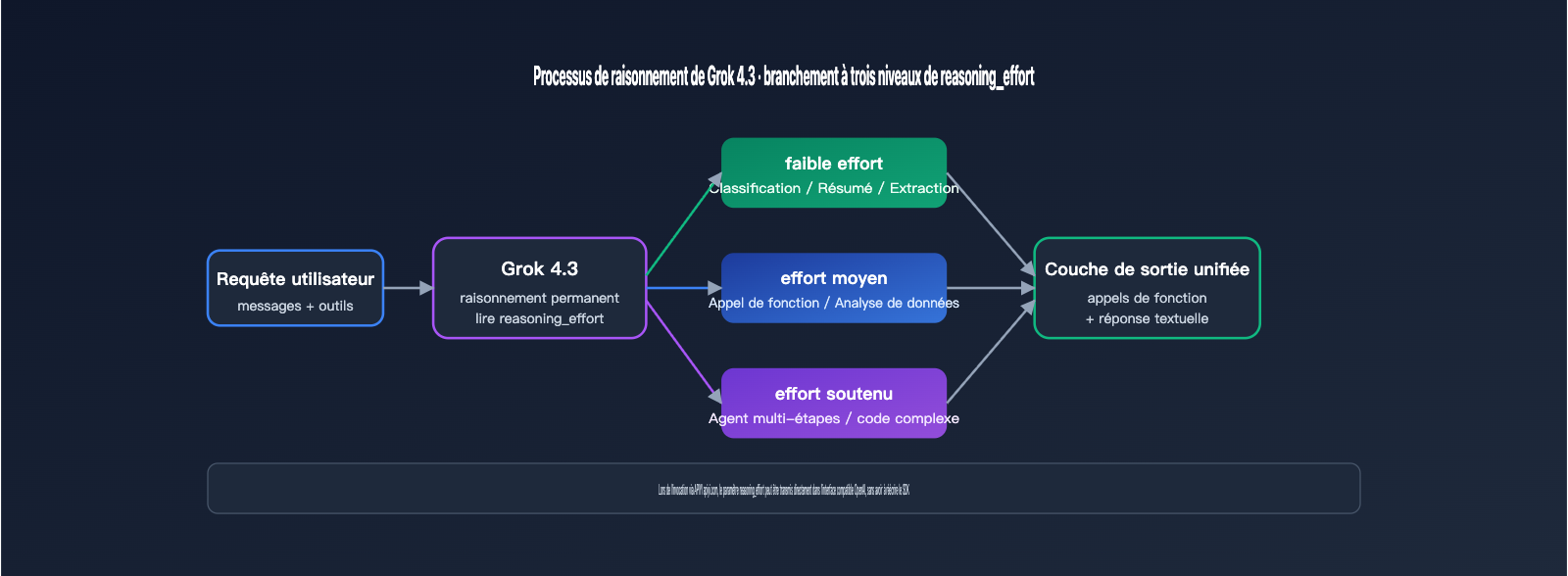
Les 3 niveaux d'intensité de raisonnement (reasoning effort) sont une nouvelle fonctionnalité clé qui distingue Grok 4.3 de la génération précédente. Ils permettent aux développeurs d'ajuster la profondeur de « réflexion » du modèle en fonction de la complexité de la tâche, ce qui influe directement sur la latence et le coût. Ce mécanisme s'inspire de la conception reasoning_effort d'OpenAI, mais xAI a rendu le raisonnement « toujours actif » (always-on), en permettant simplement d'ajuster sa profondeur. Le tableau ci-dessous présente les scénarios d'application typiques et les impacts de ces trois niveaux.
| Intensité | Scénarios typiques | Latence | Impact sur le coût |
|---|---|---|---|
| low | Classification simple, résumé, extraction de règles | Proche des modèles sans raisonnement | Quantité de jetons de sortie minimale |
| medium | Appel de fonction, analyse de données, complétion de code | Équilibre entre latence et qualité | Niveau recommandé par défaut |
| high | Agents multi-étapes, mathématiques complexes, code long | Phase de réflexion plus longue | Augmentation significative des jetons de sortie |
🎯 Conseils d'intégration : Pour les équipes qui hésitent sur le niveau à choisir, nous recommandons d'exécuter un ensemble d'échantillons métier réels sur la plateforme APIYI (apiyi.com) avec le niveau medium, puis de décider s'il est nécessaire de passer au niveau high en fonction de la précision et du retour sur investissement. L'interface unifiée permet de basculer le paramètre
reasoning_effortentre différents modèles en un clic, sans avoir à réécrire le SDK.
Performances de Grok 4.3 sur les classements d'agents et de suivi d'instructions
Si xAI a insisté dans ses e-mails sur le fait que Grok 4.3 « domine les classements en matière d'appel d'outils par des agents et de suivi d'instructions », c'est grâce aux données issues de classements tiers tels qu'Artificial Analysis, τ²-Bench, IFBench et GDPval-AA. L'indice d'intelligence d'Artificial Analysis lui attribue un score global de 53,2, pour un coût total d'évaluation d'environ 395 $, soit une économie d'environ 20 % par rapport à Grok 4.20. Sur τ²-Bench Telecom (qui simule des appels d'outils bidirectionnels pour le service client), le test le plus proche des scénarios réels d'agents, Grok 4.3 a obtenu un score de 98 %, soit une progression de 5 points par rapport à Grok 4.20, se hissant au niveau du GLM-5.1.
Pour les développeurs, le classement GDPval-AA, qui mesure la valeur économique réelle des flux de travail, est encore plus révélateur. Grok 4.3 y atteint 1500 ELO, soit une hausse de 321 points par rapport aux 1179 ELO de la génération précédente (Grok 4.20 0309 v2), dépassant ainsi des modèles comme Gemini 3.1 Pro Preview, Muse Spark, GPT-5.4 mini (xhigh) et Kimi K2.5. En matière de suivi d'instructions, Grok 4.3 maintient un score de 81 % sur IFBench, égalant Grok 4.20 0309 v2.
| Benchmark | Score Grok 4.3 | Comparatif | Capacité évaluée |
|---|---|---|---|
| AA Intelligence Index | 53.2 | Meilleur que 98 % des modèles | Intelligence globale |
| AA Coding Index | 41.0 | Meilleur que 89 % des modèles | Codage et refactorisation |
| τ²-Bench Telecom | 98 % | Égal au GLM-5.1 | Appel d'outils + collaboration |
| IFBench | 81 % | Égal au Grok 4.20 | Suivi d'instructions complexes |
| GDPval-AA | ELO 1500 | Dépasse Gemini 3.1 Pro Preview | Valeur réelle des flux de travail |
Il est important de noter que les points forts de Grok 4.3 résident dans les flux de travail d'agents et l'appel d'outils, plutôt que dans les concours d'algorithmes purs. Pour les applications telles que les agents de code, les agents de navigation ou les bots de service client qui nécessitent une sortie JSON stable et des appels d'outils multi-tours, la fiabilité de Grok 4.3 est nettement supérieure à celle de la génération précédente. Cependant, si le cœur de métier de votre équipe repose sur la synthèse de code pure (type SWE-bench), nous vous recommandons de tester Grok 4.3, Claude 4.7 Opus et GPT-5.4 sur le même jeu de données via la plateforme APIYI (apiyi.com) avant de choisir votre modèle principal en fonction du taux de réussite.
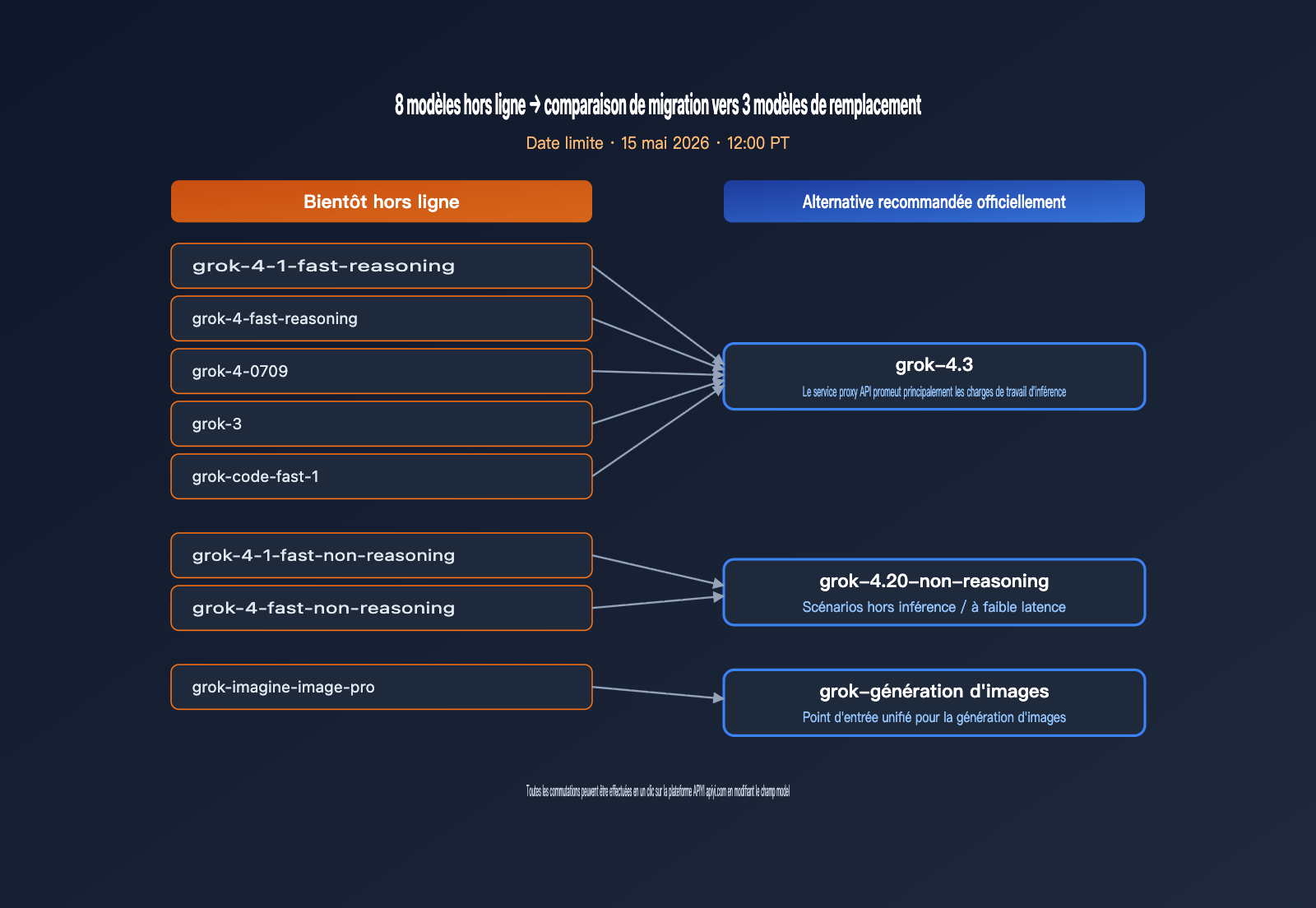
Liste des modèles xAI retirés et conseils de migration
xAI retire simultanément 8 modèles, couvrant le raisonnement textuel, les modèles de code et la génération d'images, ce qui revient à nettoyer l'ensemble de la gamme de l'ère Grok 4. Pour les équipes ayant codé en dur (hard-code) les noms des modèles, il s'agit d'une contrainte impérative nécessitant une mise à jour du code sous 9 jours. Le tableau ci-dessous récapitule les modèles concernés et les alternatives recommandées.
| Modèle retiré | Type | Alternative recommandée | Notes de migration |
|---|---|---|---|
| grok-4-1-fast-reasoning | Raisonnement | grok-4.3 | Meilleure qualité, prix réduit |
| grok-4-1-fast-non-reasoning | Non-raisonnement | grok-4.20-non-reasoning | Maintient la faible latence |
| grok-4-fast-reasoning | Raisonnement | grok-4.3 | Accès à 1M de fenêtre de contexte |
| grok-4-fast-non-reasoning | Non-raisonnement | grok-4.20-non-reasoning | Compatibilité API conservée |
| grok-4-0709 | Raisonnement | grok-4.3 | Retrait des anciennes versions |
| grok-code-fast-1 | Code | grok-4.3 | Unification sur 4.3 |
| grok-3 | Général | grok-4.3 | Fin de l'ère Grok 3 |
| grok-imagine-image-pro | Génération d'images | grok-imagine-image | Simplification de la gamme |
La date de retrait est fixée au 15 mai 2026 à 12h00 PT (soit le 16 mai à 3h00, heure de Pékin). Passé ce délai, toutes les requêtes adressées à ces 8 identifiants de modèles renverront une erreur. Depuis l'envoi de l'e-mail le 6 mai, les développeurs disposent d'une fenêtre de 9 jours, ce qui est très court pour les projets de taille moyenne ou grande. Nous suggérons de diviser la migration en 3 étapes : d'abord localiser tous les identifiants codés en dur, ensuite effectuer des tests de montée en charge sur la plateforme APIYI (apiyi.com), et enfin basculer le champ model via des variables d'environnement plutôt que de modifier la logique métier.
À noter : grok-code-fast-1 était le modèle par défaut pour de nombreux projets d'agents de code au cours des six derniers mois. Son retrait signifie que tous les outils de type Cursor, plugins IDE et agents CLI dépendant de cet identifiant devront migrer vers grok-4.3. Dans les scénarios de code, la stabilité de l'appel d'outils de Grok 4.3 est supérieure à celle de grok-code-fast-1, mais le coût par jeton est légèrement plus élevé, ce qui nécessite une réévaluation de votre budget d'invocation.
Analyse comparative : Grok 4.3, GPT-5.4, Claude 4.7 et Gemini 3.1 Pro
Avec le lancement de Grok 4.3 au deuxième trimestre 2026, le marché des modèles de pointe traverse l'une de ses périodes les plus compétitives. Claude Opus 4.7 maintient une avance avec 87,6 % sur SWE-bench Verified, Gemini 3.1 Pro atteint 94,3 % sur GPQA Diamond, tandis que GPT-5.4 reste la référence en matière de stabilité de raisonnement sur textes longs. Le positionnement de Grok 4.3 repose sur un triptyque : « intelligence équilibrée + prix ultra-compétitif + chaîne d'outils Agent robuste », ciblant principalement les scénarios d'invocation à haute fréquence sensibles aux coûts.
Le tableau ci-dessous compare les données clés de ces quatre modèles phares. Les prix sont exprimés en dollars par million de jetons (tokens).
| Modèle | Prix entrée | Prix sortie | Contexte | Cas d'usage principaux |
|---|---|---|---|---|
| Grok 4.3 | 1,25 $ | 2,50 $ | 1M | Chaîne d'outils Agent, appels fréquents, raisonnement intermédiaire |
| GPT-5.4 | 2,50 $ | 15,00 $ | 400K | Cohérence sur textes longs, planification complexe |
| Claude 4.7 Opus | 15,00 $ | 75,00 $ | 1M | Codage de haut niveau, rédaction, analyse approfondie |
| Gemini 3.1 Pro | 2,00 $ | 12,00 $ | 2M | Multimodal, compréhension vidéo, documents ultra-longs |
Ce tableau met en évidence un fait marquant : le prix des jetons de sortie de Grok 4.3 est 30 fois inférieur à celui de Claude 4.7 Opus et environ 4,8 fois moins cher que celui de Gemini 3.1 Pro. Pour des activités comme les agents de service client à haute fréquence, les linters de code ou le nettoyage de données en masse, l'avantage de coût unitaire de Grok 4.3 est démultiplié. Toutefois, pour des besoins exigeant une qualité de codage extrême ou une compréhension multimodale poussée, Claude 4.7 Opus et Gemini 3.1 Pro restent irremplaçables.
🎯 Conseil de stratégie multi-modèles : Nous recommandons d'utiliser Grok 4.3 pour la couche générale à haute fréquence, Claude 4.7 Opus pour la génération de code complexe et de documents, et Gemini 3.1 Pro pour la couche multimodale. En utilisant l'interface unifiée d'APIYI (apiyi.com) pour la distribution des modèles au niveau de la couche de routage, vous bénéficiez à la fois des économies de Grok 4.3 et de la puissance des modèles spécialisés pour les tâches critiques.
Guide de migration et exemples de code pour Grok 4.3
La migration vers Grok 4.3 est très directe sur le plan technique. xAI propose une interface de chat compatible avec OpenAI ; la majeure partie du travail consiste simplement à modifier les champs base_url et model. Pour les projets utilisant déjà le SDK OpenAI, voici un exemple Python minimaliste pour l'intégration.
from openai import OpenAI
client = OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://vip.apiyi.com/v1",
)
resp = client.chat.completions.create(
model="grok-4.3",
messages=[
{"role": "user", "content": "Expliquez le 'reasoning effort' en une phrase"},
],
extra_body={"reasoning_effort": "medium"},
)
print(resp.choices[0].message.content)
En pointant la base_url vers la plateforme APIYI (apiyi.com), votre application bénéficie d'un point d'entrée unifié pour Grok 4.3, Claude 4.7, GPT-5.4 et Gemini 3.1 Pro. Le changement de modèle se résume ensuite à modifier le paramètre model, sans avoir à réécrire la gestion de l'authentification ou le routage. Cette abstraction permet de réduire considérablement les risques de migration avant la date limite du 15 mai.
Pour la migration des anciens modèles, nous avons préparé un tableau de correspondance minimaliste pour passer aux nouveaux identifiants de modèles :
| Ancien champ model | Nouveau champ model | Autres paramètres requis |
|---|---|---|
| grok-3 | grok-4.3 | Ajout optionnel de reasoning_effort |
| grok-4-0709 | grok-4.3 | Ajout optionnel de reasoning_effort |
| grok-4-fast-reasoning | grok-4.3 | Ajout optionnel de reasoning_effort |
| grok-4-fast-non-reasoning | grok-4.20-non-reasoning | Aucune modification nécessaire |
| grok-code-fast-1 | grok-4.3 | reasoning_effort=high recommandé |
| grok-imagine-image-pro | grok-imagine-image | Point de terminaison API image inchangé |
FAQ sur Grok 4.3
Q1 : Grok 4.3 prend-il vraiment en charge une fenêtre de contexte de 1M ? Les performances se dégradent-elles sur les textes longs ?
Oui, Grok 4.3 propose officiellement une fenêtre de contexte de 1M de jetons via l'API xAI, se plaçant au même niveau que Claude 4.7 Opus. Cependant, comme pour tous les modèles à longue fenêtre de contexte, la compréhension des besoins peut subir une certaine dégradation au-delà de 600K jetons. Nous recommandons de placer les informations clés dans la première moitié de vos documents. Vous pouvez utiliser la plateforme APIYI (apiyi.com) pour effectuer des tests de rappel de recherche sur vos documents métier réels avant de décider si Grok 4.3 doit devenir votre modèle principal pour les textes longs.
Q2 : Comment choisir entre les niveaux d'intensité de raisonnement low / medium / high ?
Utilisez low pour les tâches à faible risque (classification, résumé, extraction de règles), medium pour les activités courantes (service client, invocation de fonctions, analyse de données), et high pour le raisonnement complexe (agents multi-étapes, chaînes de code longues, mathématiques complexes). Le niveau high augmente considérablement le nombre de jetons de sortie et la latence ; nous vous conseillons d'évaluer ce choix en fonction de votre budget et de vos SLA de latence.
Q3 : Après le 15 mai à 12h00 PT, les anciens modèles seront-ils toujours utilisables ?
Non. L'e-mail de xAI indique clairement : « Après le 15 mai 2026, les requêtes vers ces modèles ne fonctionneront plus ». Les requêtes expirées renverront une erreur. Tout code contenant des identifiants de modèles obsolètes en dur (hard-coded) doit être mis à jour avant cette date limite.
Q4 : Comment minimiser les coûts de migration ?
La méthode la plus sûre consiste à abstraire le champ model dans vos variables d'environnement ou vos fichiers de configuration, plutôt que de l'écrire en dur dans votre code. En utilisant l'interface compatible OpenAI d'APIYI (apiyi.com), la migration se résume à une simple modification de configuration et à une série de tests de régression.
Q5 : Grok 4.3 est-il adapté aux agents de codage (Coding Agents) ?
Absolument. Grok 4.3 a obtenu un score de 98 % sur le benchmark τ²-Telecom. Sa stabilité en matière d'invocation d'outils et de conversations multi-tours est supérieure à celle de grok-code-fast-1. De plus, son coût unitaire très bas le rend idéal pour les plugins IDE, les agents CLI et les scripts d'automatisation opérationnelle à haute fréquence.
Résumé : Points clés sur le lancement de Grok 4.3 et la migration vers l'API xAI
L'intérêt majeur de cette version de Grok 4.3 ne réside pas seulement dans sa puissance accrue, mais dans son excellent rapport performance-prix. Avec une tarification de 1,25 $ / 2,50 $, xAI place la fenêtre de contexte de 1M et les capacités d'invocation d'outils pour agents au même niveau tarifaire que Gemini 3.1 Pro, redéfinissant ainsi la référence en matière de rentabilité pour les usages généraux à haute fréquence. Par ailleurs, le retrait de 8 anciens modèles le 15 mai rappelle à toutes les équipes que les identifiants de modèles ne doivent pas être codés en dur, mais abstraits derrière une couche de routage configurable.
Nous recommandons d'utiliser Grok 4.3 comme pilier pour vos appels fréquents et vos chaînes d'outils d'agents. Passez par l'interface unifiée d'APIYI (apiyi.com) pour minimiser les coûts de bascule, tout en conservant la flexibilité de combiner plusieurs modèles comme Claude 4.7 Opus, GPT-5.4 et Gemini 3.1 Pro. Cela vous permettra d'orchestrer dynamiquement vos ressources selon les tâches et d'atteindre un équilibre optimal entre coût et qualité.
Équipe technique APIYI · Suivez nos contenus pratiques sur les API de modèles d'IA et les outils de développement. Pour plus d'articles techniques, visitez apiyi.com