En 2026, le paysage des grands modèles de langage dédiés au code est scindé en deux catégories de produits radicalement différentes : d'un côté, les champions de l'« IDE prioritaire et de la complétion haute fréquence », représentés par Mistral Codestral 2 (version actuelle Codestral 25.08), qui se concentrent sur le Fill-in-the-Middle (FIM), un taux de réussite élevé en complétion et une réponse instantanée sur plus de 80 langages ; de l'autre, les spécialistes de l'« agent longue portée », incarnés par Zhipu GLM-5.1, qui misent sur une architecture MoE de 744B de paramètres et une fenêtre de contexte de 200K pour offrir des capacités de codage complexes de niveau SWE-Bench Pro, capables de gérer des « tâches d'ingénierie autonomes de 8 heures ».
Ces deux approches ciblent des publics et des stratégies de facturation qui ne se recoupent presque jamais, mais elles sont pourtant souvent comparées sur la question : « lequel est le meilleur pour coder ? ». Cet article, basé sur les annonces officielles de Mistral AI (30 juillet 2025, Codestral 25.08) et la documentation développeur de Z.ai (GLM-5.1, publié le 27 mars 2026), ainsi que sur d'autres sources anglophones de première main, vous propose une grille de décision réutilisable structurée autour de 6 dimensions : architecture, benchmarks, contexte, tâches longue portée, déploiement et prix. Vous y trouverez également un comparatif de code pour l'invocation du modèle via API, afin de vous aider à trancher en moins de 10 minutes.

Différences de positionnement entre Codestral 2 et GLM-5.1
Avant d'entrer dans les détails des performances, il faut clarifier un point : ces deux modèles n'appartiennent pas à la même catégorie de produits. Les comparer sur un pied d'égalité mènerait à des conclusions trompeuses.
Positionnement en bref
- Codestral 2 (25.08) : Un grand modèle de langage dédié au code, conçu pour les tâches de complétion et d'édition. Avec son architecture dense de 22B, son objectif d'entraînement FIM natif et l'accent mis sur une « réponse en quelques secondes + un taux d'acceptation élevé », c'est l'un des standards de fait pour les produits de type IDE Copilot.
- GLM-5.1 : Un grand modèle de langage phare à usage général, orienté vers les agents et les tâches de programmation longue portée. Avec son architecture MoE de 744B (environ 40B activés par jeton) et sa fenêtre de contexte de 200K, il a atteint un score de 58,4 sur SWE-Bench Pro, dépassant GPT-5.4, Claude Opus 4.6 et Gemini 3.1 Pro.
Trois questions à se poser avant de choisir
| Question | Pencher pour Codestral 2 | Pencher pour GLM-5.1 |
|---|---|---|
| Usage principal : complétion dans l'IDE ou PR autonome ? | Complétion IDE | Tâches autonomes multi-étapes |
| Volume de jetons par requête : dizaines ou dizaines de milliers ? | Dizaines à milliers | Milliers à dizaines de milliers |
| Tolérance à une attente de plusieurs dizaines de secondes ? | Non | Oui |
🎯 Conseil de sélection : Si 80 % de vos appels concernent la « complétion de la ligne suivante », choisissez Codestral 2 ; si 80 % concernent « aide-moi à corriger ce bug dans le dépôt », optez pour GLM-5.1. Les deux peuvent être testés en parallèle via l'interface unifiée d'APIYI (apiyi.com), sans avoir besoin d'intégrer séparément Mistral et Z.ai.
Les différences d'architecture sont à la base de toutes les performances observées par la suite.
Aperçu des spécifications clés
| Élément | Codestral 2 (25.08) | GLM-5.1 |
|---|---|---|
| Fabricant | Mistral AI | Zhipu AI (Z.ai) |
| Architecture | Dense Transformer | Mixture-of-Experts |
| Paramètres totaux | 22B | 744B |
| Paramètres activés | 22B | Env. 40B (256 experts, 8 activés par token) |
| Fenêtre de contexte | 256K | 200K |
| Sortie maximale | Standard | 128K tokens |
| Mécanisme d'attention | Standard + optimisation FIM | DeepSeek Sparse Attention |
| Licence | Licence commerciale Mistral / MNPL | MIT (poids open source) |
| Date de sortie | 30/07/2025 (dernière itération) | 27/03/2026 |
| Couverture langages code | 80+ langages courants | Multilingue généraliste |
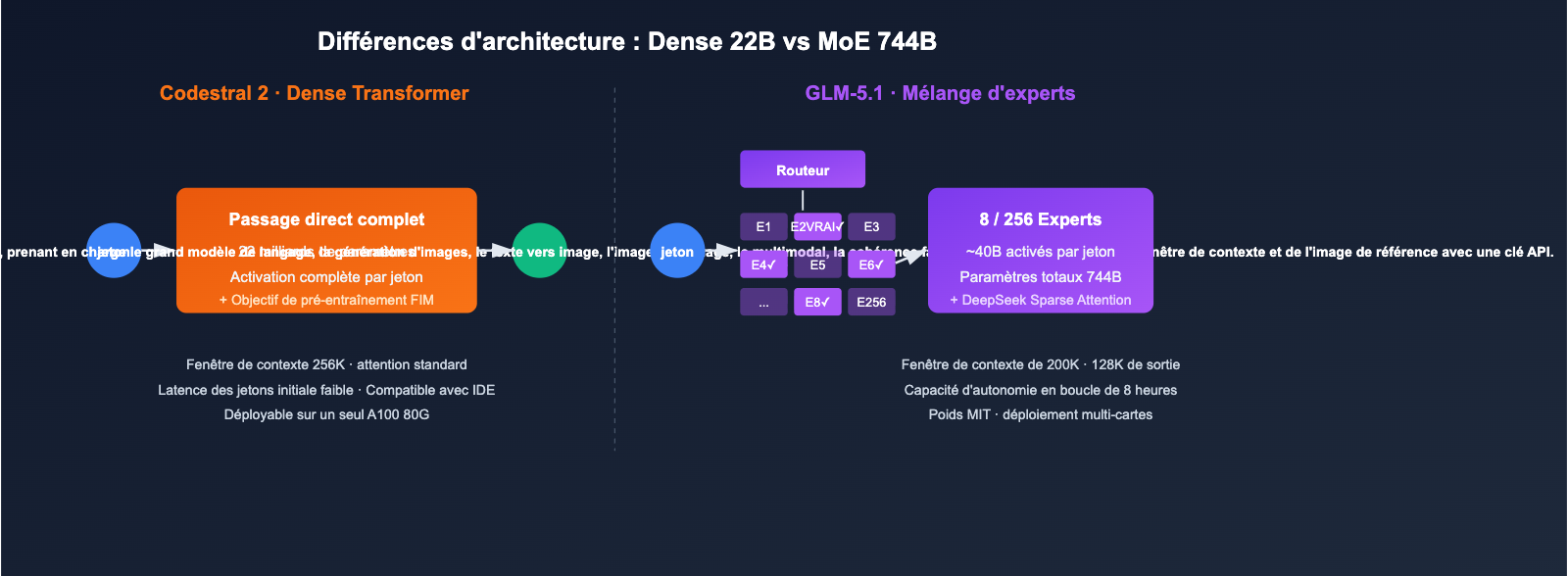
Impact direct des différences d'architecture
- VRAM et coûts de déploiement : Le Codestral 2 (22B) peut être utilisé en inférence sur une seule machine (A100 80G) ; le GLM-5.1 nécessite un parallélisme multi-GPU ou un service d'inférence managé.
- Latence par token : L'architecture dense du Codestral 2 offre une latence plus stable sur les entrées courtes ; le GLM-5.1, en raison du choix du routeur et de l'attention creuse, présente un premier token légèrement plus lent, mais se révèle plus performant sur les séquences longues.
- Stratégie open source : Le GLM-5.1 propose ses poids sous licence MIT, ce qui est plus avantageux pour le déploiement privé et le réentraînement ; bien que le Codestral 2 puisse être exécuté localement, son usage commercial nécessite une licence.
🎯 Conseils de déploiement : Les équipes ayant besoin d'un déploiement entièrement privé privilégieront les poids MIT du GLM-5.1. Celles qui souhaitent une intégration rapide sans gérer l'auto-hébergement peuvent passer par APIYI (apiyi.com) pour invoquer directement les API de ces deux modèles, économisant ainsi les efforts de procurement et de gestion des licences.
Comparaison comparative des codes de base : Codestral 2 vs GLM-5.1
Les scores de ces deux modèles proviennent des tests internes des fabricants, et les jeux de données d'évaluation ne se chevauchent pas totalement. Voici uniquement les indicateurs pertinents pour une comparaison directe.
Les points forts de Codestral 2 : Qualité de complétion & indicateurs IDE
| Indicateur | Valeur | Explication |
|---|---|---|
| Accepted Completions (Taux d'acceptation) | +30% (relatif à 25.01) | Taux d'adoption dans l'IDE en production |
| Retained Code (Taux de rétention) | +10% | Proportion de code suggéré non supprimé lors du commit |
| Runaway Generations (Générations incontrôlées) | -50% | Baisse des suites de code inutiles et trop longues |
| IFEval v8 (Suivi d'instructions) | +5% | Précision des instructions |
| Score moyen MultiPL-E | +5% | Capacité de codage multilingue |
| HumanEval (Données génération précédente 25.01) | 86.6% | Données de référence |
| MBPP (Données génération précédente 25.01) | 91.2% | Données de référence |
Les points forts de GLM-5.1 : Tâches d'ingénierie complexes
| Indicateur | Valeur | Explication |
|---|---|---|
| SWE-Bench Pro | 58.4 | Supérieur à GPT-5.4 / Claude Opus 4.6 / Gemini 3.1 Pro |
| Comparaison Claude Code | 45.3 (Opus 4.6 à 47.9) | Atteint 94,6 % des performances d'Opus 4.6 |
| vs Ligne de base GLM-5 | +28% | Issu de l'optimisation post-entraînement |
| KernelBench Level 3 | Accélération 3.6x | Scénarios d'optimisation de noyau ML |
| Durée continue par tâche | Jusqu'à 8 heures | Boucle autonome "Expérience-Analyse-Optimisation" |
Évaluation du chevauchement des capacités
| Capacité | Codestral 2 | GLM-5.1 |
|---|---|---|
| Complétion fichier unique | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| Refactorisation multi-fichiers | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| Localisation de bugs + PR de correction | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| Traduction inter-langues | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Agent / Utilisation d'outils | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| Latence premier token | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
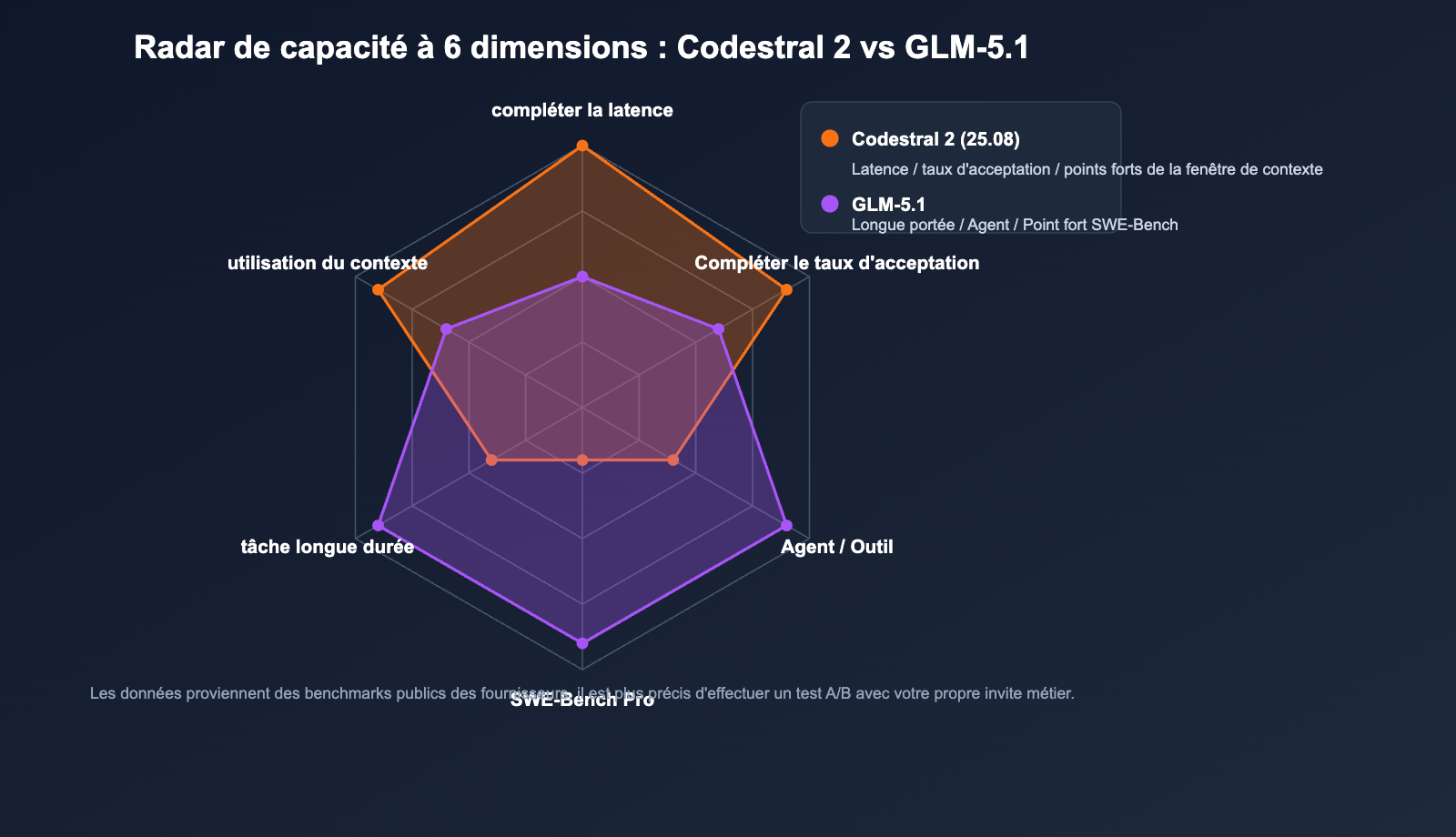
🎯 Conseil de lecture des scores : Les données officielles proviennent généralement de configurations de test optimales ; les performances réelles peuvent varier de 10 % à 20 %. Nous vous recommandons d'effectuer un test A/B avec votre propre base de code sur APIYI (apiyi.com) avant de prendre une décision finale.
Capacités de contexte et de tâches à long terme : Codestral 2 vs GLM-5.1
Les fenêtres de contexte de 256K et 200K sont numériquement proches, mais les types de tâches qu'elles supportent sont totalement différents.
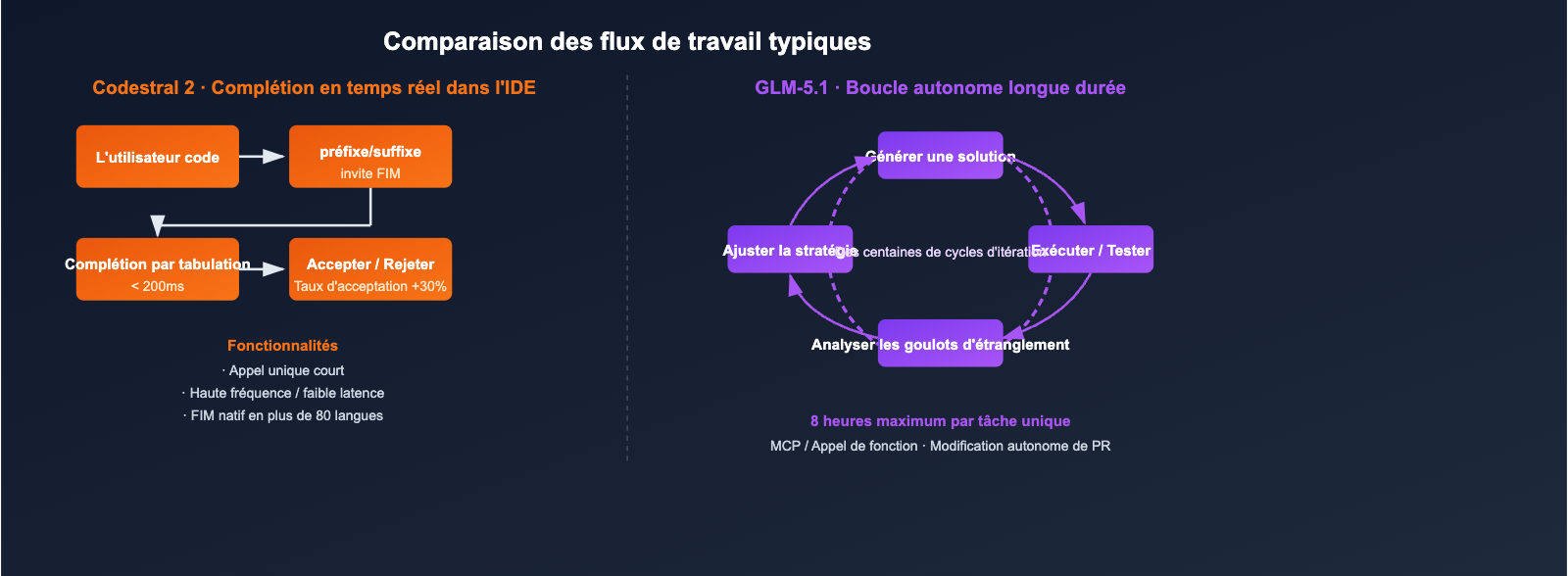
Le contexte 256K de Codestral 2 : Complétion de dépôt complet
Codestral 2 utilise principalement ses 256K de contexte pour "intégrer l'ensemble du dépôt de code dans l'invite", afin de percevoir les dépendances inter-fichiers lors de la complétion :
- Idéal pour : la complétion de grandes fonctions au sein d'un monorepo, les corrections de Lint sur tout le projet, le renommage inter-modules.
- Moins adapté pour : les processus d'agents nécessitant un raisonnement en plusieurs étapes, l'appel d'outils et la réécriture de résultats.
Le contexte 200K + boucle autonome de 8 heures de GLM-5.1
La percée de GLM-5.1 ne réside pas dans "la taille du contexte", mais dans "la durée pendant laquelle il peut travailler en continu" :
- Dans les démonstrations officielles, le modèle peut itérer des centaines de fois au sein d'une seule tâche : exécuter un benchmark → identifier les goulots d'étranglement → ajuster la stratégie → relancer le benchmark.
- L'attention creuse (Sparse Attention) de DeepSeek permet de maintenir les coûts d'inférence des séquences longues de 200K dans une plage utilisable.
- Associé à l'appel de fonction (Function Calling) / MCP, il peut se connecter directement aux chaînes d'outils externes.
Comparaison des tâches à long terme typiques
| Tâche | Codestral 2 | GLM-5.1 |
|---|---|---|
| Compléter une fonction de 200 lignes | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Générer une PR à partir d'un ticket GitHub | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| Trouver et corriger des bugs dans tout le repo | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| Optimisation automatique multi-tours de noyau ML | ⭐ | ⭐⭐⭐⭐⭐ |
| Complétion par Tab dans l'IDE | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
🎯 Conseil de migration de scénario : Pour les équipes qui utilisaient Codestral pour la complétion de dépôts complets et qui rencontrent des cas où "le code est complété mais ne passe pas les tests", essayez de laisser GLM-5.1 prendre en charge la boucle "génération-exécution-correction". Vous pouvez réutiliser le même code compatible OpenAI en changeant simplement le
base_urlsur APIYI (apiyi.com).
Démarrage rapide : Comparaison de l'intégration API pour Codestral 2 et GLM-5.1
Les deux modèles proposent des interfaces compatibles avec OpenAI, les différences réelles se situant principalement au niveau du nom du modèle et des paramètres. L'exemple ci-dessous utilise le base_url unifié d'APIYI (apiyi.com) pour présenter le code minimal requis.
Appel de Codestral 2 (complétion de code)
from openai import OpenAI
client = OpenAI(
base_url="https://api.apiyi.com/v1",
api_key="VOTRE_CLE_API",
)
resp = client.chat.completions.create(
model="codestral-latest", # Pointe vers Codestral 25.08
messages=[
{"role": "system", "content": "Tu es un ingénieur Python senior."},
{"role": "user", "content": "Complète une implémentation de cache LRU haute performance."},
],
temperature=0.2,
max_tokens=512,
)
print(resp.choices[0].message.content)
Appel de GLM-5.1 (tâches longue durée)
from openai import OpenAI
client = OpenAI(
base_url="https://api.apiyi.com/v1",
api_key="VOTRE_CLE_API",
)
resp = client.chat.completions.create(
model="glm-5.1",
messages=[
{"role": "system", "content": "Tu es un agent développeur. Analyse le dépôt, exécute les tests, itère."},
{"role": "user", "content": "Corrige tous les cas de test en échec dans tests/test_api.py du dépôt."},
],
temperature=0.3,
max_tokens=8192,
# GLM-5.1 prend en charge le Function Calling + la sortie structurée
)
print(resp.choices[0].message.content)
📎 Déplier pour voir l’appel spécifique FIM (exclusif à Codestral 2)
# Le FIM natif de Codestral assemble l'invite via prefix / suffix
prefix = "def binary_search(arr, target):\n "
suffix = "\n return -1"
prompt = f"[PREFIX]{prefix}[SUFFIX]{suffix}[MIDDLE]"
# Envoyez simplement le prompt en tant que contenu utilisateur à codestral-latest pour obtenir une complétion de haute précision
🎯 Conseil d'intégration : Les deux modèles respectent le schéma OpenAI, il suffit donc de changer le nom du modèle pour réutiliser la même base de code. L'utilisation du service proxy API d'APIYI (apiyi.com) permet d'économiser les coûts opérationnels liés à la gestion séparée des comptes, des soldes et des politiques de limitation de débit de la console Mistral et de Z.ai.
Stratégies de prix et de déploiement pour Codestral 2 et GLM-5.1
Le prix et la flexibilité de déploiement sont souvent le dernier kilomètre de la prise de décision.
Référence des prix publics
| Modèle | Prix unitaire entrée | Prix unitaire sortie | Remarques |
|---|---|---|---|
| Codestral 2 (25.08) | 0,20 $ / 1M | 0,60 $ / 1M | Suit la tarification de la série Codestral |
| GLM-5.1 | À partir d'env. 3 $ (forfait Coding) | Système de forfait | Option de facturation au jeton également disponible |
Note : Les prix ci-dessus sont basés sur les informations publiques des fabricants et des canaux ; les taux de change et promotions réels dépendent du jour de la consultation.
Comparaison des options de déploiement
| Mode de déploiement | Codestral 2 | GLM-5.1 |
|---|---|---|
| API Cloud officielle | ✅ Console Mistral | ✅ Plateforme Z.ai |
| Passerelle compatible tierce | ✅ (APIYI apiyi.com, etc.) | ✅ (APIYI apiyi.com, etc.) |
| VPC / Cloud privé | ✅ Licence requise | ✅ Déploiement libre MIT |
| Inférence locale sur machine | ✅ A100 unique / GPU grand public limité | ❌ Nécessite plusieurs cartes |
| Function Calling | Supporté (via chat completions) | ✅ Support natif + MCP |
🎯 Conseil d'optimisation des coûts : Pour les scénarios IDE avec une fréquence de complétion élevée et peu de jetons par requête, privilégiez Codestral 2 avec cache. Pour les scénarios d'agents avec une faible fréquence mais un grand nombre de jetons par requête, le système de forfait de GLM-5.1 sera plus rentable. Vous pouvez configurer ces deux stratégies par groupe de modèles sur APIYI (apiyi.com) pour éviter qu'un seul modèle ne consomme tout le solde de votre compte.
Guide de recommandation et pièges à éviter pour Codestral 2 et GLM-5.1
Décisions pour quatre scénarios typiques
| Scénario | Modèle recommandé | Raison clé |
|---|---|---|
| Plugin de complétion VSCode / JetBrains | Codestral 2 | FIM natif + faible latence |
| Correction automatique de bugs / Bot PR | GLM-5.1 | Boucle autonome longue durée |
| Assistant de revue de code (commentaire par fichier) | Codestral 2 | Réponse rapide, coût réduit |
| Agent de bout en bout (test/déploiement) | GLM-5.1 | MCP + Appel de fonction |
| Génération de squelette de projet (boilerplate) | Égalité | N'importe lequel |
| Optimisation des performances ML kernel | GLM-5.1 | Accélération 3,6x KernelBench |
Liste des pièges courants à éviter
- ❌ Ne demandez pas à Codestral 2 de gérer des agents : bien que le taux de génération incontrôlée ait diminué de 50 %, il n'est pas optimisé pour la prise de décision en plusieurs étapes.
- ❌ Ne demandez pas à GLM-5.1 de faire de la complétion à la milliseconde : la latence du premier jeton (Time to First Token) nuit à l'expérience de réponse de la touche Tab dans l'IDE.
- ❌ Ne vous fiez pas à un seul classement : GLM-5.1 gagne sur SWE-Bench Pro, mais la série Codestral n'est pas en reste sur HumanEval.
- ✅ Effectuez un test A/B sur un petit échantillon : utilisez 100 invites typiques de votre activité et comparez les résultats en basculant les paramètres du modèle via APIYI apiyi.com.
FAQ : Questions fréquentes
Q1 : Pourquoi la page officielle indique Codestral 25.08 et non Codestral 2 ?
La convention de nommage de Mistral suit le format <série>-<année>.<mois>. Codestral 25.08 appartient à la deuxième génération d'itération de Codestral (la première génération, 24.05, a été publiée, et la deuxième a évolué de 25.01 à 25.08). L'industrie et la communauté appellent généralement les versions 25.01+ "Codestral 2". Lors de l'invocation du modèle, spécifiez codestral-latest pour obtenir la version la plus récente de la deuxième génération.
Q2 : Les 744B de paramètres de GLM-5.1 ne rendent-ils pas l'inférence très lente ?
Grâce à l'architecture MoE (Mixture of Experts), seuls 40B de paramètres sont activés par jeton. Couplé à l'attention creuse (Sparse Attention) de DeepSeek, la vitesse d'inférence réelle est proche de celle d'un modèle dense de 40B. Avec les stratégies de connexion longue et de mise en cache d'APIYI apiyi.com, la latence perçue dans les scénarios à long contexte reste acceptable.
Q3 : Lequel des deux modèles gère le mieux la fenêtre de contexte ?
Les 256K de Codestral 2 relèvent davantage de la "capacité", tandis que les 200K de GLM-5.1, associés à l'attention creuse, sont plus conviviaux en termes de "taux d'utilisation réel". Avant de lancer des tâches sur l'ensemble d'une base de code, il est conseillé d'estimer le nombre réel de jetons avec tiktoken ou le tokenizer officiel pour éviter les troncatures inutiles.
Q4 : Quelle est la signification réelle des poids open source pour les entreprises ?
GLM-5.1 publie ses poids sous licence MIT, ce qui permet un déploiement sur réseau interne et un réentraînement ; Codestral 2 nécessite un accord de licence pour un usage commercial. Pour les clients du secteur financier ou gouvernemental soumis à des exigences de conformité strictes, la différence est majeure. Si vous cherchez simplement à contourner les restrictions d'accès régionales, APIYI apiyi.com peut également fournir une passerelle stable et disponible localement.
Q5 : Peut-on utiliser les deux modèles simultanément ?
Oui, et c'est même recommandé. L'approche typique consiste à utiliser Codestral 2 pour la complétion dans l'IDE et GLM-5.1 pour l'agent en arrière-plan. Les deux utilisent des clés de modèle différentes, tout en étant centralisés sur la facturation d'APIYI apiyi.com.
Q6 : Les scores sont mesurés par les fabricants eux-mêmes, quelle est leur crédibilité ?
Les scores de Codestral et de GLM sont des auto-évaluations. Le score de 58,4 sur SWE-Bench Pro par Z.ai n'a pas encore été reproduit de manière indépendante. Il est conseillé de considérer les scores publics comme une "limite supérieure de capacité" et d'effectuer impérativement des tests de régression sur vos propres scénarios métier avant toute mise en production.
Résumé : Conseils de sélection finale entre Codestral 2 et GLM-5.1
Revenons aux trois questions posées au début :
- Si votre produit est axé sur Copilot, la complétion de code ou la génération d'extraits de code, choisissez Codestral 2. Ses capacités FIM (Fill-In-the-Middle), sa latence, son prix et sa couverture de plus de 80 langages en font le meilleur compromis pour ce type de scénarios.
- Si votre produit concerne des robots de PR (Pull Request), des agents de correction de bugs ou des agents en arrière-plan effectuant des tâches sur 8 heures, choisissez GLM-5.1. Avec son architecture 744B MoE, son score de 58.4 sur SWE-Bench Pro et ses capacités de cycle autonome longue durée, c'est l'option open-source la plus proche de Claude Opus 4.6 à l'heure actuelle.
- Si votre produit combine ces deux types de scénarios, utiliser les deux modèles en parallèle est la solution la plus économique en 2026.
🎯 Conseil de mise en œuvre : Faites évoluer votre sélection d'un choix "l'un ou l'autre" vers une "orchestration bimodale". Grâce à l'interface compatible OpenAI d'APIYI (apiyi.com), il vous suffit d'utiliser un champ dans votre code métier pour distinguer "complétion courte / tâche longue". Vous pourrez ainsi router automatiquement chaque requête vers le modèle le plus adapté entre Codestral 2 et GLM-5.1.
— Équipe APIYI (L'équipe technique d'APIYI apiyi.com)