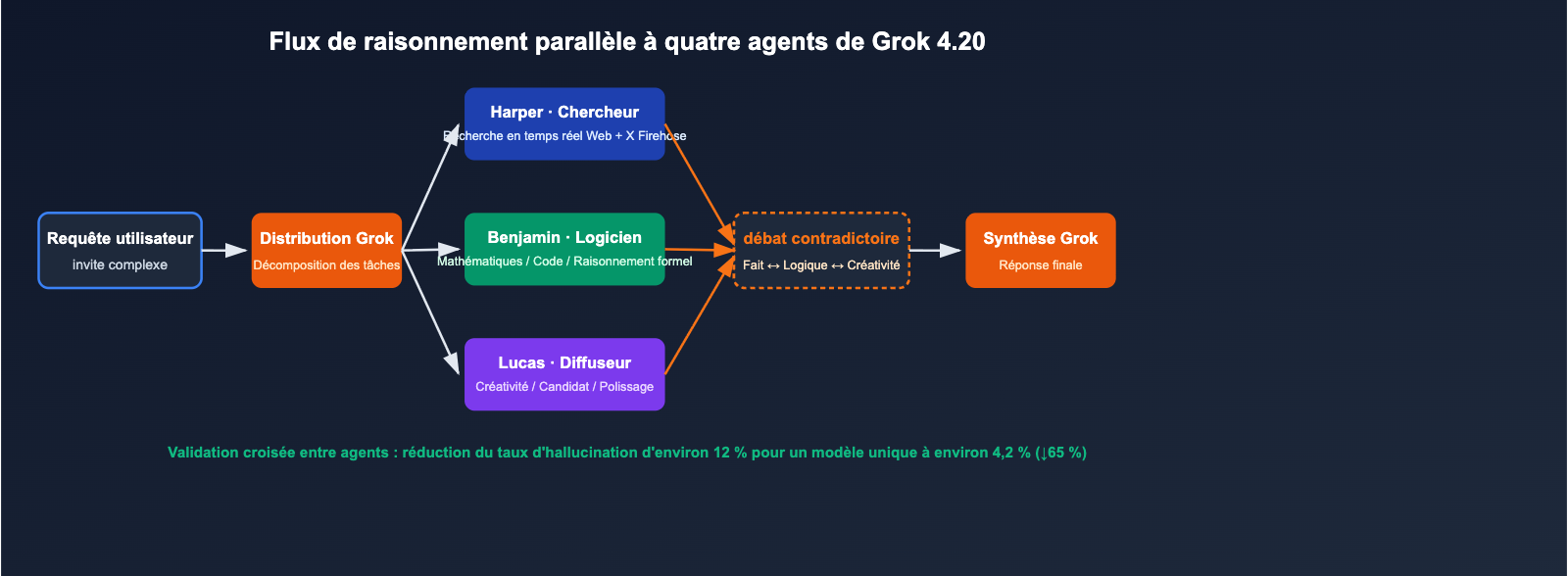
Le 17 février 2026, xAI a officiellement lancé Grok 4.20 Beta. En adoptant une approche peu conventionnelle, le modèle a réussi à surpasser les leaders du marché (Claude et GPT) sur le terrain difficile du « taux de non-hallucination ». Plutôt que de simplement augmenter le nombre de paramètres ou les étapes de raisonnement, xAI a mis en place 4 agents spécialisés (Grok / Harper / Benjamin / Lucas) qui travaillent en parallèle sur chaque requête complexe, débattent entre eux et synthétisent la réponse finale. L'évaluation indépendante par Artificial Analysis Omniscience affiche un taux de non-hallucination de 78 %, tandis que xAI annonce jusqu'à 83 % lors de tests internes, dépassant ainsi Claude Opus 4.6 et GPT-5.4 dans les benchmarks publics. Parallèlement, Grok 4.20 porte sa fenêtre de contexte à 2 millions de jetons, offrant un avantage majeur pour le traitement de documents ultra-longs et les tâches d'agents sur le long terme.
La puissance de calcul sous-jacente évolue également : le supercalculateur Colossus 2 de xAI monte progressivement en puissance pour atteindre le niveau 1,5 GW, préparant ainsi le terrain pour Grok 5 et la mise à l'échelle des systèmes multi-agents. Cet article synthétise les informations de première main sur l'architecture de Grok 4.20, ses performances, son mode « Heavy », son intégration API et ses cas d'usage, pour vous aider à décider en 10 minutes si le passage à ce modèle est pertinent pour vous.

Percée de l'architecture multi-agents de Grok 4.20
Plutôt que de suivre la tendance du « modèle unique plus grand + chaîne de raisonnement plus profonde », Grok 4.20 a choisi la voie de l'intelligence collective (raisonnement de type essaim).
Répartition des rôles des 4 agents
| Rôle | Nom | Responsabilité | Capacité clé |
|---|---|---|---|
| Coordinateur | Grok | Décomposition des tâches, arbitrage des débats, synthèse finale | Orchestration / Arbitre |
| Chercheur | Harper | Recherche Web en temps réel + récupération de données X Firehose | Complétion factuelle, vérification temporelle |
| Logicien | Benjamin | Mathématiques, code, raisonnement structuré et vérification | Vérification de l'exécution de code, raisonnement formel |
| Créatif | Lucas | Sortie créative, extension de solutions, polissage linguistique | Génération de candidats multiples, optimisation des réponses |
Lorsqu'une requête complexe est soumise, Harper récupère le contexte en temps réel, Benjamin effectue simultanément le raisonnement logique et le code, Lucas génère plusieurs groupes de réponses candidates, et enfin, Grok coordonne le débat pour synthétiser la version finale. Ce mécanisme transforme une « inférence directe unique » en « cycles de négociation interne entre quatre rôles spécialisés ».
Pourquoi cela réduit-il les hallucinations ?
Les hallucinations des LLM traditionnels proviennent souvent du fait que le modèle manque d'auto-vérification sur ce qu'il « ignore ». Grok 4.20 forme un mécanisme de vérification factuelle naturelle grâce à la validation croisée entre agents :
- Harper détecte que l'inférence de Benjamin contredit les données Web/X les plus récentes → renvoi ;
- Benjamin détecte que la solution créative de Lucas est mathématiquement invalide → rejet ;
- Grok, en tant que coordinateur, ne produit que des conclusions approuvées par les trois autres parties.
Les données officielles révèlent que ce mécanisme réduit le taux d'hallucination d'un modèle unique (environ 12 %) à environ 4,2 %, soit une diminution de 65 % des hallucinations.
🎯 Conseil pour comprendre l'architecture : Le multi-agents ne signifie pas « 4 exécutions en série d'un modèle unique », mais 4 voies parallèles avec débat au sein d'une seule inférence. Pour les équipes souhaitant expérimenter rapidement la différence, vous pouvez utiliser le service proxy API APIYI (apiyi.com) pour appeler directement Grok 4.20, exécuter le même lot d'invites avec d'autres modèles en parallèle et comparer les écarts de taux d'hallucination.
Indicateurs clés et analyse comparative de Grok 4.20
La valeur des benchmarks dépend énormément des jeux de données utilisés. Voici une distinction entre les auto-évaluations et les tests indépendants.
Aperçu des benchmarks publics
| Indicateur | Grok 4.20 | Claude Opus 4.6 | GPT-5.4 |
|---|---|---|---|
| Artificial Analysis Omniscience (taux de non-hallucination) | 78 % (en tête) | 2e place | 3e place |
| Taux de non-hallucination (auto-test xAI) | env. 83 % | — | — |
| Taux d'hallucination (vs base Grok 4.1) | 4,22 % (↓65 %) | — | — |
| LMArena Thinking Elo | 1483 | — | — |
| Fenêtre de contexte | 2 000 000 tokens | 200K (extensible à 1M) | Niveau 400K |
| Architecture | 4 agents en parallèle (mode Heavy : 16) | Modèle unique | Modèle unique |
Mode Heavy : passage de 4 à 16 agents
En plus de la configuration par défaut à 4 agents, Grok 4.20 propose un mode Heavy : lorsque une profondeur de raisonnement accrue est nécessaire, le nombre d'agents passe à 16, permettant un espace de débat plus large et une vérification croisée des chaînes de preuves à plus haute dimension. Le compromis réside dans une augmentation du coût et de la latence par requête, ce qui le rend idéal pour les scénarios exigeants en précision et insensibles aux coûts (recherche en investissement, audit de conformité, analyse de sécurité, etc.).
Guide rapide des modes et scénarios
| Mode | Nombre d'agents | Scénarios d'utilisation | Caractéristiques |
|---|---|---|---|
| Grok 4.20 mode non-raisonnement | 1 | Chat, Q&A | Faible latence, faible coût |
| Grok 4.20 mode raisonnement | 1 + CoT | Mathématiques, code | Coût modéré |
| Grok 4.20 multi-agents (par défaut) | 4 | Requêtes complexes, vérification des faits | Baisse significative des hallucinations |
| Grok 4.20 Heavy | 16 | Recherche spécialisée, audit de conformité | Précision maximale |
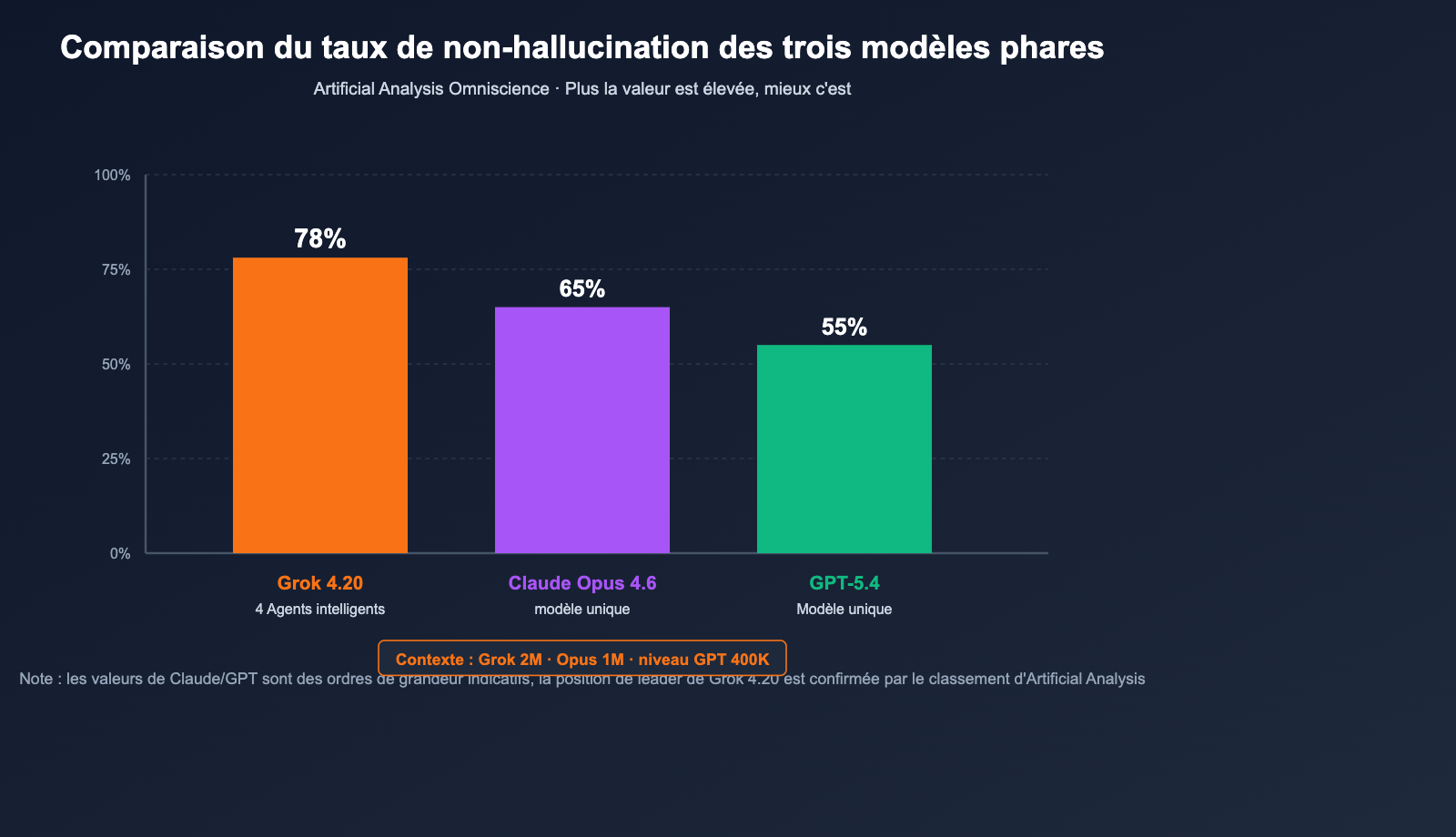
🎯 Conseil de lecture des benchmarks : Il peut y avoir un écart de 5 à 10 points de pourcentage entre les auto-évaluations d'un modèle et les tests tiers. Lors du choix d'un modèle, privilégiez les références indépendantes comme Artificial Analysis. En utilisant APIYI (apiyi.com) pour comparer Grok 4.20 / Opus 4.6 / GPT-5.4 sur une même invite, vous pourrez observer leurs performances réelles dans votre contexte métier.
La fenêtre de contexte de 2M de Grok 4.20 et l'infrastructure Colossus 2
L'innovation architecturale nécessite un support matériel. Deux mises à niveau fondamentales de Grok 4.20 méritent d'être soulignées.
La valeur d'une fenêtre de contexte de 2M de tokens
Grok 4.20 porte sa fenêtre de contexte à 2 000 000 de tokens, ce qui signifie :
- Des documents de la taille d'un livre entier peuvent être insérés dans une invite en une seule fois, sans découpage manuel ;
- Les longues conversations / sessions d'agents conservent un historique complet ;
- Les revues de code multi-fichiers peuvent couvrir des monorepos de taille moyenne ;
- Couplé aux capacités de recherche en temps réel de Harper, cela crée un avantage combiné de "mémoire longue + faits en temps réel".
Le supercalculateur Colossus 2 mis à niveau vers 1,5 GW
Le cluster de supercalculateurs Colossus 2, conçu par xAI pour la série Grok, est en cours de mise à niveau vers une échelle de puissance de 1,5 GW. Cet objectif infrastructurel vise Grok 5 et des groupes d'agents plus vastes. Impact direct pour les développeurs :
- Disponibilité de l'inférence et limites de concurrence plus élevées ;
- Accélération de la vitesse d'itération des nouvelles versions du modèle ;
- Grok 4.20 est déjà capable de supporter le mode Heavy "16 agents × 2M de contexte", la base de calcul correspondante provenant de ce cluster.
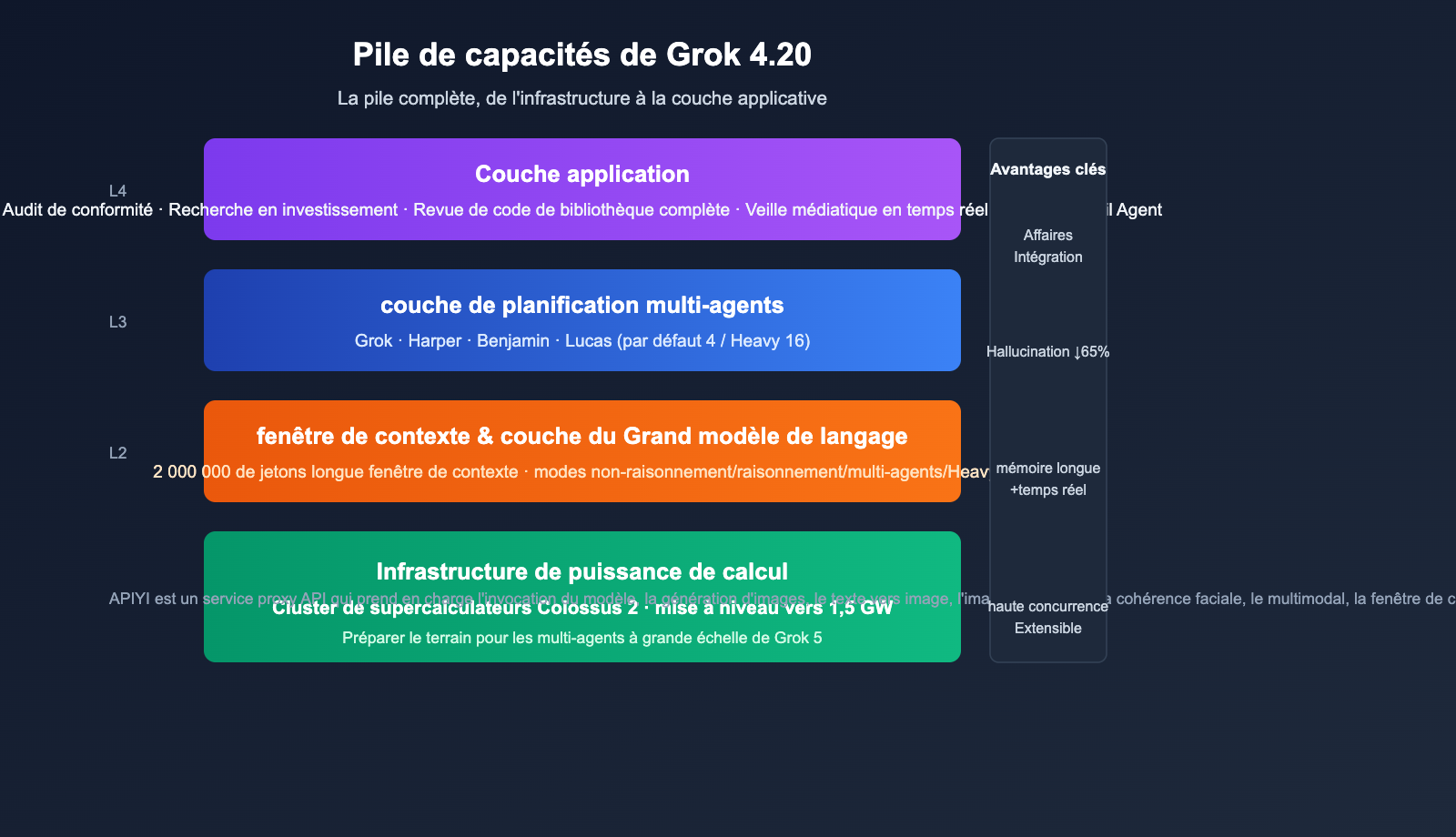
Démarrage rapide : Invocation de l'API Grok 4.20 et intégration via APIYI
Exemple d'invocation de base (compatible OpenAI)
from openai import OpenAI
client = OpenAI(
base_url="https://api.apiyi.com/v1",
api_key="VOTRE_CLE_API",
)
# Mode multi-agents par défaut (4 agents)
resp = client.chat.completions.create(
model="grok-4-20",
messages=[
{"role": "system", "content": "Vous êtes un assistant de recherche factuel."},
{"role": "user", "content": "Résumez les données sur les expéditions mondiales de puces IA au T1 2026 et listez les sources clés."},
],
temperature=0.3,
max_tokens=4096,
)
print(resp.choices[0].message.content)
Appel en mode Heavy (16 agents)
# Le mode Heavy est idéal pour les scénarios exigeant une haute précision,
# bien que la latence et le coût soient plus élevés.
resp = client.chat.completions.create(
model="grok-4-20-heavy",
messages=[
{"role": "user", "content": "Effectuez un résumé des points de risque et une vérification par recoupement de ce document de conformité de 800 pages."},
],
max_tokens=16384,
)
📎 Déplier pour voir l’exemple d’invocation avec une fenêtre de contexte étendue de 2M
# La fenêtre de 2M permet d'analyser un livre entier ou un dépôt complet en une seule fois
with open("large_repo_dump.txt", "r") as f:
repo_text = f.read() # Peut atteindre des millions de jetons
resp = client.chat.completions.create(
model="grok-4-20",
messages=[
{"role": "system", "content": "Vous êtes un réviseur de code senior."},
{"role": "user", "content": f"Voici le code de l'ensemble du dépôt, veuillez identifier les 5 problèmes les plus critiques :\n\n{repo_text}"},
],
max_tokens=8192,
)
Avantages de l'intégration via la plateforme APIYI
L'API de Grok 4.20 est désormais disponible sur APIYI apiyi.com. Les tarifs sont identiques à ceux du site officiel, avec les avantages supplémentaires suivants :
- Promotions sur les recharges allant jusqu'à 15 % de réduction, rendant le coût d'utilisation à long terme inférieur à une connexion directe ;
- Concurrence illimitée, idéal pour exécuter des tâches par lots en mode Heavy ;
- Interface compatible OpenAI, aucune modification de votre code existant n'est nécessaire, il suffit de remplacer les champs
base_urletmodel; - Facturation unifiée avec d'autres modèles comme Claude ou GPT, facilitant les tests A/B entre plusieurs modèles.
🎯 Conseil d'intégration : La consommation de jetons par requête en mode Heavy est nettement plus élevée qu'en mode standard ; l'avantage de la concurrence illimitée est donc particulièrement pertinent ici. Pour les nouvelles équipes, nous recommandons de tester d'abord la logique de base sur APIYI apiyi.com avec un mode hors-inférence, avant de basculer les flux critiques vers le mode multi-agents ou Heavy.
Cas d'utilisation typiques de Grok 4.20
5 types de charges de travail idéales pour Grok 4.20
| Scénario | Mode recommandé | Avantages clés |
|---|---|---|
| Vérification des faits (actualités/rapports) | Multi-agents (par défaut) | Recherche en temps réel Harper + vérification croisée entre agents |
| Recherche en investissement et conformité | Heavy | 16 agents pour réduire le taux d'erreur sur les faits critiques |
| Analyse de documents longs (livres/dépôts) | Multi-agents + 2M | Analyse complète en une seule fois, sans découpage |
| Flux de travail Agent multi-étapes | Multi-agents | Coordinateur intégré, réduit la complexité de l'ingénierie externe |
| Surveillance de l'opinion publique / réseaux sociaux | Multi-agents | Connexion native de Harper au flux X Firehose |
Scénarios non recommandés
- Auto-complétion IDE à la milliseconde : La latence induite par le parallélisme multi-agents n'est pas adaptée aux interactions de type "Tab" ;
- Traitement par lots à très bas coût : Le prix du mode Heavy est élevé ; préférez un mode hors-inférence ou un modèle de type Haiku ;
- Besoin d'un déploiement local strict : Grok 4.20 est actuellement fourni sous forme d'API, sans poids auto-hébergés.
🎯 Conseil de migration : Basculez en priorité les flux "sensibles aux hallucinations" (conformité, santé, recherche financière, etc.) vers le mode multi-agents de Grok 4.20. En utilisant le tableau de bord de facturation d'APIYI apiyi.com pour ventiler les coûts par flux, vous pourrez quantifier le gain métier apporté par la réduction des hallucinations.
FAQ : Questions fréquentes
Q1 : Entre 78 % et 83 % de taux de non-hallucination, lequel est le plus fiable ?
Le chiffre de 78 % provient du jeu de tests indépendant Artificial Analysis Omniscience, qui est actuellement la référence la plus crédible. Le chiffre de 83 % est le résultat des tests internes de xAI sur un ensemble de données plus large. Pour vos choix techniques, nous vous conseillons de privilégier les benchmarks indépendants et d'utiliser les données officielles comme complément. La conclusion commune aux deux est que Grok 4.20 a désormais dépassé Claude Opus 4.6 et GPT-5.4 en matière de réduction des hallucinations.
Q2 : 4 agents signifient-ils 4 appels API ?
Non. La planification multi-agents est effectuée en interne sur les serveurs de xAI ; un seul appel API est exposé à l'utilisateur. La facturation des jetons (tokens) sera plus élevée que pour un mode mono-agent, mais bien inférieure à une solution où vous enchaîneriez vous-même 4 requêtes côté client, avec une latence également plus faible.
Q3 : Quelle est la différence entre le mode Heavy et le mode multi-agents classique ?
Le mode Heavy fait passer le nombre d'agents parallèles de 4 à 16, ce qui améliore encore la précision pour les tâches de raisonnement complexe et les chaînes de preuves longues. Le coût est une augmentation significative du coût par requête et de la latence. Nous recommandons de ne l'activer que dans les scénarios où chaque erreur coûte cher, comme la conformité, la médecine ou la recherche en investissement. Grâce à APIYI (apiyi.com), vous pouvez router vos requêtes vers différents modes pour optimiser l'utilisation de la puissance de calcul en fonction de la valeur ajoutée.
Q4 : Peut-on vraiment utiliser les 2M de fenêtre de contexte ?
Oui. Grok 4.20 annonce une fenêtre de contexte réellement utilisable, et non une limite théorique. Cependant, gardez à l'esprit que plus le contexte est long, plus le coût par jeton et la latence augmentent de manière linéaire. Pour les contextes très larges, nous recommandons de combiner la compression de contexte + la recherche Harper multi-agents.
Q5 : Quelle est la différence entre l'offre d'APIYI et le site officiel ?
Les prix sont identiques à ceux du site officiel, avec des promotions sur les recharges permettant d'obtenir jusqu'à 15 % de réduction. L'avantage majeur est l'absence de limite de concurrence, ce qui est idéal pour les appels en masse en mode Heavy. L'interface reste compatible avec le schéma OpenAI ; au niveau du code, il suffit de pointer base_url vers apiyi.com.
Q6 : Grok 4.20 va-t-il remplacer Grok 5 ?
Non. Grok 5 reste le fer de lance de la prochaine génération de xAI, soutenu par le cluster Colossus 2 1.5GW. Le positionnement de Grok 4.20 ressemble davantage à une étape visant à "valider le paradigme multi-agents sur l'architecture de 4e génération", fournissant une vérification technique pour le déploiement à grande échelle des multi-agents de Grok 5.
Conclusion : Le paradigme multi-agents commence à transformer le paysage des modèles phares
Grok 4.20 n'apporte pas seulement une mise à jour de version, mais un changement dans les dimensions de la concurrence entre modèles phares : on passe d'un "modèle unique plus grand avec une chaîne de raisonnement plus profonde" à une "inférence collective multi-rôles + vérification des preuves en temps réel". Le taux de non-hallucination indépendant de 78 % combiné aux 2M de fenêtre de contexte signifie que les secteurs à haut risque (conformité, recherche en investissement, médecine, droit) disposent pour la première fois d'une solution "prioritaire contre les hallucinations" accessible via une API généraliste.
Pour les développeurs, la première étape n'est pas de remplacer tous les modèles, mais de migrer en priorité les flux de travail les plus critiques vers le mode multi-agents de Grok 4.20, tout en conservant les flux classiques sur des modèles moins coûteux, pour créer une orchestration hybride. La tendance du secteur montre que Grok 5 et le cluster 1.5GW de Colossus 2 continueront d'amplifier cet avantage. Une adoption précoce signifie une accumulation plus rapide d'expérience dans l'invocation multi-agents.
🎯 Conseil d'action : L'API Grok 4.20 est officiellement disponible sur APIYI (apiyi.com). Les prix sont alignés sur le site officiel, avec 15 % de réduction sur les recharges. L'atout clé est l'absence de limite de concurrence, parfait pour les besoins en gros volume, le mode Heavy et les 2M de contexte. Une simple ligne de code compatible OpenAI suffit pour l'intégrer. Migrez dès aujourd'hui vos flux les plus sensibles aux hallucinations.
— APIYI Team (L'équipe technique d'APIYI apiyi.com)