Les développeurs qui utilisent Qwen3.6-Plus connaissent bien ce sentiment : sur OpenRouter, l'erreur 429 Too Many Requests est devenue monnaie courante. Même en ayant un compte crédité, on se retrouve souvent limité au point de remettre en question l'intérêt du service.
Valeur ajoutée : Cet article analyse en profondeur les causes réelles de l'erreur 429 sur Qwen3.6-Plus, propose 3 solutions concrètes et vous explique comment passer par le canal officiel d'Alibaba Cloud pour des invocations de modèle stables et économiques.

Points clés sur l'erreur 429 de Qwen3.6-Plus
| Point | Description | Bénéfice développeur |
|---|---|---|
| Analyse de la cause racine | Demande excédant l'offre + abus du niveau gratuit + stratégie d'allocation | Comprendre le problème pour arrêter les tentatives aveugles |
| 3 solutions | Stratégie de réessai / Changement de canal / Accès direct officiel | Choisir la voie optimale selon le scénario |
| Tests de performance | Comparaison de latence par canal | Choisir la méthode d'accès la plus stable |
| Exemples de code | Python/Node.js prêts à l'emploi | Migration terminée en 5 minutes |
Pourquoi Qwen3.6-Plus est-il si populaire ?
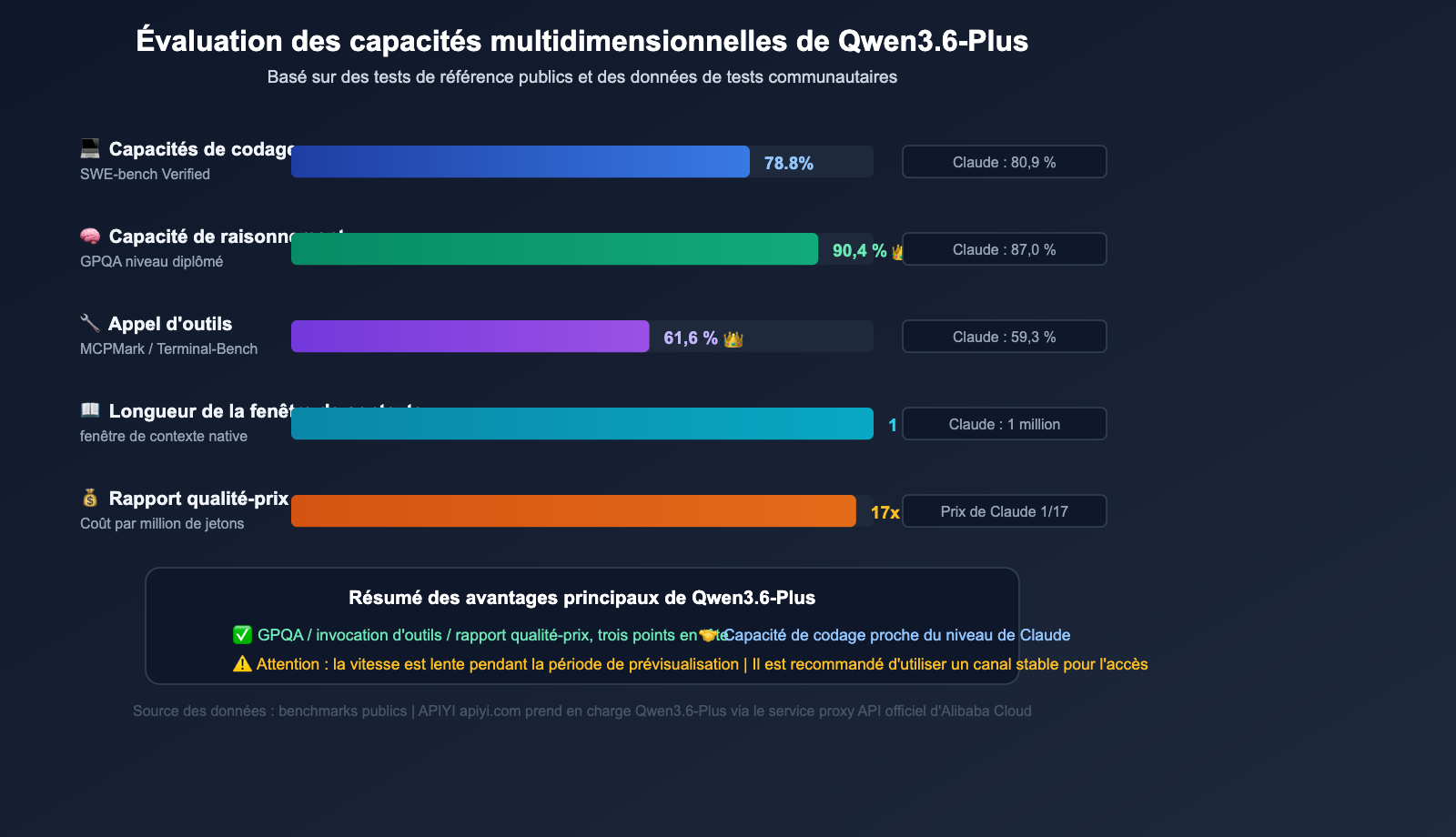
Qwen3.6-Plus est le modèle phare publié par l'équipe Qwen d'Alibaba en avril 2026, positionné directement face à Claude Opus 4.5 et GPT-5.4. Son succès est simple : des performances élevées pour un coût réduit :
| Benchmarks | Qwen3.6-Plus | Claude Opus 4.5 | GPT-5.4 |
|---|---|---|---|
| SWE-bench Verified | 78,8 % | 80,9 % | 76,2 % |
| Terminal-Bench 2.0 | 61,6 % | 59,3 % | 57,8 % |
| GPQA (Niveau recherche) | 90,4 % | 87,0 % | 88,1 % |
| MCPMark (Appel d'outils) | 48,2 % | 45,6 % | 43,9 % |
| Fenêtre de contexte | 1 million de tokens | 1 million de tokens | 256 000 tokens |
| Sortie maximale | 65 536 tokens | 32 000 tokens | 16 384 tokens |
Sur les benchmarks clés comme Terminal-Bench et GPQA, Qwen3.6-Plus surpasse même Claude Opus 4.5, tout en affichant un prix d'API officiel environ 17 fois moins élevé que celui de Claude. Ce rapport performance/prix a fait exploser la demande des développeurs, ce qui est précisément la source des problèmes d'erreur 429.
Analyse approfondie de l'erreur 429 sur Qwen3.6-Plus
Qu'est-ce qu'une erreur 429 ?
Le code d'état HTTP 429 est sans équivoque : Too Many Requests (Trop de requêtes). Il survient lorsque le serveur reçoit, sur une période donnée, un volume de requêtes dépassant sa capacité de traitement ou les limites prédéfinies.
Voici à quoi ressemble une réponse d'erreur 429 typique :
{
"error": {
"code": 429,
"message": "Rate limit exceeded. Please slow down your requests.",
"metadata": {
"provider_name": "Qwen",
"raw": "{\"error\":{\"message\":\"Rate limit reached\",\"type\":\"rate_limit_error\"}}"
}
}
}
Les 4 raisons majeures de la fréquence des erreurs 429 sur Qwen3.6-Plus via OpenRouter
Raison 1 : Une demande qui dépasse largement l'offre
Le rapport performance-prix de Qwen3.6-Plus est exceptionnel. Avec un tarif d'entrée d'environ 0,29 $ par million de jetons en entrée, il coûte 17 fois moins cher que Claude Opus 4.5. Résultat : un afflux massif de développeurs, alors qu'OpenRouter, en tant que service proxy API, dispose d'un quota de puissance de calcul limité auprès d'Alibaba Cloud.
Raison 2 : La saturation par les utilisateurs du niveau gratuit
OpenRouter propose un modèle gratuit qwen/qwen3.6-plus:free, attirant une multitude d'utilisateurs sans frais. Ces requêtes gratuites partagent le même pool de ressources backend que les requêtes payantes, ce qui pénalise directement les utilisateurs ayant souscrit à un abonnement.
Raison 3 : Une allocation de calcul prudente durant la phase de prévisualisation
Qwen3.6-Plus est encore en phase de prévisualisation (lancé le 30 mars, sortie officielle le 2 avril). Durant cette période, Alibaba Cloud adopte généralement une stratégie conservatrice concernant l'allocation de puissance de calcul aux plateformes tierces, privilégiant la qualité de service de ses propres plateformes (DashScope / Bailian).
Raison 4 : Le goulot d'étranglement lié à l'inférence du modèle
Bien que les tests communautaires montrent que le débit de Qwen3.6-Plus est environ 3 fois supérieur à celui de Claude Opus 4.6, son utilisation réelle — avec sa fenêtre de contexte d'un million de jetons et son architecture MoE — génère une latence élevée lors du traitement de tâches complexes par des agents. Chaque requête monopolise donc le GPU plus longtemps, réduisant mécaniquement le nombre total de requêtes traitables par unité de temps.
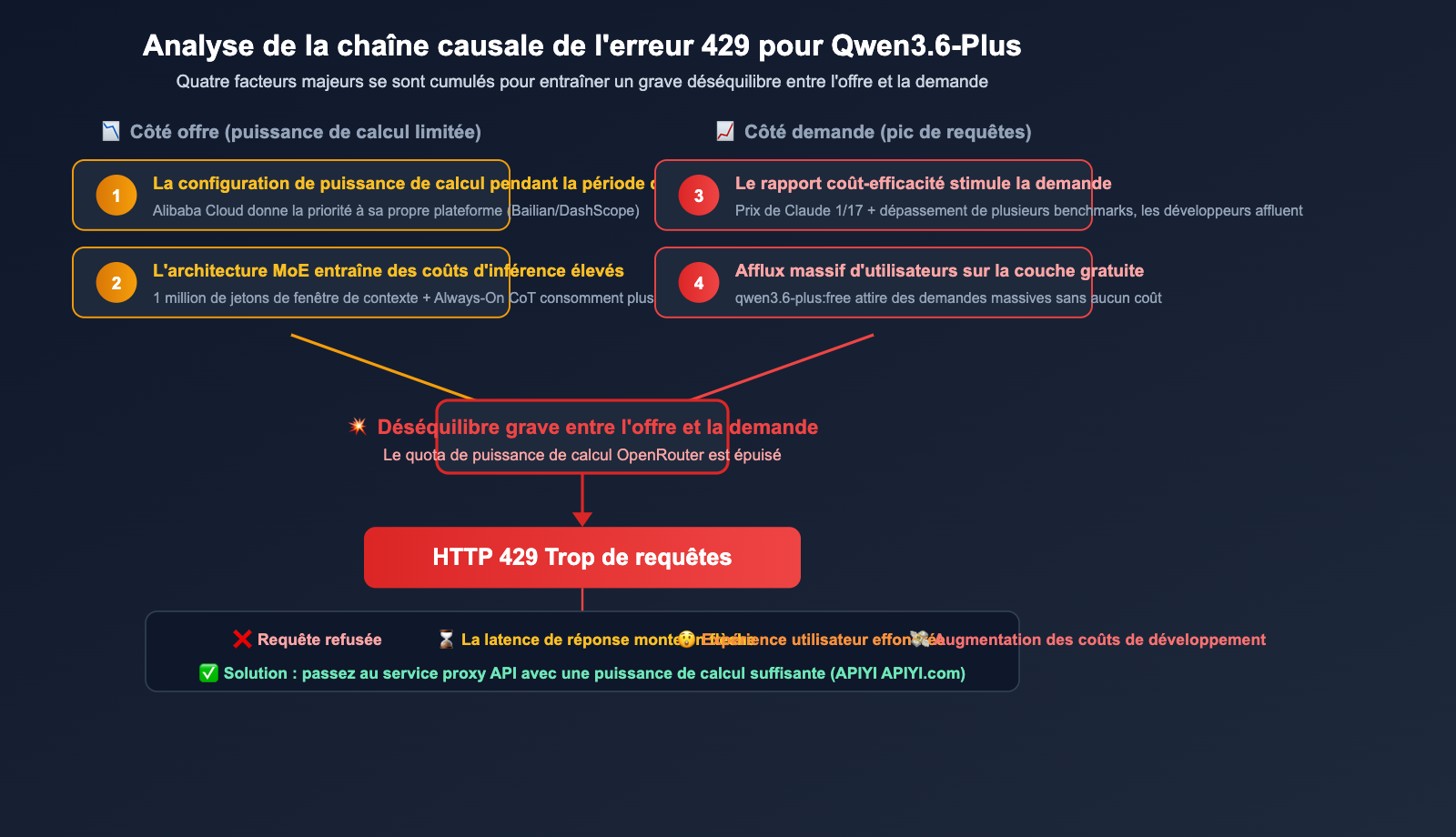
🎯 Insight clé : L'erreur 429 ne signifie pas que votre code est défaillant, mais qu'il y a un déséquilibre entre l'offre et la demande. La solution consiste à changer pour un canal disposant d'une offre suffisante, plutôt que de multiplier les tentatives. En passant par APIYI (apiyi.com) pour accéder au canal direct officiel d'Alibaba Cloud, vous pouvez contourner efficacement les limitations de débit d'OpenRouter.
Solution n°1 à l'erreur 429 sur Qwen3.6-Plus : Stratégie de nouvelle tentative intelligente
Nouvelle tentative avec recul exponentiel
Lorsque vous ne pouvez pas changer de canal immédiatement, une stratégie de nouvelle tentative bien pensée peut atténuer (mais pas résoudre totalement) le problème des erreurs 429 :
import openai
import time
import random
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Interface unifiée APIYI, relais officiel Alibaba Cloud
)
def call_qwen36_with_retry(messages, max_retries=5):
"""Invocation de Qwen3.6-Plus avec recul exponentiel"""
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=messages,
max_tokens=4096
)
return response.choices[0].message.content
except openai.RateLimitError as e:
if attempt == max_retries - 1:
raise
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"Erreur 429 (limite de débit), tentative n°{attempt+1}, attente de {wait_time:.1f}s...")
time.sleep(wait_time)
# Exemple d'utilisation
result = call_qwen36_with_retry([
{"role": "user", "content": "Analyse les goulots d'étranglement de performance de ce code"}
])
print(result)
Suggestions de paramètres pour la stratégie de nouvelle tentative
| Paramètre | Valeur recommandée | Explication |
|---|---|---|
| Nombre max de tentatives | 3-5 fois | Au-delà de 5, le canal est probablement instable |
| Temps d'attente initial | 1-2 secondes | Trop court, c'est inefficace ; trop long, c'est une perte de temps |
| Multiplicateur de recul | 2x | Le recul exponentiel est la norme du secteur |
| Gigue aléatoire | 0-1 seconde | Évite l'effet de "troupeau" (thundering herd) |
| Limite de timeout | 30 secondes | Ne pas dépasser 30 secondes par attente |
Limites de la stratégie de nouvelle tentative
Il est important de noter que : la nouvelle tentative est un antidouleur, pas un remède. Lorsque le backend Qwen3.6-Plus d'OpenRouter est continuellement surchargé, le taux de réussite de cette stratégie chute drastiquement. La solution la plus radicale consiste à basculer vers un canal API disposant d'une capacité suffisante.
Solution n°2 à l'erreur 429 sur Qwen3.6-Plus : Changement de canal API
Pourquoi changer de canal est plus efficace qu'une nouvelle tentative
La fréquence élevée des erreurs 429 sur OpenRouter est due à une insuffisance de quota de calcul pour Qwen3.6-Plus sur ce canal. Passer par un canal directement connecté aux ressources d'Alibaba Cloud permet de résoudre le problème à la racine.
Comparaison des canaux API pour Qwen3.6-Plus
| Canal | Stabilité | Prix (entrée/million de jetons) | Fréquence 429 | Collecte de données |
|---|---|---|---|---|
| OpenRouter Free | Médiocre | Gratuit | Très élevée | Oui (données d'entraînement) |
| OpenRouter Paid | Moyenne | ~$0.29 | Fréquente | Oui (période de prévisualisation) |
| Alibaba Cloud Bailian | Bonne | ¥2.00 | Faible | Selon accord |
| APIYI (Relais Alibaba) | Bonne | -20% officiel | Faible | Non |
💡 Conseil de sélection : Si votre application exige une grande stabilité, nous vous recommandons d'accéder à Qwen3.6-Plus via APIYI (apiyi.com). Cette plateforme utilise le canal de transfert officiel d'Alibaba Cloud, avec des tarifs 20 % inférieurs aux prix officiels (remise de 0,88 sur les groupes + 10 $ offerts pour 100 $ rechargés), tout en évitant les limitations de débit d'OpenRouter.
Migrer d'OpenRouter vers APIYI ne nécessite que 2 lignes de code
Le coût de migration est minime, il suffit de modifier base_url et api_key :
import openai
# ❌ Avant : OpenRouter (erreurs 429 fréquentes)
# client = openai.OpenAI(
# api_key="sk-or-v1-xxxx",
# base_url="https://openrouter.ai/api/v1"
# )
# ✅ Maintenant : APIYI (relais Alibaba, stable sans 429)
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[
{"role": "system", "content": "Tu es un assistant expert en revue de code"},
{"role": "user", "content": "Aide-moi à optimiser les performances de cette requête SQL"}
],
max_tokens=8192
)
print(response.choices[0].message.content)
Version Node.js :
import OpenAI from 'openai';
const client = new OpenAI({
apiKey: 'YOUR_APIYI_KEY',
baseURL: 'https://api.apiyi.com/v1' // Interface unifiée APIYI
});
const response = await client.chat.completions.create({
model: 'qwen3.6-plus',
messages: [
{ role: 'user', content: 'Analyse la complexité temporelle de ce code' }
],
max_tokens: 4096
});
console.log(response.choices[0].message.content);

Qwen3.6-Plus : Solution n°3 aux erreurs 429 – Optimisation des requêtes locales
Réduire les invocations d'API inutiles
Au-delà du changement de canal, l'optimisation de vos modèles de requête peut réduire la probabilité de déclencher une erreur 429 :
1. Fusionner les requêtes
# ❌ Inefficace : envoi ligne par ligne
for item in data_list:
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[{"role": "user", "content": f"Analyse : {item}"}]
)
# ✅ Efficace : traitement par lots
batch_content = "\n".join([f"{i+1}. {item}" for i, item in enumerate(data_list)])
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[{"role": "user", "content": f"Analysez successivement le contenu suivant :\n{batch_content}"}],
max_tokens=16384
)
2. Mettre en cache les réponses fréquentes
import hashlib
import json
_cache = {}
def cached_qwen_call(prompt, model="qwen3.6-plus"):
cache_key = hashlib.md5(f"{model}:{prompt}".encode()).hexdigest()
if cache_key in _cache:
return _cache[cache_key]
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
result = response.choices[0].message.content
_cache[cache_key] = result
return result
3. Limitation du débit de la file d'attente des requêtes
| Stratégie d'optimisation | Effet | Cas d'utilisation |
|---|---|---|
| Fusion de requêtes | Réduction de 60-80% du volume | Traitement de données par lots |
| Mise en cache | Zéro invocation API pour requêtes identiques | Requêtes répétitives |
| Limitation du débit | Lissage des pics de requêtes | Applications à haute concurrence |
| Stratégie de repli | Bascule automatique vers un petit modèle en cas de 429 | Services sensibles à la latence |
🔧 Conseil technique : Ces stratégies d'optimisation locale fonctionnent mieux lorsqu'elles sont associées à des canaux API stables. En accédant à Qwen3.6-Plus via APIYI (apiyi.com) et en combinant la fusion de requêtes avec une stratégie de mise en cache, vous pouvez garantir la stabilité tout en réduisant davantage vos coûts.
Analyse des causes de lenteur du modèle Qwen3.6-Plus
Pourquoi les réponses de Qwen3.6-Plus sont-elles parfois lentes ?
De nombreux développeurs signalent que, même sans erreur 429, la vitesse de réponse de Qwen3.6-Plus est « inexplicablement lente ». Ce n'est pas un cas isolé, et cela s'explique par des raisons techniques :
1. Surcharge d'inférence de l'architecture MoE
Qwen3.6-Plus utilise une architecture d'experts mixtes (MoE). Bien que le MoE réduise considérablement les coûts d'entraînement, les décisions de routage et la commutation d'experts entraînent une surcharge supplémentaire lors de l'inférence. Surtout lors du traitement de longues fenêtres de contexte, l'efficacité d'inférence de l'architecture MoE est inférieure à celle d'un modèle dense à paramètres équivalents.
2. Pression sur la mémoire pour un contexte de 1 million de jetons
La fenêtre de contexte de 1 million de jetons est l'argument de vente principal de Qwen3.6-Plus, mais cela signifie également que le cache KV occupe une quantité massive de mémoire vidéo (VRAM) GPU. Lorsque plusieurs utilisateurs lancent des requêtes à long contexte simultanément, la VRAM du GPU devient un goulot d'étranglement, ralentissant considérablement la vitesse d'inférence.
3. Ressources de calcul limitées en période de prévisualisation
Qwen3.6-Plus est toujours en phase de prévisualisation. À ce stade, Alibaba Cloud n'investit généralement pas la même échelle de puissance de calcul que lors d'un lancement officiel. Il est probable que l'équipe observe les modèles d'utilisation réels avant d'augmenter progressivement la capacité.
4. Consommation supplémentaire de jetons par la chaîne de réflexion (Always-On)
Qwen3.6-Plus a activé par défaut le mode de réflexion "Always-On Chain-of-Thought". Cela signifie que le modèle génère un processus de réflexion interne à chaque réponse, le nombre réel de jetons générés étant bien supérieur à la sortie finale. Ces « jetons cachés » consomment un temps d'inférence supplémentaire.
Référence des tests de latence par canal
| Canal | Latence du premier jeton | Débit (jetons/s) | Remarques |
|---|---|---|---|
| OpenRouter (Pic) | 8-15s | 15-25 | Erreurs 429 fréquentes |
| OpenRouter (Creux) | 3-5s | 30-50 | Période nocturne |
| Alibaba Cloud Bailian | 2-4s | 40-60 | Connexion directe en Chine |
| APIYI (Proxy direct) | 2-5s | 35-55 | Accès stable depuis l'étranger |
💰 Conseil coût : La vitesse de Qwen3.6-Plus varie considérablement selon le canal et la charge. Si vous êtes sensible à la latence, nous vous recommandons d'effectuer des tests réels via APIYI (apiyi.com). La plateforme propose des canaux officiels Alibaba Cloud, vous permettant de bénéficier de remises de 20 % tout en obtenant une vitesse de réponse plus stable.
Prise en main rapide de Qwen3.6-Plus
Exemple complet d'invocation de Qwen3.6-Plus via APIYI
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
# Conversation de base
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[
{"role": "system", "content": "Tu es un expert chevronné en développement Python"},
{"role": "user", "content": "Aide-moi à écrire un framework de scraping asynchrone haute performance"}
],
max_tokens=8192,
temperature=0.7
)
print(response.choices[0].message.content)
Voir le code complet pour la sortie en streaming
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
# Sortie en streaming - idéal pour les scénarios nécessitant un retour en temps réel
stream = client.chat.completions.create(
model="qwen3.6-plus",
messages=[
{"role": "system", "content": "Tu es un architecte logiciel senior"},
{"role": "user", "content": "Conçois un système de file d'attente de messages supportant un million de requêtes simultanées"}
],
max_tokens=16384,
temperature=0.7,
stream=True
)
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="", flush=True)
print() # Saut de ligne
🚀 Démarrage rapide : Nous vous recommandons d'obtenir votre clé API via la plateforme APIYI (apiyi.com) pour invoquer Qwen3.6-Plus. Inscrivez-vous pour tester le service ; pour tout rechargement de 100 USD, recevez 10 USD offerts, et profitez d'une remise de 20 % sur le prix officiel de Qwen3.6-Plus.
Scénarios d'utilisation et conseils de sélection pour Qwen3.6-Plus
Dans quels cas Qwen3.6-Plus est-il particulièrement adapté ?
| Scénario d'application | Raison recommandée | Alternative |
|---|---|---|
| Automatisation par Agent | 61,6 % de performance sur Terminal-Bench, appel d'outils natif | Claude Opus 4.5 |
| Revue/Correction de code | 78,8 % sur SWE-bench, proche du niveau de Claude | Claude Opus 4.5 |
| Raisonnement scientifique | 90,4 % sur GPQA, le meilleur score actuel | GPT-5.4 |
| Traitement de documents longs | Fenêtre de contexte de 1 million de jetons | Gemini 2.5 Pro |
| Projets sensibles aux coûts | Environ 1/17ème du prix de Claude | DeepSeek V3 |
Dans quels cas faut-il être prudent ?
- Applications temps réel ultra-sensibles à la latence : L'architecture MoE de Qwen3.6-Plus entraîne une latence plus élevée avec une longue fenêtre de contexte.
- Chemin critique en production : Les modèles en phase de prévisualisation peuvent subir des changements de comportement imprévisibles.
- Scénarios nécessitant une garantie SLA stricte : Aucun SLA formel n'est disponible durant la phase de prévisualisation.
🎯 Conseil de sélection : Pour les projets nécessitant l'utilisation simultanée de plusieurs modèles, nous recommandons une intégration unifiée via la plateforme APIYI (apiyi.com). La plateforme prend en charge les interfaces compatibles OpenAI pour les modèles phares tels que Qwen3.6-Plus, Claude et GPT. Une seule clé API suffit pour basculer entre différents modèles, facilitant ainsi une gestion flexible selon vos besoins.
FAQ sur les erreurs 429 avec Qwen3.6-Plus
Q1 : Pourquoi ai-je toujours une erreur 429 alors que j’ai payé sur OpenRouter ?
C'est parce que les utilisateurs payants et gratuits d'OpenRouter partagent le même pool de ressources. Même avec un abonnement, si le volume global des requêtes dépasse le quota alloué à OpenRouter par Alibaba Cloud, les utilisateurs payants subissent aussi des limitations. La solution consiste à passer par un canal offrant une meilleure disponibilité, comme l'accès direct via le service proxy API d'APIYI (apiyi.com) qui utilise les canaux officiels d'Alibaba Cloud.
Q2 : L’erreur 429 sur Qwen3.6-Plus va-t-elle s’améliorer ?
Avec l'augmentation de la capacité d'Alibaba Cloud et le passage du modèle en disponibilité générale (GA), le problème des erreurs 429 devrait s'atténuer. Cependant, en tant que plateforme de transit, OpenRouter dépend toujours de l'offre en amont. Si la stabilité est critique pour vos projets, nous vous recommandons d'utiliser un canal connecté directement aux ressources d'Alibaba Cloud plutôt que de dépendre d'une plateforme intermédiaire.
Q3 : Quelle est la différence entre le Qwen3.6-Plus d’APIYI et celui d’OpenRouter ?
La différence majeure réside dans la source de la puissance de calcul. La plateforme APIYI (apiyi.com) utilise le canal officiel d'Alibaba Cloud, ce qui signifie que la puissance provient directement de la plateforme Bailian et non d'un intermédiaire. Cela se traduit par un taux d'erreur 429 beaucoup plus faible et une réactivité plus stable. Côté tarif, APIYI propose une remise officielle de 20 % (remise de groupe de 0,88 + bonus de recharge) et une compatibilité totale avec l'interface SDK d'OpenAI, rendant la migration quasi instantanée.
Q4 : Est-il normal que Qwen3.6-Plus soit lent ?
L'architecture MoE de Qwen3.6-Plus et sa fenêtre de contexte d'un million de jetons demandent effectivement plus de ressources lors de l'inférence qu'un modèle dense. Comme la configuration actuelle est encore en phase de prévisualisation, une certaine lenteur est un phénomène courant. Toutefois, son débit global reste impressionnant ; nous vous conseillons d'utiliser la sortie en flux continu (stream=True) pour améliorer l'expérience utilisateur.
Q5 : Comment utiliser Qwen3.6-Plus dans Claude Code ?
Qwen3.6-Plus est compatible à la fois avec les protocoles Anthropic et OpenAI. Vous pouvez l'utiliser en modifiant la configuration du point de terminaison API de Claude Code. Si vous passez par la plateforme APIYI (apiyi.com), utilisez simplement le format standard du SDK OpenAI ; vous trouverez les détails de configuration dans la documentation de la plateforme.
Résumé des solutions à l'erreur 429 sur Qwen3.6-Plus
Le problème 429 rencontré avec Qwen3.6-Plus est essentiellement un problème de déséquilibre entre l'offre et la demande : le modèle est très performant, son prix est attractif et la demande est massive, ce qui fait que les quotas de calcul d'OpenRouter ne suffisent plus à satisfaire tous les utilisateurs.
Voici trois solutions adaptées à différents scénarios :
- Réessai intelligent : Solution temporaire, adaptée aux scénarios d'invocation à faible fréquence.
- Optimisation locale : Réduction du volume de requêtes, adaptée à tous les scénarios.
- Changement de canal : Solution radicale, adaptée aux projets exigeant une grande stabilité.
Pour les développeurs ayant besoin d'une invocation stable de Qwen3.6-Plus, nous recommandons de passer par la plateforme APIYI (apiyi.com) pour accéder au canal officiel d'Alibaba Cloud. Profitez d'une remise de 20 % sur les tarifs officiels tout en disant adieu aux limitations de débit 429, permettant ainsi à votre application de se concentrer sur la logique métier plutôt que sur la gestion des erreurs.
📝 Auteur : APIYI Team | Pour plus de tutoriels sur l'intégration d'API de modèles d'IA et des guides pour éviter les pièges, visitez le centre d'aide APIYI : help.apiyi.com