Note de l'auteur : Sans changer de modèle pour des alternatives bas de gamme, voici une analyse détaillée sur la façon dont OpenClaw réduit les coûts en contrôlant la longueur des jetons (tokens) en entrée : isolation des nouvelles conversations, récupération précise de blocs de code au lieu d'un envoi complet, élagage du contexte, recherche locale QMD, et 2 autres stratégies clés.
OpenClaw est réputé pour sa consommation élevée de jetons : certains utilisateurs atteignent 21,5 millions de jetons par jour, avec des factures mensuelles dépassant les 600 $. Le premier réflexe est souvent de passer à des modèles moins chers, mais cela se fait au détriment de la qualité. La véritable méthode pour économiser des jetons consiste à contrôler l'entrée : la quantité de contexte que vous fournissez au modèle est le facteur déterminant du coût. Cet article se concentre sur une question centrale : comment passer d'une approche "tout envoyer" à une alimentation "précise et ciblée", sans changer de modèle ni sacrifier la qualité.
Valeur ajoutée : Après avoir lu cet article, vous maîtriserez 6 stratégies pratiques pour contrôler les jetons en entrée, avec une économie attendue de 50 à 90 % sur vos coûts de jetons.
Points clés pour économiser des jetons avec OpenClaw
Commençons par une précision importante : cet article traite des méthodes pour économiser des jetons sans changer de modèle et sans sacrifier la qualité. Vous utilisez toujours Claude Opus 3.5 ou GPT-4o, le modèle reste identique, ce sont les données d'entrée que nous optimisons.
| Stratégie | Taux d'économie | Difficulté | Concept clé |
|---|---|---|---|
| Nouvelle session par tâche | 60-80% | Faible | Ouvrir une nouvelle session pour chaque tâche isolée afin d'éviter l'accumulation de l'historique |
| Récupération précise de code | 40-95% | Moyenne | Ne fournir que les extraits de code pertinents, pas le fichier complet |
| Élagage du contexte | 30-50% | Faible | Nettoyer manuellement ou automatiquement l'historique de discussion inutile |
| Recherche locale QMD | 80-90% | Moyenne | Recherche vectorielle locale, n'envoyer que les fragments pertinents |
| Mise en cache des invites | 80-90% (coût entrée) | Faible | Utiliser le cache pour éviter de renvoyer systématiquement les invites système |
| Désactivation du mode Thinking | 10-50x | Faible | Désactiver le mode réflexion pour les tâches non liées au raisonnement |
Mécanisme sous-jacent de la consommation de jetons dans OpenClaw
Pour économiser des jetons, il faut d'abord comprendre pourquoi OpenClaw en consomme autant.
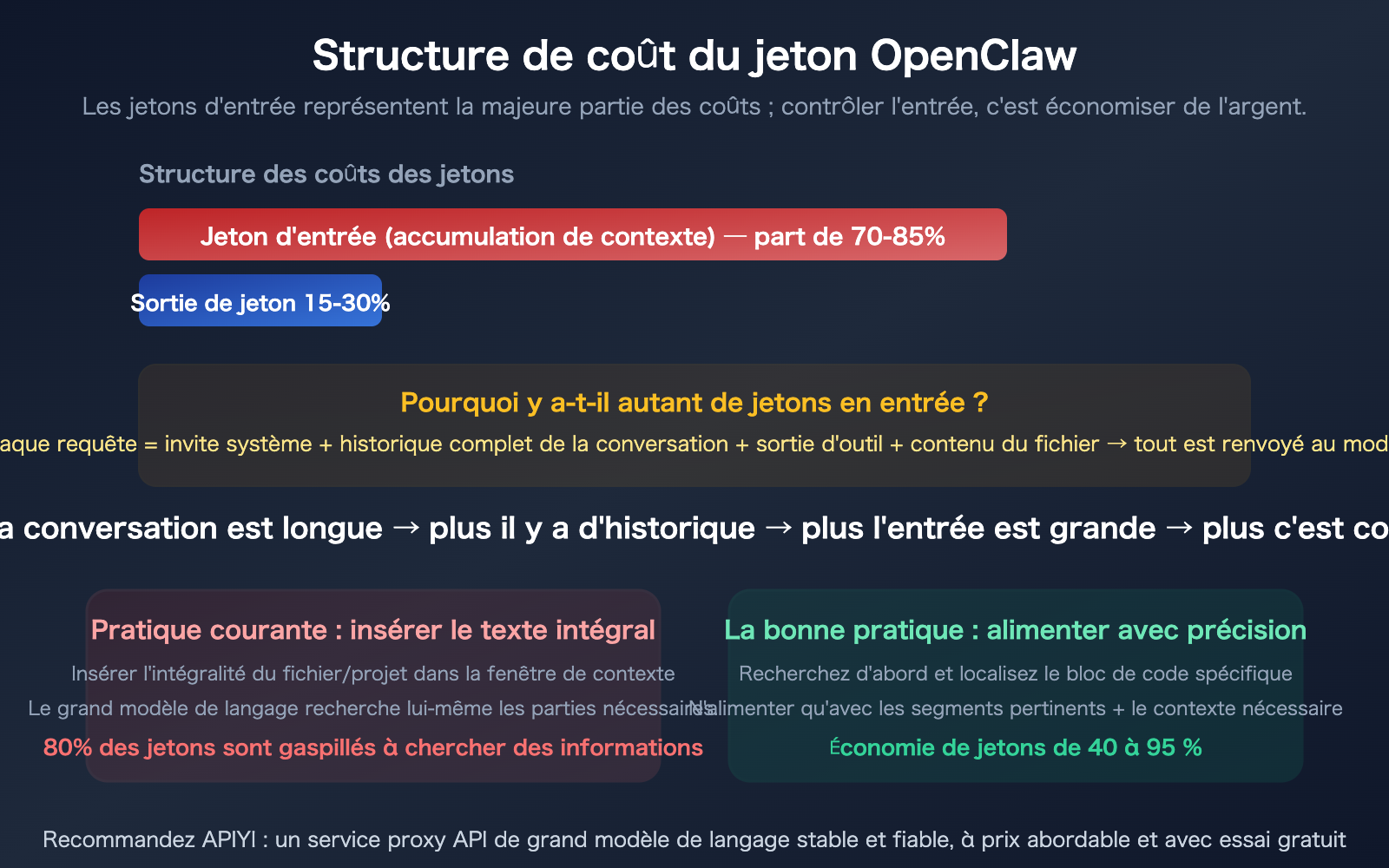
Chaque fois que vous envoyez un message dans OpenClaw, il ne transmet pas seulement votre dernière entrée, mais l'intégralité de l'historique de la conversation au modèle. Plus la conversation est longue, plus le nombre de jetons d'entrée par requête augmente.
Concrètement, une requête inclut :
- Invite système (System Prompt) : Les instructions fondamentales d'OpenClaw, généralement entre 2000 et 5000 jetons.
- AGENTS.md / SOUL.md : Fichiers de configuration de l'espace de travail.
- Compétences chargées : Chaque compétence activée consomme des jetons.
- Historique complet de la conversation : Tous les messages depuis le début de la session.
- Résultats d'invocation du modèle : Sorties de chaque lecture de fichier ou exécution de commande.
- Résultats de recherche en mémoire : Contenu pertinent récupéré depuis la base de connaissances.
Dans une session OpenClaw de 30 minutes, les jetons d'entrée du dernier message peuvent atteindre 100 000, voire 1 million, alors que la majeure partie des 29 premières minutes n'est plus utile pour la tâche en cours.
Stratégie 1 : Ouvrir une nouvelle session pour chaque tâche dans OpenClaw
C'est la stratégie la plus simple et la plus efficace.
Pourquoi une nouvelle session permet-elle d'économiser des jetons ?
Imaginons que vous effectuiez 3 tâches dans la même session : corriger le bug A → écrire la fonctionnalité B → refactoriser le module C. Lors de la troisième tâche, l'entrée du modèle contient tout l'historique et les lectures de fichiers des deux premières tâches, alors qu'ils sont totalement inutiles pour la refactorisation du module C.
Même session :
Historique tâche A (20K jetons)
+ Contenu fichier tâche A (30K jetons)
+ Historique tâche B (25K jetons)
+ Contenu fichier tâche B (40K jetons)
+ Message actuel tâche C (5K jetons)
= 120K jetons en entrée (dont 115K sont du poids mort historique)
Nouvelle session :
Message actuel tâche C (5K jetons)
+ Invite système (3K jetons)
= 8K jetons en entrée (économie de 93%)
Bonnes pratiques pour vos sessions
| Scénario | Nouvelle session ? | Raison |
|---|---|---|
| Passage à une tâche totalement différente | Oui | Le contexte précédent est inutile |
| Itérations sur une même fonctionnalité | Non | Besoin du contexte des discussions précédentes |
| Correction de bugs différents dans des fichiers différents | Oui | Chaque bug est indépendant, pas besoin de contexte croisé |
| Modifications continues d'un même module | Non | Le modèle doit comprendre l'intention des modifications précédentes |
| Plus de 20 échanges dans la conversation | Oui ou compact | L'accumulation historique est devenue trop lourde |
🎯 Conseil pratique : Un critère simple : si vous devez dire "oublie ce qu'on a fait avant, on passe à autre chose", ouvrez directement une nouvelle session.
Ce principe ne s'applique pas seulement à OpenClaw, mais aussi à Claude Code et aux autres outils de développement assistés par IA. Chaque requête API indépendante effectuée via APIYI (apiyi.com) constitue naturellement une "nouvelle session", éliminant tout problème d'accumulation de contexte.
Stratégie 2 : Recherche précise de blocs de code avec OpenClaw, sans tout envoyer
C'est le point central de cet article : comment faire en sorte que le modèle ne voie que les blocs de code à modifier, au lieu d'y injecter tout le fichier, voire tout le projet ?
L'essence du problème : pourquoi "tout envoyer" est un gaspillage
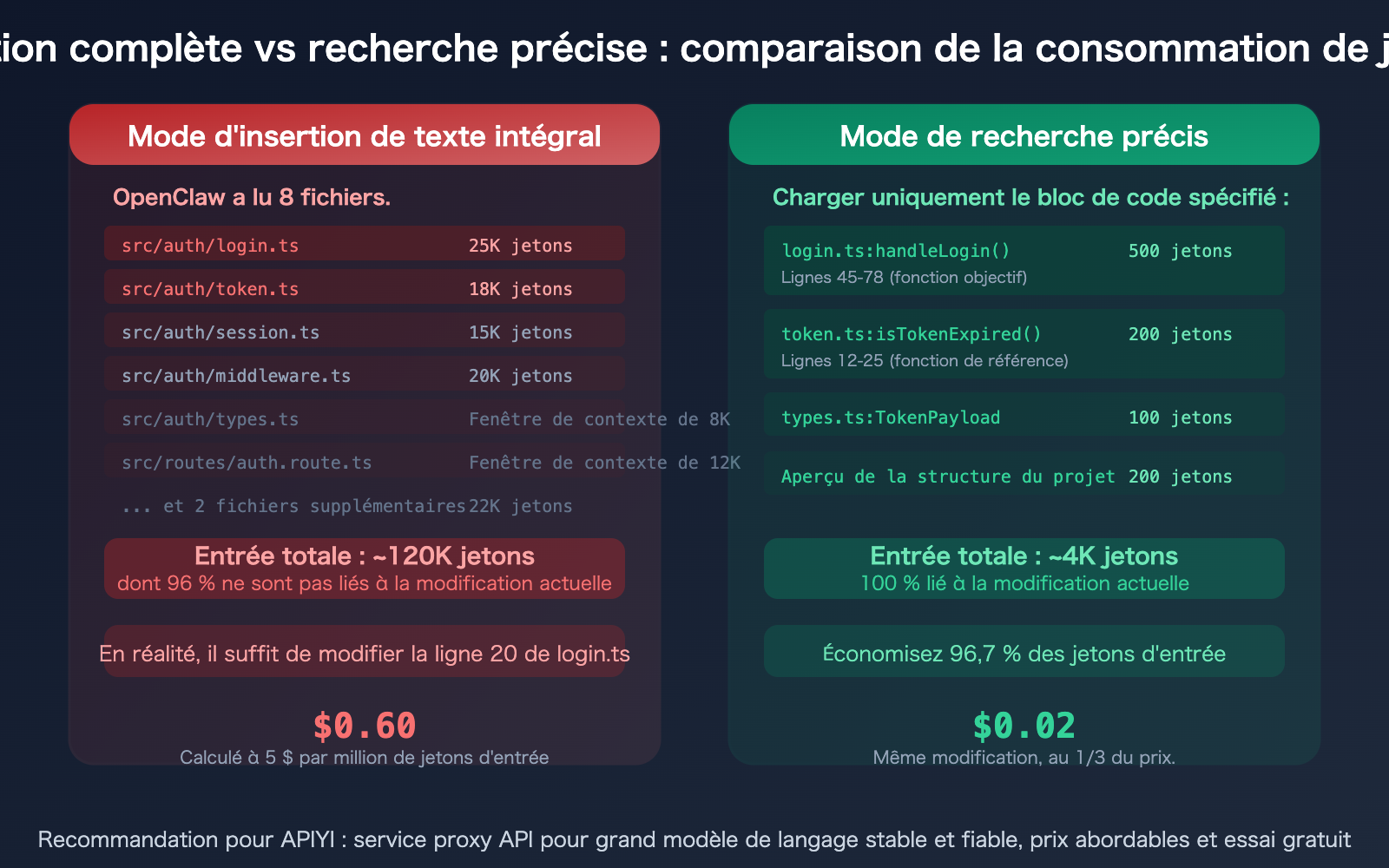
Les études montrent que les agents de codage IA gaspillent 80 % de leurs jetons (tokens) à "chercher des informations". Scénario typique : vous demandez à OpenClaw de modifier une fonction, il lit 25 fichiers juste pour trouver les 3 fonctions réellement pertinentes — et le coût en jetons de la lecture de ces 25 fichiers est entièrement à votre charge.
Un fichier de 1 000 lignes représente environ 15 000 à 25 000 jetons. Si vous n'avez besoin de modifier que 20 lignes (environ 300 à 500 jetons), mais que le fichier entier est transmis au modèle, alors 96 à 98 % des jetons d'entrée sont gaspillés.
4 méthodes pour une recherche précise de blocs de code avec OpenClaw
Méthode 1 : Spécifier explicitement le fichier et les numéros de ligne
Ne dites pas "modifie la fonction de connexion", dites plutôt "modifie la fonction handleLogin dans src/auth/login.ts aux lignes 45-78". Plus l'instruction est précise, moins OpenClaw lira de fichiers.
❌ "Corrige le bug de connexion"
→ OpenClaw lit 10+ fichiers, consomme 200K+ jetons
✅ "Corrige le contrôle de pointeur nul à la ligne 52 de src/auth/login.ts"
→ OpenClaw ne lit que la partie pertinente d'un seul fichier, consomme ~20K jetons
Méthode 2 : Utiliser la recherche sémantique locale QMD
Le QMD (Quick Memory Database) d'OpenClaw peut créer un index vectoriel local. Il recherche les extraits de code pertinents et n'envoie que le contenu le plus important au modèle.
Comment l'activer : activez le QMD dans les paramètres d'OpenClaw ; il indexera automatiquement vos fichiers de projet et l'historique de vos conversations. Lors des requêtes ultérieures, le QMD trouvera d'abord les blocs de code localement et n'enverra que les segments correspondants au modèle.
Méthode 3 : Utiliser la syntaxe @file pour une référence directe
Dans OpenClaw, vous pouvez utiliser la syntaxe @file pour référencer précisément un fichier et éviter que le modèle ne doive effectuer sa propre recherche :
Modifie la fonction handleLogin dans @src/auth/login.ts,
ajoute la logique de traitement pour l'expiration du refreshToken.
Référence la méthode isTokenExpired dans @src/auth/token.ts.
Ainsi, OpenClaw ne chargera que les 2 fichiers spécifiés, au lieu de scanner tout le répertoire src/auth/.
Méthode 4 : Guider via un fichier de structure de projet
Indiquez une vue d'ensemble de la structure du projet dans AGENTS.md ou SOUL.md pour qu'OpenClaw sache "quelle fonctionnalité se trouve dans quel fichier", réduisant ainsi le scan exploratoire des fichiers.
## Structure du projet
- Authentification: src/auth/ (login.ts, token.ts, session.ts)
- Gestion des utilisateurs: src/user/ (profile.ts, settings.ts)
- Routes API: src/routes/ (auth.route.ts, user.route.ts)
Ce résumé ne consomme que quelques centaines de jetons, mais il permet à OpenClaw d'économiser des dizaines de milliers de jetons en évitant un scan aveugle des fichiers.
Stratégies 3 à 6 : Astuces avancées pour économiser des jetons avec OpenClaw
Stratégie 3 : Élagage du contexte (Context Pruning)
OpenClaw prend en charge l'élagage manuel et automatique du contexte. Lorsque la conversation devient trop longue, vous pouvez nettoyer les messages historiques devenus inutiles.
La version 2026.3.7 d'OpenClaw a introduit les plugins "Context Engine", permettant à des plugins tiers de proposer des stratégies de gestion du contexte alternatives (auparavant, cette partie était codée en dur dans le cœur du logiciel). Le plugin lossless-claw permet de compresser l'historique de la conversation sans perdre d'informations essentielles.
Conseils pratiques :
- Après chaque sous-tâche terminée, nettoyez manuellement les sorties d'appels d'outils inutiles.
- Définissez
contextTokens: 50000pour limiter la taille de la fenêtre de contexte. - Utilisez la fonction
compactpour compresser l'historique de la conversation.
Stratégie 4 : Recherche sémantique locale QMD
QMD (Quick Memory Database) est la fonctionnalité de recherche vectorielle locale d'OpenClaw. Elle établit une base de données vectorielle sur votre appareil local pour indexer l'historique des conversations et les documents. Lors d'une requête, le système effectue d'abord une recherche locale et n'envoie que les segments les plus pertinents au modèle.
Résultat : réduction de 80 à 90 % des coûts en jetons d'entrée.
Stratégie 5 : Utilisation du Prompt Caching
Les familles de modèles Claude et GPT prennent en charge le Prompt Caching. Lorsque l'invite système ou le contexte fréquemment utilisé ne change pas, l'API utilise automatiquement la version mise en cache, réduisant ainsi le coût des jetons d'entrée de 80 à 90 %.
Mais attention, il y a une limite cruciale : l'appel de Claude via le format compatible OpenAI (/v1/chat/completions) ne prend pas en charge le Prompt Caching ; vous devez utiliser le format natif d'Anthropic (/v1/messages). Si vous passez par APIYI (apiyi.com), la plateforme prend en charge le Prompt Caching au format natif.
Stratégie 6 : Désactivation du mode Thinking pour les tâches sans raisonnement
Le mode Thinking/Reasoning peut faire exploser la consommation de jetons de 10 à 50 fois. Si la tâche en cours ne nécessite pas de raisonnement approfondi (comme un simple formatage, un déplacement de fichier ou un remplacement de texte), désactiver le mode Thinking permet de réaliser des économies substantielles.
| Type de tâche | Thinking nécessaire ? | Différence de jetons |
|---|---|---|
| Analyse de bug complexe | Oui | Consommation normale |
| Conception d'architecture | Oui | Consommation normale |
| Formatage simple | Non | 10-50x moins après désactivation |
| Déplacement/Renommage de fichiers | Non | 10-50x moins après désactivation |
| Génération de code boilerplate | Selon le cas | Désactivable pour les modèles simples |
Astuce : Le "Context Compaction" de Claude Code et l'"Élagage du contexte" d'OpenClaw résolvent le même problème : le contrôle des jetons d'entrée cumulés. Si vous utilisez les deux outils, vous pouvez gérer vos quotas d'invocation du modèle de manière centralisée via APIYI (apiyi.com).
Comparaison des économies de jetons : OpenClaw vs Claude Code
Ces deux outils font face aux mêmes défis, mais leurs solutions diffèrent.

FAQ (Foire aux questions)
Q1 : Que faire si le modèle ne connaît pas le contexte du projet lors de l’ouverture d’une nouvelle conversation ?
Utilisez le système de mémoire d'OpenClaw et le fichier AGENTS.md. La mémoire récupère automatiquement les informations de contexte pertinentes dans les nouvelles sessions (en n'envoyant que les segments les plus pertinents, plutôt que tout l'historique). En définissant la structure du projet et les conventions clés dans AGENTS.md, ces éléments sont chargés automatiquement à chaque nouvelle session — c'est bien plus efficace que de traîner 20 tours d'historique de conversation.
Q2 : Comment connaître la consommation de jetons (tokens) de la session actuelle ?
Les journaux de conversation d'OpenClaw sont enregistrés dans des fichiers JSONL situés dans le répertoire .openclaw/agents.main/sessions/. Vous pouvez y consulter directement le nombre de jetons pour chaque requête. Une méthode plus pratique consiste à utiliser le tableau de bord de votre fournisseur d'API — en passant par le service proxy API APIYI (apiyi.com), vous pouvez visualiser la consommation précise de jetons et les coûts de chaque requête depuis l'interface.
Q3 : Quelle est la différence entre QMD et une recherche grep classique ?
grep effectue une correspondance exacte : si vous cherchez "handleLogin", vous ne trouverez que les occurrences contenant cette chaîne de caractères. QMD utilise la recherche sémantique : si vous cherchez "gestion des erreurs de connexion utilisateur", il trouvera tous les blocs de code sémantiquement liés, même si les termes "connexion" ou "gestion des erreurs" n'apparaissent pas explicitement dans le code. La recherche sémantique est beaucoup plus précise, réduit le contenu inutile envoyé au modèle et permet d'économiser davantage de jetons.
Q4 : Pourquoi le Heartbeat consomme-t-il autant de jetons ?
Le mécanisme de Heartbeat (battement de cœur) d'OpenClaw vérifie régulièrement l'état des tâches. Si l'intervalle est trop court (par exemple toutes les 5 minutes), chaque battement envoie le contexte complet de la session au modèle. Certains utilisateurs ont constaté que la fonction de vérification automatique des e-mails pouvait coûter jusqu'à 50 $ par jour. Solution : augmentez l'intervalle du Heartbeat ou désactivez-le lorsque vous n'avez pas besoin de surveillance automatique.
Résumé
Les points clés pour économiser des jetons avec OpenClaw (sans changer de modèle ni sacrifier la qualité) :
- Les jetons d'entrée représentent la majeure partie du coût (70-85 %) : renvoyer tout l'historique à chaque requête rend les conversations longues très coûteuses. La méthode la plus simple consiste à ouvrir une nouvelle conversation pour chaque tâche différente.
- La récupération précise des blocs de code est le levier le plus puissant : passer d'un "copier-coller complet" (120 000 jetons) à une "alimentation précise" (4 000 jetons) permet d'économiser 96 % sur une même modification. Méthodes : spécifiez les numéros de ligne, utilisez les références
@file, la recherche sémantique QMD et les déclarations de structure dansAGENTS.md. - Parcours d'optimisation en trois étapes : 5 minutes pour voir les résultats (nouvelle conversation + désactivation du Thinking, économie de 50 %) → 30 minutes pour des résultats concrets (instructions précises + limitation du contexte, économie de 80 %) → Long terme (QMD + mise en cache, économie de 97 %).
Nous vous recommandons de gérer vos invocations d'API OpenClaw via APIYI (apiyi.com). La plateforme fournit des statistiques précises sur l'utilisation des jetons et un suivi des coûts, vous aidant à quantifier l'impact réel de chaque optimisation.
📚 Références
-
Guide d'utilisation des jetons et de contrôle des coûts OpenClaw : Documentation officielle sur la gestion des jetons
- Lien :
docs.openclaw.ai/reference/token-use - Description : Inclut la configuration des
contextTokenset l'optimisation du Heartbeat
- Lien :
-
Optimisation des jetons OpenClaw : passer de 600 $ à 20 $ : Cadre d'optimisation complet en trois étapes
- Lien :
blog.laozhang.ai/en/posts/openclaw-save-money-practical-guide - Description : Contient des paramètres de configuration spécifiques et les économies attendues
- Lien :
-
80 % des jetons gaspillés par les agents de codage IA servent à chercher des informations : Étude sur la précision du contexte
- Lien :
medium.com/@jakenesler/context-compression-to-reduce-llm-costs - Description : Explique pourquoi une recherche précise est plus efficace que l'augmentation de la fenêtre de contexte
- Lien :
-
Centre de documentation APIYI : Statistiques d'utilisation des jetons et suivi des coûts
- Lien :
docs.apiyi.com - Description : Prend en charge la gestion de l'invocation du modèle pour OpenClaw et Claude Code
- Lien :
Auteur : Équipe technique APIYI
Échanges techniques : N'hésitez pas à discuter dans les commentaires, pour plus d'informations, visitez le centre de documentation APIYI sur docs.apiyi.com