Choisir un modèle d'IA à la fois rapide et économique est un défi majeur pour tout développeur travaillant sur des scénarios à haute fréquence d'appels. Le 3 mars 2026, Google a officiellement lancé Gemini 3.1 Flash Lite Preview. Il s'agit du modèle le plus rapide et le plus rentable de la gamme Gemini 3, spécialement conçu pour les tâches à haut débit comme la traduction, le résumé ou la classification.
Valeur ajoutée : En lisant cet article, vous maîtriserez les spécifications techniques, les avantages en termes de performances et les meilleurs cas d'usage de Gemini 3.1 Flash Lite, tout en apprenant à l'intégrer rapidement grâce à des exemples de code.

Aperçu des paramètres clés de Gemini 3.1 Flash Lite
Avant d'entrer dans le vif du sujet, voici les spécifications techniques essentielles de ce modèle :
| Paramètre | Spécifications Gemini 3.1 Flash Lite | Note |
|---|---|---|
| ID du modèle | gemini-3.1-flash-lite-preview |
Version préliminaire |
| Fenêtre de contexte | 1 000 000 tokens | Contexte étendu |
| Sortie max. | 64 000 tokens | Supporte les textes longs |
| Prix d'entrée | 0,25 $ / million de tokens | Coût ultra-faible |
| Prix de sortie | 1,50 $ / million de tokens | Excellent rapport qualité-prix |
| Vitesse de sortie | ~382 tokens/seconde | Réponse ultra-rapide |
| Modalités d'entrée | Texte, image, audio, vidéo | Multimodal natif |
| Modalités de sortie | Texte | Génération de texte |
| Date de sortie | 3 mars 2026 | Dernier lancement |
🚀 Démarrage rapide : Gemini 3.1 Flash Lite Preview est déjà disponible sur la plateforme APIYI (apiyi.com). Il prend en charge les interfaces compatibles OpenAI, vous permettant une intégration immédiate sans configuration complexe.
Les 5 avantages clés de Gemini 3.1 Flash Lite
Avantage n°1 : Une vitesse multipliée par 2,5
Gemini 3.1 Flash Lite marque un bond en avant spectaculaire en termes de vitesse. Selon les données de benchmark d'Artificial Analysis :
- Temps jusqu'au premier jeton (TTFT) : 2,5 fois plus rapide que Gemini 2.5 Flash.
- Vitesse de sortie : atteint 382 jetons/seconde, soit une amélioration de 64 % par rapport aux 232 jetons/seconde de Gemini 2.5 Flash.
- Débit global : en hausse d'environ 45 %.
Cela signifie que pour les scénarios sensibles à la latence, comme la traduction en temps réel, les chatbots ou le résumé de contenu, les utilisateurs bénéficient d'une réactivité quasi instantanée.
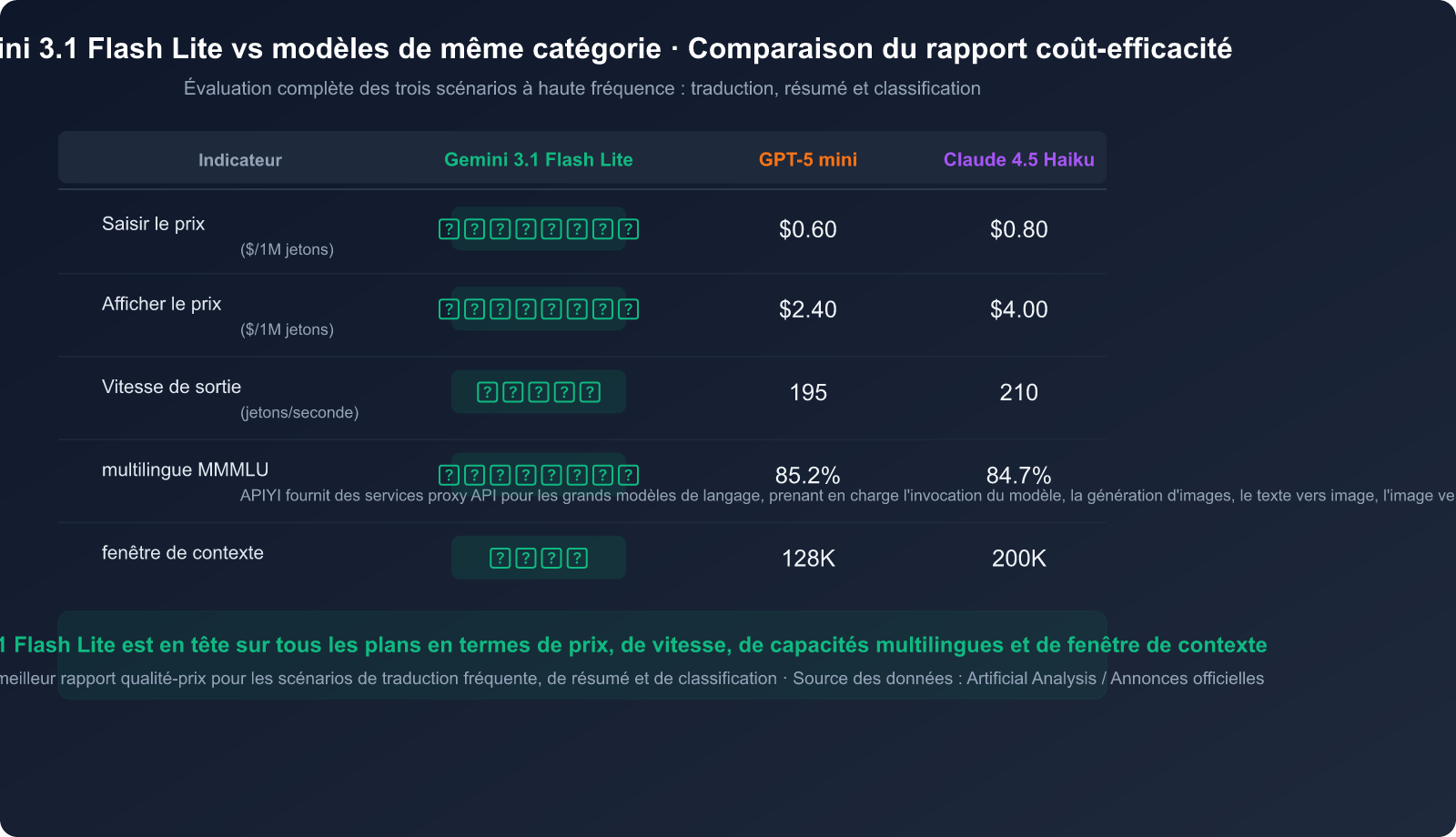
Avantage n°2 : Un rapport coût-efficacité ultime
La stratégie tarifaire de Gemini 3.1 Flash Lite est extrêmement compétitive :
| Comparaison des prix | Prix d'entrée ($/1M jetons) | Prix de sortie ($/1M jetons) | Coût global |
|---|---|---|---|
| Gemini 3.1 Flash Lite | 0,25 $ | 1,50 $ | ⭐ Le plus bas |
| Gemini 3 Flash | 1,00 $ | 4,00 $ | Moyen |
| Gemini 3 Pro | 2,50 $ | 15,00 $ | Élevé |
| Claude 4.5 Haiku | 0,80 $ | 4,00 $ | Moyen |
| GPT-5 mini | 0,60 $ | 2,40 $ | Moyen |
Sur la base d'un traitement quotidien d'un million de jetons, le coût mensuel de Gemini 3.1 Flash Lite n'est que d'environ 52,50 $, soit une économie de plus de 80 % par rapport à Gemini 3 Pro.
Avantage n°3 : Une fenêtre de contexte d'un million de jetons
Gemini 3.1 Flash Lite prend en charge une fenêtre de contexte de 1M de jetons, ce qui est extrêmement rare pour un modèle de cette gamme de prix. Cela vous permet de :
- Traduire ou résumer des livres entiers en une seule fois.
- Analyser des heures de transcriptions d'enregistrements de réunions.
- Comprendre des bases de code massives et générer la documentation associée.
- Effectuer des traductions multilingues croisées de documents longs.
Avantage n°4 : Support multimodal natif
Bien qu'il soit positionné comme un modèle léger, Gemini 3.1 Flash Lite conserve des capacités d'entrée multimodales complètes :
- Texte : compréhension et génération de texte standard.
- Image : reconnaissance et compréhension d'images.
- Audio : traitement de contenu vocal.
- Vidéo : compréhension de contenu vidéo.
Cela le rend adapté non seulement aux tâches textuelles, mais aussi aux scénarios multimodaux comme la traduction d'images avec texte ou la génération de sous-titres vidéo.
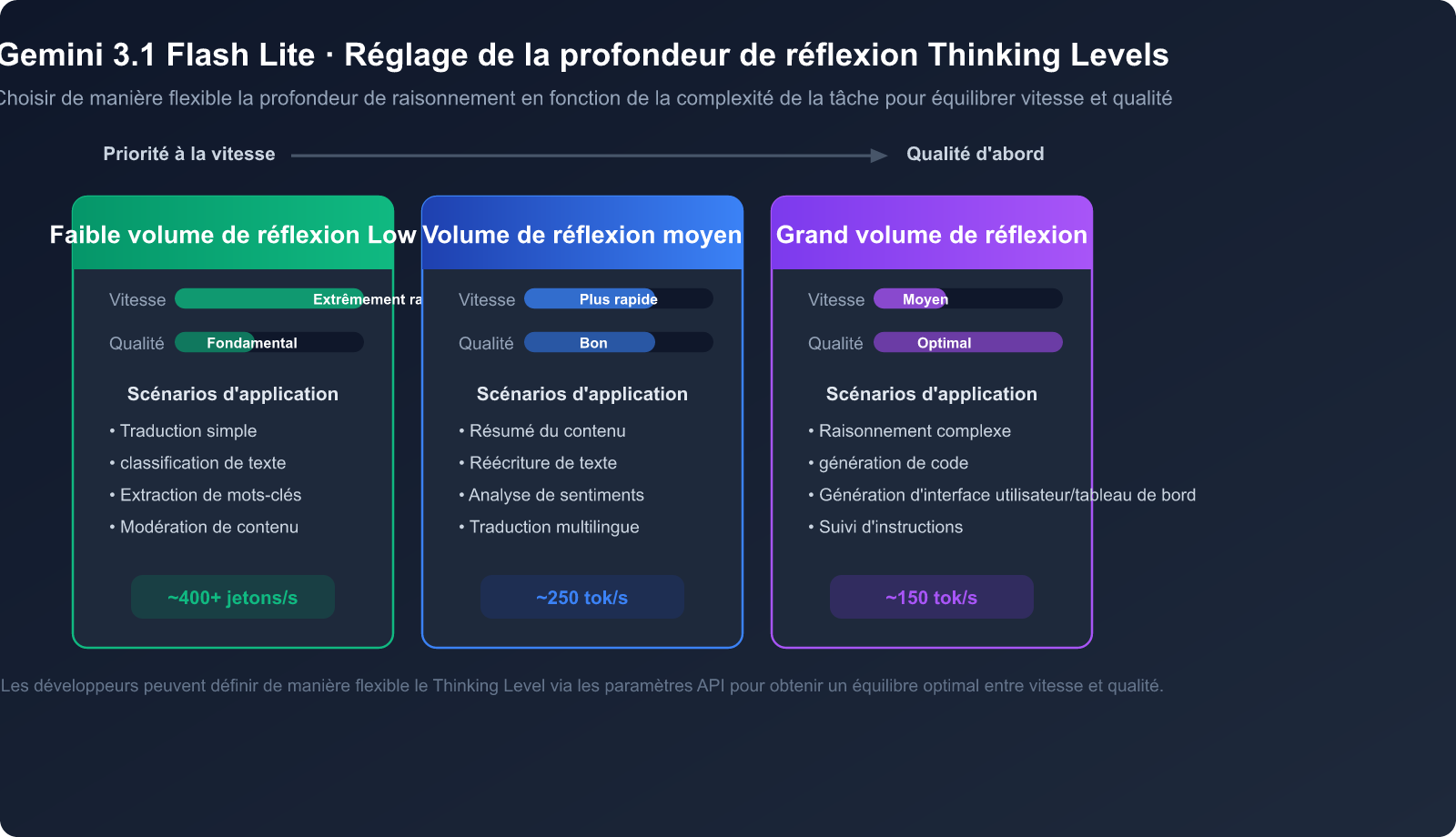
Avantage n°5 : Profondeur de réflexion ajustable
Gemini 3.1 Flash Lite prend en charge la fonction Thinking Levels (niveaux de réflexion), permettant aux développeurs d'ajuster la profondeur de raisonnement du modèle selon la complexité de la tâche :
- Faible réflexion : idéal pour les traductions simples ou la classification, privilégiant une vitesse maximale.
- Réflexion moyenne : adapté aux résumés ou à la réécriture de contenu nécessitant une certaine compréhension.
- Réflexion élevée : conçu pour le raisonnement complexe, la génération de code et les tâches nécessitant une réflexion approfondie.
Benchmarks de performance de Gemini 3.1 Flash Lite
Gemini 3.1 Flash Lite a obtenu un score Elo de 1432 sur le classement Arena.ai, se distinguant ainsi parmi les modèles de sa catégorie.
| Benchmark | Gemini 3.1 Flash Lite | Description |
|---|---|---|
| GPQA Diamond | 86,9 % | Raisonnement scientifique |
| MMMU-Pro | 76,8 % | Raisonnement multimodal |
| MMMLU | 88,9 % | Questions-réponses multilingues |
| LiveCodeBench | 72,0 % | Génération de code |
| Video-MMMU | 84,8 % | Compréhension vidéo |
| SimpleQA | 43,3 % | Connaissances paramétriques |
| MRCR v2 (128k) | 60,1 % | Compréhension de contexte long |
Il est intéressant de noter que sur 6 benchmarks, dont GPQA Diamond et MMMLU, Gemini 3.1 Flash Lite surpasse GPT-5 mini et Claude 4.5 Haiku, prouvant que les modèles légers peuvent également offrir des performances d'intelligence de pointe.
🎯 Conseil technique : Les données de benchmark ci-dessus montrent que Gemini 3.1 Flash Lite excelle particulièrement dans le traitement multilingue (88,9 % au MMMLU), ce qui le rend idéal pour les scénarios de traduction interlinguistique. Vous pouvez tester rapidement ce modèle pour des tâches multilingues via APIYI sur apiyi.com.
Prise en main rapide de Gemini 3.1 Flash Lite
Exemple de code minimaliste
En utilisant l'interface compatible OpenAI, quelques lignes de code suffisent pour invoquer Gemini 3.1 Flash Lite :
import openai
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://api.apiyi.com/v1" # Interface unifiée APIYI
)
# Exemple de scénario de traduction
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=[
{"role": "system", "content": "Vous êtes un traducteur professionnel. Veuillez traduire le texte chinois saisi par l'utilisateur en anglais, en conservant le sens et le ton originaux."},
{"role": "user", "content": "L'intelligence artificielle transforme profondément notre façon de travailler et de vivre."}
],
temperature=0.3
)
print(response.choices[0].message.content)
Voir le code complet : Traduction par lots + Scénario de résumé
import openai
import time
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://api.apiyi.com/v1" # Interface unifiée APIYI
)
MODEL = "gemini-3.1-flash-lite-preview"
def translate_text(text, target_lang="English"):
"""Traduit le texte vers la langue cible"""
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": f"Traduisez le texte suivant en {target_lang}. Conservez le sens et le ton originaux."},
{"role": "user", "content": text}
],
temperature=0.3
)
return response.choices[0].message.content
def summarize_text(text, max_words=100):
"""Génère un résumé du texte"""
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": f"Veuillez résumer les points clés du contenu suivant en {max_words} mots maximum."},
{"role": "user", "content": text}
],
temperature=0.5
)
return response.choices[0].message.content
def classify_text(text, categories):
"""Classification de texte"""
cats = "、".join(categories)
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": f"Classez le texte suivant dans l'une de ces catégories : {cats}. Ne renvoyez que le nom de la catégorie."},
{"role": "user", "content": text}
],
temperature=0.1
)
return response.choices[0].message.content
# Exemple d'utilisation
texts = [
"L'informatique quantique révolutionnera le domaine de la cryptographie au cours de la prochaine décennie",
"La nouvelle voiture électrique dépasse les 1000 km d'autonomie",
"La banque centrale annonce une baisse des taux directeurs de 25 points de base"
]
categories = ["Technologie", "Automobile", "Finance", "Sport", "Divertissement"]
for text in texts:
# Traduction
translated = translate_text(text)
# Classification
category = classify_text(text, categories)
# Résumé
summary = summarize_text(text, max_words=30)
print(f"Original : {text}")
print(f"Traduction : {translated}")
print(f"Catégorie : {category}")
print(f"Résumé : {summary}")
print("---")
💰 Optimisation des coûts : Pour les scénarios d'invocation fréquente tels que la traduction, le résumé ou la classification, le prix ultra-compétitif de Gemini 3.1 Flash Lite (seulement 0,25 $ par million de jetons en entrée) permet de réduire considérablement les coûts opérationnels. L'utilisation via la plateforme APIYI (apiyi.com) offre également des avantages tarifaires supplémentaires et des crédits de test gratuits.
Cas d'utilisation optimaux pour Gemini 3.1 Flash Lite
Cas n°1 : Traduction par lots à haute fréquence
Avec un score impressionnant de 88,9 % sur le benchmark multilingue MMMLU, combiné à des coûts d'invocation extrêmement bas et une vitesse de réponse fulgurante, Gemini 3.1 Flash Lite est le choix idéal pour les tâches de traduction en masse :
- Traduction de descriptions de produits e-commerce : Traduction multilingue de dizaines de milliers d'informations produits par jour.
- Traduction d'avis clients : Traduction en temps réel des retours d'utilisateurs internationaux.
- Internationalisation de documentation technique : Génération de versions multilingues pour des volumes massifs de documents.
- Traduction de sous-titres : Conversion rapide et multilingue de sous-titres vidéo.
Cas n°2 : Résumé de contenu en temps réel
Sa vitesse de sortie de 382 tokens/seconde le rend parfaitement adapté aux scénarios de résumé en temps réel :
- Génération de résumés d'actualités : Extraction automatique de résumés pour un flux massif d'informations.
- Comptes-rendus de réunion : Synthèse rapide d'enregistrements de réunions longues.
- Revues de littérature : Génération par lots de résumés d'articles académiques.
- Résumé d'e-mails : Tri et résumé automatique des e-mails d'entreprise.
Cas n°3 : Modération et classification de contenu à grande échelle
Grâce à sa faible latence et son coût réduit, il constitue une solution idéale pour les pipelines de modération de contenu :
- Modération de contenu généré par les utilisateurs : Filtrage de sécurité sur les plateformes sociales.
- Classification automatique de tickets : Routage intelligent pour les systèmes de support client.
- Analyse de sentiment : Surveillance en temps réel de l'e-réputation d'une marque.
- Génération automatique de tags : Étiquetage automatique pour les systèmes de gestion de contenu.
Guide de décision pour le choix du scénario
| Cas d'utilisation | Raison recommandée | Avantages clés | Coût mensuel estimé |
|---|---|---|---|
| Traduction par lots | Capacité multilingue MMMLU 88,9 % | Prix bas + Haute qualité | ~50 $ (1M tokens/jour) |
| Résumé en temps réel | Sortie ultra-rapide 382 tokens/s | Faible latence + Rapidité | ~30 $ (500k tokens/jour) |
| Modération de contenu | Précision de classification + réactivité | Faible coût + Traitement par lots | ~20 $ (300k tokens/jour) |
| Chatbot | TTFT 2,5 fois plus rapide | Réponse instantanée | ~80 $ (2M tokens/jour) |
| Traitement de longs documents | Fenêtre de contexte de 1M tokens | Traitement d'un livre entier en une fois | Facturation à l'usage |
💡 Conseil de sélection : Si votre activité repose sur des tâches de traitement de texte à haute fréquence, par lots et sensibles aux coûts, Gemini 3.1 Flash Lite est actuellement le meilleur choix en termes de rapport qualité-prix. Nous vous recommandons d'effectuer des tests en conditions réelles via la plateforme APIYI (apiyi.com), qui permet de basculer facilement vers d'autres modèles pour comparer les résultats.
Précautions d'utilisation de Gemini 3.1 Flash Lite
Limitations actuelles
En tant que modèle en version préliminaire, voici quelques points à garder à l'esprit :
- Phase de prévisualisation : Le modèle est toujours en état "Preview", ce qui signifie que l'interface API et les comportements peuvent être ajustés.
- Limites de sortie : La sortie maximale est de 64K tokens ; les tâches de génération très longues doivent être traitées par segments.
- Performance avec contexte étendu : Les performances sont moyennes dans les scénarios de contexte extrême de 1M tokens (seulement 12,3 % au test MRCR v2 1M). Il est recommandé de rester en dessous de 128K pour obtenir les meilleurs résultats.
- Limites de sécurité : Le score de sécurité pour l'analyse d'images vers texte doit encore être amélioré ; ajoutez une couche de modération pour les contenus sensibles.
Conseils d'utilisation
- Paramètre de température : Pour les tâches de traduction, utilisez
temperature=0.3, et pour les tâches de résumé,temperature=0.5. - Invite système : Fournir une définition claire du rôle et des exigences de format de sortie peut améliorer considérablement la qualité des résultats.
- Traitement par lots : Utilisez des appels asynchrones pour augmenter le débit et tirer pleinement parti de la vitesse du modèle.
- Contrôle du contexte : Bien que le modèle prenne en charge 1M de tokens, il est conseillé de limiter les tâches courantes à 128K pour un meilleur rapport coût-efficacité.
Foire aux questions
Q1 : Quelle est la différence entre Gemini 3.1 Flash Lite et Gemini 3 Flash ?
Gemini 3.1 Flash Lite est la version légère de la série Gemini 3, optimisée pour les scénarios à haute fréquence et à faible coût. Par rapport à Gemini 3 Flash, son prix d'entrée est inférieur de 75 % (0,25 $ contre 1,00 $) et sa vitesse de sortie est environ 64 % plus rapide, bien que ses capacités de raisonnement complexe soient légèrement inférieures. En résumé : choisissez Flash Lite pour un rapport qualité-prix optimal, et Flash si vous avez besoin de capacités de raisonnement plus poussées. La plateforme APIYI (apiyi.com) vous permet de tester les deux modèles simultanément pour trouver rapidement celui qui convient le mieux à votre cas d'usage.
Q2 : Gemini 3.1 Flash Lite est-il adapté à la traduction ?
Absolument. Gemini 3.1 Flash Lite a obtenu un score élevé de 88,9 % sur le benchmark multilingue MMMLU, se classant parmi les meilleurs modèles de sa catégorie. Avec un prix d'entrée ultra-bas de 0,25 $/million de tokens et une vitesse de sortie de 382 tokens/seconde, c'est l'un des modèles les plus rentables pour les tâches de traduction en masse. Nous vous recommandons d'utiliser APIYI (apiyi.com) pour obtenir des crédits de test gratuits et vérifier la qualité de traduction par vous-même.
Q3 : Comment appeler Gemini 3.1 Flash Lite via une interface compatible OpenAI ?
Il suffit de définir base_url sur l'adresse de l'interface APIYI et d'utiliser gemini-3.1-flash-lite-preview comme paramètre model. Il n'est pas nécessaire de modifier la structure de votre code SDK OpenAI existant, ce qui permet une transition fluide. Voir les exemples de code dans la section "Démarrage rapide" de cet article.
Q4 : La fenêtre de contexte de 1M de Gemini 3.1 Flash Lite est-elle réellement efficace ?
Les performances sont excellentes dans la plage des 128K tokens (score de 60,1 % au MRCR v2 128K), mais elles chutent de manière significative dans les scénarios extrêmes de 1M tokens (score de 12,3 % au MRCR v2 1M). Pour une utilisation quotidienne, nous vous conseillons de rester en dessous de 128K et d'adopter une stratégie de segmentation pour le traitement de documents très longs.
Résumé
Le Gemini 3.1 Flash Lite Preview s'impose comme le champion du rapport qualité-prix pour 2026 dans les scénarios à haute fréquence tels que la traduction, le résumé et la classification. Il se distingue par son prix ultra-compétitif de 0,25 $ par million de tokens en entrée, une vitesse de sortie fulgurante de 382 tokens/seconde, une fenêtre de contexte de 1 M de tokens, ainsi que des performances exceptionnelles dans les benchmarks comme le traitement multilingue (MMMLU 88,9 %) et le raisonnement scientifique (GPQA Diamond 86,9 %).
Que vous ayez besoin de gérer des traductions par lots de plusieurs millions de tokens par jour ou de concevoir un service de résumé en temps réel à faible latence, le Gemini 3.1 Flash Lite est une option à privilégier.
Nous vous recommandons d'accéder rapidement au Gemini 3.1 Flash Lite Preview via APIYI (apiyi.com). Cette plateforme propose une interface compatible avec OpenAI et permet de basculer entre plusieurs modèles majeurs en un clic, facilitant ainsi la validation rapide des résultats et la comparaison des modèles.
Références
-
Google DeepMind – Fiche technique du modèle Gemini 3.1 Flash-Lite : Spécifications techniques officielles et données de benchmark
- Lien :
deepmind.google/models/model-cards/gemini-3-1-flash-lite/
- Lien :
-
Google AI for Developers – Gemini 3.1 Flash-Lite Preview : Documentation officielle de l'API et guide de développement
- Lien :
ai.google.dev/gemini-api/docs/models/gemini-3.1-flash-lite-preview
- Lien :
-
Artificial Analysis – Évaluation des performances : Benchmarks indépendants de vitesse et de performance
- Lien :
artificialanalysis.ai/models/gemini-3-1-flash-lite-preview
- Lien :
📝 Auteur : Équipe technique APIYI | Pour plus de guides d'utilisation et de tutoriels techniques sur les modèles d'IA, veuillez visiter le centre d'aide APIYI sur help.apiyi.com





