Note de l'auteur : Comparaison approfondie des 3 meilleurs modèles d'IA pour la résolution de problèmes mathématiques en 2026, incluant des données de référence provenant de benchmarks faisant autorité comme AIME et MATH, pour vous aider à trouver le modèle de raisonnement mathématique le plus adapté.
Choisir le bon modèle d'IA pour résoudre des problèmes mathématiques est l'une des préoccupations majeures des développeurs et des étudiants. Cet article compare les trois derniers modèles de raisonnement mathématique publiés en 2026 : Gemini 3.1 Pro Preview, Claude Sonnet 4.6 et GPT-5.4. Il fournit des recommandations claires basées sur plusieurs dimensions : résultats aux benchmarks, capacités de raisonnement, tarification des API et cas d'utilisation.
Valeur clé : Après avoir lu cet article, vous saurez exactement quel modèle d'IA choisir pour différents scénarios de résolution de problèmes mathématiques, et comment les appeler de manière optimale en termes de coût.
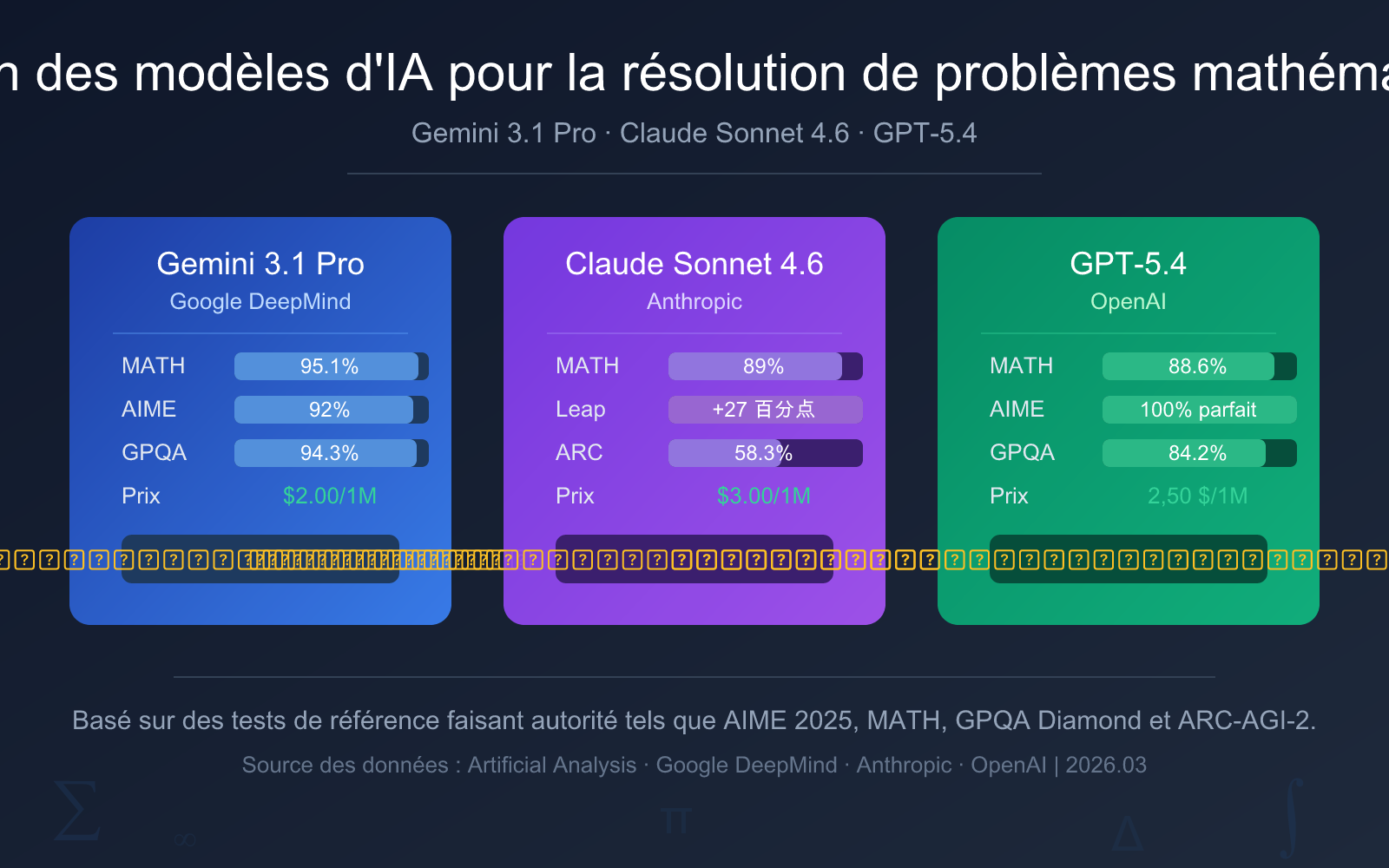
Analyse comparative rapide des modèles d'IA pour la résolution de problèmes mathématiques
Avant d'entrer dans une analyse détaillée, voici un tableau comparatif des données clés pour vous aider à comprendre rapidement les différences essentielles entre les trois principaux modèles d'IA de résolution de problèmes mathématiques.
| Dimension de comparaison | Gemini 3.1 Pro Preview | Claude Sonnet 4.6 | GPT-5.4 |
|---|---|---|---|
| Date de sortie | 19 février 2026 | Début 2026 | 6 mars 2026 |
| AIME 2025 | 92% (sans outils) | — | 100% (score parfait) |
| Benchmark MATH | 95.1% | 89% | 88.6% |
| GPQA Diamond | 94.3% | 74.1% | 84.2% |
| ARC-AGI-2 | 77.1% | 58.3% | 73.3% |
| Prix d'entrée | 2,00 $ / 1M de tokens | 3,00 $ / 1M de tokens | 2,50 $ / 1M de tokens |
| Prix de sortie | 12,00 $ / 1M de tokens | 15,00 $ / 1M de tokens | 15,00 $ / 1M de tokens |
| Recommandation globale | ⭐ Premier choix | ⭐ Choix pour l'apprentissage | ⭐ Choix pour les concours |
Classement recommandé des modèles d'IA pour les mathématiques
Du point de vue du rapport qualité-prix global, nous suggérons l'ordre de priorité suivant :
- Premier choix : Gemini 3.1 Pro Preview : Leader avec 95,1% au benchmark MATH, prix le plus bas, capacités mathématiques globales les plus fortes.
- Deuxième choix : Claude Sonnet 4.6 : Capacités mathématiques en hausse de 27 points de pourcentage, processus de résolution clair et compréhensible, idéal pour les scénarios d'apprentissage.
- Niveau concours : GPT-5.4 : Score parfait de 100% à l'AIME 2025, adapté aux concours mathématiques de haut niveau et à la recherche spécialisée.
🎯 Conseil technique : Les trois modèles peuvent être invoqués de manière unifiée via la plateforme APIYI apiyi.com. Il est recommandé de les tester un par un sur vos problèmes mathématiques réels pour sélectionner celui qui correspond le mieux à vos besoins.
Capacités détaillées de résolution mathématique de Gemini 3.1 Pro Preview
Gemini 3.1 Pro Preview est le dernier modèle phare publié par Google DeepMind le 19 février 2026. C'est la première fois que Google utilise un incrément de version « .1 » (les mises à jour intermédiaires utilisaient auparavant systématiquement « .5 »), marquant une mise à niveau ciblée axée sur les capacités de raisonnement intelligent.
Résultats de Gemini 3.1 Pro aux benchmarks mathématiques
| Benchmark | Score | Description |
|---|---|---|
| MATH | 95.1% | Test mathématique complet couvrant l'algèbre, la géométrie, le calcul, etc. |
| AIME 2025 (sans outils) | 92% | American Invitational Mathematics Examination, niveau concours lycée. |
| AIME 2025 (exécution de code) | 100% | L'ancien Gemini 3 Pro obtenait un score parfait avec l'exécution de code activée. |
| GPQA Diamond | 94.3% | Questions-réponses scientifiques de niveau master, leader parmi tous les modèles de son niveau. |
| ARC-AGI-2 | 77.1% | Capacités de raisonnement abstrait, doublées par rapport à la génération précédente 3 Pro. |
| MathArena Apex | Leader significatif | Amélioration de plus de 20 fois par rapport à la génération précédente. |
Sur les 18 principaux benchmarks publiés officiellement par Google, Gemini 3.1 Pro a obtenu la première place dans 12 d'entre eux. En raisonnement mathématique, la performance de 95,1% au benchmark MATH est particulièrement remarquable, ce qui signifie qu'il possède des capacités de résolution très fortes dans tous les sous-domaines mathématiques : algèbre, géométrie, probabilités, calcul, etc.
Système de pensée à trois niveaux de Gemini 3.1 Pro
Gemini 3.1 Pro introduit une innovation architecturale clé : un système de pensée à trois niveaux :
- Low (Mode rapide) : Traite les calculs mathématiques simples et les dérivations de formules, avec la vitesse de réponse la plus élevée.
- Medium (Mode équilibré) : Nouvelle couche intermédiaire, traite les problèmes mathématiques de difficulté moyenne, équilibre vitesse et précision.
- High (Mode approfondi) : Traite les problèmes complexes de raisonnement en plusieurs étapes, comme les problèmes de mathématiques de niveau concours.
Ce système à trois niveaux permet aux développeurs d'acheminer les requêtes de manière flexible en fonction de la difficulté du problème mathématique, sans avoir à choisir entre « rapide mais approximatif » et « lent mais précis ». Cet avantage architectural est particulièrement évident pour les scénarios traitant en masse des problèmes de difficultés variées (comme les systèmes de génération de questions adaptatives pour les plateformes éducatives).
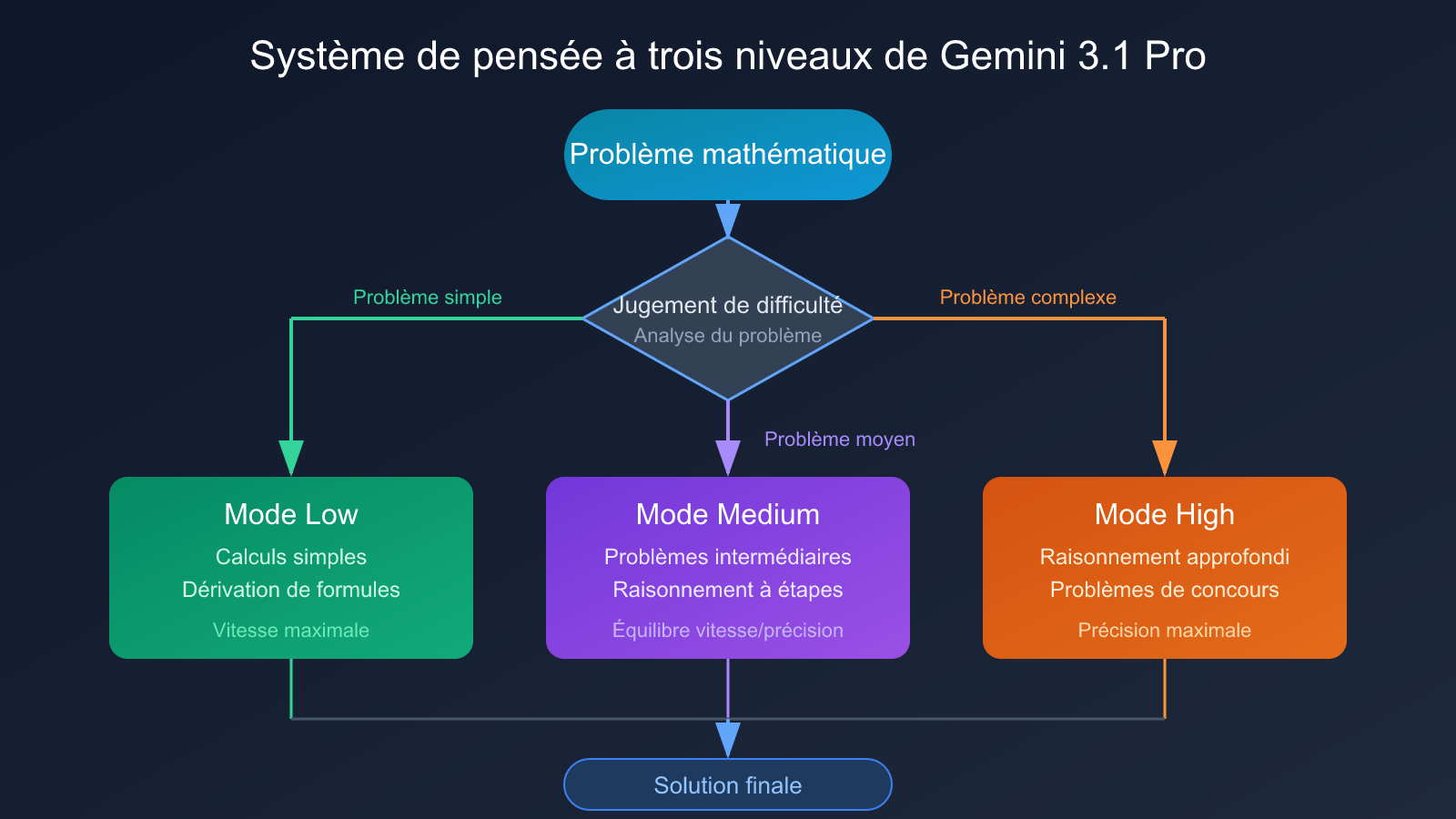
Expérience pratique de résolution mathématique avec Gemini 3.1 Pro
Dans la pratique de résolution de problèmes mathématiques, la performance de Gemini 3.1 Pro Preview peut être résumée comme « complète et stable » :
- Domaine de l'algèbre : Opérations polynomiales, résolution de systèmes d'équations, preuves d'inégalités, etc., avec pratiquement aucune erreur, grâce à la couverture élevée de 95,1% du benchmark MATH.
- Domaine de la géométrie : Chaînes de raisonnement complètes en géométrie analytique et solide, particulièrement performant sur les problèmes de calcul liés aux coordonnées.
- Probabilités et statistiques : Logique de raisonnement claire pour les probabilités conditionnelles, les permutations et combinaisons, capable de traiter correctement les calculs complexes en plusieurs étapes.
- Calcul différentiel et intégral : Résolution précise des intégrales définies et indéfinies, capable de reconnaître et d'appliquer correctement les techniques d'intégration courantes.
Les 12 premières places sur 18 benchmarks principaux de Gemini 3.1 Pro ne sont pas un hasard. Son score à l'Artificial Analysis Intelligence Index est de 57 points, à égalité avec GPT-5.4 (xhigh) pour la première place, bien au-dessus de la médiane de 28 points, reflétant un avantage global en matière de raisonnement intelligent.
Capacités de résolution mathématique de Claude Sonnet 4.6
Claude Sonnet 4.6 est le dernier modèle intermédiaire publié par Anthropic, qui a réalisé un bond qualitatif dans ses capacités de raisonnement mathématique – passant de 62% pour la génération précédente Sonnet 4.5 à 89%, soit une augmentation de 27 points de pourcentage.
Résultats aux tests de référence mathématiques de Claude Sonnet 4.6
| Test de référence | Sonnet 4.6 | Sonnet 4.5 (génération précédente) | Amélioration |
|---|---|---|---|
| Mathématiques globales | 89% | 62% | +27 points de pourcentage |
| ARC-AGI-2 | 58.3% | 13.6% | Amélioration de 4.3 fois |
| GPQA Diamond | 74.1% | — | Raisonnement scientifique niveau master |
| Capacités en programmation | 79.6% | — | Proche de 80.8% d'Opus 4.6 |
| Analyse financière | 63.3% | — | Meilleure de sa catégorie |
Le bond des capacités mathématiques de 62% à 89% est l'un des changements les plus marquants de Sonnet 4.6. Cela signifie qu'il est passé d'un « modèle qui fait parfois des erreurs sur des problèmes mathématiques » à un « modèle capable de traiter de manière fiable des calculs complexes ».
Mécanisme de pensée adaptative de Claude Sonnet 4.6
Un autre point fort de Claude Sonnet 4.6 est son mécanisme de profondeur de pensée adaptative (Adaptive Thinking) :
- Problèmes simples : Réponse rapide, sans gaspiller de ressources de raisonnement. Par exemple, l'arithmétique de base, la résolution d'équations simples.
- Problèmes de difficulté moyenne : Chaîne de raisonnement modérément étendue. Par exemple, les opérations algébriques en plusieurs étapes, les calculs de probabilité.
- Problèmes complexes : Déclenche automatiquement une chaîne de raisonnement profonde. Par exemple, les mathématiques combinatoires, les problèmes de démonstration, les problèmes de niveau compétition.
L'avantage de ce mécanisme adaptatif dans une utilisation pratique est le suivant : vous n'avez pas besoin de régler manuellement la profondeur de raisonnement, le modèle évalue automatiquement la difficulté du problème mathématique et alloue les ressources de calcul correspondantes, trouvant ainsi l'équilibre optimal entre latence et coût.
Avantage unique de Claude Sonnet 4.6 : Le processus de résolution
Dans les scénarios de résolution de problèmes mathématiques, Claude Sonnet 4.6 possède un avantage unique largement reconnu – la clarté du processus de résolution. Plusieurs évaluations indiquent que les modèles Claude sont les meilleurs pour expliquer les concepts mathématiques. De plus, le Learning Mode (mode apprentissage) lancé par Anthropic est spécialement conçu pour guider le processus de raisonnement de l'étudiant, plutôt que de donner directement la réponse.
Cela rend Claude Sonnet 4.6 particulièrement adapté à :
- Les scénarios d'éducation et de tutorat en mathématiques
- Les apprenants qui ont besoin de comprendre les étapes de résolution
- Les chercheurs souhaitant vérifier leur raisonnement pour résoudre un problème
💡 Conseil d'apprentissage : Si votre besoin principal est de « comprendre le processus de résolution mathématique » plutôt que d'obtenir uniquement la réponse, Claude Sonnet 4.6 est le meilleur choix. Vous pouvez obtenir un crédit de test gratuit via APIYI apiyi.com pour expérimenter le niveau de détail de son processus de résolution.
Capacités de résolution mathématique de GPT-5.4
GPT-5.4 est le dernier modèle phare publié par OpenAI le 6 mars 2026. C'est le premier modèle de raisonnement OpenAI à intégrer dans un même modèle par défaut des capacités professionnelles de pointe, des capacités de programmation (issues de GPT-5.3-Codex), une manipulation informatique native et une fenêtre de contexte de 1,05 million de tokens.
Résultats aux tests de référence mathématiques de GPT-5.4
| Test de référence | Score | Explication |
|---|---|---|
| AIME 2025 | 100% (score parfait) | Niveau compétition mathématique lycée, performance parfaite |
| GSM8K | 99% | Problèmes de mathématiques niveau primaire, quasi parfait |
| MATH | 88.6% | Test de référence de raisonnement mathématique global |
| GPQA Diamond | 84.2% (standard) / 92.8% (raisonnement élevé) | Raisonnement scientifique niveau master |
| ARC-AGI-2 | 73.3% (standard) / 83.3% (Pro) | Capacités de raisonnement abstrait |
| FrontierMath (génération précédente 5.2) | 40.3% | Nouveau record pour les mathématiques de pointe de niveau expert |
GPT-5.4 a obtenu le score étonnant de 100% à l'AIME 2025, ce qui signifie qu'il peut résoudre parfaitement tous les problèmes de haute difficulté de l'American Invitational Mathematics Examination. Pour les utilisateurs ayant besoin de résoudre des problèmes mathématiques de niveau compétition, cette performance est très convaincante.
Il est à noter que le score de GPT-5.4 au test MATH est de 88.6%, ce qui présente un certain écart par rapport aux 95.1% de Gemini 3.1 Pro. Cela indique que bien que GPT-5.4 soit parfait sur les problèmes difficiles de niveau compétition, il n'est pas le plus fort dans les tests globaux couvrant un large éventail de domaines mathématiques.
Options de configuration du raisonnement pour GPT-5.4
GPT-5.4 propose plusieurs configurations de raisonnement pour s'adapter à différents types de problèmes mathématiques :
- GPT-5.4 Standard : Adapté aux calculs mathématiques quotidiens et aux problèmes de difficulté moyenne.
- GPT-5.4 Thinking : Active le raisonnement avancé, adapté aux raisonnements et démonstrations complexes en plusieurs étapes.
- GPT-5.4 Pro : Configuration de performance maximale, peut atteindre 83.3% sur ARC-AGI-2, adaptée aux scénarios de plus haute difficulté.
Cependant, il faut noter que le prix de GPT-5.4 Pro est de 30,00 $ / 1M tokens d'entrée + 180,00 $ / 1M tokens de sortie, un coût bien supérieur à la version standard. Pour la plupart des scénarios de résolution de problèmes mathématiques, la version standard est suffisante.
Expérience pratique de résolution mathématique avec GPT-5.4
Les performances de GPT-5.4 sur les problèmes mathématiques de niveau compétition sont particulièrement impressionnantes :
- Mathématiques de compétition : Répond presque parfaitement aux problèmes complexes de théorie des nombres, combinatoire, géométrie de niveau AMC/AIME, le score parfait de 100% à l'AIME est mérité.
- Problèmes de démonstration : Capable de construire des chaînes de démonstration mathématique complètes, logiquement rigoureuses, avec des transitions naturelles entre les étapes.
- Mathématiques appliquées : Le score de 99% au GSM8K montre qu'il est également très fiable sur les problèmes appliqués (comme les calculs d'ingénierie, la modélisation économique).
- Raisonnement en plusieurs étapes : Grâce à la fenêtre de contexte ultra-longue de 1,05M tokens, il peut traiter des problèmes mathématiques en plusieurs étapes extrêmement complexes tout en maintenant une chaîne de raisonnement complète.
Un avantage unique de GPT-5.4 est que sa génération précédente, GPT-5.2, a établi un nouveau record de 40.3% sur FrontierMath (mathématiques de pointe de niveau expert). Cela signifie que la série GPT possède également une certaine capacité d'exploration sur des problèmes mathématiques véritablement de pointe et non résolus, ce que les autres modèles ont actuellement du mal à égaler.
Interprétation des benchmarks pour les modèles d'IA de résolution de problèmes mathématiques
Avant de comparer les modèles d'IA pour la résolution de problèmes mathématiques, il est essentiel de comprendre la signification et le focus de chaque benchmark pour évaluer plus précisément les capacités des modèles :
| Benchmark | Nom complet | Contenu testé | Niveau de difficulté |
|---|---|---|---|
| AIME 2025 | American Invitational Mathematics Examination | Questions réelles de l'examen américain, couvrant la théorie des nombres, la combinatoire, la géométrie, etc. | Niveau compétition lycée (Top 5% des élèves) |
| MATH | Mathematics Aptitude Test of Heuristics | Test complet couvrant 7 grands domaines (algèbre, géométrie, calcul, etc.) | Niveau lycée à premier cycle universitaire |
| GSM8K | Grade School Math 8K | 8000 problèmes de mathématiques appliquées du primaire au collège | Niveau basique |
| GPQA Diamond | Graduate-Level Google-Proof QA | Questions de raisonnement scientifique de niveau master/doctorat, rédigées par des experts | Niveau master/doctorat |
| ARC-AGI-2 | Abstraction and Reasoning Corpus | Reconnaissance de nouveaux schémas logiques, testant la capacité de raisonnement abstrait | Niveau intelligence générale |
| FrontierMath | Frontier Mathematics | Problèmes mathématiques de pointe de niveau expert, impliquant des domaines non résolus ou nouveaux | Niveau expert/chercheur |
Compréhension clé : AIME se concentre davantage sur les astuces mathématiques de niveau compétition et la pensée créative, tandis que MATH se concentre sur la capacité de couverture large dans divers domaines. Un modèle qui obtient un score parfait à AIME mais pas le score le plus élevé à MATH (comme GPT-5.4) indique qu'il est extrêmement fort sur les problèmes astucieux de niveau compétition, mais que sa couverture dans certains domaines fondamentaux peut être légèrement inférieure à celle d'un modèle avec un score MATH plus élevé.
C'est pourquoi nous recommandons Gemini 3.1 Pro Preview comme premier choix global — un score MATH de 95,1 % signifie qu'il a des performances plus équilibrées dans tous les sous-domaines mathématiques.
Il est important de noter que le benchmark AIME 2025 est désormais proche de la saturation — plusieurs modèles de pointe (combinés à l'exécution de code) peuvent atteindre plus de 95 % voire un score parfait. Par conséquent, les benchmarks qui permettent de mieux distinguer les véritables capacités mathématiques des modèles sont ceux de plus haute difficulté comme MathArena Apex et FrontierMath. Sur MathArena Apex, Gemini 3.1 Pro a réalisé une amélioration de plus de 20 fois par rapport à la génération précédente, démontrant des bases de raisonnement mathématique intrinsèques extrêmement solides.
Une autre dimension à surveiller est ARC-AGI-2 (capacité de raisonnement abstrait). Ce test évalue la capacité d'un modèle à reconnaître de nouveaux schémas logiques — des schémas que le modèle n'a jamais vus pendant son entraînement. Gemini 3.1 Pro Preview mène avec 77,1 %, ce qui montre qu'il peut non seulement résoudre des types de problèmes déjà vus, mais qu'il possède également une meilleure capacité de raisonnement généralisé, performant mieux face à de nouveaux types de problèmes mathématiques.
Mise en pratique : Appel API des modèles d'IA de résolution de problèmes mathématiques
Voici un exemple de code minimaliste pour appeler un modèle d'IA de résolution de problèmes mathématiques via une API, fonctionnel en seulement 10 lignes :
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # Interface unifiée APIYI
)
response = client.chat.completions.create(
model="gemini-3.1-pro-preview", # Peut être remplacé par claude-sonnet-4.6 ou gpt-5.4
messages=[{"role": "user", "content": "Résoudre : Étant donné une suite arithmétique {an} de premier terme a1=2 et de raison d=3, trouver la somme S20 des 20 premiers termes."}]
)
print(response.choices[0].message.content)
Afficher le code complet d’appel pour la résolution mathématique (avec comparaison multi-modèles)
import openai
from typing import Optional
def solve_math(
problem: str,
model: str = "gemini-3.1-pro-preview",
system_prompt: Optional[str] = None
) -> str:
"""
Appelle un modèle d'IA pour résoudre un problème mathématique
Args:
problem: Description du problème mathématique
model: Nom du modèle, supporte gemini-3.1-pro-preview / claude-sonnet-4.6 / gpt-5.4
system_prompt: Invite système, peut spécifier le style de résolution
Returns:
La réponse de résolution du modèle
"""
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # Interface unifiée APIYI
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
else:
messages.append({
"role": "system",
"content": "Vous êtes un expert en résolution de problèmes mathématiques. Veuillez résoudre les problèmes mathématiques avec des étapes claires, en expliquant le raisonnement pour chaque étape."
})
messages.append({"role": "user", "content": problem})
try:
response = client.chat.completions.create(
model=model,
messages=messages,
max_tokens=2000
)
return response.choices[0].message.content
except Exception as e:
return f"Erreur : {str(e)}"
# Exemple d'utilisation : Comparaison de la résolution d'un même problème par trois modèles
problem = "Dans un triangle ABC, on connaît a=5, b=7, C=60°. Trouver l'aire du triangle et la longueur du troisième côté c."
models = ["gemini-3.1-pro-preview", "claude-sonnet-4.6", "gpt-5.4"]
for m in models:
print(f"\n{'='*50}")
print(f"Modèle : {m}")
print(f"{'='*50}")
result = solve_math(problem, model=m)
print(result)
Conseil : Obtenez des crédits de test gratuits via APIYI apiyi.com. Une seule clé API vous permet d'appeler les trois modèles de résolution mathématique mentionnés ci-dessus, pour comparer rapidement leurs performances sur vos problèmes réels.
Comparaison des prix et du rapport qualité-prix des modèles d'IA pour la résolution de problèmes mathématiques
Lors du choix d'un modèle d'IA pour la résolution de problèmes mathématiques, le prix est un facteur à ne pas négliger. Voici une comparaison détaillée des prix de trois modèles :
| Dimension du prix | Gemini 3.1 Pro Preview | Claude Sonnet 4.6 | GPT-5.4 |
|---|---|---|---|
| Prix d'entrée | 2,00 $/1M de tokens | 3,00 $/1M de tokens | 2,50 $/1M de tokens |
| Prix de sortie | 12,00 $/1M de tokens | 15,00 $/1M de tokens | 15,00 $/1M de tokens |
| Prix mixte (3:1) | 4,50 $/1M de tokens | 6,00 $/1M de tokens | 5,63 $/1M de tokens |
| Majoration long contexte | >200K double | Aucune | >272K double |
| Fenêtre de contexte | 1M de tokens | Fenêtre standard | 1,05M de tokens |
| Sortie maximale | 65 536 tokens | Sortie standard | 128 000 tokens |
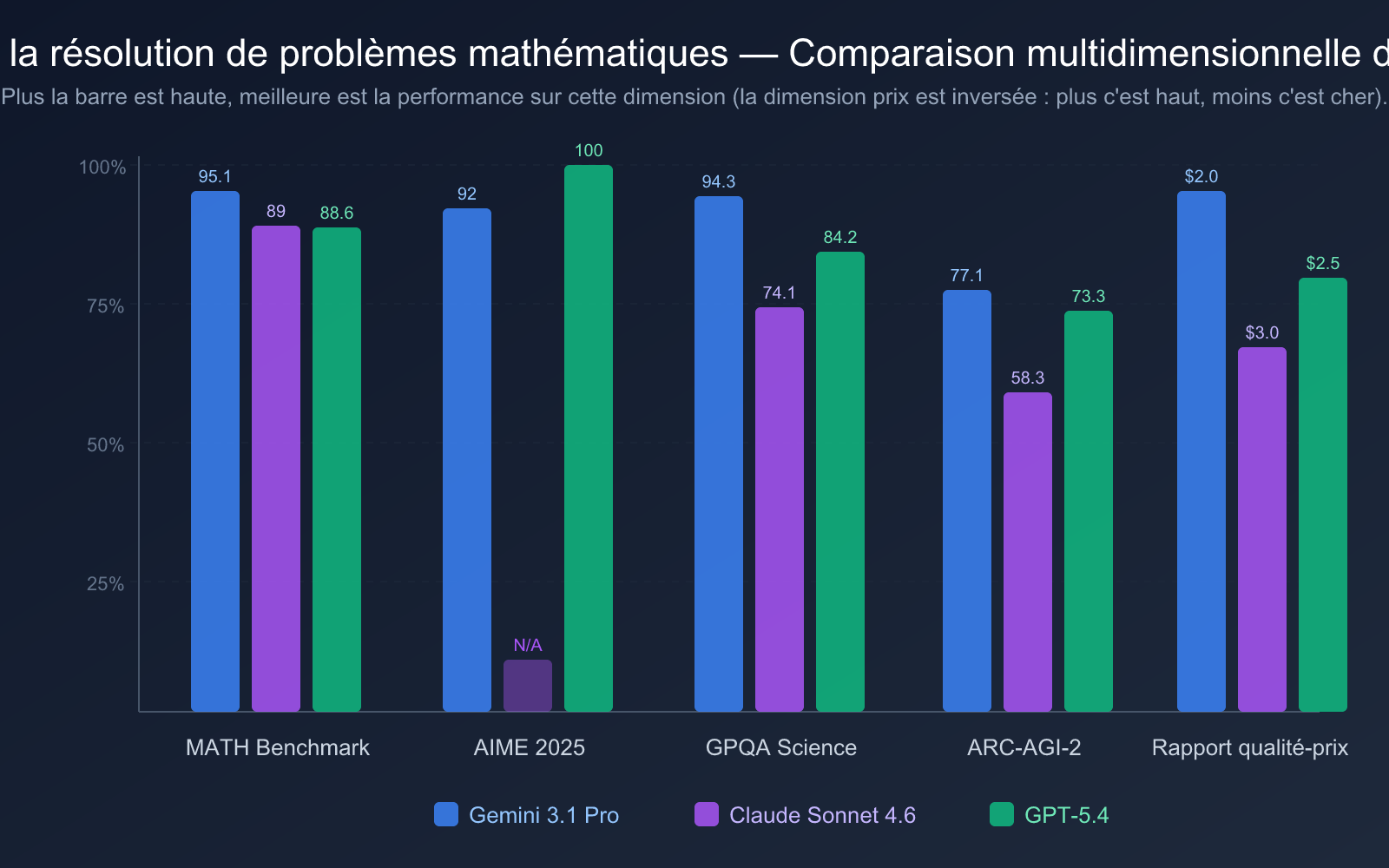
Analyse du rapport qualité-prix :
- Gemini 3.1 Pro Preview offre le meilleur rapport qualité-prix : Prix d'entrée seulement 2,00 $/1M de tokens, avec un score de référence MATH de 95,1 % en tête. Selon l'analyse d'Artificial Analysis, son coût opérationnel est environ 1/7,5 de celui de Claude Opus 4.6, tout en égalant ou dépassant les références en mathématiques et programmation.
- Claude Sonnet 4.6 à prix modéré : La tarification de 3,00 $/15,00 $ est identique à celle de la génération précédente Sonnet 4.5, mais les capacités mathématiques ont augmenté de 27 points de pourcentage, améliorant considérablement le rapport qualité-prix.
- GPT-5.4 Standard à prix raisonnable : La tarification de 2,50 $/15,00 $ est dans une fourchette raisonnable, mais l'utilisation de GPT-5.4 Pro (30 $/180 $) augmenterait considérablement les coûts.
💰 Conseil de coût : Pour les besoins quotidiens de résolution de problèmes mathématiques, nous recommandons d'utiliser Gemini 3.1 Pro Preview pour obtenir le meilleur rapport qualité-prix. Pour optimiser davantage les coûts, envisagez d'utiliser une plateforme d'agrégation d'API pour obtenir des options de recharge plus flexibles.
Estimation pratique des coûts de résolution de problèmes mathématiques
Pour vous aider à mieux comprendre les différences de coût, voici une estimation pour un scénario typique de résolution de problèmes mathématiques :
Hypothèse du scénario : Résolution de 100 problèmes mathématiques de difficulté moyenne par jour, chaque problème consommant en moyenne 500 tokens d'entrée + 1500 tokens de sortie.
| Modèle | Coût d'entrée quotidien | Coût de sortie quotidien | Coût total quotidien | Coût mensuel (30 jours) |
|---|---|---|---|---|
| Gemini 3.1 Pro | 0,10 $ | 1,80 $ | 1,90 $ | 57,00 $ |
| GPT-5.4 | 0,13 $ | 2,25 $ | 2,38 $ | 71,25 $ |
| Claude Sonnet 4.6 | 0,15 $ | 2,25 $ | 2,40 $ | 72,00 $ |
| GPT-5.4 Pro | 1,50 $ | 27,00 $ | 28,50 $ | 855,00 $ |
| DeepSeek R2 | 0,03 $ | 0,33 $ | 0,36 $ | 10,80 $ |
Cette estimation des coûts montre clairement :
- Le coût mensuel de Gemini 3.1 Pro Preview est d'environ 57 $, ce qui en fait le plus économique des trois modèles principaux.
- Les coûts de Claude Sonnet 4.6 et de GPT-5.4 Standard sont similaires, autour de 71-72 $/mois.
- Le coût de GPT-5.4 Pro atteint 855 $/mois, adapté uniquement aux scénarios disposant d'un budget confortable et nécessitant une précision extrême.
- DeepSeek R2 propose une solution très compétitive à un coût ultra-bas de 10,80 $/mois.
Comparaison des indices d'intelligence globale des modèles d'IA pour la résolution de problèmes mathématiques
Au-delà des tests de référence individuels, l'indice d'intelligence globale reflète de manière plus complète le potentiel de raisonnement mathématique d'un modèle. L'Artificial Analysis Intelligence Index est actuellement l'un des systèmes d'évaluation globale les plus reconnus. Il calcule un score composite pour les modèles basé sur quatre dimensions : raisonnement, connaissances, mathématiques et programmation.
| Modèle | Indice d'intelligence globale | AIME 2025 | MATH | GPQA Diamond | ARC-AGI-2 | Évaluation globale |
|---|---|---|---|---|---|---|
| GPT-5.4 (xhigh) | 57 | 100% | 88.6% | 84.2% | 73.3% | Maître des problèmes de compétition, ex æquo au 1er rang de l'indice global |
| Gemini 3.1 Pro Preview | 57 | 92% | 95.1% | 94.3% | 77.1% | Ex æquo au 1er rang de l'indice global, couverture mathématique la plus complète |
| Claude Opus 4.6 | 53 | — | — | 91.3% | — | Capacités de raisonnement scientifique et d'explication au top niveau |
| Claude Sonnet 4.6 (max) | 52 | — | 89% | 74.1% | 58.3% | Excellent rapport qualité-prix, processus de résolution le plus clair |
Du point de vue de l'indice d'intelligence globale, GPT-5.4 (xhigh) et Gemini 3.1 Pro Preview sont ex æquo à la première place avec 57 points, mais leurs points forts diffèrent :
- GPT-5.4 : Performance parfaite (100%) sur des problèmes de compétition comme l'AIME, mais score légèrement inférieur (88.6%) sur le test de référence MATH.
- Gemini 3.1 Pro : Performance plus équilibrée sur le test de référence MATH (95.1%) et le raisonnement scientifique GPQA Diamond (94.3%).
Cela signifie que si vos besoins en mathématiques sont orientés vers les compétitions et les problèmes extrêmement difficiles, GPT-5.4 est le meilleur choix. Si vous avez besoin d'une performance stable couvrant un large éventail de domaines mathématiques, Gemini 3.1 Pro Preview est l'option la plus sûre.
Recommandations par scénario pour les modèles d'IA de résolution de problèmes mathématiques
Différents scénarios d'application mathématique ont des besoins différents en termes de modèles. Voici des recommandations basées sur des cas d'utilisation réels :
Scénarios mathématiques pour choisir Gemini 3.1 Pro Preview
- Plateforme de tutorat mathématique complète : Couvre tous les domaines (algèbre, géométrie, calcul, etc.), capacité globale la plus forte avec MATH à 95.1%.
- Traitement de grands volumes de problèmes mathématiques : Prix le plus bas, système de réflexion à trois niveaux s'adapte automatiquement à la difficulté, réduisant les coûts de traitement.
- Scénarios combinant calcul scientifique : Capacité de raisonnement scientifique GPQA Diamond à 94.3%, adapté aux problèmes combinant physique, chimie et mathématiques.
- Problèmes mathématiques visuels : Avantage des capacités multimodales de Gemini pour traiter les problèmes incluant des diagrammes ou des figures géométriques.
Scénarios mathématiques pour choisir Claude Sonnet 4.6
- Éducation et tutorat mathématique : Processus de résolution le plus clair, le "Learning Mode" guide spécifiquement le raisonnement de l'élève sans donner directement la réponse.
- Apprentissage des étapes de résolution : Scénarios nécessitant de comprendre le "pourquoi". La capacité d'explication de Claude est reconnue comme la meilleure. 70% des utilisateurs préfèrent Sonnet 4.6 à la version précédente 4.5, indiquant une amélioration significative de l'expérience utilisateur.
- Assistance à la recherche mathématique : Adapté aux chercheurs qui ont besoin de processus de dérivation détaillés pour valider leurs idées. La profondeur de réflexion adaptative correspond automatiquement à la complexité du problème.
- Calculs de bureau et financiers : Meilleur de sa catégorie en analyse financière (63.3%), score de productivité bureautique GDPval-AA de 1633 Elo, surpassant même l'Opus 4.6 plus coûteux.
- Combinaison programmation + mathématiques : Capacité en programmation à 79.6%, proche de l'Opus 4.6, adapté aux développeurs ayant besoin d'écrire des programmes de calcul mathématique.
Scénarios mathématiques pour choisir GPT-5.4
- Compétitions mathématiques de haut niveau : Score parfait à l'AIME (100%), modèle de choix pour les problèmes de compétition.
- Raisonnement mathématique sur de longs documents : Fenêtre de contexte de 1.05M, adapté aux problèmes complexes nécessitant beaucoup d'informations de fond mathématiques.
- Recherche mathématique professionnelle : La version précédente GPT-5.2 a établi un nouveau record de 40.3% sur FrontierMath, capacité de pointe en mathématiques avancées.
- Banque d'investissement et finance quantitative : Score élevé de 87.3% aux tâches de modélisation bancaire, adapté aux scénarios de mathématiques financières haut de gamme.
Stratégie d'utilisation mixte : La meilleure combinaison de modèles pour la résolution de problèmes
Dans des environnements de production réels, de nombreuses équipes adoptent une stratégie d'utilisation mixte pour obtenir les meilleurs résultats :
Stratégie 1 : Routage par niveau de difficulté
- Problèmes de base (arithmétique, équations simples) → Mode "Low" de Gemini 3.1 Pro, coût minimum.
- Problèmes de difficulté moyenne (raisonnement à plusieurs étapes, problèmes appliqués) → Mode adaptatif de Claude Sonnet 4.6, processus de résolution clair.
- Problèmes de haute difficulté (compétition, preuves) → Mode "Thinking" de GPT-5.4, précision maximale.
Stratégie 2 : Vérification croisée
- Résoudre d'abord rapidement avec Gemini 3.1 Pro (coût faible, vitesse élevée).
- Vérifier les résultats clés une seconde fois avec GPT-5.4 (précision élevée).
- Reformuler avec Claude Sonnet 4.6 si une explication à l'utilisateur est nécessaire (expression claire).
🚀 Conseil de mise en œuvre : Les stratégies d'utilisation mixte ci-dessus peuvent être facilement implémentées via la plateforme APIYI apiyi.com. Une seule clé API permet d'appeler tous les modèles, il suffit de changer le paramètre
modeldans le code.
Recommandations de décision pour les modèles d'IA de résolution de problèmes mathématiques
En synthétisant l'analyse ci-dessus, voici les recommandations de décision pour différents groupes d'utilisateurs :
| Type d'utilisateur | Modèle recommandé | Raison de la recommandation |
|---|---|---|
| Étudiants/Autodidactes | Claude Sonnet 4.6 | Processus de résolution clair, mode "Learning" qui guide la réflexion |
| Développeurs de plateformes éducatives | Gemini 3.1 Pro Preview | Capacités globales les plus fortes, prix le plus bas, réflexion à trois niveaux adaptée à la difficulté |
| Participants/Entraîneurs de concours | GPT-5.4 | Score parfait à l'AIME, capacité de résolution de problèmes de niveau compétitif la plus forte |
| Chercheurs scientifiques | Gemini 3.1 Pro Preview | GPQA Diamond 94.3%, capacités interdisciplinaires (science + maths) en tête |
| Traitement par lots en entreprise | Gemini 3.1 Pro Preview | Meilleur rapport qualité-prix, prix d'entrée de 2,00 $/1M tokens |
| Équipes de finance quantitative | GPT-5.4 | Modélisation bancaire d'investissement 87.3%, le plus fort pour les scénarios de mathématiques financières |
💡 Conseil de choix : Le choix du modèle d'IA pour résoudre des problèmes mathématiques dépend principalement de votre scénario d'application spécifique. Si vous n'êtes pas sûr du modèle le plus adapté, nous vous recommandons de tester les trois modèles sur la plateforme APIYI (apiyi.com) avec le même problème mathématique, puis de faire votre choix final en fonction de la qualité de la résolution et de la vitesse de réponse. La plateforme prend en charge un appel d'interface unifié, facilitant la comparaison rapide et le changement de modèle.
Autres modèles de résolution de problèmes mathématiques dignes d'intérêt
Outre les trois principaux modèles mentionnés ci-dessus, voici quelques autres modèles d'IA de résolution de problèmes mathématiques qui méritent l'attention dans des scénarios spécifiques :
| Nom du modèle | AIME 2025 | Avantage principal | Prix API (entrée/sortie) | Scénario adapté |
|---|---|---|---|---|
| DeepSeek R2 | Bat Gemini 3.1 Pro | Rapport qualité-prix ultime | 0,55 $/2,19 $ par 1M | Traitement par lots de problèmes mathématiques sensible au budget |
| Claude Opus 4.6 | — | GPQA 91,3%, explications les plus approfondies | 15 $/75 $ par 1M | Recherche haut de gamme et raisonnement profond |
| Qwen3-235B | 89,2% | Le plus fort en open source | Coût de déploiement propre | Scénarios nécessitant un déploiement privé |
| DeepSeek R1 | ~87,5% | Référence open source, architecture MoE 671B | Coût de déploiement propre | Recherche communautaire open source et développement secondaire |
| MiMo-V2-Flash | 94,1% | Coût de raisonnement seulement 2,5% de celui de Claude | Extrêmement bas | Raisonnement à très grande échelle et à faible coût |
Parmi ceux-ci, DeepSeek R2 mérite une attention particulière : il a battu Gemini 3.1 Pro Preview à l'AIME, pour un prix d'environ 1/4 de celui de ce dernier. Si votre scénario de résolution de problèmes mathématiques est extrêmement sensible au budget, DeepSeek R2 est un choix très compétitif.
Quant à MiMo-V2-Flash, il a atteint un score élevé de 94,1% à l'AIME 2025, avec un coût de raisonnement représentant seulement 2,5% de celui de Claude, ce qui le rend très adapté aux plateformes EdTech nécessitant un traitement par lots à grande échelle de problèmes mathématiques.
Techniques d'optimisation des invites pour les modèles d'IA de résolution de problèmes mathématiques
Quel que soit le modèle choisi, une bonne invite peut améliorer significativement la qualité de la résolution. Voici des techniques d'invite pour la résolution de problèmes mathématiques qui ont fait leurs preuves :
- Préciser le type de problème : Indiquer dans l'invite « Il s'agit d'un problème de combinatoire » ou « C'est un problème de géométrie analytique » pour aider le modèle à adopter la bonne stratégie de résolution.
- Demander une résolution étape par étape : Ajouter « Veuillez dériver étape par étape, en indiquant le théorème ou la formule utilisé à chaque étape » pour améliorer la lisibilité du processus.
- Spécifier le format de sortie : Par exemple, « Veuillez sortir les formules mathématiques au format LaTeX » ou « Encadrer la réponse finale ».
- Fournir des contraintes contextuelles : Comme « Supposons que x soit un entier positif » ou « Résoudre dans l'ensemble des nombres réels » pour éviter que le modèle ne produise des discussions de cas inutiles.
- Validation croisée multi-modèles : Pour les résultats clés, vérifier la cohérence des réponses avec différents modèles pour augmenter la confiance.
Questions fréquentes
Q1 : Les résultats des benchmarks des modèles d’IA pour la résolution de problèmes mathématiques sont-ils fiables ?
Les benchmarks fournissent une base de comparaison standardisée, mais l'efficacité réelle dépend également de facteurs tels que le type de problème et la qualité de l'invite. AIME et MATH sont actuellement les références les plus autorisées pour le raisonnement mathématique, largement reconnues par les milieux académiques et industriels. Il est recommandé de tester et de valider avec vos propres problèmes réels, tout en vous référant aux données des benchmarks.
Q2 : Je suis étudiant, quel modèle d’IA pour la résolution de problèmes mathématiques dois-je choisir ?
Nous recommandons Claude Sonnet 4.6 en premier choix. Son processus de résolution est le plus clair, avec une explication raisonnée explicite à chaque étape, ce qui est idéal pour apprendre et comprendre la démarche de résolution. La fonction "Learning Mode" d'Anthropic peut également vous guider à réfléchir par vous-même, plutôt que de donner directement la réponse. Si vous rencontrez un problème de compétition particulièrement difficile, vous pouvez passer à GPT-5.4 pour obtenir de l'aide.
Q3 : Comment commencer rapidement à tester ces modèles d’IA pour la résolution de problèmes mathématiques ?
Nous recommandons d'utiliser une plateforme d'agrégation d'API prenant en charge une interface unifiée pour plusieurs modèles :
- Visitez APIYI sur apiyi.com pour créer un compte
- Obtenez une clé API et un crédit de test gratuit
- Utilisez l'exemple de code Python fourni dans cet article, modifiez simplement le paramètre
modelpour basculer entre les différents modèles - Testez les trois modèles avec le même problème mathématique et comparez la qualité de la résolution et la vitesse de réponse
Q4 : Ces modèles d’IA pour la résolution de problèmes mathématiques prennent-ils en charge la sortie de formules en LaTeX ?
Les trois modèles prennent en charge la sortie de formules mathématiques au format LaTeX. Ajoutez simplement « Veuillez sortir toutes les formules mathématiques au format LaTeX » à votre invite. Gemini 3.1 Pro et GPT-5.4 formatent le LaTeX de manière plus standardisée, tandis que Claude Sonnet 4.6 fournit des explications textuelles plus détaillées entre les formules. Pour les scénarios nécessitant de copier directement des formules dans un article, nous recommandons d'utiliser Gemini ou GPT.
Q5 : Les modèles d’IA pour la résolution de problèmes mathématiques peuvent-ils traiter des problèmes à partir d’images ?
Gemini 3.1 Pro Preview et GPT-5.4 prennent tous deux en charge l'entrée multimodale, vous permettant de télécharger directement une image contenant un problème mathématique pour obtenir une réponse. Gemini excelle particulièrement dans le traitement d'images contenant des figures géométriques et des formules manuscrites. Claude Sonnet 4.6 prend également en charge l'entrée d'images, mais est légèrement inférieur à Gemini dans la reconnaissance de figures géométriques complexes. Si vos problèmes mathématiques apparaissent souvent sous forme d'images (comme pour une recherche par photo), Gemini 3.1 Pro Preview est le meilleur choix.
Conclusion
Points clés pour choisir un modèle d'IA pour la résolution de problèmes mathématiques :
- Meilleur choix polyvalent : Gemini 3.1 Pro Preview : Leader global avec MATH à 95,1 %, prix optimal à 2,00 $/1M de tokens, système de réflexion à trois niveaux s'adaptant flexiblement aux différentes difficultés.
- Meilleur choix pour l'apprentissage : Claude Sonnet 4.6 : Capacités mathématiques améliorées de 27 points de pourcentage pour atteindre 89 %, étapes de résolution claires, profondeur de réflexion adaptative équilibrant coût et qualité.
- Meilleur choix pour les compétitions difficiles : GPT-5.4 : Score parfait de 100 % à l'AIME 2025, contexte ultra-long de 1,05 million de tokens, capacités de raisonnement de haute difficulté inégalées.
Aucun modèle n'est la solution optimale dans tous les scénarios mathématiques. Le paysage concurrentiel des modèles d'IA pour la résolution de problèmes mathématiques en 2026 peut se résumer ainsi :
- Couverture polyvalente : Gemini 3.1 Pro Preview, avec MATH à 95,1 % et le prix le plus bas, occupe la position de premier choix polyvalent.
- Éducation et apprentissage : Claude Sonnet 4.6, grâce à une amélioration mathématique de 27 points de pourcentage et des capacités d'explication de résolution inégalées, devient le meilleur choix pour les scénarios éducatifs.
- Compétitions extrêmes : GPT-5.4, avec sa performance absolue d'un score parfait à l'AIME, est inégalé dans le domaine des compétitions mathématiques de haute difficulté.
- Priorité au budget : DeepSeek R2 offre des capacités de raisonnement mathématique comparables à un prix inférieur au quart de celui de Gemini.
La stratégie la plus intelligente consiste à choisir le modèle adapté à vos besoins réels, voire à utiliser plusieurs modèles de manière mixte pour des problèmes de difficultés différentes, en tirant pleinement parti des avantages uniques de chaque modèle.
Nous recommandons de tester et de comparer rapidement ces modèles via APIYI sur apiyi.com. La plateforme offre un crédit gratuit et une interface API unifiée, permettant un accès unique pour invoquer facilement tous les principaux modèles de raisonnement mathématique, facilitant ainsi la mise en œuvre d'une stratégie d'utilisation mixte de plusieurs modèles.
📚 Références
-
Fiche technique Google DeepMind Gemini 3.1 Pro : Données de référence officielles et détails techniques
- Lien :
deepmind.google/models/model-cards/gemini-3-1-pro/ - Description : Contient les résultats complets des tests de référence et les spécifications de l'architecture
- Lien :
-
Notes de version Anthropic Claude Sonnet 4.6 : Détails sur l'amélioration des capacités de raisonnement mathématique
- Lien :
docs.anthropic.com - Description : Contient les données comparatives de Sonnet 4.6 avec la version précédente et l'explication du mécanisme de pensée adaptative
- Lien :
-
Annonce de sortie OpenAI GPT-5.4 : Fonctionnalités du dernier modèle et données de référence
- Lien :
openai.com/index/introducing-gpt-5-4/ - Description : Contient les résultats complets des tests de référence de GPT-5.4 et l'explication de la configuration du raisonnement
- Lien :
-
Évaluation de modèles par Artificial Analysis : Plateforme de comparaison de référence tierce indépendante
- Lien :
artificialanalysis.ai/evaluations/aime-2025 - Description : Fournit des classements et analyses indépendants pour les tests de référence comme AIME 2025
- Lien :
-
Classement du test de référence AIME 2025 : Comparaison faisant autorité des capacités de raisonnement mathématique
- Lien :
vals.ai/benchmarks/aime - Description : Données du classement des tests de référence en raisonnement mathématique pour l'IA, mises à jour en continu
- Lien :
Auteur : Équipe technique APIYI
Échanges techniques : N'hésitez pas à partager votre expérience d'utilisation de l'IA pour la résolution de problèmes mathématiques dans les commentaires. Pour plus de tutoriels sur l'invocation des modèles, visitez le centre de documentation APIYI à docs.apiyi.com