El 1 de junio de 2026, MiniMax lanzó oficialmente su nuevo modelo insignia de código abierto: MiniMax-M3. Es el primer modelo de pesos abiertos en la industria que logra tres hitos en una sola arquitectura: capacidades de programación de vanguardia, una ventana de contexto de 1 millón de tokens y entrada multimodal nativa. En el benchmark SWE-Bench Pro, obtuvo una puntuación de 59.0, superando directamente a GPT-5.5 y Gemini 3.1 Pro, y acercándose peligrosamente al rendimiento de Claude Opus 4.7.
Lo que resulta aún más impactante es su precio. El precio oficial estándar es de $0.60 por entrada y $2.40 por salida por cada millón de tokens, lo cual ya representa solo entre el 5% y el 10% de los modelos cerrados de su misma categoría. Además, durante el periodo de lanzamiento, se aplica un descuento adicional del 50%, reduciendo el costo a $0.30 por entrada y $1.20 por salida. Actualmente, MiniMax-M3 ya está disponible en la plataforma APIYI (apiyi.com), alineándose con el descuento del 50% del sitio oficial. Al sumar las bonificaciones por recarga, el costo real puede reducirse hasta un 41% adicional. Esta promoción es válida hasta la medianoche del 8 de junio (UTC+8).
En este artículo, desglosaremos los puntos fuertes de la arquitectura de MiniMax-M3, sus resultados en benchmarks, su estructura de precios y el código de integración, para ayudarte a decidir si vale la pena migrar durante este periodo promocional.

¿Qué es MiniMax-M3?: El buque insignia "tres en uno" del ecosistema abierto
MiniMax-M3 es la nueva generación insignia de MiniMax tras la serie M2, posicionándose como un modelo de propósito general orientado a la programación y escenarios de agentes. Utiliza una arquitectura MoE (Mezcla de Expertos) de grano fino, con un total de aproximadamente 229.9B de parámetros, de los cuales solo se activan unos 9.8B por token, distribuidos entre 256 expertos. Esto significa que, en términos de costos de inferencia, se acerca más a un modelo pequeño de 10B, pero con capacidades que compiten con los modelos insignia de primer nivel.
El volumen de datos de entrenamiento es de aproximadamente 100 billones de tokens, y desde la fase de preentrenamiento se integraron datos intercalados de texto e imagen. Por lo tanto, la capacidad multimodal de MiniMax-M3 es "nativa": la comprensión de imágenes y videos está integrada directamente en el espacio semántico, en lugar de ser un codificador visual externo añadido posteriormente. Además de la entrada de imágenes y videos, admite el uso de computadoras de escritorio (Computer Use), dejando interfaces abiertas para escenarios de agentes.
La empresa se ha comprometido a liberar completamente los pesos del modelo y el informe técnico dentro de los 10 días posteriores al lanzamiento. Estarán disponibles en HuggingFace y GitHub, permitiendo el despliegue privado y el ajuste fino (fine-tuning). Siguiendo la licencia MIT modificada utilizada en la serie M2, se espera que la barrera para el uso comercial sea muy baja, aunque los detalles finales dependerán de la licencia oficial publicada.
Resumen de especificaciones clave de MiniMax-M3
| Dimensión | Especificación de MiniMax-M3 |
|---|---|
| Fecha de lanzamiento | 1 de junio de 2026 |
| Arquitectura | MoE de grano fino, 229.9B parámetros totales / 9.8B activos, 256 expertos |
| Mecanismo de atención | MSA (MiniMax Sparse Attention) |
| Ventana de contexto | 1,000,000 tokens (aprox. 5 veces la serie M2) |
| Soporte multimodal | Entrada de texto + imagen + video, salida de texto, soporte para operaciones de escritorio |
| Datos de entrenamiento | Aprox. 100T tokens, corpus multimodal intercalado |
| Modo de razonamiento | Modo "Thinking" activable, precio consistente |
| Plan de código abierto | Pesos e informe técnico disponibles en 10 días |
🎯 Sugerencia para una prueba rápida: Si quieres verificar el nivel real de MiniMax-M3 de inmediato, no hace falta esperar a que se liberen los pesos para construir tu propio clúster. Recomendamos realizar la invocación directamente a través de la interfaz compatible con OpenAI de APIYI (apiyi.com), utilizando el nombre de modelo
MiniMax-M3. Podrás realizar pruebas comparativas en cuestión de minutos y, durante el periodo de actividad, reducir el costo a la mitad.
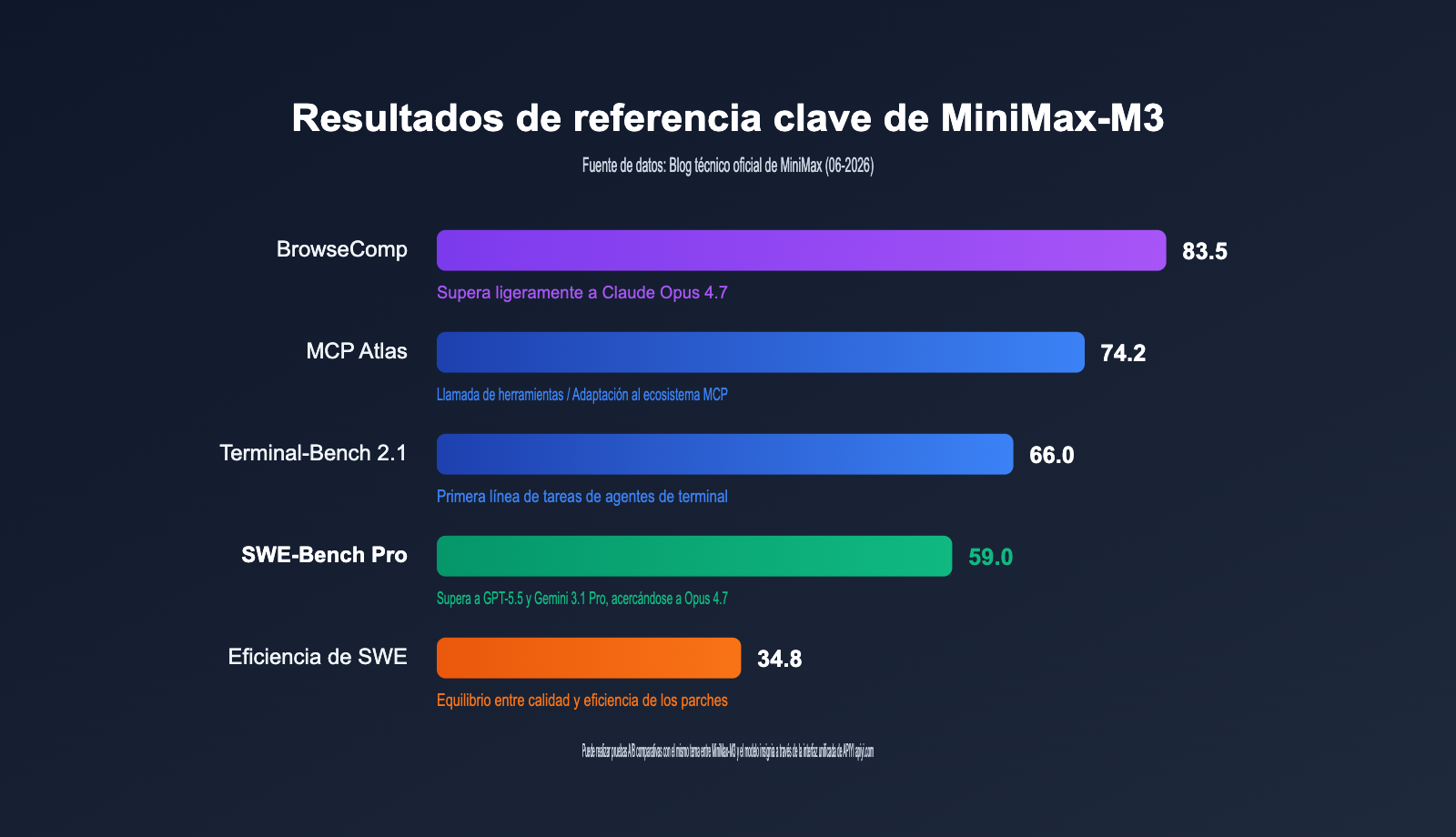
¿Qué significa que MiniMax-M3 obtenga 59.0 puntos en el benchmark SWE-Bench Pro?
SWE-Bench Pro es reconocido actualmente como uno de los benchmarks de ingeniería de software real más exigentes, ya que evalúa la capacidad de un modelo para corregir errores y escribir parches en repositorios reales de extremo a extremo. MiniMax-M3 alcanzó una puntuación de 59.0; los datos comparativos oficiales muestran que este resultado supera tanto a GPT-5.5 como a Gemini 3.1 Pro, quedando a solo un paso de Claude Opus 4.7. Para un modelo que pronto será de código abierto y cuenta con menos de 10B de parámetros activos, este es un hito histórico: es la primera vez que el sector del código abierto supera a los modelos cerrados de referencia en este benchmark.
Más allá de la programación, los indicadores relacionados con agentes son igualmente impresionantes. Obtuvo 66.0 puntos en Terminal-Bench 2.1, 74.2 puntos en MCP Atlas y 83.5 puntos en tareas de navegación autónoma con BrowseComp (este último superando ligeramente a Claude Opus 4.7). En el ámbito multimodal, superó a Opus 4.7 en SVG-Bench y obtuvo mejores resultados que Gemini 3.1 Pro en el benchmark de comprensión de documentos OmniDocBench.
Por supuesto, no es una victoria absoluta. En PostTrainBench, que evalúa la capacidad de post-entrenamiento científico, MiniMax-M3 obtuvo 0.37, por debajo del 0.42 de Claude Opus 4.7 y a la par con el 0.39 de GPT-5.5. Un recordatorio importante: estas cifras provienen principalmente del blog técnico oficial; las pruebas independientes de terceros aún están en curso, por lo que, para aplicaciones críticas, recomendamos realizar sus propias evaluaciones.
Comparativa de MiniMax-M3 frente a los modelos insignia actuales
| Benchmark | MiniMax-M3 | Conclusión comparativa |
|---|---|---|
| SWE-Bench Pro | 59.0 | Supera a GPT-5.5 y Gemini 3.1 Pro, se acerca a Opus 4.7 |
| Terminal-Bench 2.1 | 66.0 | Primera línea en tareas de agentes de terminal |
| BrowseComp | 83.5 | Supera ligeramente a Claude Opus 4.7 |
| MCP Atlas | 74.2 | Gran capacidad de invocación de herramientas y adaptación al ecosistema MCP |
| SWE-fficiency | 34.8 | Equilibrio entre calidad de parches y eficiencia |
| PostTrainBench | 0.37 | Inferior a Opus 4.7 (0.42), a la par con GPT-5.5 (0.39) |
Si deseas verificar estas cifras de forma transversal, puedes usar la plataforma APIYI para realizar invocaciones simultáneas a MiniMax-M3, GPT-5.5 y Claude Opus 4.7 con la misma indicación. La plataforma unifica el formato de la interfaz y cambiar de modelo solo requiere modificar un parámetro, lo que la hace ideal para pruebas A/B.
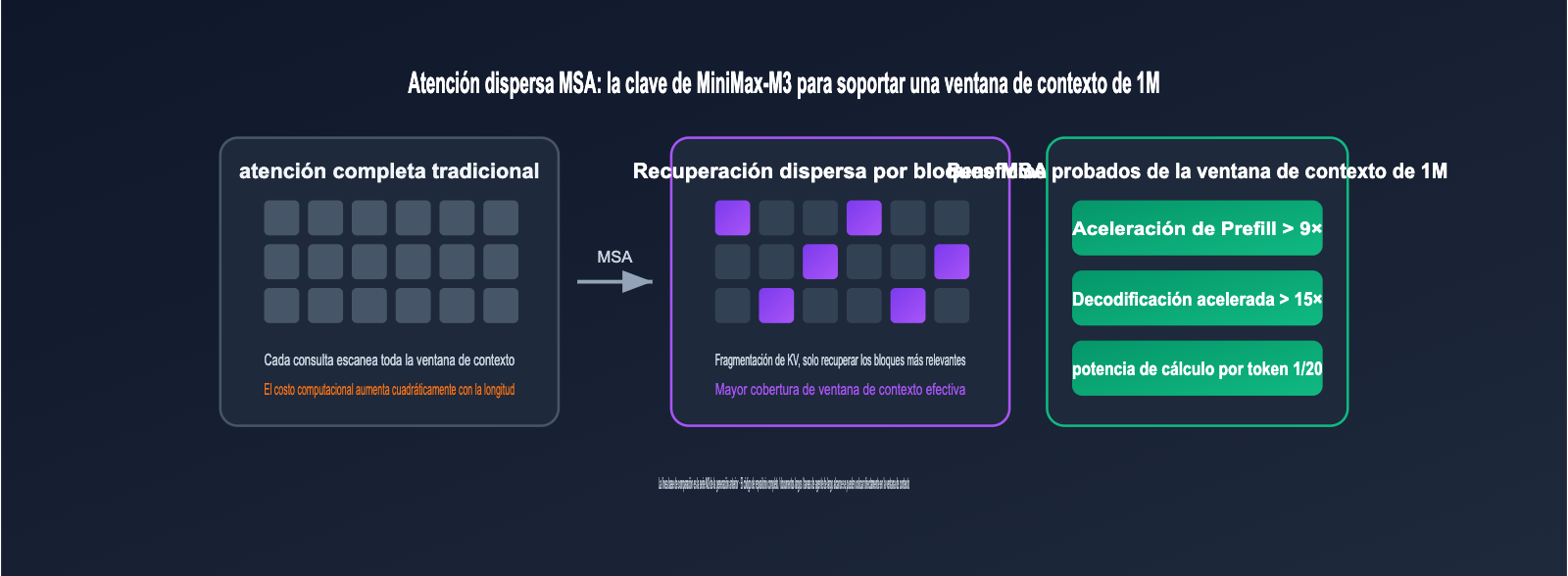
Análisis de la arquitectura de MiniMax-M3: Cómo la atención dispersa MSA permite una ventana de contexto de 1M
Una ventana de contexto de 1 millón de tokens no es algo extraño, lo extraño es hacer que sea económicamente viable. La respuesta de MiniMax-M3 es su MSA (MiniMax Sparse Attention) de desarrollo propio. El cálculo de la atención total tradicional crece de forma cuadrática con la longitud del contexto, mientras que MSA divide la caché KV en bloques y cada consulta (query) recupera con precisión solo los bloques KV más relevantes, logrando una mayor cobertura efectiva del contexto.
Los datos de ingeniería proporcionados oficialmente son bastante agresivos: con una ventana de contexto de 1M de tokens, el cálculo por token de MiniMax-M3 es solo 1/20 del de la generación anterior M2; la velocidad de prellenado (prefill) aumenta más de 9 veces, y la de decodificación (decode) más de 15 veces; a nivel de operador, es 4 veces más rápido que el Flash-Sparse-Attention de código abierto. En otras palabras, insertar todo un repositorio de código, cientos de páginas de PDF o una hora de video de reunión en el contexto ya no implica latencias o costos prohibitivos.
Para los desarrolladores, esto significa directamente que muchas tareas de documentos largos que antes requerían fragmentación RAG, recuperación vectorial o resúmenes de varias rondas, ahora pueden procesarse directamente en una sola indicación. Las tareas de agentes de larga duración tampoco requieren comprimir el historial con frecuencia, lo que mejora significativamente la coherencia de la tarea.
💡 Consejo para pruebas de contexto largo: La facturación del contexto de 1M se divide en dos niveles; el precio unitario se duplica al superar los 512K de entrada. Recomendamos probar primero el rendimiento con documentos reales de nivel 200K-400K en el panel de control de APIYI (apiyi.com). Una vez confirmada la calidad, puede proceder con entradas más largas; las estadísticas de uso de la plataforma le ayudarán a calcular con precisión el costo de tokens de cada invocación.
Precio de la API de MiniMax-M3: 50% de descuento por tiempo limitado + recargas que bajan el costo hasta un 41%
El modelo de precios de MiniMax-M3 utiliza una estructura escalonada basada en la longitud de entrada. Las entradas de 0 a 512K tokens se cobran bajo la tarifa estándar, mientras que las que superan los 512K utilizan la tarifa de ventana de contexto larga. Durante el periodo de lanzamiento, todo el servicio tiene un 50% de descuento. APIYI (apiyi.com) ya ha alineado sus precios con este descuento oficial. La promoción es válida hasta la medianoche del 8 de junio de 2026 (UTC+8); las políticas de descuento posteriores están por definirse.
Tabla de precios de la API de MiniMax-M3 (por cada 1M de tokens)
| Nivel de facturación | Entrada (precio actual con 50% desc.) | Salida (precio actual con 50% desc.) | Precio estándar tras promoción (Entrada/Salida) |
|---|---|---|---|
| Entrada 0-512K | $0.30 | $1.20 | $0.60 / $2.40 |
| Entrada > 512K | $0.60 | $2.40 | $1.20 / $4.80 |
Para poner este precio en perspectiva: realizar una tarea de revisión de código de un millón de tokens con un modelo insignia de código cerrado podría costar más de diez dólares, mientras que con el precio promocional de MiniMax-M3 solo costaría unos pocos centavos; una diferencia de costo de 10 a 20 veces. Para flujos de trabajo de agentes de alta frecuencia, migraciones masivas de código o procesamiento de documentos largos, este ahorro puede cubrir el costo de una máquina de desarrollo en un solo mes.
En la plataforma APIYI, el costo puede reducirse aún más. Las promociones de recarga de la plataforma se pueden combinar con el descuento del 50% del modelo, lo que permite obtener un costo real de hasta un 41% del precio original. Si tu equipo ya tiene un volumen de invocación del modelo estable, realizar una recarga antes del 8 de junio es la opción más rentable.

Guía rápida de la API de MiniMax-M3: Conéctate en 5 minutos
MiniMax-M3 utiliza el protocolo estándar compatible con OpenAI en la plataforma APIYI, por lo que cualquier SDK, framework o cliente que admita un base_url personalizado puede conectarse sin problemas. El único detalle a tener en cuenta: el nombre del modelo MiniMax-M3 distingue entre mayúsculas y minúsculas; la M debe ser mayúscula. Si escribes minimax-m3, recibirás un error indicando que el modelo no existe.
La conexión se realiza en tres pasos: regístrate en APIYI (apiyi.com) y crea una clave API; apunta el base_url a https://api.apiyi.com/v1; y en el parámetro model escribe MiniMax-M3. Aquí tienes un ejemplo sencillo en Python:
from openai import OpenAI
client = OpenAI(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com/v1" # Interfaz unificada de APIYI
)
response = client.chat.completions.create(
model="MiniMax-M3", # Nota: distingue mayúsculas, la M debe ser mayúscula
messages=[
{"role": "user", "content": "Implementa una función de Fibonacci con caché LRU en Python"}
]
)
print(response.choices[0].message.content)
Cuando necesites enviar imágenes o videos, simplemente utiliza el formato de mensaje multimodal de OpenAI, cambiando el content por una matriz que incluya image_url. MiniMax-M3 completará la comprensión visual y la generación de código en la misma sesión. Para herramientas de agentes como Cline, Cursor u OpenClaw, solo necesitas cambiar el base_url y el nombre del modelo en la configuración para reemplazar la base de tu asistente de programación con MiniMax-M3.
Consulta rápida de casos de uso para MiniMax-M3
| Escenario | Adaptabilidad | Descripción |
|---|---|---|
| Programación con agentes / Corrección automática de errores | ⭐⭐⭐⭐⭐ | SWE-Bench Pro 59.0, no pierde contexto en tareas largas |
| Análisis y migración de repositorios de código | ⭐⭐⭐⭐⭐ | 1M de ventana de contexto permite albergar repositorios medianos completos |
| Análisis de documentos largos / multimodales | ⭐⭐⭐⭐⭐ | OmniDocBench supera a Gemini 3.1 Pro |
| Agente de navegación autónoma y llamada a herramientas | ⭐⭐⭐⭐ | BrowseComp 83.5, MCP Atlas 74.2 |
| Entrenamiento posterior científico / Razonamiento avanzado | ⭐⭐⭐ | PostTrainBench inferior a Opus 4.7, se recomienda enrutamiento mixto |
El enrutamiento mixto es el enfoque más realista: deja que MiniMax-M3 maneje el 80% del volumen de llamadas para tareas diarias de codificación y documentos, y reserva las tareas de razonamiento más complejas para Claude Opus 4.7 o GPT-5.5. A través de la interfaz unificada de APIYI, puedes implementar esta estrategia de "rentabilidad estratificada" con un solo código, sin necesidad de gestionar claves API y SDKs de múltiples proveedores.
Preguntas frecuentes sobre MiniMax-M3
P1: ¿Cuándo termina la promoción del 50% de descuento de MiniMax-M3?
La promoción finaliza el 8 de junio de 2026 a las 00:00 (UTC+8), sincronizada entre la plataforma APIYI y el sitio web oficial de MiniMax. Aún no se ha anunciado la política de precios posterior, pero, como es habitual, es probable que se restablezcan las tarifas estándar. Si tienes planes de realizar invocaciones masivas, te recomendamos recargar antes de la fecha límite; al combinarlo con los bonos de recarga, el costo real puede bajar hasta un 41% del precio original.
P2: ¿Es MiniMax-M3 realmente de código abierto? ¿Se pueden descargar los pesos ahora?
La empresa se comprometió a liberar los pesos del modelo y el informe técnico dentro de los 10 días posteriores al lanzamiento, los cuales se esperan en la página de MiniMaxAI en HuggingFace. Hasta la fecha de publicación de este artículo, los pesos aún no se han subido. Los equipos que no puedan esperar para realizar su propia implementación pueden usar la API para verificar los resultados y, una vez que se publiquen los pesos, evaluar la inversión en hardware para la privatización, ya que, al ser un modelo MoE de 230B de parámetros totales, los requisitos de VRAM para el despliegue local no son menores.
P3: ¿El contexto de 1M es solo marketing o es realmente funcional?
La arquitectura MSA hace que el contexto de 1M sea realmente utilizable a nivel de ingeniería: la velocidad de prefill aumenta más de 9 veces, la de decode 15 veces, y el costo computacional por token se reduce a 1/20 en comparación con la generación anterior. Sin embargo, ten en cuenta los niveles de facturación: el precio unitario se duplica una vez que la entrada supera los 512K. Recomendamos controlar la longitud del contexto según las necesidades reales de la tarea en lugar de llenarlo sin criterio.
P4: ¿Cómo elegir entre MiniMax-M3, GPT-5.5 y Claude Opus 4.7?
Depende del tipo de tarea y del presupuesto. En escenarios de agentes de programación, contextos largos y documentos multimodales, la relación costo-beneficio de MiniMax-M3 actualmente no tiene rival. Para tareas de razonamiento complejo de alto nivel y de investigación científica, Opus 4.7 sigue teniendo ventaja. Recomendamos realizar pruebas comparativas a pequeña escala en la plataforma APIYI utilizando tus propias indicaciones (prompts) de negocio; los datos serán mucho más convincentes que cualquier tabla de clasificación.
Resumen: MiniMax-M3 lleva las capacidades de un modelo insignia a un "precio de ganga"
El lanzamiento de MiniMax-M3 ha sido una verdadera bomba en el mercado de modelos de 2026: pesos de código abierto, superación de GPT-5.5 en SWE-Bench Pro con 59.0 puntos, 1 millón de tokens de contexto y capacidades multimodales nativas, todo con un precio oficial que es solo del 5% al 10% de los modelos insignia de código cerrado. Incluso si las pruebas de terceros ajustan ligeramente algunas puntuaciones más adelante, su dominio en la dimensión de "relación costo-beneficio" será difícil de superar.
Lo más inteligente a corto plazo es aprovechar la ventana de precios: el 50% de descuento por tiempo limitado ($0.30 por entrada / $1.20 por salida por cada 1M de tokens) finaliza el 8 de junio a medianoche. En APIYI (apiyi.com), al combinarlo con las promociones de recarga, puedes obtener un descuento efectivo de hasta el 41%. Ejecutar tus pruebas con el mínimo costo posible antes de decidir si migrar el tráfico de producción es la estrategia más segura en este momento.
Para detalles sobre la actividad y las últimas actualizaciones del modelo, puedes consultar el anuncio oficial de APIYI: docs.apiyi.com/news/minimax-m3-launch
Autor: Equipo de APIYI
Especialistas en agregación de API de Modelos de Lenguaje Grande y mejores prácticas. Para más evaluaciones de modelos y guías de integración, visita APIYI en apiyi.com.