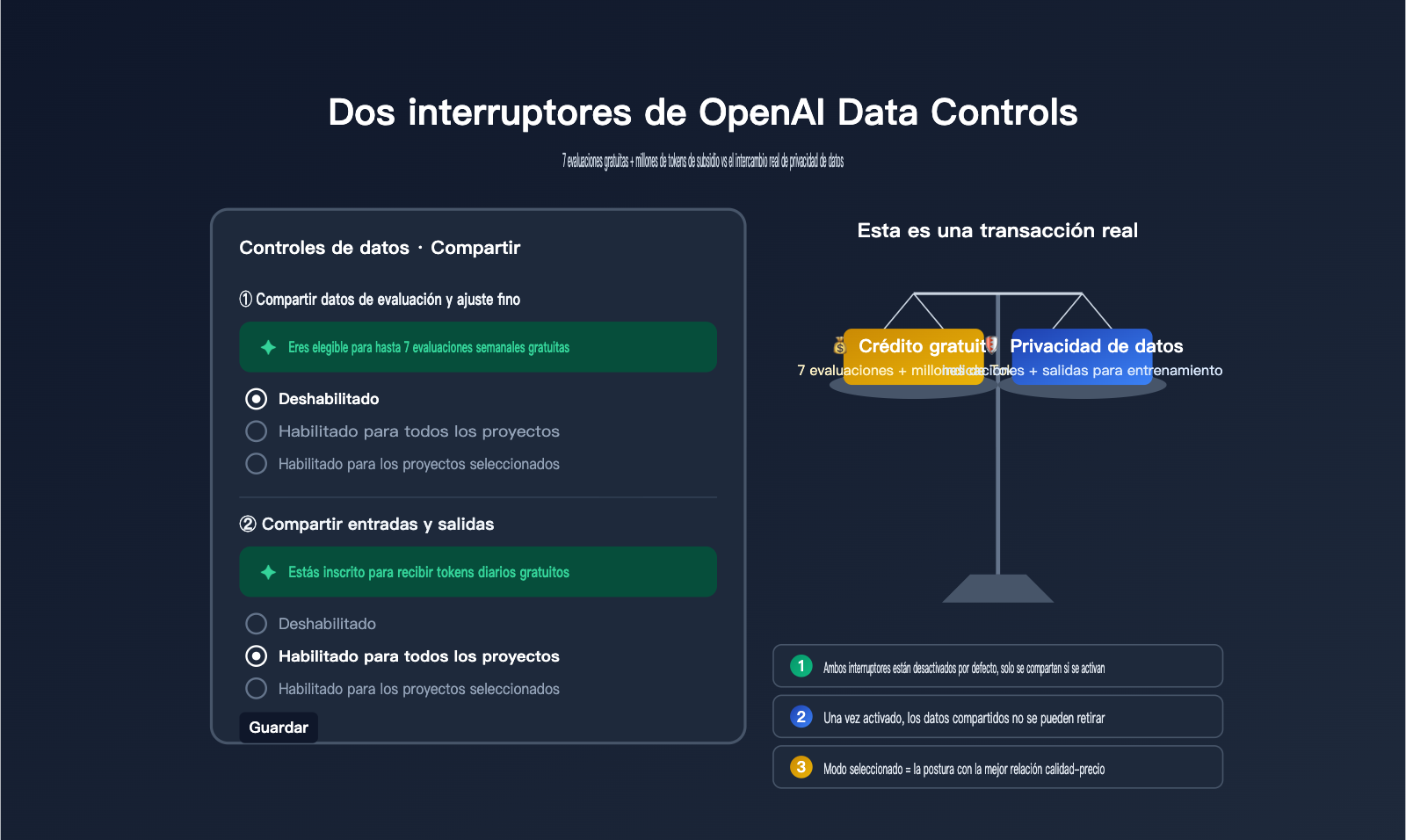
Recientemente, un cliente nos preguntó sobre la página "Data Controls" en el panel de control de OpenAI. Al entrar, se encontró con dos interruptores: "Share evaluation and fine-tuning data with OpenAI" (Compartir datos de evaluación y ajuste fino con OpenAI) y "Share inputs and outputs with OpenAI" (Compartir entradas y salidas con OpenAI). Cada uno tiene tres opciones: Desactivado, Activado para todos los proyectos o Activado para proyectos seleccionados. El primero muestra un aviso en verde: "You're eligible for up to 7 free weekly evals" (Eres elegible para hasta 7 evaluaciones semanales gratuitas), mientras que el segundo indica: "You're enrolled for complimentary daily tokens" (Estás inscrito para recibir tokens diarios gratuitos). Parecía que OpenAI estaba regalando recursos, pero el cliente no estaba seguro de si valía la pena activarlos o qué precio tendría hacerlo.
En esencia, estos interruptores representan un intercambio bidireccional donde OpenAI ofrece "créditos gratuitos" a cambio de "datos de entrenamiento/evaluación". El costo de activarlos es real: los datos de evaluación y las entradas/salidas de tu API serán utilizados por OpenAI para mejorar sus futuros modelos. Entre los clientes de APIYI (apiyi.com), hemos visto casos de usuarios que los mantuvieron activos durante medio año antes de darse cuenta de que representaban una brecha de privacidad, y otros que los desactivaron y perdieron millones de tokens gratuitos al día. En este artículo, analizamos la documentación oficial para explicarte el funcionamiento real, las cuotas obtenidas, el impacto en la privacidad y la configuración recomendada.
Definiciones clave de los dos ajustes de OpenAI Data Controls
Al abrir la página Settings → Data Controls → Sharing, verás dos interruptores independientes que a menudo se confunden. Comparten contenidos distintos, ofrecen beneficios diferentes y tienen un impacto en la privacidad de magnitudes totalmente distintas. Entender sus límites es el requisito previo para tomar la decisión correcta.
| Ajuste | Share evaluation and fine-tuning data | Share inputs and outputs |
|---|---|---|
| Contenido compartido | Indicaciones de evaluación + resultados + lógica de calificación + datos de ajuste fino | Todas las entradas y salidas de la invocación del modelo |
| Beneficio gratuito | Hasta 7 ejecuciones de evaluación gratuitas por semana | Créditos diarios de tokens (asignados según el nivel y grupo de modelos) |
| Uso de datos | Mejora del flujo de trabajo de evaluación + entrenamiento de futuros modelos | Uso directo para entrenamiento / mejora de modelos |
| Estado predeterminado | Desactivado | Desactivado |
| Granularidad | Tres niveles: Desactivado / Todo / Seleccionado | Tres niveles: Desactivado / Todo / Seleccionado |
| Permisos | Solo propietario de la organización | Solo propietario de la organización |
| Alcance | Solo se comparten datos generados tras la activación | Solo se comparte tráfico generado tras la activación |
| Facilidad de cierre | Se puede cambiar en cualquier momento | Se puede cambiar en cualquier momento |
🎯 Consejo de comprensión rápida: Si solo buscas "obtener cuotas gratuitas de forma segura", puedes configurar el interruptor en "Enabled for selected projects". Crea un proyecto de prueba independiente para ejecutar scripts de desarrollo o internos, y dirige el tráfico de tus proyectos principales y de producción a través del servicio proxy de API de APIYI (apiyi.com) para evitar exponer todos tus proyectos al canal de entrenamiento de datos de una sola vez.
Análisis detallado de la configuración "Share evaluation and fine-tuning data"
El nombre de este interruptor sugiere "compartir datos de evaluación y ajuste fino", pero el alcance real es más amplio de lo que implica su nombre. Al activarlo, OpenAI no solo recibirá tus indicaciones de evaluación y finalizaciones, sino también la lógica de calificación (criterios de evaluación) que definas y las indicaciones + finalizaciones de tus conjuntos de datos de ajuste fino. Esto significa que OpenAI recopilará cómo calificas al modelo, qué consideras una buena respuesta y el conocimiento especializado presente en tus datos de entrenamiento.
El beneficio es de hasta 7 ejecuciones de evaluación gratuitas por semana. OpenAI especifica en su centro de ayuda que "las evaluaciones que compartes con OpenAI se procesan actualmente sin costo hasta 7 ejecuciones por semana". Si superas este límite o utilizas modelos que no participan en el programa gratuito, se te cobrará según la tarifa estándar de tokens. Esta cifra puede parecer pequeña, pero para equipos que realizan comparaciones frecuentes de modelos, 7 ejecuciones gratuitas a la semana pueden ahorrar cientos de dólares en costos de evaluación.
Es importante destacar que el interruptor solo afecta a los datos generados después de la activación. Los datos históricos no se comparten retroactivamente y, al desactivarlo, no se "retiran" los datos ya compartidos. Por lo tanto, tu decisión debe basarse en "cuántos datos de evaluación planeas compartir en los próximos 6 a 12 meses", no en "qué datos tengo ahora mismo".
| Dimensión | Beneficio de activar | Costo de activar |
|---|---|---|
| Beneficio directo | 7 evaluaciones gratuitas por semana | / |
| Beneficio indirecto | Optimización del flujo de trabajo de evaluación por parte de OpenAI | / |
| Costo de datos | / | Recopilación de indicaciones de evaluación, finalizaciones y estándares de calificación |
| Costo de negocio | / | Fuga de conocimiento especializado (know-how) en conjuntos de datos de ajuste fino |
| Reversibilidad | Se puede desactivar en cualquier momento | Los datos ya compartidos no se pueden retirar |
🎯 ¿Cuándo activar el uso compartido de Eval/FT?: Si tus evaluaciones se basan en benchmarks públicos o conjuntos de pruebas no sensibles, activarlo es prácticamente inofensivo. Si las indicaciones de evaluación contienen datos reales de clientes, reglas de negocio internas o lógica de calificación propietaria, te recomendamos configurarlo en modo "Seleccionado" y activarlo solo para proyectos en entorno de pruebas (sandbox).
Explicación detallada de la configuración de "Compartir entradas y salidas"
Este es uno de los dos interruptores que, aunque conlleva un "mayor coste", también ofrece una recompensa más significativa. Al activarlo, todas las invocaciones del modelo que pasen por este proyecto, tanto la indicación (prompt) de entrada como la finalización (completion) de salida, serán recopiladas por OpenAI y utilizadas para entrenar o mejorar sus modelos. Esto supone una diferencia fundamental respecto al comportamiento predeterminado de la API: desde marzo de 2023, OpenAI especifica que no utiliza los datos de la API para el entrenamiento de modelos, por lo que activar este interruptor equivale a revocar voluntariamente esa protección.
La recompensa consiste en tokens de subsidio diario (complimentary daily tokens), que se distribuyen según el nivel (tier) de la cuenta y el grupo de modelos. Este es el esquema de cuota gratuita más específico publicado por OpenAI, y se restablece automáticamente todos los días a las 00:00 UTC.
| Grupo de modelos | Límite diario Tier 1-2 | Límite diario Tier 3-5 | Hora de reinicio |
|---|---|---|---|
| Grupo de modelos insignia | 250,000 tokens | 1,000,000 tokens | 00:00 UTC |
| Grupo de modelos pequeños | 2,500,000 tokens | 10,000,000 tokens | 00:00 UTC |
La división entre el grupo de modelos insignia y el de modelos pequeños no se basa en una clasificación aproximada de rendimiento, sino en una lista explícita proporcionada por OpenAI; la invocación de modelos que no figuren en dicha lista no contará para la cuota gratuita.
| Grupo de modelos | Modelos incluidos |
|---|---|
| Grupo insignia | gpt-5, gpt-5-codex, gpt-5-chat-latest, gpt-4.5-preview, gpt-4.1, gpt-4o, o1, o3, o1-preview |
| Grupo pequeño | gpt-5-mini, gpt-5-nano, gpt-4.1-mini, gpt-4.1-nano, gpt-4o-mini, o1-mini, o4-mini, codex-mini-latest |
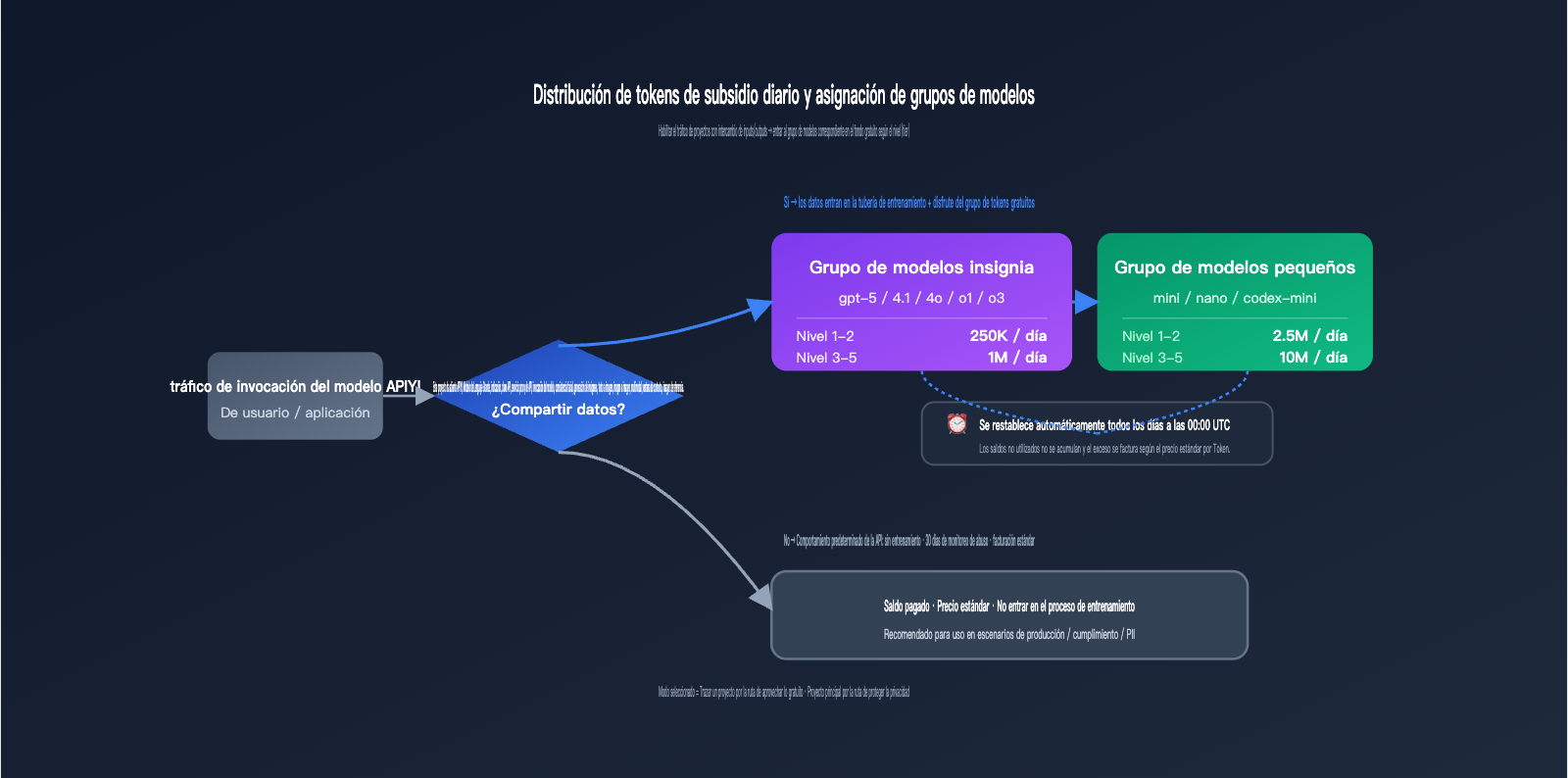
🎯 El valor real de la cuota de tokens: Estimando con gpt-4o-mini a $0.15/M de entrada y $0.60/M de salida, 2.5M de tokens de modelos pequeños al día en el Tier 1-2 equivalen a unos $1-2 de cuota gratuita diaria, lo que supone un ahorro mensual de $30-60. En el Tier 3-5, al subir a 10M de tokens al día, el ahorro mensual puede ser de $120-240. Si el objetivo es solo obtener esta cuota, no resulta rentable activar el tráfico de toda la organización; se recomienda crear un proyecto de prueba independiente y configurarlo en modo "Selected" (Seleccionado).
Diferencias reales entre la privacidad de la API por defecto y tras activar el uso compartido
Muchos equipos no terminan de entender si la API "se utiliza para entrenamiento por defecto". La política real de OpenAI es: la API por defecto no se utiliza para entrenamiento, pero retiene los datos durante 30 días para el monitoreo de abusos (abuse monitoring). La Retención de Datos Cero (ZDR, por sus siglas en inglés) es algo distinto; requiere que los clientes empresariales contacten específicamente al equipo de ventas de OpenAI para solicitarla, no es un interruptor que se activa con un clic en el panel.
Una vez comprendida esta base, el impacto de los dos interruptores es claro: activar Inputs/Outputs significa "renunciar voluntariamente a la protección de entrenamiento vigente desde 2023", y activar Eval/FT significa "contribuir adicionalmente con metodologías de evaluación". Ninguno de los dos afecta la retención de 30 días para monitoreo de abusos, ni son compatibles con ZDR.
| Dimensión | API por defecto (ambos apagados) | Activar Inputs/Outputs | Activar Eval/FT Data |
|---|---|---|---|
| ¿Se usa para entrenamiento? | ❌ No se entrena | ✅ Se usa para entrenamiento | ✅ Entrenamiento + evaluación |
| Retención monitoreo abuso | 30 días | 30 días | 30 días |
| ¿Se pueden retirar datos? | / | ❌ No se pueden retirar | ❌ No se pueden retirar |
| ¿Compatible con ZDR? | ✅ Se puede solicitar ZDR | ❌ Incompatible con el interruptor | ❌ Incompatible con el interruptor |
| Escenario ideal | Producción / Cumplimiento / PII | dev / pruebas / datos públicos | Evaluación de benchmarks públicos |
🎯 Recomendación de privacidad: Si tu negocio tiene requisitos de cumplimiento sobre privacidad de datos (GDPR, HIPAA, NDA corporativos, PII de clientes, etc.), ambos interruptores deben permanecer desactivados. Además, canaliza el tráfico altamente sensible a través de un servicio proxy de API como APIYI (apiyi.com) o solicita ZDR. Si solo se trata de proyectos personales, herramientas internas o demostraciones de Hackathon, puedes activarlos con confianza para todos los proyectos.
Marco de decisión: 4 puntos para evaluar si activar los controles de datos de OpenAI
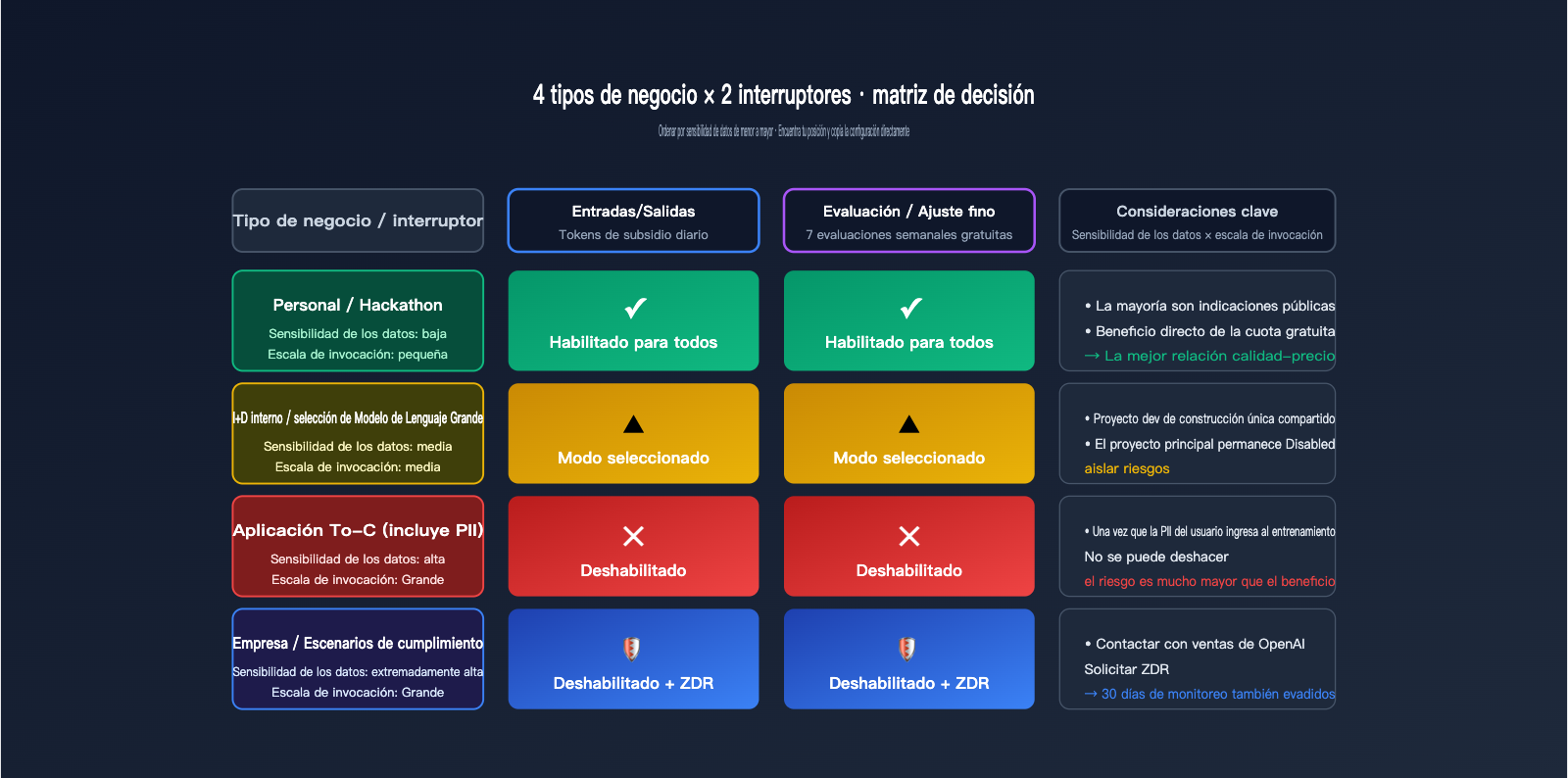
Dar una respuesta binaria de "activar o no" es demasiado simplista. Utilicemos una matriz con 4 escenarios de negocio típicos, donde cada uno tiene una configuración razonable. Las dimensiones clave para la decisión son dos: sensibilidad de los datos (si el contenido maneja privacidad o secretos comerciales) y escala de invocación (cuánto valor real obtienes de las cuotas gratuitas).
| Tipo de negocio | Sensibilidad de datos | Recomendación Inputs/Outputs | Recomendación Eval/FT |
|---|---|---|---|
| Desarrollo personal / Hackathon | Baja | Activado para todos | Activado para todos |
| I+D interno / Selección de modelos | Media | Activado para seleccionados | Activado para seleccionados |
| Aplicaciones To-C (con PII) | Alta | Desactivado o Seleccionados (proyectos dev) | Desactivado |
| Empresa / Escenarios de cumplimiento | Muy alta | Desactivado + usar ZDR | Desactivado |
La primera categoría son proyectos personales o de Hackathon. En estos casos, el consumo de tokens proviene principalmente de indicaciones públicas (como retos de programación o código de demostración). Activar el uso compartido permite obtener subsidios diarios sin exponer información sensible, lo que ofrece la mejor relación costo-beneficio. La segunda categoría es I+D interno; se recomienda el modo "Seleccionado": crea un proyecto específico llamado "data-share-test" para ejecutar experimentos compartibles, mientras mantienes el proyecto de desarrollo principal desactivado.
La tercera categoría son las aplicaciones To-C, que a menudo involucran entradas de usuario, historial de chat e información personal. En estos casos, se recomienda desactivar ambos interruptores; la cuota gratuita no compensa el riesgo de que la PII del usuario termine en la tubería de entrenamiento. La cuarta categoría son escenarios empresariales o de cumplimiento, como clientes de salud, finanzas o gobierno; estos deben utilizar ZDR o un servicio proxy de API como APIYI (apiyi.com) para evitar incluso la retención de 30 días por monitoreo de abusos.
🎯 Cómo elegir entre las opciones: Si decides activar algún interruptor, prioriza "Enabled for selected projects" en lugar de "Enabled for all projects". De esta forma, puedes reservar un proyecto específico para "entrenamiento elegible" destinado a desarrollo o pruebas, manteniendo los proyectos de producción aislados. Así, cualquier ajuste futuro solo afectará a ese proyecto y el costo de migración será mínimo.
Preguntas frecuentes sobre los controles de datos de OpenAI
P1: ¿OpenAI tomará todos mis datos históricos inmediatamente después de activar Inputs/Outputs?
No. Ambos interruptores especifican claramente: "Only traffic sent after turning this setting on will be shared" / "Only evaluation and fine-tuning data created after turning this setting on will be shared". Los interruptores solo afectan a los datos generados después de su activación; los datos históricos no se comparten retroactivamente.
P2: ¿Los tokens gratuitos son lo mismo que los créditos (Credit Grants)?
No son lo mismo, pero están relacionados. Lo que se obtiene al compartir Inputs/Outputs es un "fondo diario de tokens", que se reinicia automáticamente a las 00:00 UTC. Los "centavos" que aparecen en la sección de Credit Grants de OpenAI son el registro contable posterior de ese fondo, convertido a valor en dólares según el uso. Puedes entenderlo como dos formas de visualizar el mismo proyecto.
P3: Si activo el modo "Selected" para compartir solo un proyecto, ¿el tráfico del proyecto principal está totalmente seguro?
Totalmente seguro. En la interfaz de configuración de OpenAI, puedes seleccionar con precisión qué proyectos participan en el intercambio. El tráfico de los proyectos no seleccionados se procesa según el comportamiento estándar de la API: no se entrena y se conserva durante 30 días para monitoreo de abuso. Si aún tienes preocupaciones, puedes desviar el tráfico del proyecto principal a través de un servicio proxy de API como APIYI (apiyi.com) para lograr un aislamiento arquitectónico total.
P4: ¿Cómo se cuentan exactamente las "7 free weekly evals" (evaluaciones gratuitas semanales)?
Se cuentan por "número de ejecuciones", no por cantidad de tokens. Cada vez que ejecutas una evaluación (independientemente de cuántas muestras proceses) cuenta como una, con un máximo de 7 gratuitas por semana. Una vez superado el límite, se factura según el precio estándar de tokens del modelo utilizado. Algunos modelos no están en la lista gratuita, por lo que su ejecución siempre tendrá costo.
P5: Si desactivo Inputs/Outputs, ¿puedo recuperar los datos que ya fueron recopilados?
No. La política de OpenAI establece claramente que los datos ya compartidos no se pueden retirar. Desactivar el interruptor solo impide que los datos futuros entren en el proceso de entrenamiento. Por eso siempre recomendamos usar un servicio proxy de API como APIYI (apiyi.com) para el tráfico de producción, logrando un "aislamiento estricto": por defecto, los datos ni siquiera entran en el proceso de entrenamiento de OpenAI, lo cual es mucho más fiable que intentar "desactivarlo después".
3 conclusiones sobre los controles de datos de OpenAI
Primero, estos dos interruptores son un "intercambio bidireccional" real: utilizas datos reales y cuantificables (metodología de evaluación, entradas y salidas de la API) a cambio de beneficios cuantificables (7 evaluaciones gratuitas por semana, millones de tokens diarios). Entender que esto es una transacción y no un regalo gratuito evitará que tomes decisiones equivocadas.
Segundo, la API predeterminada no entrena modelos, pero el monitoreo de abuso de 30 días sigue vigente. Si tu negocio tiene requisitos de cumplimiento de privacidad, ambos interruptores deben estar desactivados y debes aplicar una restricción adicional mediante ZDR o un servicio proxy de API como APIYI (apiyi.com). Los interruptores solo deciden si se autoriza el entrenamiento adicional, no si el tráfico es monitoreado.
Tercero, prioriza el modo "Selected" para el "aislamiento por proyecto". Crea un proyecto independiente dedicado exclusivamente a tráfico de desarrollo o pruebas para compartir y mantener el proyecto de producción y los datos sensibles completamente aislados. Esta es la estrategia con mejor relación costo-beneficio: obtienes los beneficios gratuitos sin que ni un solo dato de usuario fluya hacia el proceso de entrenamiento.
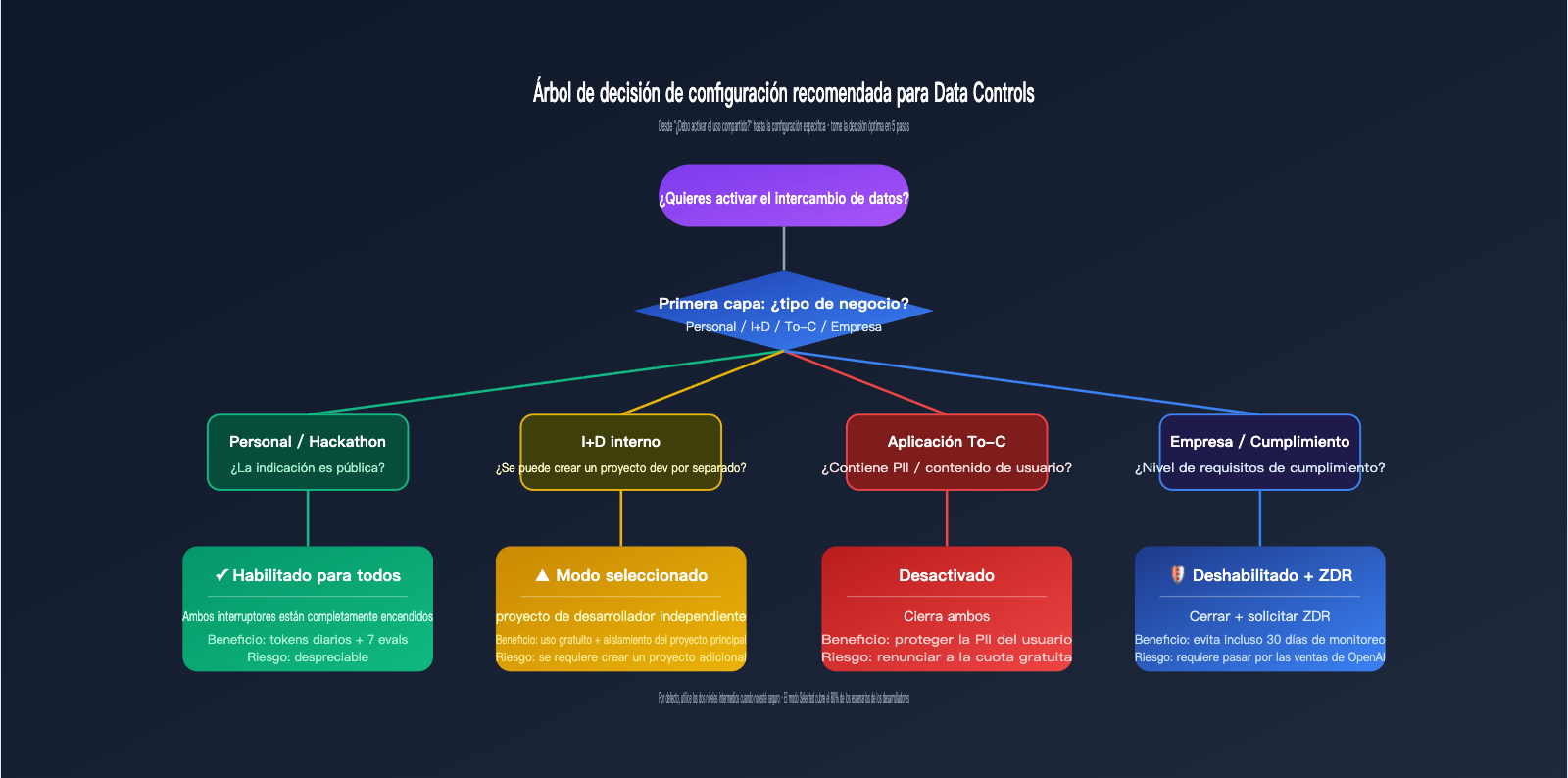
Si estás evaluando estos dos interruptores, la postura más segura es clasificar tu uso en cuatro categorías (Personal / Interno / To-C / Empresa), decidir el nivel y luego usar el modo "Selected" para crear un proyecto de prueba independiente para obtener los beneficios gratuitos, mientras diriges el tráfico de producción a través de un servicio proxy de API como APIYI (apiyi.com) para el aislamiento arquitectónico. De esta manera, puedes disfrutar de la política gratuita de OpenAI sin comprometer la privacidad de los datos de tus usuarios ni tu know-how empresarial.
📌 Autor: Equipo técnico de APIYI — Seguimos de cerca los cambios en las políticas clave de OpenAI, como Data Controls, ZDR y estrategias de facturación, para ofrecer a los desarrolladores una experiencia de API multimodal unificada, con facturación centralizada y privacidad controlada. Para más información, visita APIYI en apiyi.com.