Nota del autor: La serie mini más reciente de OpenAI, gpt-5.4-mini, ya está disponible vía API. Con un 54.4% en SWE-Bench Pro, supera el 45.7% del GPT-5 mini. Este artículo analiza en profundidad su salto de capacidad, el descuento del 90% en la entrada de caché y la estrategia de actualización frente a los modelos 4o-mini y 5-mini.
Si todavía utilizas gpt-4o-mini o gpt-5-mini, es posible que hayas notado que OpenAI lanzó el 17 de marzo de 2026 el que llaman "nuestro modelo mini más potente hasta la fecha": gpt-5.4-mini. Ha obtenido un 54.4% en SWE-Bench Pro (frente al 45.7% del GPT-5 mini), un 60.0% en Terminal-Bench 2.0 y un 72.1% en OSWorld-Verified para tareas de Computer Use, todo ello con una velocidad de respuesta el doble de rápida que la generación anterior.
Aunque parece una actualización menor, su intención de diseño va mucho más allá. OpenAI ha posicionado oficialmente al gpt-5.4-mini como un modelo mini "optimizado para programación, Computer Use y subagentes", marcando la primera vez que la serie mini traslada capacidades agénticas a un rango de precio de entrada. En este artículo, desglosaremos qué es realmente el GPT-5.4 mini, en qué supera a los modelos 4o-mini y 5-mini, y qué significa esto para tu trabajo diario.
Valor central: Un análisis completo de la solución de acceso al GPT-5.4 mini, cubriendo el salto de capacidad, la estructura de precios, la optimización de caché y los criterios de actualización frente a la serie mini anterior.

Puntos clave de la API de GPT-5.4 mini
| Punto | Descripción | Valor |
|---|---|---|
| Salto de capacidad | SWE-Bench Pro 54.4% vs GPT-5 mini 45.7% | Mejora del 19% en precisión de tareas de codificación |
| Contexto largo de 400K | 400,000 tokens de entrada + 128,000 de salida | Procesamiento integral de bases de código / documentos largos |
| 90% dto. en caché | Entrada en caché por solo $0.075/1M | Reducción drástica de costes en escenarios de contexto frecuente |
| Computer Use | OSWorld-Verified 72.1% | Soporte completo para automatización de escritorio en serie mini |
| Abierto por defecto | Disponible en grupos de APIYI | Uso inmediato para nuevos usuarios, sin necesidad de solicitud |
Diferencias clave entre GPT-5.4 mini y la generación anterior
GPT-5.4 mini no es simplemente una "versión con precio reducido". OpenAI ha realizado mejoras sustanciales en tres dimensiones:
Primero, la orquestación de subagentes llega por primera vez al segmento mini. En el pasado, era casi imposible que un modelo mini coordinara de forma fiable múltiples subtareas o gestionara cadenas de llamadas a herramientas; solían perder el contexto o ignorar instrucciones después de 3-4 pasos. Gracias a un mecanismo reforzado de Reasoning Tokens y entrenamiento en seguimiento de instrucciones, el GPT-5.4 mini alcanza una fiabilidad del 90% respecto a la versión estándar de GPT-5.4 en escenarios de colaboración multi-agente, con un coste de solo 1/6.
Segundo, soporte completo para Computer Use. GPT-5.4 mini es el primer modelo de la serie mini de OpenAI que eleva el rendimiento en OSWorld-Verified por encima del 70%. Esto significa que puedes desplegar agentes de automatización de escritorio completos a precio mini para realizar clics, rellenar formularios y manipular archivos.
Tercero, velocidad de respuesta 2x más rápida. Al mantener el salto de capacidad, el GPT-5.4 mini es el doble de rápido que el GPT-5 mini. Para escenarios de alto rendimiento (atención al cliente, procesamiento por lotes), esto se traduce en un ahorro directo de costes.

Inicio rápido con la API de GPT-5.4 mini
Ejemplo minimalista en Python (reemplazo de modelos mini antiguos)
Si anteriormente utilizabas gpt-4o-mini o gpt-5-mini, solo necesitas modificar el parámetro model para cambiar a gpt-5.4-mini. El resto del código permanece intacto:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-5.4-mini", # Solo cambia esta línea
messages=[
{"role": "user", "content": "Implementa en Python una caché concurrente que soporte eliminación LRU"}
]
)
print(response.choices[0].message.content)
Ejemplo minimalista con cURL
curl https://vip.apiyi.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY" \
-d '{
"model": "gpt-5.4-mini",
"messages": [
{"role": "user", "content": "Resume los puntos clave de este documento largo"}
]
}'
Paradigma de invocación para Computer Use (soporte por primera vez en la serie mini)
# Habilitar la herramienta Computer Use
response = client.chat.completions.create(
model="gpt-5.4-mini",
messages=[{
"role": "user",
"content": "Ayúdame a abrir el navegador, busca 'Documentación de la API de OpenAI' y haz clic en el primer resultado"
}],
tools=[{
"type": "computer_use",
"config": {
"screen_width": 1920,
"screen_height": 1080
}
}]
)
# El modelo devuelve instrucciones de operación estructuradas (click/type/scroll, etc.)
for action in response.choices[0].message.tool_calls:
print(f"Acción: {action.function.name}, Parámetros: {action.function.arguments}")
Ver código de invocación completo para entorno de producción (incluye seguimiento de aciertos de caché y estadísticas de costos)
import openai
from typing import List, Dict
# Precios de GPT-5.4 mini (por cada 1M de tokens)
PRICE_INPUT = 0.75
PRICE_INPUT_CACHED = 0.075 # Precio con acierto de caché (90% de descuento)
PRICE_OUTPUT = 4.50
def call_gpt54_mini(
messages: List[Dict],
api_key: str,
max_tokens: int = 4096
) -> Dict:
"""
Invocación de GPT-5.4 mini a nivel de producción, con seguimiento de tasa de aciertos de caché
"""
client = openai.OpenAI(
api_key=api_key,
base_url="https://vip.apiyi.com/v1"
)
try:
response = client.chat.completions.create(
model="gpt-5.4-mini",
messages=messages,
max_tokens=max_tokens
)
usage = response.usage
input_tokens = usage.prompt_tokens
output_tokens = usage.completion_tokens
# Tokens de caché (depende de la versión del SDK)
cached_tokens = getattr(usage, 'prompt_tokens_details', {}).get('cached_tokens', 0)
regular_input = input_tokens - cached_tokens
# Facturación segmentada
input_cost = (
regular_input / 1_000_000 * PRICE_INPUT +
cached_tokens / 1_000_000 * PRICE_INPUT_CACHED
)
output_cost = output_tokens / 1_000_000 * PRICE_OUTPUT
total_cost = input_cost + output_cost
cache_rate = cached_tokens / max(input_tokens, 1) * 100
print(f"📊 Entrada: {input_tokens:,} | Aciertos de caché: {cached_tokens:,} ({cache_rate:.1f}%)")
print(f"📊 Salida: {output_tokens:,} tokens")
print(f"💰 Costo de esta ejecución: ${total_cost:.4f}")
print(f"💰 Ahorro por caché: ${(cached_tokens / 1_000_000 * (PRICE_INPUT - PRICE_INPUT_CACHED)):.4f}")
return {
"content": response.choices[0].message.content,
"tokens": {
"input": input_tokens,
"cached": cached_tokens,
"output": output_tokens
},
"cost_usd": total_cost,
"cache_hit_rate": cache_rate
}
except openai.RateLimitError:
return {"error": "Límite de tasa alcanzado, reintente más tarde"}
except openai.APIError as e:
return {"error": f"Error de API: {str(e)}"}
# Ejemplo de uso
result = call_gpt54_mini(
messages=[
{"role": "system", "content": "Eres un ingeniero senior de Python"},
{"role": "user", "content": "Ayúdame a revisar los problemas de seguridad de concurrencia en este código..."}
],
api_key="YOUR_API_KEY"
)
print(result["content"])
🎯 Consejo de inicio rápido: GPT-5.4 mini ya está totalmente abierto en el grupo predeterminado de APIYI; los nuevos usuarios pueden invocarlo directamente sin necesidad de solicitar acceso. Se recomienda conectarse a través de la plataforma APIYI apiyi.com, donde al recargar 100 USD obtienes un 10% adicional, lo que equivale a un descuento del 15% respecto al sitio oficial, con conexión directa desde China sin necesidad de VPN y total compatibilidad con el SDK de OpenAI.
Detalles de precios de la API de GPT-5.4 mini
Estructura de precios oficial
El precio de GPT-5.4 mini es ligeramente superior al de la serie mini anterior, pero mediante el mecanismo de caché se puede reducir significativamente el costo real:
| Tipo de facturación | Precio (por 1M de tokens) | Nota |
|---|---|---|
| Entrada | $0.75 | Precio estándar |
| Entrada en caché | $0.075 | 90% de descuento, gran ahorro |
| Salida | $4.50 | Incluye tokens de razonamiento |
| Entrada Batch API | $0.75 | Igual al precio estándar |
| Endpoint de residencia de datos | +10% | Escenarios de cumplimiento de datos |
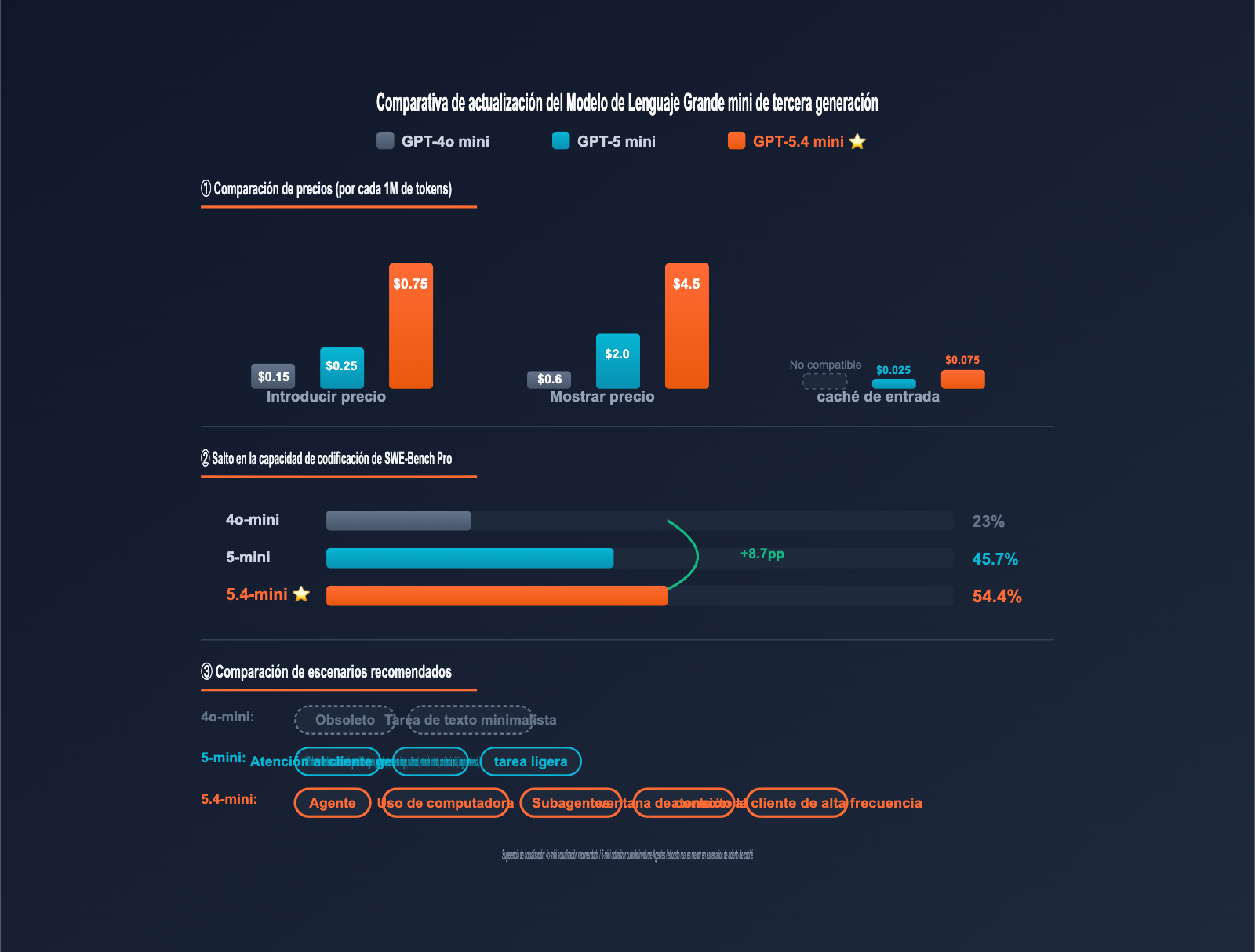
Comparativa de precios de la serie mini (3 generaciones)
| Modelo | Precio de entrada | Entrada en caché | Precio de salida | Ventana de contexto | Salida máxima |
|---|---|---|---|---|---|
| GPT-4o mini | $0.15 | No soportado | $0.60 | 128K | 16K |
| GPT-5 mini | $0.25 | $0.025 | $2.00 | 400K | 128K |
| GPT-5.4 mini | $0.75 | $0.075 | $4.50 | 400K | 128K |
⚠️ Observación importante: El precio estándar de GPT-5.4 mini es 5 veces el de GPT-4o mini y 3 veces el de GPT-5 mini. Sin embargo, considere dos hechos clave: 1) Al activar la caché, el costo por ejecución puede bajar hasta $0.0075/1M (en ciertos escenarios de alta frecuencia), y 2) el salto en capacidad a menudo elimina la necesidad de múltiples rondas de depuración, reduciendo el número total de invocaciones.
Cálculo de costos en escenarios con aciertos de caché
El descuento del 90% en caché de GPT-5.4 mini es la característica más subestimada de esta actualización:
| Escenario | Tokens de entrada | Tasa de aciertos de caché | Costo real por ejecución |
|---|---|---|---|
| Atención al cliente de alta frecuencia (reutilización de system prompt) | 5K | 80% | $0.0046 |
| Asistente de código (reutilización de contexto) | 50K | 70% | $0.034 |
| Preguntas sobre documentos largos (reutilización de documentos) | 200K | 90% | $0.030 |
| Orquestación de subagentes (instrucciones compartidas) | 30K | 85% | $0.0162 |
💰 Consejo de optimización de caché: El mecanismo de caché de GPT-5.4 mini funciona mejor en escenarios con system prompt largo + contexto repetitivo. Para casos de uso como atención al cliente, asistentes de código y preguntas sobre documentos largos, el costo real puede ser incluso menor que el de GPT-5 mini. Puede reducir aún más su factura aprovechando la promoción de recarga del 10% en APIYI apiyi.com.
Salto en las capacidades de la API de GPT-5.4 mini
Comparativa de rendimiento
| Dimensión de evaluación | GPT-4o mini | GPT-5 mini | GPT-5.4 mini | Mejora |
|---|---|---|---|---|
| SWE-Bench Pro (codificación) | ~23% | 45.7% | 54.4% | +8.7pp |
| Terminal-Bench 2.0 | ~30% | ~50% | 60.0% | +10pp |
| OSWorld-Verified (uso de computadora) | No soportado | ~58% | 72.1% | +14pp |
| Velocidad de respuesta | Base | Base | 2x mejora | Doble |
Análisis de la actualización de capacidades
SWE-Bench Pro 54.4%: Este es el dato más destacado de GPT-5.4 mini. Un 54.4% se acerca mucho al 57.7% de la versión estándar de GPT-5.4, pero a un costo de solo 1/6 parte. Para tareas como la corrección de problemas reales en GitHub o la refactorización de bases de código, el modelo mini es ahora una opción sumamente fiable.
Terminal-Bench 60.0%: Esto significa que el modelo mini puede completar con éxito más del 60% de las tareas relacionadas con la ejecución de comandos en terminal, depuración y flujos de trabajo automatizados. Al combinarlo con la orquestación de subagentes, es posible construir aplicaciones robustas de automatización CI/CD o bots de revisión de código.
OSWorld 72.1%: Representa un avance histórico para la serie mini en tareas de "uso de computadora" (Computer Use). Ahora es posible desplegar agentes de automatización de escritorio a un costo asequible para gestionar formularios, clics y operaciones con archivos.
Comparativa: GPT-5.4 mini vs. modelos de su misma categoría
| Modelo | Entrada / Salida | Ventana de contexto | Capacidad de codificación | Computer Use | Escenarios recomendados |
|---|---|---|---|---|---|
| GPT-4o mini | $0.15 / $0.60 | 128K | Débil | No compatible | Obsoleto, tareas simples |
| GPT-5 mini | $0.25 / $2.00 | 400K | Media | Soporte parcial | Atención al cliente general, tareas ligeras |
| GPT-5.4 mini | $0.75 / $4.50 | 400K | Fuerte | Soporte completo | Agentes / Computer Use / Contexto largo |
| GPT-5.4 Estándar | $5.00 / $30.00 | 1M | Top | Top | Razonamiento complejo, decisiones críticas |
| Claude Haiku 4.5 | $0.80 / $4.00 | 200K | Fuerte | No compatible | Estilo de redacción / Escritura |
Recomendaciones para la toma de decisiones de actualización
4o-mini → 5.4-mini: GPT-4o mini sigue teniendo una ventaja de precio en tareas de texto simples. Sin embargo, sus capacidades se han quedado significativamente atrás; si tu aplicación implica razonamiento, codificación o una ventana de contexto larga, vale la pena actualizar a 5.4-mini. Incluso calculando un precio unitario 5 veces mayor, la mejora en la calidad y el número de invocaciones del modelo suele compensar la inversión.
5-mini → 5.4-mini: GPT-5 mini sigue siendo competente en tareas de atención al cliente general y traducción. Pero si necesitas Computer Use, orquestación de Subagentes o flujos de trabajo de Agentes complejos, 5.4-mini es la opción obligatoria. Además, aunque el descuento por caché se mantiene en el 90%, el valor absoluto es mayor, lo que resulta más rentable a largo plazo.
5.4-mini → 5.4 Estándar: GPT-5.4 mini tiene capacidades similares en el 80% de las tareas rutinarias, pero a un precio de solo 1/6. Solo cuando la tarea realmente requiera un razonamiento de nivel superior (pruebas matemáticas, Agentes complejos de 20 horas), será necesario cambiar a la versión estándar.
📊 Sugerencia de ruta de actualización: A través de APIYI (apiyi.com), puedes comparar sin problemas el rendimiento real de GPT-4o mini, 5-mini, 5.4-mini y 5.4 Estándar bajo la misma clave API, simplemente modificando el parámetro
model. Este método de acceso unificado es ideal para equipos que necesitan realizar migraciones graduales o pruebas A/B.
Escenarios de aplicación de la API de GPT-5.4 mini
La combinación de "alta capacidad + optimización de caché + Computer Use + Subagentes" de GPT-5.4 mini es ideal para los siguientes escenarios:
- Atención al cliente de alto volumen: Alta tasa de aciertos en caché, respuesta rápida y una profundidad de razonamiento suficiente para manejar problemas complejos.
- Generación de contenido a gran escala: Resúmenes, traducciones y reescrituras por lotes; su ventana de contexto de 400K permite procesar documentos completos de una sola vez.
- Colaboración de múltiples Agentes (Subagentes): Por primera vez se logra una orquestación de subtareas fiable en el segmento de precio "mini".
- Agentes de automatización de escritorio: Con un 72.1% en OSWorld, hace posible la operación en navegadores, formularios y archivos.
- Autocompletado y revisión de código ligero: Con un 54.4% en SWE-Bench Pro, se acerca a la versión estándar, siendo ideal para la integración en IDEs.
- Procesamiento de documentos por lotes: Al combinar Batch API y caché, ofrece una ventaja de costos extrema para el procesamiento de miles de documentos.
- Herramientas de tutoría educativa: El aumento en los tokens de razonamiento proporciona capacidades más fiables para la resolución de problemas y la asistencia académica.
🎯 Decisión de escenario: Si tu aplicación realiza más de 10,000 invocaciones al día, tiene una tasa de aciertos en caché superior al 50% y requiere capacidades de razonamiento o herramientas, GPT-5.4 mini es el modelo "mini" más recomendable para cambiar en 2026. Puedes acceder directamente a través de APIYI (apiyi.com); no se requiere ninguna solicitud para el grupo
Default.
Instrucciones de acceso a GPT-5.4 mini en APIYI
Estrategia de apertura del grupo Default
La plataforma APIYI adopta para GPT-5.4 mini una estrategia de apertura consistente con Grok 4.3, diferenciándose de la de GPT-5.5 Pro:
- ✅ Grupo Default (Predeterminado): Acceso total, disponible para nuevos usuarios desde el registro.
- ✅ Grupo SVIP (Premium): Acceso total, sin restricciones.
- ✅ Sincronización de descuentos por caché: Precio de caché de $0.075/1M totalmente aplicable.
¿Por qué GPT-5.4 mini está abierto en todos los grupos, mientras que GPT-5.5 Pro es solo para SVIP? La clave reside en la evaluación de riesgos por invocación:
- GPT-5.4 mini: El coste por invocación suele ser de unos pocos centavos, por lo que abrirlo a todos los grupos no conlleva riesgos.
- GPT-5.5 Pro: Una sola invocación puede costar varios dólares, por lo que requiere la protección del grupo SVIP para evitar usos accidentales por parte de usuarios novatos.
Este diseño de gestión por niveles de riesgo permite que la serie mini mantenga una barrera de entrada baja para todos los desarrolladores, mientras que los modelos de alto valor cuentan con protección de grupo.
Comparativa de costes: APIYI vs. Sitio oficial
| Ítem | Sitio oficial OpenAI | APIYI apiyi.com |
|---|---|---|
| Precio base | $0.75 / $4.50 por 1M | $0.75 / $4.50 por 1M (mismo precio) |
| Descuento por caché | $0.075 / 1M (90%) | $0.075 / 1M (totalmente sincronizado) |
| Bonificación de recarga | Ninguna | Recarga $100 y recibe $10 (10%) |
| Coste real | 100% precio estándar | aprox. 90% precio estándar (aprox. 15% de ahorro) |
| Acceso desde China | Requiere VPN | Conexión directa, sin VPN |
| Métodos de pago | Tarjetas internacionales | Soporta RMB, Alipay, WeChat |
| Compatibilidad SDK | Nativo de OpenAI | Totalmente compatible con SDK de OpenAI |
| Restricciones de grupo | Ninguna | Default + SVIP acceso total |
💰 Optimización de costes: Al acceder a GPT-5.4 mini a través de APIYI apiyi.com, la recarga de 100 USD con un 10% de regalo equivale a un ahorro del 15% respecto al precio oficial, con descuentos de caché totalmente sincronizados. Para aplicaciones con alto volumen de llamadas y alta tasa de aciertos en caché, el coste total puede ser un 20% inferior al del sitio oficial de OpenAI.
Preguntas frecuentes (FAQ)
Q1: ¿Qué es GPT-5.4 mini? ¿Cuál es la diferencia principal con GPT-5 mini y GPT-4o mini?
GPT-5.4 mini es el modelo mini de nueva generación lanzado por OpenAI el 17-03-2026, posicionado como "nuestro modelo mini más potente hasta la fecha". Diferencias clave: 1) SWE-Bench Pro con 54.4%, superando significativamente a GPT-5 mini (45.7%) y 4o-mini (23%); 2) Soporte completo por primera vez para Computer Use (OSWorld 72.1%); 3) Capacidades de orquestación de subagentes en el rango de precio mini; 4) Velocidad de respuesta 2x más rápida que 5 mini. Aunque el precio aumentó a $0.75/$4.50, el uso de caché puede compensar parte del coste.
Q2: Actualmente uso gpt-4o-mini / gpt-5-mini, ¿vale la pena actualizar a 5.4-mini?
Usuarios de 4o-mini: se recomienda encarecidamente actualizar. La brecha de capacidad es demasiado grande; incluso calculando un precio unitario 5 veces mayor, la calidad general y la reducción en las iteraciones de depuración suelen hacerlo más rentable.
Usuarios de 5-mini: depende del escenario:
- ✅ Se recomienda actualizar: Aplicaciones que involucren Computer Use, subagentes, cadenas de herramientas complejas o contexto largo (>200K).
- ⏸️ Se puede seguir usando: FAQ de atención al cliente simple, traducción ligera, generación de texto puro, etc., donde 5-mini ya es suficiente.
Mejor práctica: realice pruebas A/B con la misma clave API en APIYI apiyi.com para comprobar cuál es más rentable.
Q3: ¿Cómo se activa el descuento de caché de $0.075/1M en GPT-5.4 mini?
El mecanismo de caché de OpenAI se activa automáticamente, sin necesidad de parámetros adicionales. Cuando el prefijo de tu indicación (normalmente el system prompt + contexto compartido) coincide con las solicitudes de los últimos 5-10 minutos, se aplicará automáticamente el descuento del 90% ($0.075/1M).
Consejos de optimización:
- Coloca el system prompt al principio de la matriz de mensajes.
- Coloca el contexto compartido (como bases de conocimiento o resúmenes de documentos) después del system prompt.
- Coloca la consulta real del usuario al final.
- Mantén una frecuencia de llamadas alta (caduca después de >5 minutos).
Al realizar llamadas a través de la plataforma APIYI apiyi.com, el descuento de caché está totalmente sincronizado con el oficial, sin necesidad de configuración adicional.
Q4: ¿Cuándo usar GPT-5.4 mini y cuándo la versión estándar de GPT-5.4?
Escenarios para priorizar mini:
- Alto rendimiento (>10K llamadas/día).
- Tasa de aciertos de caché > 50%.
- Tareas tipo SWE-Bench / Terminal-Bench.
- Automatización con Computer Use.
- Entornos de producción sensibles a los costes.
Escenarios para priorizar la versión estándar:
- Pruebas matemáticas de nivel FrontierMath.
- Agentes complejos de larga duración (nivel 20 horas).
- Tareas de alto riesgo como lectura detallada de contratos legales o diagnósticos médicos.
- Decisiones críticas donde el valor de una sola invocación sea > $0.10.
Principio simple: el 80% de las tareas se resuelven bien con mini; solo actualice a la versión estándar para razonamientos extremadamente complejos.
Q5: ¿Cómo invocar GPT-5.4 mini a través de APIYI? ¿Qué código debo modificar?
APIYI es totalmente compatible con el SDK de OpenAI, solo requiere tres pasos:
- Visita APIYI apiyi.com para registrar una cuenta (no requiere solicitud, el grupo Default está disponible directamente).
- Obtén tu clave API.
- Modifica el
base_urlen tu código ahttps://vip.apiyi.com/v1y establece el modelo comogpt-5.4-mini.
client = openai.OpenAI(
api_key="TU_CLAVE",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-5.4-mini",
messages=[...]
)
Recarga 100 USD y recibe un 10% adicional, equivalente a un ahorro del 15% respecto al oficial, con descuentos de caché sincronizados.
Q6: ¿GPT-5.4 mini admite ajuste fino (Fine-tuning)?
No lo admite. Esta es una de las limitaciones actuales de GPT-5.4 mini. Si tu aplicación requiere obligatoriamente ajuste fino, debes elegir:
- GPT-5 mini (admite ajuste fino, capacidad ligeramente inferior).
- GPT-4o mini (admite ajuste fino, capacidad más débil).
- GPT-5.4 versión estándar (admite ajuste fino, precio 6 veces mayor).
Alternativa: el uso de Reasoning Tokens + Function Calling + mecanismo de caché de GPT-5.4 mini suele lograr resultados excelentes sin necesidad de ajuste fino.
Q7: ¿Cómo se invoca Computer Use en GPT-5.4 mini?
Se habilita a través del parámetro tools:
response = client.chat.completions.create(
model="gpt-5.4-mini",
messages=[{"role": "user", "content": "Ayúdame a abrir el navegador y buscar..."}],
tools=[{
"type": "computer_use",
"config": {"screen_width": 1920, "screen_height": 1080}
}]
)
El modelo devolverá instrucciones de operación estructuradas (click/type/scroll/screenshot); deberás implementar estas acciones en el cliente y enviar los resultados de vuelta al modelo para continuar con el razonamiento. Una puntuación de 72.1% en OSWorld-Verified significa que puede completar la mayoría de las tareas de escritorio.
Q8: ¿Qué limitaciones conocidas tiene GPT-5.4 mini?
Las limitaciones principales incluyen:
- No admite Fine-tuning: No se puede ajustar con conjuntos de datos personalizados.
- No admite salida de imágenes: Solo salida de texto, no puede generar imágenes.
- Precio superior a los mini antiguos: El precio estándar es 5 veces mayor que el de 4o-mini, requiere optimización con caché.
- Reasoning Tokens incluidos en la facturación de salida: Los costes de salida en tareas complejas pueden superar las expectativas.
- Residencia de datos regional +10%: Costes adicionales en escenarios de cumplimiento normativo.
Para escenarios extremadamente sensibles a la latencia (respuesta < 1 segundo), se recomienda realizar pruebas antes de decidir el cambio.
Puntos clave de la API de GPT-5.4 mini
- Salto en capacidades: Alcanza un 54.4% en SWE-Bench Pro, superando al GPT-5 mini (45.7%) por 8.7 puntos porcentuales.
- Descuento por caché: 90% de descuento en la entrada de caché a $0.075/1M, lo que reduce drásticamente los costos en escenarios de alta frecuencia.
- Computer Use: 72.1% en OSWorld; la serie mini admite por primera vez la automatización de escritorio completa.
- Compatible con subagentes: Por primera vez, la colaboración multi-agente se traslada al segmento de precios mini.
- Ventana de contexto de 400K: Capacidad para procesar libros técnicos completos o bases de código completas de una sola vez.
- Velocidad de respuesta 2x: Velocidad duplicada manteniendo un aumento en las capacidades.
- Acceso abierto por defecto: Disponible directamente en el grupo predeterminado de APIYI, sin necesidad de realizar ninguna solicitud.
Resumen
Puntos clave de la API de GPT-5.4 mini:
- Motivación de la actualización: Mejora integral en tres dimensiones principales: SWE-Bench Pro, Terminal-Bench y OSWorld. Es la primera vez que Computer Use y los subagentes llegan al segmento de precios mini.
- Posicionamiento de precios: $0.75 / $4.50 por cada 1M de tokens; la entrada en caché cuesta $0.075 con un 90% de descuento, lo que hace que el costo real en escenarios de alta frecuencia pueda ser incluso menor que el del mini anterior.
- Método de acceso: Invocación directa a través del grupo predeterminado en APIYI (apiyi.com). Con la promoción de recarga de 100 obtienes 10 extra, y cuenta con conexión directa desde China sin necesidad de VPN.
GPT-5.4 mini no es simplemente una "versión más cara del GPT-5 mini", sino un paso crucial de OpenAI para llevar las capacidades de agente al segmento de precios de entrada. Para aplicaciones que realizan más de 10,000 invocaciones al día, con una tasa de acierto de caché superior al 50% y que requieren capacidades de agente o Computer Use, esta actualización es prácticamente obligatoria. Para tareas de texto simples, se pueden seguir utilizando GPT-4o mini o GPT-5 mini.
Recomendamos acceder rápidamente a GPT-5.4 mini a través de la plataforma APIYI (apiyi.com). El grupo predeterminado no requiere solicitud, los descuentos por caché están totalmente sincronizados, obtienes un 10% adicional en recargas y disfrutas de una conexión directa y estable.
Lecturas recomendadas
Si te interesa la API de GPT-5.4 mini, te recomiendo seguir explorando estos temas:
- 📘 Guía de integración de la API de GPT-5.5 Pro – Conoce el modelo insignia de razonamiento de OpenAI y cómo complementa los casos de uso del modelo mini.
- 📊 Análisis profundo del mecanismo de caché de OpenAI: Mejores prácticas para obtener un 90% de descuento – Domina las técnicas de ingeniería para la optimización de caché.
- 🚀 Práctica: Construcción de un Agente de automatización de Computer Use basado en GPT-5.4 mini – Explora aplicaciones de nivel de producción para la automatización de escritorio.
📚 Referencias
-
Documentación oficial del modelo GPT-5.4 mini de OpenAI: Especificaciones del modelo, precios y ejemplos de invocación.
- Enlace:
developers.openai.com/api/docs/models/gpt-5.4-mini - Descripción: Obtén los parámetros técnicos oficiales más recientes y fiables.
- Enlace:
-
Evaluación de GPT-5.4 mini por DataCamp: Desglose detallado de los benchmarks y comparativa entre generaciones.
- Enlace:
datacamp.com/blog/gpt-5-4-mini-nano - Descripción: Evaluación independiente de terceros, ideal para comparar modelos similares.
- Enlace:
-
Documentación de integración de GPT-5.4 mini en APIYI: Soluciones de invocación local, explicaciones de grupos y promociones de recarga.
- Enlace:
docs.apiyi.com - Descripción: Guía práctica de integración diseñada para desarrolladores en China.
- Enlace:
-
Página de precios de OpenAI: Tabla completa de precios y explicación del mecanismo de caché.
- Enlace:
developers.openai.com/api/docs/pricing - Descripción: Estándares de facturación más recientes para todos los modelos.
- Enlace:
Autor: Equipo técnico de APIYI
Intercambio técnico: Te invitamos a comentar tu experiencia con la actualización a GPT-5.4 mini. Para más información sobre la integración de modelos, visita el centro de documentación de APIYI en docs.apiyi.com.