El 24 de abril de 2026, DeepSeek lanzó simultáneamente los modelos V4-Pro y V4-Flash. Si el modelo Flash es el punto ideal de relación calidad-precio para quienes buscan "eficiencia y bajo costo", el V4-Pro es una propuesta completamente distinta:
Es el Modelo de Lenguaje Grande de código abierto con la mayor capacidad de programación hasta la fecha.
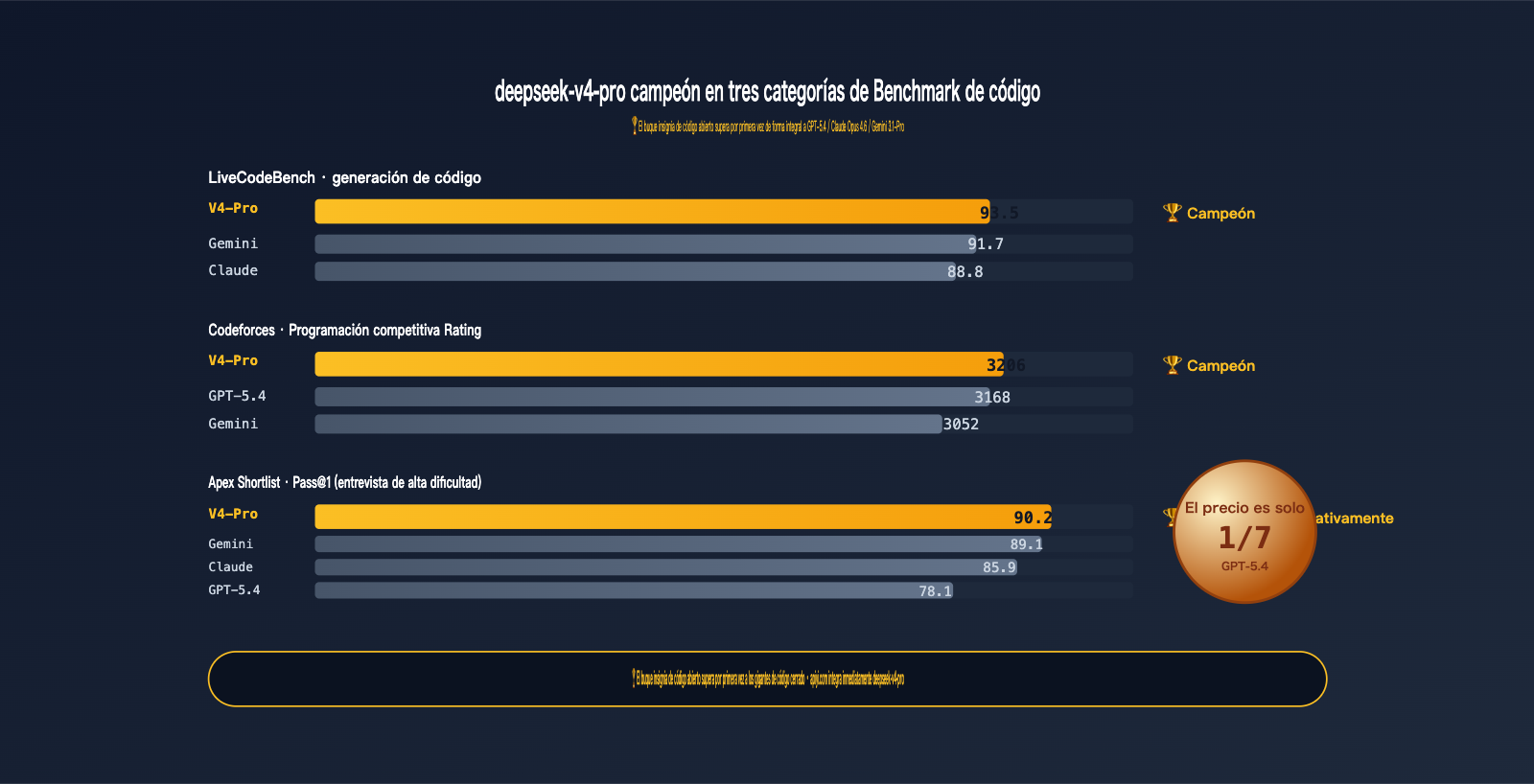
No es una forma sutil de decir "el mejor entre los abiertos", sino un campeón que supera directamente en datos duros a GPT-5.4, Claude Opus 4.6 y Gemini 3.1-Pro:
- LiveCodeBench 93.5: Primer lugar absoluto, superando a Gemini 3.1-Pro (91.7) y Claude Opus 4.6 (88.8).
- Codeforces Rating 3206: Por encima de GPT-5.4 (3168) y Gemini 3.1-Pro (3052).
- Apex Shortlist Pass@1 90.2: Con una ventaja significativa sobre GPT-5.4 (78.1) y Claude (85.9).
- IMOAnswerBench 89.8: En problemas de olimpiadas matemáticas, aventaja a Claude Opus 4.6 (75.3) por 14 puntos completos.
Su configuración técnica es impresionante: 1.6T de parámetros totales / 49B activos / 32T tokens de preentrenamiento / 1M de ventana de contexto / 384K de salida, sumado a las cuatro innovaciones arquitectónicas que DeepSeek diseñó específicamente para la serie V4: Hybrid Attention, Manifold-Constrained Hyper-Connections (mHC), Engram Conditional Memory y Muon Optimizer.
deepseek-v4-pro ya está disponible en APIYI (apiyi.com). Puedes integrarlo sin realizar cambios en tu código utilizando el SDK de OpenAI o Anthropic, con un precio que es apenas 1/7 del costo de GPT-5.4.
Este artículo no repetirá los conceptos básicos de "cómo migrar" o "cómo elegir modelos económicos" que ya cubrimos en el post sobre el modelo Flash. Esta es una guía técnica para los entusiastas del rendimiento de deepseek-v4-pro:
- Entiende en 3 minutos por qué el modelo Pro merece el título de "buque insignia" (arquitectura + datos + escala).
- 4 tablas comparativas de benchmarks para ver dónde gana y dónde pierde el modelo Pro.
- 5 minutos para la integración + 2 casos prácticos reales en programación y matemáticas.

一、Las cuatro capacidades insignia de deepseek-v4-pro
1.1 Tabla de especificaciones clave
| Dimensión | deepseek-v4-pro |
|---|---|
| Fecha de lanzamiento | 24-04-2026 (versión preliminar) |
| Repositorio de código abierto | huggingface.co/deepseek-ai/DeepSeek-V4-Pro |
| Parámetros totales | 1.6T (Mezcla de Expertos) |
| Parámetros activos | 49B |
| Datos de preentrenamiento | > 32T tokens |
| Ventana de contexto | 1M tokens |
| Salida máxima | 384K tokens |
| Innovación de arquitectura | Hybrid Attention + mHC + Engram Memory + Muon |
| Modo de inferencia | Modo dual Thinking / Non-Thinking |
| Function Calling | ✅ Compatible |
| Modo JSON | ✅ Compatible |
| Protocolo API | Doble compatibilidad OpenAI + Anthropic |
| Precio de entrada | $1.74 / M tokens |
| Precio de salida | $3.48 / M tokens |
Recuerda los 4 números clave: 1.6T / 49B / 32T / 1M; esta es la base de su potencia.
1.2 1.6T / 49B MoE: El "techo de código abierto" en escala
DeepSeek-V4-Pro cuenta con 1.6 billones de parámetros totales, utilizando una arquitectura de Mezcla de Expertos (MoE), donde cada token activa solo 49B de parámetros. El significado de estas cifras:
| Modelo | Parámetros totales | Parámetros activos | Tipo |
|---|---|---|---|
| Llama 3 70B | 70B | 70B | Denso (activación total) |
| Mistral Large 2 | 123B | 123B | Denso |
| DeepSeek-V3.2 | 671B | 37B | MoE |
| DeepSeek-V4-Pro | 1.6T | 49B | MoE ⭐ |
| Claude Opus 4.6 | No público | No público | Cerrado |
Los 1.6T de parámetros totales otorgan al modelo un nivel de conocimiento cercano a GPT-5.4 / Claude Opus, mientras que los 49B de parámetros activos mantienen el costo de inferencia por token bajo control; esta es la razón fundamental por la que la arquitectura MoE logra un rendimiento de vanguardia.
1.3 32T tokens de preentrenamiento: Volumen de datos al máximo
Datos de preentrenamiento > 32T tokens
Esta es una cifra impactante:
- Datos de preentrenamiento de GPT-4: aprox. 13T tokens (estimación de la industria)
- Llama 3: 15T tokens
- DeepSeek-V3: 14.8T tokens
- DeepSeek-V4-Pro: >32T tokens ⭐
Los beneficios directos de duplicar el volumen de datos son: una cobertura más completa de conocimientos de cola larga, corpus de código más actualizados y una base de datos de problemas matemáticos más profunda; esta es la raíz por la que V4-Pro domina en LiveCodeBench e IMOAnswerBench.
1.4 Cuatro innovaciones arquitectónicas: El verdadero foso defensivo de Pro
Aquí es donde V4-Pro se diferencia de "otro modelo MoE más". Las cuatro innovaciones clave reveladas oficialmente:
| Innovación | Nombre completo | Problema que resuelve |
|---|---|---|
| Hybrid Attention | Atención híbrida CSA + HCA | Problemas de FLOPs y memoria de video en inferencia de contexto largo (1M) |
| mHC | Manifold-Constrained Hyper-Connections | Estabilidad de conexiones residuales profundas, evita la desaparición/explosión del gradiente |
| Engram | Engram Conditional Memory | Desacopla "hechos estáticos" de "capacidad de razonamiento", actualización de hechos más económica |
| Muon | Muon Optimizer | Velocidad de convergencia y estabilidad del entrenamiento, reduce costos de entrenamiento |
Cada una merece una explicación detallada:
-
Hybrid Attention (CSA + HCA): La complejidad de la atención en el Transformer tradicional es O(n²), lo que hace que 1M de contexto sea inmanejable. V4 utiliza Atención Dispersa Comprimida (CSA) para un filtrado de grano grueso y Atención Altamente Comprimida (HCA) para un enfoque de grano fino, reduciendo los FLOPs al 27% de V3.2 y el caché KV a solo el 10%. Esta es la clave para que deepseek-v4-pro pueda "abrir y ejecutar" 1M de contexto.
-
mHC (Manifold-Constrained Hyper-Connections): Al entrenar modelos MoE profundos, la señal de las conexiones residuales se distorsiona después de varias capas. mHC añade restricciones en el espacio de variedades (manifold), haciendo que la propagación de la señal sea más estable. En la práctica: el modelo puede entrenarse más profundo y por más tiempo sin colapsar.
-
Engram Conditional Memory: Una innovación muy orientada a la ingeniería. Desacopla los "hechos en la memoria del modelo" de la "capacidad de razonamiento": los hechos se almacenan en un módulo de memoria especializado, mientras que la cadena de razonamiento sigue otra ruta. El resultado es que cuando el conocimiento mundial necesita actualizarse, no es necesario reentrenar todo el modelo, lo que reducirá drásticamente los costos de lanzamiento de futuras versiones de Pro.
-
Muon Optimizer: Un optimizador desarrollado por DeepSeek que converge más rápido y es más estable que AdamW. A una escala de entrenamiento de billones de parámetros, esto significa un entrenamiento más completo con la misma potencia de cómputo.
🎯 Perspectiva técnica: deepseek-v4-pro no es solo una versión ampliada de una arquitectura antigua, sino una reescritura completa de la infraestructura. Esta es la razón fundamental por la que puede alcanzar niveles de gigantes cerrados siendo de código abierto. Si planeas usarlo a fondo, te sugiero probar primero un conjunto de indicaciones típicas de tu negocio a través de APIYI (apiyi.com) para sentir la diferencia que aporta la actualización de la arquitectura, especialmente en escenarios de contexto largo y razonamiento multietapa.
1.5 1M de contexto + 384K de salida: Un parteaguas en la generación de textos largos
Las especificaciones de contexto de Pro y Flash son idénticas: 1M de entrada y 384K de salida. Pero la ventaja de Pro no es "cuánto puede leer", sino "qué tan profundo puede pensar con 1M".
Significado práctico para escenarios de textos largos:
| Tarea | Era V3.2 | Era V4-Pro |
|---|---|---|
| Edición completa de un manuscrito de 500k palabras | Requiere dividir en 10+ bloques | Procesamiento de una sola vez en ventana de 1M |
| Preguntas y respuestas sobre 200 páginas de documentación técnica | Requiere construir RAG | Se alimenta directamente |
| Auditoría de repositorios de código medianos | Análisis basado en resúmenes | Verificación de consistencia entre archivos |
| Coherencia en la escritura de novelas | Gestión manual de memoria | Salida de 384K de una sola vez |
二、El trono de los Benchmarks de deepseek-v4-pro

2.1 Capacidad de código: deepseek-v4-pro domina los rankings
Primero, veamos los datos más sólidos: la capacidad de programación:
| Benchmark | V4-Pro | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1-Pro | Ganador |
|---|---|---|---|---|---|
| LiveCodeBench | 93.5 | — | 88.8 | 91.7 | V4-Pro 🏆 |
| Codeforces Rating | 3206 | 3168 | — | 3052 | V4-Pro 🏆 |
| Apex Shortlist Pass@1 | 90.2 | 78.1 | 85.9 | 89.1 | V4-Pro 🏆 |
| SWE-bench Verified | 80.6–82.1 | — | 80.8 | 80.6 | Empate |
| Terminal-Bench 2.0 | 67.9 | 75.1 | 65.4 | 68.5 | GPT-5.4 |
Lidera en tres categorías y en dos "empata o pierde por poco". Es la primera vez que un modelo de código abierto supera integralmente a los modelos insignia cerrados en capacidad de código; un evento muy emblemático de 2026.
Interpretación detallada:
- LiveCodeBench 93.5: LiveCodeBench actualiza los problemas mensualmente, evitando la contaminación del conjunto de entrenamiento. El 93.5 de V4-Pro indica que su capacidad de código es generalizada y capaz de resolver problemas nuevos, no solo memorizar bancos de preguntas.
- Codeforces 3206: Puntuación en programación competitiva; 3206 puntos se acercan al nivel de IGM (Gran Maestro Internacional). Esta puntuación para código de negocio diario es una victoria aplastante.
- Apex Shortlist Pass@1 90.2 vs GPT-5.4 78.1: Esta brecha es sistémica. Apex Shortlist es una colección de preguntas de entrevista de alta dificultad, donde V4-Pro lidera por 12 puntos porcentuales completos.
- Terminal-Bench 2.0 ligeramente más débil: Esta es la capacidad de usar herramientas de línea de comandos en múltiples pasos. GPT-5.4 sigue liderando aquí, lo que indica que en escenarios de "Agentes complejos de múltiples pasos", GPT-5.4 aún tiene una ventaja competitiva.
2.2 Matemáticas y razonamiento: deepseek-v4-pro se acerca a la vanguardia
En la dimensión matemática, Pro y los gigantes cerrados están en una "carrera constante", sin un liderazgo absoluto:
| Benchmark | V4-Pro | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1-Pro |
|---|---|---|---|---|
| MMLU-Pro | 87.5 | 87.5 | 89.1 | 91.0 |
| IMOAnswerBench | 89.8 | 91.4 | 75.3 | 81.0 |
| HMMT 2026 | 95.2 | 97.7 | 96.2 | — |
| MATH | 92% | — | — | — |
| HumanEval | 90% | — | — | — |
| MMLU | 89% | — | — | — |
El punto brillante es IMOAnswerBench: La colección de problemas de la Olimpiada Internacional de Matemáticas, donde V4-Pro obtiene 89.8 puntos, superando a Claude Opus 4.6 por 14.5 puntos y a Gemini 3.1-Pro por 8.8 puntos. Para tareas de alto nivel como razonamiento matemático y pruebas formales, Pro es actualmente el techo de los modelos de código abierto.
Punto débil en conocimiento general MMLU-Pro: El 87.5 de Pro está a la par con GPT-5.4, pero 3.5 puntos por debajo del 91.0 de Gemini 3.1-Pro. En escenarios de preguntas de conocimiento general, Gemini aún mantiene cierta ventaja.
2.3 Mapa de batalla: ¿Dónde gana y dónde pierde deepseek-v4-pro?
| Campo | Campeón | Posición de V4-Pro |
|---|---|---|
| Generación de código (LiveCodeBench) | V4-Pro 🏆 | Campeón |
| Programación competitiva (Codeforces) | V4-Pro 🏆 | Campeón |
| Entrevistas de alta dificultad (Apex) | V4-Pro 🏆 | Campeón (liderazgo amplio) |
| Ingeniería de software (SWE-bench) | Empate | Empate en primer lugar |
| Olimpiada matemática (IMO) | GPT-5.4 | Segundo (muy por encima de Claude/Gemini) |
| Conocimiento general (MMLU-Pro) | Gemini 3.1-Pro | Tercero |
| Cadena de herramientas multietapa (Terminal-Bench) | GPT-5.4 | Segundo |
| Razonamiento de consistencia (HMMT) | GPT-5.4 | Tercero |
Conclusión: Si tu carga de trabajo se centra principalmente en código, deepseek-v4-pro es actualmente una de las opciones más potentes del planeta (incluyendo modelos abiertos y cerrados). Si te centras en cadenas de herramientas de agentes multietapa, GPT-5.4 aún tiene una ligera ventaja; si tu enfoque principal es el conocimiento general, Gemini 3.1-Pro es más fuerte.
🎯 Sugerencia de selección: Recomendamos probar primero un conjunto de comparativas AB de V4-Pro vs modelos existentes con las indicaciones típicas de tu negocio en APIYI (apiyi.com) (20-50 ejemplos son suficientes). No confíes en los benchmarks públicos para decidir tu selección: tu propia distribución de indicaciones es el verdadero benchmark. Para pruebas AB por lotes, sugerimos usar la línea de alta concurrencia
vip.apiyi.com.
III. 5 minutos para invocar deepseek-v4-pro en APIYI apiyi.com
3.1 Paso 1: Obtener la clave y elegir la ruta
Entorno previo: Python 3.8+ o Node.js 18+, usando el SDK oficial de OpenAI o Anthropic.
Obtener la clave:
- Visita APIYI
apiyi.com, ve a Panel de control → API Keys → Crear nueva clave. - Se recomienda establecer un límite diario para la clave Pro (¥200–500, según el volumen de tu negocio).
- Copia la clave que comienza con
sk-.
Elegir la ruta (las tres rutas comparten la misma clave):
| base_url | Uso |
|---|---|
https://api.apiyi.com/v1 |
Invocaciones diarias, escenarios interactivos |
https://vip.apiyi.com/v1 |
Tareas por lotes, alta concurrencia |
https://b.apiyi.com/v1 |
Respaldo ante inestabilidad del sitio principal |
3.2 Paso 2: Invocación mínima en Python (Sin razonamiento)
from openai import OpenAI
client = OpenAI(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com/v1",
)
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "system", "content": "Eres un ingeniero senior de Python."},
{"role": "user", "content": "Escribe una caché LRU lista para producción en 30 líneas."},
],
max_tokens=2048,
)
print(resp.choices[0].message.content)
Solo cambia dos cosas: base_url y model. El resto del código del SDK de OpenAI no se toca.
3.3 Paso 3: Habilitar el modo de razonamiento (El valor destacado de Pro)
El verdadero valor de deepseek-v4-pro se libera por completo en el modo de razonamiento (Thinking). Los resultados en benchmarks como IMOAnswerBench (89.8) y LiveCodeBench (93.5) se obtuvieron bajo este modo.
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "user", "content": """
Por favor, implementa un limitador de tasa (rate limiter) de tipo token bucket seguro para concurrencia, que cumpla con:
1. Soporte para ajuste dinámico de tasa
2. Soporte para reserva de tráfico en ráfagas
3. Implementación sin bloqueos (usando CAS u operaciones atómicas)
4. Incluya pruebas unitarias completas
"""},
],
extra_body={
"reasoning": {"enabled": True, "effort": "high"},
},
max_tokens=16384,
)
print("--- Proceso de razonamiento ---")
print(resp.choices[0].message.reasoning_content)
print("\n--- Respuesta final ---")
print(resp.choices[0].message.content)
Con effort=high, el modelo Pro realiza una planificación profunda: analizará los requisitos, diseñará la API, discutirá diferentes enfoques y finalmente entregará el código. Esta es la mayor ventaja de pagar la diferencia por deepseek-v4-pro frente a la versión Flash.
3.4 Paso 4: Escenario real de corrección de código
Escenario de negocio real: pedirle a Pro que corrija un error.
buggy_code = """
def find_kth_largest(nums, k):
nums.sort()
return nums[k] # ERROR aquí
"""
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "system", "content": "Eres un revisor de código senior. Identifica errores, explica la causa raíz y proporciona el código corregido."},
{"role": "user", "content": f"Revisa este código:\n```python\n{buggy_code}\n```"},
],
extra_body={"reasoning": {"enabled": True}},
max_tokens=4096,
)
print(resp.choices[0].message.content)
Pro señalará que el índice debería ser -k (el k-ésimo mayor tras ordenar está en la posición k desde el final), y proporcionará la corrección junto con el manejo de casos límite (k <= 0, k > len(nums)) y casos de prueba.
El rendimiento superior al 80% en SWE-bench se siente realmente en este tipo de escenarios.
3.5 Paso 5: Llamada a funciones / Uso de herramientas
Pro es muy estable en llamadas a herramientas individuales. Aunque en cadenas de herramientas de múltiples pasos es ligeramente inferior a GPT-5.4, supera a Claude:
tools = [
{
"type": "function",
"function": {
"name": "run_sql",
"description": "Ejecuta una consulta SQL de solo lectura en la base de datos de análisis.",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "SQL solo de tipo SELECT"},
},
"required": ["query"],
},
},
},
]
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "user", "content": "¿Cuáles son las 5 ciudades con mayor DAU en los últimos 30 días?"},
],
tools=tools,
tool_choice="auto",
)
print(resp.choices[0].message.tool_calls)
3.6 Paso 6: Protocolo Anthropic (Integración de Claude Code con Pro)
Esta ruta es el valor más subestimado de deepseek-v4-pro: puedes tomar todos tus proyectos existentes de Claude SDK / Claude Code y cambiar el modelo subyacente por V4-Pro sin modificar ni una línea de código de negocio.
from anthropic import Anthropic
client = Anthropic(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com", # Nota: sin /v1
)
resp = client.messages.create(
model="deepseek-v4-pro",
max_tokens=4096,
messages=[
{"role": "user", "content": "Refactoriza este código de Python a estilo async/await..."},
],
)
print(resp.content[0].text)
Terminal de Claude Code: En la configuración, establece ANTHROPIC_BASE_URL=https://api.apiyi.com, ANTHROPIC_API_KEY=sk-... y cambia el modelo a deepseek-v4-pro para obtener instantáneamente un agente de terminal con capacidades de programación líderes.
3.7 Paso 7: Integrar deepseek-v4-pro en Cursor
En Cursor, ve a Settings → Models → Custom OpenAI-Compatible:
- Base URL:
https://api.apiyi.com/v1 - API Key:
sk-... - Model Name:
deepseek-v4-pro
Una vez configurado, las funciones de Chat, Cmd+K y Composer de Cursor utilizarán V4-Pro, mejorando notablemente la calidad de la autocompletación y la refactorización.
🎯 Sugerencia para IDE: Herramientas de programación con IA como Cursor, Windsurf, Cline y Continue son compatibles con el protocolo OpenAI. Solo apunta la
base_urlaapi.apiyi.com/v1y cambia el modelo adeepseek-v4-propara una migración sin problemas. Puedes consultar ejemplos detallados de configuración en la sección de DeepSeek V4 de la documentación oficial de APIYI endocs.apiyi.com.
IV. ¿Cuándo elegir deepseek-v4-pro y cuándo no?
4.1 Condiciones de decisión para elegir Pro
✅ Elige deepseek-v4-pro directamente en estos escenarios:
| Escenario | ¿Por qué? |
|---|---|
| Generación, refactorización y revisión de código | Campeón absoluto con 93.5 en LiveCodeBench |
| Programación competitiva, entrenamiento en algoritmos | Nivel IGM equivalente a 3206 en Codeforces |
| Resolución masiva de preguntas de entrevista | Liderazgo amplio con 90.2 en Apex Shortlist |
| Razonamiento matemático, pruebas formales | Supera a Claude por 14 puntos en IMOAnswerBench |
| Comprensión de repositorios completos | 1M de ventana de contexto + 49B de activación |
| Escritura y edición de textos largos | 384K de salida en una sola vez |
| Despliegue local / reentrenamiento | Pesos de código abierto + módulo Engram para ajuste fino |
| Reemplazo del modelo subyacente de Cursor / Claude Code | Integración sin cambios mediante protocolo Anthropic |
4.2 Casos en los que no elegir Pro
❌ No desperdicies la potencia de Pro en estos casos:
| Escenario | Sugerencia |
|---|---|
| Conversaciones diarias, FAQ | Usa Flash (ahorra 12 veces el costo) |
| Clasificación o extracción de textos cortos | Usa Flash o un modelo más pequeño |
| Cadenas de herramientas de agentes complejos de múltiples pasos | Considera prioritariamente GPT-5.4 (líder en Terminal-Bench) |
| Preguntas y respuestas de conocimiento general | Gemini 3.1-Pro es más fuerte |
| Interacciones en línea sensibles a la latencia | Usa Flash (modo sin razonamiento) o añade caché |
4.3 Sugerencia de enrutamiento mixto
La solución óptima en entornos de producción suele ser el enrutamiento por capas:
def pick_model(request_type: str, complexity: str) -> str:
# Trabajo pesado de código → Pro
if request_type in ("code_gen", "code_review", "refactor") and complexity == "hard":
return "deepseek-v4-pro"
# Razonamiento matemático → Pro
if request_type in ("math_proof", "competitive_programming"):
return "deepseek-v4-pro"
# Comprensión profunda de documentos largos → Pro
if request_type == "long_doc_analysis":
return "deepseek-v4-pro"
# Otros usos diarios → Flash
return "deepseek-v4-flash"
En APIYI apiyi.com, ambos modelos comparten la misma clave. El cambio solo requiere modificar el campo model, sin tocar ninguna otra configuración.
V. Preguntas frecuentes (FAQ) sobre deepseek-v4-pro
Q1: ¿Por qué la capacidad de programación del Pro es tan potente?
Se debe a la combinación de tres factores:
- Preentrenamiento con 32T tokens: Incluye una enorme cantidad de corpus de código de alta calidad.
- MoE de 1.6T / 49B activados: Permite almacenar y recuperar conocimientos de programación de forma eficiente.
- Modo Thinking + Engram Memory: Desacopla la "memorización de paradigmas de código" de la "inferencia de nuevo código".
Ninguno de estos factores por sí solo lograría este rendimiento; juntos, alcanzan una puntuación de 93.5 en LiveCodeBench.
Q2: ¿Los 1.6T de parámetros hacen que la respuesta sea muy lenta?
La velocidad de respuesta depende de los parámetros activados, no del total. El Pro solo activa 49B por token y, gracias a la optimización de FLOPs de Hybrid Attention, la latencia del primer token es cercana a la de Flash. El modo Thinking es más lento (porque debe generar el proceso de razonamiento), pero es una decisión de diseño: estás pagando tiempo a cambio de calidad de razonamiento.
Q3: ¿Es obligatorio activar el modo Thinking?
No. Para conversaciones casuales, código sencillo o preguntas cotidianas, puedes desactivarlo. Sin embargo, gran parte del valor por el que pagas en el Pro reside en el modo Thinking. Para código complejo, problemas matemáticos o lógica de varios pasos, asegúrate de activar reasoning.enabled=true + effort=high.
Q4: ¿Cómo usarlo en Cursor / Claude Code?
- Cursor: Ajustes → Modelos → Custom OpenAI-Compatible. En Base URL escribe
https://api.apiyi.com/v1y en Modelo escribedeepseek-v4-pro. - Claude Code: Configura las variables de entorno
ANTHROPIC_BASE_URL=https://api.apiyi.com+ANTHROPIC_API_KEY=sk-...y especificadeepseek-v4-procomo modelo al iniciar.
Puedes encontrar capturas de pantalla detalladas en la sección de integración de IDE en docs.apiyi.com.
Q5: ¿Cuál vale más la pena comparado con GPT-5.4?
Si tienes que elegir uno:
- Código diario / Competiciones / Matemáticas / Sensibilidad al costo → deepseek-v4-pro (Campeón en código, precio 1/7).
- Agentes de herramientas de varios pasos / Conocimiento general → GPT-5.4.
- El uso mixto es la mejor solución (usando la misma clave de APIYI apiyi.com para alternar entre ambos modelos).
Q6: ¿Se puede implementar localmente?
Sí, el V4-Pro ha liberado sus pesos completos en Hugging Face (deepseek-ai/DeepSeek-V4-Pro). Pero la autoinstalación requiere:
- Un equipo con ≥ 8×H200 o GPU equivalente.
- Caché KV adicional para 1M de ventana de contexto (aunque el Pro ya ha reducido la caché al 10% respecto a V3.2).
- Costos de ingeniería para mantener el servicio de inferencia.
Cálculo de costos: A menos que tu volumen mensual supere los 50 mil millones de tokens, usar el servicio proxy de API de APIYI (apiyi.com) es más económico que la autoinstalación.
Q7: ¿Cuál es el límite de concurrencia?
Recomendaciones para entornos de producción:
- Sitio principal
api.apiyi.com: 50 conexiones simultáneas seguras. - Línea de alta concurrencia
vip.apiyi.com: 200+ conexiones simultáneas. - Respaldo
b.apiyi.com: Fallback automático si la línea principal presenta inestabilidad.
Debido a que el Pro tiene una latencia mayor en tareas complejas de Thinking, más concurrencia no siempre es mejor; es más preciso estimar la ventana necesaria basándose en QPS × tiempo medio de respuesta.
Q8: ¿Saldrá pronto la versión oficial?
Lo publicado el 24-04-2026 es una versión preliminar (Preview). Siguiendo el ritmo de DeepSeek, la versión oficial suele lanzarse 1 o 2 meses después, posiblemente con mejoras menores en los benchmarks. Usar la versión preliminar en APIYI apiyi.com no supone ningún problema; es muy probable que el ID del modelo deepseek-v4-pro se mantenga en la versión oficial para garantizar la compatibilidad.
VI. Resumen del lanzamiento de deepseek-v4-pro
Si te saltaste el resto, aquí tienes las conclusiones clave:
- ✅ deepseek-v4-pro es el modelo de código abierto con mayor capacidad de programación actual, superando a GPT-5.4 / Claude Opus 4.6 / Gemini 3.1-Pro en los benchmarks LiveCodeBench, Codeforces y Apex.
- ✅ Cuatro innovaciones arquitectónicas (Hybrid Attention, mHC, Engram Memory y Muon) lo convierten no en "otro Modelo de Lenguaje Grande", sino en una nueva especie tras una reescritura de la infraestructura.
- ✅ Escala de 1.6T / 49B MoE + 32T tokens de preentrenamiento + 1M de ventana de contexto, alcanzando el techo de los modelos abiertos.
- ✅ Ya disponible en APIYI apiyi.com, compatible con los protocolos de OpenAI y Anthropic, permitiendo una integración sin modificaciones en Cursor, Claude Code, Cline y otras herramientas principales.
- ✅ Precio de solo 1/7 del GPT-5.4, brillando especialmente en el modo Thinking.
Para equipos de desarrollo centrados en código, deepseek-v4-pro merece ser probado de inmediato. No es solo una alternativa más barata, sino un modelo insignia que podría convertirse en el nuevo estándar.
🎯 Recomendación: Solicita hoy mismo una clave en APIYI
apiyi.com(dedicada al Pro, con un límite diario de ¥200–500). Ejecuta 20 de tus indicaciones (prompts) más representativas de código, matemáticas o textos largos, y realiza una comparativa AB entre V4-Pro (modo Thinking) y tu modelo principal actual. Si la calidad de las tareas de código mejora notablemente, cambia el modelo predeterminado en Cursor / Claude Code. Si necesitas un modelo económico para el día a día, añade V4-Flash (consulta la guía de migración anterior). Para pruebas masivas, usavip.apiyi.com, y si hay inestabilidad,b.apiyi.comactuará como respaldo automático. Encontrarás ejemplos de integración, configuración de IDE y scripts de replicación de benchmarks endocs.apiyi.com.
El significado de deepseek-v4-pro trasciende el ser "otro modelo SOTA barato". Marca la primera vez que un modelo de código abierto supera por completo a los modelos cerrados insignia en su capacidad central de programación; algo que todo equipo que se tome en serio la ingeniería de IA debería probar seriamente.
Autor: Equipo técnico de APIYI
Recursos relacionados:
- Anuncio oficial de DeepSeek: api-docs.deepseek.com/news/news260424
- Repositorio de código abierto en Hugging Face: huggingface.co/deepseek-ai/DeepSeek-V4-Pro
- Sitio web de APIYI: apiyi.com
- Documentación de APIYI: docs.apiyi.com
- Sitio principal de APIYI: api.apiyi.com (respaldos: vip.apiyi.com / b.apiyi.com)