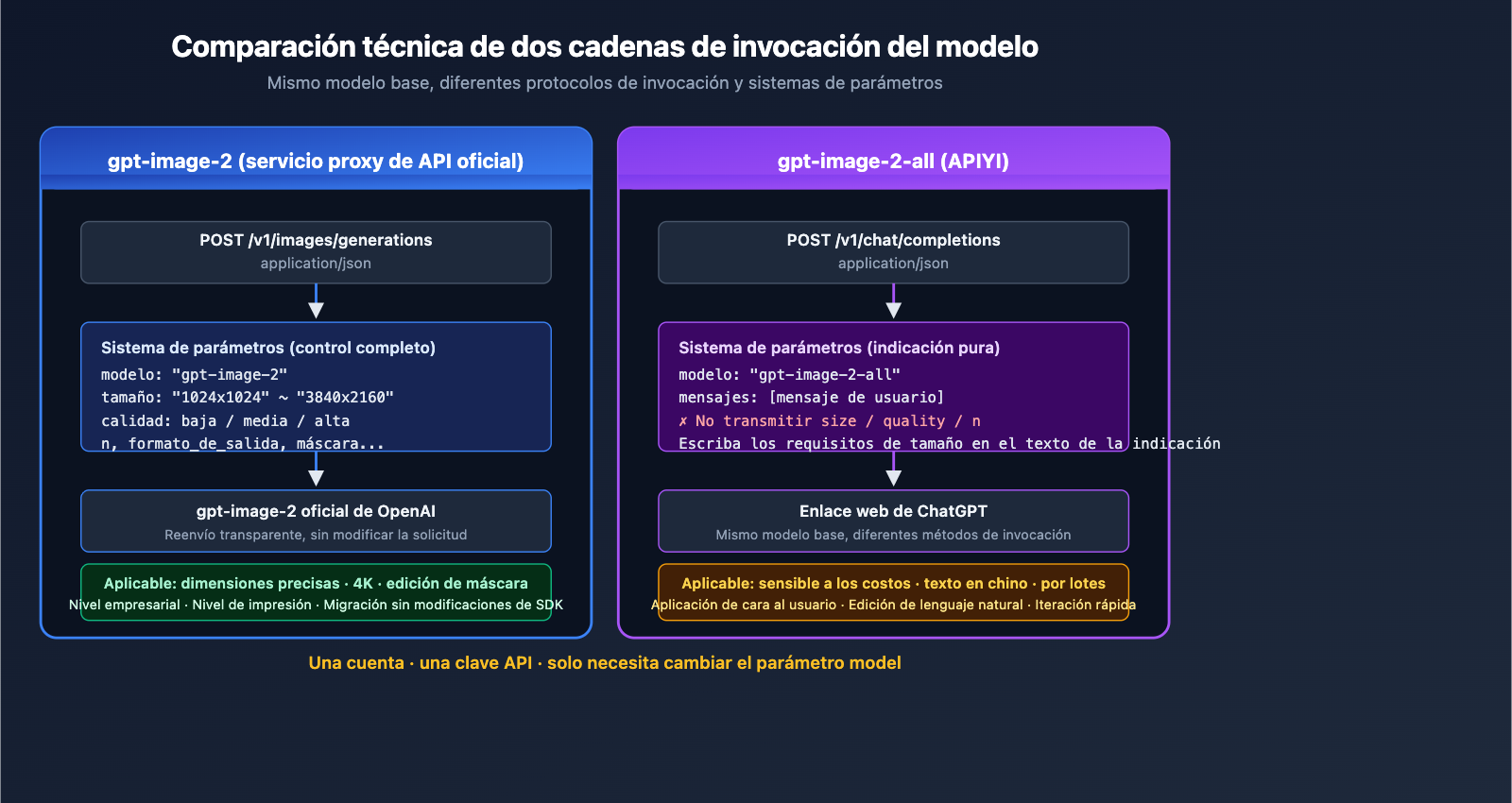
OpenAI lanzó oficialmente ChatGPT Images 2.0 el 21 de abril de 2026, y su modelo de API correspondiente, gpt-image-2, trae consigo una serie de mejoras en capacidades como razonamiento, búsqueda web en tiempo real, consistencia entre múltiples imágenes y renderizado de texto detallado.
Siguiendo esta línea, APIYI ha lanzado simultáneamente dos rutas de acceso independientes para gpt-image-2:
- ① Versión oficial (proxy)
gpt-image-2: Facturación por uso, precios idénticos a los oficiales de OpenAI, 15% de descuento en recargas, suministro estable y sin límites de concurrencia. - ② Versión optimizada (inversa)
gpt-image-2-all: Facturación por solicitud, $0.03 por uso (antes de descuentos), integración sencilla y costos predecibles.
Esto significa que los desarrolladores pueden contar con ambas rutas técnicas bajo una misma cuenta, permitiéndoles elegir de forma flexible según las necesidades de su negocio, equilibrando calidad, costo y estabilidad. En este artículo, desglosamos las diferencias clave, la estructura de precios, el soporte de parámetros, los casos de uso típicos y cómo realizar la integración rápidamente.

I. Resumen rápido del lanzamiento de los modelos duales GPT-image-2 de APIYI
Puedes entender las diferencias clave entre ambos modelos rápidamente con esta tabla:
| Dimensión | gpt-image-2 (Oficial) |
gpt-image-2-all (Inversa) |
|---|---|---|
| Posicionamiento | Reenvío transparente oficial de OpenAI | Simulación de enlace de llamada web de ChatGPT |
| Método de facturación | Basado en tokens reales | Fijo $0.03 / solicitud |
| Referencia de precio | 1024² medium ≈ $0.053, 2K medium ≈ $0.05 | $0.03 / solicitud, sin importar tamaño/calidad |
| Descuento recarga | 15% durante el periodo de promoción | 15% durante el periodo de promoción |
| Resolución | Soporta hasta 4K (3840×2160) | Salida entre 1K-2K |
| Niveles de calidad | auto / low / medium / high | Sin control de parámetros |
| Soporte de parámetros | Parámetros completos (size, quality, n, mask, etc.) |
No soporta parámetros tradicionales, se especifica vía indicación |
| Endpoint | /v1/images/generations + /v1/images/edits |
/v1/chat/completions (recomendado) |
| Límite de concurrencia | Sin límites de nivel de OpenAI | Sin límites |
| Velocidad de generación | 100-120 s (4K alta calidad 3-5 min) | ~30 s |
| Soporte nativo chino | Sí | Optimización nativa de indicaciones en chino |
| Documentación | docs.apiyi.com/api-capabilities/gpt-image-2/overview | docs.apiyi.com/api-capabilities/gpt-image-2-all/overview |
Ambos modelos pueden probarse en línea en imagen.apiyi.com, lo que permite comparar visualmente las diferencias de salida de ambas rutas sin necesidad de escribir código.
二、Análisis profundo del modelo de transferencia oficial gpt-image-2
2.1 Posicionamiento técnico del modelo de transferencia oficial
La versión de transferencia oficial de gpt-image-2 es un proxy transparente de la API oficial de OpenAI. APIYI solo realiza lo siguiente:
- Reenvío de protocolo: Totalmente compatible con el endpoint oficial de OpenAI
/v1/images/generations. - Sustitución de autenticación: Los desarrolladores utilizan la clave API de APIYI, que el backend sustituye por la autorización de OpenAI.
- Medición de facturación: Se contabiliza según el consumo real de tokens.
- Procesamiento de contenido cero: No se modifica la indicación ni se filtra la salida.
El valor directo de esto es: la calidad de salida es idéntica a la oficial de OpenAI, superando al mismo tiempo los cuellos de botella de concurrencia de los niveles Tier. Las cuentas oficiales de nivel Tier 1 solo pueden generar 5 imágenes por minuto, mientras que el canal de transferencia oficial de APIYI no tiene esta limitación.
2.2 Matriz de resolución admitida por el modelo de transferencia oficial
La versión de transferencia oficial conserva el sistema completo de tamaños de OpenAI:
| Tamaño preestablecido | Relación de aspecto | Uso típico |
|---|---|---|
| 1024 × 1024 | 1:1 | Avatares sociales, Instagram |
| 1536 × 1024 | 3:2 | Imágenes destacadas de blogs |
| 1024 × 1536 | 2:3 | Pósteres para móviles |
| 2048 × 2048 | 1:1 | Imágenes de marca de alta resolución |
| 2048 × 1152 | 16:9 | Portadas de vídeo |
| 3840 × 2160 | 16:9 (4K) | Materiales de calidad de impresión |
| 2160 × 3840 | 9:16 (4K) | Publicidad vertical para pantallas grandes |
| Personalizado | Máximo 3:1 | Banners, imágenes largas |
Restricciones de tamaño personalizado: El lado largo debe ser ≤ 3840 px, ambos lados deben ser múltiplos de 16, y el total de píxeles debe estar entre 655,360 y 8,294,400.
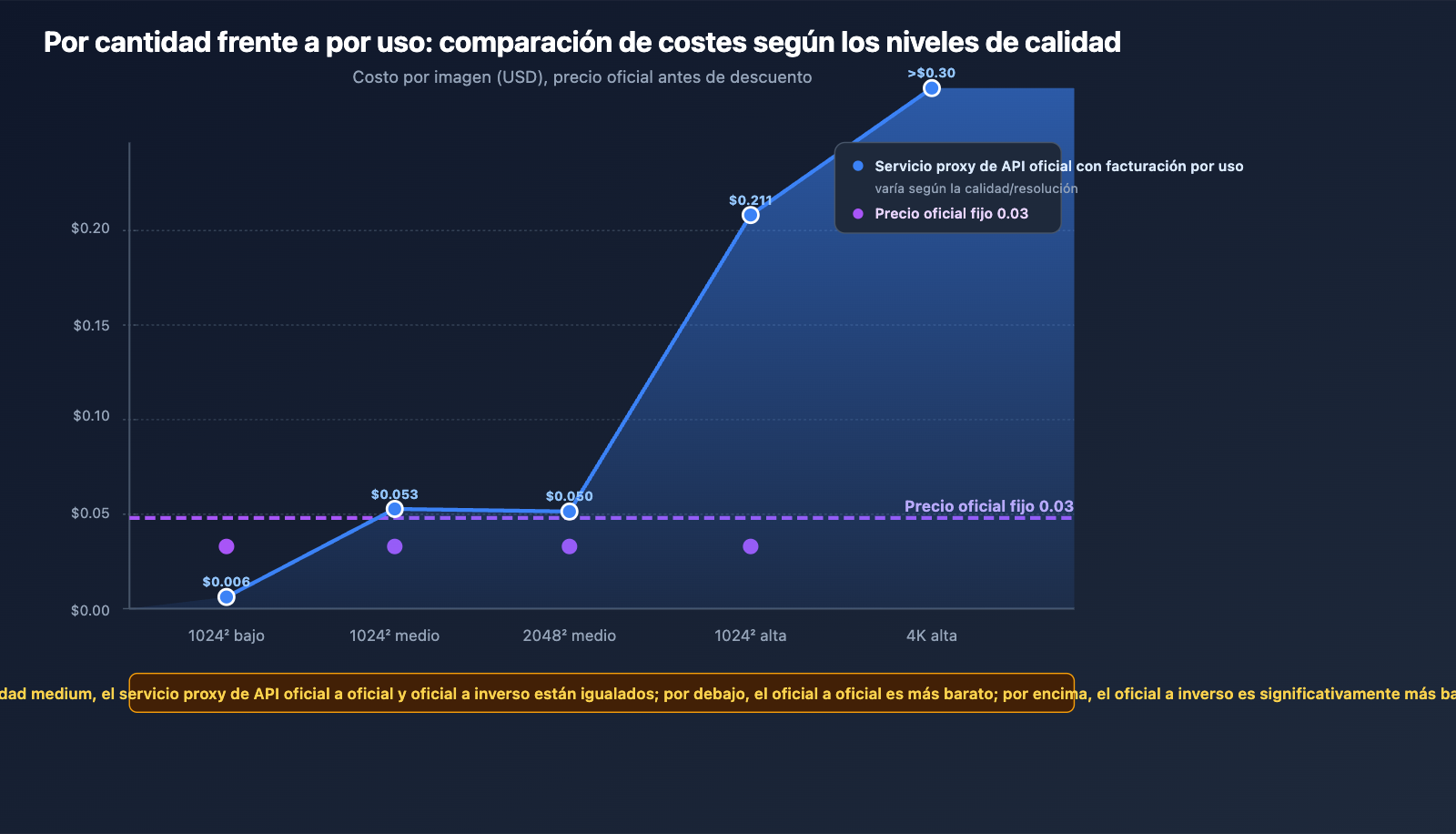
2.3 Cuatro niveles de calidad y precios del modelo de transferencia oficial
El precio está totalmente alineado con el oficial de OpenAI:
| Resolución × Calidad | Precio unitario (Oficial) | Pago real (15% desc.) |
|---|---|---|
| 1024² low | $0.006 | $0.0051 |
| 1024² medium | $0.053 | $0.045 |
| 1024² high | $0.211 | $0.179 |
| 2048² medium | ≈ $0.05 | ≈ $0.043 |
| 1024×1536 medium | $0.041 | $0.035 |
| 1024×1536 high | $0.165 | $0.140 |
Facturación de tokens: entrada de texto/imagen $8/1M, salida de imagen $30/1M, entrada en caché $2/1M.
💡 Estrategia de optimización de costes: Para la exploración inicial de soluciones, se recomienda usar calidad "low" o "medium" para una iteración rápida, y cambiar a "high" para la versión final. Gracias a la promoción de recarga del 15% de descuento en APIYI apiyi.com, el coste real es incluso un 15% inferior al de la conexión directa con OpenAI.
2.4 Escenarios adecuados para el modelo de transferencia oficial
- Necesidad de control preciso de la resolución (imágenes de productos de comercio electrónico, materiales de impresión).
- Necesidad de salida 4K (publicidad en pantallas grandes, fondos de pantalla).
- Necesidad de edición local con máscara (retoque de productos, restauración de imágenes).
- Altos requisitos de compatibilidad con el SDK oficial (migración sin cambios en el código existente).
- Requisitos de SLA de nivel empresarial (posibilidad de firmar acuerdos personalizados).
III. Análisis profundo del modelo de inversión oficial gpt-image-2-all
3.1 Posicionamiento técnico del modelo de inversión oficial
gpt-image-2-all es una implementación inversa que simula el enlace de llamada de la versión web de ChatGPT, con características clave: precio fijo + sin parámetros.
Para los desarrolladores, la mayor diferencia en la experiencia es el método de llamada:
- No utiliza
/v1/images/generations, sino/v1/chat/completions. - No requiere pasar parámetros como
size,qualityon(pasarlos provocará un error de validación). - La resolución y la relación de aspecto se especifican mediante lenguaje natural en la indicación.
- Una llamada genera una imagen.
3.2 Lógica de precio fijo del modelo de inversión oficial
gpt-image-2-all adopta un precio fijo de $0.03 por llamada, independientemente de si generas 1K o 2K, o de la longitud de la indicación (las solicitudes fallidas no se cobran).
El valor que aporta:
| Escenario | Transferencia (por uso) | Inversión (fijo) | Opción ventajosa |
|---|---|---|---|
| 1024² medium (pequeña) | $0.053 | $0.030 | Inversión ahorra 43% |
| 2048² medium (mediana) | ~$0.05 | $0.030 | Inversión ahorra 40% |
| 1024² high (alta calidad) | $0.211 | $0.030 | Inversión ahorra 86% |
| 4K (calidad extrema) | > $0.20 | No soportado | Transferencia es la única opción |
En resumen: Para imágenes de calidad media-baja, la inversión oficial es mucho más barata; pero para 4K y escenarios de alta precisión, solo se puede usar la transferencia oficial.
3.3 Características de tamaño de salida del modelo de inversión oficial
La versión de inversión oficial especifica el tamaño mediante lenguaje natural en la indicación, y el modelo generará imágenes entre 1K y 2K según la solicitud. Tamaños comunes:
| Descripción de relación de aspecto en la indicación | Resolución de salida real |
|---|---|
| "Cuadrado 1:1" | 1254 × 1254 |
| "Horizontal 16:9" | 1672 × 941 |
| "Vertical 9:16" | 941 × 1672 |
| "Ultra ancho 3:1" | El modelo puede no seguirlo estrictamente |
Punto clave: La inversión oficial no ofrece un control determinista a nivel de píxel, por lo que es adecuada para escenarios donde el tamaño no es crítico.
3.4 Capacidades únicas del modelo de inversión oficial
Aunque carece de algunos controles de parámetros, la versión de inversión oficial tiene varias características que la transferencia oficial no posee:
① Optimización nativa de indicaciones en chino
La versión de inversión oficial tiene una optimización especial para indicaciones en chino, logrando una mayor precisión en el renderizado de texto en pósteres, infografías, menús, etc., en comparación con la transferencia oficial.
② Fusión y edición de múltiples imágenes
Permite la síntesis de múltiples imágenes haciendo referencia a ellas en la indicación como "Imagen 1/Imagen 2/Imagen 3". La transferencia oficial también admite múltiples imágenes, pero la sintaxis en la inversión es más natural.
③ Edición en lenguaje natural (sin necesidad de máscara)
Para modificar una imagen existente, no es necesario dibujar una máscara; basta con decir en lenguaje natural: "cambia la ropa de esta persona a rojo". La transferencia oficial requiere subir un canal alfa como máscara.
④ Ventaja de velocidad
El tiempo de generación promedio es de ~30 segundos, significativamente más rápido que los 100-120 segundos de la transferencia oficial. Para tareas por lotes, el tiempo ahorrado es considerable.
3.5 Limitaciones a tener en cuenta en el modelo de inversión oficial
- Caducidad de URL de imagen (24 horas): Los enlaces CDN de R2 devueltos tras la generación son válidos por 24 horas; se recomienda guardarlos inmediatamente en su propio almacenamiento.
- No admite streaming: El parámetro
stream=trueno es válido. - Una imagen por llamada: Cada llamada genera solo una imagen; para lotes, se deben realizar llamadas concurrentes.
- Se recomienda un tiempo de espera de 300 segundos: Incluye los costes de subida y descarga.
3.6 Escenarios adecuados para el modelo de inversión oficial
- Tareas por lotes sensibles a los costes (presupuesto predecible, cálculo sencillo de $0.03 × N).
- Renderizado de texto en chino (menús de restaurantes, pósteres de eventos, infografías).
- Exploración de iteración rápida (generación en 30 segundos, mejora la eficiencia del flujo de trabajo).
- Edición en lenguaje natural (usuarios que no desean crear máscaras).
- Aplicaciones de cara al cliente (C-end) (dibujo interactivo para usuarios, con requisitos de tamaño elásticos).
IV. Inicio rápido con el modelo dual GPT-image-2 de APIYI
4.1 Portal de pruebas en línea
Ambos modelos están integrados en la herramienta de pruebas visuales de APIYI, imagen.apiyi.com, donde desarrolladores y diseñadores pueden:
- Comparación sin código: Introducir la misma indicación y ver los resultados de ambos modelos lado a lado.
- Ajuste de parámetros: En la versión de conversión oficial, es posible ajustar el tamaño y la calidad para percibir las diferencias de forma intuitiva.
- Exportación de código: Una vez satisfecho con la prueba, generar directamente fragmentos de código en curl, Python o Node.js.
Esta es la forma más directa de familiarizarse con los límites de capacidad de ambos modelos. Recomendamos encarecidamente realizar una comparación intuitiva de 10 minutos en imagen.apiyi.com antes de su primera integración.
4.2 Ejemplo en Python para el modelo de conversión oficial gpt-image-2
from openai import OpenAI
import base64
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.images.generate(
model="gpt-image-2",
prompt="Sala de estar de estilo minimalista moderno, grandes ventanales, luz natural entrando en ángulo",
size="2048x1152",
quality="medium",
n=1,
output_format="png"
)
image_bytes = base64.b64decode(response.data[0].b64_json)
with open("output.png", "wb") as f:
f.write(image_bytes)
Punto clave: La versión de conversión oficial utiliza el SDK estándar de OpenAI. El código es idéntico al de la conexión directa con OpenAI; solo necesita reemplazar base_url y api_key.
4.3 Ejemplo en Python para el modelo de inversión oficial gpt-image-2-all
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-image-2-all",
messages=[
{
"role": "user",
"content": "Genera un póster horizontal 16:9 de una sala de estar minimalista moderna,"
"grandes ventanales, luz natural entrando en ángulo,"
'renderiza "Vida Nórdica" en la esquina superior derecha con una fuente china en negrita'
}
]
)
print(response.choices[0].message.content)
Punto clave: La versión de inversión oficial utiliza el punto de conexión chat/completions. La respuesta incluirá un enlace a la imagen o datos en base64. Tenga en cuenta no pasar los parámetros size/quality/n, de lo contrario, se producirá un error.
4.4 Ejemplo de arquitectura mixta para ambas rutas
La práctica recomendada en entornos de producción es utilizar ambos modelos de forma combinada, enrutando las tareas según sus características:
def generate_image(prompt: str, task_type: str):
if task_type in ["batch", "draft", "chinese_text"]:
return client.chat.completions.create(
model="gpt-image-2-all",
messages=[{"role": "user", "content": prompt}]
)
elif task_type in ["print", "4k", "precise_size"]:
return client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="3840x2160",
quality="high"
)
else:
return client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1024",
quality="medium"
)
Mediante esta estrategia de enrutamiento, puede lograr el equilibrio óptimo entre costo y calidad bajo una misma cuenta de APIYI apiyi.com.
V. Análisis del impacto del modelo dual GPT-image-2 de APIYI en los equipos de producto
5.1 Impacto en equipos emprendedores y desarrolladores individuales
Valor central: Reducción de los costos de prueba y error y de las barreras de entrada.
El principal problema para los desarrolladores novatos al integrar gpt-image-2 de OpenAI era que el Nivel 1 solo permitía 5 imágenes por minuto, además de tener que esperar la calificación de la cuenta tras la primera recarga. Ahora, a través de APIYI:
- Registro y uso inmediato, sin barreras.
- Precio fijo de $0.03 por llamada en la versión de inversión oficial, presupuesto extremadamente fácil de predecir.
- En la fase de prototipo, se utiliza la versión de inversión oficial para completar el flujo, y al pasar a producción, se cambia a la versión de conversión oficial según sea necesario.
Esto significa que el tiempo desde "quiero probar gpt-image-2" hasta "ejecutar la primera demo" se reduce a 5 minutos.
5.2 Impacto en equipos de comercio electrónico y producción de contenido
Valor central: Reducción de costos de generación por lotes entre un 40% y un 85%.
Supongamos que un equipo de comercio electrónico necesita generar 5000 imágenes de productos al mes (resolución 1024×1024, calidad media):
- Conexión directa a OpenAI: 5000 × $0.053 = $265/mes + limitación de tasa de Nivel 1 que ralentiza el ritmo.
- Conversión oficial de APIYI: 5000 × $0.053 × 0.85 = $225/mes + sin límites de concurrencia.
- Inversión oficial de APIYI: 5000 × $0.03 × 0.85 = $128/mes + generación rápida en 30 segundos.
Si el negocio no requiere una precisión de tamaño estricta, cambiar completamente a la versión de inversión oficial puede ahorrar más del 50% en costos.
5.3 Impacto en clientes empresariales
Valor central: Flexibilidad en la selección técnica.
Anteriormente, los clientes empresariales debían elegir entre el modelo oficial de OpenAI y modelos alternativos de terceros. Ahora pueden:
- Flujos de negocio críticos: Utilizar la versión de conversión oficial para mantener la calidad y el SLA consistentes con el oficial.
- Flujos de tareas por lotes: Utilizar la versión de inversión oficial para maximizar la ventaja de costos.
- Experimentos A/B: Realizar comparaciones por lotes primero en imagen.apiyi.com antes de decidir la inversión en el modelo.
El servicio empresarial de APIYI también puede proporcionar canales independientes personalizados, compromisos de SLA y facturas de cumplimiento para grandes clientes.
5.4 Impacto en productos de IA tipo herramienta
Valor central: Equilibrio entre la experiencia del usuario y el control de costos.
Muchos productos de generación de imágenes por IA para el consumidor final (C-end) solían tener dificultades para equilibrar "dar al usuario una buena calidad de imagen" y "controlar los costos". Ahora, con la matriz de modelo dual:
- Usuarios gratuitos → Inversión oficial a $0.03/llamada para garantizar la disponibilidad básica.
- Usuarios de pago → Conversión oficial con alta calidad para ofrecer una experiencia diferenciada.
- Usuarios empresariales → Conversión oficial en 4K para satisfacer las necesidades de impresión.

VI. Preguntas frecuentes (FAQ) sobre el modelo dual GPT-image-2 de APIYI
P1: ¿Hay mucha diferencia en la calidad de imagen entre los dos modelos?
En escenarios de calidad media-baja (1024 medium e inferiores), la diferencia es mínima y difícil de distinguir a simple vista. En escenarios de alta calidad (1024 high / 2K / 4K), la versión oficial (官转) tiene una ventaja clara, ya que permite especificar explícitamente quality="high" y una resolución precisa. Te sugerimos realizar pruebas comparativas con la misma indicación en imagen.apiyi.com para evaluarlo tú mismo.
P2: ¿La versión de ingeniería inversa gpt-image-2-all es peor que el modelo oficial?
No. gpt-image-2-all utiliza internamente el mismo modelo gpt-image-2 de OpenAI; la diferencia radica únicamente en que se completa a través del flujo de interacción web de ChatGPT. La distinción principal está en el control de parámetros y el modelo de precios, no en los pesos del modelo.
P3: ¿Se pueden usar ambos modelos bajo una misma cuenta de APIYI?
Sí, es totalmente compatible. La clave API de tu cuenta en APIYI (apiyi.com) puede invocar tanto gpt-image-2 como gpt-image-2-all simultáneamente; solo necesitas cambiar el parámetro model. La facturación se consolidará en un mismo estado de cuenta.
P4: Las imágenes generadas por la versión de ingeniería inversa caducan en 24 horas, ¿qué recomiendan hacer?
La mejor práctica es descargar la imagen a tu propio almacenamiento de objetos (OSS / S3 / R2) inmediatamente después de recibir la respuesta, sin depender de la URL devuelta por APIYI. Si utilizas response_format="b64_json", obtendrás los datos en base64 directamente, eliminando el problema de caducidad.
P5: ¿Cómo migro el código que escribí anteriormente con el SDK oficial de OpenAI?
- Para cambiar a la versión oficial
gpt-image-2: Solo necesitas modificarbase_urlyapi_key; el resto del código permanece igual. - Para cambiar a la versión de ingeniería inversa
gpt-image-2-all: Debes cambiar al endpointchat/completions, eliminar los parámetrossize/qualitye incluir los requisitos de dimensiones dentro de la indicación.
Recomendamos probar primero en imagen.apiyi.com para confirmar que la calidad de salida cumple con tus expectativas antes de pasar a producción.
P6: ¿Ambos modelos admiten indicaciones en chino?
Ambos son compatibles, pero su rendimiento varía ligeramente. La versión de ingeniería inversa gpt-image-2-all cuenta con una optimización nativa para indicaciones en chino, lo que resulta especialmente efectivo al renderizar texto en chino. La versión oficial admite chino, pero está más alineada con la distribución de entrenamiento original basada en indicaciones en inglés. Para producción, recomendamos realizar pruebas según tu caso de uso.
P7: ¿La promoción de recarga del 15% de descuento aplica a ambos modelos?
Sí. El saldo recargado puede cubrir todas las invocaciones de modelos en APIYI, incluyendo la versión oficial gpt-image-2, la versión de ingeniería inversa gpt-image-2-all y otros modelos de imagen como Nano Banana Pro/2 e Imagen. Las reglas específicas de la promoción se rigen por el anuncio vigente en apiyi.com.
P8: ¿Los clientes corporativos pueden obtener mejores precios o canales exclusivos?
Sí. APIYI ofrece un canal de negociación comercial para grandes clientes. Dependiendo del volumen mensual, se pueden solicitar descuentos personalizados, canales independientes de alta concurrencia, compromisos de SLA, facturación legal y soporte técnico dedicado. Te sugerimos contactar directamente al equipo comercial de APIYI en apiyi.com para obtener una propuesta a medida.
VII. Resumen del lanzamiento del modelo dual GPT-image-2 de APIYI
Una imagen resume el valor central de este lanzamiento:
Una cuenta, dos rutas, tres opciones:
- Prioridad en calidad →
gpt-image-2(versión oficial), pago por uso + 15% de descuento.- Prioridad en costos →
gpt-image-2-all(versión de ingeniería inversa), precio fijo de $0.03/solicitud.- Estrategia híbrida → Operaciones críticas por la versión oficial, tareas por lotes por la versión de ingeniería inversa.
Para los equipos que están evaluando o ya utilizan gpt-image-2, esta es la lista de acciones recomendadas:
- Visita ahora
imagen.apiyi.compara probar ambos modelos en línea. - Compara resultados usando el mismo conjunto de indicaciones típicas para evaluar la diferencia en calidad y velocidad.
- Planifica el enrutamiento diseñando una estrategia de invocación híbrida según las características de tu negocio.
- Controla costos aprovechando la promoción de recarga del 15% de descuento y utilizando la versión de ingeniería inversa para exploraciones por lotes.
- Conexión corporativa para grandes clientes, utiliza el canal comercial de APIYI en apiyi.com para obtener soluciones personalizadas.
La generación de imágenes ha entrado en una nueva etapa de "múltiples rutas paralelas + segmentación de negocio"; un solo modelo y un precio único ya no pueden cubrir todas las necesidades. El lanzamiento simultáneo de este modelo dual por parte de APIYI devuelve, en esencia, el poder de elección a los desarrolladores: combinar de forma flexible ambas rutas según las necesidades de su negocio para encontrar la solución óptima.
Sobre el autor: El equipo técnico de APIYI, dedicado a proporcionar servicios de acceso a API de Modelos de Lenguaje Grande estables, transparentes y completos para desarrolladores y clientes corporativos. Visita el sitio web oficial de APIYI en apiyi.com para obtener la documentación de acceso más reciente y detalles sobre servicios corporativos para modelos de imagen líderes como gpt-image-2, gpt-image-2-all y Nano Banana Pro.