Nota del autor: APIYI ha lanzado el modelo oficial inverso gpt-image-2-all, con una tarifa de $0.03 por uso, sin límites de concurrencia y soporte para texto a imagen, fusión de múltiples imágenes y edición mediante lenguaje natural. Ofrece una paridad total con las capacidades de generación de imágenes más recientes de la versión web de ChatGPT. A continuación, te explicamos cómo integrarlo.
En abril de 2026, la versión web de ChatGPT comenzó a realizar pruebas A/B de su capacidad de generación de imágenes de próxima generación; aunque los usuarios siguen viendo la etiqueta "GPT Image 1.5" en la interfaz, algunas solicitudes ya son procesadas por el nuevo modelo. La API oficial de OpenAI aún no ha abierto el ID de modelo gpt-image-2, por lo que cualquier servicio que afirme realizar "llamadas directas a la API de gpt-image-2" debe verificarse con precaución.
APIYI ha lanzado oficialmente gpt-image-2-all mediante una solución inversa oficial, con paridad total respecto a las capacidades de generación de imágenes más recientes de la versión web de ChatGPT, a un costo de $0.03 por uso y sin límites de concurrencia. Esto no es una promesa vacía, sino una interfaz de nivel de producción que ya puede invocarse mediante solicitudes HTTP estándar.
Valor principal: Al terminar de leer este artículo, dominarás los 3 puntos finales de la API de gpt-image-2-all, técnicas de fusión de múltiples imágenes, el uso de edición mediante lenguaje natural y podrás completar la integración en 10 minutos.

Puntos clave de gpt-image-2-all
| Capacidad | Descripción | Valor |
|---|---|---|
| Paridad con ChatGPT Web | Solución inversa oficial sincronizada con las capacidades oficiales | No hay que esperar a que OpenAI abra la API |
| Tarifa por uso | $0.03/uso, sin límite de resolución/calidad/indicación | Costo transparente y predecible |
| Sin límite de concurrencia | Sin restricciones en el número de solicitudes | Ideal para flujos de trabajo por lotes |
| Fusión de imágenes | Referencia a "imagen1/imagen2/imagen3" en la indicación | Generación de consistencia entre múltiples sujetos |
| Edición por lenguaje natural | Edición conversacional sin necesidad de máscara | Umbral de iteración significativamente más bajo |
Interpretación del posicionamiento de gpt-image-2-all
¿Qué significa "inverso oficial"? Es una solución de servicio proxy de API que se conecta a las capacidades de generación de imágenes más recientes de la versión web de ChatGPT mediante ingeniería inversa. No es la misma interfaz que la gpt-image-2 que OpenAI abrirá oficialmente en el futuro, pero las capacidades del modelo subyacente son idénticas. Antes de que la API oficial esté abierta, esta es la única solución de nivel de producción que puede invocar de manera estable las capacidades de generación de imágenes más recientes de ChatGPT.
¿Por qué integrarlo ahora? Tres razones prácticas: (1) La fecha de lanzamiento de la gpt-image-2 oficial de OpenAI aún no está definida (se espera entre finales de abril y mediados de mayo de 2026); (2) El periodo de lanzamiento inicial inevitablemente tendrá problemas de cuotas limitadas y arranque en frío; (3) Al completar el flujo de trabajo con gpt-image-2-all con antelación, solo necesitarás cambiar el nombre del modelo para una migración sin problemas cuando se abra la versión oficial.
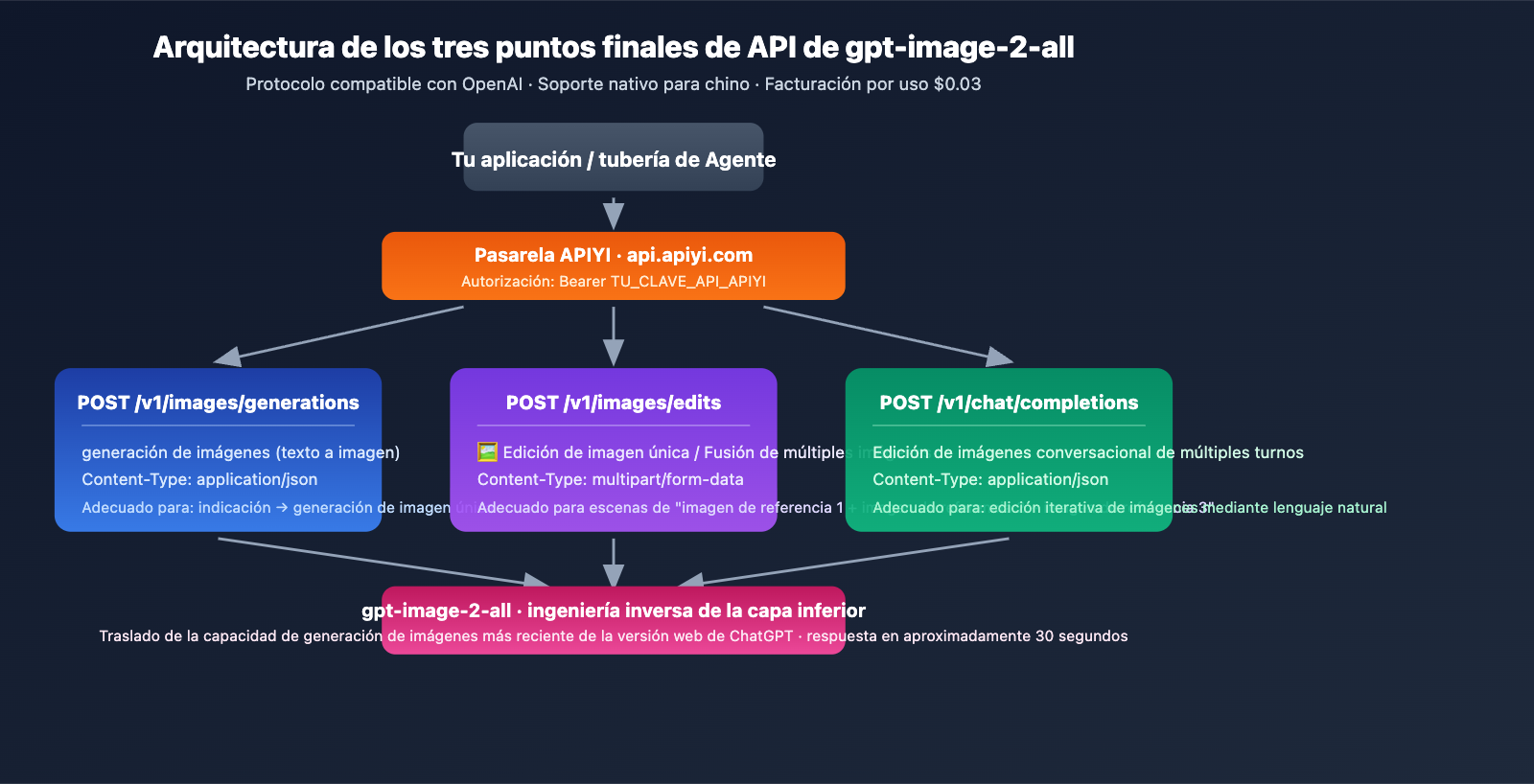
Guía rápida de gpt-image-2-all
Tres puntos finales de API principales
gpt-image-2-all ofrece tres puntos finales para cubrir todo el flujo de trabajo de generación de imágenes:
| Punto final | Uso | Content-Type |
|---|---|---|
POST /v1/images/generations |
Texto a imagen | application/json |
POST /v1/images/edits |
Edición de imagen única / Fusión de múltiples imágenes | multipart/form-data |
POST /v1/chat/completions |
Edición conversacional de múltiples turnos | application/json |
URL base: https://api.apiyi.com (Alternativas: b.apiyi.com, vip.apiyi.com)
Ejemplo minimalista de texto a imagen
import requests
response = requests.post(
"https://api.apiyi.com/v1/images/generations",
headers={
"Authorization": "Bearer YOUR_APIYI_KEY",
"Content-Type": "application/json"
},
json={
"model": "gpt-image-2-all",
"prompt": "Formato horizontal 16:9, una taza de café latte, etiqueta en la mesa que dice 'Morning Blend $4.50', luz de la mañana entrando por la ventana de la cafetería",
},
timeout=120
)
result = response.json()
print(result["data"][0]["url"])
Ver código de integración completo (incluye manejo de errores, concurrencia, fusión de imágenes y edición conversacional)
import requests
import time
from typing import Optional, List
API_KEY = "YOUR_APIYI_KEY"
BASE_URL = "https://api.apiyi.com"
def text_to_image(prompt: str, timeout: int = 120) -> Optional[str]:
"""Texto a imagen: a través del punto final /v1/images/generations"""
for attempt in range(3):
try:
r = requests.post(
f"{BASE_URL}/v1/images/generations",
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
},
json={"model": "gpt-image-2-all", "prompt": prompt},
timeout=timeout
)
if r.status_code == 200:
return r.json()["data"][0]["url"]
if r.status_code == 429:
time.sleep(2 ** attempt)
continue
except requests.Timeout:
continue
return None
def multi_image_fusion(prompt: str, image_paths: List[str]) -> Optional[str]:
"""Fusión de múltiples imágenes: a través del punto final /v1/images/edits"""
files = [
("image[]", (f"img{i}.png", open(p, "rb"), "image/png"))
for i, p in enumerate(image_paths)
]
data = {"model": "gpt-image-2-all", "prompt": prompt}
r = requests.post(
f"{BASE_URL}/v1/images/edits",
headers={"Authorization": f"Bearer {API_KEY}"},
data=data,
files=files,
timeout=120
)
return r.json()["data"][0]["url"] if r.status_code == 200 else None
def conversational_edit(messages: List[dict]) -> Optional[str]:
"""Edición conversacional: a través del punto final /v1/chat/completions"""
r = requests.post(
f"{BASE_URL}/v1/chat/completions",
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
},
json={"model": "gpt-image-2-all", "messages": messages},
timeout=120
)
return r.json()["choices"][0]["message"]["content"] if r.status_code == 200 else None
url = text_to_image("Formato vertical 9:16, póster para móvil, un café latte helado, texto grande en la parte superior 'Summer Sale 50% OFF'")
print(f"Generado: {url}")
fusion_url = multi_image_fusion(
"Coloca a la persona de la imagen 1 en la escena de playa de la imagen 2, manteniendo la ropa de la persona intacta",
["person.png", "beach.png"]
)
print(f"Fusión: {fusion_url}")
Sugerencia de integración: Regístrate en APIYI (apiyi.com) para obtener créditos de prueba. Una sola clave API admite todos los modelos, incluidos gpt-image-2-all, GPT-4o y Claude, evitando los costes de gestión de múltiples cuentas de proveedores.
Características clave de gpt-image-2-all
Característica 1: Renderizado de texto de alta precisión
Para gpt-image-2-all, la estabilidad en el renderizado de texto (tanto en chino como en inglés) es la fortaleza principal de la capacidad de generación de imágenes más reciente de ChatGPT. El texto en carteles, pósteres e infografías se genera correctamente a la primera, algo que era difícil de lograr con gpt-image-1.5.
Escenarios probados:
- Menú de cafetería:
"Americano $4.00, Latte $4.50"precisión a nivel de carácter. - Empaque de productos: Tablas de ingredientes con mezcla de chino e inglés, claras y legibles.
- Mockups de UI: Botones y etiquetas de navegación renderizados con precisión.
- Infografías: Títulos, subtítulos y etiquetas de datos con jerarquía clara.
Característica 2: Capacidad de fusión de múltiples imágenes
A través del punto final /v1/images/edits, puedes subir varias imágenes de referencia simultáneamente y hacer referencia a ellas directamente en la indicación como "imagen 1", "imagen 2", "imagen 3".
prompt = """
Coloca el producto de la imagen 1 en la escena de la imagen 2,
utiliza el estilo de color de la imagen 3,
ángulo de cámara ligeramente cenital,
detalles en alta definición 4K.
"""
Escenarios de uso:
| Escenario | Aplicación |
|---|---|
| Imágenes de comercio electrónico | Foto de producto + Escena → Composición realista |
| Consistencia facial | Foto original del personaje + Nueva escena → Múltiples ángulos |
| Transferencia de estilo | Imagen de contenido + Imagen de estilo → Salida estilizada |
| Sistema visual de marca | Producto + LOGO + Paleta de colores → Visual unificado |
Característica 3: Edición con lenguaje natural (sin necesidad de máscaras)
El mayor avance en eficiencia es la edición conversacional: ya no necesitas dibujar máscaras ni seleccionar áreas; simplemente describe tus necesidades de modificación con lenguaje natural.
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": "Genera una vista exterior de una cafetería, con la luz del sol de la tarde entrando en ángulo"},
]
},
{
"role": "assistant",
"content": "[Enlace a la imagen generada]"
},
{
"role": "user",
"content": "Cambia el clima a lluvioso, manteniendo el edificio igual"
}
]
¿Qué significa este flujo de trabajo?: El ciclo anterior de "generar → editar en Photoshop → volver a generar" se convierte ahora en una iteración conversacional. Cada ajuste solo requiere describir la diferencia, sin necesidad de reescribir la indicación completa.
Característica 4: Soporte nativo para chino
La indicación puede escribirse directamente en chino, sin necesidad de traducirla al inglés antes de realizar la llamada. Para los equipos de desarrollo y negocios locales, esta es una experiencia fluida y natural:
prompt = "Formato vertical 9:16, portada para Xiaohongshu, una chica de rasgos orientales bebiendo café, título 'Explorando el fin de semana · La cafetería secreta en el callejón', estilo realista con luz suave"
Control de dimensiones y proporciones en gpt-image-2-all
Notas importantes
gpt-image-2-all no acepta los parámetros size, n, quality ni aspect_ratio; incluirlos provocará un error de validación. El control de las dimensiones debe realizarse exclusivamente a través de la descripción en el texto de la indicación.
Escritura recomendada para la indicación
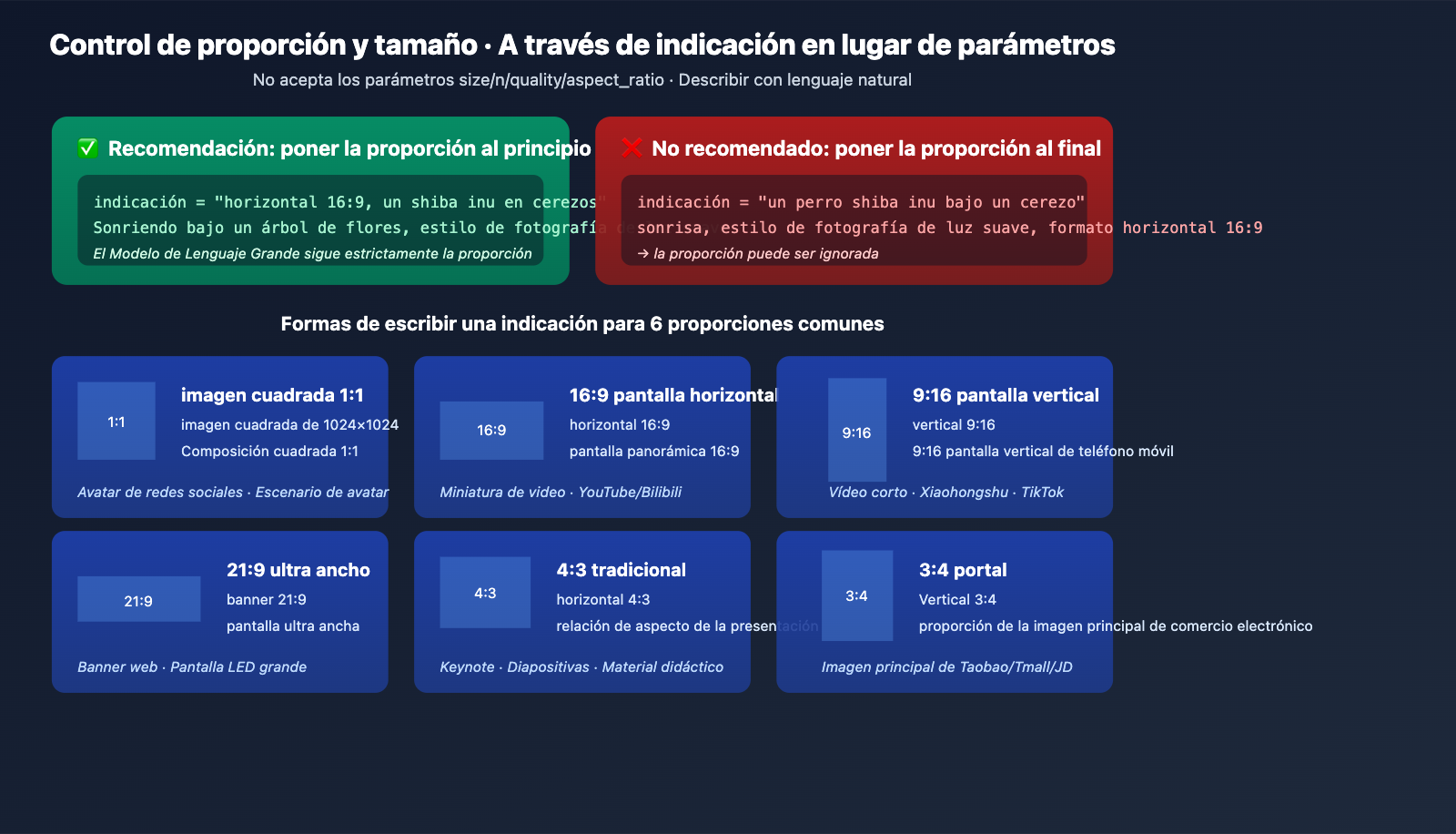
| Proporción objetivo | Escritura recomendada | Descripción |
|---|---|---|
| 1:1 Cuadrada | "1024×1024 cuadrada" o "Composición cuadrada 1:1" | Avatar de redes sociales |
| 16:9 Horizontal | "Horizontal 16:9" o "Pantalla ancha 16:9" | Miniatura de video |
| 9:16 Vertical | "Vertical 9:16" o "Pantalla vertical 9:16" | Video corto/Redes sociales |
| 21:9 Ultra ancho | "Banner 21:9" o "Pantalla ultra ancha" | Banner web |
| 4:3 Tradicional | "Horizontal 4:3" | Diapositivas |
| 3:4 Vertical | "Vertical 3:4" | Imagen principal de e-commerce |
Consejos clave
Coloca la descripción de la proporción al principio de la indicación. El modelo sigue mejor las instrucciones que aparecen al inicio; si la proporción se coloca al final, es posible que sea ignorada.
# ✅ Recomendado
prompt = "Horizontal 16:9, un Shiba Inu sonriendo bajo un cerezo, estilo de fotografía de luz suave"
# ❌ No recomendado
prompt = "Un Shiba Inu sonriendo bajo un cerezo, estilo de fotografía de luz suave, horizontal 16:9"
Estrategia de precios y concurrencia de gpt-image-2-all
Reglas de facturación
| Ítem | Regla |
|---|---|
| Precio unitario | $0.03 / solicitud |
| Unidad de facturación | Por generación exitosa |
| Sin cargo por error | No se cobra en errores 401/4xx/5xx |
| Impacto de parámetros | Ninguno (independiente de la resolución/calidad) |
| Límite de concurrencia | Ninguno (limitado naturalmente por el saldo de la cuenta) |
Estimación de costos típicos
| Escenario de negocio | Volumen mensual | Costo mensual |
|---|---|---|
| Proyecto personal | 500 solicitudes | $15 |
| Equipo pequeño | 5,000 solicitudes | $150 |
| E-commerce masivo | 50,000 solicitudes | $1,500 |
| Pipeline a gran escala | 500,000 solicitudes | $15,000 |
Consejo de optimización de costos: A través de la gestión unificada de cuentas de APIYI (apiyi.com), puedes enrutar las tareas al modelo óptimo entre gpt-image-2-all, gpt-image-1.5 y Nano Banana Pro según el tipo de tarea en tiempo real, evitando pagar el precio unitario más alto para todos los escenarios.
Manejo de errores y mejores prácticas para gpt-image-2-all
Códigos de error comunes y manejo
| Código de estado | Método de manejo |
|---|---|
| 401 | Verifica si el Token de Autorización (Bearer Token) es correcto |
| 429 | Reintento con retroceso exponencial (2s → 4s → 8s) |
| 5xx | Reintenta 1-2 veces; si no funciona, genera una alerta |
| Tiempo de espera | Se recomienda un timeout de cliente ≥ 120 segundos |
Consejos de solución de problemas
Todas las respuestas incluyen el encabezado request-id. Si encuentras algún problema, registra este ID y envíalo al soporte técnico de APIYI para localizar rápidamente los registros del servidor.
Funciones no compatibles
- Salida en streaming:
stream=trueno es válido, solo se admite la devolución única. - Salida de múltiples imágenes: Cada solicitud devuelve solo 1 imagen; si necesitas varias, realiza llamadas concurrentes.
- Parámetros predeterminados del SDK de OpenAI: Los parámetros
size/nincluidos por defecto en el SDK oficial activarán errores de validación; se recomienda realizar las peticiones directamente conrequests.
Preguntas frecuentes (FAQ)
Q1: ¿Qué es gpt-image-2-all?
gpt-image-2-all es un modelo de servicio proxy de API proporcionado por APIYI que conecta con la capacidad de generación de imágenes más reciente de la versión web de ChatGPT mediante ingeniería inversa oficial. Antes de que OpenAI lance oficialmente la API de gpt-image-2, este servicio ofrece un canal de invocación de nivel de producción con las mismas capacidades que ChatGPT, soportando los tres escenarios principales: texto a imagen, fusión de múltiples imágenes y edición de imágenes mediante lenguaje natural.
Q2: ¿Cuál es la diferencia entre gpt-image-2-all y el gpt-image-2 oficial?
La capacidad del modelo subyacente es la misma, pero el método de interfaz es diferente. La API oficial de OpenAI aún no ha abierto el ID de modelo gpt-image-2 (se debe verificar con cautela cualquier servicio que afirme poder llamarlo directamente por API), mientras que la versión web de ChatGPT ya está probando el nuevo modelo en pruebas A/B. gpt-image-2-all proporciona un canal de invocación estable mediante ingeniería inversa. Una vez que la versión oficial esté disponible, los usuarios podrán migrar sin problemas a la interfaz oficial simplemente cambiando el campo model.
Q3: ¿Cómo entender el precio de $0.03 por solicitud?
Se factura por cada generación exitosa, sin límites de resolución, calidad o longitud de la indicación. Comparado con el precio estimado de la API oficial de OpenAI para gpt-image-2 ($0.15-$0.20), gpt-image-2-all cuesta entre 1/5 y 1/6. Las solicitudes fallidas (errores de autenticación, errores de parámetros) no se cobran, y no hay un límite estricto de concurrencia (está limitado naturalmente por el saldo de la cuenta).
Q4: ¿Por qué tarda 30 segundos en generar una imagen?
30 segundos es el tiempo de respuesta promedio actual de la solución de ingeniería inversa, cercano a la velocidad de la versión web de ChatGPT. Se espera que el gpt-image-2 oficial sea más rápido (unos 3 segundos) una vez que se abra, pero antes de que se publique la API oficial, gpt-image-2-all es la única solución capaz de invocar las capacidades más recientes de forma estable. Se recomienda configurar el tiempo de espera (timeout) del cliente en ≥120 segundos para evitar errores de tiempo de espera.
Q5: ¿Cómo integrar gpt-image-2-all?
La integración se completa en tres pasos:
- Visita APIYI en apiyi.com, registra una cuenta y obtén tu clave API.
- Configura la Base URL como
https://api.apiyi.com. - Utiliza la librería
requestspara llamar al endpoint/v1/images/generations(el SDK oficial requiere personalizar HTTP para evitar problemas con el parámetrosize).
Documentación detallada: docs.apiyi.com/api-capabilities/gpt-image-2-all/overview · Prueba en línea: imagen.apiyi.com
Q6: ¿Cuántas imágenes de referencia soporta la fusión de múltiples imágenes?
Una sola solicitud a /v1/images/edits soporta múltiples imágenes de referencia, cada una debe ser ≤10MB y en formato PNG/JPG/WebP. En la indicación, se hace referencia a ellas como "imagen1", "imagen2", "imagen3", etc. Las pruebas muestran que la fusión de 3 a 5 imágenes de referencia es lo más estable; más de 10 imágenes pueden provocar la pérdida de elementos.
Q7: ¿Por qué no puedo usar el SDK oficial de OpenAI directamente?
El método images.generate() del SDK oficial de OpenAI envía por defecto parámetros como size y n, los cuales gpt-image-2-all no acepta (esto activaría un error de validación). Soluciones recomendadas: (1) Enviar la solicitud HTTP directamente usando requests; o (2) sobrescribir el cuerpo de la solicitud del SDK para eliminar esos parámetros. Una vez que la versión oficial esté abierta, el SDK será compatible.
Q8: ¿Qué limitaciones conocidas tiene gpt-image-2-all?
Declaración objetiva de las limitaciones actuales:
- Salida de 1 imagen por solicitud: se requiere invocación concurrente para obtener varias.
- No soporta streaming: respuesta única, sin
stream. - Fase beta: la estabilidad está en constante optimización, con fluctuaciones ocasionales.
- Dependencia de ingeniería inversa: si la capacidad web de ChatGPT se ajusta temporalmente, el servicio podría verse afectado brevemente.
- Se recomienda combinar con modelos estables: para negocios críticos, se sugiere configurar simultáneamente gpt-image-1.5 o Nano Banana Pro como plan de respaldo.
Puntos clave de gpt-image-2-all
- Solución de ingeniería inversa · Traslado de las capacidades más recientes de ChatGPT: el único canal de nivel de producción antes de la apertura de la API oficial.
- $0.03/solicitud · Concurrencia ilimitada: facturación por éxito, costos transparentes, ideal para tuberías de procesamiento por lotes.
- Tres endpoints para todos los escenarios: texto a imagen / fusión de múltiples imágenes / edición conversacional.
- Chino nativo + texto de alta precisión: renderizado estable de texto en chino e inglés, sin necesidad de traducir la indicación.
- Ruta de inicio: registro en APIYI apiyi.com → timeout de 120 segundos → llamada directa con
requests.
Resumen
El valor fundamental de gpt-image-2-all:
- Cubre el vacío oficial: Antes de que OpenAI abra oficialmente la API de
gpt-image-2, ofrecemos una interfaz de nivel de producción para invocar de forma estable las capacidades de generación de imágenes más recientes de ChatGPT. - Costes significativamente inferiores a la estimación oficial: $0.03 por solicitud frente a los $0.15-$0.20 estimados oficialmente; una ventaja de costes destacada para escenarios de procesamiento por lotes.
- Diseño de migración fluida: Basado en el protocolo compatible con OpenAI, el día del lanzamiento de la versión oficial solo necesitarás reemplazar el nombre del modelo para realizar la transición.
Para la toma de decisiones de tu equipo, recomendamos integrar gpt-image-2-all a través de APIYI (apiyi.com) de inmediato para validar sus flujos de trabajo. El precio actual de $0.03 por solicitud hace que la validación masiva sea prácticamente gratuita. Cuando se lance oficialmente gpt-image-2, podrán cambiar según sea necesario. Los equipos que se anticipen obtendrán una ventaja competitiva significativa en el momento del lanzamiento del nuevo modelo.
Experiencia en línea: imagen.apiyi.com · Documentación en chino: docs.apiyi.com/api-capabilities/gpt-image-2-all/overview
Lecturas recomendadas
Si te interesa gpt-image-2-all, te recomendamos seguir leyendo:
- 📘 Análisis completo de las 8 grandes mejoras: gpt-image-2 vs gpt-image-1.5 – Entiende las razones detrás del salto en capacidades.
- 📊 Análisis completo de los 6 escenarios de aplicación de gpt-image-2 – Domina las rutas de implementación en negocios reales.
- 🚀 Comparativa profunda: gpt-image-2 vs Nano Banana Pro – Elige el modelo óptimo de forma racional.
📚 Referencias
-
Documentación oficial de APIYI: Especificaciones técnicas completas de gpt-image-2-all
- Enlace:
docs.apiyi.com/api-capabilities/gpt-image-2-all/overview - Descripción: Documentación de integración oficial y autorizada, incluye parámetros, códigos de error y mejores prácticas.
- Enlace:
-
Playground en línea de APIYI: imagen.apiyi.com
- Enlace:
imagen.apiyi.com - Descripción: Prueba los resultados de generación de imágenes de gpt-image-2-all sin necesidad de escribir código.
- Enlace:
-
Documentación de la API de imágenes de OpenAI: API del modelo de imagen más reciente
- Enlace:
openai.com/index/image-generation-api - Descripción: Compara y comprende las especificaciones de la API oficial gpt-image-1.5 de OpenAI.
- Enlace:
-
Observaciones de pruebas beta en LM Arena: Información filtrada sobre GPT Image 2
- Enlace:
mindstudio.ai/blog/what-is-gpt-image-2 - Descripción: Vista previa de las capacidades de la próxima generación de modelos de imagen.
- Enlace:
Autor: Equipo técnico de APIYI
Intercambio técnico: Te invitamos a participar en la sección de comentarios. Para más información, visita el centro de documentación de APIYI en docs.apiyi.com.