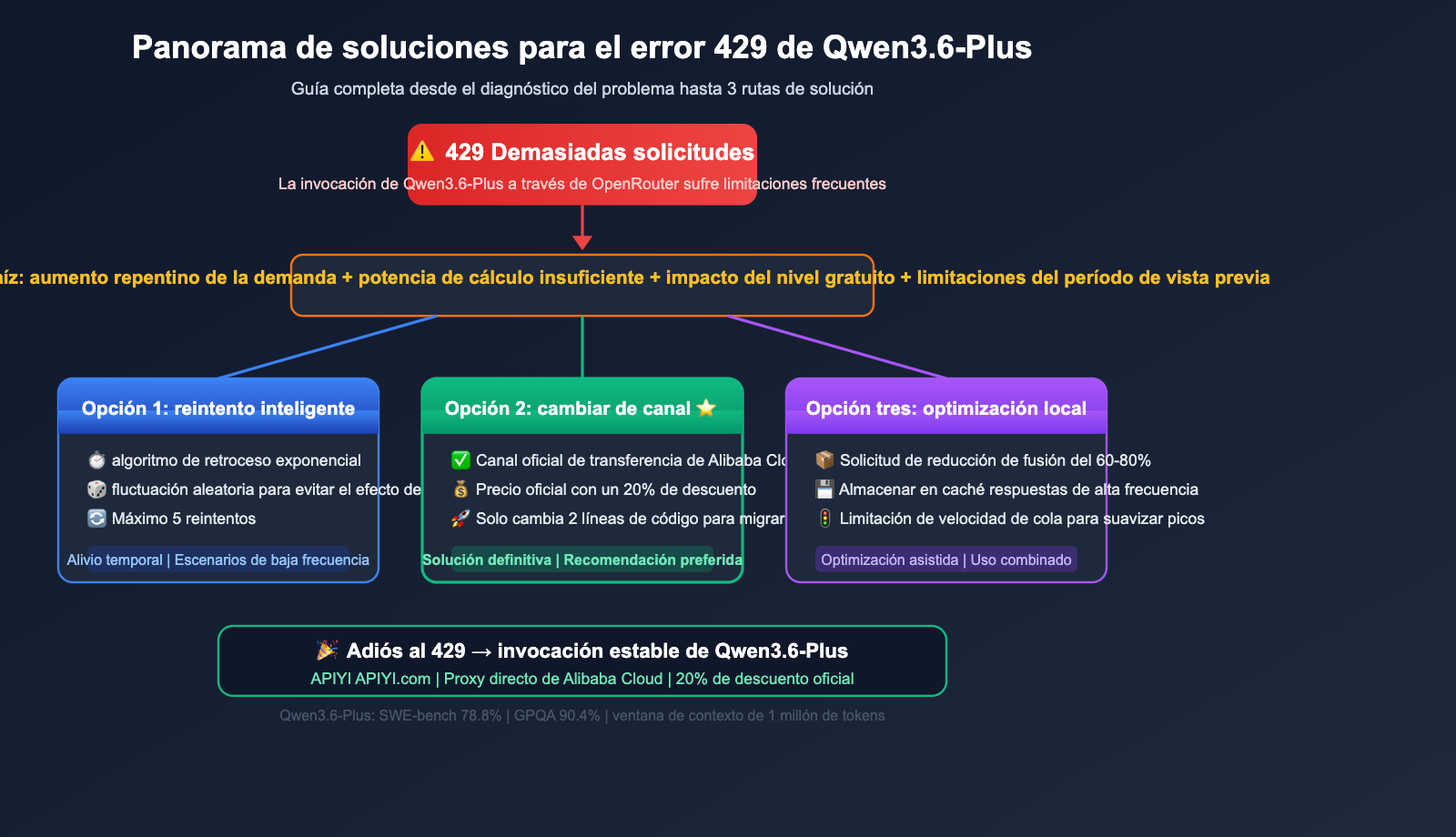
Cualquier desarrollador que haya utilizado Qwen3.6-Plus probablemente comparta el mismo sentimiento: al invocar este modelo en OpenRouter, el error 429 Too Many Requests se ha convertido en algo cotidiano. A pesar de haber pagado y no ser un usuario gratuito, las limitaciones de tasa te hacen cuestionar tu propia existencia.
Valor fundamental: Este artículo analiza a fondo la causa raíz del error 429 en Qwen3.6-Plus, ofrece 3 soluciones prácticas y comparte cómo lograr una invocación de API estable y económica a través del canal directo oficial de Alibaba Cloud.
Puntos clave sobre el error 429 en Qwen3.6-Plus
| Punto | Descripción | Beneficio para el desarrollador |
|---|---|---|
| Análisis de causa raíz del 429 | Exceso de demanda + abuso de niveles gratuitos + estrategia de asignación de cómputo | Comprender la esencia del problema, dejar de reintentar a ciegas |
| 3 soluciones | Estrategia de reintento / Cambio de canal / Acceso directo oficial | Elegir la ruta óptima según el escenario |
| Prueba de rendimiento | Comparativa de latencia entre canales de Qwen3.6-Plus | Elegir el método de acceso más estable |
| Ejemplo de código | Python/Node.js listo para ejecutar | Migración completada en 5 minutos |
Por qué Qwen3.6-Plus es tan popular
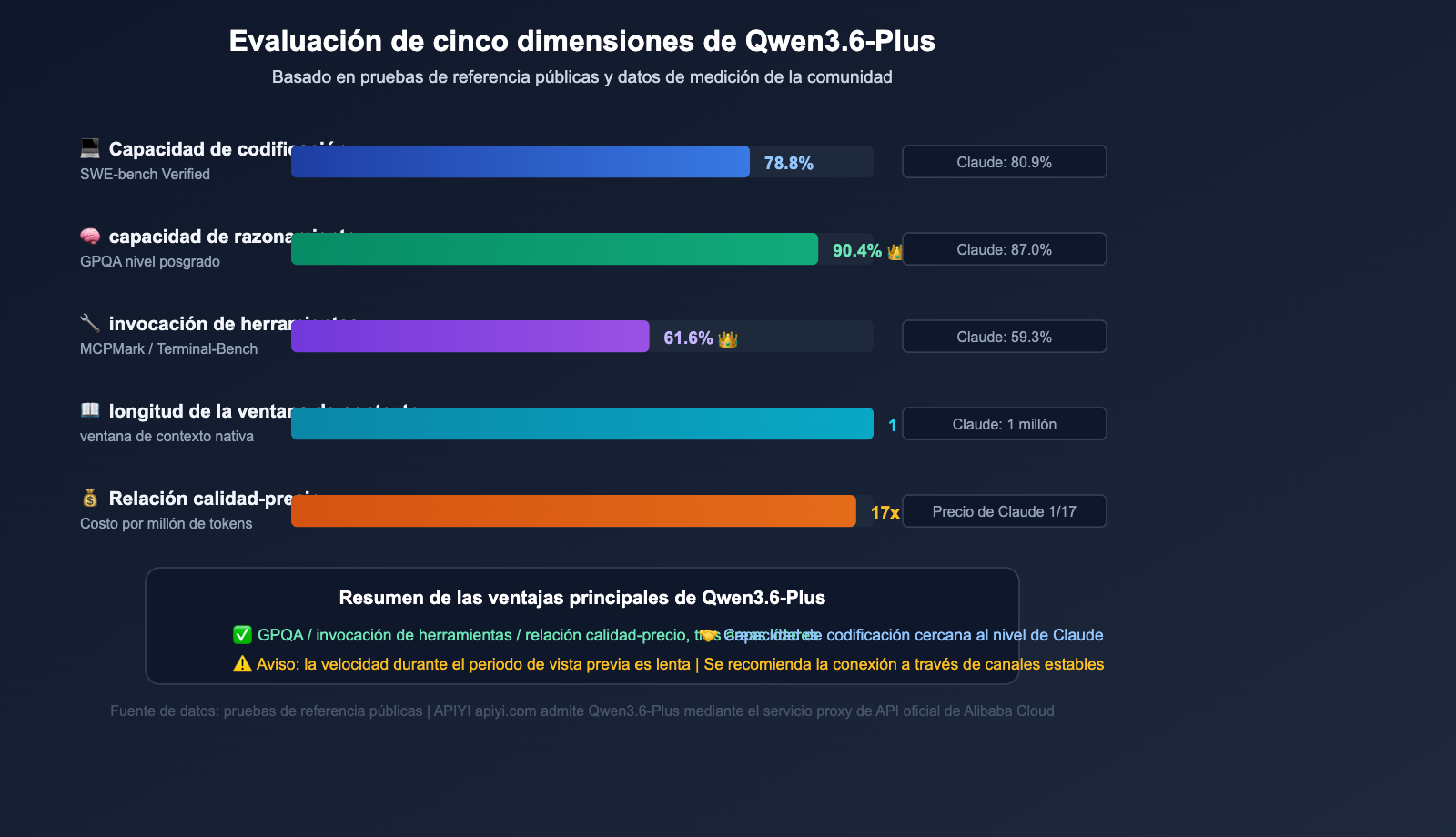
Qwen3.6-Plus es el modelo insignia lanzado por el equipo de Tongyi Qianwen de Alibaba en abril de 2026, compitiendo directamente con Claude Opus 4.5 y GPT-5.4. La razón de su popularidad es simple: alto rendimiento y bajo costo:
| Benchmarks | Qwen3.6-Plus | Claude Opus 4.5 | GPT-5.4 |
|---|---|---|---|
| SWE-bench Verified | 78.8% | 80.9% | 76.2% |
| Terminal-Bench 2.0 | 61.6% | 59.3% | 57.8% |
| GPQA (Ciencia nivel posgrado) | 90.4% | 87.0% | 88.1% |
| MCPMark (Invocación de herramientas) | 48.2% | 45.6% | 43.9% |
| Ventana de contexto | 1 millón de tokens | 1 millón de tokens | 256 mil tokens |
| Salida máxima | 65,536 tokens | 32,000 tokens | 16,384 tokens |
En los benchmarks clave Terminal-Bench y GPQA, Qwen3.6-Plus incluso supera a Claude Opus 4.5, mientras que el precio de la API oficial es solo aproximadamente 1/17 del de Claude. Esta relación costo-beneficio disparó la demanda de los desarrolladores, lo cual es precisamente la raíz del problema 429.
Análisis profundo del error 429 en Qwen3.6-Plus
¿Qué es el error 429?
El código de estado HTTP 429 tiene un significado muy claro: Too Many Requests (Demasiadas solicitudes). Este error aparece cuando el servidor recibe más peticiones de las que puede procesar o de las que permite su límite preestablecido en un intervalo de tiempo determinado.
Una respuesta típica de error 429 se ve así:
{
"error": {
"code": 429,
"message": "Rate limit exceeded. Please slow down your requests.",
"metadata": {
"provider_name": "Qwen",
"raw": "{\"error\":{\"message\":\"Rate limit reached\",\"type\":\"rate_limit_error\"}}"
}
}
}
4 razones principales de la frecuencia del error 429 en Qwen3.6-Plus en OpenRouter
Razón 1: La demanda supera con creces la oferta
La relación calidad-precio de Qwen3.6-Plus es imbatible. El precio oficial de la API es de aproximadamente $0.29 por millón de tokens de entrada, lo que equivale a 1/17 del costo de Claude Opus 4.5. Esto ha atraído a una gran cantidad de desarrolladores, mientras que OpenRouter, como servicio proxy de API, tiene una cuota de capacidad de cómputo limitada obtenida de Alibaba Cloud.
Razón 2: Uso intensivo por parte de usuarios del nivel gratuito
OpenRouter ofrece el modelo gratuito qwen/qwen3.6-plus:free, lo que atrae a muchos usuarios que no desean incurrir en costos. Estas solicitudes gratuitas comparten el mismo grupo de recursos backend que las solicitudes de pago, lo que provoca que los usuarios de pago también sufran las consecuencias.
Razón 3: Asignación conservadora de recursos durante el periodo de vista previa
Qwen3.6-Plus se encuentra actualmente en fase de vista previa (lanzada el 30 de marzo, con lanzamiento oficial el 2 de abril). Durante esta etapa, la asignación de potencia de cómputo de Alibaba Cloud para plataformas de terceros suele ser bastante conservadora, priorizando la calidad del servicio en sus propias plataformas (DashScope / Bailian).
Razón 4: Cuello de botella en la velocidad de inferencia del propio modelo
Aunque las pruebas de la comunidad muestran que el rendimiento de Qwen3.6-Plus es aproximadamente 3 veces mayor que el de Claude Opus 4.6, en el uso real, su ventana de contexto de 1 millón de tokens y su arquitectura MoE generan una latencia de respuesta aún elevada al procesar tareas complejas de agentes. Esto significa que cada solicitud ocupa la GPU durante más tiempo, reduciendo el número total de peticiones que se pueden procesar por unidad de tiempo.

🎯 Perspectiva clave: El error 429 no significa que tu código esté mal, sino que hay un desequilibrio entre la oferta y la demanda. La solución es buscar un canal con suficiente oferta en lugar de reintentar indefinidamente. Al conectarte a través del canal directo oficial de Alibaba Cloud mediante APIYI (apiyi.com), puedes evitar eficazmente los problemas de limitación de tasa de OpenRouter.
Solución 1 para el error 429 en Qwen3.6-Plus: Estrategia de reintento inteligente
Reintento con retroceso exponencial
Cuando no puedes cambiar de canal temporalmente, una estrategia de reintento razonable puede mitigar (aunque no curar por completo) el problema 429:
import openai
import time
import random
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Interfaz unificada de APIYI, redirección oficial de Alibaba Cloud
)
def call_qwen36_with_retry(messages, max_retries=5):
"""Invocación de Qwen3.6-Plus con retroceso exponencial"""
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=messages,
max_tokens=4096
)
return response.choices[0].message.content
except openai.RateLimitError as e:
if attempt == max_retries - 1:
raise
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"Límite de tasa 429, reintento {attempt+1}, esperando {wait_time:.1f}s...")
time.sleep(wait_time)
# Ejemplo de uso
result = call_qwen36_with_retry([
{"role": "user", "content": "Analiza los cuellos de botella de rendimiento de este código"}
])
print(result)
Recomendaciones de parámetros para la estrategia de reintento
| Parámetro | Valor recomendado | Explicación |
|---|---|---|
| Máximos reintentos | 3-5 veces | Más de 5 indica que el canal es inestable |
| Tiempo de espera inicial | 1-2 segundos | Demasiado corto es ineficaz, demasiado largo desperdicia tiempo |
| Factor de retroceso | 2x | El retroceso exponencial es el estándar de la industria |
| Jitter aleatorio | 0-1 segundos | Evita el "efecto manada" |
| Límite de tiempo de espera | 30 segundos | No esperar más de 30 segundos por intento |
Limitaciones de la estrategia de reintento
Es importante tener claro que: el reintento es solo un analgésico, no una cura. Cuando el backend de Qwen3.6-Plus en OpenRouter está constantemente sobrecargado, la tasa de éxito de la estrategia de reintento caerá drásticamente. La solución más fundamental es cambiar a un canal de API con suficiente capacidad.
Solución 2 para el error 429 en Qwen3.6-Plus: Cambiar de canal de API
Por qué cambiar de canal es más efectivo que reintentar
La causa raíz de los frecuentes errores 429 en OpenRouter es la insuficiencia de cuota de cómputo para Qwen3.6-Plus en ese canal. Cambiar a un canal conectado directamente a la capacidad de cómputo de Alibaba Cloud puede resolver el problema desde la raíz.
Comparativa de canales de API para Qwen3.6-Plus
| Canal | Estabilidad | Precio (Entrada/Millón de tokens) | Frecuencia de 429 | Recopilación de datos |
|---|---|---|---|---|
| OpenRouter Free | Mala | Gratis | Extremadamente alta | Sí (datos de entrenamiento) |
| OpenRouter Paid | Regular | ~$0.29 | Frecuente | Sí (periodo de vista previa) |
| Alibaba Cloud Bailian | Buena | ¥2.00 | Baja | Según acuerdo |
| APIYI (Directo Alibaba) | Buena | 20% de descuento oficial | Baja | No |
💡 Sugerencia de elección: Si tu aplicación requiere estabilidad, recomendamos acceder a Qwen3.6-Plus a través de APIYI (apiyi.com). Esta plataforma utiliza el canal de redirección oficial de Alibaba Cloud, con un precio de solo el 80% del oficial (descuento de grupo del 0.88 + 10$ de regalo por cada 100$ recargados), evitando al mismo tiempo los problemas de limitación de tasa de OpenRouter.
Migrar de OpenRouter a APIYI solo requiere cambiar 2 líneas de código
El coste de migración es mínimo, solo necesitas modificar base_url y api_key:
import openai
# ❌ Antes: OpenRouter (frecuentes 429)
# client = openai.OpenAI(
# api_key="sk-or-v1-xxxx",
# base_url="https://openrouter.ai/api/v1"
# )
# ✅ Ahora: APIYI Redirección Alibaba (estable, sin 429)
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[
{"role": "system", "content": "Eres un asistente profesional de revisión de código"},
{"role": "user", "content": "Ayúdame a optimizar el rendimiento de esta consulta SQL"}
],
max_tokens=8192
)
print(response.choices[0].message.content)
Versión para Node.js:
import OpenAI from 'openai';
const client = new OpenAI({
apiKey: 'YOUR_APIYI_KEY',
baseURL: 'https://api.apiyi.com/v1' // Interfaz unificada de APIYI
});
const response = await client.chat.completions.create({
model: 'qwen3.6-plus',
messages: [
{ role: 'user', content: 'Analiza la complejidad temporal de este código' }
],
max_tokens: 4096
});
console.log(response.choices[0].message.content);

Solución 3 para el error 429 en Qwen3.6-Plus: Optimización de solicitudes locales
Reducción de llamadas a la API innecesarias
Además de cambiar de canal, optimizar tu patrón de solicitudes puede reducir la probabilidad de activar un error 429:
1. Combinación de solicitudes
# ❌ Ineficiente: enviar una por una
for item in data_list:
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[{"role": "user", "content": f"Analiza: {item}"}]
)
# ✅ Eficiente: procesamiento por lotes
batch_content = "\n".join([f"{i+1}. {item}" for i, item in enumerate(data_list)])
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[{"role": "user", "content": f"Analiza el siguiente contenido secuencialmente:\n{batch_content}"}],
max_tokens=16384
)
2. Caché de respuestas de alta frecuencia
import hashlib
import json
_cache = {}
def cached_qwen_call(prompt, model="qwen3.6-plus"):
cache_key = hashlib.md5(f"{model}:{prompt}".encode()).hexdigest()
if cache_key in _cache:
return _cache[cache_key]
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
result = response.choices[0].message.content
_cache[cache_key] = result
return result
3. Limitación de velocidad en la cola de solicitudes
| Estrategia de optimización | Efecto | Escenario de aplicación |
|---|---|---|
| Combinación de solicitudes | Reduce el volumen de peticiones en un 60-80% | Procesamiento de datos por lotes |
| Caché de respuestas | Cero llamadas a la API para solicitudes idénticas | Escenarios de consultas repetitivas |
| Limitación de cola | Suaviza los picos de solicitudes | Aplicaciones de alta concurrencia |
| Estrategia de degradación | Cambio automático a un modelo menor ante 429 | Servicios sensibles a la latencia |
🔧 Consejo técnico: Las estrategias de optimización local anteriores funcionan mejor cuando se combinan con canales de API estables. Al acceder a Qwen3.6-Plus a través de APIYI (apiyi.com), combinando la combinación de solicitudes y las estrategias de caché, puedes reducir costos mientras garantizas la estabilidad.
Análisis de las causas de la lentitud en el modelo Qwen3.6-Plus
¿Por qué la respuesta de Qwen3.6-Plus a veces es muy lenta?
Muchos desarrolladores han reportado que, incluso sin encontrar errores 429, la velocidad de respuesta de Qwen3.6-Plus es "inexplicablemente lenta". Esto no es un caso aislado, sino que tiene razones técnicas subyacentes:
1. Sobrecarga de inferencia de la arquitectura MoE
Qwen3.6-Plus utiliza una arquitectura de Mezcla de Expertos (MoE). Aunque MoE puede reducir significativamente los costos de entrenamiento, en la etapa de inferencia, la toma de decisiones de enrutamiento y el cambio de expertos generan una sobrecarga adicional. Especialmente al procesar contextos largos, la eficiencia de inferencia de la arquitectura MoE es menor que la de un modelo denso con la misma cantidad de parámetros.
2. Presión de memoria para una ventana de contexto de 1 millón de tokens
La ventana de contexto de 1 millón de tokens es el punto fuerte de Qwen3.6-Plus, pero también implica que el KV Cache ocupa una enorme cantidad de memoria de video (VRAM) en la GPU. Cuando varios usuarios realizan solicitudes de contexto largo simultáneamente, la memoria de la GPU se convierte en un cuello de botella y la velocidad de inferencia disminuye significativamente.
3. Recursos de cómputo limitados durante el periodo de vista previa
Qwen3.6-Plus aún se encuentra en periodo de vista previa. En esta etapa, Alibaba Cloud generalmente no invierte la misma escala de potencia de cómputo que en el lanzamiento oficial. Es posible que el equipo oficial esté observando los patrones de uso reales antes de expandir gradualmente la capacidad.
4. Consumo adicional de tokens por la cadena de inferencia "Always-On"
Qwen3.6-Plus tiene activado por defecto el modo de inferencia "Always-On Chain-of-Thought" (cadena de pensamiento). Esto significa que el modelo genera un proceso de pensamiento interno en cada respuesta, por lo que la cantidad real de tokens generados es mucho mayor que la salida final. Estos "tokens ocultos" consumen tiempo de inferencia adicional.
Referencia de latencia medida en diferentes canales
| Canal | Latencia del primer token | Rendimiento (Token/s) | Notas |
|---|---|---|---|
| OpenRouter (pico) | 8-15s | 15-25 | Frecuentes 429 |
| OpenRouter (valle) | 3-5s | 30-50 | Horas de madrugada |
| Alibaba Cloud Bailian | 2-4s | 40-60 | Conexión directa nacional |
| APIYI (proxy directo) | 2-5s | 35-55 | Acceso estable desde el extranjero |
💰 Nota sobre costos: La velocidad de Qwen3.6-Plus varía significativamente según el canal y la carga. Si eres sensible a la latencia, te recomendamos realizar pruebas reales a través de APIYI (apiyi.com). La plataforma ofrece canales de transferencia directa oficiales de Alibaba Cloud, lo que te permite disfrutar de un 20% de descuento y obtener una velocidad de respuesta más estable.
Guía rápida de Qwen3.6-Plus
Ejemplo completo para invocar Qwen3.6-Plus mediante APIYI
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
# Conversación básica
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[
{"role": "system", "content": "Eres un experto desarrollador senior en Python"},
{"role": "user", "content": "Ayúdame a escribir un framework de scraping asíncrono de alto rendimiento"}
],
max_tokens=8192,
temperature=0.7
)
print(response.choices[0].message.content)
Ver código completo para salida en streaming
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
# Salida en streaming - ideal para escenarios que requieren respuesta en tiempo real
stream = client.chat.completions.create(
model="qwen3.6-plus",
messages=[
{"role": "system", "content": "Eres un arquitecto de software senior"},
{"role": "user", "content": "Diseña un sistema de colas de mensajes que soporte un millón de conexiones concurrentes"}
],
max_tokens=16384,
temperature=0.7,
stream=True
)
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="", flush=True)
print() # Salto de línea
🚀 Inicio rápido: Recomendamos obtener tu clave API a través de la plataforma APIYI (apiyi.com) para invocar Qwen3.6-Plus. Regístrate para probarlo; al recargar 100 USD obtienes 10 USD adicionales, y Qwen3.6-Plus cuenta con un descuento del 20% sobre el precio oficial.
Escenarios de uso y recomendaciones de selección para Qwen3.6-Plus
¿Para qué escenarios es ideal Qwen3.6-Plus?
| Escenario de aplicación | Razón recomendada | Alternativa |
|---|---|---|
| Automatización de Agentes | Lidera con 61.6% en Terminal-Bench, llamada a herramientas nativa | Claude Opus 4.5 |
| Revisión/Corrección de código | 78.8% en SWE-bench, nivel cercano a Claude | Claude Opus 4.5 |
| Razonamiento científico | 90.4% en GPQA, el más alto del mercado | GPT-5.4 |
| Procesamiento de documentos largos | Ventana de contexto de 1 millón de tokens | Gemini 2.5 Pro |
| Proyectos sensibles al costo | Aproximadamente 1/17 del precio de Claude | DeepSeek V3 |
¿En qué escenarios se debe usar con precaución?
- Aplicaciones en tiempo real extremadamente sensibles a la latencia: La arquitectura MoE de Qwen3.6-Plus presenta una latencia mayor con contextos largos.
- Rutas críticas en entornos de producción: Los modelos en fase de vista previa pueden tener cambios de comportamiento impredecibles.
- Escenarios que requieren garantías estrictas de SLA: No hay SLA formal durante la fase de vista previa.
🎯 Recomendación de selección: Para proyectos que requieren el uso simultáneo de múltiples modelos, sugerimos integrarlos de forma unificada a través de la plataforma APIYI (apiyi.com). La plataforma admite interfaces compatibles con OpenAI para modelos líderes como Qwen3.6-Plus, Claude y GPT, permitiéndote cambiar entre diferentes modelos con una sola clave API y facilitando la gestión flexible según el escenario.
Preguntas frecuentes sobre el error 429 en Qwen3.6-Plus
P1: ¿Por qué sigo recibiendo un error 429 si ya pagué en OpenRouter?
Esto sucede porque los usuarios de pago y los gratuitos en OpenRouter comparten el mismo grupo de recursos de cómputo. Incluso si tienes una cuenta de pago, cuando el volumen total de solicitudes supera la cuota que OpenRouter tiene asignada desde Alibaba Cloud, los usuarios de pago también sufren limitaciones. La solución es cambiar a un canal con mayor disponibilidad, como utilizar el canal de acceso directo oficial de Alibaba Cloud a través de APIYI (apiyi.com).
P2: ¿El error 429 en Qwen3.6-Plus mejorará con el tiempo?
A medida que Alibaba Cloud amplíe su capacidad y el modelo alcance su disponibilidad general (GA), se espera que el problema del 429 disminuya. Sin embargo, dado que OpenRouter es una plataforma de servicio proxy de API, su asignación de recursos siempre estará limitada por la oferta del proveedor. Si tu negocio requiere estabilidad, te recomendamos utilizar canales que conecten directamente con la infraestructura de Alibaba Cloud en lugar de depender de plataformas intermediarias.
P3: ¿Qué diferencia hay entre el Qwen3.6-Plus de APIYI y el de OpenRouter?
La diferencia principal radica en la fuente de los recursos de cómputo. La plataforma APIYI (apiyi.com) utiliza el canal oficial de acceso directo de Alibaba Cloud, por lo que la potencia proviene directamente de la plataforma Bailian de Alibaba, no de un intermediario. Esto se traduce en una menor tasa de errores 429 y una velocidad de respuesta más estable. En cuanto al precio, APIYI ofrece un descuento oficial del 20% (descuento de grupo del 0.88 + bonificaciones por recarga) y es compatible con el formato de SDK de OpenAI, por lo que el coste de migración es prácticamente nulo.
P4: ¿Es normal que Qwen3.6-Plus sea lento?
La arquitectura MoE de Qwen3.6-Plus y su ventana de contexto de 1 millón de tokens consumen, efectivamente, más recursos durante la inferencia que los modelos densos. Sumado a que la configuración de recursos durante el periodo de vista previa es conservadora, la lentitud es un fenómeno común en esta etapa. No obstante, su rendimiento absoluto sigue siendo considerable; te sugerimos utilizar la salida por streaming (stream=True) para mejorar la experiencia del usuario.
P5: ¿Cómo puedo usar Qwen3.6-Plus en Claude Code?
Qwen3.6-Plus es compatible tanto con el protocolo de Anthropic como con el de OpenAI. Puedes usar Qwen3.6-Plus modificando la configuración del endpoint de la API en Claude Code. Al conectarte a través de la plataforma APIYI (apiyi.com), simplemente utiliza el formato estándar del SDK de OpenAI; puedes consultar los detalles de configuración en la documentación de la plataforma.
Resumen de soluciones para el error 429 en Qwen3.6-Plus
El problema 429 en Qwen3.6-Plus es, en esencia, un problema de desequilibrio entre oferta y demanda: el modelo es muy potente, su precio es bajo y la demanda es enorme, lo que provoca que la cuota de cómputo de OpenRouter no pueda satisfacer a todos los usuarios.
Escenarios de aplicación para las tres soluciones:
- Reintento inteligente: Solución temporal, ideal para escenarios de invocación de baja frecuencia.
- Optimización local: Reduce el volumen de solicitudes, apto para todos los escenarios.
- Cambio de canal: La solución definitiva, recomendada para proyectos que requieren alta estabilidad.
Para los desarrolladores que necesitan una invocación estable de Qwen3.6-Plus, recomendamos acceder a través del canal oficial de Alibaba Cloud mediante la plataforma APIYI (apiyi.com). Disfruta de un 20% de descuento sobre el precio oficial y despídete de las limitaciones del error 429, permitiendo que tu aplicación se centre en la lógica de negocio en lugar de en el manejo de errores.
📝 Autor: Equipo de APIYI | Para más tutoriales sobre la integración de API de Modelos de Lenguaje Grande y guías para evitar errores, visita el Centro de Ayuda de APIYI: help.apiyi.com