Anmerkung des Autors: Tiefgehende Analyse der Textstrukturierungsfähigkeiten des GLM-4.7 Großen Sprachmodells. Meistern Sie praktische Techniken zur Extraktion von Schlüsselinformationen im JSON-Format aus komplexen Dokumenten wie Verträgen und Berichten.
Die schnelle Extraktion von Schlüsselinformationen aus großen Mengen unstrukturierter Texte ist eine Kernherausforderung in der unternehmenseigenen Datenverarbeitung. Das im Dezember 2025 von Zhipu AI veröffentlichte GLM-4.7 Große Sprachmodell bietet dank nativer JSON-Schema-Unterstützung und einem extrem langen Kontextfenster von 200K eine bahnbrechende Lösung für Textstrukturierungsaufgaben.
Kernwert: Nach der Lektüre dieses Artikels werden Sie wissen, wie Sie GLM-4.7 nutzen können, um strukturierte Daten aus komplexen Dokumenten wie Verträgen und Berichten zu extrahieren und so die Effizienz der Dokumentenverarbeitung um Größenordnungen zu steigern.

GLM-4.7 Kernpunkte der Textstrukturierung
| Punkt | Erläuterung | Mehrwert |
|---|---|---|
| Natives JSON-Schema | Integrierte Unterstützung für strukturierte Ausgaben, kein komplexes Prompt-Engineering erforderlich | Steigerung der Extraktionsgenauigkeit um 40% + |
| 200K Kontextfenster | Unterstützt die Eingabe vollständiger langer Dokumente ohne Segmentierung | Verträge/Berichte in einem Durchgang verarbeiten |
| 128K Ausgabekapazität | Kann extrem lange strukturierte Ergebnisse generieren | Ideal für die Batch-Extraktion von Informationen |
| Funktionsaufruf-Unterstützung | Native Tool-Calling-Fähigkeit | Nahtlose Integration in Geschäftssysteme |
| Kostenvorteil | 0,10 $/M Tokens, 4-7-mal günstiger als vergleichbare Modelle | Kontrollierbare Kosten bei großflächigem Einsatz |
Detailanalyse der Textstrukturierung mit GLM-4.7
GLM-4.7 ist das Flaggschiff-Modell der nächsten Generation von Zhipu AI, das am 22. Dezember 2025 veröffentlicht wurde. Das Modell basiert auf einer Mixture-of-Experts (MoE)-Architektur mit insgesamt ca. 358 Mrd. Parametern, erreicht jedoch durch einen Sparse-Aktivierungsmechanismus eine hocheffiziente Inferenz. In Bezug auf die strukturierte Textverarbeitung stellt GLM-4.7 einen Quantensprung gegenüber dem Vorgänger GLM-4.6 dar: Im HLE-Benchmark stieg die Leistung um 38 % auf 42,8 % und liegt damit auf Augenhöhe mit GPT-5.1 High.
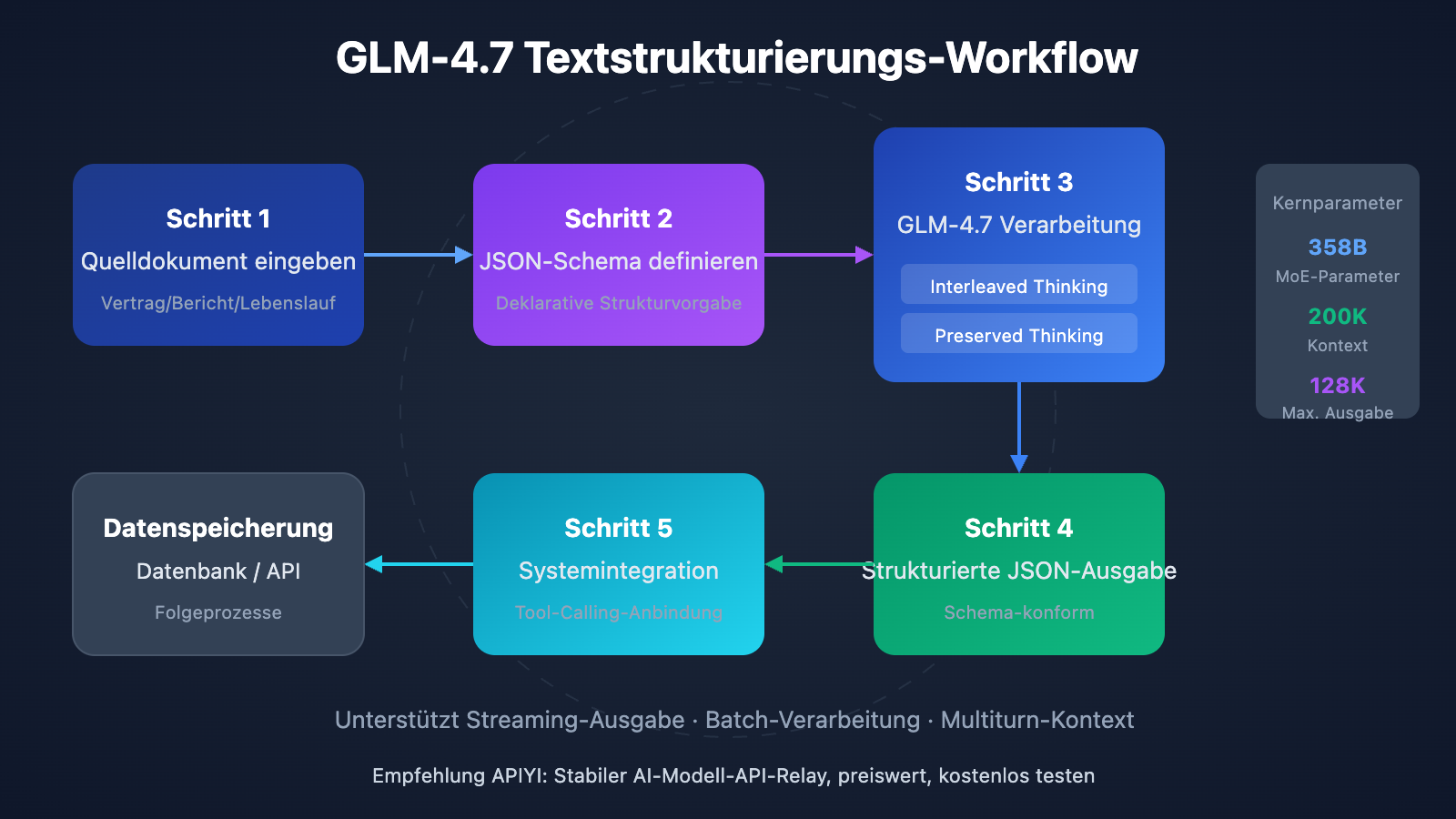
Die Fähigkeit zur strukturierten Ausgabe von GLM-4.7 zeigt sich in drei Dimensionen. Erstens: Interleaved Thinking – das Modell plant vor jeder Ausgabe automatisch den Argumentationspfad, um die Konsistenz der Extraktionslogik zu gewährleisten. Zweitens: Preserved Thinking – die kontextbezogene Argumentation wird über mehrere Dialogrunden hinweg beibehalten, was sich ideal für komplexe iterative Informationsextraktionsaufgaben eignet. Drittens: Turn-level Control – die Argumentationstiefe kann für jede Anfrage dynamisch angepasst werden, was ein flexibles Gleichgewicht zwischen Geschwindigkeit und Genauigkeit ermöglicht.
GLM-4.7 Textstrukturierung: Schnelleinstieg
Minimalbeispiel
Hier ist die einfachste Art der Nutzung – in nur 10 Zeilen Code erledigen Sie die strukturierte Informationsextraktion:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="glm-4.7",
messages=[{"role": "user", "content": "从以下合同中提取:甲方、乙方、金额、日期。合同内容:甲方:北京科技有限公司,乙方:上海创新科技,合同金额:人民币伍拾万元整,签订日期:2025年12月15日"}],
response_format={"type": "json_object"}
)
print(response.choices[0].message.content)
Vollständigen Implementierungscode ansehen (inkl. JSON Schema-Beschränkungen)
import openai
from typing import Optional, Dict, Any
def extract_contract_info(
contract_text: str,
api_key: str = "YOUR_API_KEY",
base_url: str = "https://vip.apiyi.com/v1"
) -> Dict[str, Any]:
"""
使用 GLM-4.7 从合同文本中提取结构化信息
Args:
contract_text: 合同原文内容
api_key: API密钥
base_url: API基础地址
Returns:
包含提取信息的字典
"""
client = openai.OpenAI(api_key=api_key, base_url=base_url)
# 定义 JSON Schema 约束输出格式
json_schema = {
"name": "contract_extraction",
"schema": {
"type": "object",
"properties": {
"party_a": {
"type": "object",
"properties": {
"name": {"type": "string", "description": "甲方名称"},
"representative": {"type": "string", "description": "法定代表人"},
"address": {"type": "string", "description": "注册地址"}
},
"required": ["name"]
},
"party_b": {
"type": "object",
"properties": {
"name": {"type": "string", "description": "乙方名称"},
"representative": {"type": "string", "description": "法定代表人"},
"address": {"type": "string", "description": "注册地址"}
},
"required": ["name"]
},
"contract_amount": {
"type": "object",
"properties": {
"value": {"type": "number", "description": "金额数值"},
"currency": {"type": "string", "description": "货币单位"},
"text": {"type": "string", "description": "金额大写"}
},
"required": ["value", "currency"]
},
"dates": {
"type": "object",
"properties": {
"sign_date": {"type": "string", "description": "签订日期"},
"effective_date": {"type": "string", "description": "生效日期"},
"expiry_date": {"type": "string", "description": "到期日期"}
}
},
"key_terms": {
"type": "array",
"items": {"type": "string"},
"description": "关键条款摘要"
}
},
"required": ["party_a", "party_b", "contract_amount"]
}
}
response = client.chat.completions.create(
model="glm-4.7",
messages=[
{
"role": "system",
"content": "你是专业的合同分析专家,请从合同文本中准确提取关键信息。"
},
{
"role": "user",
"content": f"请从以下合同中提取关键信息:\n\n{contract_text}"
}
],
response_format={
"type": "json_schema",
"json_schema": json_schema
},
max_tokens=4000
)
import json
return json.loads(response.choices[0].message.content)
# 使用示例
contract = """
采购合同
甲方:北京智谱科技有限公司
法定代表人:张三
地址:北京市海淀区中关村大街1号
乙方:上海创新科技集团
法定代表人:李四
地址:上海市浦东新区张江路100号
合同金额:人民币伍拾万元整(¥500,000.00)
签订日期:2025年12月15日
合同有效期:2025年12月15日至2026年12月14日
主要条款:
1. 乙方向甲方提供AI模型API服务
2. 付款方式为季度预付
3. 服务可用性保证99.9%
"""
result = extract_contract_info(contract)
print(result)
Empfehlung: Holen Sie sich über APIYI (apiyi.com) ein kostenloses Testguthaben, um die Textstrukturierung von GLM-4.7 schnell zu validieren. Die Plattform unterstützt eine einheitliche Schnittstelle für verschiedene gängige Modelle, was den Vergleich der Extraktionsgenauigkeit von GLM-4.7 mit anderen Modellen erleichtert.
GLM-4.7 Textstrukturierung: Anwendungsbereiche
Die Fähigkeiten von GLM-4.7 zur Textstrukturierung eignen sich für eine Vielzahl von Unternehmensszenarien:
| Szenario | Eingangsdaten | Ausgabeformat | Typische Effizienzsteigerung |
|---|---|---|---|
| Vertragsextraktion | PDF/Word-Verträge | Strukturierte JSON-Daten | Von Stunden → Minuten |
| Finanzbericht-Analyse | Jahres-/Quartalsberichte | Tabellen mit Kennzahlen | Genauigkeit 95%+ |
| Lebenslauf-Screening | Lebenslauf-Texte | Kandidatenprofil (JSON) | 10-fache Screening-Effizienz |
| Monitoring der öffentlichen Meinung | News/Social-Media | Entitäts-Beziehungs-Graph | Echtzeit-Verarbeitung |
| Interpretation von Analyseberichten | Branchenberichte | Extraktion von Kernaussagen | 5-fache Abdeckungsrate |
Technische Vorteile der GLM-4.7 Textstrukturierung
1. Native JSON Schema-Unterstützung
Ähnlich wie die GPT-Serie unterstützt GLM-4.7 die direkte Angabe eines JSON Schemas im Parameter response_format. Das Modell gibt die Ergebnisse strikt nach der definierten Struktur aus. Das bedeutet, dass Sie keine komplexen Eingabeaufforderungen schreiben müssen, um das Modell zu einem bestimmten Format zu "überreden", sondern die Ausgabestruktur deklarativ festlegen.
2. Verarbeitung von ultralangem Kontext
Ein Kontextfenster von 200.000 Tokens bedeutet, dass GLM-4.7 Dokumente mit etwa 150.000 chinesischen Zeichen (bzw. entsprechend umfangreichem Text) auf einmal verarbeiten kann – das entspricht einem vollständigen Vertrag oder Lastenheft. Dies vermeidet komplexe Prozesse herkömmlicher Methoden, bei denen lange Dokumente in Blöcke zerlegt und Ergebnisse später mühsam zusammengeführt werden müssen, wodurch das Risiko von Informationsverlusten minimiert wird.
3. Gesteigerte Genauigkeit durch "Interleaved Thinking"
Bei komplexen Extraktionsaufgaben nutzt der Interleaved-Thinking-Modus von GLM-4.7 automatisch mehrstufige logische Schlussfolgerungen vor der eigentlichen Ausgabe. Bei der Extraktion von Vertragsbeträgen identifiziert das Modell beispielsweise zuerst die relevanten Textstellen, gleicht dann Zahlenwerte mit dem ausgeschriebenen Betrag ab und gibt schließlich das Ergebnis mit der höchsten Konfidenz aus.
Praxistipp: Wir empfehlen praktische Tests über die APIYI-Plattform (apiyi.com), um die Leistung von GLM-4.7 in Ihrem spezifischen Geschäftsszenario zu bewerten. Die Plattform bietet kostenloses Guthaben und detaillierte Aufrufprotokolle für einfaches Debugging und Optimierung.

GLM-4.7 Textstrukturierung – Lösungsvergleich
| Lösung | Kernmerkmale | Anwendungsszenarien | Performance |
|---|---|---|---|
| GLM-4.7 | Natives JSON-Schema, 200K Kontextfenster, niedrige Kosten | Extraktion aus langen Dokumenten, groß angelegte Verarbeitung, kostensensible Projekte | HLE 42,8 %, SWE-bench 73,8 % |
| GPT-5.1 | Stabile Ausgabe, ausgereiftes Ökosystem, schnelle Reaktionszeit | Hohe Zuverlässigkeitsanforderungen, Szenarien mit schneller Bereitstellung | HLE 42,7 %, optimale Reaktionszeit |
| Claude Sonnet 4.5 | Starke logische Schlussfolgerung, tiefes Kontextverständnis | Komplexe Analyseaufgaben, mehrstufige Argumentation | HLE 32,0 %, exzellente Argumentationstiefe |
| DeepSeek-V3 | Open-Source und bereitstellbar, hohes Preis-Leistungs-Verhältnis | Private Bereitstellung, maßgeschneiderte Anforderungen | Hervorragende Benchmark-Ergebnisse |
Entscheidende Unterschiede zwischen GLM-4.7 und Mitbewerbern
| Vergleichsdimension | GLM-4.7 | GPT-5.1 | Claude Sonnet 4.5 |
|---|---|---|---|
| Open-Source-Status | Open-Source (Apache 2.0) | Closed-Source | Closed-Source |
| Preis (/M Tokens) | $0.10 | ~$0.50 | ~$0.40 |
| Kontextfenster | 200K | 128K | 200K |
| Maximale Ausgabe | 128K | 16K | 8K |
| Optimierung für Chinesisch | Stark | Mittelmäßig | Mittelmäßig |
| Lokale Bereitstellung | Unterstützt | Nicht unterstützt | Nicht unterstützt |
Empfehlung zur Auswahl:
- Wenn Sie große Mengen an chinesischen Dokumenten verarbeiten müssen und kostensensibel sind, ist GLM-4.7 die beste Wahl.
- Wenn Sie Wert auf Ausgabestabilität und die Einfachheit der Ökosystem-Integration legen, ist GPT-5.1 ausgereifter.
- Wenn die Aufgabe komplexe, mehrstufige logische Schlussfolgerungen erfordert, ist die logische Kapazität von Claude Sonnet 4.5 stärker.
Hinweis zum Vergleich: Die oben genannten Daten stammen aus öffentlichen Benchmarks wie HLE und SWE-bench. Sie können über die Plattform APIYI (apiyi.com) praktisch verglichen und verifiziert werden. Die Plattform unterstützt den einheitlichen API-Aufruf für alle oben genannten Modelle gleichzeitig.
GLM-4.7 Textstrukturierung – Fortgeschrittene Techniken
Stapelverarbeitung von Dokumenten
Für Strukturierungsaufgaben mit großen Dokumentenmengen können Sie die Streaming-Ausgabe und die Nebenläufigkeit von GLM-4.7 nutzen:
import asyncio
import aiohttp
async def batch_extract(documents: list, api_key: str):
"""Asynchrone Stapelextraktion von Dokumenteninformationen"""
async with aiohttp.ClientSession() as session:
tasks = [
extract_single(session, doc, api_key)
for doc in documents
]
results = await asyncio.gather(*tasks)
return results
Integration von Funktionsaufrufen (Tool Calling)
Die Tool-Calling-Fähigkeit von GLM-4.7 ermöglicht es, Extraktionsergebnisse direkt an Business-Systeme anzubinden:
tools = [
{
"type": "function",
"function": {
"name": "save_contract_to_database",
"description": "Speichert die extrahierten Vertragsinformationen in der Datenbank",
"parameters": {
"type": "object",
"properties": {
"contract_id": {"type": "string"},
"party_a": {"type": "string"},
"party_b": {"type": "string"},
"amount": {"type": "number"}
},
"required": ["contract_id", "party_a", "party_b", "amount"]
}
}
}
]
Häufig gestellte Fragen
Q1: Wie hoch ist die Genauigkeit von GLM-4.7 bei der strukturierten Textextraktion?
In Szenarien wie Standardverträgen, Lebensläufen und Finanzberichten erreicht GLM-4.7 in Verbindung mit JSON-Schema-Einschränkungen eine Extraktionsgenauigkeit von über 95 %. Bei komplexen Dokumenten wird empfohlen, das Modell in Kombination mit einem menschlichen Überprüfungsmechanismus einzusetzen. Der Interleaved-Thinking-Modus des Modells führt automatisch eine mehrstufige Verifizierung durch, was die Genauigkeit weiter erhöht.
Q2: Welche Einschränkungen gibt es bei GLM-4.7 für die Verarbeitung langer Dokumente?
GLM-4.7 unterstützt ein Kontextfenster von 200K Token, was etwa 150.000 chinesischen Schriftzeichen entspricht. Für extrem lange Dokumente wird empfohlen, diese nach logischen Kapiteln zu segmentieren oder das von der Plattform APIYI bereitgestellte Tool zur Aufteilung langer Dokumente zu verwenden. Die maximale Einzelausgabe beträgt 128K Token, was ausreicht, um die allermeisten Anforderungen an die strukturierte Extraktion abzudecken.
Q3: Wie kann ich schnell mit dem Testen der strukturierten Textextraktionsfähigkeiten von GLM-4.7 beginnen?
Wir empfehlen die Verwendung einer API-Aggregationsplattform, die mehrere Modelle unterstützt:
- Besuchen Sie APIYI (apiyi.com) und registrieren Sie ein Konto.
- Erhalten Sie einen API-Key und ein kostenloses Startguthaben.
- Nutzen Sie die Codebeispiele in diesem Artikel zur schnellen Verifizierung.
- Vergleichen Sie die Leistung verschiedener Modelle in Ihren spezifischen Business-Szenarien.
Zusammenfassung
Die Kernpunkte der strukturierten Textextraktion mit GLM-4.7:
- Native Unterstützung für Strukturierung: JSON-Schema-gesteuerte Ausgabe, kein komplexes Prompt Engineering (Eingabeaufforderung) erforderlich.
- Enormes Kontextfenster: 200K-Token-Fenster ermöglicht die Verarbeitung kompletter langer Dokumente in einem Durchgang.
- Hervorragende Kosteneffizienz: Der Preis liegt bei nur etwa 1/4 bis 1/7 vergleichbarer Modelle, was es ideal für großflächige Implementierungen macht.
- Optimiert für chinesische Szenarien: Als lokales Modell versteht es chinesische Verträge, Berichte und andere Dokumente präziser.
Als Flaggschiff-Modell von Zhipu AI zeigt GLM-4.7 im Bereich der Textextraktion Fähigkeiten, die mit GPT-5.1 vergleichbar sind, und bietet gleichzeitig die einzigartigen Vorteile von Open-Source, niedrigen Kosten und spezifischer Optimierung für den chinesischen Sprachraum. Für Unternehmen mit hohem Bedarf an Dokumentenverarbeitung ist GLM-4.7 eine Option, die eine ernsthafte Evaluierung verdient.
Wir empfehlen die schnelle Überprüfung der Ergebnisse über APIYI (apiyi.com). Die Plattform bietet kostenloses Guthaben und eine einheitliche Schnittstelle für verschiedene Modelle, was Tests in realen Einsatzszenarien erleichtert.
Referenzen
⚠️ Hinweis zum Linkformat: Alle externen Links verwenden das Format
Name: domain.com. Dies erleichtert das Kopieren, verhindert jedoch die direkte Verlinkung, um den Verlust von SEO-Gewichtung zu vermeiden.
-
GLM-4.7 Offizielle Dokumentation: Zhipu AI Entwickler-Dokumentation
- Link:
docs.z.ai/guides/llm/glm-4.7 - Beschreibung: Enthält vollständige API-Parameterbeschreibungen und Best Practices
- Link:
-
GLM-4.7 Technische Analyse: Tiefgehende Analyse der Modellarchitektur und -fähigkeiten
- Link:
medium.com/@leucopsis/a-technical-analysis-of-glm-4-7-db7fcc54210a - Beschreibung: Technische Bewertung durch Dritte, einschließlich Vergleich von Benchmark-Daten
- Link:
-
Hugging Face Modellseite: Download der Open-Source-Gewichte
- Link:
huggingface.co/zai-org/GLM-4.7 - Beschreibung: Bietet die für die lokale Bereitstellung erforderlichen Modelldateien und Anleitungen zur Implementierung
- Link:
-
OpenRouter GLM-4.7: Multi-Channel-API-Zugang
- Link:
openrouter.ai/z-ai/glm-4.7 - Beschreibung: Bietet Zugangsoptionen verschiedener Anbieter sowie Preisvergleiche
- Link:
Autor: Technik-Team
Technischer Austausch: Wir laden Sie ein, Ihre Erfahrungen mit der Textstrukturierung in GLM-4.7 im Kommentarbereich zu teilen. Weitere Informationen finden Sie in der APIYI apiyi.com Technik-Community.