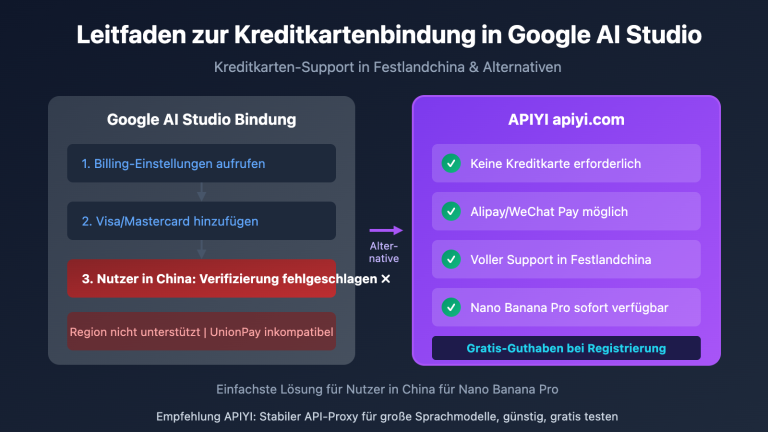
Viele Teams, die die Gemini-API für Bilderkennungsaufgaben nutzen, stehen vor demselben Rätsel: Lädt man dasselbe Bild mit derselben Eingabeaufforderung bei gemini.google.com hoch, erkennt das Modell Details präzise und liefert strukturierte Antworten. Wechselt man jedoch zur gemini-3.5-flash-API, wirkt das Ergebnis deutlich oberflächlicher oder lässt sogar wichtige Informationen aus. Diese Diskrepanz zwischen "starker Webseite" und "schwacher API" liegt nicht daran, dass das Modell selbst gedrosselt wurde, sondern daran, dass die technischen Unterschiede zwischen der Weboberfläche und der API für Sie sichtbar werden.
Dieser Artikel basiert auf einer zentralen Erkenntnis: Die Webversion von Gemini ist ein umfassender Agent, der automatisch Eingabeaufforderungen optimiert, mehrstufige Schlussfolgerungen zieht, Tools aufruft und Ergebnisse validiert. Der API-Aufruf hingegen nutzt das nackte Modell – was Sie senden, ist das, was Sie bekommen. Wenn Sie diesen Unterschied verstehen, können Sie mit den folgenden 6 Tipps, die weit über das bloße "Anpassen der Eingabeaufforderung" hinausgehen, die Qualität Ihrer Bilderkennung stabil auf das Niveau der Webseite heben.
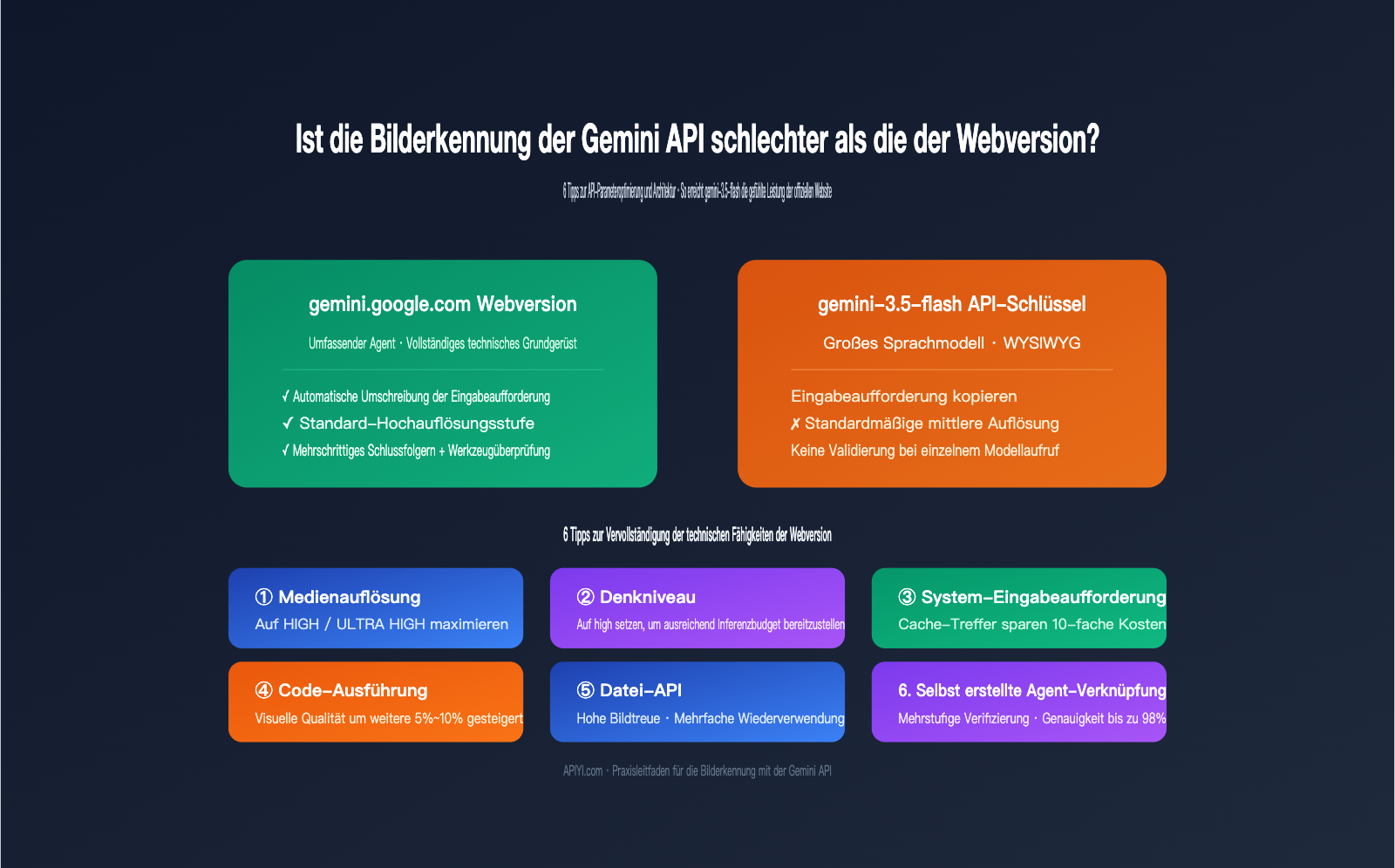
Warum die Gemini-API bei der Bilderkennung hinter der Webversion zurückbleibt: Der Unterschied zwischen Agent und nacktem Modell
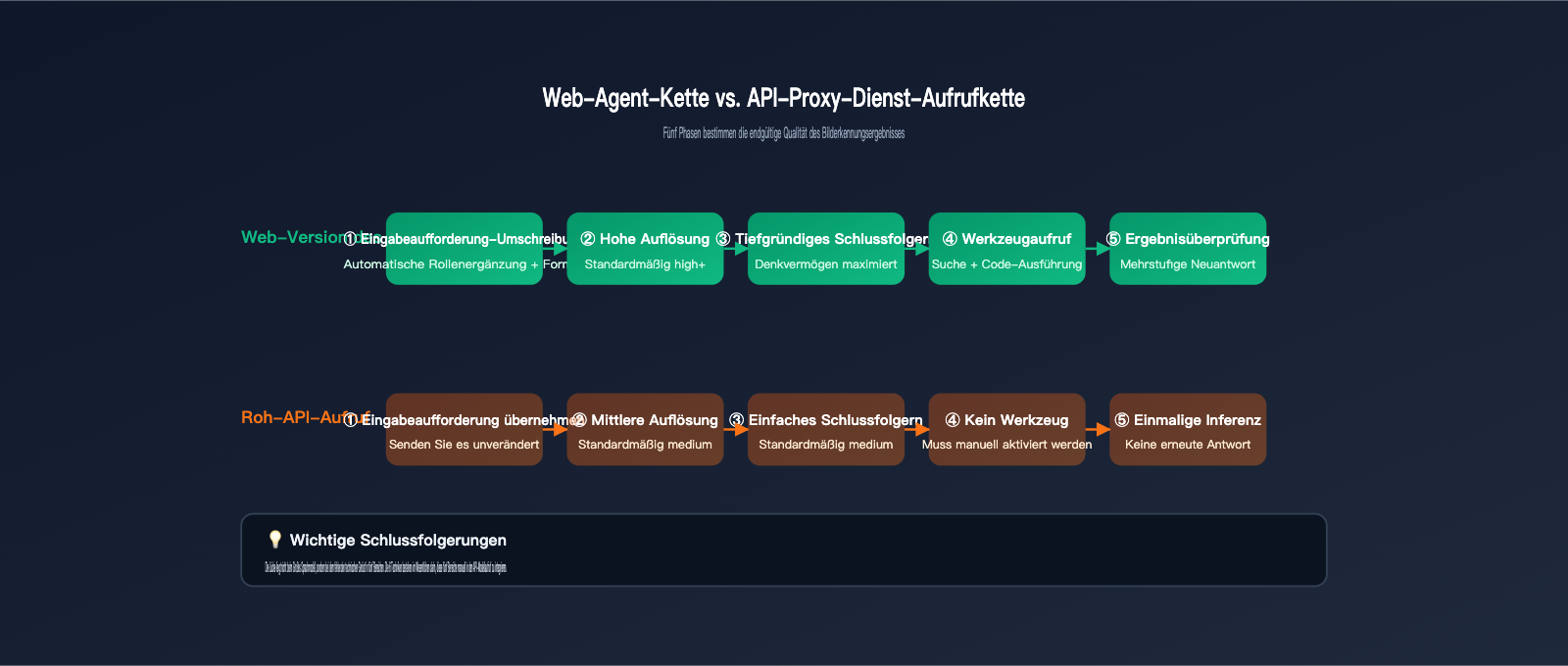
Um diesen Unterschied zu verstehen, muss man zunächst wissen, wie viel Arbeit gemini.google.com zwischen dem Hochladen eines Bildes und der endgültigen Antwort für Sie erledigt. Basierend auf Googles Dokumentation zu "Agentic Vision" und unseren Beobachtungen bei APIYI (apiyi.com) hinsichtlich der Unterschiede zwischen Webseite und API, ist die Webversion im Wesentlichen ein produktiver Agent, der um das Basismodell herum aufgebaut ist. Er erledigt mindestens 5 Aufgaben, die Sie nicht explizit angefordert haben:
- Automatische Optimierung der Eingabeaufforderung: Er ergänzt "Erkenne dieses Bild" um Rollenzuweisungen, Aufgabenbeschreibungen und ein gewünschtes Ausgabeformat.
- Höhere Bildauflösung: Intern wird das Bild mit einer höheren Auflösung verarbeitet, um sicherzustellen, dass Details nicht zu unscharfen Pixeln komprimiert werden.
- Höheres Schlussfolgerungsbudget: Standardmäßig ist ein intensives Schlussfolgerungsbudget aktiviert (ähnlich wie
thinking_level=high), damit das Modell Zeit zum "Nachdenken" hat. - Tool-Nutzung: Bei Bedarf werden interne Tools wie Code-Ausführung oder Websuche zur Kreuzvalidierung genutzt, um die Richtigkeit der Details zu bestätigen.
- Ergebnisprüfung: Die Ausgabe wird formatiert und auf Plausibilität geprüft; bei vagen Antworten wird das Modell erneut befragt.
Wenn Sie die API direkt aufrufen, passiert keine dieser 5 Dinge automatisch. Mit anderen Worten: Sie nutzen ein Modell mit vollem Funktionsumfang, aber ohne das "technische Gerüst". Die folgende Tabelle verdeutlicht die Unterschiede in der Prozesskette:
| Vergleichsdimension | gemini.google.com Webseite | gemini-3.5-flash API |
|---|---|---|
| Eingabeaufforderung | Automatische Umschreibung & Rollen/Format-Ergänzung | Übernimmt Benutzereingabe 1:1 |
| Bildauflösung | Standardmäßig hoch | Standardmäßig mittel (manuelle Anpassung nötig) |
| Schlussfolgerungsbudget | Hoch, ohne explizites Limit | Standardmäßig mittel (manuell via thinking_level einstellbar) |
| Tool-Aufruf | Standardmäßig Suche & Code-Ausführung | Standardmäßig deaktiviert (muss explizit aktiviert werden) |
| Ergebnisprüfung | Mehrstufige Agenten-Validierung | Einmalige Schlussfolgerung, keine Validierung |
| Abrechnungstransparenz | Durch monatliche Abos abgedeckt | Abrechnung pro Token |
Wir empfehlen, über ein Aggregator-Gateway wie APIYI (apiyi.com) dasselbe Bild und dieselbe Eingabeaufforderung parallel an die gemini-3.5-flash API, Claude Opus und GPT-5.5 zu senden. So lässt sich schnell feststellen, ob die aktuelle Aufgabe durch die Modellkapazität oder durch die technische Kette limitiert ist.
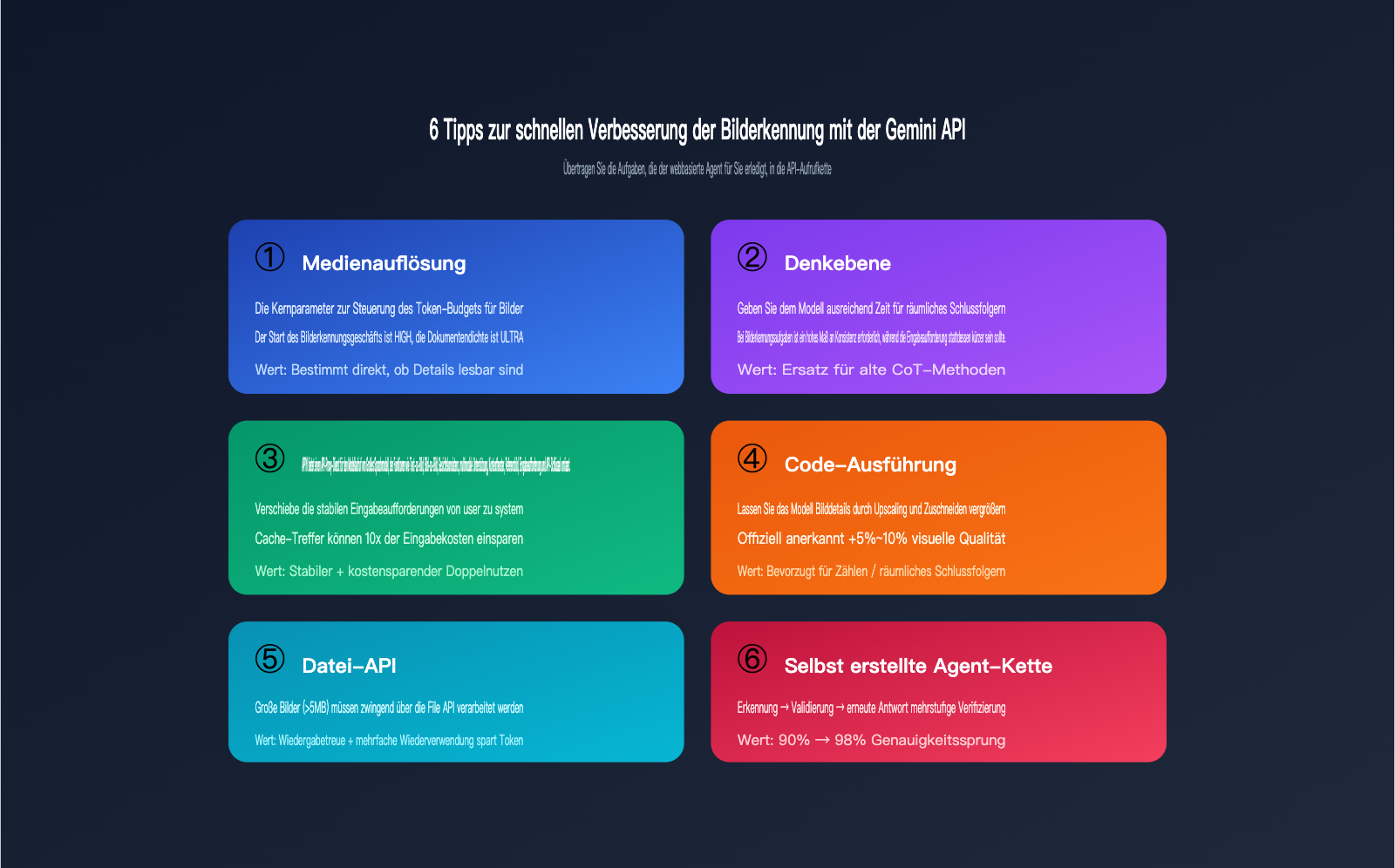
Gemini API-Tipp 1: Erhöhen des Parameters media_resolution
Ab der Gemini 3-Serie wurde der Parameter media_resolution eingeführt. Er steuert direkt, wie viele Token die API für die Bildanalyse bereitstellt. Dieser Parameter bietet die vier Stufen low, medium, high und ultra high, wobei standardmäßig meist medium eingestellt ist. Bei bildintensiven Details wie kleinem Text, Belegen, Schaltplänen oder UI-Screenshots reicht medium oft nicht aus: Das Modell komprimiert das Bild zu einer groben Feature-Map, wodurch Details verloren gehen.
Die folgende Tabelle zeigt die Unterschiede der vier Stufen, damit Sie je nach Aufgabenstellung die richtige Wahl treffen können:
| Auflösungsstufe | Token-Verbrauch | Anwendungsbereich | Typisches Problem |
|---|---|---|---|
| low | Niedrig | Vorschaubilder, Logo-Erkennung | Kleiner Text geht fast vollständig verloren |
| medium (Standard) | Mittel | Normale Fotos, Porträts | Details wirken unscharf |
| high | Hoch | Dokumente, Tabellen, Belege | Informationen sind weitgehend lesbar |
| ultra high | Sehr hoch | Komplexe Zeichnungen, dichte UI | Nahe an der Erkennungsqualität der Website |
Für die Bilderkennung reicht es meist aus, den Parameter von medium auf high zu stellen, um die Erkennungsgenauigkeit sofort zu steigern. Wenn Ihr Budget es zulässt und die Aufgabe tatsächlich kleinen Text oder komplexe Tabellen umfasst, ist ultra high eine sinnvolle Wahl.
# Aufruf von gemini-3.5-flash über APIYI mit expliziter Festlegung der Medienauflösung auf high
from google import genai
from google.genai import types
client = genai.Client(
api_key="YOUR_APIYI_KEY",
http_options={"base_url": "https://api.apiyi.com"}
)
resp = client.models.generate_content(
model="gemini-3.5-flash",
contents=[image_part, "Extrahiere den gesamten sichtbaren Text aus dem Bild und gib ihn als Tabelle aus"],
config=types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH"
)
)
print(resp.text)
Bei der Nutzung über APIYI (apiyi.com) werden die Parameter direkt an das Backend durchgereicht und nicht vom Gateway neu verpackt. Sie können die Werte also bedenkenlos gemäß der offiziellen Dokumentation übergeben.
Gemini API-Tipp 2: Explizite Aktivierung von thinking_level=high
Gemini 3.5 Flash führt den Parameter thinking_level ein, der die interne logische Tiefe des Modells vor der Antwortausgabe steuert. Bei Bilderkennungsaufgaben liegt der Unterschied zwischen "Details erkennen" und "Fehler machen" oft darin, ob das Modell "lange genug" und "gründlich genug" nachdenkt. Die Standardeinstellung der API ist eher auf Geschwindigkeit als auf Qualität optimiert. Für die Bilderkennung empfiehlt es sich, den Wert aktiv auf high zu setzen, damit das Modell genügend Zeit für räumliche Schlussfolgerungen und Zählaufgaben hat, ähnlich wie in der Web-Version.
| thinking_level | Empfohlener Einsatz | Wahrnehmbarer Unterschied |
|---|---|---|
| low | Einfache Dialoge, Stilanalysen | Schnell, grobe Erkennung |
| medium | Allgemeine Fragen | Durchschnittliches Niveau |
| high (Empfohlen) | Dokumente, Belege, Zählen, räumliche Logik | Nahe am Erlebnis der Website |
Die offizielle Dokumentation weist zudem auf einen kontraintuitiven Punkt hin: Wenn thinking_level=high verwendet wird, sollte die Eingabeaufforderung direkter und prägnanter formuliert werden. Vermeiden Sie alte "Chain-of-Thought"-Muster wie "Bitte denke Schritt für Schritt nach" oder "Bitte berücksichtige alle Eventualitäten". Diese Ansätze waren für ältere Modelle gedacht; bei der Gemini 3-Serie führen sie oft zu einer "Überanalyse".
🎯 Empfehlung zur Parameterwahl: Nutzen Sie die Kombination
media_resolution=HIGHundthinking_level=highals Standard für Bilderkennungsaufgaben und hinterlegen Sie diese in Ihren Aufruf-Templates bei APIYI (apiyi.com). Justieren Sie anschließend je nach Ergebnis in Richtungultra highoderlow, anstatt bei jeder Anfrage erneut mit Parametern zu experimentieren.
Gemini API-Tipps für die Bilderkennung (Teil 3): Anweisungen in system_instruction statt in den user prompt schreiben
Ein häufiger Fehler bei der Arbeit mit APIs besteht darin, alles in den user prompt zu stopfen: Rollendefinitionen, Aufgabenbeschreibungen, Ausgabeformate und die eigentliche Benutzeranfrage – alles vermischt in einem einzigen Textblock. Diese Vorgehensweise zwingt das Modell dazu, den Kontext jedes Mal neu zu verarbeiten, während die „System-Eingabeaufforderung“ in der Web-Version für das Caching optimiert ist.
Der richtige Ansatz ist es, Ihre „stabilen Anweisungen“ in die system_instruction zu verlagern:
config = types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH",
thinking_level="high",
system_instruction=(
"Du bist ein präziser Assistent für die Bildanalyse."
"Antworte nur unter Bezugnahme auf Details, die im Bild klar erkennbar sind, und stelle keine Vermutungen an."
"Gib die Antwort als strukturiertes JSON aus, mit den festen Feldern entities/attributes/text."
)
)
Dies bringt zwei Vorteile: Das Modell antwortet konsistent nach einheitlichen Regeln, was die Ergebnisse stabilisiert. Zudem können die Eingabekosten nach Aktivierung des System Prompt Caching um das Zehnfache sinken – ein enormer Mehrwert für langfristige Batch-Verarbeitungen bei der Bilderkennung. Im Backend von APIYI (apiyi.com) können Sie die Cache-Trefferquote pro Modell-ID einsehen, um den Optimierungserfolg bequem zu überwachen.
Gemini API-Tipps für die Bilderkennung (Teil 4): Code-Ausführung aktivieren, damit das Modell „ins Bild zoomen“ kann
Google hat in der Ankündigung zur Agentic Vision für Gemini 1.5 Flash (bzw. 3.0 Flash) einen klaren Wert geliefert: Durch die Aktivierung der Code-Ausführung zusätzlich zum nativen Modell lässt sich die Qualität bei Bilderkennungsaufgaben um durchschnittlich 5 % bis 10 % steigern. Das Prinzip dahinter: Das Modell kann intern Python-Code generieren, um Bilder zuzuschneiden, zu vergrößern, zu drehen oder Pixelwerte auszulesen, und die verarbeiteten Teilbilder anschließend erneut zur Analyse verwenden. Genau das tut die Web-Version standardmäßig.
Die API aktiviert die Code-Ausführung nicht automatisch; sie muss explizit deklariert werden:
config = types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH",
thinking_level="high",
tools=[types.Tool(code_execution=types.ToolCodeExecution())]
)
resp = client.models.generate_content(
model="gemini-1.5-flash",
contents=[image_part, "Zähle alle roten Knöpfe im Bild und liste ihre Positionen auf"],
config=config
)
Für Aufgaben wie Zählen, räumliches Denken oder die Analyse komplexer Benutzeroberflächen – Bereiche, in denen die Code-Ausführung laut Google nachweislich hilft – ist dies die effizienteste Optimierung. Wir bei APIYI (apiyi.com) haben beobachtet, dass die Latenz bei aktivierter Code-Ausführung leicht ansteigt. Daher empfehlen wir, diese Funktion bei asynchronen Prozessen standardmäßig zu aktivieren und bei synchronen Anwendungen je nach Bedarf zuzuschalten.
Gemini API-Tipps Teil 5: Große Bilder über die File API statt Base64-Inline
Bei Bildern, die größer als ein paar Megabyte sind, betten viele Teams diese direkt als Base64-kodierte Strings in den Request-Body ein. Bei kleinen Dateien ist das unproblematisch, doch sobald die Gesamtgröße des Requests 20 MB überschreitet, greifen die Limits von Gemini. Dies führt dazu, dass Bilder im Hintergrund komprimiert werden, was die Qualität der Analyse spürbar verschlechtert.
Die offiziellen Grenzwerte für die Übertragungsmethode sind klar definiert:
| Bildgröße | Empfohlene Übertragung | Grund |
|---|---|---|
| Unter 5 MB | Base64-Inline | Schlanke Requests, einfache Implementierung |
| 5–20 MB | File API-Upload | Vermeidung von aufgeblähten Request-Größen |
| Über 20 MB | File API erforderlich | Base64-Kodierung beschädigt den Request |
| Mehrfache Nutzung | File API empfohlen | Einmal hochladen, mehrfach referenzieren (spart Token) |
Ein weiterer Vorteil der File API ist, dass dasselbe Bild in mehreren Requests wiederverwendet werden kann, was den Upload-Aufwand minimiert. Über das API-Gateway von APIYI (apiyi.com) nutzen die Endpunkte der File API dieselben Anmeldedaten, sodass Sie kein separates Google Cloud-Konto für den Bild-Upload benötigen.

Gemini API-Tipps für die Bilderkennung (Teil 6): Aufbau einer Agent-Kette für mehrstufige Validierung
Nachdem Sie die ersten fünf Tipps umgesetzt haben, ist Ihr einzelner API-Aufruf bereits sehr nah an der Qualität der Web-Version. Die Web-Oberfläche hat jedoch noch ein Ass im Ärmel: die mehrstufige Validierung. Dabei wird nach der ersten Antwort eine zweite Schlussfolgerung gezogen, um wichtige Fakten zu prüfen. Bei unsicheren Ergebnissen wird eine "erneute Antwort" ausgelöst. Da es für die API keinen fertigen Schalter dafür gibt, müssen Sie eine einfache Agent-Kette aufbauen.
Eine minimale, funktionsfähige Zwei-Schritte-Kette sieht so aus:
- Erster Aufruf: Lassen Sie
gemini-3.5-flashein strukturiertes Erkennungsergebnis generieren (JSON-Ausgabe). - Zweiter Aufruf: Speisen Sie das Ergebnis zusammen mit dem Originalbild erneut ein und fragen Sie das Modell: "Basierend auf diesem Bild, sind die folgenden Schlussfolgerungen jeweils korrekt?"
Wenn der zweite Aufruf ein "inkorrektes" Feld identifiziert, lösen Sie einen dritten Aufruf zur "erneuten Beantwortung" aus. Diese Kette lässt sich bei APIYI (apiyi.com) direkt mit derselben base_url und demselben API-Schlüssel verknüpfen, ohne dass zusätzliche Dienste erforderlich sind. Für geschäftliche Anwendungen mit hohen Anforderungen an die Erkennungsgenauigkeit (Vertragserkennung, unterstützende Kennzeichnung medizinischer Bilder, Sicherheits- und Compliance-Prüfungen) ist die mehrstufige Validierung der entscheidende Schritt, um die Genauigkeit von 90 % auf 98 % zu steigern.
| Aufgabentyp | Empfohlene Kette | Parameter für Einzelschritt |
|---|---|---|
| Allgemeine Bilderkennung | Einzelschritt | high + thinking_high |
| Dokumentenextraktion | Einzelschritt + JSON-Validierung | ultra high + thinking_high |
| Komplexe Zählaufgaben | Zweischritt + Code-Ausführung | high + thinking_high + tools |
| Hochpräzise Geschäftsanwendungen | Dreischritt-Kette (Erkennung → Validierung → Korrektur) | ultra high + thinking_high + tools |
Praxis-Parameter-Vorlage: 6 Tipps in einem wiederverwendbaren Aufruf vereinen
Damit Sie die Tipps direkt anwenden können, finden Sie hier eine Standardvorlage für Bilderkennungsaufgaben, die alle 6 Tipps kombiniert und als Ausgangspunkt für die meisten geschäftlichen Anforderungen dient:
from google import genai
from google.genai import types
client = genai.Client(
api_key="YOUR_APIYI_KEY",
http_options={"base_url": "https://api.apiyi.com"}
)
SYSTEM = (
"Du bist ein präziser Assistent für die Bildanalyse. Zitiere nur Inhalte, "
"die im Bild klar erkennbar sind. Spekuliere nicht. Gib striktes JSON aus, "
"mit den Feldern entities/attributes/text."
)
config = types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH",
thinking_level="high",
system_instruction=SYSTEM,
tools=[types.Tool(code_execution=types.ToolCodeExecution())],
response_mime_type="application/json"
)
resp = client.models.generate_content(
model="gemini-3.5-flash",
contents=[image_part, "Erkenne dieses Bild gemäß den SYSTEM-Anforderungen"],
config=config
)
print(resp.text)
Bei der tatsächlichen Bereitstellung empfiehlt es sich, die Vorlage bei APIYI (apiyi.com) in eine einheitliche SDK-Aufrufschicht zu extrahieren. Die Fachabteilungen übermitteln dann nur noch das Bild und die Frage, während die Parameter zentral über das Gateway injiziert werden – so vermeiden Sie, dass jedes Team dieselben Fehler erneut macht.
FAQ: Häufige Fragen zur Bilderkennung via Gemini API im Vergleich zur Webversion
F1: Ist die API nach Aktivierung dieser Parameter immer noch schlechter als die Webversion?
In den allermeisten Anwendungsfällen lässt sich die Leistung der Webversion erreichen. Bei einigen hochkomplexen Aufgaben (sehr kleine Schrift, schlechte Lichtverhältnisse, spezielle künstlerische Stile) kann die Leistung jedoch leicht abweichen, da die Webversion zusätzlich auf nicht öffentliche, interne Optimierungs-Pipelines zugreift. Für solche Szenarien können Sie auf APIYI (apiyi.com) verschiedene visuelle Modelle anderer Anbieter für einen direkten Vergleich nutzen, um das für Ihre Anforderungen am besten geeignete Modell zu finden.
F2: Verdoppelt thinking_level=high die Kosten?
Es erhöht den internen Verbrauch an Reasoning-Token, wirkt sich jedoch nur auf die Ausgabephase aus. Zudem machen bei der Bilderkennung die Bild-Token meist den größeren Teil der Gesamtkosten aus. Der Genauigkeitsgewinn durch die Einstellung „high“ überwiegt die zusätzlichen Kosten bei weitem, insbesondere bei Geschäftsprozessen, bei denen eine manuelle Überprüfung ersetzt werden soll.
F3: Wie ändere ich die base_url? Ich verwende das offizielle Google SDK.
Das google-genai SDK unterstützt die Umleitung von Anfragen an das APIYI-Gateway (apiyi.com) über http_options={"base_url": "https://api.apiyi.com"}. Verwenden Sie einfach den im APIYI-Backend generierten API-Schlüssel; ein separates Google Cloud-Projekt ist nicht erforderlich.
F4: Kann das Problem allein durch die Optimierung der Eingabeaufforderung gelöst werden?
Die Möglichkeiten bei der reinen Anpassung der Eingabeaufforderung sind begrenzt. Faktoren wie Auflösung, logische Tiefe und Tool-Nutzung liegen außerhalb der reinen Prompt-Ebene. Von den 6 Tipps in diesem Artikel bezieht sich nur einer auf die Eingabeaufforderung; die anderen fünf sind Hebel auf technischer Ebene.
F5: Was tun, wenn die API „chinesische Wasserzeichen auf Bildern“ übersieht, die in der Webversion erkannt werden?
Die Erkennung von Wasserzeichen hängt oft von einer Kombination aus hoher Auflösung und dem Einsatz von Code-Ausführung (Cropping) ab. Stellen Sie media_resolution auf ultra high, aktivieren Sie code execution und nutzen Sie eine zweistufige Validierungskette; dies führt in der Regel zu einer stabilen Erkennung.
Fazit: Die technischen Fähigkeiten der Webversion in den API-Aufruf integrieren
Zurück zur Ausgangsfrage: Warum ist die Bilderkennung der Gemini API schlechter als die der Webversion? Die Antwort lautet nicht, dass das Modell schwächer ist, sondern dass die Webversion über ein umfangreiches technisches „Gerüst“ verfügt. Wenn Sie die gemini-3.5-flash API direkt aufrufen, müssen Sie Prompt-Rewriting, Auflösungsstufen, Reasoning-Budget, Tool-Nutzung und Ergebnisvalidierung explizit selbst implementieren. Wenn man dies verstanden hat, wird klar: Die 6 Tipps dienen dazu, all das, was die Webversion für Sie erledigt, in Ihre eigene API-Aufrufkette zu übertragen.
Der praktische Weg ist klar: Stellen Sie media_resolution und thinking_level auf das Maximum, integrieren Sie Anweisungen in die system_instruction und aktivieren Sie das Caching. Nutzen Sie für komplexe Bilderkennungsaufgaben code execution, verarbeiten Sie große Bilder einheitlich über die File API und sichern Sie kritische Geschäftsprozesse mit einer zwei- bis dreistufigen Agenten-Kette ab. Wenn Sie diese Kombination anwenden und anschließend im APIYI-Backend (apiyi.com) Trefferquote und Latenz vergleichen, werden die meisten Teams den Unterschied zwischen „Web vs. API“ auf ein kaum noch wahrnehmbares Minimum reduzieren können.
📌 Autoreninfo: Dieser Artikel wurde vom technischen Team von APIYI (apiyi.com) zusammengestellt. Weitere Anleitungen zur praktischen Einbindung und Parameteroptimierung der Gemini-, Claude- und GPT-Modellreihen finden Sie im APIYI-Hilfezentrum.