Eine interessante Entdeckung: In letzter Zeit sind viele Entwickler beim Testen des im März 2026 veröffentlichten M2.7-Modells von MiniMax auf ein kontraintuitives Problem gestoßen: Dieses Flaggschiff-Modell, das als „König der Code- und Agenten-Workflows“ bezeichnet wird, unterstützt tatsächlich keine Bildeingaben. Angesichts der Tatsache, dass multimodale Fähigkeiten bei Claude 4, GPT-5 und Gemini 3 mittlerweile Standard sind, ist es durchaus überraschend, dass ein 230B-Parameter-Flaggschiff keine Bilder verarbeiten kann. Dieser Artikel analysiert die Produktlogik hinter der „reinen Text“-Positionierung des M2.7, basierend auf der offiziellen Dokumentation von MiniMax, den NVIDIA NIM-Modellkarten und den öffentlichen Spezifikationen von OpenRouter, kombiniert mit Beobachtungen von APIYI (apiyi.com) bei der praktischen Implementierung.
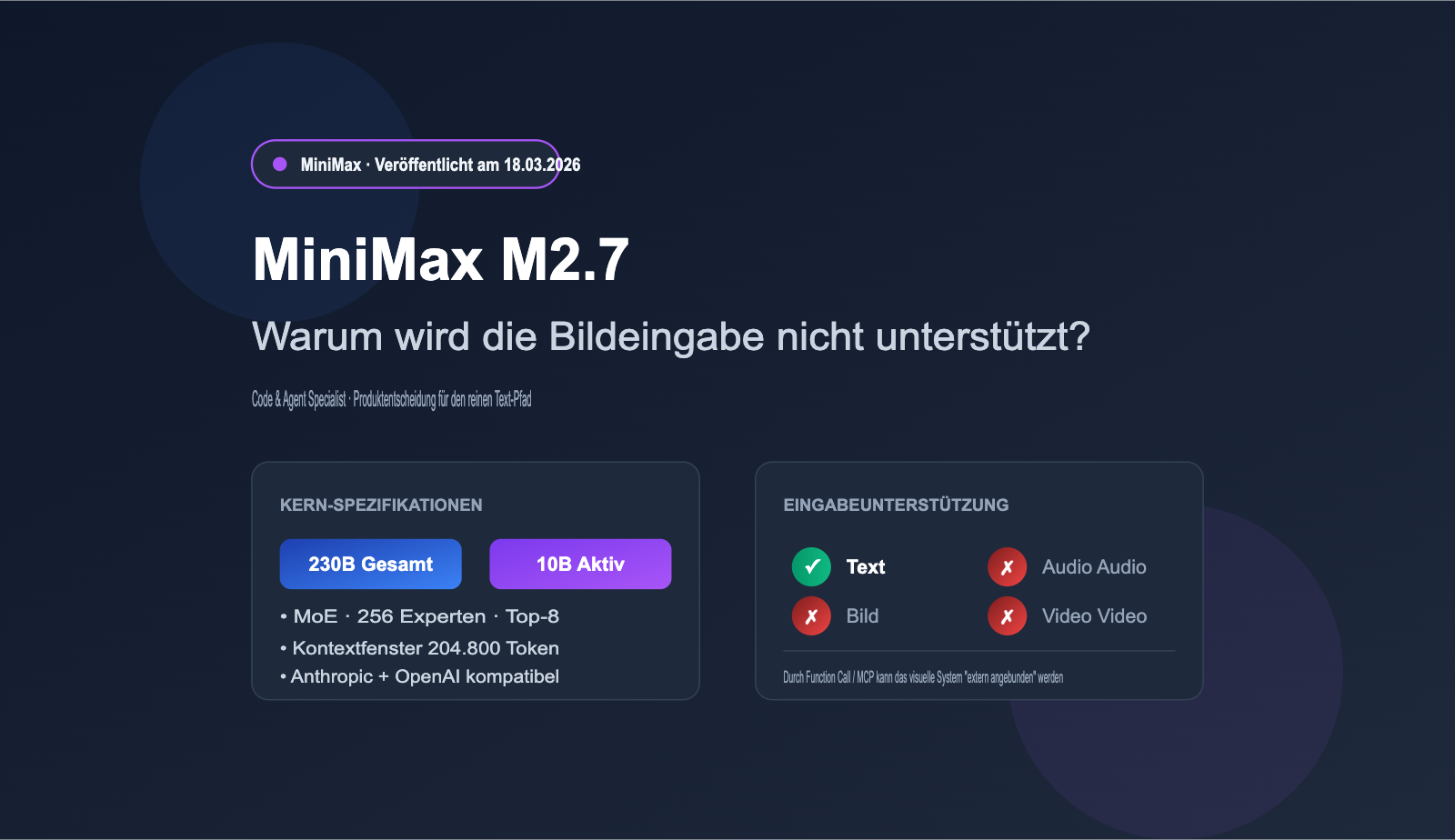
I. Ist es wahr, dass MiniMax M2.7 keine Bildeingaben unterstützt?
Beantworten wir die direkteste Frage zuerst: Ja, es ist wahr. Laut den offiziellen Spezifikationen der MiniMax-Plattform und der NVIDIA NIM-Modellkarte unterstützt M2.7 (einschließlich der M2.7-highspeed-Version) derzeit nur Texteingaben und kann keine Bilder, Audios oder Videos direkt verarbeiten. Dies entspricht der reinen Text-Ausrichtung der vorherigen M2.5-Generation, steht jedoch in krassem Gegensatz zum Mainstream der „nativen multimodalen“ Modelle wie Claude 4 Opus, GPT-5 und der Gemini 3-Serie, die im gleichen Zeitraum veröffentlicht wurden.
1.1 Kurzübersicht der Kernspezifikationen von MiniMax M2.7
M2.7 wurde am 18. März 2026 offiziell für API-Aufrufe freigegeben. Es verwendet eine MoE-Architektur (Mixture-of-Experts) mit insgesamt 230B Parametern, von denen 10B pro Token aktiviert werden. Der Fokus liegt auf „hoher Leistung bei niedrigen Kosten“.
| Spezifikation | Parameter |
|---|---|
| Veröffentlichungsdatum | 18.03.2026 |
| Architekturtyp | MoE Transformer (256 Experten, 8 pro Token aktiviert) |
| Gesamtparameter / Aktivierte Parameter | 230B / 10B |
| Kontextfenster | 204.800 Token |
| Maximale Ausgabe | 131.072 Token |
| Eingabepreis | $0,279 / M Token |
| Ausgabepreis | $1,20 / M Token |
| Multimodale Unterstützung | ❌ Nur Text |
| API-Kompatibilität | Anthropic API + OpenAI API |
1.2 In welchen Szenarien tappen Sie in die „Falle“?
Wenn Ihre Anwendung Szenarien wie Screenshot-Fragen, PDF-Screenshot-Analysen, Verständnis von Produktbildern, visuelle UI-Automatisierungstests oder Bildabruf in multimodalen RAG-Systemen umfasst, wird der direkte Aufruf von M2.7 fehlschlagen oder sinnlose Ausgaben liefern. Es wird empfohlen, auf der Routing-Ebene (z. B. LiteLLM, One API oder ein einheitlicher API-Proxy-Dienst wie APIYI apiyi.com) eine Prüfung des Modelltyps durchzuführen und Anfragen mit Bildinhalten an die Claude-, GPT-5- oder Gemini 3-Serie weiterzuleiten.
II. Warum sich MiniMax M2.7 für den „Nur-Text“-Weg entschieden hat
Die Ausrichtung des M2.7 auf reinen Text ist kein Mangel an technischer Kapazität, sondern eine sehr bewusste Produktentscheidung. MiniMax hat zuvor die abab-Modellreihe mit multimodalen Fähigkeiten veröffentlicht und wäre durchaus in der Lage gewesen, ein visuelles Modul in die M-Serie zu integrieren. Stattdessen entschied man sich jedoch, die gesamte Trainingsleistung des M2.7 in die Bereiche „Code + Agent“ zu investieren, um in diesen Disziplinen eine Spitzenleistung zu erzielen.
2.1 Code und Agent sind das Kernschlachtfeld des M2.7
Laut der offiziellen README und dem NVIDIA-Technikblog wurde das M2.7 speziell für „die Bearbeitung mehrerer Dateien, Code-Ausführungs-Reparatur-Zyklen, testgetriebene Fehlerbehebung sowie lange Tool-Aufrufketten über Shell, Browser, Retrieval und Code-Runner“ optimiert. Bei realen Programmieraufgaben wie SWE-bench, Aider Polyglot und Terminal Bench erreicht das M2.7 Ergebnisse, die nahe an Claude 4 Sonnet heranreichen – bei nur 10B aktivierten Parametern und etwa 1/8 der Inferenzkosten.
2.2 Abwägung: Nur-Text-Weg vs. multimodaler Weg
Die Konzentration der Trainingsressourcen auf einen einzigen Bereich bringt sowohl kalkulierbare Gewinne als auch Verluste mit sich. Die folgende Tabelle fasst die wichtigsten Abwägungspunkte beider Ansätze zusammen:
| Dimension | Nur-Text-Weg (M2.7 / DeepSeek-R1) | Multimodaler Weg (Claude/GPT/Gemini) |
|---|---|---|
| Trainingskosten | Konzentriert, hohe Effizienz | Gestreut, hohe Datenkosten |
| Preis pro Token | Niedriger ($0,28-2 / M) | Höher ($3-15 / M) |
| Tiefe der Text-/Code-Inferenz | Meist stärker | Etwas schwächer, aber ausreichend |
| Bild-/Videoverständnis | Nicht unterstützt | Nativ unterstützt |
| Breite der Anwendungsszenarien | Fokusorientiert | Universeller |
| Komplexität der Einbindung | Niedrig | Niedrig bis mittel |
2.3 „Ergänzung“ multimodaler Fähigkeiten durch Tool-Aufrufe
Obwohl das M2.7 selbst keine Bilder erkennt, unterstützt es nativ MCP (Model Context Protocol) und Function Calling. Das bedeutet, Entwickler können das M2.7 anweisen, Bildverständnis-Aufgaben an spezialisierte visuelle Modelle (wie Claude 4 Opus oder Gemini 3 Vision) „auszulagern“, während es selbst nur die Steuerung und die finale Schlussfolgerung übernimmt. Diese „Master-Controller + visuelle Kooperation“-Architektur ist in Agenten-Systemen weit verbreitet.
III. Sind multimodale APIs im Jahr 2026 wirklich Industriestandard?
Intuitiv hat sich die Auffassung „Multimodalität = Standard“ bis 2026 fast zu einem Branchenkonsens entwickelt. Bei genauerer Betrachtung der führenden Modell-Lager zeigt sich jedoch, dass dieses Urteil differenziert betrachtet werden muss.
3.1 Führende Closed-Source-Flaggschiffe unterstützen fast alle Multimodalität
Die Claude 4-Serie von Anthropic, die GPT-5-Serie von OpenAI und Gemini 3 Pro/Ultra von Google nutzen Bilder bereits als grundlegende Eingabefähigkeit. Gemini 3 steigerte sich im ScreenSpot-Pro-Test von 11,4 % auf 72,7 % und kann nun direkt Screenshots „verstehen“ und Benutzeroberflächen bedienen; auch Claude 4 hat seine Fähigkeiten zur Diagrammerkennung und PDF-Analyse deutlich ausgebaut.
3.2 Deutliche Spaltung im Open-Source-/Preis-Leistungs-Lager
Im Open-Source-Bereich zeigt sich eine klare Trennung: Einerseits gibt es „Full-Stack-multimodale“ Modelle wie Llama 3.2 Vision, Qwen3-VL und InternVL; andererseits Modelle wie DeepSeek-R1 und MiniMax M2.7, die auf „Text/Inferenz“ spezialisiert sind und durch Fokus ihre Preis-Leistungs-Vorteile ausspielen. Diese beiden Kategorien sind kein einfaches „Besser oder Schlechter“, sondern differenzierte Entscheidungen für unterschiedliche Anwendungsformen.
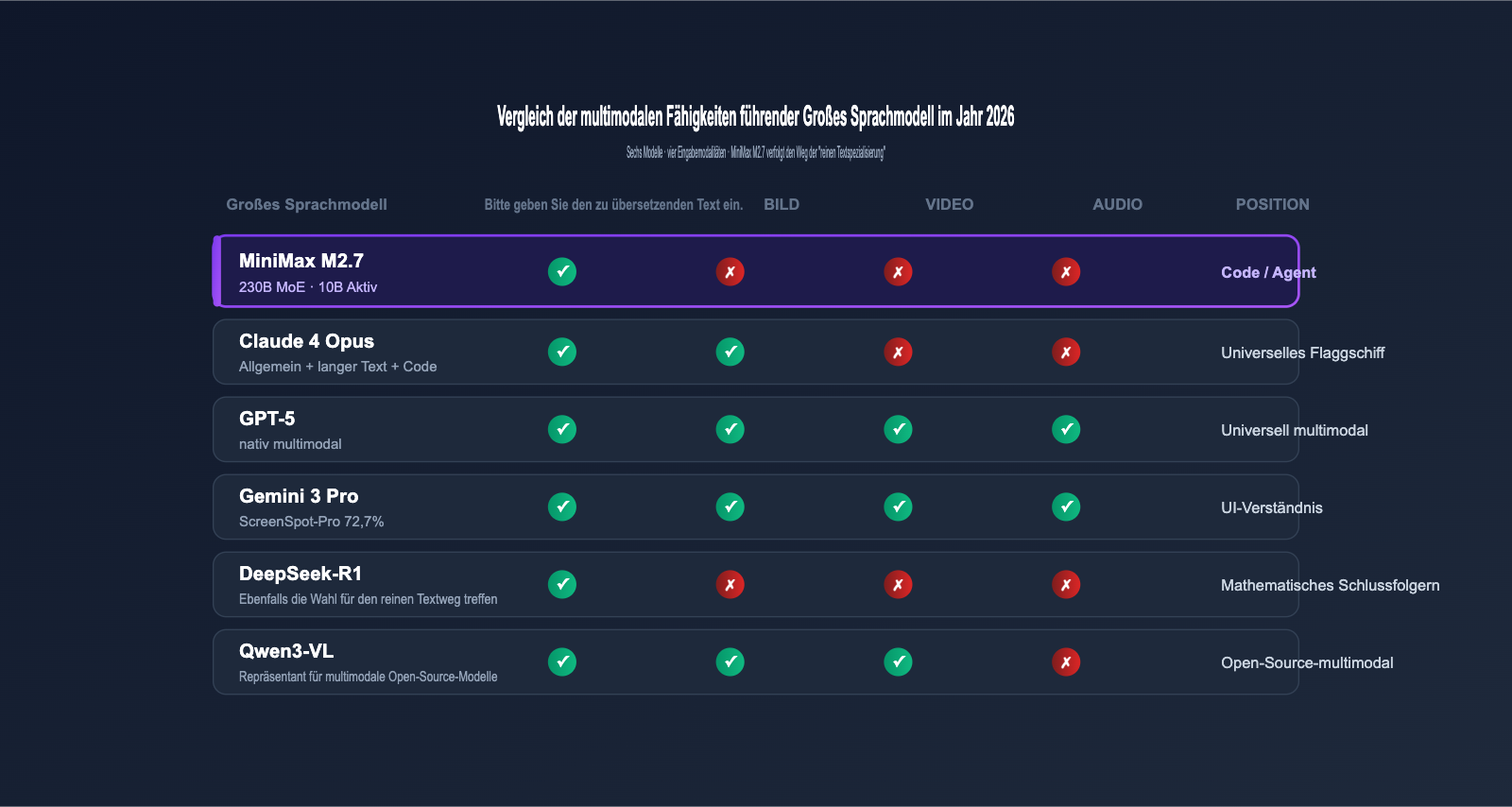
3.3 Vergleich der multimodalen Fähigkeiten führender Modelle
Die folgende Tabelle fasst die Unterschiede in den multimodalen Fähigkeiten der führenden großen Sprachmodelle im Mai 2026 zusammen und verdeutlicht die Positionierung des M2.7:
| Modell | Bildeingabe | Videoeingabe | Audioeingabe | Hauptfokus |
|---|---|---|---|---|
| MiniMax M2.7 | ❌ | ❌ | ❌ | Code/Agent-Inferenz |
| Claude 4 Opus | ✅ | ❌ | ❌ | Allgemein + Lange Texte + Code |
| GPT-5 | ✅ | ✅ | ✅ | Universelle Multimodalität |
| Gemini 3 Pro | ✅ | ✅ | ✅ | Multimodalität + UI-Verständnis |
| DeepSeek-R1 | ❌ | ❌ | ❌ | Mathematische Inferenz |
| Qwen3-VL | ✅ | ✅ | ❌ | Open-Source-Multimodalität |
Es zeigt sich, dass sich der „Standard Multimodalität“ hauptsächlich auf das Lager der Closed-Source-Flaggschiffe konzentriert. Im Open-Source- und Preis-Leistungs-Bereich bleibt die Spezialisierung auf Text ein effektiver Weg zur Differenzierung.
IV. Wie man MiniMax M2.7 für die Bildverarbeitung nutzt, obwohl es keine native visuelle Unterstützung hat
Obwohl M2.7 von sich aus keine Bilder lesen kann, lässt sich durch die Kombination von Werkzeugaufrufen (Tool Calling) und Routing eine hybride Architektur aufbauen: "M2.7 als Hauptsteuerung + visuelles Modell als Unterstützung". So profitieren Sie von den niedrigen Kosten von M2.7, ohne auf eine multimodale Erfahrung verzichten zu müssen.
4.1 Empfohlene hybride Architektur
Der gängigste Ansatz ist die Verwendung eines einheitlichen Gateways (wie das von APIYI apiyi.com angebotene Multi-Modell-Routing), das Anfragen je nach Inhaltstyp verteilt. Text- oder Code-Anfragen gehen an M2.7, während Bildanfragen an Claude 4 oder Gemini 3 weitergeleitet werden. Die resultierende Textausgabe des visuellen Modells wird dann an M2.7 zurückgegeben, um die endgültige Schlussfolgerung und Entscheidung zu treffen. Diese Architektur ist für das Frontend transparent; eine Anpassung der SDK-Aufrufe auf der Geschäftsseite ist nicht erforderlich.
4.2 Einbindung visueller Modelle via Function Calling
Wenn Ihre Anwendung Function Calling nutzt, können Sie für M2.7 ein Werkzeug namens analyze_image registrieren. Intern ruft dieses die visuelle Schnittstelle von Claude, GPT oder Gemini auf und gibt das Erkennungsergebnis als JSON zurück. M2.7 entscheidet automatisch basierend auf der Benutzeranfrage, wann dieses Werkzeug aufgerufen werden muss – eine explizite Steuerung auf Prompt-Ebene ist nicht nötig. Dieses Modell eignet sich hervorragend für Agenten-Frameworks (wie LangGraph, CrewAI oder das OpenAI Agents SDK).
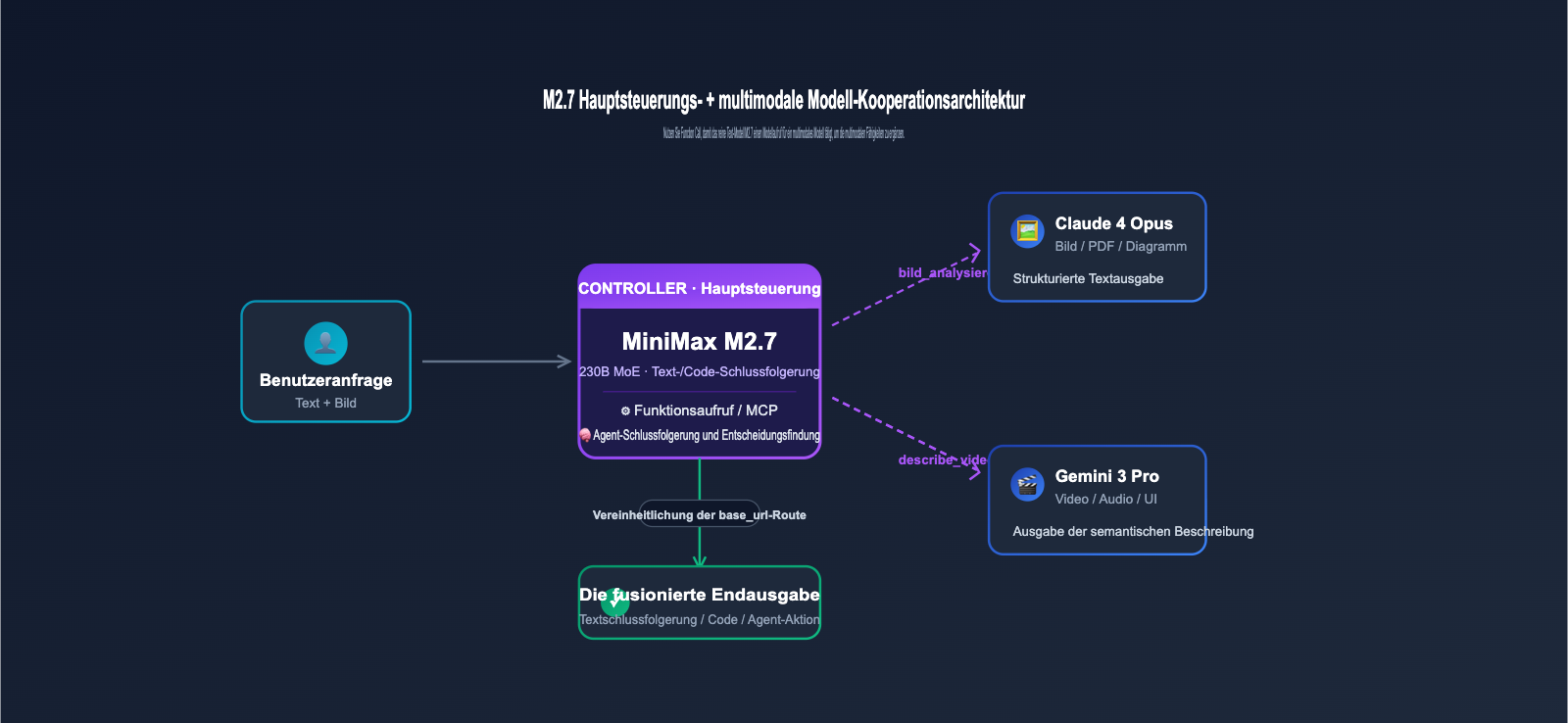
🎯 Empfehlung zur Anbindung: Wir empfehlen, über APIYI apiyi.com eine einzige
base_urlzu nutzen, um sowohl M2.7 als auch multimodale Modelle (wie Claude 4 Opus oder Gemini 3 Pro) anzubinden. So müssen Sie nicht für jeden Anbieter separate SDKs und API-Schlüssel verwalten. Dies senkt die technische Komplexität der hybriden Architektur erheblich und erleichtert die einheitliche Überwachung von Token-Verbrauch und Kosten.
4.3 Empfohlene Parameter für die Inferenz
MiniMax empfiehlt für M2.7 offiziell etwas höhere Sampling-Parameter: temperature=1.0, top_p=0.95, top_k=40. Dies unterscheidet sich von den Empfehlungen für niedrige Temperaturen bei vielen anderen Modellen. In der Praxis zeigt sich, dass diese Parameter bei der Codegenerierung und in Agenten-Szenarien zu qualitativ hochwertigeren und kreativeren Ergebnissen führen. Falls Ihre bisherigen Prompt-Vorlagen standardmäßig temperature=0 verwenden, könnten Sie bei M2.7 eher starre oder repetitive Ausgaben erhalten – hier empfiehlt sich eine erneute Optimierung.
V. Entscheidungsfindung: MiniMax M2.7 vs. multimodale Modelle
Wann sollten Sie sich für M2.7 und wann für ein multimodales Flaggschiff-Modell entscheiden? Der Kernpunkt liegt nicht in der reinen Parameteranzahl, sondern darin, ob Ihre Anwendung „text-/code-zentriert“ oder „multimodal-zentriert“ ist.
5.1 M2.7 als erste Wahl für text-/code-zentrierte Szenarien
Wenn über 90 % der Anfragen Ihres Produkts textbasiert sind (Codegenerierung, Dokumenten-Q&A, Agent-Orchestrierung, Zusammenfassung langer Texte), ist M2.7 derzeit eine der kosteneffizientesten Optionen. Die Leistungsgrenze, die durch die 230B-Gesamtparameter erreicht wird, nähert sich der von Claude 4 Sonnet an, während der Preis pro Token nur einen Bruchteil davon beträgt – besonders vorteilhaft für SaaS-Backends mit hoher Parallelität.
5.2 Claude / Gemini als erste Wahl für häufige multimodale Szenarien
Wenn Ihr Kernszenario Bildverständnis (OCR, UI-Automatisierung, Produkterkennung, medizinische Bildanalyse), Videoanalyse oder Audioverarbeitung umfasst, ist die direkte Wahl von Claude 4 Opus, GPT-5 oder Gemini 3 Pro einfacher und zuverlässiger als eine hybride Architektur aus „M2.7 + visuellem Modell“. Dies reduziert die Latenz und die Fehlerquote bei modellübergreifenden Aufrufen.
5.3 Empfehlungen für verschiedene Szenarien
| Anwendungsfall | Bevorzugtes Modell | Alternative |
|---|---|---|
| Codegenerierung / Refactoring | MiniMax M2.7 | Claude 4 Sonnet |
| Agent-Tool-Aufrufe | MiniMax M2.7 | GPT-5 |
| Langdokumenten-Q&A (bis 200K) | MiniMax M2.7 | Claude 4 Opus |
| Bild-OCR / Screenshot-Q&A | Gemini 3 Pro | Claude 4 Opus |
| Videoanalyse | Gemini 3 Pro | GPT-5 |
| Multimodales RAG | Claude 4 Opus | Gemini 3 Pro |
| Hybride Aufgaben (Text-zentriert + wenig Bild) | M2.7 + visuelles Modell | Claude 4 Opus (einzeln) |
🎯 Auswahl-Tipp: Die Wahl des Modells hängt nicht davon ab, „wer stärker ist“, sondern „wer besser zu Ihrer Anfragenverteilung passt“. Wir empfehlen, über die Plattform APIYI (apiyi.com) A/B-Tests mit echtem Traffic durchzuführen, um Kosten und Qualität der verschiedenen Modelle bei identischen Aufgaben zu vergleichen, bevor Sie sich für die endgültige Modellkombination entscheiden.
VI. Häufig gestellte Fragen zu MiniMax M2.7
6.1 Kann M2.7 wirklich keine Bilder verarbeiten?
Korrekt. Wenn Sie Bilddateien (base64 oder URL) direkt in die messages einfügen, wird dies von der Schnittstelle abgelehnt oder führt zu einem Fehler. Der einzige gangbare Weg ist, das Bild zunächst mit einem anderen visuellen Modell in eine Textbeschreibung umzuwandeln und diese Beschreibung dann für die weitere Schlussfolgerung an M2.7 zu übergeben.
6.2 Was ist der Unterschied zwischen M2.7 und M2.7-highspeed?
Beide liefern identische Ergebnisse, unterscheiden sich jedoch in der Antwortgeschwindigkeit. M2.7-highspeed eignet sich für latenzkritische Szenarien (z. B. Echtzeit-Codevervollständigung in der IDE), während die M2.7-Standardversion für große Mengen asynchroner Aufgaben optimiert ist. Beide Versionen können über das APIYI-Dashboard (apiyi.com) per Modellname gewechselt werden; die Schnittstellenparameter sind vollständig kompatibel.
6.3 Ist M2.7 ein Open-Source-Modell und kann es lokal bereitgestellt werden?
Ja, M2.7 ist ein Modell mit offenen Gewichten und kann auf HuggingFace heruntergeladen und selbst gehostet werden. Sie benötigen jedoch mindestens 8 A100/H100-GPUs, um das 200K-Kontextfenster voll auszunutzen. Die Kosten für die lokale Bereitstellung sind deutlich höher als bei API-Aufrufen. Sofern keine strengen Compliance-Anforderungen vorliegen, ist ein Selbstbau nicht ratsam.
6.4 Ist M2.7 mit den offiziellen SDKs von Anthropic / OpenAI kompatibel?
Ja, vollständig kompatibel. Sie können direkt die offiziellen SDKs von anthropic oder openai verwenden. Ändern Sie einfach die base_url auf den API-Proxy-Dienst (z. B. den einheitlichen Endpunkt von APIYI apiyi.com) und passen Sie den Modellnamen an – eine Anpassung der Geschäftslogik ist nicht erforderlich. Dies ist der effizienteste Weg für die Implementierung einer hybriden Architektur.
6.5 Sollten Teams mit hohem Bedarf an Multimodalität M2.7 gar nicht in Betracht ziehen?
Nicht unbedingt. Selbst bei multimodalen Anwendungen machen Textschlussfolgerungen und Orchestrierung einen Großteil des Anfragevolumens aus. Es empfiehlt sich, die multimodalen Teile Claude/Gemini zu überlassen und die Textsteuerung sowie Entscheidungsfindung M2.7 zu übertragen, um die gesamten Inferenzkosten erheblich zu senken. Für maßgeschneiderte hybride Lösungen kontaktieren Sie bitte das Business-Team von APIYI (apiyi.com) für eine Architekturberatung.
VII. Fazit: Multimodalität ist der Trend, doch „Spezialisierung“ bleibt ein effektiver Weg
Dass das MiniMax M2.7 keine Bildeingaben unterstützt, ist sowohl eine Tatsache als auch eine bewusste Produktstrategie. Im Jahr 2026, in dem Multimodalität zum Standard bei proprietären Flaggschiff-Modellen geworden ist, hat sich MiniMax dazu entschieden, alle Trainingsressourcen auf die beiden differenziertesten Bereiche – Code und Agenten – zu konzentrieren. Das Ergebnis ist eine Code-Leistung, die nahezu an Claude 4 Sonnet heranreicht, bei deutlich geringeren Inferenzkosten.
Für Entwickler bedeutet dies, dass die Modellauswahl kein einfacher Vergleich mehr ist, wer „allumfassender“ ist, sondern wer besser zu Ihrer spezifischen Anforderungsverteilung passt. In Szenarien, die von Text oder Code dominiert werden, bleibt M2.7 eine der kosteneffizientesten Optionen auf dem Markt. Für hochfrequente multimodale Anwendungen sollten hingegen spezialisierte Modelle wie Claude 4 Opus, GPT-5 oder Gemini 3 herangezogen werden. Durch die Kombination beider Ansätze über ein einheitliches Gateway lässt sich oft das optimale Gleichgewicht zwischen Kosten und Leistung erzielen.
Wenn Sie M2.7 und verschiedene multimodale Flaggschiff-Modelle unter einer einheitlichen base_url anbinden möchten, finden Sie in der offiziellen Dokumentation von APIYI unter apiyi.com eine vollständige Modellliste sowie Implementierungsbeispiele.
Autor: APIYI Team — Wir bieten globalen KI-Entwicklern kontinuierlich stabile und effiziente API-Proxy-Dienste sowie Multi-Modell-Routing. Weitere Informationen finden Sie unter apiyi.com