Kürzlich fragte ein Entwicklerkollege in unserer Gruppe: „Kann gpt-image-2 Bilder aus CSV- oder Excel-Dateien generieren? Ich habe auf TikTok gesehen, wie jemand ein Bildmodell für die PPT-Erstellung nutzt, und würde gerne wissen, ob man Dateiinformationen direkt einlesen kann.“ Die Antwort ist kurz und direkt: Nein. Das im April 2026 veröffentlichte gpt-image-2 von OpenAI akzeptiert ausschließlich Text-Eingabeaufforderungen und Bilder. Es kann weder CSV/Excel-Dateien lesen noch PPTX/PDF-Dateien ausgeben.
Das bedeutet jedoch nicht, dass dieser Weg eine Sackgasse ist. Der aktuelle Standard-Workflow besteht darin, den Dateiinhalt in Text zu extrahieren, die Dateiseiten als Bilder zu speichern und diese dann an gpt-image-2 zur Bilderzeugung zu übergeben. In diesem Artikel erläutern wir die Kapazitätsgrenzen von gpt-image-2 in Bezug auf Datei-Uploads und stellen 5 Umgehungslösungen vor, mit denen Sie Anforderungen umsetzen können, die Kunden zunächst für unmöglich hielten.

Status quo der Datei-Upload-Unterstützung bei gpt-image-2: Nur Text und Bilder zulässig
Lassen Sie uns zunächst die offiziellen Grenzen klären, da alle weiteren Lösungen darauf aufbauen. Laut der OpenAI-Entwicklerdokumentation ist gpt-image-2 (Snapshot gpt-image-2-2026-04-21) ein natives multimodales Modell zur Bilderzeugung. Die folgende Tabelle verdeutlicht die unterstützten Modalitäten.
| Modalitätstyp | Eingabe unterstützt | Ausgabe unterstützt | Anmerkung |
|---|---|---|---|
| Text | ✅ Ja | ❌ Nein | Dient als Eingabeaufforderung, unterstützt mehrere Sprachen |
| Bild | ✅ Ja | ✅ Ja | Eingabe für Bearbeitung/Referenz, Ausgabe als PNG/JPEG/WebP |
| Audio | ❌ Nein | ❌ Nein | Nicht relevant für Bilderzeugung |
| Video | ❌ Nein | ❌ Nein | Nicht relevant für Bilderzeugung |
| Dokumente (CSV/Excel/PDF/Word/PPT) | ❌ Nein | ❌ Nein | Kein direkter Upload oder Dateiexport möglich |
Kurz gesagt: gpt-image-2 ist kein „universelles Gehirn“ wie GPT-4, sondern auf die Bilderzeugung und -bearbeitung spezialisiert. Daher hat OpenAI keinen Parser für CSV/Excel/PDF integriert. Wenn Sie eine Excel-Binärdatei senden, gibt die API direkt einen 400-Fehler zurück. Wenn Ihr Projekt einen stabilen Modellaufruf mit hoher RPM für gpt-image-2 benötigt, empfehlen wir die Nutzung einer aggregierten API-Proxy-Dienst-Plattform wie APIYI (apiyi.com). Diese Plattform hat die Eingabeprüfungen und Parameterbeschränkungen bereits dokumentiert, was Anfängern hilft, Fehler zu vermeiden.
🎯 Kernverständnis: Die Kapazitätsgrenze von gpt-image-2 liegt bei „Text + Bild → Bild“. Betrachten Sie es nicht als einen allmächtigen Agenten. Datei-Anforderungen müssen durch externe Tools ergänzt werden. Der API-Proxy-Dienst (wie APIYI) sorgt für Stabilität, während die Geschäftsebene die Datenvorverarbeitung übernimmt.
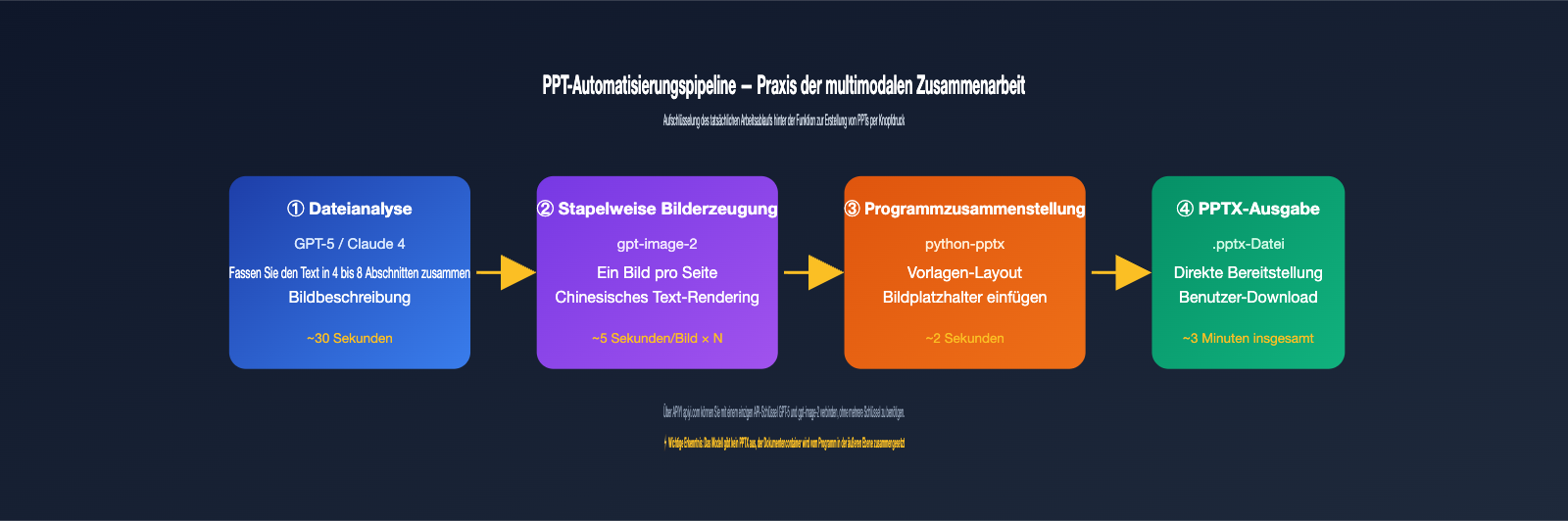
Warum „PPT-Generierung“ und „Dateibasierte Bilderzeugung“ zwei verschiedene Dinge sind
Viele Kunden verwechseln „KI-gestützte PPT-Generierung“ mit „Modell liest Datei und generiert Bild“. Tatsächlich handelt es sich um zwei völlig unterschiedliche Workflows. Die Automatisierungslösungen für PPTs, die man auf Social-Media-Plattformen sieht, sind fast immer mehrstufige Pipelines: Zuerst extrahiert ein Großes Sprachmodell die Daten in einen Textentwurf, dann generiert ein Bildmodell die Illustrationen für jede Seite, und schließlich setzt ein Programm alles zu einer PPTX-Datei zusammen.
Der Teil, der für die Bilderzeugung zuständig ist, nutzt meist ein Modell wie gpt-image-2. Es sieht nur die erhaltene Texteingabeaufforderung und das Referenzbild; es weiß nicht, ob die Quelle eine Excel-Tabelle oder Notion war. Wenn Sie diesen Punkt verstanden haben, ergeben die folgenden 5 Lösungen Sinn.
Upgrades gegenüber der Vorgängergeneration gpt-image-1
Viele Bestandskunden fragen: Wenn man keine Dateien hochladen kann, was macht gpt-image-2 dann besser als gpt-image-1? Der Unterschied ist entscheidend und bestimmt, ob der Ansatz „Screenshot als Eingabe“ funktioniert. Die neue Version bietet massive Verbesserungen bei der Textwiedergabe, der Anzahl der Referenzbilder und der Schlussfolgerungsfähigkeit.
| Fähigkeitsdimension | gpt-image-1 | gpt-image-2 |
|---|---|---|
| Maximale Anzahl Referenzbilder | 4 | 16 (empfohlen: ≤4 für beste Ergebnisse) |
| Textwiedergabe | Englisch gut, Probleme bei CJK | Deutlich verbesserte Genauigkeit bei vielen Sprachen |
| Schlussfolgerungsfähigkeit | Keine | Integrierter Thinking-Modus für komplexe Layouts |
| Wissensstichtag | Anfang 2024 | Dezember 2025 |
| Ausgabeauflösung | Max. 1024×1024 | Max. 3840×2160 (4K) |
Das bedeutet: Wenn Sie zuvor mit gpt-image-1 bei der „Screenshot-Stiländerung“ keine idealen Ergebnisse erzielt haben, lohnt sich ein erneuter Versuch mit gpt-image-2, insbesondere bei Szenarien wie chinesischen Postern oder PPT-Folien, die eine präzise Textwiedergabe erfordern.
5 Workflow-Lösungen, um mit gpt-image-2 aus Dateiinhalten Bilder zu generieren
Die folgenden 5 Lösungen decken unterschiedliche Datenquellen und Anwendungsszenarien ab. Die Wahl hängt von Ihrem Dateityp, dem gewünschten Ausgabeformat und dem Grad der Automatisierung ab. Wir haben sie von leichtgewichtig bis komplex sortiert.
Lösung 1: Datei in Text-Eingabeaufforderung umwandeln und direkt an gpt-image-2 übergeben
Geeignet für strukturierte Daten wie CSV, Excel, JSON oder reinen Text. Der Prozess besteht darin, die Datei zunächst mit Skripten (pandas, openpyxl) zu lesen, die Kopfzeilen, Schlüsselzeilen und statistischen Kennzahlen zu einer Beschreibung in natürlicher Sprache zusammenzufügen und diese dann als prompt für den Aufruf von /v1/images/generations zu verwenden. Beispiel: Fassen Sie Verkaufsdaten zusammen als „Säulendiagramm der Verkaufszahlen in drei Regionen für Q1 2026, Ostchina 12 Mio., Nordchina 9,8 Mio., Südchina 7,6 Mio., dunkler Business-Stil“.
Der Vorteil dieser Methode ist die Einfachheit; es ist keine Bildeingabe erforderlich. Der Nachteil ist, dass die Informationsmenge im prompt begrenzt ist. gpt-image-2 ist bei der präzisen Wiedergabe von Zahlen gut, aber nicht perfekt. Sie müssen die Werte für jede Säule explizit in der Eingabeaufforderung angeben, da das Modell sonst die Höhen nach visueller Plausibilität neu verteilt.
Lösung 2: Screenshot der Dateiseite als Referenzbild verwenden
Geeignet für PDF, PPT mit festem Layout, Web-Berichte usw. – also Inhalte, die „bereits wie ein Bild aussehen“. Konvertieren Sie die Zielseite in ein PNG (mit macOS-Vorschau, pdftoppm, Puppeteer etc.) und laden Sie es über den Endpunkt /v1/images/edits als image-Parameter hoch, kombiniert mit einem prompt, der die gewünschten Änderungen beschreibt, z. B.: „Layout beibehalten, englische Titel in Chinesisch ändern, Säulendiagramm im Apple-Stil gestalten“.
In der Version 2026 akzeptiert gpt-image-2 maximal 16 Referenzbilder. Offizielle Empfehlungen und Community-Tests legen jedoch nahe, 1 Hauptreferenzbild + 1–2 Stilreferenzbilder zu verwenden, da bei zu vielen Bildern die Aufmerksamkeit des Modells verwässert wird. Jedes Bild sollte idealerweise unter 1,5 MB groß sein, da sonst der Verbrauch an Input-Tokens deutlich ansteigt.
Lösung 3: Daten zuerst visualisieren und dann von gpt-image-2 verschönern lassen
Geeignet für Szenarien, in denen Datenvisualisierungen „sowohl präzise als auch ästhetisch ansprechend“ sein sollen. Erstellen Sie zunächst mit matplotlib, ECharts oder den integrierten Excel-Diagrammen eine Basisversion der Daten und exportieren Sie diese als PNG. Übergeben Sie dieses Basisbild dann als Eingabe an gpt-image-2 mit einem prompt wie: „Datenpunkte und Werte beibehalten, Diagrammstil auf dunkel, Neon-Highlights, Infografik-Stil ändern“.
Dies ist derzeit der stabilste Ansatz für die Kombination von Datendiagrammen und KI-Verschönerung. Die Rohwerte werden durch die deterministische Grafikbibliothek garantiert, während der visuelle Stil von gpt-image-2 neu gestaltet wird – beide Seiten tun das, was sie am besten können. Wenn Sie diesen Prozess stapelweise ausführen möchten, empfehlen wir den Aufruf von gpt-image-2 über APIYI apiyi.com. Der Dienst bietet ein Upstream-Account-Pool-Scheduling für Szenarien mit hoher Parallelität von 5000 RPM, ideal für Aufgaben mit tausenden Bildern pro Tag.
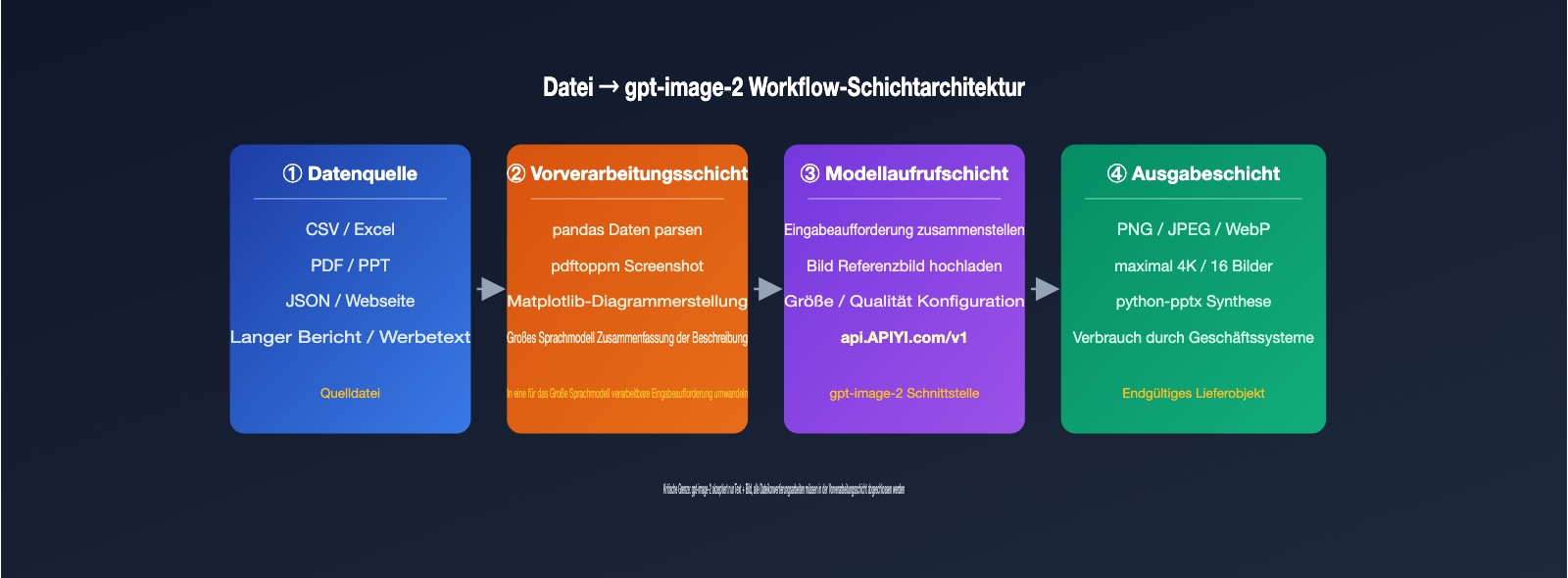
Lösung 4: LLM + gpt-image-2 Dual-Modell-Pipeline
Geeignet für Dateien mit komplexen Inhalten, die ein semantisches Verständnis erfordern, wie z. B. lange Berichte, Vertragszusammenfassungen oder Produktbeschreibungen. Verwenden Sie zunächst die GPT-4-Serie oder Claude 4, um die Datei zu verstehen und 4–8 Bildbeschreibungen zu extrahieren, und rufen Sie dann in einer Schleife gpt-image-2 auf, um die entsprechende Anzahl an Bildern zu generieren.
Der Schlüssel hierbei ist die Entkopplung von „semantischem Verständnis“ und „Bilderzeugung“. Das LLM ist dafür verantwortlich zu sagen: „Was auf dieser Seite dargestellt werden sollte“, und gpt-image-2 ist dafür verantwortlich: „Das Bild gemäß dieser Eingabeaufforderung zu zeichnen“. Die gesamte Pipeline kann auf APIYI apiyi.com mit einem einzigen API-Schlüssel verbunden werden, was das Wechseln von SDKs und die Verwaltung von Schlüsseln erspart.
Lösung 5: Programmgesteuerte Synthese von PPT/Postern nach Stapel-Bilderzeugung
Dies ist das Geheimnis hinter den „One-Click-PPT“-Fällen, die man oft sieht. Das Modell selbst gibt keine PPTX-Datei aus, aber es kann für jede Seite ein Bild generieren. Anschließend können Sie mit Python python-pptx oder dem Frontend-Tool PptxGenJS die Bilder an den entsprechenden Stellen in einer PPT-Vorlage platzieren.
Kurz gesagt: Eine PPT ist im Wesentlichen eine Präsentation, die aus mehreren Bildern besteht. gpt-image-2 löst das „Bild“-Problem, python-pptx das Problem des „Dokument-Containers“. Eine gängige Aufteilung ist: Deckblatt mit hochwertigem 4K-Bild, Innenseiten mit mittelwertigen 1536×1024-Bildern, Inhaltsverzeichnis und Übergangsseiten mit qualitativ niedrigen Entwürfen – so lässt sich die Kostenstruktur über den quality-Parameter differenziert steuern. Eine PPT mit 20 Seiten erfordert etwa 20–30 Modellaufrufe und kann über den 5000-RPM-API-Proxy-Dienst in wenigen Minuten fertiggestellt werden.
| Lösung | Geeigneter Dateityp | Arbeitsaufwand | Ausgabequalität | Empfohlenes Szenario |
|---|---|---|---|---|
| Lösung 1 Datei zu Text | CSV/Excel/JSON | Niedrig | Mittel | Einfache Diagramme, stilisierte Illustrationen |
| Lösung 2 Seitenscreenshot | PDF/PPT/Web | Niedrig | Mittel-Hoch | Layout-Anpassung, Stiltransfer |
| Lösung 3 Visualisierungs-Vorrendering | CSV/Excel | Mittel | Hoch | Verschönerung von Datendiagrammen |
| Lösung 4 LLM + gpt-image-2 | Lange Berichte/Texte | Mittel-Hoch | Hoch | Inhaltskarten, Tutorial-Bilder |
| Lösung 5 Stapel-PPT-Synthese | Beliebig | Hoch | Hoch | Automatisierung von Präsentationsdokumenten |
API-Aufruf-Codebeispiel: Wie Dateiinhalte zur Eingabe für gpt-image-2 werden
Wenn man die Konzepte auf die Code-Ebene überträgt, wird alles anschaulicher. Hier ist ein minimales, ausführbares Python-Beispiel, das eine Excel-Tabelle in eine Text-Eingabeaufforderung umwandelt und dann gpt-image-2 aufruft, um das entsprechende Visualisierungsdiagramm zu erstellen. Wir nutzen APIYI (apiyi.com) als einheitlichen API-Proxy-Dienst; Sie müssen lediglich die base_url anpassen, die restliche SDK-Syntax bleibt identisch mit der offiziellen Version.
from openai import OpenAI
import pandas as pd
import base64
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
# Excel-Datei einlesen
df = pd.read_excel("sales_q1.xlsx")
summary = df.groupby("region")["sales"].sum().to_dict()
# Eingabeaufforderung für das Modell erstellen
prompt_text = (
f"Erstelle ein Balkendiagramm für die regionalen Umsätze im Q1 2026,"
f"Daten: {summary}, "
f"dunkler Business-Stil, reinweiße Überschrift, Datenbeschriftungen gut lesbar."
)
# Modellaufruf
resp = client.images.generate(
model="gpt-image-2",
prompt=prompt_text,
size="1536x1024",
quality="high"
)
img_b64 = resp.data[0].b64_json
with open("sales_chart.png", "wb") as f:
f.write(base64.b64decode(img_b64))
Das Prinzip ist klar: Die Anwendungsebene analysiert die Excel-Datei in eine Textbeschreibung, das Modell verarbeitet ausschließlich Text. Falls Sie Bild-zu-Bild (Szenario 2) nutzen möchten, ersetzen Sie client.images.generate durch client.images.edit und übergeben das Bild via image=open("page.png", "rb").
| Parameter | Wertebereich | Beschreibung |
|---|---|---|
model |
gpt-image-2 / gpt-image-2-mini |
Die Mini-Version ist schneller und günstiger |
size |
1024×1024 / 1536×1024 / 1024×1536 / Benutzerdefiniert | Längste Seite ≤ 3840px, Seitenlänge muss durch 16 teilbar sein |
quality |
low / medium / high / auto | Hohe Qualität benötigt mehr Zeit und Token |
n |
1–4 | Anzahl der Bilder pro Aufruf; für Stapelverarbeitung wird eine Schleife empfohlen |
response_format |
png(Standard) / jpeg / webp | gpt-image-2 unterstützt keine PDF/PPTX-Ausgabe |
🎯 Tipp für die Implementierung: Um diesen Prozess schnell zu starten, empfehlen wir, ein Konto bei APIYI (apiyi.com) zu registrieren. Sobald Sie die
base_urlaufhttps://api.apiyi.com/v1umstellen, können Sie über eine einheitliche Schnittstelle gleichzeitig gpt-image-2, GPT-5 und die Claude 4-Serie nutzen und sparen sich die mühsame Anbindung verschiedener Anbieter.

Die 4 häufigsten Fehler bei Kunden und wie man sie vermeidet
Nachdem Sie die 5 Lösungsansätze verstanden haben, können bei der praktischen Umsetzung noch einige Details für Stolpersteine sorgen. Wir haben die vier am häufigsten gestellten Fragen aus unserem Support-Chat zusammengefasst.
Fehler 1: Base64-kodierte CSV-Daten in die Eingabeaufforderung einfügen
Einige Nutzer hatten eine „clevere“ Idee: Eine CSV-Datei in einen Base64-String umwandeln und diesen in die Eingabeaufforderung einfügen, in der Hoffnung, das Modell würde ihn selbst dekodieren. Dieser Weg funktioniert nicht. gpt-image-2 führt keinen Code aus und interpretiert Strings nicht als Daten. Es betrachtet den Base64-String lediglich als bedeutungslose Zeichenfolge und rendert daraus nur Zeichensalat. Der richtige Weg ist, die CSV-Datei auf der Anwendungsebene in eine textuelle Beschreibung zu parsen (siehe Ansatz 1).
Fehler 2: Erwarten, dass gpt-image-2 Tabellen „exakt wie in Excel“ zeichnet
Das Modell ist hervorragend in visueller Konsistenz und Stilisierung, aber eine pixelgenaue Wiedergabe ist eine andere Sache. Wenn Sie präzise Tabellen benötigen, empfehlen wir eine Kombinationsstrategie: Erstellen Sie eine exakte Version mit ECharts/matplotlib (Ansatz 3) und lassen Sie gpt-image-2 anschließend das Design verschönern. Die Erwartung, dass das Modell mit einer einzigen Eingabeaufforderung 100 Zeilen Daten präzise zeichnet, ist derzeit nicht erfüllbar.
Fehler 3: Wunsch nach SVG- oder PDF-Vektorformaten
gpt-image-2 gibt Dateien ausschließlich in den drei Rasterformaten PNG, JPEG und WebP aus; Vektorformate wie SVG, PDF oder AI werden nicht unterstützt. Wenn Sie Vektorgrafiken benötigen, nutzen Sie Stable Diffusion in Kombination mit vectorizer.ai oder lassen Sie direkt GPT-5 den SVG-Code generieren. Klären Sie das Ausgabeformat vor der Modellauswahl, um Nacharbeiten zu vermeiden.
Fehler 4: Wiederholtes Hochladen desselben Referenzbildes treibt Token-Verbrauch in die Höhe
gpt-image-2 verarbeitet jedes Eingabebild mit hoher Wiedergabetreue. Selbst wenn Sie Ihre Eingabeaufforderung nur geringfügig anpassen, werden bei jeder Anfrage die Input-Token neu berechnet. Wir empfehlen, auf Client-Seite ein Caching für Referenzbilder einzurichten oder direkt die previous_response_id für dialogbasiertes Editieren (Responses API) zu verwenden, um den Bildkontext wiederzuverwenden.
Ein weiteres Detail: Selbst wenn Sie nur ein 256×256-Thumbnail ausgeben möchten, werden die Input-Token basierend auf der 4K-Auflösung des Referenzbildes berechnet. Komprimieren Sie das Referenzbild lokal auf eine maximale Kantenlänge von 1024 Pixeln, bevor Sie es hochladen. Dies kann mehr als 60 % der Input-Token einsparen und ist der am häufigsten übersehene Punkt bei der Kostenkontrolle für Massenaufgaben.
| Fehlerbild | Ursache | Empfohlene Lösung |
|---|---|---|
| 400 invalid_request_error | Nicht-Bild-Binärdaten hochgeladen (CSV/Excel) | Datei vorab in Text oder Screenshot umwandeln |
| Zeichensalat bei der Darstellung | Base64-String als Eingabeaufforderung genutzt | Geparste natürliche Sprache verwenden |
| Ungenaue Tabellendaten | Versuch, Tabellen per Eingabeaufforderung zu zeichnen | Vorab-Visualisierung (Ansatz 3) nutzen |
| Wunsch nach SVG-Ausgabe | Modell unterstützt keine Vektorformate | GPT-5 für SVG-Code-Generierung nutzen |
| Unerwartet hoher Token-Verbrauch | Großes Referenzbild wiederholt hochgeladen | Auf < 1,5 MB komprimieren, Caching nutzen |
Häufig gestellte Fragen (FAQ)
Q1: Kann gpt-image-2 wirklich absolut keine PDFs verarbeiten?
Direkt können keine PDFs hochgeladen werden. Sie können jedoch pdftoppm verwenden, um jede Seite in ein PNG zu konvertieren und diese dann als Bild einzuspeisen. Wenn Sie „PDF-Inhalte verstehen und daraus Bilder generieren“ möchten, empfehlen wir, das PDF zuerst von GPT-5 zusammenfassen zu lassen und diese Beschreibung dann an gpt-image-2 zu übergeben. Diese Kombination lässt sich bei APIYI (apiyi.com) mit einem einzigen API-Schlüssel umsetzen.
Q2: Ist es sicher, Dateien mit sensiblen Daten an das Modell zu senden?
Die Konvertierung der Datei in Text erfolgt auf Ihrem eigenen Server. Nur der finale Text der Eingabeaufforderung wird an das Modell gesendet; Sie können die Daten bereits bei der Textumwandlung anonymisieren. Bei Nutzung eines API-Proxy-Dienstes wie APIYI (apiyi.com) werden die Eingabeaufforderungen und Antworten der Nutzer explizit nicht gespeichert, was die Compliance besser kontrollierbar macht als bei der Nutzung externer Proxys.
Q3: Nutzen „Ein-Klick-PPT-Generatoren“ auf TikTok/Douyin gpt-image-2?
Teilweise. Die Logik sieht meist so aus: LLM schreibt den Text → Bildmodell (gpt-image-2 / Nano Banana Pro / Flux) erstellt Illustrationen → Backend setzt alles mit python-pptx zusammen. gpt-image-2 bietet die beste Textdarstellung, insbesondere bei chinesischen Schriftzeichen, und eignet sich daher hervorragend für PPT-Folien-Illustrationen.
Q4: Warum behaupten manche, man könne Excel-Dateien hochladen?
Dabei handelt es sich um Screenshots von Excel-Tabellen, die als Bilder hochgeladen werden. Im Grunde ist es also eine Bildeingabe, das Modell versteht die Excel-Struktur nicht. Wenn die Zahlen im Screenshot unscharf sind, kann das Modell sie nur so unscharf nachzeichnen.
Q5: Sollte ich gpt-image-2 oder gpt-image-2-mini wählen?
Die Mini-Version ist schneller und kostengünstiger – ideal für Massenentwürfe und Thumbnails. Für offizielle Publikationen sollten Sie die Standardversion verwenden. Die Eingabebeschränkungen sind bei beiden identisch (keine Dokumentdateien unterstützt). Sie müssen lediglich die Modell-ID im model-Parameter anpassen, der SDK-Code bleibt unverändert.
Zusammenfassung
gpt-image-2 unterstützt weder den direkten Upload von CSV-, Excel- oder PPT-Dateien, noch gibt es PPTX- oder PDF-Dateien aus. Dies ist eine systembedingte Kapazitätsgrenze des Modells und kein Problem mit den Verbindungsparametern. Sobald man diese Grenze verstanden hat, lässt sich das Modell für fast alle Anwendungsfälle nutzen, die "Dateieingaben" erfordern – man muss die Inhalte lediglich vorverarbeiten: in Text umwandeln, Screenshots erstellen oder Daten erst visualisieren und dann grafisch aufbereiten. Die auf TikTok gezeigten Lösungen für "One-Click-PPTs", "Excel-zu-Poster" oder "PDF-Stiländerungen" basieren im Kern auf solchen mehrstufigen Workflows. Wenn man die Arbeitsteilung zwischen Modell-Inferenz und Datenverarbeitung klar trennt, lassen sich diese Anforderungen problemlos umsetzen.
Der wichtigste Grundsatz bei der Implementierung lautet: Die Modellebene übernimmt nur das, was sie am besten kann; die Datenebene wird extern vorbereitet. Wenn Sie einen vollständigen Workflow aufbauen möchten, empfehlen wir, sowohl GPT-5 (für das Textverständnis) als auch gpt-image-2 (für die Bilderzeugung) über APIYI (apiyi.com) einzubinden. So nutzen Sie einen einzigen API-Schlüssel für den gesamten Prozess. Dank der hohen Parallelität von 5000 RPM laufen auch Batch-Aufgaben reibungslos, ohne dass Sie für verschiedene Modelle mehrere Schlüssel oder SDKs verwalten müssen.
Über den Autor: Das APIYI-Team ist auf die Aggregation multimodaler Schnittstellen und eine hochperformante Inferenz-Infrastruktur spezialisiert und bearbeitet täglich zahlreiche Anfragen zur Bilderzeugungs-API. Dieser Artikel wurde auf Basis der offiziellen OpenAI-Dokumentation und echter Kundenanfragen erstellt. Wenn Sie mehr über die Einbindung von gpt-image-2 erfahren möchten, besuchen Sie APIYI unter apiyi.com.



