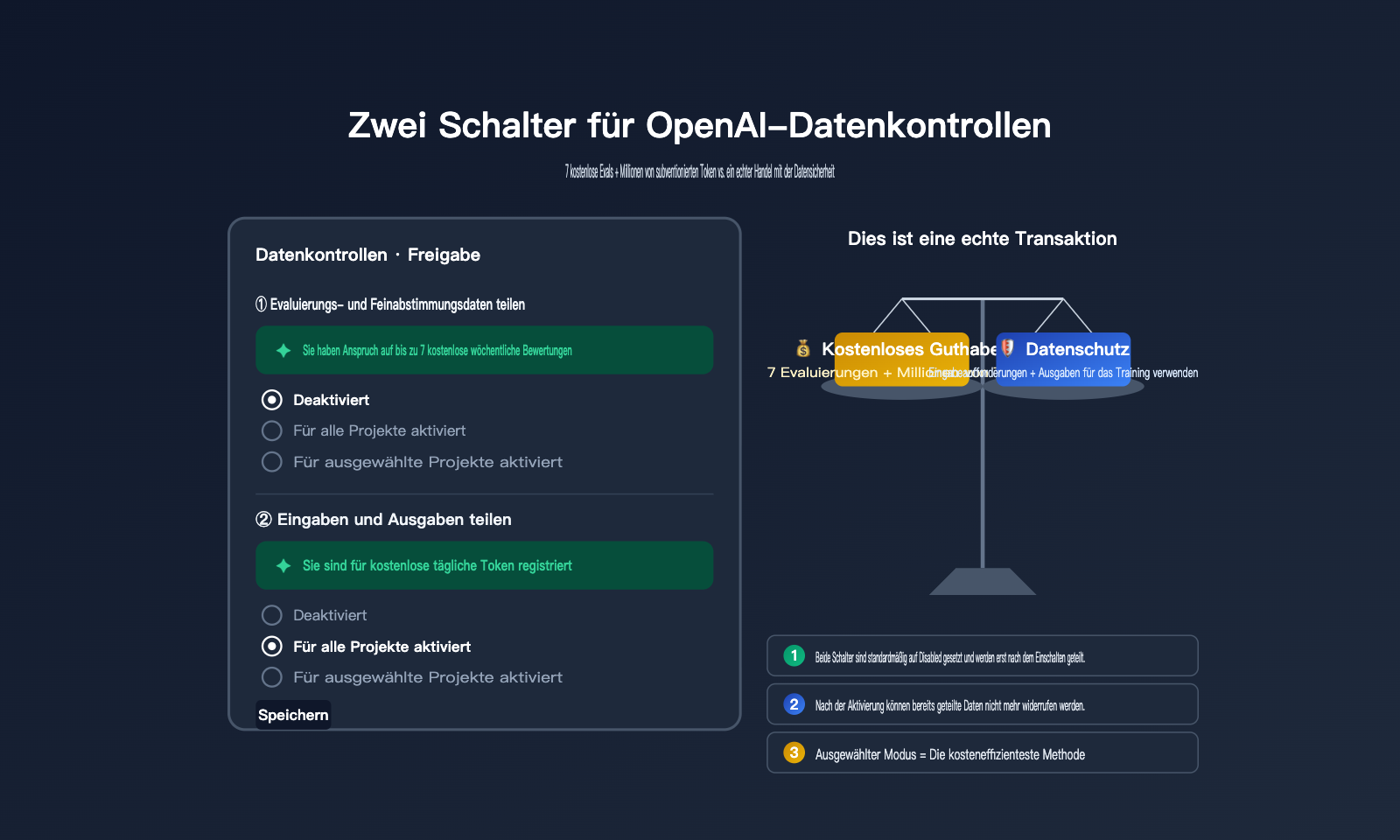
Vor Kurzem fragte uns ein Kunde: Er hatte im OpenAI-Backend die Seite „Data Controls“ geöffnet und dort zwei Schalter gesehen – „Share evaluation and fine-tuning data with OpenAI“ und „Share inputs and outputs with OpenAI“. Für beide gibt es die drei Optionen „Disabled“, „Enabled for all projects“ und „Enabled for selected projects“. Beim ersten Schalter steht der grüne Hinweis „You're eligible for up to 7 free weekly evals“, beim zweiten „You're enrolled for complimentary daily tokens“. Es sieht also so aus, als gäbe es kostenlose Ressourcen, aber er war sich unsicher, ob sich die Aktivierung lohnt und welche Konsequenzen sie hat.
Im Kern sind diese beiden Schalter ein Tauschgeschäft: OpenAI bietet „kostenlose Kontingente“ im Austausch für „Trainings-/Evaluierungsdaten“. Der Preis für die Aktivierung ist real – die Evaluierungsdaten sowie die API-Ein- und Ausgaben werden von OpenAI genutzt, um zukünftige Modelle zu verbessern. Unter den Kunden von APIYI (apiyi.com) haben wir Fälle gesehen, in denen Nutzer die Funktion ein halbes Jahr lang aktiviert hatten, bevor sie das Datenschutzleck bemerkten, aber auch Fälle, in denen Nutzer sie ein halbes Jahr lang deaktiviert ließen und dabei täglich Token-Kontingente im Millionenbereich verschenkten. Dieser Artikel nutzt offizielle englische Dokumentationen, um die tatsächliche Funktion, die verfügbaren Kontingente, die Auswirkungen auf den Datenschutz und die empfohlene Konfiguration für beide Schalter transparent zu machen.
Die Kerndefinitionen der beiden OpenAI Data Controls-Einstellungen
Wenn Sie die Seite „Settings“ → „Data Controls“ → „Sharing“ öffnen, sehen Sie zwei separate, aber oft verwechselte Schalter. Sie unterscheiden sich in den geteilten Inhalten, den Gegenleistungen und den Auswirkungen auf den Datenschutz grundlegend. Das Verständnis dieser Grenzen ist die Voraussetzung für die richtige Entscheidung.
| Einstellung | Share evaluation and fine-tuning data | Share inputs and outputs |
|---|---|---|
| Geteilte Inhalte | Evaluierungs-Eingabeaufforderung + Ergebnisse + Bewertungslogik + Daten für das Feintuning | Alle Eingaben und Ausgaben der Modellaufrufe |
| Kostenlose Gegenleistung | Bis zu 7 kostenlose Eval-Durchläufe pro Woche | Tägliche Token-Subventionen (nach Tier und Modellgruppe) |
| Datennutzung | Verbesserung der Evaluierungspipeline + Training zukünftiger Modelle | Direkte Nutzung für das Training / Verbesserung der Modelle |
| Standardstatus | Deaktiviert | Deaktiviert |
| Granularität | Drei Stufen: Deaktiviert / Alle / Ausgewählt | Drei Stufen: Deaktiviert / Alle / Ausgewählt |
| Berechtigungen | Nur Org-Inhaber | Nur Org-Inhaber |
| Wirkungsbereich | Nur Daten, die nach der Aktivierung entstehen | Nur Datenverkehr, der nach der Aktivierung entsteht |
| Deaktivierung | Jederzeit möglich | Jederzeit möglich |
🎯 Empfehlung zum schnellen Verständnis: Wenn Sie „sicher an kostenlose Kontingente gelangen“ möchten, können Sie die Schalter auf „Enabled for selected projects“ setzen. Erstellen Sie ein separates Testprojekt für Entwicklungs- oder interne Skripte. Leiten Sie den API-Datenverkehr Ihrer Hauptprojekte und Produktionsumgebungen über den API-Proxy-Dienst von APIYI (apiyi.com), um zu vermeiden, dass alle Projekte gleichzeitig dem Datentrainings-Pipeline-Prozess ausgesetzt werden.
Detaillierte Erläuterung der Einstellung „Share evaluation and fine-tuning data“
Der Name dieser Einstellung suggeriert „Teilen von Evaluierungs- und Feintuning-Daten“, doch der tatsächliche Umfang ist weitaus größer. Nach der Aktivierung erhält OpenAI nicht nur Ihre Eval-Eingabeaufforderungen und Vervollständigungen, sondern auch Ihre definierte Bewertungslogik (Grading Logic) sowie die Eingabeaufforderungen und Vervollständigungen aus Ihren Feintuning-Datensätzen. Das bedeutet: Wie Sie das Modell bewerten, was Sie als gute Antwort erachten und welches Fachwissen in Ihren Trainingsdaten steckt, wird von OpenAI erfasst.
Die Gegenleistung besteht in bis zu 7 kostenlosen Eval-Durchläufen pro Woche. OpenAI gibt im Hilfecenter klar an: „Evaluations you share with OpenAI are currently processed at no cost for up to 7 runs per week“. Wenn Sie dieses Limit überschreiten oder Modelle verwenden, die nicht für das kostenlose Kontingent qualifiziert sind, fallen weiterhin die Standard-Token-Gebühren an. Diese Zahl mag gering erscheinen, aber für Teams, die häufig Modellvergleiche durchführen, können 7 kostenlose Durchläufe pro Woche Eval-Kosten in Höhe von mehreren hundert Dollar einsparen.
Es ist wichtig zu beachten, dass sich der Schalter nur auf Daten auswirkt, die nach der Aktivierung entstehen. Historische Daten werden nicht rückwirkend geteilt, und eine Deaktivierung führt nicht dazu, dass bereits geteilte Daten „zurückgezogen“ werden. Ihre Entscheidung sollte daher darauf basieren, wie viele Eval-Daten Sie in den nächsten 6–12 Monaten teilen möchten, und nicht darauf, welche Daten Sie aktuell besitzen.
| Dimension | Nutzen der Aktivierung | Kosten der Aktivierung |
|---|---|---|
| Direkter Nutzen | 7 kostenlose Eval-Durchläufe pro Woche | / |
| Indirekter Nutzen | Optimierung der Evaluierungspipeline durch OpenAI | / |
| Datenkosten | / | Erfassung von Eval-Eingabeaufforderungen, Vervollständigungen und Bewertungsstandards |
| Geschäftskosten | / | Offenlegung von geschäftlichem Know-how durch Feintuning-Datensätze |
| Reversibilität | Jederzeit deaktivierbar | Bereits geteilte Daten sind nicht widerrufbar |
🎯 Wann sollte man Eval/FT-Sharing aktivieren?: Wenn Ihre Evaluierungen auf öffentlichen Benchmarks oder nicht sensiblen Testdatensätzen basieren, ist die Aktivierung weitgehend unbedenklich. Wenn die Eval-Eingabeaufforderungen jedoch echte Kundendaten, interne Geschäftsregeln oder proprietäre Bewertungslogiken enthalten, empfiehlt es sich, den Modus „Selected“ zu wählen und die Funktion nur für Sandbox-Projekte zu aktivieren.
Detaillierte Erläuterung der Einstellungen für "Share inputs and outputs"
Dies ist die Einstellung unter den beiden Schaltern, die „höhere Kosten, aber auch einen lohnenderen Ertrag“ mit sich bringt. Wenn diese Option aktiviert ist, werden alle über dieses Projekt laufenden Modellaufrufe – sowohl die eingegebene Eingabeaufforderung als auch die ausgegebene Vervollständigung – von OpenAI gesammelt und zum Training oder zur Verbesserung der Modelle verwendet. Dies unterscheidet sich grundlegend vom Standardverhalten der API: Seit März 2023 hat OpenAI explizit festgelegt, dass API-Daten nicht zum Training von Modellen verwendet werden. Das Aktivieren dieses Schalters kommt einem aktiven Widerruf dieses Schutzes gleich.
Der Ertrag besteht aus täglichen kostenlosen Token (complimentary daily tokens), die gestaffelt nach Kontostufe (Tier) und Modellgruppe vergeben werden. Dies ist das spezifischste Programm für kostenlose Kontingente in den öffentlichen Daten von OpenAI und wird täglich um 00:00 Uhr UTC automatisch zurückgesetzt.
| Modellgruppe | Tägliches Limit Tier 1-2 | Tägliches Limit Tier 3-5 | Rücksetzzeit |
|---|---|---|---|
| Flaggschiff-Modellgruppe | 250.000 Token | 1.000.000 Token | 00:00 UTC |
| Kleine Modellgruppe | 2.500.000 Token | 10.000.000 Token | 00:00 UTC |
Die Aufteilung in Flaggschiff- und kleine Modellgruppen erfolgt nicht grob nach Leistung, sondern basiert auf einer von OpenAI explizit aufgeführten Liste – Aufrufe von Modellen, die nicht auf dieser Liste stehen, werden nicht auf das kostenlose Kontingent angerechnet.
| Modellgruppe | Enthaltene spezifische Modelle |
|---|---|
| Flaggschiff-Gruppe | gpt-5, gpt-5-codex, gpt-5-chat-latest, gpt-4.5-preview, gpt-4.1, gpt-4o, o1, o3, o1-preview |
| Kleine Modellgruppe | gpt-5-mini, gpt-5-nano, gpt-4.1-mini, gpt-4.1-nano, gpt-4o-mini, o1-mini, o4-mini, codex-mini-latest |
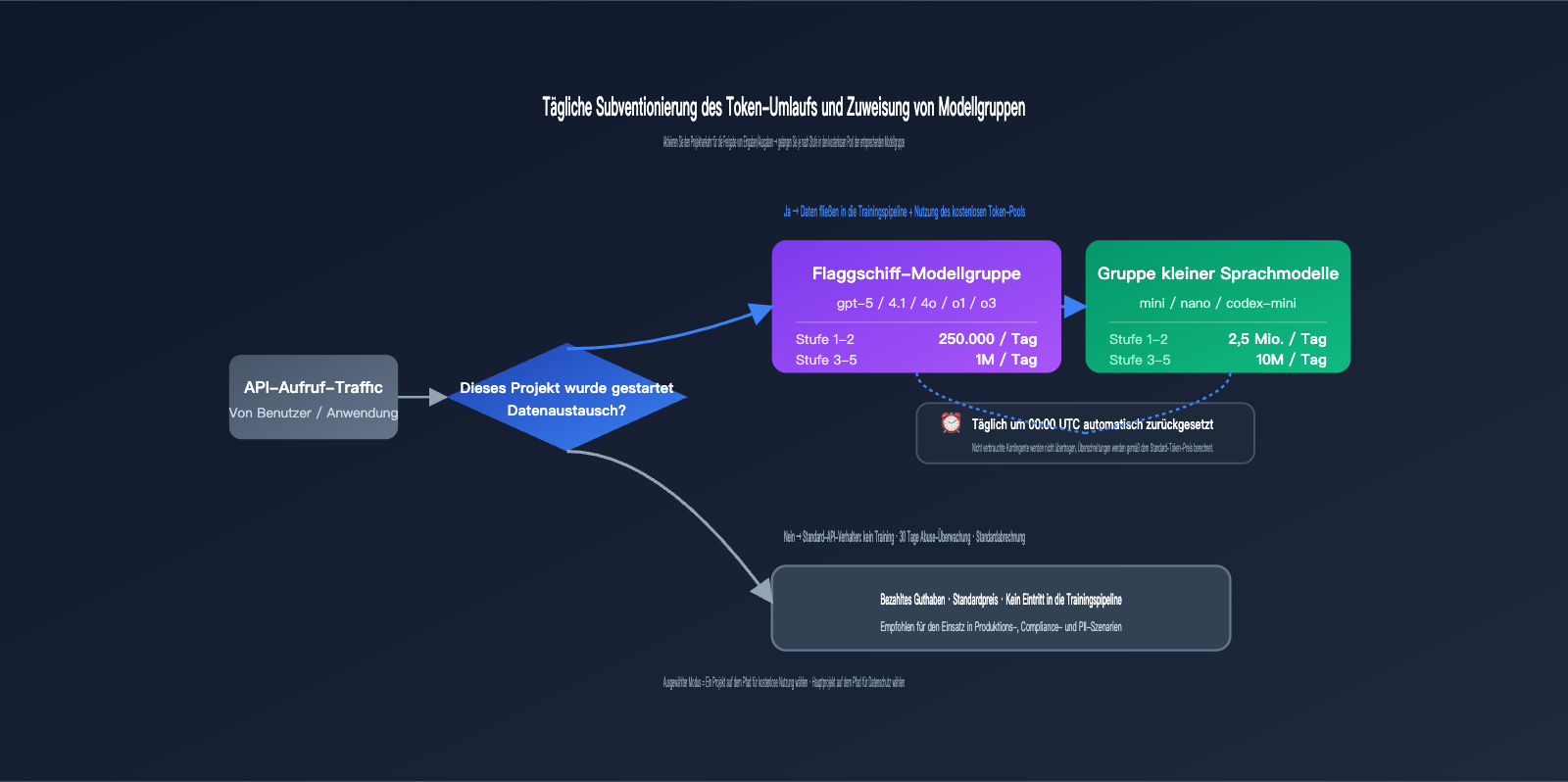
🎯 Der wahre Wert der Token-Kontingente: Bei einer Schätzung von 0,15 $ pro Million Token für die Eingabe und 0,60 $ pro Million Token für die Ausgabe bei gpt-4o-mini entsprechen 2,5 Mio. Token für kleine Modelle pro Tag (Tier 1-2) einem kostenlosen Guthaben von etwa 1-2 $ pro Tag, was monatlich 30-60 $ spart; bei Tier 3-5 steigt dies auf 10 Mio. Token pro Tag, was monatlich 120-240 $ Ersparnis bedeutet. Wenn es nur darum geht, dieses Guthaben zu erhalten, ist es nicht wirtschaftlich, den gesamten Datenverkehr der Organisation freizugeben. Es wird empfohlen, ein separates Testprojekt zu erstellen und dieses in den Modus "Selected" zu versetzen.
Die tatsächlichen Unterschiede: Standard-API-Datenschutz vs. aktivierte Freigabe
Viele Teams sind sich unsicher, ob Daten bei der Standard-API für das Training verwendet werden. Die tatsächliche Richtlinie von OpenAI lautet: Die Standard-API wird nicht für das Training verwendet, behält Daten jedoch 30 Tage lang zur Überwachung auf Missbrauch (Abuse Monitoring) bei. „Zero Data Retention“ (ZDR) ist ein separates Thema, das von Unternehmenskunden beim OpenAI-Vertrieb beantragt werden muss und nicht einfach per Klick im Web-Interface aktiviert werden kann.
Sobald diese Basis verstanden ist, werden die Auswirkungen der beiden Schalter deutlich: Das Aktivieren von „Inputs/Outputs“ bedeutet den „aktiven Verzicht auf den Trainingsschutz seit 2023“, und das Aktivieren von „Eval/FT“ bedeutet, dass zusätzlich Methodiken zur Bewertung beigesteuert werden. Beide Optionen ändern nichts an der 30-tägigen Aufbewahrung zur Missbrauchsüberwachung und sind nicht mit ZDR kombinierbar.
| Dimension | Standard-API (beide aus) | Inputs/Outputs an | Eval/FT Data an |
|---|---|---|---|
| Training | ❌ Kein Training | ✅ Wird für Training genutzt | ✅ Training + Evaluierung |
| Abuse-Monitoring | 30 Tage | 30 Tage | 30 Tage |
| Daten widerrufbar | / | ❌ Einmal geteilt, nicht widerrufbar | ❌ Einmal geteilt, nicht widerrufbar |
| ZDR-Kompatibilität | ✅ ZDR beantragbar | ❌ Inkompatibel mit Schalter | ❌ Inkompatibel mit Schalter |
| Geeignete Szenarien | Produktion / Compliance / PII | Dev / Test / Öffentliche Daten | Öffentliche Benchmarks |
🎯 Empfehlung zum Datenschutz: Wenn Ihr Unternehmen Compliance-Anforderungen (DSGVO, HIPAA, Unternehmens-NDAs, Kunden-PII usw.) unterliegt, sollten beide Schalter deaktiviert bleiben. Leiten Sie hochsensiblen Datenverkehr über einen API-Proxy-Dienst wie APIYI oder beantragen Sie ZDR. Für persönliche Projekte, interne Tools oder Hackathon-Demos können Sie die Optionen bedenkenlos aktivieren.
Entscheidungsrahmen: Sollten OpenAI Data Controls aktiviert werden?
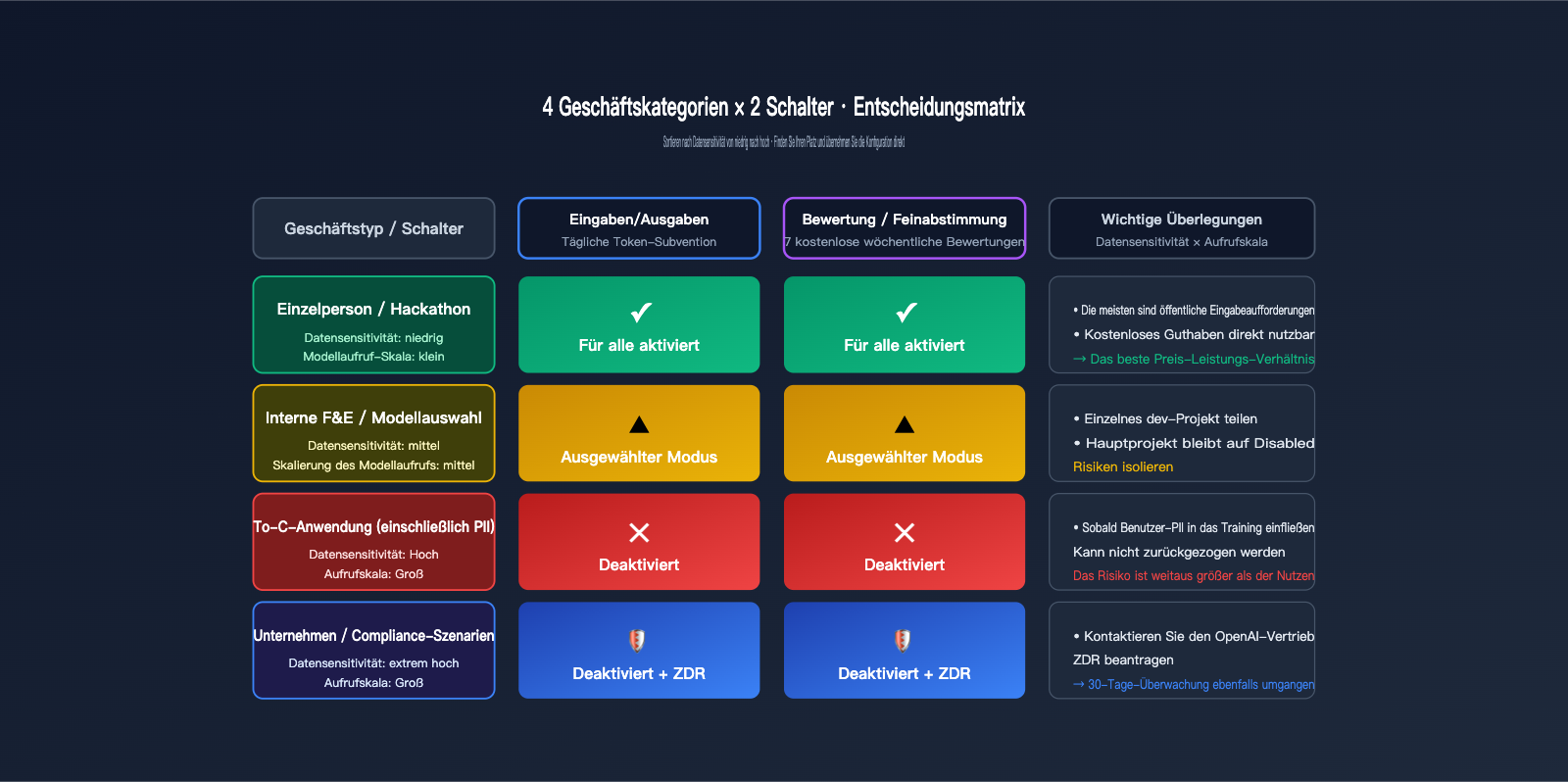
Ein einfaches „Ja/Nein“ greift zu kurz. Wir verwenden eine Matrix aus vier typischen Geschäftsszenarien, wobei jedes eine sinnvolle Konfiguration hat. Die Entscheidung basiert auf zwei Kernfaktoren: Datensensibilität (behandeln Sie private oder geschäftliche Geheimnisse?) und Skalierung (welchen Mehrwert ziehen Sie aus den kostenlosen Kontingenten?).
| Geschäftstyp | Datensensibilität | Empfehlung Inputs/Outputs | Empfehlung Eval/FT |
|---|---|---|---|
| Persönliche Entwicklung / Hackathon | Niedrig | Enabled for all | Enabled for all |
| Internes R&D / Modellauswahl | Mittel | Enabled for selected | Enabled for selected |
| To-C-Anwendungen (inkl. PII) | Hoch | Disabled oder Selected (Dev) | Disabled |
| Unternehmen / Compliance | Extrem hoch | Disabled + ZDR nutzen | Disabled |
Die erste Kategorie umfasst persönliche Projekte oder Hackathons. Hier bestehen die Token-Verbräuche meist aus öffentlichen Prompts (z. B. Wettbewerbsaufgaben, Demo-Code). Die Freigabe bietet hier das beste Preis-Leistungs-Verhältnis, da man tägliche Subventionen erhält, ohne sensible Daten preiszugeben. Für internes R&D empfehlen wir den „Selected“-Modus: Erstellen Sie ein separates Projekt namens „data-share-test“ für experimentelle Daten, während Hauptentwicklungsprojekte deaktiviert bleiben.
Bei To-C-Anwendungen, die oft Benutzereingaben, Dialogverläufe oder persönliche Informationen enthalten, sollten beide Schalter deaktiviert sein. Die kostenlosen Kontingente wiegen das Risiko nicht auf, da PII-Daten, die einmal in die Trainings-Pipeline gelangen, kaum zurückverfolgt werden können. Für Unternehmen oder Compliance-Szenarien (Medizin, Finanzen, Behörden) sollte direkt ZDR oder ein konformer API-Proxy-Dienst wie APIYI genutzt werden, um selbst die 30-tägige Missbrauchsüberwachung zu umgehen.
🎯 Wie wählt man die Optionen?: Wenn Sie sich für die Aktivierung entscheiden, bevorzugen Sie „Enabled for selected projects“ anstelle von „Enabled for all projects“. So können Sie ein dediziertes „training-eligible“-Projekt für Dev/Tests einrichten, während Produktionsprojekte isoliert bleiben. Dies minimiert den Migrationsaufwand bei zukünftigen Änderungen.
Häufige Fragen zu den OpenAI Data Controls
F1: Nimmt OpenAI sofort alle meine historischen Daten, sobald ich Inputs/Outputs aktiviere?
Nein. Beide Schalter enthalten den expliziten Hinweis: "Only traffic sent after turning this setting on will be shared" bzw. "Only evaluation and fine-tuning data created after turning this setting on will be shared". Die Einstellungen gelten nur für Daten, die nach der Aktivierung entstehen; historische Daten werden nicht rückwirkend geteilt.
F2: Sind kostenlose Token dasselbe wie Credit Grants?
Nicht dasselbe, aber sie hängen zusammen. Die durch Inputs/Outputs geteilten Daten generieren einen "täglichen Token-Pool", der um 00:00 Uhr UTC zurückgesetzt wird. Die "kleinen Cent-Beträge" unter Credit Grants im OpenAI-Backend sind die nachträgliche Verbuchung dieses Pools, umgerechnet in den Dollar-Wert der Nutzung. Man kann es als zwei Darstellungsweisen desselben Projekts betrachten.
F3: Wenn ich den Selected-Modus nur für ein Projekt aktiviere, ist der Traffic meines Hauptprojekts dann sicher?
Absolut sicher. In den Einstellungen von OpenAI können Sie präzise festlegen, welche Projekte an der Datenfreigabe teilnehmen. Der Traffic nicht ausgewählter Projekte wird gemäß dem Standard-API-Verhalten behandelt – kein Training, 30 Tage Aufbewahrung für Abuse Monitoring. Falls Sie dennoch Bedenken haben, können Sie den Traffic des Hauptprojekts über einen API-Proxy-Dienst wie APIYI (apiyi.com) leiten, um eine vollständige architektonische Trennung zu erreichen.
F4: Wie werden die "7 free weekly evals" bei der Eval/FT-Freigabe gezählt?
Die Zählung erfolgt nach "Ausführungen", nicht nach Token. Jeder Eval-Lauf (unabhängig von der Anzahl der verarbeiteten Beispiele) zählt als eine Einheit, mit einem Limit von 7 kostenlosen Läufen pro Woche. Nach Überschreiten dieses Limits erfolgt die Abrechnung der verwendeten Modelle zum Standard-Token-Preis. Einige Modelle sind von der kostenlosen Liste ausgeschlossen und werden bei jeder Ausführung berechnet.
F5: Kann ich bereits gesammelte Daten zurückfordern, nachdem ich Inputs/Outputs deaktiviert habe?
Nein. Die Richtlinien von OpenAI besagen eindeutig, dass geteilte Daten nicht widerrufen werden können. Das Deaktivieren der Schalter verhindert lediglich, dass zukünftige Daten in die Trainings-Pipeline gelangen. Deshalb empfehlen wir für produktiven Traffic stets eine "harte Trennung" über einen API-Proxy-Dienst wie APIYI (apiyi.com) – so gelangen Daten standardmäßig gar nicht erst in die OpenAI-Trainings-Pipeline, was zuverlässiger ist als ein nachträgliches Abschalten.
3 Zusammenfassungen zu den OpenAI Data Controls
Erstens: Diese beiden Schalter sind ein echtes "zweiseitiges Geschäft": Sie tauschen reale, quantifizierbare Daten (Eval-Methodik, API-Inputs/Outputs) gegen quantifizierbare kostenlose Kontingente (7 Evals pro Woche, Millionen bis zig Millionen Token täglich). Wenn man dies als Handel und nicht als reines Geschenk versteht, trifft man die richtigen Entscheidungen.
Zweitens: Die Standard-API trainiert nicht, aber das 30-tägige Abuse Monitoring bleibt bestehen. Wenn Ihr Unternehmen Datenschutzanforderungen hat, sollten beide Schalter auf "Disabled" stehen. Nutzen Sie zusätzlich ZDR-Anträge oder einen konformen API-Proxy-Dienst wie APIYI (apiyi.com), um die Sicherheit weiter zu erhöhen. Die Schalter entscheiden nur über die "zusätzliche Autorisierung für das Training", nicht über die Überwachung.
Drittens: Nutzen Sie den Selected-Modus für eine "projektbezogene Trennung". Erstellen Sie ein separates Projekt für Dev/Test-Traffic, der geteilt werden darf, und isolieren Sie Ihr Produktionsprojekt mit sensiblen Daten vollständig. So erhalten Sie die kostenlosen Kontingente, ohne dass Nutzerdaten in die Trainings-Pipeline fließen – das ist die effizienteste Strategie.
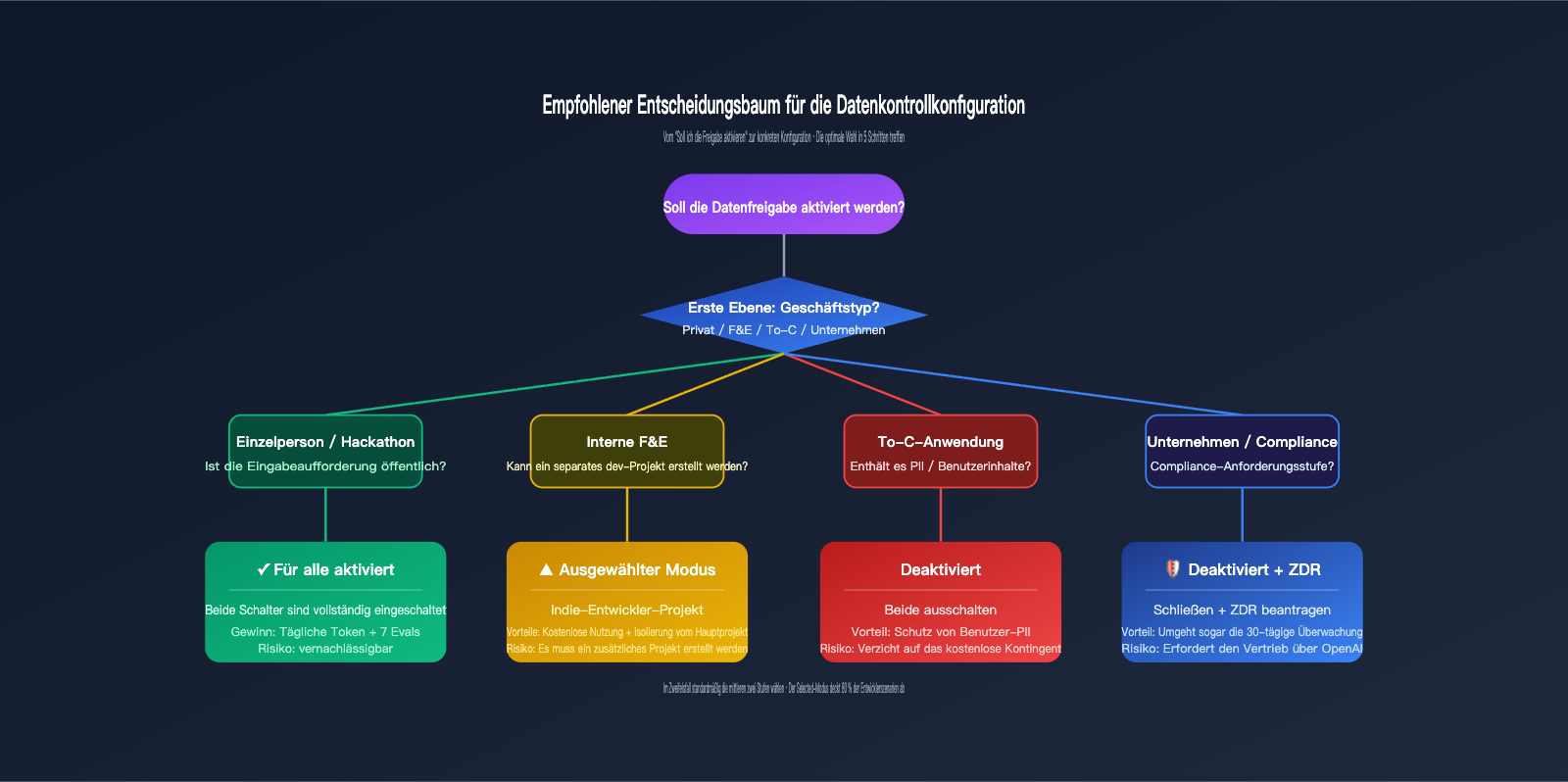
Wenn Sie diese beiden Schalter abwägen, ist der sicherste Weg, die Konfiguration anhand der vier Kategorien "Persönlich / Intern / To-C / Unternehmen" festzulegen. Nutzen Sie dann den Selected-Modus für ein separates Testprojekt, um die kostenlosen Kontingente zu nutzen, während der produktive Traffic über einen API-Proxy-Dienst wie APIYI (apiyi.com) architektonisch isoliert wird. So genießen Sie die Vorteile der OpenAI-Richtlinien, ohne die Privatsphäre Ihrer Nutzerdaten und Ihres geschäftlichen Know-hows zu gefährden.
📌 Autor: APIYI-Technikteam — Wir verfolgen kontinuierlich Änderungen bei OpenAI Data Controls, ZDR und Abrechnungsstrategien, um Entwicklern eine einheitliche, datenschutzkonforme Multi-Modell-API-Gateway-Erfahrung zu bieten. Mehr erfahren unter APIYI (apiyi.com).