Anmerkung des Autors: Das günstigste Modell von OpenAI, gpt-5.4-nano, kostet nur $0,20/$1,25 und erreicht mit 92,5 % im τ2-Bench fast das Niveau von mini. Dieser Artikel erläutert die 7 besten Anwendungsfälle für nano, wann ein Umstieg auf mini sinnvoll ist und wie Sie durch Caching-Optimierungen bis zu 90 % Kosten sparen können.
Wenn Ihre Anwendung täglich mehr als zehntausend Aufrufe verzeichnet oder Sie ein Modell für Aufgaben mit hohem Durchsatz wie Kundensupport, Klassifizierung oder RAG-Routing suchen, ist Ihnen vielleicht aufgefallen, dass OpenAI den „Mindestpreis“ der GPT-5.4-Serie auf ein neues Tief gesenkt hat – gpt-5.4-nano, $0,20 für Eingabe / $1,25 für Ausgabe pro 1 Mio. Token, was die Eingabekosten um das 3,75-fache günstiger macht als bei 5.4-mini.
Dies ist kein bloßes „abgespecktes Billigmodell“. Benchmarks von OpenAI zeigen, dass nano bei Modellaufrufen (τ2-Bench) 92,5 % erreicht und damit fast das Niveau von mini (93,4 %) erreicht. Bei allgemeinen Wissensfragen (GPQA Diamond) liegt es mit 82,8 % nur 5,2 Prozentpunkte hinter mini. Das bedeutet: Für eine Vielzahl von Szenarien mit „hohem Durchsatz und geringer Komplexität“ ist nano die wahre optimale Lösung.
Kernnutzen: Dieser Artikel beleuchtet 7 spezifische Anwendungsfälle, erklärt detailliert, bei welchen Aufgaben nano „ausreichend und günstiger“ ist oder wann „mini zwingend erforderlich“ ist, und liefert für jedes Szenario Code-Snippets sowie Kostenkalkulationen.

Kernpunkte zu den Anwendungsfällen von GPT-5.4 nano
| Punkt | Beschreibung | Wert |
|---|---|---|
| Extrem günstig | $0,20 / $1,25 pro 1 Mio. Token | 3,75x günstiger als 5.4-mini |
| Caching -90 % | Zwischengespeicherte Eingabe nur $0,02 / 1 Mio. | Kontext bei hoher Frequenz fast kostenlos |
| Modellaufruf fast wie mini | τ2-Bench 92,5 % vs. mini 93,4 % | Für die meisten Tool-Use-Szenarien ausreichend |
| Stark bei Wissensfragen | GPQA Diamond 82,8 % | Geeignet für allgemeine FAQs und Wissensabfragen |
| 400K Kontextfenster | 400K Eingabe + 128K Ausgabe | Mühelose Verarbeitung langer Dokumente |
| Führende Geschwindigkeit | ~200 t/s, 10 % schneller als mini | Erste Wahl für Pipelines mit hohem Durchsatz |
Wie bestimmt man den „Ausreichend-Schwellenwert“ für GPT-5.4 nano?
Um zu beurteilen, ob nano ausreicht, kann man eine einfache „Drei-Zonen-Klassifizierung“ verwenden:
Grüne Zone (Sicher nano verwenden): Modellaufruf, strukturierte Extraktion, Klassifizierung, Wissensabfragen, Inhalts-Routing, Batch-Übersetzung/Zusammenfassung – bei diesen Aufgaben liegt der Leistungsunterschied zwischen nano und mini unter 10 Prozentpunkten; der Preisvorteil überwiegt den Leistungsunterschied bei weitem.
Gelbe Zone (Vorsichtige Bewertung): Komplexe mehrstufige Schlussfolgerungen, lange Agenten-Orchestrierung, Codegenerierung – SWE-Bench Pro 52,4 % ist zwar noch leistungsfähig, aber es wird empfohlen, vorab einen A/B-Test mit nano durchzuführen.
Rote Zone (Direkt mini verwenden): Computer Use (nano OSWorld nur 39 %), lange Terminal-Aufgaben (46,3 % schwächer), maßgeschneiderte Szenarien, die ein Fine-tuning erfordern – in diesen Fällen kann nano nicht mithalten; wählen Sie direkt mini oder die Standardversion.

GPT-5.4 nano Anwendungsfall 1: Echtzeit-Klassifizierung
Szenario-Beschreibung
Die Echtzeit-Klassifizierung ist die klassische Anwendung für nano – dazu gehören Sentiment-Analyse, Absichtserkennung, Themenmarkierung, Inhaltsmoderation und mehr. Solche Aufgaben erfordern bei jedem Modellaufruf meist nur wenige hundert Tokens für die Eingabe und einige Dutzend für die Ausgabe, weshalb sie extrem empfindlich gegenüber Latenz und Kosten sind.
Minimalistisches Code-Beispiel
import openai
import json
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def classify_intent(user_query: str) -> dict:
"""Klassifiziert die Absicht der Benutzeranfrage"""
response = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[
{"role": "system", "content": "Du bist ein Absichtsklassifikator. Antworte im JSON-Format: {intent, confidence, sub_category}"},
{"role": "user", "content": user_query}
],
response_format={"type": "json_object"}
)
return json.loads(response.choices[0].message.content)
# Verwendung
result = classify_intent("Ich möchte meine Bestellung von letzter Woche stornieren")
# {"intent": "refund_request", "confidence": 0.95, "sub_category": "subscription_cancel"}
Kostenkalkulation
| Szenario-Größe | Kosten pro Aufruf | Tageskosten (100.000 Aufrufe) |
|---|---|---|
| Einstiegs-Support(50 Input + 20 Output) | $0,000035 | $3,5 |
| Mittelständische SaaS(200 Input + 30 Output) | $0,000078 | $7,8 |
| Enterprise-Level(500 Input + 50 Output) | $0,000163 | $16,3 |
💡 Optimierungstipp: Platzieren Sie Klassifizierungs-Labels und Beispiele in der System-Eingabeaufforderung. Nach Aktivierung des Cachings können die Eingabekosten um weitere 90 % gesenkt werden. Bei der Nutzung über APIYI (apiyi.com) werden die Caching-Rabatte vollständig synchronisiert.
GPT-5.4 nano Anwendungsfall 2: Datenextraktion
Szenario-Beschreibung
Strukturierte Felder aus unstrukturierten Texten (Lebensläufe, Verträge, Nachrichten, E-Mails) extrahieren. Dies ist eine Stärke von nano – in Kombination mit Structured Outputs (starke JSON-Schema-Einschränkungen) kann eine Formatgenauigkeit von über 99 % erreicht werden.
Praxis-Code
from pydantic import BaseModel
from typing import Optional
class ContactInfo(BaseModel):
name: str
email: Optional[str]
phone: Optional[str]
company: Optional[str]
role: Optional[str]
def extract_contact(text: str) -> ContactInfo:
response = client.beta.chat.completions.parse(
model="gpt-5.4-nano",
messages=[
{"role": "system", "content": "Extrahiere Kontaktinformationen, gib bei fehlenden Feldern null zurück"},
{"role": "user", "content": text}
],
response_format=ContactInfo
)
return response.choices[0].message.parsed
Liste der für nano geeigneten Extraktionsaufgaben
- Extraktion wichtiger Felder aus Lebensläufen/CVs
- Ziffernerkennung bei Rechnungen/Quittungen
- Analyse von E-Mail-Signaturblöcken
- Erkennung von Entitäten in Nachrichten (Personennamen, Orte, Organisationen)
- Normalisierung von Formulardaten
- Kategorisierung von Log-Ereignissen
GPT-5.4 nano Anwendungsfall 3: Inhalts-Ranking
Szenario-Beschreibung
Neusortierung von Suchergebnissen, Empfehlungslisten und Nachrichtenwarteschlangen. Dank der niedrigen Kosten von nano wird der Einsatz eines LLM als „Reranker“ in Produktionsumgebungen wirtschaftlich machbar.
Code-Beispiel für das Reranking
def rerank_documents(query: str, candidates: list[str], top_k: int = 5) -> list:
"""Neusortierung von Kandidatendokumenten basierend auf der Relevanz zur Anfrage"""
docs_text = "\n".join([f"[{i}] {doc[:300]}" for i, doc in enumerate(candidates)])
response = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[{
"role": "user",
"content": f"""Sortiere die folgenden Dokumente basierend auf der Anfrage "{query}" nach ihrer Relevanz.
Dokumente:
{docs_text}
Rückgabe als JSON: {{"ranking": [Liste der Dokumentenindizes, vom relevantesten zum am wenigsten relevanten]}}"""
}],
response_format={"type": "json_object"}
)
ranking = json.loads(response.choices[0].message.content)["ranking"]
return [candidates[i] for i in ranking[:top_k]]
🎯 Empfehlung für das Szenario: Das Reranking mit nano ist präziser als herkömmliche Reranker auf Basis von BM25 + Vektorsuche, kostet jedoch nur 27 % im Vergleich zu GPT-5.4-mini. Der Zugriff erfolgt direkt über APIYI (apiyi.com), wobei die Standardgruppe ohne vorherige Beantragung genutzt werden kann.
GPT-5.4 nano Anwendungsfall 4: Sub-Agent-Ausführungsebene
Szenario-Beschreibung
In Multi-Agenten-Architekturen übernimmt der Haupt-Agent (meist mini oder die Standardversion) die Planung, während der Sub-Agent (der ausführende Worker) für spezifische Werkzeugaufrufe, Datenabfragen und Statusaktualisierungen zuständig ist. Mit einem Score von 92,5 % auf dem τ2-Bench ist nano für die Rolle als Worker bestens geeignet.
Beispiel für Multi-Agenten-Zusammenarbeit
def execute_subtask(task: dict, available_tools: list) -> dict:
"""nano fungiert als Sub-Agent zur Ausführung einer einzelnen Teilaufgabe"""
response = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[
{"role": "system", "content": f"Du bist ein ausführender Worker. Verfügbare Werkzeuge: {available_tools}"},
{"role": "user", "content": f"Führe die Aufgabe aus: {task['description']}"}
],
tools=task.get("tools", []),
tool_choice="auto"
)
return {
"task_id": task["id"],
"result": response.choices[0].message.content,
"tool_calls": response.choices[0].message.tool_calls
}
# Haupt-Agent nutzt mini, Sub-Agent nutzt nano – Kosteneinsparung von über 60 %
GPT-5.4 nano Anwendungsfall 5: RAG-Routing-Ebene
Szenariobeschreibung
In einem RAG-System fungiert das nano-Modell als „Routing-Ebene“, die den Abfragetyp bestimmt (technische Frage / Vorverkaufsberatung / Produktfeedback / Smalltalk) und diesen an den entsprechenden Prozessor weiterleitet. Dieses Design stellt sicher, dass die teureren mini- oder Standard-Modelle nur dann aufgerufen werden, wenn sie wirklich benötigt werden.
RAG-Routing-Beispiel
def route_query(query: str) -> str:
"""nano bestimmt, an welchen RAG-Prozessor die Anfrage weitergeleitet wird"""
response = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[
{"role": "system", "content": """Geben Sie basierend auf dem Abfragetyp das Routing-Label zurück:
- "technical_docs": Abfrage technischer Dokumentationen
- "product_faq": Produkt-FAQ
- "code_help": Code-Hilfe
- "small_talk": Smalltalk (kein RAG erforderlich)
- "complex_reasoning": Komplexe Schlussfolgerungen (Weiterleitung an mini/Standard-Modell)"""},
{"role": "user", "content": query}
],
max_tokens=20
)
return response.choices[0].message.content.strip()
route = route_query(user_input)
if route == "complex_reasoning":
final_model = "gpt-5.4-mini" # Upgrade auf mini
else:
final_model = "gpt-5.4-nano" # Weiterhin nano verwenden
💰 Kostenoptimierung: Diese Architektur aus „nano-Routing + mini/Standard-Verarbeitung“ senkt die Gesamtkosten für Modellaufrufe in der Regel um 60–80 %. Über APIYI (apiyi.com) können Sie unter demselben API-Schlüssel flexibel zwischen den beiden Modellen wechseln, indem Sie einfach den Parameter
modelanpassen.
GPT-5.4 nano Anwendungsfall 6: Zusammenfassung und Übersetzung mit hohem Durchsatz
Szenariobeschreibung
Die stapelweise Verarbeitung von Nachrichtenzusammenfassungen, Dokumentenübersetzungen, Kommentarüberarbeitungen und ähnlichen Aufgaben. In Kombination mit einem 400K-Kontextfenster kann nano ganze lange Texte in einem Durchgang verarbeiten, wobei die Kosten pro Einheit nahezu vernachlässigbar sind.
Batch-API-Beispiel
# Batch-Aufgaben vorbereiten
batch_requests = []
for doc_id, content in documents.items():
batch_requests.append({
"custom_id": f"summary-{doc_id}",
"method": "POST",
"url": "/v1/chat/completions",
"body": {
"model": "gpt-5.4-nano",
"messages": [
{"role": "system", "content": "Fassen Sie den folgenden Inhalt in 100 Wörtern zusammen"},
{"role": "user", "content": content}
],
"max_tokens": 200
}
})
# Batch-API übermitteln (gleicher Preis, belegt jedoch kein Online-Kontingent)
batch = client.batches.create(
input_file_id=file_id,
endpoint="/v1/chat/completions",
completion_window="24h"
)
GPT-5.4 nano Anwendungsszenario 7: Tool Use (Werkzeugnutzung)
Szenariobeschreibung
Auf dem τ2-Bench erreicht das nano-Modell 92,5 % und liegt damit fast gleichauf mit dem mini-Modell bei 93,4 %. Für standardisierte Function-Calling-Szenarien wie „Wetter abfragen“, „Bestellungen prüfen“ oder „Dokumente durchsuchen“ ist das nano-Modell absolut leistungsfähig.
Beispiel für Function Calling
tools = [{
"type": "function",
"function": {
"name": "get_order_status",
"description": "Status einer Bestellung abfragen",
"parameters": {
"type": "object",
"properties": {
"order_id": {"type": "string"}
},
"required": ["order_id"]
}
}
}]
response = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[{"role": "user", "content": "Wie ist der Status meiner Bestellung #12345?"}],
tools=tools,
tool_choice="auto"
)
# nano erkennt präzise, dass get_order_status aufgerufen werden muss, und extrahiert order_id="12345"
Detaillierte Preisübersicht für GPT-5.4 nano
Offizielle Preisstruktur
| Abrechnungsart | Preis (pro 1 Mio. Token) | Erläuterung |
|---|---|---|
| Eingabe | $0,20 | Standardpreis |
| Gecachte Eingabe | $0,02 | 90 % Rabatt |
| Ausgabe | $1,25 | Inklusive Reasoning-Token |
| Batch API | $0,20 / $1,25 | Gleicher Preis, belegt kein Online-Kontingent |
| Regionale Datenhaltung | +10 % | Für Szenarien mit Daten-Compliance |
Preisvergleich: nano vs. mini
| Dimension | gpt-5.4-nano | gpt-5.4-mini | Faktor |
|---|---|---|---|
| Eingabe | $0,20 | $0,75 | nano ist 3,75x günstiger |
| Gecachte Eingabe | $0,02 | $0,075 | nano ist 3,75x günstiger |
| Ausgabe | $1,25 | $4,50 | nano ist 3,6x günstiger |
| Reaktionszeit | ~200 t/s | ~180 t/s | nano ist ca. 10 % schneller |
| Kontextfenster | 400K | 400K | Gleichstand |
| Maximale Ausgabe | 128K | 128K | Gleichstand |
💰 Kostenoptimierung: Bei Szenarien mit hohem Durchsatz von Millionen Anfragen pro Tag kann sich die Preisdifferenz zwischen nano und mini auf mehrere tausend US-Dollar pro Monat summieren. Durch die Anbindung über APIYI (apiyi.com) erhalten Sie zudem 10 % Bonus bei einer Aufladung von 100 US-Dollar, was effektiv 15 % Rabatt gegenüber den offiziellen Preisen entspricht. Die Gesamtkosten können somit bis zu 25 % niedriger ausfallen als bei der direkten Nutzung.
Hier ist der umfassende Vergleich zwischen GPT-5.4 nano und mini.
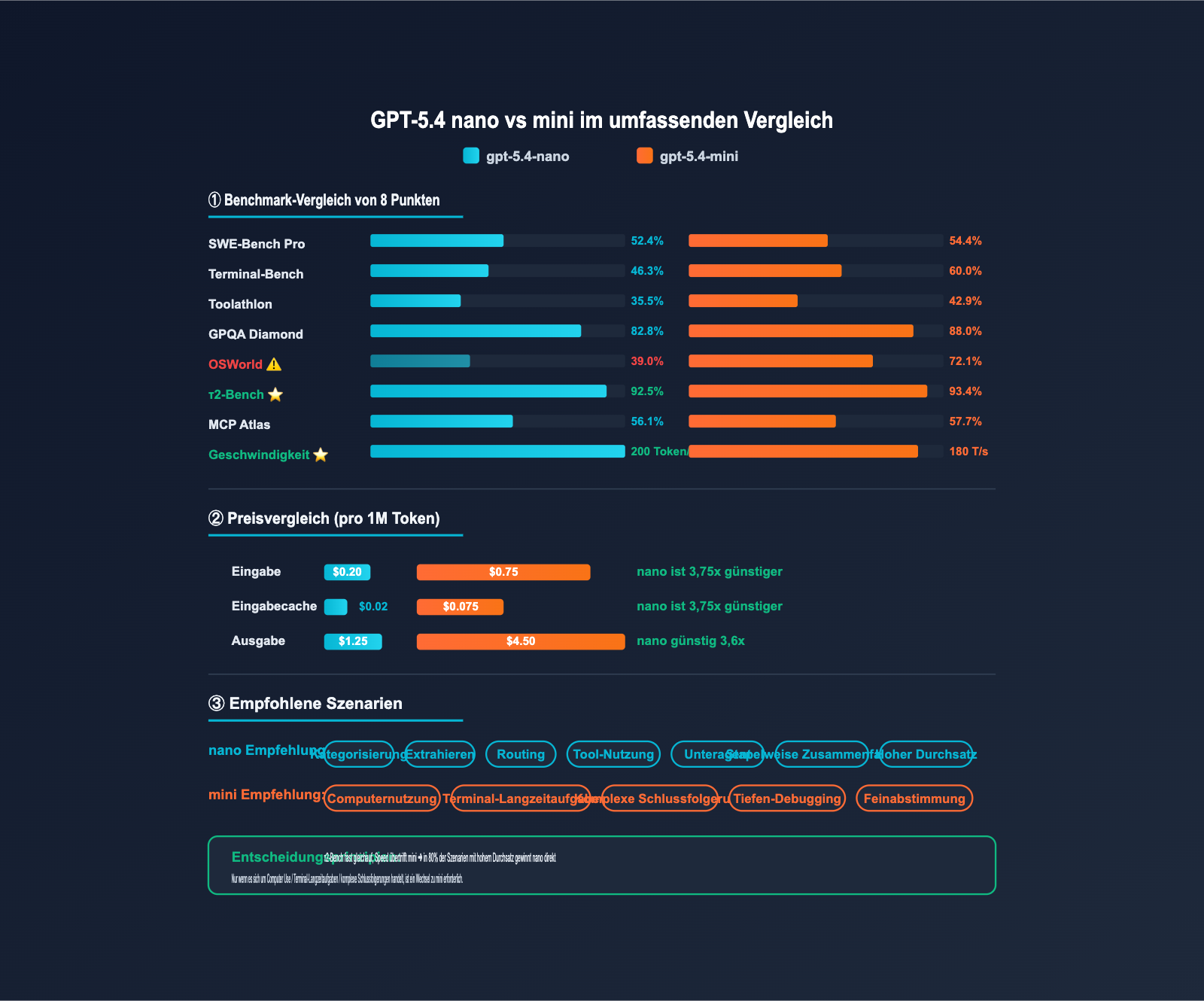
| Bewertungsdimension | gpt-5.4-nano | gpt-5.4-mini | Differenz | Ist nano ausreichend? |
|---|---|---|---|---|
| SWE-Bench Pro | 52,4% | 54,4% | -2,0pp | ✅ Fast gleichauf |
| Terminal-Bench 2.0 | 46,3% | 60,0% | -13,7pp | ⚠️ Für lange Aufgaben mini nutzen |
| Toolathlon | 35,5% | 42,9% | -7,4pp | ✅ Für Standardaufgaben okay |
| GPQA Diamond | 82,8% | 88,0% | -5,2pp | ✅ Für Wissensfragen geeignet |
| OSWorld-Verified | 39,0% | 72,1% | -33,1pp | ❌ Computer Use erfordert mini |
| τ2-Bench (Tool Use) | 92,5% | 93,4% | -0,9pp | ✅ Fast gleichauf |
| MCP Atlas | 56,1% | 57,7% | -1,6pp | ✅ Fast gleichauf |
| Reaktionszeit | ~200 t/s | ~180 t/s | +10% | ✅ nano ist sogar schneller |
Empfehlungen zur Modellauswahl
Wann Sie bevorzugt nano einsetzen sollten:
- Aufgaben im "grünen Bereich" (Klassifizierung, Extraktion, Sortierung, Routing, Tool Use, Batch-Verarbeitung)
- Hohes Aufrufvolumen (> 10.000 Anfragen/Tag), hohe Kostensensibilität
- Notwendigkeit einer Latenz von < 1 Sekunde
- Sub-Agent-Ausführungsschicht (Haupt-Agent nutzt mini, Worker nutzt nano)
Wann Sie auf mini upgraden sollten:
- Bei Aufgaben mit Computer Use (entscheidender Vorsprung laut OSWorld)
- Lange Terminal-Aufgaben (> 10 Schritte)
- Bedarf an komplexem, mehrstufigem Reasoning oder tiefgreifendem Debugging von Code
- Wenn die Aufgabenqualität wichtiger ist als die Kosten
📊 Entscheidungshilfe: In 80% der Szenarien mit "hohem Durchsatz bei geringer Komplexität" ist das Preis-Leistungs-Verhältnis von nano dem von mini weit überlegen. Über den API-Proxy-Dienst APIYI (apiyi.com) können Sie die Leistung beider Modelle direkt für Ihre spezifischen Aufgaben vergleichen, indem Sie einfach den
model-Parameter anpassen.
Einbindung von GPT-5.4 nano über APIYI
Sofort verfügbar in der Default-Gruppe
Die APIYI-Plattform verfolgt für GPT-5.4 nano und 5.4-mini die gleiche Öffnungsstrategie:
- ✅ Default-Gruppe: Vollständig geöffnet, für neue Benutzer sofort nach der Registrierung verfügbar.
- ✅ SVIP-Gruppe: Vollständig geöffnet, ohne jegliche Einschränkungen.
- ✅ Cache-Rabatte synchronisiert: Der Cache-Preis von $0,02/1M Tokens gilt vollständig.
- ✅ Batch API synchronisiert: Batch-Aufgaben profitieren von denselben Konditionen.
Kostenvergleich: APIYI vs. offizielle Webseite
| Projekt | OpenAI Webseite | APIYI apiyi.com |
|---|---|---|
| Basispreis | $0,20 / $1,25 pro 1M | $0,20 / $1,25 pro 1M (identisch) |
| Cache-Rabatt | $0,02 / 1M (90%) | $0,02 / 1M (vollständig synchron) |
| Aufladebonus | Keiner | $100 aufladen, $10 geschenkt (10%) |
| Tatsächliche Kosten | 100% Standardpreis | ca. 90% Standardpreis (ca. 15% Rabatt) |
| Zugriff aus China | VPN erforderlich | Direktzugriff, kein VPN nötig |
| Zahlungsmethoden | Internationale Kreditkarte | RMB, Alipay, WeChat Pay |
| SDK-Kompatibilität | OpenAI nativ | Vollständig kompatibel mit OpenAI SDK |
| Mindestaufladung | $5 | Ab $1 möglich |
💰 Kostenoptimierung: Bei Anwendungen mit einem monatlichen Volumen von über einer Million Aufrufen können Sie durch die Einbindung von nano über APIYI apiyi.com in Kombination mit Cache-Optimierungen die Gesamtkosten um 25-35 % gegenüber dem direkten Aufruf über die OpenAI-Webseite senken.
Häufig gestellte Fragen (FAQ)
Q1: Was ist gpt-5.4-nano? Wo liegen die Hauptunterschiede zu gpt-5.4-mini?
GPT-5.4-nano ist das günstigste und schnellste Leichtgewichtsmodell der OpenAI GPT-5.4-Serie ($0,20/$1,25 pro 1M Tokens) mit einer Reaktionsgeschwindigkeit von ca. 200 t/s. Die Kernunterschiede zu 5.4-mini: 1) Preis ist 3,6- bis 3,75-mal günstiger; 2) Computer Use (OSWorld 39 % vs. 72,1 %) und Terminal-Langzeitaufgaben (46,3 % vs. 60 %) sind deutlich schwächer; 3) In anderen Szenarien (Klassifizierung, Extraktion, Tool Use, Wissensfragen) liegt der Leistungsunterschied meist unter 10 Prozentpunkten.
Q2: Für welche Anwendungsszenarien ist nano am besten geeignet? Wann muss mini verwendet werden?
Geeignet für nano (Grüner Bereich):
- Echtzeit-Klassifizierung (Stimmung, Absicht, Thema)
- Strukturierte Datenextraktion
- Inhaltsranking und -neuordnung
- Sub-Agent-Ausführungsebene
- RAG-Routing-Ebene
- Hochdurchsatz-Zusammenfassungen/Übersetzungen
- Standardisierte Werkzeugaufrufe (τ2-Bench 92,5 %)
Szenarien, die mini erfordern (Roter Bereich):
- Computer Use Desktop-Automatisierung (OSWorld-Differenz 33 Prozentpunkte)
- Terminal-Langzeitaufgaben (>10 Schritte)
- Komplexe mehrstufige Schlussfolgerungen
- Kundenspezifische Szenarien, die Fine-tuning erfordern
Q3: Warum wird nano nicht für Computer Use empfohlen?
In der OSWorld-Verified-Bewertung erreicht nano nur 39,0 %, was weit unter den 72,1 % von mini liegt. Das bedeutet, dass die Fehlerrate bei mehrstufigen Desktop-Operationen (Browser öffnen → suchen → klicken → Formular ausfüllen) zu hoch ist, um Aufgabenketten stabil abzuschließen. Wenn Ihr Szenario Computer Use erfordert, sollten Sie direkt mini oder die Standardversion 5.4 wählen.
Q4: Wie wird der Cache-Rabatt von $0,02/1M für nano aktiviert?
Der OpenAI-Cache-Mechanismus wird automatisch ausgelöst und erfordert keine zusätzlichen Parameter. Wenn das Prompt-Präfix (normalerweise System-Prompt + geteilter Kontext) mit den Anfragen der letzten 5-10 Minuten übereinstimmt, wird der Cache automatisch genutzt und der 90%-Rabatt angewendet.
Optimierungstipps:
- System-Prompt an den Anfang des messages-Arrays setzen.
- Geteilten Kontext (Klassifizierungs-Tags, Schema-Definitionen) direkt danach platzieren.
- Die eigentliche Benutzeranfrage ganz ans Ende stellen.
- Aufrufhäufigkeit beibehalten (nach >5 Minuten läuft der Cache ab).
Bei Aufrufen über APIYI apiyi.com ist der Cache-Rabatt vollständig mit der Webseite synchronisiert.
Q5: Was sind die Best Practices für die Verarbeitung von Batch-Aufgaben mit nano?
Drei Schlüsselstrategien:
- Batch API verwenden: Nutzen Sie das
/v1/batches-Interface für die Übermittlung von Batch-Aufgaben. Diese werden innerhalb von 24 Stunden abgeschlossen, kosten das Gleiche, belegen aber kein Online-RPM-Kontingent. - Geteilten System-Prompt nutzen: Verwenden Sie für alle Aufgaben dieselben Anweisungen, um Cache-Treffer auszulösen.
- Angemessene max_tokens einstellen: Die Ausgabe von nano ist zwar günstig, summiert sich aber. Setzen Sie je nach Aufgabe ein vernünftiges Limit von 50-500 Tokens.
Durch das Einreichen von Batch-Aufgaben über APIYI apiyi.com profitieren Sie vom 10%-Aufladebonus, was die tatsächlichen Kosten auf etwa 85 % des offiziellen Preises senkt.
Q6: Wie rufe ich GPT-5.4 nano über APIYI auf?
APIYI ist vollständig mit dem OpenAI SDK kompatibel. Es sind nur drei Schritte erforderlich:
- Besuchen Sie APIYI apiyi.com und registrieren Sie ein Konto (keine Bewerbung nötig, Default-Gruppe ist sofort verfügbar).
- API-Schlüssel abrufen.
- Ändern Sie die
base_urlim Code aufhttps://vip.apiyi.com/v1und setzen Sie das Modell aufgpt-5.4-nano.
client = openai.OpenAI(
api_key="IHR_SCHLUESSEL",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[...]
)
Bei einer Aufladung von 100 USD erhalten Sie 10 % Bonus, was einem effektiven Preis von ca. 85 % des offiziellen Preises entspricht; Cache-Rabatte sind synchron.
Q7: Wann ist nano wirtschaftlicher als mini? Wie berechnet man das?
Berechnungsformel:
nano lohnt sich, wenn = (Toleranz für Qualitätsverlust) × (Aufrufvolumen) × (Preisdifferenz)
> (Qualitätsgewinn durch Upgrade auf mini)
Praktische Szenarien:
- Aufrufvolumen > 10K/Tag: Ersparnis > $30/Tag ($1000/Monat)
- Aufrufvolumen > 100K/Tag: Ersparnis > $300/Tag ($9000/Monat)
- Aufrufvolumen > 1M/Tag: Ersparnis > $3000/Tag ($90000/Monat)
Für Aufgaben im grünen Bereich (Klassifizierung, Extraktion, Tool Use) liegt der Qualitätsverlust von nano meist unter 5 %, während die Kosten um 73 % sinken (bei reiner Berechnung des 3,6-fachen Faktors). Der ROI fällt fast immer zugunsten von nano aus.
Q8: Welche bekannten Einschränkungen hat GPT-5.4 nano?
Wichtigste Einschränkungen:
- Kein Computer Use: Mit 39 % OSWorld-Score zu niedrig für stabile Desktop-Automatisierung.
- Kein Fine-tuning: Kann nicht mit eigenen Datensätzen feinabgestimmt werden.
- Keine Audio-/Videoeingabe: Nur Text- und Bildeingabe möglich.
- Schwäche bei Terminal-Langzeitaufgaben: Terminal-Bench 46,3 %; Operationen mit mehr als 10 Schritten schlagen häufig fehl.
- Begrenzte komplexe Schlussfolgerungsfähigkeit: GPQA 82,8 % liegt nahe an mini, aber bei extrem schwierigen Aufgaben wie FrontierMath ist ein deutlicher Leistungsabfall zu verzeichnen.
Alternative: Bei diesen Einschränkungen direkt auf gpt-5.4-mini oder die Standardversion 5.4 umsteigen.
GPT-5.4 nano Anwendungsszenarien: Die wichtigsten Erkenntnisse
- Preis-Untergrenze: $0,20/$1,25 pro 1 Mio. Token, 3,6- bis 3,75-mal günstiger als 5.4-mini
- 90 % Cache-Rabatt: Eingabe ab $0,02/1 Mio. Token, nahezu kostenlos bei Szenarien mit häufigem Kontext
- 7 „Grüne“ Einsatzbereiche: Klassifizierung, Extraktion, Sortierung, Sub-Agent, Routing, Stapelverarbeitung, Tool-Nutzung
- τ2-Bench 92,5 %: Tool-Aufrufe fast auf Augenhöhe mit mini; ausreichend für über 90 % der Function-Calling-Szenarien
- GPQA 82,8 %: Starke allgemeine Wissensabfrage, ideal für FAQs und Inhaltsmoderation
- Geschwindigkeit 200 t/s: 10 % schneller als mini, die erste Wahl für Pipelines mit hohem Durchsatz
- „Rote“ Warnung: Bei Computer Use oder langen Terminal-Aufgaben muss zwingend auf mini gewechselt werden
Zusammenfassung
Die wichtigsten Punkte zu den Anwendungsszenarien von GPT-5.4 nano:
- Positionierung: nano ist die optimale Wahl für Aufgaben mit hohem Durchsatz und geringer Komplexität – Echtzeit-Klassifizierung, Datenextraktion, Sub-Agent-Worker, RAG-Routing und Stapelverarbeitung sind sein Haupteinsatzgebiet.
- Leistungsgrenzen: Bei τ2-Bench, GPQA und SWE-Bench Pro liegt es fast gleichauf mit mini, zeigt jedoch deutliche Schwächen bei Computer Use oder langen Terminal-Aufgaben.
- Zugang: Direkter Aufruf über die APIYI (apiyi.com) Default-Gruppe, Cache-Rabatte inklusive, 10 % Bonus bei Aufladung ab 100.
GPT-5.4 nano ist kein „Billigprodukt, das alles kann, aber nichts richtig“, sondern eine von OpenAI präzise optimierte Leichtgewicht-Waffe für Szenarien mit hohem Durchsatz und geringer Komplexität. Wenn Ihre Anwendung in die sieben genannten „grünen“ Bereiche fällt, ist nano fast immer kosteneffizienter als mini. Bei Computer Use oder langen Terminal-Aufgaben ist jedoch der Wechsel zu mini die richtige Entscheidung.
Wir empfehlen den schnellen Zugriff auf GPT-5.4 nano über die Plattform APIYI (apiyi.com): Die Default-Gruppe erfordert keine gesonderte Beantragung, Cache-Rabatte werden vollständig übernommen, Sie erhalten 10 % Bonus bei Aufladungen und profitieren von einer stabilen Direktverbindung aus dem Inland.
Weiterführende Artikel
Wenn Sie sich für die GPT-5.4 nano API interessieren, empfehlen wir Ihnen folgende Lektüre:
- 📘 GPT-5.4 mini API Upgrade-Leitfaden – Erfahren Sie mehr über die Fähigkeiten und Einsatzszenarien des mini-Modells.
- 📊 Deep Dive in den OpenAI-Caching-Mechanismus: Best Practices für 90 % Rabatt – Meistern Sie technische Kniffe zur Cache-Optimierung.
- 🚀 Praxisleitfaden: Aufbau einer RAG-Routing-Ebene mit GPT-5.4 nano – Entdecken Sie die hybride Architektur aus "nano-Routing + mini-Verarbeitung".
📚 Referenzen
-
Offizielle OpenAI GPT-5.4 nano Dokumentation: Modellspezifikationen, Preisgestaltung, Aufrufbeispiele
- Link:
developers.openai.com/api/docs/models/gpt-5.4-nano - Hinweis: Hier erhalten Sie die aktuellsten und verbindlichsten technischen Parameter.
- Link:
-
AI Cost Check Benchmark-Analyse: Umfassender Vergleich zwischen nano und mini
- Link:
aicostcheck.com/blog/gpt-5-4-mini-nano-pricing-benchmarks - Hinweis: Unabhängige Bewertung, ideal für den direkten Leistungsvergleich.
- Link:
-
APIYI GPT-5.4 nano Integrationsdokumentation: Lösungen für den Zugriff aus China, Gruppierungshinweise, Auflade-Rabatte
- Link:
docs.apiyi.com - Hinweis: Praktischer Leitfaden für Entwickler zur Implementierung.
- Link:
-
OpenAI Preisübersicht: Vollständige Preisliste und Erläuterung der Caching-Mechanismen
- Link:
developers.openai.com/api/docs/pricing - Hinweis: Aktuelle Abrechnungsstandards für alle Modelle.
- Link:
Autor: APIYI Technik-Team
Technischer Austausch: Diskutieren Sie gerne in den Kommentaren über Ihre Erfahrungen mit GPT-5.4 nano. Weitere Informationen zur Modellanbindung finden Sie im APIYI-Dokumentationszentrum unter docs.apiyi.com.