Am 24.04.2026 hat DeepSeek zeitgleich die Modelle V4-Pro und V4-Flash veröffentlicht. Während das Flash-Modell als preiswerte „Hauptsache es funktioniert“-Lösung für ein exzellentes Preis-Leistungs-Verhältnis steht, ist das V4-Pro ein völlig anderes Kaliber:
Es ist das Open-Source-Modell mit der derzeit stärksten Coding-Leistung.
Das ist keine bloße Untertreibung im Sinne von „stark für ein Open-Source-Modell“, sondern ein echter Champion, der bei den harten Fakten GPT-5.4 / Claude Opus 4.6 / Gemini 3.1-Pro direkt in den Schatten stellt:
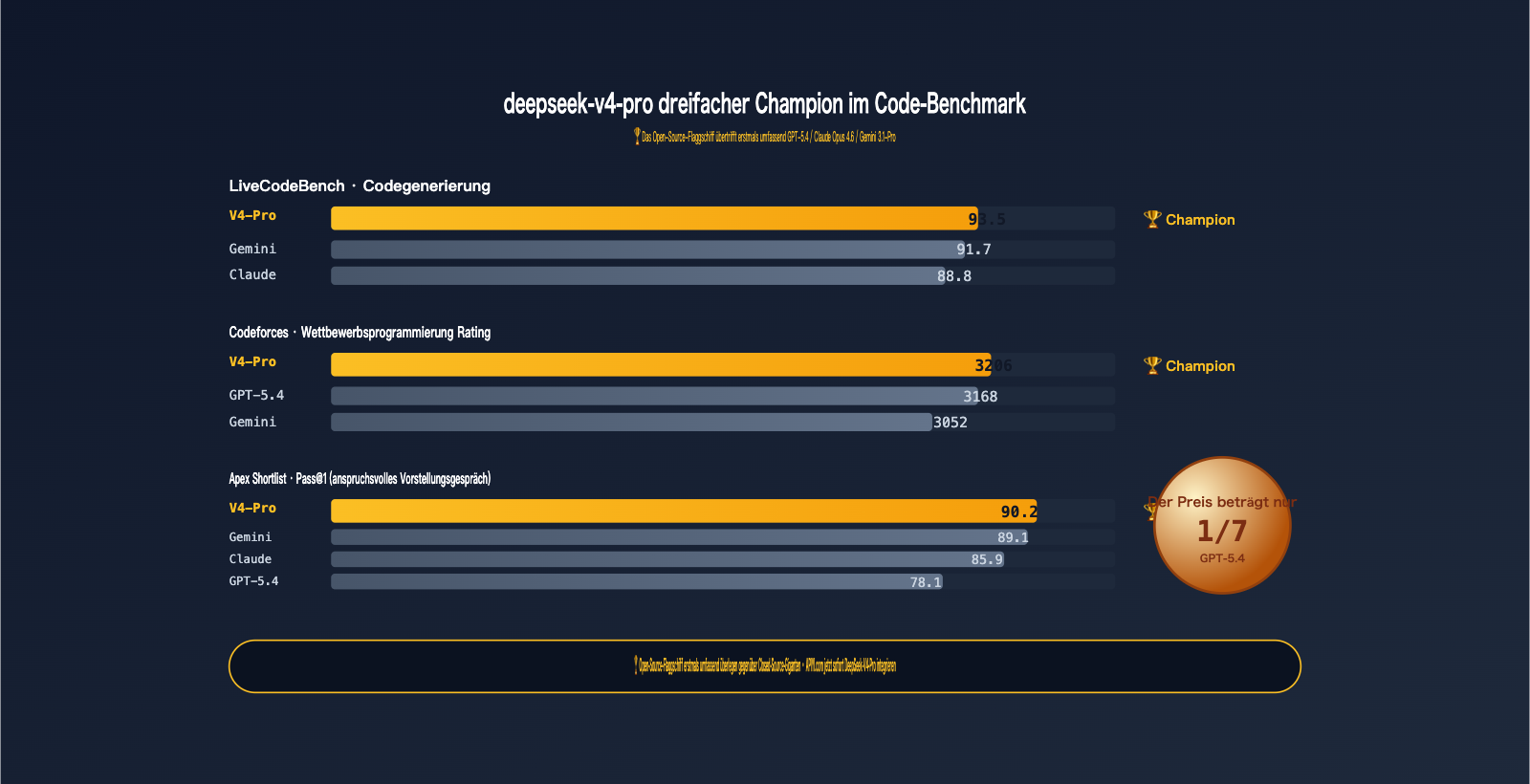
- LiveCodeBench 93,5 — Platz 1, vor Gemini 3.1-Pro (91,7) und Claude Opus 4.6 (88,8)
- Codeforces Rating 3206 — Übertrifft GPT-5.4 (3168) und Gemini 3.1-Pro (3052)
- Apex Shortlist Pass@1 90,2 — Deutlicher Vorsprung vor GPT-5.4 (78,1) und Claude (85,9)
- IMOAnswerBench 89,8 — Lässt Claude Opus 4.6 (75,3) bei mathematischen Wettbewerbsaufgaben mit satten 14 Punkten Vorsprung hinter sich
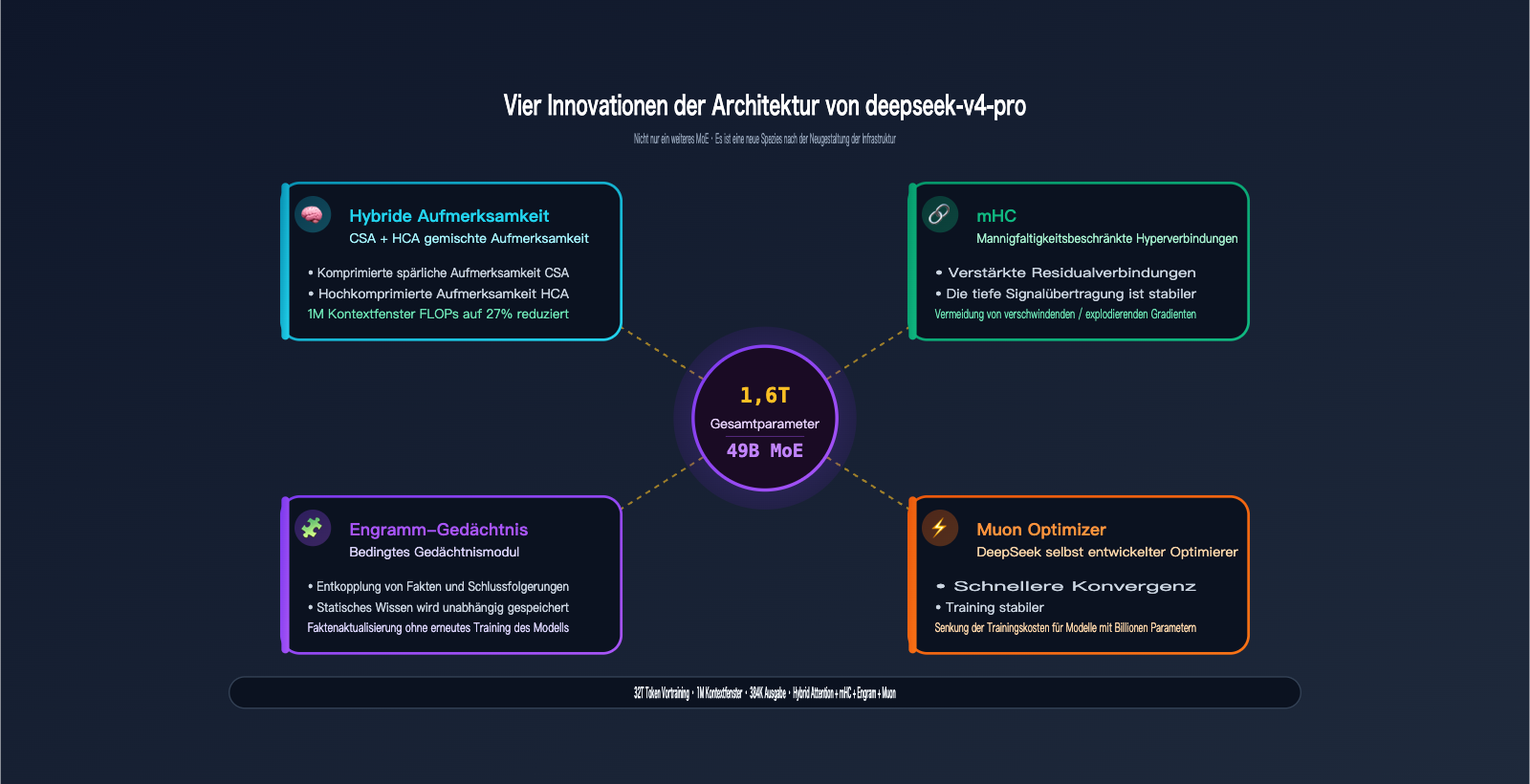
Die technischen Spezifikationen: 1,6T Gesamtparameter / 49B aktiv / 32T Tokens Vortraining / 1M Kontextfenster / 384K Output, ergänzt durch die vier architektonischen Innovationen, die DeepSeek speziell für die V4-Serie entwickelt hat: Hybrid Attention, Manifold-Constrained Hyper-Connections (mHC), Engram Conditional Memory und den Muon Optimizer.
deepseek-v4-pro ist ab sofort auf APIYI (apiyi.com) verfügbar. Sie können es ohne Code-Anpassungen über das OpenAI- oder Anthropic-Protokoll-SDK einbinden – zu einem Preis, der nur ein Siebtel von GPT-5.4 beträgt.
In diesem Artikel wiederholen wir nicht die Grundlagen zur Migration oder Modellauswahl, die bereits im Flash-Beitrag behandelt wurden – dies ist eine Analyse für echte Technik-Enthusiasten, die das volle Potenzial des deepseek-v4-pro ausschöpfen wollen:
- In 3 Minuten verstehen, warum das Pro-Modell den Titel „Flaggschiff“ verdient (Architektur + Daten + Skalierung)
- 4 Benchmark-Vergleichstabellen, die zeigen, wo das Pro-Modell dominiert und wo es sich behaupten muss
- 5 Minuten Integration + 2 Praxisbeispiele für Coding- und Mathematik-Szenarien
I. Die vier Flaggschiff-Fähigkeiten von deepseek-v4-pro
1.1 Übersicht der Kernspezifikationen
| Dimension | deepseek-v4-pro |
|---|---|
| Veröffentlichungsdatum | 24.04.2026 (Vorschauversion) |
| Open-Source-Repository | huggingface.co/deepseek-ai/DeepSeek-V4-Pro |
| Gesamtparameter | 1,6T (Mixture of Experts) |
| Aktivierte Parameter | 49B |
| Pre-Training-Daten | > 32T Tokens |
| Kontextfenster | 1M Tokens |
| Maximale Ausgabe | 384K Tokens |
| Architektur-Innovation | Hybrid Attention + mHC + Engram Memory + Muon |
| Inferenzmodus | Thinking / Non-Thinking Dual-Modus |
| Function Calling | ✅ Unterstützt |
| JSON-Modus | ✅ Unterstützt |
| API-Protokoll | OpenAI + Anthropic dual kompatibel |
| Eingabepreis | $1,74 / M Tokens |
| Ausgabepreis | $3,48 / M Tokens |
Merken Sie sich die vier wichtigsten Zahlen: 1,6T / 49B / 32T / 1M – das ist das Fundament dieses Flaggschiffs.
1.2 1,6T / 49B MoE: Die "Open-Source-Obergrenze" bei der Skalierung
DeepSeek-V4-Pro verfügt über insgesamt 1,6 Billionen Parameter und nutzt eine Mixture-of-Experts-Architektur, bei der pro Token nur 49B Parameter aktiviert werden. Die Bedeutung dieser Zahlen:
| Modell | Gesamtparameter | Aktivierte Parameter | Typ |
|---|---|---|---|
| Llama 3 70B | 70B | 70B | Dense (voll aktiviert) |
| Mistral Large 2 | 123B | 123B | Dense |
| DeepSeek-V3.2 | 671B | 37B | MoE |
| DeepSeek-V4-Pro | 1,6T | 49B | MoE ⭐ |
| Claude Opus 4.6 | Nicht öffentlich | Nicht öffentlich | Closed Source |
Die 1,6T Gesamtparameter verleihen dem Modell ein Wissensspektrum auf dem Niveau von GPT-5.4 / Claude Opus, während die 49B aktivierten Parameter die Inferenzkosten pro Token kontrollierbar halten – das ist der Grund, warum die MoE-Architektur Spitzenleistung erbringen kann.
1.3 32T Tokens Pre-Training: Datenmenge am Limit
Pre-Training-Daten > 32T Tokens
Dies ist eine beeindruckende Zahl:
- GPT-4 Pre-Training-Datenmenge ca. 13T Tokens (branchenweit geschätzt)
- Llama 3 15T Tokens
- DeepSeek-V3 14,8T Tokens
- DeepSeek-V4-Pro: >32T Tokens ⭐
Der direkte Vorteil der verdoppelten Datenmenge ist: umfassendere Abdeckung von Long-Tail-Wissen, aktuellere Code-Korpora und tiefere mathematische Aufgabensammlungen – das ist auch der Grund, warum V4-Pro bei LiveCodeBench und IMOAnswerBench die Bestenlisten anführt.
1.4 Vier Architektur-Innovationen: Der echte Burggraben von Pro
Dies ist der entscheidende Punkt, der V4-Pro von "einem weiteren MoE-Modell" abhebt. Die offiziell vorgestellten vier Kerninnovationen:
| Innovation | Vollständiger Name | Gelöstes Problem |
|---|---|---|
| Hybrid Attention | CSA + HCA Hybrid Attention | FLOPs- und Speicherprobleme bei langer Kontext-Inferenz (1M) |
| mHC | Manifold-Constrained Hyper-Connections | Stabilität tiefer Residuenverbindungen, verhindert Gradientenverschwinden/-explosion |
| Engram | Engram Conditional Memory | Entkopplung von "statischen Fakten" und "Schlussfolgerungsfähigkeit", günstigere Faktenaktualisierung |
| Muon | Muon Optimizer | Konvergenzgeschwindigkeit und Stabilität des Trainings, Senkung der Trainingskosten |
Jeder Punkt ist eine genauere Betrachtung wert:
-
Hybrid Attention (CSA + HCA): Die Attention-Komplexität herkömmlicher Transformer liegt bei O(n²), was bei 1M Kontext explodieren würde. V4 nutzt Compressed Sparse Attention (CSA) für grobe Filterung und Highly Compressed Attention (HCA) für feine Fokussierung. Zusammen senken sie die FLOPs auf 27 % von V3.2 und den KV-Cache auf nur 10 %. Dies ist der Schlüssel dazu, dass deepseek-v4-pro 1M Kontext "tatsächlich nutzbar" macht.
-
mHC (Manifold-Constrained Hyper-Connections): Beim Training tiefer MoE-Modelle können Signale in Residuenverbindungen nach einigen Dutzend Schichten verzerrt werden. mHC fügt Einschränkungen im Manifold-Raum hinzu, um die Signalübertragung zu stabilisieren. Praktisch ausgedrückt: Das Modell kann tiefer und länger trainiert werden, ohne zu kollabieren.
-
Engram Conditional Memory: Eine sehr ingenieurstechnische Innovation. Sie entkoppelt "Fakten im Gedächtnis des Modells" von der "Schlussfolgerungsfähigkeit" – Fakten werden in einem speziellen Speichermodul abgelegt, während die Schlussfolgerungskette einen anderen Pfad nimmt. Das Ergebnis: Wenn Weltwissen aktualisiert werden muss, muss nicht das gesamte Modell neu trainiert werden, was die Veröffentlichungskosten für zukünftige Pro-Versionen massiv senkt.
-
Muon Optimizer: Ein von DeepSeek selbst entwickelter Optimierer, der im Vergleich zu AdamW schneller konvergiert und stabiler ist. Bei einem Trainingsmaßstab von Billionen Parametern bedeutet dies: Bei gleicher Rechenleistung wird das Modell gründlicher trainiert.
🎯 Technischer Hinweis: deepseek-v4-pro vergrößert nicht einfach eine alte Architektur, sondern hat die Infrastruktur komplett neu geschrieben. Das ist der Grund, warum es im Open-Source-Zustand das Niveau von Closed-Source-Giganten erreicht. Wenn Sie planen, es intensiv zu nutzen, empfehlen wir, über APIYI apiyi.com zunächst eine Reihe typischer Geschäfts-Eingabeaufforderungen auszuführen, um die durch das Architektur-Upgrade bedingten Unterschiede zu spüren – insbesondere bei langen Kontexten und mehrstufigen Schlussfolgerungsszenarien.
1.5 1M Kontext + 384K Ausgabe: Ein Wendepunkt für die Generierung langer Texte
Pro und Flash haben identische Kontextspezifikationen: 1M Tokens Eingabe, 384K Tokens Ausgabe. Der Vorteil von Pro liegt jedoch nicht darin, "wie viel gelesen werden kann", sondern darin, "wie tief bei 1M nachgedacht werden kann".
Praktische Bedeutung für Szenarien mit langen Texten:
| Aufgabe | V3.2-Ära | V4-Pro-Ära |
|---|---|---|
| Überarbeitung eines 500.000-Wörter-Manuskripts | Muss in 10+ Stücke zerlegt werden | 1M-Fenster in einem Durchgang |
| Fragen zu 200 Seiten technischer Dokumentation | RAG muss aufgebaut werden | Direkt einspeisen |
| Audit mittelgroßer Code-Repositories | Zusammenfassende Analyse | Konsistenzprüfung über Dateien hinweg |
| Kohärenz beim Roman-Schreiben | Gedächtnis muss selbst verwaltet werden | 384K Ausgabe in einem Rutsch |
II. Der Benchmark-Thron von deepseek-v4-pro
2.1 Programmierfähigkeiten: deepseek-v4-pro führt die Bestenlisten an
Zuerst die härtesten Daten – die Programmierfähigkeiten:
| Benchmark | V4-Pro | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1-Pro | Erster Platz |
|---|---|---|---|---|---|
| LiveCodeBench | 93,5 | — | 88,8 | 91,7 | V4-Pro 🏆 |
| Codeforces Rating | 3206 | 3168 | — | 3052 | V4-Pro 🏆 |
| Apex Shortlist Pass@1 | 90,2 | 78,1 | 85,9 | 89,1 | V4-Pro 🏆 |
| SWE-bench Verified | 80,6–82,1 | — | 80,8 | 80,6 | Gleichstand |
| Terminal-Bench 2.0 | 67,9 | 75,1 | 65,4 | 68,5 | GPT-5.4 |
Spitzenreiter in drei Kategorien, in zwei Kategorien "Gleichstand oder knapp geschlagen". Zum ersten Mal übertrifft ein Open-Source-Modell die Closed-Source-Flaggschiffe in der Programmierfähigkeit umfassend – ein sehr bezeichnendes Ereignis für das Jahr 2026.
Interpretation:
- LiveCodeBench 93,5: LiveCodeBench aktualisiert die Aufgaben monatlich, um eine Kontamination der Trainingsdaten zu vermeiden. Die 93,5 von V4-Pro zeigen, dass seine Programmierfähigkeit generalisiert ist und es neue Aufgaben lösen kann, anstatt nur Aufgaben auswendig zu lernen.
- Codeforces 3206: Ein Wert für Wettbewerbsprogrammierung; 3206 Punkte entsprechen fast dem IGM-Niveau (International Grandmaster). Dieser Wert ist für den täglichen Geschäftscode mehr als ausreichend.
- Apex Shortlist Pass@1 90,2 vs. GPT-5.4 78,1: Dieser Abstand ist systemisch. Apex Shortlist ist eine Sammlung hochschwieriger Interviewfragen; V4-Pro führt hier mit ganzen 12 Prozentpunkten.
- Terminal-Bench 2.0 etwas schwächer: Dies betrifft die Nutzung von mehrstufigen Befehlszeilen-Tools. GPT-5.4 führt hier weiterhin, was zeigt, dass GPT-5.4 bei Szenarien mit "komplexen mehrstufigen Agenten" einen Burggraben hat.
2.2 Mathematik und Schlussfolgerung: deepseek-v4-pro nähert sich der Spitze
In der mathematischen Dimension liefern sich Pro und die Closed-Source-Giganten ein Kopf-an-Kopf-Rennen, ohne dass Pro überall führt:
| Benchmark | V4-Pro | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1-Pro |
|---|---|---|---|---|
| MMLU-Pro | 87,5 | 87,5 | 89,1 | 91,0 |
| IMOAnswerBench | 89,8 | 91,4 | 75,3 | 81,0 |
| HMMT 2026 | 95,2 | 97,7 | 96,2 | — |
| MATH | 92 % | — | — | — |
| HumanEval | 90 % | — | — | — |
| MMLU | 89 % | — | — | — |
Highlight bei IMOAnswerBench: Die Sammlung der Internationalen Mathematik-Olympiade; V4-Pro erreicht 89,8 Punkte und übertrifft Claude Opus 4.6 um satte 14,5 Punkte sowie Gemini 3.1-Pro um 8,8 Punkte. Bei mathematischen Schlussfolgerungen und formalen Beweisen ist Pro derzeit die Obergrenze für Open-Source-Modelle.
Schwäche bei MMLU-Pro Allgemeinwissen: Die 87,5 von Pro liegen gleichauf mit GPT-5.4, sind aber 3,5 Punkte schlechter als die 91,0 von Gemini 3.1-Pro. Bei allgemeinen Wissensfragen hat Gemini weiterhin einen gewissen Vorteil.
2.3 Schlachtfeld-Verteilung: Wo gewinnt und wo verliert deepseek-v4-pro?
| Schlachtfeld | Champion | Position von V4-Pro |
|---|---|---|
| Code-Generierung (LiveCodeBench) | V4-Pro 🏆 | Champion |
| Wettbewerbsprogrammierung (Codeforces) | V4-Pro 🏆 | Champion |
| Schwierige Interviews (Apex) | V4-Pro 🏆 | Champion (deutlich führend) |
| Software Engineering (SWE-bench) | Gleichstand | Erster Platz (geteilt) |
| Mathematik-Wettbewerbe (IMO) | GPT-5.4 | Zweiter (weit vor Claude/Gemini) |
| Allgemeinwissen (MMLU-Pro) | Gemini 3.1-Pro | Dritter |
| Mehrstufige Tool-Ketten (Terminal-Bench) | GPT-5.4 | Zweiter |
| Konsistente Schlussfolgerung (HMMT) | GPT-5.4 | Dritter |
Fazit: Wenn Ihr Arbeitsaufkommen hauptsächlich aus Code besteht, ist deepseek-v4-pro derzeit eine der stärksten Optionen weltweit (einschließlich Open- und Closed-Source). Wenn es hauptsächlich um mehrstufige Agenten-Tool-Ketten geht, hat GPT-5.4 immer noch einen leichten Vorteil; bei allgemeinen Wissensfragen ist Gemini 3.1-Pro stärker.
🎯 Empfehlung zur Modellauswahl: Wir empfehlen, zunächst eine Reihe von AB-Vergleichen (V4-Pro vs. bestehendes Modell) mit Ihren typischen Geschäfts-Eingabeaufforderungen auf APIYI apiyi.com durchzuführen (20–50 Beispiele reichen aus). Vertrauen Sie nicht blind auf öffentliche Benchmarks für Ihre Entscheidung – Ihre eigene Verteilung von Eingabeaufforderungen ist der wahre Benchmark. Für Batch-AB-Tests empfehlen wir die Nutzung der Hochverfügbarkeitsleitung
vip.apiyi.com.
Drei. Aufruf von deepseek-v4-pro bei APIYI apiyi.com in 5 Minuten
3.1 Schritt 1: API-Schlüssel abrufen und Route wählen
Voraussetzungen: Python 3.8+ oder Node.js 18+, wahlweise das offizielle OpenAI SDK oder Anthropic SDK.
API-Schlüssel abrufen:
- Besuchen Sie APIYI
apiyi.com, Konsole → API Keys → Neuen Schlüssel erstellen. - Es wird empfohlen, für den Pro-Schlüssel ein separates Tageslimit festzulegen (200–500 ¥, je nach Geschäftsumfang).
- Kopieren Sie den Schlüssel, der mit
sk-beginnt.
Route wählen (alle drei Routen nutzen denselben Schlüssel):
| base_url | Verwendung |
|---|---|
https://api.apiyi.com/v1 |
Tägliche Aufrufe, interaktive Szenarien |
https://vip.apiyi.com/v1 |
Batch-Aufgaben, hohe Parallelität |
https://b.apiyi.com/v1 |
Backup bei Instabilität der Hauptseite |
3.2 Schritt 2: Minimaler Python-Aufruf (ohne Thinking)
from openai import OpenAI
client = OpenAI(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com/v1",
)
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "system", "content": "Du bist ein erfahrener Python-Entwickler."},
{"role": "user", "content": "Schreibe einen produktionsreifen LRU-Cache in 30 Zeilen."},
],
max_tokens=2048,
)
print(resp.choices[0].message.content)
Ändern Sie nur zwei Stellen: base_url und model — der restliche OpenAI SDK-Code bleibt unverändert.
3.3 Schritt 3: Thinking-Modus aktivieren (Das Highlight von Pro)
Der wahre Wert von deepseek-v4-pro entfaltet sich erst im Thinking-Modus. Die Benchmarks wie IMOAnswerBench 89.8 und LiveCodeBench 93.5 wurden alle im Thinking-Modus gemessen.
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "user", "content": """
Bitte implementiere einen nebenläufigkeitssicheren Token-Bucket-Limiter mit folgenden Anforderungen:
1. Unterstützung für dynamische Ratenanpassung
2. Unterstützung für Burst-Traffic-Reservierung
3. Lock-freie Implementierung (CAS oder atomare Operationen)
4. Inklusive vollständiger Unit-Tests
"""},
],
extra_body={
"reasoning": {"enabled": True, "effort": "high"},
},
max_tokens=16384,
)
print("--- Schlussfolgerungsprozess ---")
print(resp.choices[0].message.reasoning_content)
print("\n--- Endergebnis ---")
print(resp.choices[0].message.content)
Bei effort=high führt das Pro-Modell eine sehr tiefgehende Planung durch – Sie werden sehen, wie es zuerst die Anforderungen analysiert, dann die API entwirft, verschiedene Implementierungsansätze diskutiert und erst am Ende den Code liefert. Das ist der Grund, warum sich der Aufpreis von deepseek-v4-pro gegenüber Flash lohnt.
3.4 Schritt 4: Praxisbeispiel für Fehlerbehebung
Reales Szenario: Lassen Sie Pro einen Bug beheben.
buggy_code = """
def find_kth_largest(nums, k):
nums.sort()
return nums[k] # BUG hier
"""
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "system", "content": "Du bist ein erfahrener Code-Reviewer. Identifiziere Bugs, erkläre die Ursache und liefere korrigierten Code."},
{"role": "user", "content": f"Überprüfe diesen Code:\n```python\n{buggy_code}\n```"},
],
extra_body={"reasoning": {"enabled": True}},
max_tokens=4096,
)
print(resp.choices[0].message.content)
Pro wird darauf hinweisen, dass der Index -k sein sollte (nach dem Sortieren ist das k-größte Element an der k-letzten Position) und liefert die Korrektur sowie die Behandlung von Randbedingungen (k <= 0, k > len(nums)) und Testfälle.
Die 80%+ Daten des SWE-bench spiegeln sich in diesem Szenario in der realen Erfahrung wider.
3.5 Schritt 5: Function Calling / Tool Use
Pro ist bei einzelnen Werkzeugaufrufen sehr stabil; bei mehrstufigen Tool-Ketten ist es zwar schwächer als GPT-5.4, aber führend gegenüber Claude:
tools = [
{
"type": "function",
"function": {
"name": "run_sql",
"description": "Führe eine schreibgeschützte SQL-Abfrage auf der Analyse-Datenbank aus.",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "Nur SELECT-SQL"},
},
"required": ["query"],
},
},
},
]
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "user", "content": "Welche 5 Städte hatten in den letzten 30 Tagen die meisten DAUs?"},
],
tools=tools,
tool_choice="auto",
)
print(resp.choices[0].message.tool_calls)
3.6 Schritt 6: Anthropic-Protokoll (Claude Code mit Pro verbinden)
Dieser Pfad ist der am meisten unterschätzte Wert von deepseek-v4-pro: Sie können bei all Ihren bestehenden Claude SDK / Claude Code-Projekten das zugrunde liegende Modell durch V4-Pro ersetzen, ohne den Geschäftscode zu ändern.
from anthropic import Anthropic
client = Anthropic(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com", # Hinweis: ohne /v1
)
resp = client.messages.create(
model="deepseek-v4-pro",
max_tokens=4096,
messages=[
{"role": "user", "content": "Refactore diesen Python-Code in den async/await-Stil..."},
],
)
print(resp.content[0].text)
Claude Code Terminal: Konfigurieren Sie ANTHROPIC_BASE_URL=https://api.apiyi.com + ANTHROPIC_API_KEY=sk-... und setzen Sie das Modell auf deepseek-v4-pro, um sofort einen Terminal-Agenten mit überlegenen Code-Fähigkeiten zu erhalten.
3.7 Schritt 7: Einbindung von deepseek-v4-pro in Cursor
In Cursor unter Settings → Models → Custom OpenAI-Compatible:
- Base URL:
https://api.apiyi.com/v1 - API Key:
sk-... - Model Name:
deepseek-v4-pro
Nach Abschluss werden die Chat- / Cmd+K- / Composer-Eingänge von Cursor über V4-Pro laufen, was die Qualität der Code-Vervollständigung und des Refactorings deutlich verbessert.
🎯 IDE-Empfehlung: Gängige KI-Programmiertools wie Cursor, Windsurf, Cline und Continue sind mit dem OpenAI-Protokoll kompatibel. Richten Sie die
base_urlauf APIYIapi.apiyi.com/v1und ändern Sie das Modell aufdeepseek-v4-pro, um nahtlos zu migrieren. Detaillierte IDE-Konfigurationsbeispiele finden Sie in der DeepSeek V4-Rubrik der offiziellen APIYI-Dokumentation unterdocs.apiyi.com.
Vier. Wann man deepseek-v4-pro wählen sollte (und wann nicht)
4.1 Entscheidungsbedingungen für Pro
✅ In folgenden Szenarien direkt deepseek-v4-pro wählen:
| Szenario | Warum |
|---|---|
| Code-Generierung, Refactoring, Review | LiveCodeBench 93.5, Gesamtsieger |
| Wettbewerbsprogrammierung, Algorithmen-Training | Codeforces 3206, entspricht IGM-Niveau |
| Batch-Beantwortung von Interviewfragen | Apex Shortlist 90.2, deutlich führend |
| Mathematische Schlussfolgerungen, formale Beweise | IMOAnswerBench 89.8, 14 Punkte Vorsprung vor Claude |
| Verständnis großer Repositories | 1 Mio. Kontext + 49B aktivierte Parameter |
| Schreiben und Editieren langer Texte | 384K Output in einem Durchgang |
| Lokale Bereitstellung / Nachtraining | Offene Gewichte + Engram-Modul für Fine-Tuning |
| Ersatz für Cursor / Claude Code Basismodell | Anthropic-Protokoll ohne Anpassung |
4.2 Wann man Pro nicht wählen sollte
❌ Verschwenden Sie in folgenden Szenarien keine Pro-Rechenleistung:
| Szenario | Empfehlung |
|---|---|
| Tägliche Konversationen, FAQs | Flash verwenden (12x günstiger) |
| Klassifizierung kurzer Texte, Extraktion | Flash oder ein kleineres Modell verwenden |
| Mehrstufige komplexe Agenten-Tool-Ketten | Bevorzugt GPT-5.4 (führend bei Terminal-Bench) |
| Fokus auf allgemeine Wissensfragen | Gemini 3.1-Pro ist stärker |
| Latenzempfindliche Online-Interaktionen | Flash (Non-Thinking-Modus) oder Caching verwenden |
4.3 Empfehlung für hybrides Routing
Die optimale Lösung in Produktionsumgebungen ist in der Regel ein Layered Routing:
def pick_model(request_type: str, complexity: str) -> str:
# Schwere Code-Arbeit → Pro
if request_type in ("code_gen", "code_review", "refactor") and complexity == "hard":
return "deepseek-v4-pro"
# Mathematische Schlussfolgerungen → Pro
if request_type in ("math_proof", "competitive_programming"):
return "deepseek-v4-pro"
# Tiefes Verständnis langer Dokumente → Pro
if request_type == "long_doc_analysis":
return "deepseek-v4-pro"
# Sonstiges Alltägliches → Flash
return "deepseek-v4-flash"
Auf APIYI apiyi.com nutzen beide Modelle denselben Schlüssel. Beim Wechsel muss nur das Feld model angepasst werden, keine weiteren Konfigurationen.
V. Häufig gestellte Fragen (FAQ) zu deepseek-v4-pro
F1: Warum ist die Programmierfähigkeit von Pro so stark?
Drei Gründe wirken hier zusammen:
- 32T Token Vortraining: Enthält eine riesige Menge an hochwertigen Code-Korpora.
- 1,6T MoE / 49B aktivierte Parameter: Ermöglicht das Speichern und Abrufen von tiefgreifendem Programmierwissen.
- Thinking-Modus + Engram Memory: Entkoppelt das "Auswendiglernen von Code-Mustern" von der "Herleitung neuen Codes".
Keiner dieser Punkte allein würde zu diesem Ergebnis führen; erst die Kombination ermöglichte die 93,5 Punkte im LiveCodeBench.
F2: Führen 1,6T Parameter nicht zu einer langsamen Antwortzeit?
Die Antwortgeschwindigkeit pro Anfrage wird durch die aktivierten Parameter bestimmt, nicht durch die Gesamtanzahl. Pro aktiviert pro Token nur 49B. Dank der FLOPs-Optimierung durch Hybrid Attention ist die Latenz bis zum ersten Token vergleichbar mit Flash. Der Thinking-Modus ist zwar langsamer (da der Denkprozess ausgegeben wird), aber das ist eine bewusste Designentscheidung – Sie bezahlen mit Zeit für die Qualität der Schlussfolgerung.
F3: Muss der Thinking-Modus immer aktiviert sein?
Nicht unbedingt. Für normale Konversationen, einfachen Code oder alltägliche Fragen können Sie ihn ausschalten. Aber der Großteil des Mehrwerts, für den Sie bei Pro bezahlen, liegt im Thinking-Modus. Bei komplexem Code, mathematischen Aufgaben oder mehrstufigen logischen Schlussfolgerungen sollten Sie unbedingt reasoning.enabled=true und effort=high verwenden.
F4: Wie verwende ich es in Cursor / Claude Code?
- Cursor: Einstellungen → Models → Custom OpenAI-Compatible, Base URL auf
https://api.apiyi.com/v1setzen, Modellnamedeepseek-v4-pro. - Claude Code: Umgebungsvariablen
ANTHROPIC_BASE_URL=https://api.apiyi.com+ANTHROPIC_API_KEY=sk-...setzen, beim Start das Modelldeepseek-v4-proangeben.
Detaillierte Screenshots finden Sie im Bereich für IDE-Integration unter docs.apiyi.com.
F5: Wer ist im Vergleich zu GPT-5.4 lohnenswerter?
Wenn Sie sich entscheiden müssen:
- Täglicher Code / Wettbewerbe / Mathematik / Kostenbewusstsein → deepseek-v4-pro (Code-Champion, 1/7 des Preises).
- Mehrstufige Toolchain-Agenten / Allgemeinwissen → GPT-5.4.
- Mischbetrieb ist die optimale Lösung (über APIYI apiyi.com mit demselben Schlüssel zwischen beiden Modellen wechseln).
F6: Kann man es lokal bereitstellen?
Ja, V4-Pro hat die vollständigen Gewichte auf Hugging Face veröffentlicht (deepseek-ai/DeepSeek-V4-Pro). Die Anforderungen für eine Eigenbereitstellung sind jedoch hoch:
- Einzelmaschine ≥ 8×H200 oder äquivalente GPU.
- 1M Kontext erfordert zusätzlichen KV-Cache (obwohl Pro den Cache bereits auf 10 % von V3.2 reduziert hat).
- Technischer Aufwand für die Wartung des Inferenz-Dienstes.
Kostenkalkulation: Sofern Sie kein monatliches Volumen von über 50 Milliarden Token haben, ist die Nutzung des API-Proxy-Dienstes von APIYI (apiyi.com) wirtschaftlicher als eine Eigenbereitstellung.
F7: Wie hoch ist das Limit für gleichzeitige Anfragen (Concurrency)?
Empfehlungen für die Produktionsumgebung:
- Hauptseite
api.apiyi.com: 50 gleichzeitige Anfragen sicher. - Hochleistungs-Leitung
vip.apiyi.com: 200+ gleichzeitige Anfragen. - Backup
b.apiyi.com: Automatischer Fallback bei Schwankungen der Hauptleitung.
Da Pro bei komplexen Thinking-Aufgaben eine höhere Latenz hat, ist eine höhere Parallelität nicht immer besser – es ist sinnvoller, das benötigte Fenster anhand von QPS × durchschnittliche Antwortzeit zu schätzen.
F8: Wird es bald eine offizielle Version von Pro geben?
Die am 24.04.2026 veröffentlichte Version ist eine Preview. Nach dem bisherigen Rhythmus von DeepSeek erscheint die offizielle Version meist 1–2 Monate nach der Preview und könnte leichte Verbesserungen bei den Benchmarks aufweisen. Die Nutzung der Preview über APIYI apiyi.com ist unbedenklich – die Modell-ID wird bei der offiziellen Version höchstwahrscheinlich deepseek-v4-pro bleiben und abwärtskompatibel sein.
VI. Zusammenfassung zum Start von deepseek-v4-pro
Falls Sie nur das Fazit suchen:
- ✅ deepseek-v4-pro ist das aktuell leistungsfähigste Open-Source-Modell für Code – es schlägt GPT-5.4 / Claude Opus 4.6 / Gemini 3.1-Pro in den drei harten Benchmarks LiveCodeBench, Codeforces und Apex.
- ✅ Vier architektonische Innovationen (Hybrid Attention / mHC / Engram Memory / Muon) machen es nicht zu "einem weiteren großen Sprachmodell", sondern zu einer neuen Spezies nach einer grundlegenden Überarbeitung der Infrastruktur.
- ✅ 1,6T / 49B MoE + 32T Token Vortraining + 1M Kontext erreichen das Limit dessen, was derzeit Open Source möglich ist.
- ✅ Bereits bei APIYI apiyi.com verfügbar, kompatibel mit OpenAI- und Anthropic-Protokollen, nahtlose Integration in Cursor, Claude Code, Cline und alle gängigen Tools.
- ✅ Preis beträgt nur 1/7 von GPT-5.4, wobei der Thinking-Modus seine wahre Stärke ausspielt.
Für Entwicklungsteams, deren Fokus auf Code liegt, lohnt sich ein sofortiger Test von deepseek-v4-pro. Es ist kein "etwas billigerer Ersatz", sondern ein Flaggschiff-Modell, das zum neuen Standard werden könnte.
🎯 Handlungsempfehlung: Beantragen Sie noch heute einen Schlüssel bei APIYI
apiyi.com(speziell für Pro, Tageslimit auf 200–500 ¥ setzen). Führen Sie 20 Ihrer repräsentativsten Code-, Mathematik- oder Langtext-Prompts aus und machen Sie einen AB-Vergleich zwischen V4-Pro (Thinking-Modus) und Ihrem aktuellen Hauptmodell. Wenn die Qualität der Code-Aufgaben deutlich steigt, stellen Sie das Standardmodell in Cursor / Claude Code um. Wenn Sie ein günstiges Modell für den Alltag benötigen, fügen Sie zusätzlich V4-Flash hinzu (siehe vorheriger Migrationsleitfaden). Nutzen Sie für Batch-Testsvip.apiyi.comund bei Instabilität der Hauptseite den automatischen Fallback aufb.apiyi.com. Vollständige Integrationsbeispiele, IDE-Konfigurationen und Benchmark-Skripte finden Sie unterdocs.apiyi.com.
Die Bedeutung von deepseek-v4-pro geht über "ein weiteres günstiges SOTA-Modell" hinaus. Es markiert den Moment, in dem Open-Source-Modelle erstmals die proprietären Flaggschiffe bei der Kernkompetenz Programmierung vollständig übertreffen – ein Meilenstein, den jedes Team, das KI-Engineering ernst nimmt, einmal selbst testen sollte.
Autor: APIYI Technik-Team
Ressourcen:
- Offizielle DeepSeek-Ankündigung: api-docs.deepseek.com/news/news260424
- Hugging Face Repository: huggingface.co/deepseek-ai/DeepSeek-V4-Pro
- APIYI Website: apiyi.com
- APIYI Dokumentation: docs.apiyi.com
- APIYI Hauptseite: api.apiyi.com (Backup: vip.apiyi.com / b.apiyi.com)