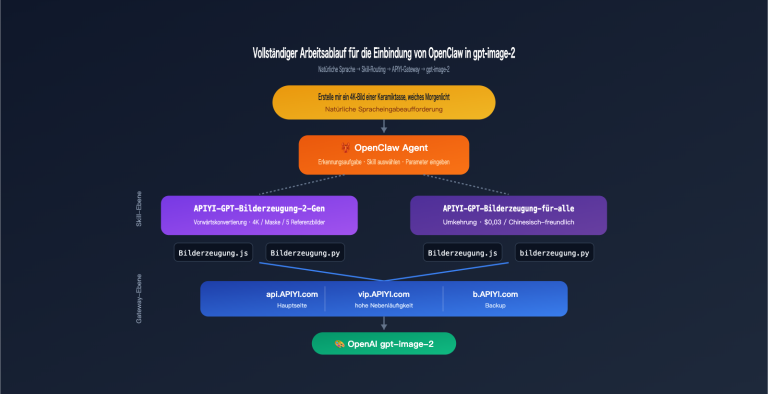
Anmerkung des Autors: APIYI hat das „Reverse-Engineering“-Modell gpt-image-2-all veröffentlicht. Die Abrechnung erfolgt pro Aufruf für $0,03 ohne Begrenzung der Parallelität. Es unterstützt Text-zu-Bild, die Zusammenführung mehrerer Bilder sowie die Bearbeitung mittels natürlicher Sprache und entspricht exakt den neuesten Funktionen der ChatGPT-Weboberfläche. Dieser Artikel bietet eine vollständige Anleitung zur API-Integration.
Im April 2026 begann die ChatGPT-Weboberfläche mit A/B-Tests für die nächste Generation der Bilderzeugung – Nutzer sahen zwar weiterhin das Label „GPT Image 1.5“, doch einige Anfragen wurden bereits vom neuen Modell verarbeitet. Die offizielle OpenAI-API hat die Modell-ID gpt-image-2 noch nicht freigegeben. Seien Sie vorsichtig bei Diensten, die behaupten, „direkt die gpt-image-2-API aufzurufen“.
APIYI hat nun offiziell gpt-image-2-all über eine „Reverse-Engineering“-Lösung gestartet, die nahtlos mit den neuesten Funktionen der ChatGPT-Weboberfläche kompatibel ist, bei einer Abrechnung von $0,03 pro Aufruf und ohne Begrenzung der Parallelität. Dies ist kein leeres Versprechen, sondern eine produktionsreife Schnittstelle, die bereits mit Standard-HTTP-Anfragen genutzt werden kann.
Kernnutzen: Nach dem Lesen dieses Artikels beherrschen Sie die 3 API-Endpunkte von gpt-image-2-all, Techniken zur Zusammenführung mehrerer Bilder sowie die Bearbeitung per natürlicher Sprache und können die Integration innerhalb von 10 Minuten abschließen.

Kernpunkte von gpt-image-2-all
| Funktion | Beschreibung | Nutzen |
|---|---|---|
| ChatGPT-Web-Parität | „Reverse-Engineering“-Lösung synchron mit offiziellen Funktionen | Kein Warten auf OpenAI-API |
| Abrechnung pro Aufruf | $0,03/Aufruf, unabhängig von Auflösung/Qualität/Eingabeaufforderung | Transparente Kosten |
| Unbegrenzte Parallelität | Keine Begrenzung der Anfragen | Ideal für Batch-Pipelines |
| Zusammenführung mehrerer Bilder | Referenzierung via „Bild1/Bild2/Bild3“ im Prompt | Konsistente Generierung |
| Bearbeitung per natürlicher Sprache | Dialogbasierte Bearbeitung ohne Masken | Niedrigere Hürde für Iterationen |
Einordnung von gpt-image-2-all
Was bedeutet „Reverse-Engineering“? Es handelt sich um eine API-Proxy-Dienst-Lösung, die über Reverse-Engineering an die neuesten Bilderzeugungsfunktionen der ChatGPT-Weboberfläche angebunden ist. Dies ist nicht dieselbe Schnittstelle wie die zukünftige offizielle gpt-image-2-API von OpenAI, bietet jedoch die gleiche zugrunde liegende Modellleistung. Bis zur offiziellen Veröffentlichung ist dies die einzige produktionsreife Lösung, um die neuesten Bilderzeugungsfunktionen von ChatGPT stabil aufzurufen.
Warum jetzt integrieren? Drei Gründe: (1) Das Veröffentlichungsdatum der offiziellen OpenAI gpt-image-2-API steht noch nicht fest (voraussichtlich Ende April bis Mitte Mai 2026); (2) In der Startphase wird es zwangsläufig zu Kapazitätsengpässen kommen; (3) Wenn Sie Ihre Geschäftsprozesse frühzeitig auf gpt-image-2-all optimieren, können Sie bei Freigabe der offiziellen Version nahtlos migrieren, indem Sie lediglich den Modellnamen anpassen.
Schnellstart für gpt-image-2-all
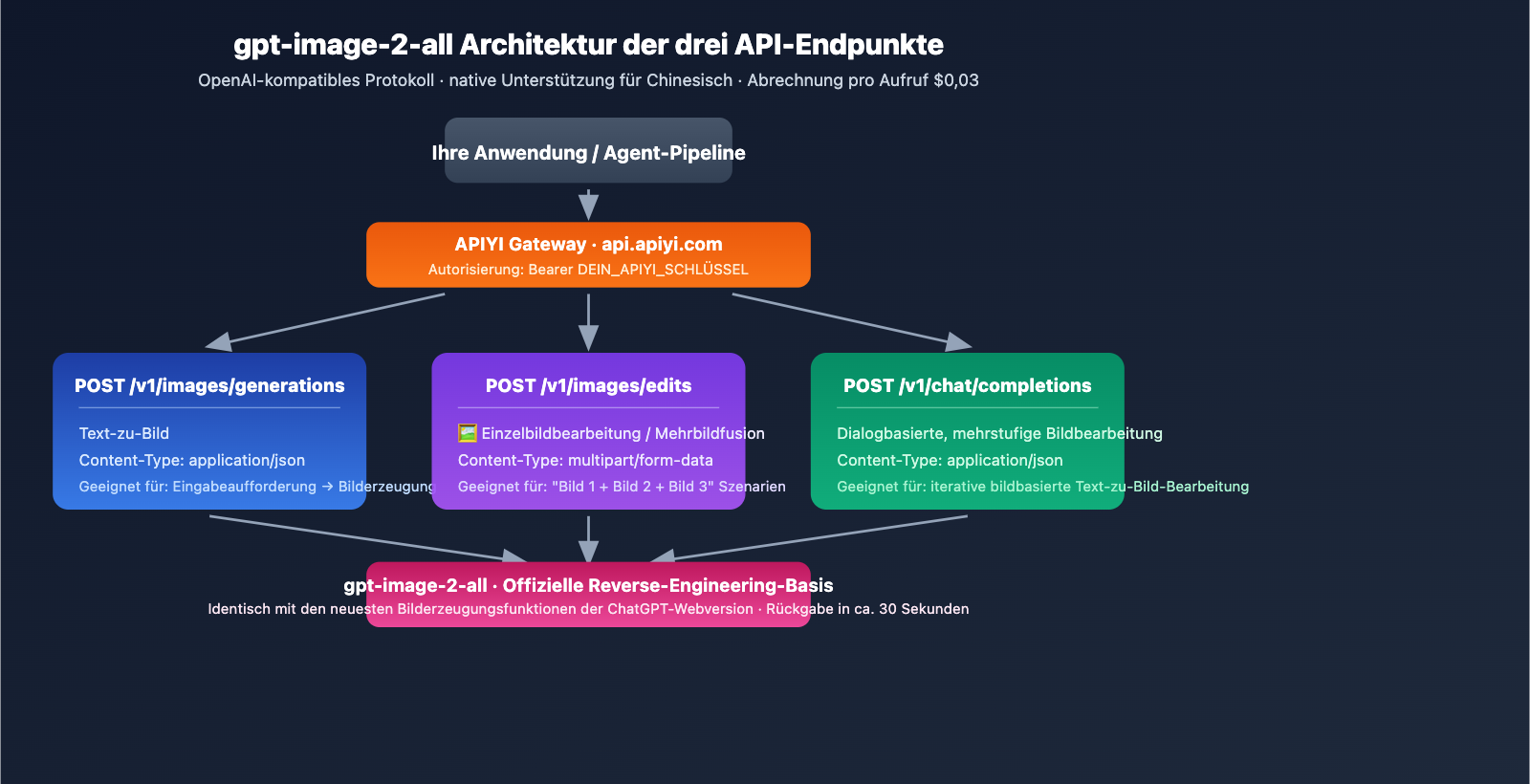
Die drei wichtigsten API-Endpunkte
gpt-image-2-all bietet drei Endpunkte, die das gesamte Spektrum der Bilderzeugung abdecken:
| Endpunkt | Zweck | Content-Type |
|---|---|---|
POST /v1/images/generations |
Text-zu-Bild | application/json |
POST /v1/images/edits |
Einzelbildbearbeitung/Mehrbildfusion | multipart/form-data |
POST /v1/chat/completions |
Dialogbasierte iterative Bildbearbeitung | application/json |
Basis-URL: https://api.apiyi.com (Alternativen: b.apiyi.com, vip.apiyi.com)
Minimalistisches Text-zu-Bild-Beispiel
import requests
response = requests.post(
"https://api.apiyi.com/v1/images/generations",
headers={
"Authorization": "Bearer YOUR_APIYI_KEY",
"Content-Type": "application/json"
},
json={
"model": "gpt-image-2-all",
"prompt": "Querformat 16:9, eine Tasse Latte Macchiato, auf dem Tisch ein Etikett mit der Aufschrift 'Morning Blend $4.50', Morgenlicht fällt durch das Café-Fenster",
},
timeout=120
)
result = response.json()
print(result["data"][0]["url"])
Vollständigen Integrationscode anzeigen (inkl. Fehlerbehandlung, Parallelisierung, Mehrbildfusion, dialogbasierte Bearbeitung)
import requests
import time
from typing import Optional, List
API_KEY = "YOUR_APIYI_KEY"
BASE_URL = "https://api.apiyi.com"
def text_to_image(prompt: str, timeout: int = 120) -> Optional[str]:
"""Text-zu-Bild: über den Endpunkt /v1/images/generations"""
for attempt in range(3):
try:
r = requests.post(
f"{BASE_URL}/v1/images/generations",
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
},
json={"model": "gpt-image-2-all", "prompt": prompt},
timeout=timeout
)
if r.status_code == 200:
return r.json()["data"][0]["url"]
if r.status_code == 429:
time.sleep(2 ** attempt)
continue
except requests.Timeout:
continue
return None
def multi_image_fusion(prompt: str, image_paths: List[str]) -> Optional[str]:
"""Mehrbildfusion: über den Endpunkt /v1/images/edits"""
files = [
("image[]", (f"img{i}.png", open(p, "rb"), "image/png"))
for i, p in enumerate(image_paths)
]
data = {"model": "gpt-image-2-all", "prompt": prompt}
r = requests.post(
f"{BASE_URL}/v1/images/edits",
headers={"Authorization": f"Bearer {API_KEY}"},
data=data,
files=files,
timeout=120
)
return r.json()["data"][0]["url"] if r.status_code == 200 else None
def conversational_edit(messages: List[dict]) -> Optional[str]:
"""Dialogbasierte Bildbearbeitung: über den Endpunkt /v1/chat/completions"""
r = requests.post(
f"{BASE_URL}/v1/chat/completions",
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
},
json={"model": "gpt-image-2-all", "messages": messages},
timeout=120
)
return r.json()["choices"][0]["message"]["content"] if r.status_code == 200 else None
url = text_to_image("Hochformat 9:16 Handy-Poster, eine Tasse Eiskaffee, oben großer Text 'Summer Sale 50% OFF'")
print(f"Generiert: {url}")
fusion_url = multi_image_fusion(
"Platziere die Person aus Bild 1 in die Strandszene aus Bild 2, behalte die Kleidung der Person bei",
["person.png", "beach.png"]
)
print(f"Fusion: {fusion_url}")
Integrationshinweis: Registrieren Sie sich bei APIYI (apiyi.com), um Testguthaben zu erhalten. Ein API-Schlüssel unterstützt alle Modelle wie gpt-image-2-all, GPT-4o und Claude, was den Verwaltungsaufwand für verschiedene Anbieter minimiert.
Detaillierte Funktionen von gpt-image-2-all
Funktion 1: Hochpräzise Textwiedergabe
Für gpt-image-2-all ist die Stabilität der Textdarstellung (sowohl Chinesisch als auch Englisch) eine Kernstärke der offiziellen ChatGPT-Bilderzeugungs-Technologie. Texte auf Schildern, Postern und Infografiken werden direkt beim ersten Versuch korrekt generiert – eine Herausforderung für gpt-image-1.5.
Praxisszenarien:
- Café-Menütafeln:
"Americano $4.00, Latte $4.50"zeichengenau. - Produktverpackungen: Zutatenlisten mit gemischten Sprachen sind klar lesbar.
- UI-Mockups: Schaltflächentexte und Navigationsbeschriftungen werden präzise gerendert.
- Infografiken: Titel, Untertitel und Datenbeschriftungen sind klar hierarchisch strukturiert.
Funktion 2: Mehrbildfusion
Über den Endpunkt /v1/images/edits können mehrere Referenzbilder gleichzeitig hochgeladen werden. Im Prompt können Sie diese direkt mit "Bild 1", "Bild 2", "Bild 3" referenzieren.
prompt = """
Platziere das Produkt aus Bild 1 in die Szene aus Bild 2,
verwende den Farbstil aus Bild 3,
Kamerawinkel leicht von oben,
4K HD-Details.
"""
Anwendungsbereiche:
| Szenario | Anwendung |
|---|---|
| E-Commerce-Szenen | Produktfoto + Szenenfoto → Lifestyle-Komposition |
| Gesichtskonsistenz | Charakter-Referenz + neue Szene → verschiedene Aufnahmen |
| Stiltransfer | Inhaltsbild + Stilbild → stilisierte Ausgabe |
| Marken-Visuelle-Systeme | Produkt + LOGO + Farbpalette → einheitliches Design |
Funktion 3: Bildbearbeitung in natürlicher Sprache (keine Masken erforderlich)
Der größte Effizienzsprung ist die dialogbasierte Bildbearbeitung – Sie müssen keine Masken mehr zeichnen oder Bereiche manuell auswählen. Beschreiben Sie Ihre Änderungswünsche einfach in natürlicher Sprache.
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": "Generiere eine Außenansicht eines Cafés, nachmittägliches Sonnenlicht fällt schräg ein"},
]
},
{
"role": "assistant",
"content": "[Link zum generierten Bild]"
},
{
"role": "user",
"content": "Ändere das Wetter in Regen, behalte das Gebäude bei"
}
]
Was bedeutet dieser Workflow?: Der bisherige Kreislauf "Generieren → in Photoshop bearbeiten → erneut generieren" wird durch eine dialogbasierte Iteration ersetzt. Jede Anpassung erfordert nur die Beschreibung der Differenz, ohne den gesamten Prompt neu schreiben zu müssen.
Funktion 4: Native Unterstützung für Chinesisch
Prompts können direkt auf Chinesisch verfasst werden, ohne dass eine Übersetzung ins Englische erforderlich ist. Für chinesische Entwicklerteams und lokalisierte Projekte bietet dies eine intuitive und reibungslose Erfahrung:
prompt = "Hochformat 9:16 Xiaohongshu-Cover, eine asiatische Frau trinkt Kaffee, Titel 'Wochenend-Entdeckung · Das geheime Café in den Hutongs', weicher, realistischer Stil"
Steuerung von Größe und Seitenverhältnis bei gpt-image-2-all
Wichtige Hinweise
gpt-image-2-all akzeptiert keine Parameter wie size, n, quality oder aspect_ratio – die Übergabe dieser Parameter führt zu einem Validierungsfehler. Die Steuerung der Bildgröße muss zwingend über die Beschreibung im Prompt erfolgen.
Empfohlene Prompt-Struktur
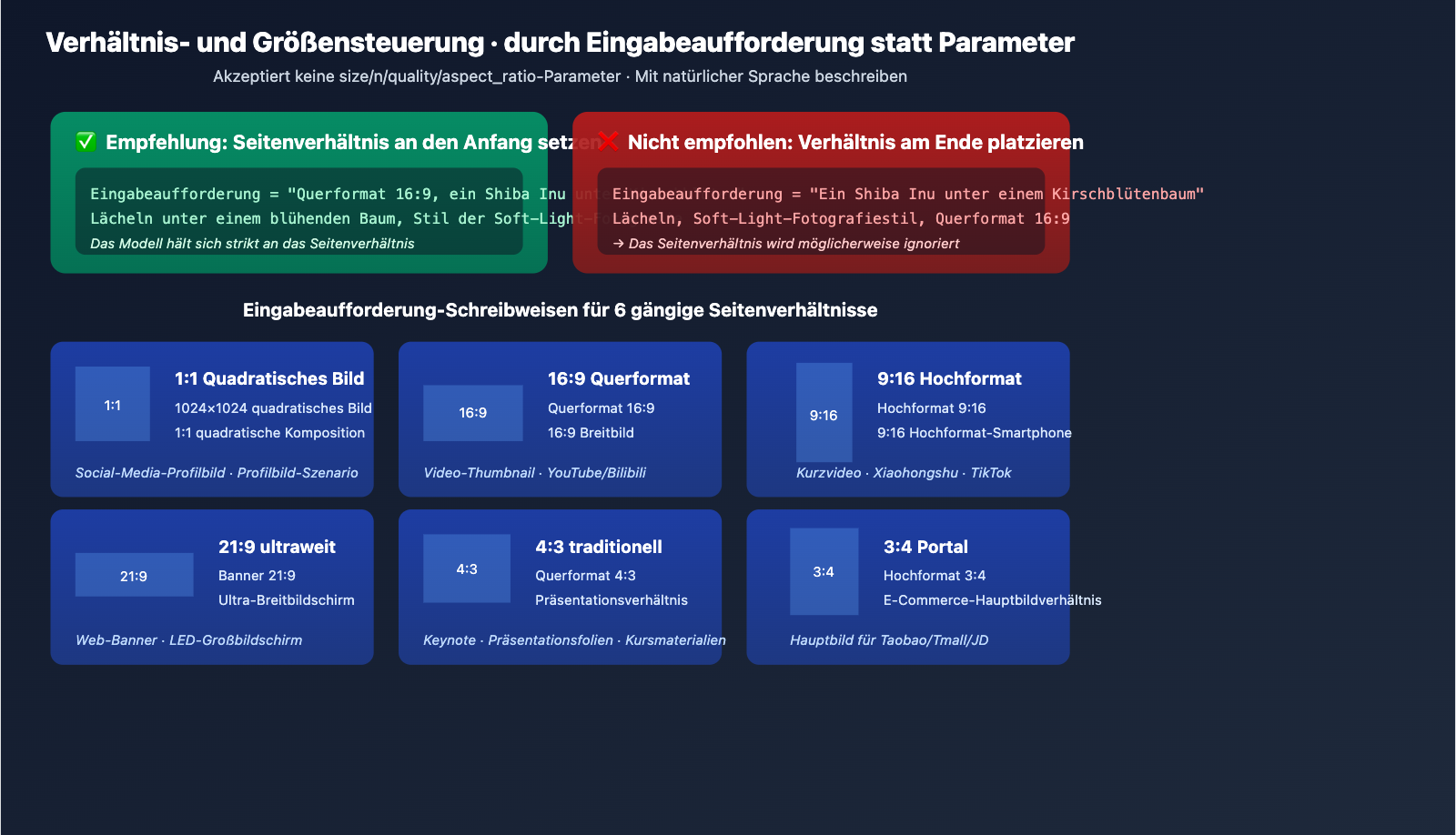
| Zielverhältnis | Empfohlene Schreibweise | Verwendung |
|---|---|---|
| 1:1 Quadrat | "1024×1024 Quadrat" oder "1:1 quadratische Komposition" | Social-Media-Profilbilder |
| 16:9 Querformat | "Querformat 16:9" oder "16:9 Breitbild" | Video-Thumbnails |
| 9:16 Hochformat | "Hochformat 9:16" oder "9:16 Smartphone-Bildschirm" | Kurzvideos / Social Media |
| 21:9 Ultra-Wide | "Banner 21:9" oder "Ultra-Wide-Bildschirm" | Web-Banner |
| 4:3 Klassisch | "Querformat 4:3" | Präsentationen |
| 3:4 Portal | "Hochformat 3:4" | E-Commerce-Hauptbilder |
Wichtige Tipps
Platzieren Sie die Angaben zum Seitenverhältnis am Anfang des Prompts. Das Modell folgt Anweisungen am Anfang des Prompts deutlich präziser; Angaben am Ende werden unter Umständen ignoriert.
# ✅ Empfohlen
prompt = "Querformat 16:9, ein Shiba Inu lächelt unter einem Kirschblütenbaum, weiche Fotografie"
# ❌ Nicht empfohlen
prompt = "ein Shiba Inu lächelt unter einem Kirschblütenbaum, weiche Fotografie, Querformat 16:9"
gpt-image-2-all Preisgestaltung und Parallelisierungsstrategie
Abrechnungsregeln
| Punkt | Regel |
|---|---|
| Einzelpreis | $0,03 / Aufruf |
| Abrechnungseinheit | Pro erfolgreicher Bilderzeugung |
| Keine Gebühr bei Fehlern | 401/4xx/5xx werden nicht berechnet |
| Parametereinfluss | Keiner (unabhängig von Auflösung/Qualität) |
| Parallelisierungslimit | Keines (natürliche Begrenzung durch Kontoguthaben) |
Typische Kostenschätzung
| Geschäftsszenario | Monatliches Volumen | Monatliche Kosten |
|---|---|---|
| Persönliches Projekt | 500 Aufrufe | $15 |
| Kleines Team | 5.000 Aufrufe | $150 |
| E-Commerce (Batch) | 50.000 Aufrufe | $1.500 |
| Großskalige Pipeline | 500.000 Aufrufe | $15.000 |
Tipp zur Kostenoptimierung: Durch die zentrale Kontoverwaltung von APIYI (apiyi.com) können Sie je nach Echtzeit-Aufgabentyp das optimale Modell zwischen gpt-image-2-all, gpt-image-1.5 und Nano Banana Pro routen. So vermeiden Sie es, für alle Szenarien den höchsten Einzelpreis zu zahlen.
gpt-image-2-all Fehlerbehandlung und Best Practices
Häufige Fehlercodes und deren Behandlung
| Statuscode | Vorgehensweise |
|---|---|
| 401 | Überprüfen Sie, ob das Authorization Bearer Token korrekt ist |
| 429 | Exponentielles Backoff-Retry (2s → 4s → 8s) |
| 5xx | 1-2 Mal erneut versuchen, bei anhaltendem Fehler Alarm auslösen |
| Timeout | Client-seitiges Timeout sollte ≥ 120 Sekunden betragen |
Tipps zur Fehlerbehebung
Alle Antworten enthalten einen request-id-Header. Notieren Sie diese ID bei Problemen und senden Sie sie an den technischen Support von APIYI, damit wir die serverseitigen Protokolle schnell analysieren können.
Nicht unterstützte Funktionen
- Streaming-Ausgabe:
stream=trueist wirkungslos, es wird nur eine einmalige Rückgabe unterstützt. - Mehrbild-Ausgabe: Eine einzelne Anfrage gibt nur 1 Bild zurück. Für mehrere Bilder sind parallele Aufrufe erforderlich.
- OpenAI SDK Standardparameter: Die offiziellen SDK-Standardparameter
size/nlösen Validierungsfehler aus. Es wird empfohlen, Anfragen direkt überrequestszu senden.
Häufig gestellte Fragen (FAQ)
Q1: Was ist gpt-image-2-all?
gpt-image-2-all ist ein API-Proxy-Dienst von APIYI, der über eine Reverse-Engineering-Lösung die neuesten Bilderzeugungsfunktionen der ChatGPT-Webversion bereitstellt. Bevor OpenAI die offizielle gpt-image-2 API freigibt, bietet dieser Dienst einen produktionsreifen Zugang, der mit den neuesten Fähigkeiten von ChatGPT identisch ist und die drei Kernszenarien Text-zu-Bild, Bildfusion sowie bildbasierte Bearbeitung mittels natürlicher Sprache unterstützt.
Q2: Was ist der Unterschied zwischen gpt-image-2-all und der offiziellen gpt-image-2?
Die zugrunde liegenden Modellfähigkeiten sind identisch, die Schnittstellenmethode unterscheidet sich. Die offizielle OpenAI-API hat das Modell gpt-image-2 derzeit noch nicht freigegeben (bei Diensten, die behaupten, dies direkt über die API aufzurufen, ist Vorsicht geboten), während die ChatGPT-Webversion das neue Modell bereits im Rahmen von A/B-Tests einsetzt. gpt-image-2-all bietet über eine Reverse-Engineering-Lösung einen stabilen Zugangskanal. Sobald die offizielle Version verfügbar ist, können Benutzer durch einfaches Ändern des model-Feldes nahtlos auf die offizielle Schnittstelle migrieren.
Q3: Wie ist der Preis von $0,03 pro Aufruf zu verstehen?
Die Abrechnung erfolgt pro erfolgreicher Generierung, unabhängig von Auflösung, Qualität oder Länge der Eingabeaufforderung. Im Vergleich zu den geschätzten Kosten der offiziellen OpenAI gpt-image-2 API ($0,15–$0,20) liegt gpt-image-2-all bei etwa 1/5 bis 1/6 des Preises. Fehlgeschlagene Anfragen (Authentifizierungsfehler, Parameterfehler) werden nicht berechnet; es gibt kein erzwungenes Limit für gleichzeitige Anfragen (die Begrenzung erfolgt lediglich durch das Kontoguthaben).
Q4: Warum dauert die Generierung eines Bildes 30 Sekunden?
30 Sekunden ist die durchschnittliche Antwortzeit der aktuellen Reverse-Engineering-Lösung, was der Geschwindigkeit der ChatGPT-Webversion entspricht. Sobald die offizielle gpt-image-2 API verfügbar ist, wird eine schnellere Antwortzeit (ca. 3 Sekunden) erwartet. Bis zur Veröffentlichung der offiziellen API ist gpt-image-2-all jedoch die einzige Lösung, um die neuesten Funktionen stabil abzurufen. Es wird empfohlen, das Timeout des Clients auf ≥120 Sekunden einzustellen, um Fehlermeldungen durch Zeitüberschreitungen zu vermeiden.
Q5: Wie binde ich gpt-image-2-all ein?
Die Einbindung erfolgt in drei Schritten:
- Registrieren Sie sich bei APIYI (apiyi.com) und erhalten Sie einen API-Schlüssel.
- Setzen Sie die Base URL auf
https://api.apiyi.com. - Verwenden Sie die
requests-Bibliothek, um den Endpunkt/v1/images/generationsaufzurufen (bei Verwendung des offiziellen SDK muss das HTTP-Protokoll angepasst werden, um Probleme mit demsize-Parameter zu vermeiden).
Detaillierte Dokumentation: docs.apiyi.com/api-capabilities/gpt-image-2-all/overview · Online-Test: imagen.apiyi.com
Q6: Wie viele Referenzbilder werden bei der Bildfusion maximal unterstützt?
Eine einzelne /v1/images/edits-Anfrage unterstützt mehrere Referenzbilder. Jedes Bild darf maximal 10 MB groß sein; unterstützt werden die Formate PNG, JPG und WebP. In der Eingabeaufforderung können die Bilder über "Bild1", "Bild2", "Bild3" referenziert werden. Praxistests zeigen, dass die Fusion von 3 bis 5 Referenzbildern am stabilsten ist; bei mehr als 10 Bildern kann es zu einem Verlust von Elementen kommen.
Q7: Warum kann ich das offizielle OpenAI-SDK nicht direkt verwenden?
Die Methode images.generate() des offiziellen OpenAI-SDK sendet standardmäßig Parameter wie size oder n, die von gpt-image-2-all nicht akzeptiert werden (dies löst einen Validierungsfehler aus). Empfohlene Vorgehensweise: (1) Senden Sie HTTP-Anfragen direkt mit requests; (2) oder passen Sie den Request-Body des SDK an, um diese Parameter zu entfernen. Sobald die offizielle Version veröffentlicht ist, wird das SDK kompatibel sein.
Q8: Welche bekannten Einschränkungen hat gpt-image-2-all?
Hier sind die aktuellen Einschränkungen:
- Ein Bild pro Ausgabe: Für mehrere Bilder sind parallele Aufrufe erforderlich.
- Kein Streaming: Die Antwort erfolgt in einem Schritt, kein
stream. - Beta-Phase: Die Stabilität wird kontinuierlich optimiert, gelegentliche Schwankungen sind möglich.
- Abhängigkeit von Reverse-Engineering: Änderungen an der ChatGPT-Weboberfläche können den Dienst kurzzeitig beeinträchtigen.
- Empfehlung für Fallback-Modelle: Für geschäftskritische Anwendungen wird empfohlen, zusätzlich gpt-image-1.5 oder Nano Banana Pro als Ausweichlösung zu konfigurieren.
Wichtige Punkte zu gpt-image-2-all
- Reverse-Engineering-Lösung · Übertragung der neuesten ChatGPT-Fähigkeiten: Der einzige produktionsreife Kanal vor der offiziellen API-Freigabe.
- $0,03 pro Aufruf · Keine Begrenzung der Parallelität: Abrechnung nach Erfolg, transparente Kosten, ideal für Batch-Pipelines.
- Drei Endpunkte für alle Szenarien: Text-zu-Bild / Bildfusion / dialogbasierte Bildbearbeitung.
- Natives Chinesisch + hochpräziser Text: Stabile Darstellung von chinesischen und englischen Texten, keine Übersetzung der Eingabeaufforderung erforderlich.
- Einstieg: Registrierung bei APIYI (apiyi.com) → 120 Sekunden Timeout → Direkter Aufruf via
requests.
Zusammenfassung
Der Kernwert von gpt-image-2-all:
- Schließung der offiziellen Lücke: Bietet eine produktionsreife Schnittstelle für den stabilen Aufruf der neuesten Bilderzeugungsfunktionen von ChatGPT, noch bevor OpenAI die
gpt-image-2API offiziell freigibt. - Kosten deutlich unter dem erwarteten offiziellen Preis: $0,03 pro Aufruf gegenüber geschätzten $0,15–$0,20 der offiziellen API – ein entscheidender Kostenvorteil bei Batch-Szenarien.
- Design für nahtlose Migration: Basierend auf dem OpenAI-kompatiblen Protokoll ist am Tag der offiziellen Veröffentlichung lediglich ein Austausch des Modellnamens erforderlich.
Für Entscheidungsträger in Teams gilt die Empfehlung: Integrieren Sie gpt-image-2-all umgehend über APIYI (apiyi.com), um Ihre Geschäftsprozesse zu validieren. Die aktuelle Preisgestaltung von $0,03 pro Aufruf macht groß angelegte Tests nahezu kostenneutral. Sobald das offizielle gpt-image-2 verfügbar ist, können Sie bei Bedarf einfach wechseln – Teams, die frühzeitig agieren, sichern sich einen signifikanten Produktvorteil beim Start des neuen Modells.
Online-Erlebnis: imagen.apiyi.com · Dokumentation: docs.apiyi.com/api-capabilities/gpt-image-2-all/overview
Weiterführende Artikel
Wenn Sie sich für gpt-image-2-all interessieren, empfehlen wir folgende Lektüre:
- 📘 gpt-image-2 vs. gpt-image-1.5: Die acht wichtigsten Upgrades im Detail – Verstehen Sie die Hintergründe der Leistungssteigerung.
- 📊 Die sechs wichtigsten Anwendungsszenarien für gpt-image-2 – Meistern Sie den Weg zur praktischen Umsetzung.
- 🚀 gpt-image-2 vs. Nano Banana Pro: Ein tiefgreifender Vergleich – Treffen Sie eine rationale Entscheidung für das optimale Modell.
📚 Referenzmaterialien
-
Offizielle APIYI-Dokumentation: Vollständige technische Spezifikationen für gpt-image-2-all
- Link:
docs.apiyi.com/api-capabilities/gpt-image-2-all/overview - Beschreibung: Offizielle, maßgebliche Integrationsdokumentation, inklusive Parametern, Fehlercodes und Best Practices.
- Link:
-
APIYI Online-Playground: imagen.apiyi.com
- Link:
imagen.apiyi.com - Beschreibung: Testen Sie die Bilderzeugungs-Ergebnisse von gpt-image-2-all ganz ohne Programmierung.
- Link:
-
Offizielle OpenAI Bild-API-Dokumentation: Aktuelle API für Bildmodelle
- Link:
openai.com/index/image-generation-api - Beschreibung: Vergleich der Spezifikationen der offiziellen OpenAI gpt-image-1.5 API.
- Link:
-
LM Arena Graustufentest-Beobachtungen: Informationen zu GPT Image 2
- Link:
mindstudio.ai/blog/what-is-gpt-image-2 - Beschreibung: Vorschau auf die Fähigkeiten der nächsten Generation von Bildmodellen.
- Link:
Autor: APIYI Technik-Team
Technischer Austausch: Wir freuen uns auf Ihre Diskussionen in den Kommentaren. Weitere Informationen finden Sie im APIYI-Dokumentationszentrum unter docs.apiyi.com.