Der Markt für große Sprachmodelle für Code wird 2026 von zwei grundlegend unterschiedlichen Produktkategorien dominiert: Einerseits gibt es die „IDE-fokussierten, auf hochfrequente Vervollständigung ausgelegten“ Modelle wie Mistral Codestral 2 (aktuelle Version Codestral 25.08). Diese konzentrieren sich auf Fill-in-the-Middle (FIM), hohe Akzeptanzraten bei Vervollständigungen und sofortige Antworten für über 80 Programmiersprachen. Andererseits stehen die „langstreckenorientierten Agenten-Modelle“ wie Zhipu GLM-5.1, die auf einer 744B-Parameter-MoE-Architektur und einem 200K-Kontextfenster basieren und auf komplexe Programmieraufgaben auf SWE-Bench-Pro-Niveau (z. B. „8 Stunden autonome technische Aufgaben“) spezialisiert sind.
Obwohl sich die Zielgruppen und Preisstrategien dieser beiden Ansätze kaum überschneiden, werden sie häufig bei der Frage „Welches Modell eignet sich besser zum Programmieren?“ miteinander verglichen. Basierend auf offiziellen Ankündigungen von Mistral AI (25.07.2025, Codestral 25.08) und den Entwicklerdokumentationen von Z.ai (GLM-5.1, veröffentlicht am 27.03.2026) sowie weiteren englischsprachigen Primärquellen bietet dieser Artikel eine reproduzierbare Entscheidungsmatrix anhand von sechs Dimensionen: Architektur, Benchmarks, Kontext, Langstreckenaufgaben, Bereitstellung und Preis. Zudem finden Sie Vergleichscode für die API-Anbindung beider Modelle, damit Sie Ihre Entscheidung innerhalb von 10 Minuten treffen können.
Kernunterschiede in der Positionierung von Codestral 2 und GLM-5.1
Bevor wir uns in die Benchmarks stürzen, müssen wir eines klarstellen: Die beiden Modelle gehören nicht zur gleichen Produktkategorie. Ein direkter Vergleich auf derselben Ebene führt zu irreführenden Ergebnissen.
Kurz gefasst
- Codestral 2 (25.08): Ein spezialisiertes Code-Modell für Code-Vervollständigung und Bearbeitungsaufgaben. Mit einer 22B-Dichte-Architektur, nativem FIM-Trainingsziel und Fokus auf „Reaktionszeit im Sekundenbereich + hohe Akzeptanzrate“ ist es ein De-facto-Standard für IDE-Copilot-Produkte.
- GLM-5.1: Ein allgemeines Flaggschiff-Modell für allgemeine Agenten- und Langstrecken-Programmieraufgaben. Mit 744B MoE (ca. 40B aktivierte Parameter pro Token) und 200K Kontextfenster übertraf es mit 58,4 Punkten auf dem SWE-Bench Pro Modelle wie GPT-5.4, Claude Opus 4.6 und Gemini 3.1 Pro.
Drei Fragen, die Sie vor der Auswahl beantworten müssen
| Frage | Tendenz zu Codestral 2 | Tendenz zu GLM-5.1 |
|---|---|---|
| Hauptanwendungsfall: IDE-Vervollständigung oder autonomes PR-Erstellen? | IDE-Vervollständigung | Mehrstufige autonome Aufgaben |
| Token-Volumen pro Anfrage: Dutzende oder Zehntausende? | Dutzende bis Tausende | Tausende bis Zehntausende |
| Können Sie bei der Wartezeit Dutzende Sekunden tolerieren? | Nein | Ja |
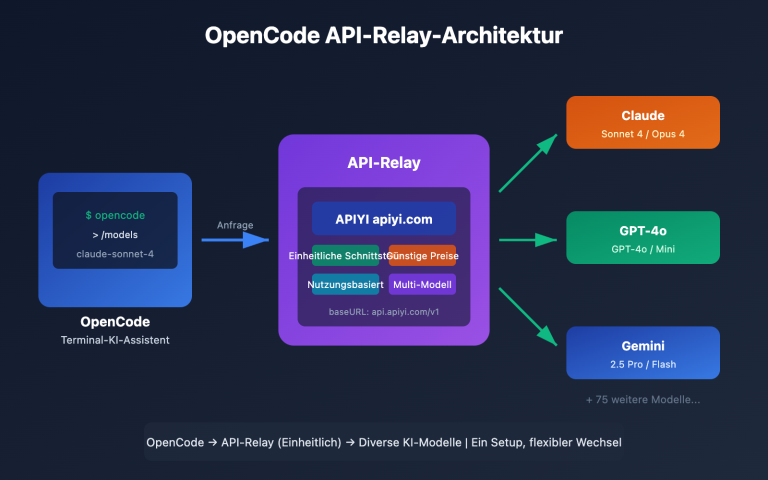
🎯 Auswahlempfehlung: Wenn 80 % Ihrer Aufrufe aus der „Vervollständigung des nächsten Schritts beim Schreiben einer Zeile“ bestehen, wählen Sie Codestral 2. Wenn 80 % Ihrer Aufrufe darauf abzielen, „einen Fehler in diesem Repository zu beheben“, wählen Sie GLM-5.1. Beide können über die einheitliche Schnittstelle von APIYI (apiyi.com) parallel getestet werden, ohne dass eine separate Anbindung an Mistral und Z.ai erforderlich ist.
Architektur- und Parametervergleich von Codestral 2 und GLM-5.1
Architektonische Unterschiede bilden das Fundament für die gesamte nachfolgende Performance.
Wichtige Spezifikationen im Überblick
| Punkt | Codestral 2 (25.08) | GLM-5.1 |
|---|---|---|
| Hersteller | Mistral AI | Zhipu AI (Z.ai) |
| Architektur | Dense Transformer | Mixture-of-Experts |
| Gesamtparameter | 22B | 744B |
| Aktivierte Parameter | 22B | ca. 40B (256 Experten, 8 pro Token aktiviert) |
| Kontextfenster | 256K | 200K |
| Max. Ausgabe | Standard | 128K Token |
| Aufmerksamkeitsmechanismus | Standard + FIM-Optimierung | DeepSeek Sparse Attention |
| Lizenz | Mistral kommerzielle Lizenz / MNPL | MIT (Open-Source-Gewichte) |
| Veröffentlichungsdatum | 30.07.2025 (neueste Iteration) | 27.03.2026 |
| Abdeckung Programmiersprachen | 80+ gängige Sprachen | Universell mehrsprachig |

Direkte Auswirkungen der architektonischen Unterschiede
- VRAM- und Bereitstellungskosten: Codestral 2 mit 22B kann auf einem einzelnen System (A100 80G) ausgeführt werden; GLM-5.1 erfordert parallele Multi-GPU-Setups oder verwaltete Inferenzdienste.
- Latenz pro Token: Die Dense-Architektur von Codestral 2 bietet eine stabilere Latenz bei kurzen Eingaben; GLM-5.1 ist aufgrund der Router-Auswahl und der spärlichen Aufmerksamkeit beim ersten Token etwas langsamer, bietet jedoch Vorteile bei langen Sequenzen.
- Open-Source-Strategie: GLM-5.1 veröffentlicht Gewichte unter der MIT-Lizenz, was für private Bereitstellungen und Nachtrainings vorteilhafter ist; Codestral 2 kann zwar lokal ausgeführt werden, erfordert jedoch für die kommerzielle Nutzung eine Lizenz.
🎯 Bereitstellungsempfehlung: Teams, die eine vollständig private Bereitstellung benötigen, sollten die MIT-Gewichte von GLM-5.1 bevorzugen. Teams, die eine schnelle Anbindung ohne Selbst-Hosting suchen, können die Modell-APIs beider Modelle direkt über APIYI (apiyi.com) aufrufen und sich so den Aufwand für Beschaffung und Lizenzverhandlungen sparen.
Codestral 2 vs GLM-5.1: Benchmark-Vergleich der Kern-Codebasis
Die Benchmarks beider Modelle stammen aus herstellerseitigen Tests, wobei sich die Testsets nicht vollständig überschneiden. Im Folgenden sind nur die Metriken mit direkter Vergleichbarkeit aufgeführt.
Codestral 2 Stärken: Vervollständigungsqualität & IDE-Metriken
| Metrik | Wert | Erläuterung |
|---|---|---|
| Accepted Completions (Akzeptanzrate) | +30% (relativ zu 25.01) | Akzeptanz in der Produktions-IDE |
| Retained Code (Beibehaltungsrate) | +10% | Anteil der Codevorschläge, die beim Commit nicht gelöscht wurden |
| Runaway Generations (Außer Kontrolle) | -50% | Rückgang bei übermäßig langen, nutzlosen Fortführungen |
| IFEval v8 (Befolgung von Anweisungen) | +5% | Genauigkeit der Anweisungsbefolgung |
| MultiPL-E Durchschnitt | +5% | Sprachübergreifende Code-Fähigkeiten |
| HumanEval (Vorgänger 25.01 Daten) | 86,6% | Referenzdaten |
| MBPP (Vorgänger 25.01 Daten) | 91,2% | Referenzdaten |
GLM-5.1 Stärken: Komplexe technische Aufgaben
| Metrik | Wert | Erläuterung |
|---|---|---|
| SWE-Bench Pro | 58,4 | Übertrifft GPT-5.4 / Claude Opus 4.6 / Gemini 3.1 Pro |
| Claude Code Vergleich | 45,3 (Opus 4.6 bei 47,9) | Erreicht 94,6% von Opus 4.6 |
| vs GLM-5 Baseline | +28% | Durch Post-Training-Optimierung |
| KernelBench Level 3 | 3,6x Beschleunigung | Optimierungsszenarien für ML-Kernel |
| Dauer pro Aufgabe | Bis zu 8 Stunden | Autonomer "Experiment-Analyse-Optimierung"-Zyklus |
Bewertung der Überschneidung der Fähigkeiten
| Fähigkeit | Codestral 2 | GLM-5.1 |
|---|---|---|
| Einzeldateivervollständigung | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| Refactoring über mehrere Dateien | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| Bug-Lokalisierung + PR-Fix | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| Sprachübergreifende Übersetzung | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Agent / Tool-Nutzung | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| Latenz des ersten Tokens | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
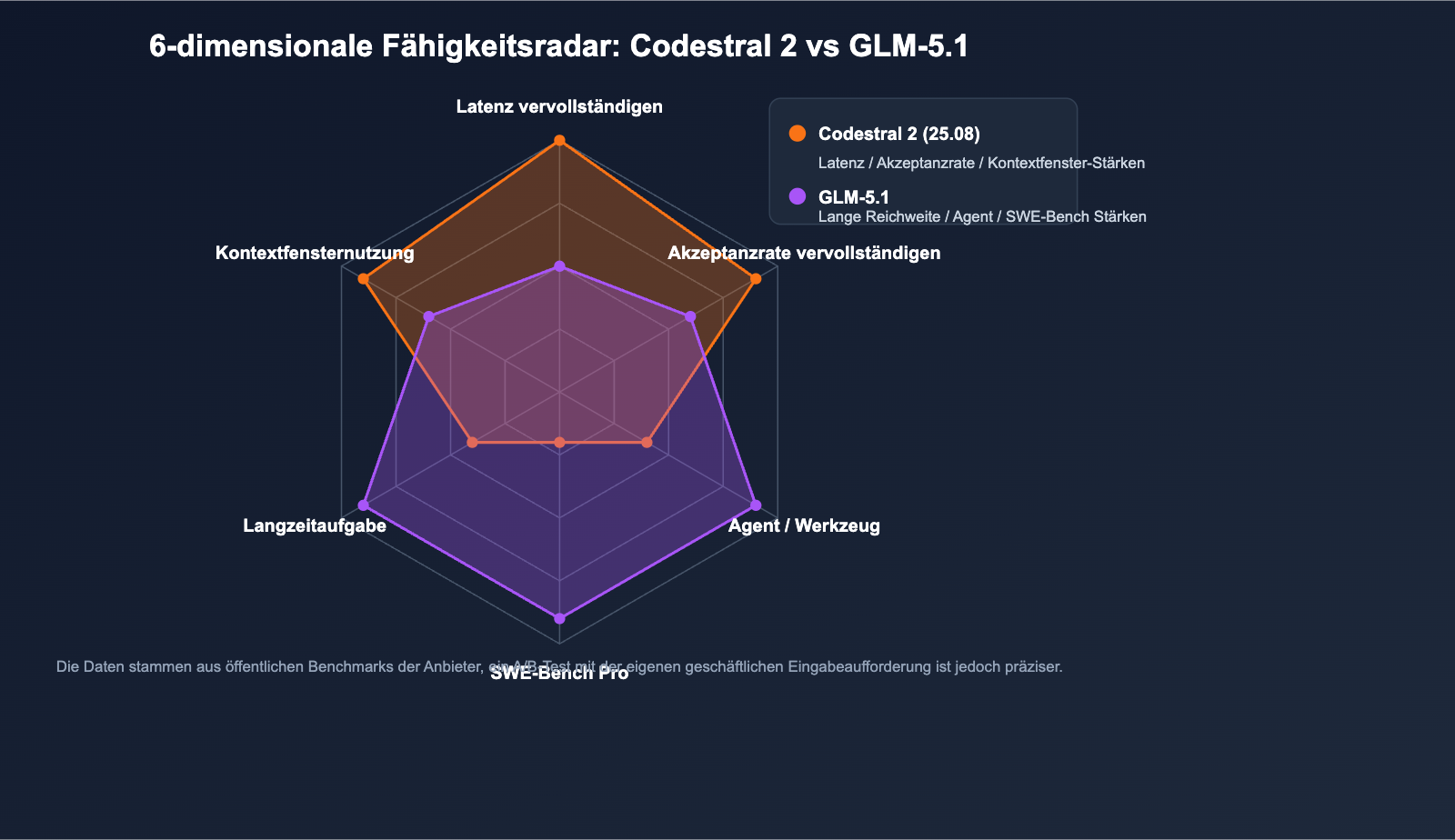
🎯 Lesehinweis zu Benchmarks: Offizielle Daten basieren meist auf optimalen Testeinstellungen; die tatsächliche Leistung kann um 10 % bis 20 % schwanken. Wir empfehlen, einen A/B-Test mit Ihrer eigenen Codebasis auf APIYI (apiyi.com) durchzuführen, bevor Sie eine endgültige Entscheidung treffen.
Codestral 2 vs. GLM-5.1: Kontext- und Langzeitaufgaben
Ein Kontextfenster von 256K gegenüber 200K klingt numerisch ähnlich, die unterstützten Aufgabentypen unterscheiden sich jedoch grundlegend.
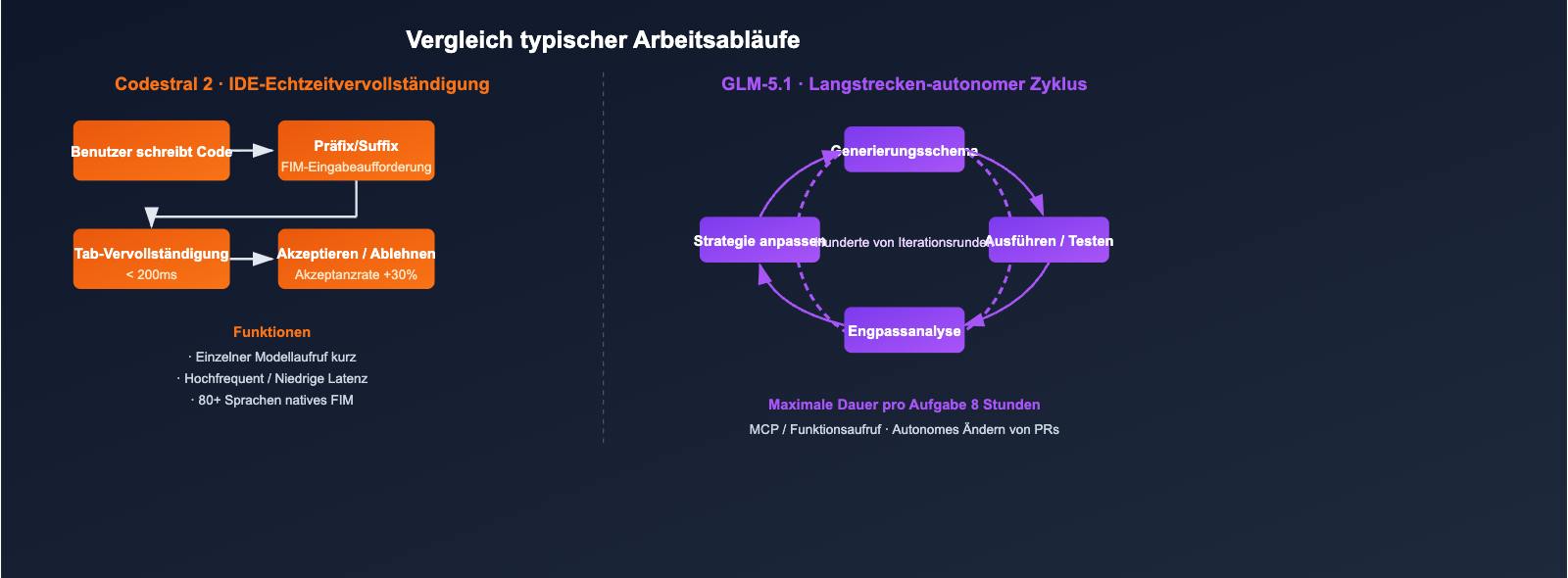
Codestral 2 (256K Kontext): Vervollständigung ganzer Repositories
Codestral 2 nutzt die 256K Kontext hauptsächlich, um "das gesamte Repository in die Eingabeaufforderung zu laden", damit Abhängigkeiten über Dateien hinweg bei der Vervollständigung erkannt werden:
- Geeignet für: Vervollständigung großer Funktionen innerhalb eines Monorepos, Lint-Fixes für das gesamte Projekt, Umbenennungen über Module hinweg.
- Nicht geeignet für: Agenten-Workflows, die mehrstufige Schlussfolgerungen, Tool-Aufrufe und Rückschreibungen erfordern.
GLM-5.1 (200K Kontext + 8 Stunden autonomer Zyklus)
Der Durchbruch von GLM-5.1 liegt nicht darin, "wie viel Kontext geladen werden kann", sondern "wie lange das Modell autonom arbeiten kann":
- In offiziellen Demos kann das Modell hunderte Male innerhalb einer einzigen Aufgabe iterieren: Benchmark ausführen → Engpässe identifizieren → Strategie anpassen → Benchmark erneut ausführen.
- DeepSeek Sparse Attention hält die Inferenzkosten für 200K lange Sequenzen in einem nutzbaren Bereich.
- Durch die Kombination mit Function Calling / MCP können externe Toolchains direkt angebunden werden.
Vergleich typischer Langzeitaufgaben
| Aufgabe | Codestral 2 | GLM-5.1 |
|---|---|---|
| Vervollständigung einer 200-Zeilen-Funktion | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| PR aus GitHub Issue generieren | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| Bug im gesamten Repo finden und beheben | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| Mehrstufige automatische Optimierung von ML-Kerneln | ⭐ | ⭐⭐⭐⭐⭐ |
| Tab-Vervollständigung in der IDE | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
🎯 Empfehlung zur Szenariomigration: Teams, die Codestral bisher für die Repository-Vervollständigung nutzen und auf das Problem "Code vervollständigt, aber Test schlägt fehl" stoßen, sollten GLM-5.1 für den "Generieren-Ausführen-Reparieren"-Zyklus in Betracht ziehen. Über APIYI (apiyi.com) lässt sich durch einfaches Ändern der
base_urlderselbe OpenAI-kompatible Code weiterverwenden.
Schnelleinstieg: Vergleich der API-Anbindung von Codestral 2 und GLM-5.1
Beide Modelle bieten OpenAI-kompatible Schnittstellen; die tatsächlichen Unterschiede liegen primär in den Modellnamen und Parametern. Das folgende Beispiel zeigt den minimalen, ausführbaren Code unter Verwendung der einheitlichen base_url von APIYI (apiyi.com).
Codestral 2 Aufruf (Code-Vervollständigung)
from openai import OpenAI
client = OpenAI(
base_url="https://api.apiyi.com/v1",
api_key="YOUR_API_KEY",
)
resp = client.chat.completions.create(
model="codestral-latest", # Verweist auf Codestral 25.08
messages=[
{"role": "system", "content": "Du bist ein erfahrener Python-Entwickler."},
{"role": "user", "content": "Vervollständige eine performante LRU-Cache-Implementierung."},
],
temperature=0.2,
max_tokens=512,
)
print(resp.choices[0].message.content)
GLM-5.1 Aufruf (Langzeitaufgaben)
from openai import OpenAI
client = OpenAI(
base_url="https://api.apiyi.com/v1",
api_key="YOUR_API_KEY",
)
resp = client.chat.completions.create(
model="glm-5.1",
messages=[
{"role": "system", "content": "Du bist ein SWE-Agent. Analysiere Repos, führe Tests aus und iteriere."},
{"role": "user", "content": "Repariere alle fehlgeschlagenen Testfälle in tests/test_api.py des Repos."},
],
temperature=0.3,
max_tokens=8192,
# GLM-5.1 unterstützt Function Calling + strukturierte Ausgabe
)
print(resp.choices[0].message.content)
📎 Ausklappen für FIM-spezifische Aufrufe (exklusiv für Codestral 2)
# Codestral natives FIM (Fill-In-the-Middle) durch Zusammenfügen von Präfix/Suffix
prefix = "def binary_search(arr, target):\n "
suffix = "\n return -1"
prompt = f"[PREFIX]{prefix}[SUFFIX]{suffix}[MIDDLE]"
# Sende den Prompt als User-Inhalt an codestral-latest für hochpräzise Vervollständigung
🎯 Anbindungsempfehlung: Beide Modelle folgen dem OpenAI-Schema. Sie können denselben Geschäftscode wiederverwenden, indem Sie einfach den Modellnamen austauschen. Die zentrale Nutzung über APIYI (apiyi.com) spart Wartungskosten für die separate Verwaltung von Mistral Console- und Z.ai-Konten, Guthaben und Ratenbegrenzungen.
Preisgestaltung und Bereitstellungsstrategien für Codestral 2 und GLM-5.1
Preisgestaltung und Flexibilität bei der Bereitstellung sind oft die entscheidenden Faktoren für die finale Entscheidung.
Öffentliche Preisübersicht
| Modell | Preis pro Input (1M) | Preis pro Output (1M) | Anmerkung |
|---|---|---|---|
| Codestral 2 (25.08) | $0,20 | $0,60 | Übernimmt die Preisgestaltung der Codestral-Serie |
| GLM-5.1 | Ab ca. $3 (Coding-Plan) | Paketbasiert | Option zur tokenbasierten Abrechnung verfügbar |
Hinweis: Die oben genannten Preise basieren auf öffentlichen Informationen der Hersteller und Kanäle. Aktuelle Wechselkurse und Aktionen sind maßgeblich.
Vergleich der Bereitstellungsoptionen
| Bereitstellungsart | Codestral 2 | GLM-5.1 |
|---|---|---|
| Offizielle Cloud-API | ✅ Mistral Console | ✅ Z.ai-Plattform |
| Drittanbieter-Gateway | ✅ (APIYI apiyi.com etc.) | ✅ (APIYI apiyi.com etc.) |
| VPC / Private Cloud | ✅ Lizenz erforderlich | ✅ MIT freie Bereitstellung |
| Lokale Inferenz | ✅ Einzelne A100/Consumer-GPU begrenzt | ❌ Benötigt mehrere Karten |
| Function Calling | Unterstützt (via Chat Completions) | ✅ Nativ unterstützt + MCP |
🎯 Empfehlung zur Kostenoptimierung: Für IDE-Szenarien mit hoher Frequenz und geringer Token-Anzahl pro Aufruf ist Codestral 2 mit Caching zu bevorzugen. Für Agenten-Szenarien mit niedriger Frequenz, aber hohem Token-Verbrauch, ist das Paketmodell von GLM-5.1 wirtschaftlicher. Beide Strategien können bei APIYI (apiyi.com) modellgruppenweise konfiguriert werden, um zu verhindern, dass das Gesamtkonto durch ein einzelnes Modell erschöpft wird.
Codestral 2 und GLM-5.1: Szenarien-Empfehlungen und Fallstricke
Entscheidungshilfe für vier typische Szenarien
| Szenario | Empfohlenes Modell | Hauptgrund |
|---|---|---|
| VSCode / JetBrains Autocomplete-Plugin | Codestral 2 | Natives FIM + geringe Latenz |
| Automatisierte Bug-Fixes / PR-Bots | GLM-5.1 | Autonome Langzeit-Zyklen |
| Code-Review-Assistent (Einzeldatei) | Codestral 2 | Schnelle Antwort, niedrige Kosten |
| End-to-End Agent (Test/Deployment) | GLM-5.1 | MCP + Function Calling |
| Generierung von Boilerplate-Projektgerüsten | Beide | Beide Modelle sind geeignet |
| ML-Kernel-Performance-Optimierung | GLM-5.1 | 3,6-fache Beschleunigung bei KernelBench |
Liste häufiger Fallstricke
- ❌ Verwenden Sie Codestral 2 nicht für Agenten: Obwohl die Rate an unkontrollierter Generierung um 50 % gesunken ist, ist es nicht für mehrstufige Entscheidungsfindungen optimiert.
- ❌ Verwenden Sie GLM-5.1 nicht für Millisekunden-Autocomplete: Die Latenz bis zum ersten Token beeinträchtigt das Erlebnis bei der Tab-Taste in der IDE.
- ❌ Verlassen Sie sich nicht auf nur ein Ranking: GLM-5.1 gewinnt bei SWE-Bench Pro, aber die Codestral-Serie steht bei HumanEval in nichts nach.
- ✅ Führen Sie einen kleinen A/B-Test durch: Testen Sie 100 typische Eingabeaufforderungen aus Ihrem Geschäftsbereich und vergleichen Sie die Ergebnisse, indem Sie die Modellparameter über APIYI (apiyi.com) umschalten.
Häufig gestellte Fragen (FAQ)
F1: Warum heißt es auf der offiziellen Seite Codestral 25.08 und nicht Codestral 2?
Die Namenskonvention von Mistral lautet <Serie>-<Jahr>.<Monat>. Codestral 25.08 gehört zur zweiten Generation von Codestral (die erste Generation wurde im Mai 2024 veröffentlicht, die zweite Generation entwickelte sich ab Januar 2025 bis August 2025). In der Branche und Community wird 25.01+ allgemein als „Codestral 2“ bezeichnet. Geben Sie beim Modellaufruf einfach codestral-latest an, um die aktuellste Version der zweiten Generation zu erhalten.
F2: Ist die Inferenz bei den 744B Parametern von GLM-5.1 nicht sehr langsam?
Dank der MoE-Architektur werden pro Token nur 40B Parameter aktiviert. In Kombination mit DeepSeek Sparse Attention nähert sich die tatsächliche Inferenzgeschwindigkeit der eines dichten 40B-Modells an. In Verbindung mit den Langverbindungs- und Caching-Strategien von APIYI (apiyi.com) ist die wahrgenommene Latenz bei Szenarien mit langem Kontext akzeptabel.
F3: Welches Modell nutzt das Kontextfenster besser aus?
Die 256K von Codestral 2 sind eher als „Kapazität“ zu verstehen, während die 200K von GLM-5.1 in Kombination mit Sparse Attention eine „effektivere Auslastung“ bieten. Vor der Durchführung von Aufgaben über das gesamte Repository hinweg empfiehlt es sich, die tatsächliche Anzahl der Token mit tiktoken oder dem offiziellen Tokenizer zu schätzen, um ineffektive Kürzungen zu vermeiden.
F4: Welche praktische Bedeutung haben Open-Weights-Modelle für Unternehmen?
GLM-5.1 wurde mit MIT-Lizenz veröffentlicht und kann im internen Netzwerk bereitgestellt und nachtrainiert werden; für die kommerzielle Nutzung von Codestral 2 ist eine Lizenzvereinbarung erforderlich. Für Finanz- und Behördenkunden mit strengen Compliance-Anforderungen ist dies ein entscheidender Unterschied. Wenn es lediglich darum geht, regionale Zugriffsbeschränkungen zu umgehen, bietet APIYI (apiyi.com) zudem einen stabilen Zugang.
F5: Können beide Modelle gleichzeitig verwendet werden?
Ja, das ist sogar empfehlenswert. Ein typischer Ansatz ist: IDE-Autocomplete mit Codestral 2, Backend-Agent mit GLM-5.1. Beide nutzen unterschiedliche Modell-Keys und werden zentral über APIYI (apiyi.com) abgerechnet.
F6: Die Benchmarks stammen vom Hersteller – wie glaubwürdig sind sie?
Die Benchmarks von Codestral und GLM sind selbst berichtet. Der Wert von 58,4 Punkten bei Z.ai's SWE-Bench Pro wurde bisher nicht unabhängig verifiziert. Es wird empfohlen, öffentliche Benchmarks als „Obergrenze der Leistungsfähigkeit“ zu betrachten und vor dem produktiven Einsatz unbedingt Regressionstests in Ihren eigenen Geschäftsszenarien durchzuführen.
Zusammenfassung: Empfehlung zur endgültigen Auswahl zwischen Codestral 2 und GLM-5.1
Kommen wir zurück auf die drei eingangs gestellten Fragen:
- Wenn Ihr Produkt auf Copilot, Tab-Vervollständigung oder die Generierung von Code-Snippets ausgerichtet ist, wählen Sie Codestral 2. Seine FIM-Fähigkeiten (Fill-In-the-Middle), die geringe Latenz, das Preis-Leistungs-Verhältnis und die Abdeckung von über 80 Sprachen machen es zur optimalen Wahl für diese Szenarien.
- Wenn Ihr Produkt ein PR-Bot, ein Bug-Fixing-Agent oder ein Hintergrund-Agent für 8-Stunden-Aufgaben ist, wählen Sie GLM-5.1. Mit 744B MoE, einem SWE-Bench Pro-Wert von 58,4 und der Fähigkeit zu autonomen Langzeit-Zyklen ist es derzeit die Open-Source-Option, die Claude Opus 4.6 am nächsten kommt.
- Wenn Ihr Produkt beide Szenarien abdeckt, ist die Kombination beider Modelle die wirtschaftlichste Lösung für das Jahr 2026.
🎯 Implementierungsempfehlung: Erweitern Sie Ihre Auswahlstrategie von einem "Entweder-oder" hin zu einer "Dual-Modell-Orchestrierung". Über die OpenAI-kompatible Schnittstelle von APIYI (apiyi.com) können Sie in Ihrem Business-Code einfach über ein Feld zwischen "Kurz-Vervollständigung" und "Langzeit-Aufgabe" unterscheiden. So werden Anfragen automatisch an das jeweils am besten geeignete Modell – Codestral 2 oder GLM-5.1 – weitergeleitet.
— APIYI Team (Technisches Team von APIYI apiyi.com)