Wer schon einmal mit Qwen3.6-Plus gearbeitet hat, kennt das Problem: Bei der Nutzung über OpenRouter gehört der Fehler „429 Too Many Requests“ fast schon zum Alltag. Obwohl man bezahlt hat und kein Free-Tier-Nutzer ist, wird man so stark gedrosselt, dass man an allem zweifelt.
Kernnutzen: Dieser Artikel analysiert die Grundursachen für den 429-Fehler bei Qwen3.6-Plus, bietet drei praxiserprobte Lösungen und zeigt, wie Sie über den offiziellen API-Proxy-Dienst von Alibaba Cloud stabile und kostengünstige Modellaufrufe realisieren.
Kernpunkte zum 429-Fehler bei Qwen3.6-Plus
| Punkt | Beschreibung | Nutzen für Entwickler |
|---|---|---|
| Ursachenanalyse 429 | Hohe Nachfrage + Missbrauch durch Free-Tier + Rechenkapazitäts-Strategie | Verstehen des Problems, kein blindes Neuversuchen |
| 3 Lösungswege | Wiederholungsstrategie / Kanalwechsel / Offizieller Proxy | Wahl des optimalen Pfads je nach Szenario |
| Leistungstest | Latenzvergleich von Qwen3.6-Plus über verschiedene Kanäle | Auswahl der stabilsten Anbindung |
| Code-Beispiele | Python/Node.js sofort ausführbar | Migration in 5 Minuten erledigt |
Warum ist Qwen3.6-Plus so beliebt?
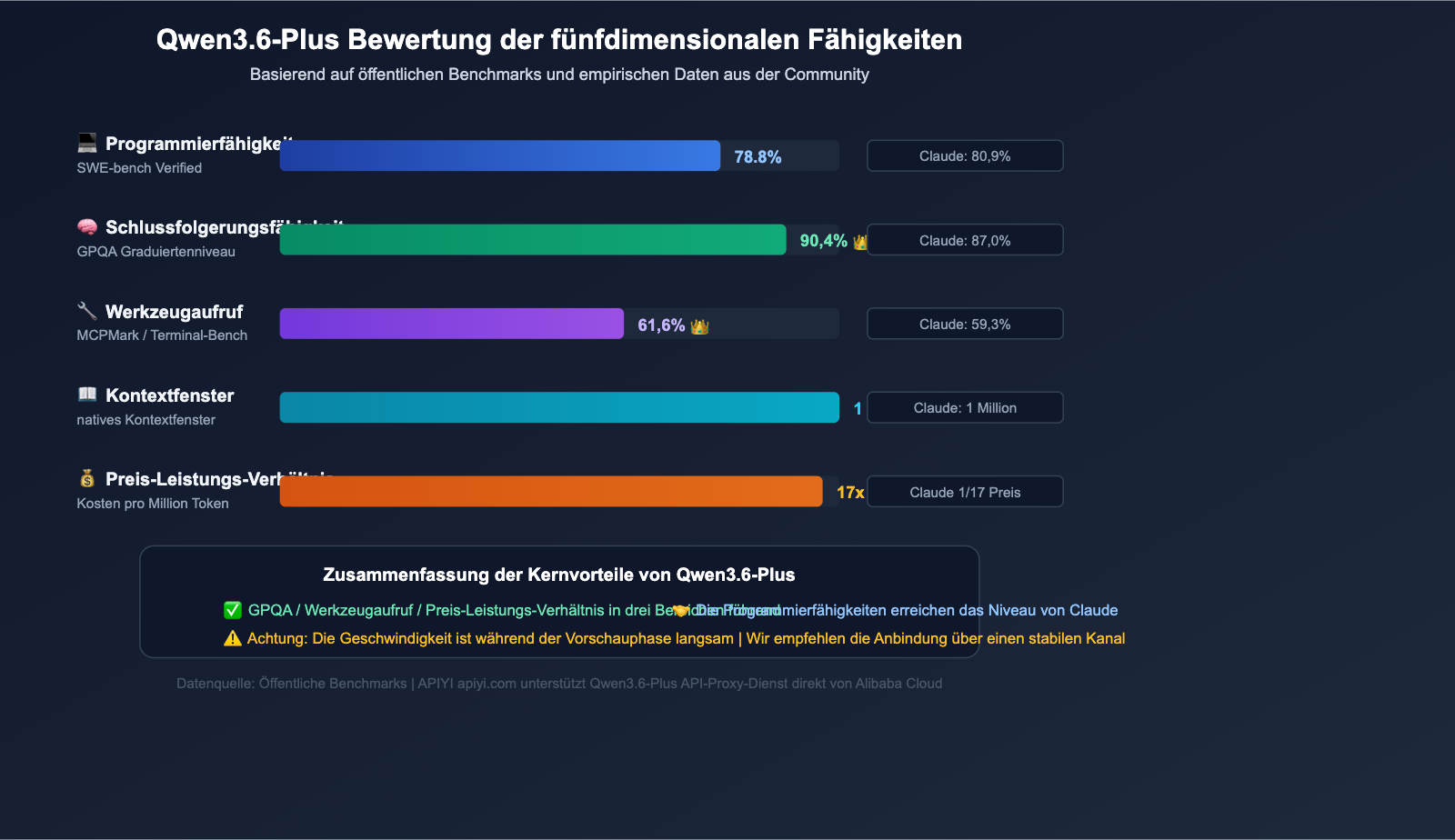
Qwen3.6-Plus ist das Flaggschiff-Modell, das vom Alibaba Tongyi Qianwen Team im April 2026 veröffentlicht wurde und direkt mit Claude Opus 4.5 und GPT-5.4 konkurriert. Der Grund für den Erfolg ist einfach: hohe Leistung bei niedrigem Preis.
| Benchmark | Qwen3.6-Plus | Claude Opus 4.5 | GPT-5.4 |
|---|---|---|---|
| SWE-bench Verified | 78,8% | 80,9% | 76,2% |
| Terminal-Bench 2.0 | 61,6% | 59,3% | 57,8% |
| GPQA (Wissenschaft auf Uni-Niveau) | 90,4% | 87,0% | 88,1% |
| MCPMark (Tool-Aufrufe) | 48,2% | 45,6% | 43,9% |
| Kontextfenster | 1 Mio. Token | 1 Mio. Token | 256.000 Token |
| Maximale Ausgabe | 65.536 Token | 32.000 Token | 16.384 Token |
Bei den wichtigen Benchmarks Terminal-Bench und GPQA übertrifft Qwen3.6-Plus sogar Claude Opus 4.5, während der offizielle API-Preis nur etwa 1/17 von Claude beträgt. Dieses Preis-Leistungs-Verhältnis hat die Nachfrage unter Entwicklern explodieren lassen – was genau die Wurzel des 429-Problems ist.
Tiefenanalyse des 429-Fehlers bei Qwen3.6-Plus
Was ist ein 429-Fehler?
Der HTTP-Statuscode 429 ist eindeutig: Too Many Requests (Zu viele Anfragen). Dieser Fehler tritt auf, wenn ein Server innerhalb eines bestimmten Zeitraums mehr Anfragen erhält, als er verarbeiten kann oder als durch vordefinierte Limits erlaubt sind.
Eine typische 429-Fehlermeldung sieht so aus:
{
"error": {
"code": 429,
"message": "Rate limit exceeded. Please slow down your requests.",
"metadata": {
"provider_name": "Qwen",
"raw": "{\"error\":{\"message\":\"Rate limit reached\",\"type\":\"rate_limit_error\"}}"
}
}
}
Die 4 Hauptgründe für häufige 429-Fehler bei Qwen3.6-Plus auf OpenRouter
Grund 1: Die Nachfrage übersteigt das Angebot bei weitem
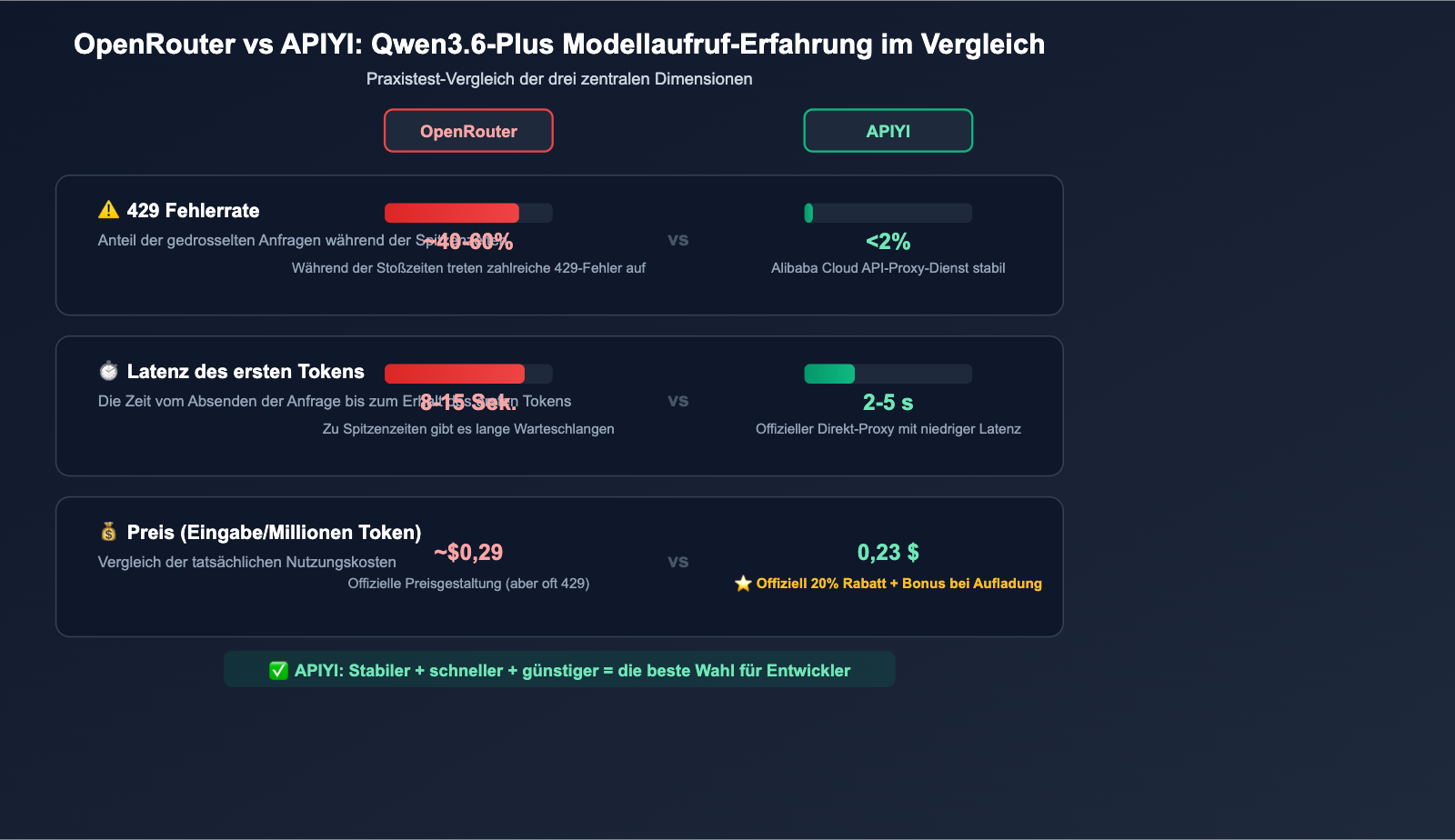
Das Preis-Leistungs-Verhältnis von Qwen3.6-Plus ist extrem attraktiv. Die offizielle API-Preisgestaltung liegt bei etwa 0,29 $ pro 1 Million Eingabe-Token – das ist nur 1/17 des Preises von Claude Opus 4.5. Dies lockt eine enorme Anzahl an Entwicklern an, während OpenRouter als API-Proxy-Dienst nur über ein begrenztes Rechenkontingent von Alibaba Cloud verfügt.
Grund 2: Hohe Auslastung durch Nutzer des kostenlosen Tarifs
OpenRouter bietet das kostenlose Modell qwen/qwen3.6-plus:free an, was viele Nutzer ohne Budget anzieht. Diese kostenlosen Anfragen teilen sich denselben Ressourcenpool wie die kostenpflichtigen Anfragen, was dazu führt, dass auch zahlende Kunden unter den Einschränkungen leiden.
Grund 3: Konservative Zuteilung der Rechenleistung während der Vorschauphase
Qwen3.6-Plus befand sich zum Zeitpunkt der Analyse noch in der Vorschauphase (Vorschau am 30. März veröffentlicht, offizielle Veröffentlichung am 2. April). Alibaba Cloud ist bei der Zuteilung von Rechenleistung an Drittplattformen während der Vorschauphase meist konservativ, um die Servicequalität der eigenen Plattformen (DashScope / Bailian) zu priorisieren.
Grund 4: Engpässe bei der Inferenzgeschwindigkeit des Modells selbst
Obwohl Community-Tests zeigen, dass der Durchsatz von Qwen3.6-Plus etwa dreimal so hoch ist wie der von Claude Opus 4.6, bleibt die Antwortlatenz bei komplexen Agenten-Aufgaben aufgrund des 1-Million-Token-Kontextfensters und der MoE-Architektur spürbar. Das bedeutet, dass jede Anfrage die GPU länger belegt, wodurch die Gesamtzahl der Anfragen, die pro Zeiteinheit verarbeitet werden können, sinkt.

🎯 Kern-Erkenntnis: Ein 429-Fehler liegt nicht an Ihrem Code, sondern an einem Ungleichgewicht zwischen Angebot und Nachfrage. Die Lösung besteht darin, einen Kanal mit ausreichend Kapazität zu wählen, anstatt unendlich viele Wiederholungsversuche zu starten. Durch die Anbindung über APIYI (apiyi.com) an den offiziellen Direktkanal von Alibaba Cloud können Sie die Ratenbegrenzung von OpenRouter effektiv umgehen.
Qwen3.6-Plus 429-Fehlerlösung 1: Intelligente Wiederholungsstrategie
Exponentielles Backoff-Retry
Wenn Sie den Kanal nicht kurzfristig wechseln können, kann eine sinnvolle Wiederholungsstrategie das 429-Problem abmildern (wenn auch nicht vollständig beheben):
import openai
import time
import random
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI einheitliche Schnittstelle, direkte Weiterleitung über Alibaba Cloud
)
def call_qwen36_with_retry(messages, max_retries=5):
"""Qwen3.6-Plus Aufruf mit exponentiellem Backoff"""
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=messages,
max_tokens=4096
)
return response.choices[0].message.content
except openai.RateLimitError as e:
if attempt == max_retries - 1:
raise
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"429 Ratenbegrenzung, {attempt+1}. Versuch, warte {wait_time:.1f}s...")
time.sleep(wait_time)
# Anwendungsbeispiel
result = call_qwen36_with_retry([
{"role": "user", "content": "Analysiere die Performance-Engpässe dieses Codes"}
])
print(result)
Empfehlungen für Wiederholungsparameter
| Parameter | Empfohlener Wert | Erläuterung |
|---|---|---|
| Max. Wiederholungen | 3-5 Mal | Mehr als 5 Versuche deuten auf einen instabilen Kanal hin |
| Anfängliche Wartezeit | 1-2 Sekunden | Zu kurz ist ineffektiv, zu lang verschwendet Zeit |
| Backoff-Faktor | 2x | Exponentielles Backoff ist Industriestandard |
| Zufälliger Jitter | 0-1 Sekunde | Vermeidet den „Thundering Herd“-Effekt |
| Timeout-Limit | 30 Sekunden | Einzelne Wartezeit sollte 30 Sekunden nicht überschreiten |
Grenzen der Wiederholungsstrategie
Es muss klar sein: Wiederholungen sind nur ein Schmerzmittel, keine Heilung. Wenn das Backend von OpenRouter für Qwen3.6-Plus dauerhaft überlastet ist, sinkt die Erfolgsquote drastisch. Die grundlegendere Lösung ist der Wechsel zu einem API-Kanal mit ausreichenden Kapazitäten.
Qwen3.6-Plus 429-Fehlerlösung 2: API-Kanal wechseln
Warum ein Kanalwechsel effektiver ist als Wiederholungen
Die häufigen 429-Fehler bei OpenRouter liegen im Kern an unzureichenden Rechenkontingenten für Qwen3.6-Plus. Der Wechsel zu einem Kanal, der direkt an die Rechenleistung von Alibaba Cloud angebunden ist, löst das Problem an der Wurzel.
Vergleich der Qwen3.6-Plus API-Kanäle
| Kanal | Stabilität | Preis (Input/Mio. Token) | 429-Frequenz | Datenerfassung |
|---|---|---|---|---|
| OpenRouter Free | Schlecht | Kostenlos | Sehr hoch | Ja (Trainingsdaten) |
| OpenRouter Paid | Mittel | ~$0.29 | Häufig | Ja (Vorschauphase) |
| Alibaba Bailian | Gut | ¥2.00 | Niedrig | Je nach Vertrag |
| APIYI (Alibaba Direkt) | Gut | Offiziell 20% Rabatt | Niedrig | Nein |
💡 Empfehlung: Wenn Ihre Anwendung Stabilität erfordert, empfehlen wir die Anbindung von Qwen3.6-Plus über APIYI (apiyi.com). Die Plattform nutzt den offiziellen direkten Kanal von Alibaba Cloud, bietet Preise mit 20 % Rabatt auf den offiziellen Tarif (Gruppenrabatt 0,88 + 10 $ Bonus bei 100 $ Aufladung) und vermeidet die Ratenbegrenzungen von OpenRouter.
Migration von OpenRouter zu APIYI in nur 2 Zeilen Code
Die Migrationskosten sind minimal; Sie müssen lediglich base_url und api_key anpassen:
import openai
# ❌ Vorher: OpenRouter (häufig 429)
# client = openai.OpenAI(
# api_key="sk-or-v1-xxxx",
# base_url="https://openrouter.ai/api/v1"
# )
# ✅ Jetzt: APIYI Alibaba Direkt (stabil, keine 429)
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[
{"role": "system", "content": "Du bist ein professioneller Code-Review-Assistent"},
{"role": "user", "content": "Hilf mir, die Performance dieser SQL-Abfrage zu optimieren"}
],
max_tokens=8192
)
print(response.choices[0].message.content)
Node.js Version:
import OpenAI from 'openai';
const client = new OpenAI({
apiKey: 'YOUR_APIYI_KEY',
baseURL: 'https://api.apiyi.com/v1' // APIYI einheitliche Schnittstelle
});
const response = await client.chat.completions.create({
model: 'qwen3.6-plus',
messages: [
{ role: 'user', content: 'Analysiere die Zeitkomplexität dieses Codes' }
],
max_tokens: 4096
});
console.log(response.choices[0].message.content);
Qwen3.6-Plus 429 Fehlerlösung Teil 3: Lokale Anfrageoptimierung
Unnötige Modellaufrufe reduzieren
Neben dem Wechsel des Kanals kann auch die Optimierung Ihres Anfragemusters die Wahrscheinlichkeit für 429-Fehler senken:
1. Anfragen zusammenfassen
# ❌ Ineffizient: Einzeln senden
for item in data_list:
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[{"role": "user", "content": f"Analysieren: {item}"}]
)
# ✅ Effizient: Batch-Zusammenfassung
batch_content = "\n".join([f"{i+1}. {item}" for i, item in enumerate(data_list)])
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[{"role": "user", "content": f"Analysiere nacheinander die folgenden Inhalte:\n{batch_content}"}],
max_tokens=16384
)
2. Häufige Antworten zwischenspeichern
import hashlib
import json
_cache = {}
def cached_qwen_call(prompt, model="qwen3.6-plus"):
cache_key = hashlib.md5(f"{model}:{prompt}".encode()).hexdigest()
if cache_key in _cache:
return _cache[cache_key]
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
result = response.choices[0].message.content
_cache[cache_key] = result
return result
3. Ratenbegrenzung für Anfragewarteschlangen
| Optimierungsstrategie | Effekt | Einsatzszenario |
|---|---|---|
| Anfrage-Batching | Reduziert das Anfragevolumen um 60-80% | Stapelverarbeitung von Daten |
| Antwort-Caching | Null Modellaufrufe bei identischen Anfragen | Wiederholte Abfragen |
| Warteschlangen-Limitierung | Glättet Anfragespitzen | Hochkonkurrente Anwendungen |
| Fallback-Strategie | Automatischer Wechsel zu kleineren Modellen bei 429 | Latenzsensitive Dienste |
🔧 Technischer Hinweis: Die oben genannten lokalen Optimierungsstrategien funktionieren am besten in Kombination mit stabilen API-Kanälen. Durch die Anbindung von Qwen3.6-Plus über APIYI (apiyi.com) können Sie in Verbindung mit Batching- und Caching-Strategien die Stabilität erhöhen und gleichzeitig die Kosten weiter senken.
Analyse der Gründe für langsame Qwen3.6-Plus-Geschwindigkeit
Warum die Antwortzeit von Qwen3.6-Plus manchmal langsam ist
Viele Entwickler berichten, dass die Antwortgeschwindigkeit von Qwen3.6-Plus „unerklärlich langsam“ ist, selbst wenn keine 429-Fehler auftreten. Dies ist kein Einzelfall, sondern hat technische Gründe:
1. Inferenz-Overhead der MoE-Architektur
Qwen3.6-Plus verwendet eine Mixture-of-Experts (MoE) Architektur. Obwohl MoE die Trainingskosten erheblich senkt, entstehen während der Inferenzphase zusätzliche Kosten durch Routing-Entscheidungen und Expertenwechsel. Besonders bei der Verarbeitung langer Kontextfenster ist die Inferenz-Effizienz der MoE-Architektur geringer als bei Dense-Modellen gleicher Parametergröße.
2. Speicherbelastung durch 1 Million Token Kontext
Das 1-Million-Token-Kontextfenster ist ein Hauptverkaufsargument von Qwen3.6-Plus, bedeutet aber auch, dass der KV-Cache enorm viel GPU-Speicher belegt. Wenn mehrere Benutzer gleichzeitig Anfragen mit langem Kontext stellen, wird der GPU-Speicher zum Flaschenhals und die Inferenzgeschwindigkeit sinkt deutlich.
3. Begrenzte Rechenressourcen in der Vorschauphase
Qwen3.6-Plus befindet sich noch in der Vorschauphase. Alibaba stellt in dieser Phase in der Regel nicht die gleiche Rechenleistung zur Verfügung wie nach der offiziellen Veröffentlichung. Der Anbieter beobachtet möglicherweise erst die tatsächlichen Nutzungsmuster, bevor die Kapazitäten schrittweise erweitert werden.
4. Zusätzlicher Token-Verbrauch durch Always-On-Inferenzketten
Qwen3.6-Plus hat standardmäßig den Always-On Chain-of-Thought-Inferenzmodus aktiviert. Das bedeutet, dass das Modell bei jeder Antwort einen internen Denkprozess generiert; die tatsächlich generierte Token-Anzahl ist weit höher als die endgültige Ausgabe. Diese „versteckten Token“ beanspruchen zusätzliche Inferenzzeit.
Referenz zur Latenzmessung verschiedener Kanäle
| Kanal | Latenz bis zum ersten Token | Durchsatz (Token/s) | Anmerkung |
|---|---|---|---|
| OpenRouter (Spitzenlast) | 8-15s | 15-25 | Häufig 429 |
| OpenRouter (Nebenzeiten) | 3-5s | 30-50 | Nachtstunden |
| Alibaba Bailian | 2-4s | 40-60 | Direkte Verbindung (China) |
| APIYI (Direkt-Proxy) | 2-5s | 35-55 | Stabiler Zugriff aus dem Ausland |
💰 Kostentipp: Die Geschwindigkeit von Qwen3.6-Plus variiert je nach Kanal und Last stark. Wenn Sie latenzsensibel sind, empfehlen wir einen Praxistest über APIYI (apiyi.com). Die Plattform bietet offizielle Direkt-Proxy-Kanäle von Alibaba, mit denen Sie sowohl von 20% Rabatt als auch von einer stabileren Antwortgeschwindigkeit profitieren können.
Qwen3.6-Plus: Schneller Einstieg in die Praxis
Vollständiges Beispiel für den Modellaufruf von Qwen3.6-Plus über APIYI
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
# Einfacher Dialog
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[
{"role": "system", "content": "Du bist ein erfahrener Python-Entwicklungsexperte"},
{"role": "user", "content": "Hilf mir beim Schreiben eines leistungsstarken asynchronen Crawler-Frameworks"}
],
max_tokens=8192,
temperature=0.7
)
print(response.choices[0].message.content)
Vollständigen Code für Streaming-Ausgabe anzeigen
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
# Streaming-Ausgabe - ideal für Szenarien, die Echtzeit-Feedback erfordern
stream = client.chat.completions.create(
model="qwen3.6-plus",
messages=[
{"role": "system", "content": "Du bist ein erfahrener Softwarearchitekt"},
{"role": "user", "content": "Entwirf ein Nachrichtenwarteschlangensystem, das Millionen gleichzeitiger Anfragen unterstützt"}
],
max_tokens=16384,
temperature=0.7,
stream=True
)
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="", flush=True)
print() # Zeilenumbruch
🚀 Schnellstart: Wir empfehlen, den API-Schlüssel über die Plattform APIYI (apiyi.com) zu beziehen, um Qwen3.6-Plus aufzurufen. Registrieren Sie sich und legen Sie sofort los; bei einer Aufladung von 100 USD erhalten Sie 10 USD Bonus, und Qwen3.6-Plus ist dort zu 80 % des offiziellen Preises verfügbar.
Qwen3.6-Plus: Einsatzszenarien und Auswahlhilfe
Für welche Szenarien ist Qwen3.6-Plus besonders geeignet?
| Anwendungsszenario | Empfehlungsgrund | Alternative |
|---|---|---|
| Agent-Automatisierung | Führend mit 61,6 % bei Terminal-Bench, native Werkzeugnutzung | Claude Opus 4.5 |
| Code-Review/Fixes | 78,8 % bei SWE-bench, auf dem Niveau von Claude | Claude Opus 4.5 |
| Wissenschaftliche Schlussfolgerung | 90,4 % bei GPQA, Spitzenwert | GPT-5.4 |
| Verarbeitung langer Dokumente | 1 Million Token Kontextfenster | Gemini 2.5 Pro |
| Kostensensible Projekte | Etwa 1/17 des Preises von Claude | DeepSeek V3 |
In welchen Szenarien ist Vorsicht geboten?
- Echtzeitanwendungen mit extremer Latenzempfindlichkeit: Die MoE-Architektur von Qwen3.6-Plus weist bei langem Kontext eine höhere Latenz auf.
- Kritische Pfade in der Produktionsumgebung: Modelle in der Vorschauphase können unvorhersehbare Verhaltensänderungen aufweisen.
- Szenarien, die eine strikte SLA-Garantie erfordern: In der Vorschauphase gibt es keine offizielle SLA.
🎯 Auswahlhilfe: Für Projekte, die mehrere Modelle gleichzeitig nutzen, empfehlen wir die zentrale Anbindung über die Plattform APIYI (apiyi.com). Die Plattform unterstützt OpenAI-kompatible Schnittstellen für führende Modelle wie Qwen3.6-Plus, Claude und GPT. Mit einem einzigen API-Schlüssel können Sie flexibel zwischen verschiedenen Modellen wechseln und diese je nach Anwendungsfall optimal steuern.
Häufige Fragen zu 429-Fehlern bei Qwen3.6-Plus
F1: Warum erhalte ich trotz Guthaben bei OpenRouter weiterhin 429-Fehler?
Das liegt daran, dass sich zahlende Nutzer und kostenlose Nutzer bei OpenRouter einen gemeinsamen Rechenpool teilen. Selbst als zahlender Kunde werden Sie gedrosselt, wenn das gesamte Anfragevolumen das Rechenkontingent übersteigt, das OpenRouter von Alibaba Cloud bezieht. Die Lösung besteht darin, zu einem Kanal mit besserer Verfügbarkeit zu wechseln, wie etwa dem offiziellen API-Proxy-Dienst von Alibaba Cloud über APIYI (apiyi.com).
F2: Werden die 429-Fehler bei Qwen3.6-Plus bald besser?
Mit der Kapazitätserweiterung durch Alibaba Cloud und der offiziellen GA (General Availability) des Modells dürfte sich das 429-Problem entspannen. Da OpenRouter jedoch eine Plattform für Drittanbieter-Weiterleitungen ist, bleibt die Rechenkapazität stets durch das vorgelagerte Angebot begrenzt. Wenn Ihr Unternehmen auf Stabilität angewiesen ist, empfiehlt es sich, langfristig Kanäle mit direkter Anbindung an die Alibaba-Cloud-Rechenleistung zu nutzen, anstatt sich auf Proxy-Plattformen zu verlassen.
F3: Was unterscheidet Qwen3.6-Plus bei APIYI von OpenRouter?
Der Hauptunterschied liegt in der Quelle der Rechenleistung. Die Plattform APIYI (apiyi.com) nutzt den offiziellen API-Proxy-Dienst von Alibaba Cloud; die Rechenleistung stammt direkt von der Alibaba Bailian-Plattform und nicht aus einer Zwischenstation. Das bedeutet eine geringere Fehlerquote (429) und schnellere Antwortzeiten. Preislich bietet APIYI einen offiziellen Rabatt von 20 % (0,88-facher Gruppenrabatt + Auflade-Boni) und ist mit dem OpenAI-SDK-Format kompatibel, wodurch die Migrationskosten nahezu bei null liegen.
F4: Ist es normal, dass Qwen3.6-Plus langsam ist?
Die MoE-Architektur von Qwen3.6-Plus und das Kontextfenster von 1 Million Token erfordern bei der Inferenz tatsächlich mehr Ressourcen als Dense-Modelle. Da die Rechenkapazitäten in der Vorschauphase konservativ konfiguriert sind, ist eine gewisse Langsamkeit aktuell ein allgemeines Phänomen. Der absolute Durchsatz ist dennoch beachtlich; wir empfehlen die Nutzung von Streaming (stream=True), um die Nutzererfahrung zu verbessern.
F5: Wie verwende ich Qwen3.6-Plus in Claude Code?
Qwen3.6-Plus unterstützt sowohl das Anthropic- als auch das OpenAI-Protokoll. Sie können Qwen3.6-Plus nutzen, indem Sie die API-Endpunkt-Konfiguration in Claude Code anpassen. Bei der Anbindung über die Plattform APIYI (apiyi.com) verwenden Sie einfach das Standard-OpenAI-SDK-Format. Details zur Konfiguration finden Sie in der Dokumentation der Plattform.
Lösung für den 429-Fehler bei Qwen3.6-Plus
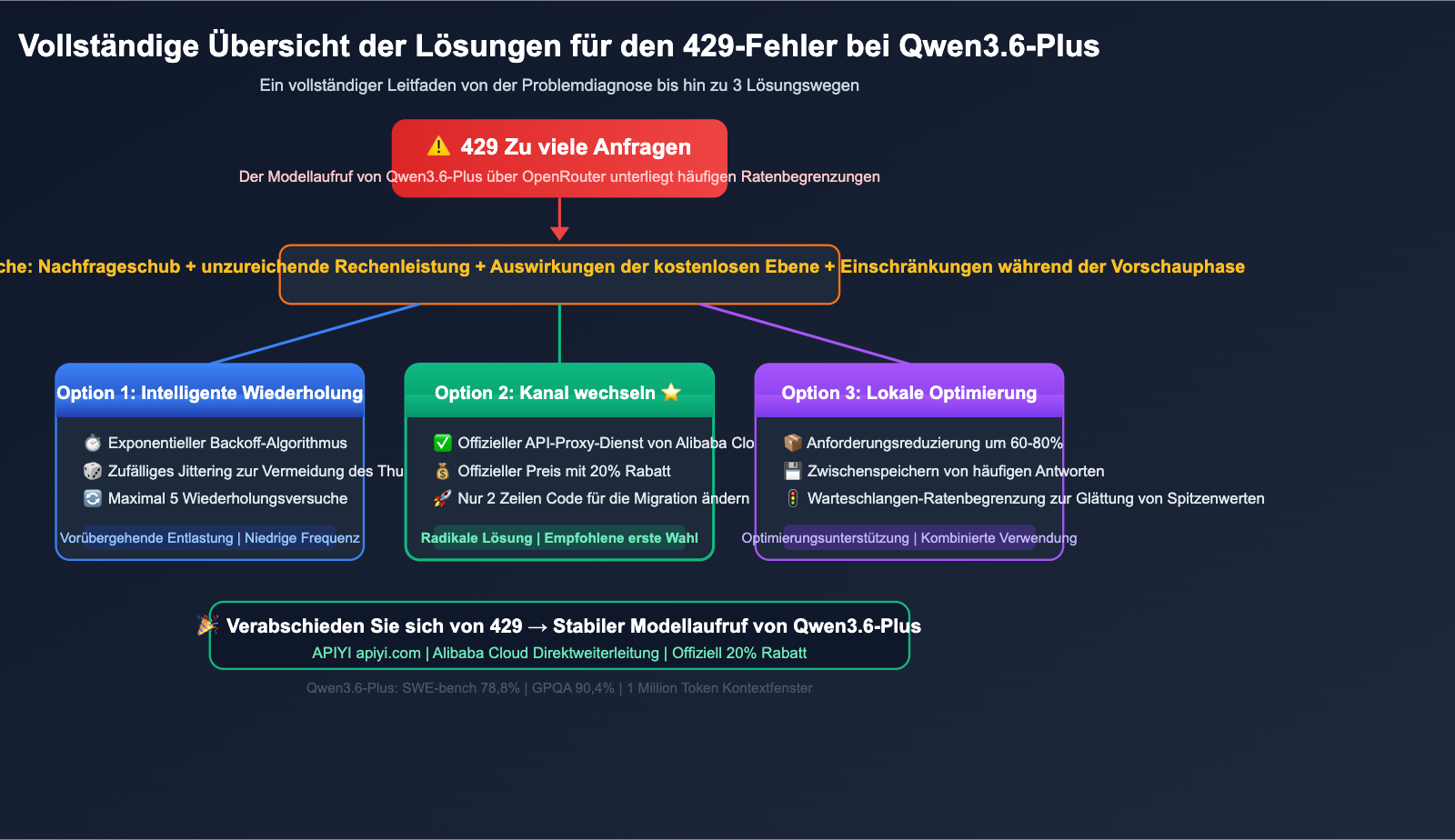
Das 429-Problem bei Qwen3.6-Plus ist im Kern ein Problem des Ungleichgewichts zwischen Angebot und Nachfrage: Das Modell ist leistungsstark, der Preis attraktiv und die Nachfrage enorm, während die Rechenkapazitäten von OpenRouter nicht für alle Nutzer ausreichen.
Hier sind drei Lösungsansätze für verschiedene Szenarien:
- Intelligente Wiederholungsversuche (Retry): Eine temporäre Lösung, geeignet für Szenarien mit geringer Aufruffrequenz.
- Lokale Optimierung: Reduzierung der Anfragemenge, geeignet für alle Anwendungsfälle.
- Kanalwechsel: Die grundlegende Lösung, ideal für Projekte, die auf hohe Stabilität angewiesen sind.
Für Entwickler, die eine stabile Anbindung an Qwen3.6-Plus benötigen, empfehlen wir den Zugriff über die offizielle API-Proxy-Dienst-Schnittstelle von Alibaba Cloud via APIYI (apiyi.com). Profitieren Sie von 20 % Rabatt auf den offiziellen Preis und verabschieden Sie sich von 429-Rate-Limits, damit sich Ihre Anwendung auf die Geschäftslogik statt auf die Fehlerbehandlung konzentrieren kann.
📝 Autor: APIYI Team | Weitere Tutorials zur Integration von KI-Modell-APIs und Leitfäden zur Fehlervermeidung finden Sie im APIYI-Hilfezentrum: help.apiyi.com