Google Gemma 4 wurde offiziell veröffentlicht und setzt erstmals auf die vollständig quelloffene Apache 2.0-Lizenz. Mit vier Modellen deckt es das gesamte Spektrum der Rechenleistung ab – vom Raspberry Pi bis hin zum Rechenzentrum. Als Open-Source-Version der Gemini 3-Technologie übertrifft Gemma 4 seinen Vorgänger in den Bereichen Schlussfolgerung, Programmierung, Bildverarbeitung und Kontextfenster bei weitem.
Kernnutzen: Nach der Lektüre dieses Artikels beherrschen Sie die Auswahl der vier Gemma 4-Modelle, verstehen die architektonischen Innovationen, die Grenzen der multimodalen Fähigkeiten sowie die Hardwareanforderungen für die lokale Bereitstellung.

Gemma 4: Die wichtigsten Informationen auf einen Blick
Gemma 4 wurde am 2. April 2026 auf der Google Cloud Next vorgestellt. Es basiert auf der Forschung hinter Gemini 3 und ist die vierte Generation der Open-Source-Modellfamilie von Google.
| Informationspunkt | Details |
|---|---|
| Veröffentlichungsdatum | 2. April 2026 |
| Anzahl der Modelle | 4 (E2B / E4B / 26B-A4B / 31B) |
| Lizenzvereinbarung | Apache 2.0 (erstmals, zuvor Google-eigene Lizenz) |
| Max. Kontextfenster | 256K Token (31B und 26B-A4B) |
| Multimodalität | Text + Bild + Video + Audio (E2B/E4B) |
| Architektur-Highlights | Erste MoE-Variante, PLE-Technologie, hybride Aufmerksamkeit |
| Verfügbare Plattformen | Hugging Face, Google AI Studio, Vertex AI, Ollama etc. |
Die vier Gemma 4 Modelle im Überblick
| Modell | Effektive Parameter | Gesamtparameter | Architektur | Kontext | Multimodalität |
|---|---|---|---|---|---|
| Gemma 4 E2B | 2,3 Mrd. | 5,1 Mrd. | Dense | 128K | Text+Bild+Video+Audio |
| Gemma 4 E4B | 4,5 Mrd. | 8 Mrd. | Dense | 128K | Text+Bild+Video+Audio |
| Gemma 4 26B-A4B | 3,8 Mrd. aktiv | 25,2 Mrd. | MoE | 256K | Text+Bild+Video |
| Gemma 4 31B | 30,7 Mrd. | 30,7 Mrd. | Dense | 256K | Text+Bild+Video |
Namenskonvention: Das Präfix "E" steht für "Effective Parameters" (effektive Parameter). Aufgrund der PLE-Technologie sind die Gesamtparameter höher als die effektiven Parameter. 26B-A4B steht für eine MoE-Architektur mit 26 Mrd. Gesamtparametern und 4 Mrd. aktivierten Parametern pro Token.
🎯 Technischer Hinweis: Die vier Gemma 4 Modelle decken alle Szenarien ab, von Edge-Geräten bis hin zum Cloud-Inference. Wenn Sie die Leistung verschiedener Open-Source-Modelle vergleichen möchten, empfiehlt sich die zentrale Anbindung über die APIYI-Plattform (apiyi.com), um schnell zwischen den Modellen zu wechseln und diese zu bewerten.
Gemma 4 vs. Gemma 3 Leistungsvergleich: Der größte Generationssprung aller Zeiten
Google bezeichnet Gemma 4 als den "größten Leistungssprung innerhalb einer Generation im Bereich der Open-Source-Modelle". Die Benchmark-Daten untermauern diese Aussage eindrucksvoll.
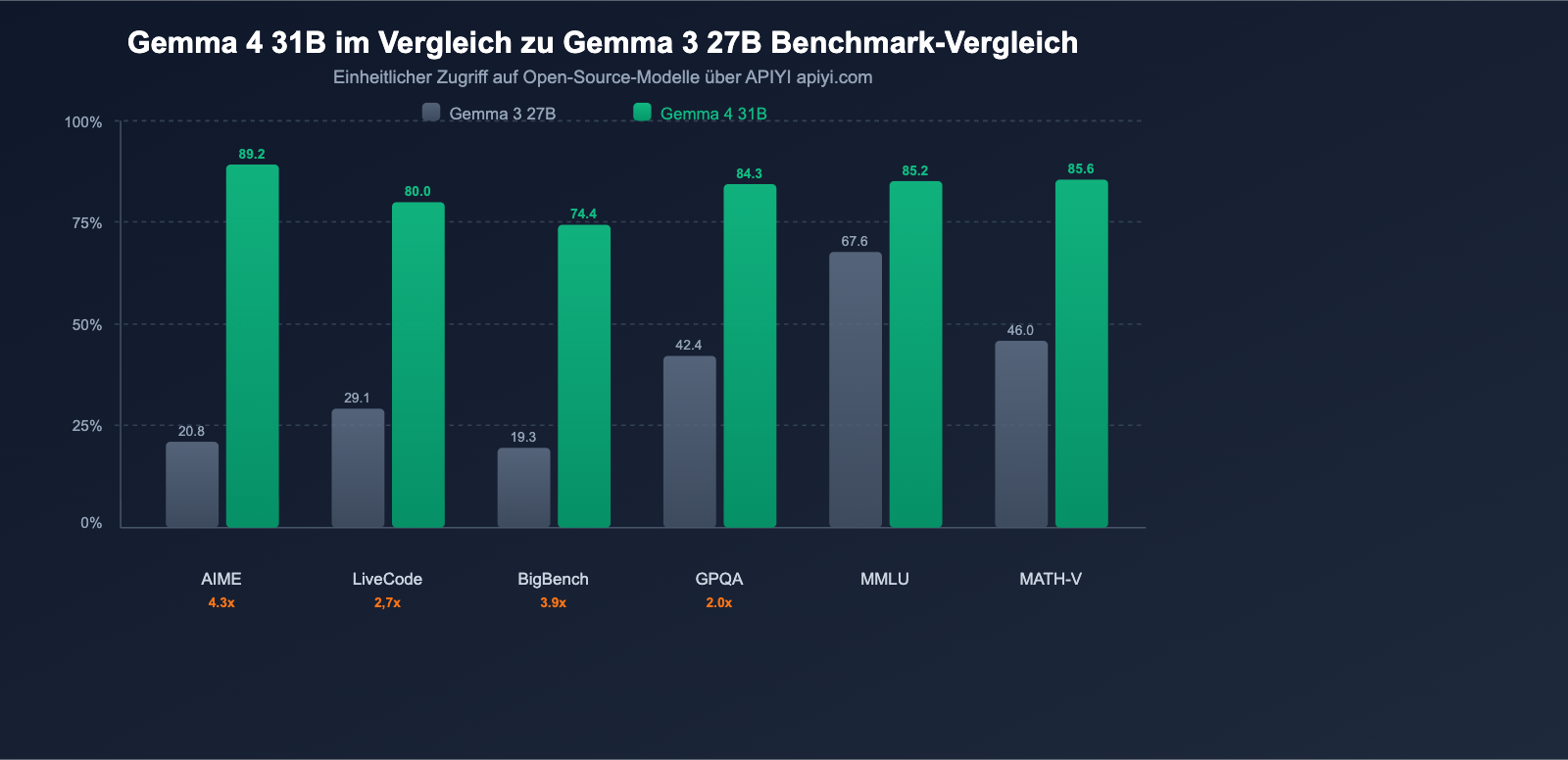
Wichtige Benchmark-Vergleiche
| Benchmark | Gemma 3 27B | Gemma 4 31B | Steigerung |
|---|---|---|---|
| AIME 2026 (Mathematisches Schließen) | 20,8% | 89,2% | +68,4 Pkt. (4,3x) |
| LiveCodeBench v6 (Programmierung) | 29,1% | 80,0% | +50,9 Pkt. (2,7x) |
| BigBench Extra Hard (Schlussfolgern) | 19,3% | 74,4% | +55,1 Pkt. (3,9x) |
| GPQA Diamond (Wissenschaftliches Schließen) | 42,4% | 84,3% | +41,9 Pkt. (2,0x) |
| MMLU Pro (Wissen) | 67,6% | 85,2% | +17,6 Pkt. |
| MATH-Vision (Visuelle Mathematik) | 46,0% | 85,6% | +39,6 Pkt. |
| MRCR 128K (Langer Kontext) | 13,5% | 66,4% | +52,9 Pkt. |
Wichtige Erkenntnis: Das mathematische Schließen bei AIME sprang von 20,8% auf 89,2% (4,3-fache Steigerung); die Programmierung bei LiveCodeBench stieg von 29,1% auf 80,0% (2,7-fache Steigerung). Dies ist keine schrittweise Verbesserung, sondern ein echter Generationssprung.
Vollständige Benchmark-Daten der 4 Modelle
| Benchmark | 31B | 26B-A4B | E4B | E2B |
|---|---|---|---|---|
| MMLU Pro | 85,2% | 82,6% | 69,4% | 60,0% |
| AIME 2026 | 89,2% | 88,3% | 42,5% | 37,5% |
| GPQA Diamond | 84,3% | 82,3% | 58,6% | 43,4% |
| LiveCodeBench v6 | 80,0% | 77,1% | 52,0% | 44,0% |
| MATH-Vision | 85,6% | 82,4% | 59,5% | 52,4% |
| MMMU Pro (Visuell) | 76,9% | 73,8% | 52,6% | 44,2% |
| Codeforces ELO | 2150 | 1718 | 940 | 633 |
Effizienzvorteil von MoE: Das 26B-A4B-Modell erreicht mit nur 3,8 Mrd. aktivierten Parametern etwa 97% der Leistung des 31B-Dense-Modells, wodurch die Inferenzkosten drastisch gesenkt werden. Auf LMArena übertraf das 26B-A4B (~1441 ELO) sogar das gpt-oss-120B von OpenAI.
💡 Auswahlempfehlung: Für maximale Leistung wählen Sie das 31B-Modell, für ein optimales Preis-Leistungs-Verhältnis das 26B-A4B (97% Leistung bei nur 12% aktivierten Parametern). Über die APIYI-Plattform (apiyi.com) können Sie die tatsächliche Performance beider Versionen in Ihren spezifischen Geschäftsszenarien schnell vergleichen.
6 Kerntechnologien der Architektur-Innovation von Gemma 4
Gemma 4 führt auf Architekturebene eine Reihe innovativer Technologien ein, die den Grundstein für den massiven Leistungssprung bilden.
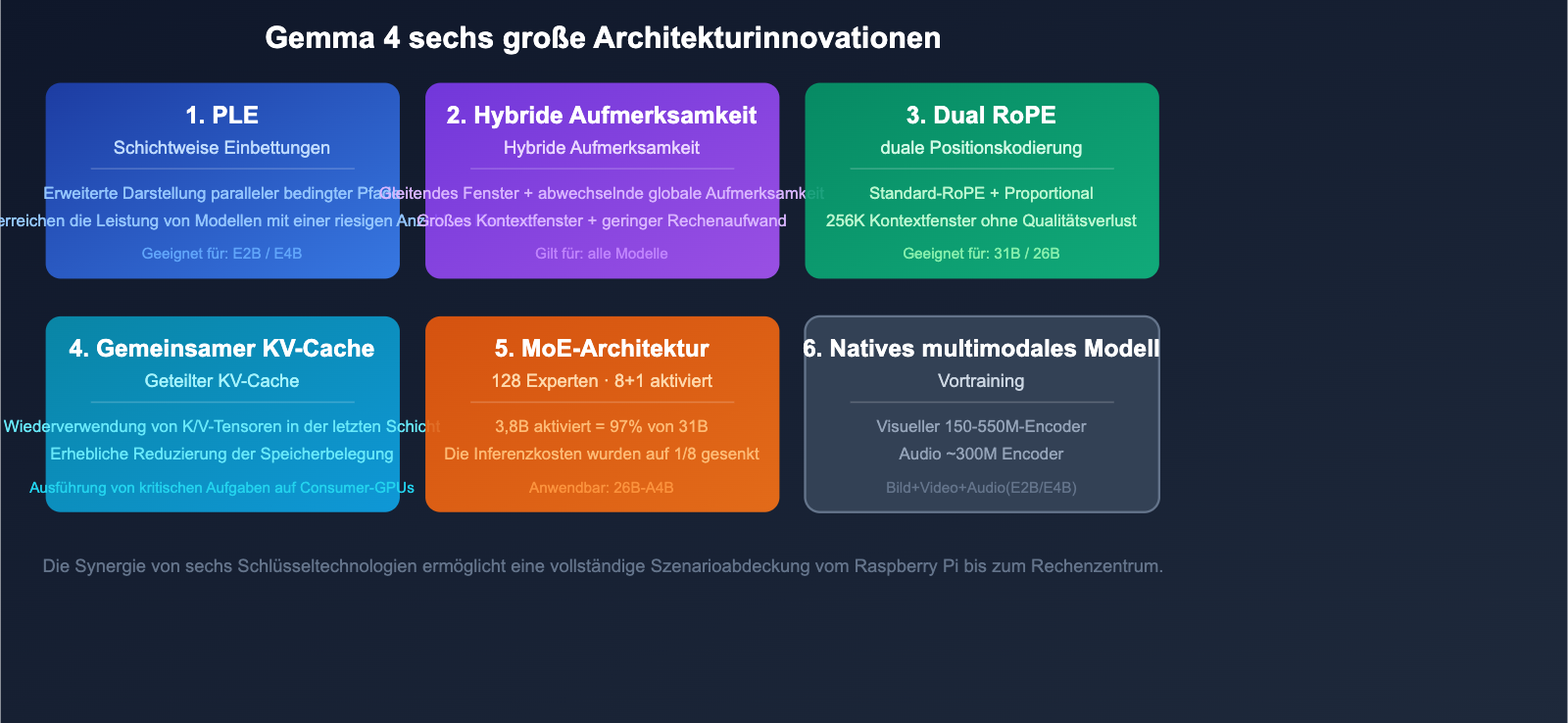
Technologie 1: Per-Layer Embeddings (PLE)
PLE fügt außerhalb des Haupt-Residualstroms einen parallelen konditionalen Pfad hinzu, um dedizierte Token-Vektoren für jede Decoder-Schicht zu generieren. Diese Technik verbessert die Ausdrucksstärke kleinerer Modelle und ermöglicht es dem E2B mit 2,3 Mrd. effektiven Parametern, eine Leistung zu erzielen, die weit über seiner eigentlichen Parametergröße liegt.
Technologie 2: Hybride Aufmerksamkeit (Hybrid Attention)
Hierbei wird zwischen lokaler Sliding-Window-Attention und globalen Full-Context-Attention-Schichten gewechselt:
- Sliding-Window-Schicht: Verarbeitet den lokalen Kontext (E2B/E4B: 512 Token; 31B/26B: 1024 Token)
- Globale Attention-Schicht: Verarbeitet den vollständigen Kontextbereich
Dieses hybride Design senkt den Rechenaufwand erheblich, während die Fähigkeit für lange Kontexte erhalten bleibt.
Technologie 3: Dual RoPE Positionskodierung
- Sliding-Window-Schichten verwenden standardmäßiges RoPE
- Globale Attention-Schichten verwenden Proportional RoPE
Dieses Dual-RoPE-Design macht ein Kontextfenster von 256K ohne Qualitätsverlust möglich.
Technologie 4: Geteilter KV-Cache
Die letzten N Schichten verwenden die K/V-Tensoren der jeweils letzten nicht geteilten Schicht desselben Typs wieder, was den Rechenaufwand und den Speicherbedarf drastisch reduziert. Dies ist eine der Schlüsseltechnologien, die es Gemma 4 ermöglicht, große Modelle auf Consumer-Hardware auszuführen.
Technologie 5: MoE Mixture-of-Experts (26B-A4B)
Gemma 4 führt erstmals eine MoE-Variante ein:
- 128 kleine Experten
- 8 Experten + 1 geteilter Experte werden pro Token aktiviert
- Erreicht mit 3,8 Mrd. aktivierten Parametern etwa 97 % der Leistung eines 31B Dense-Modells
Technologie 6: Natives Multimodal
Visuelle und auditive Fähigkeiten sind direkt in die Vortrainingsphase integriert:
- Vision-Encoder: E2B/E4B ~150 Mio. Parameter; 31B/26B ~550 Mio. Parameter
- Audio-Encoder: USM-Style Conformer, ~300 Mio. Parameter (nur E2B/E4B)
- Unterstützt Bilder mit variablem Seitenverhältnis, konfigurierbares Token-Budget (70–1120 Token)
Gemma 4: Multimodale Fähigkeiten und Agenten-Power im Detail
Gemma 4 ist nicht nur ein reines Dialogmodell, sondern ein multimodales System, das über umfassende Agenten-Fähigkeiten verfügt.
Multimodale Eingabemöglichkeiten
| Modalität | E2B | E4B | 31B | 26B-A4B |
|---|---|---|---|---|
| Text | ✅ | ✅ | ✅ | ✅ |
| Bild | ✅ | ✅ | ✅ | ✅ |
| Video (max. 60 Sek., 1 fps) | ✅ | ✅ | ✅ | ✅ |
| Audio (max. 30 Sek.) | ✅ | ✅ | ❌ | ❌ |
Die visuellen Fähigkeiten umfassen:
- Objekterkennung und Ausgabe von Begrenzungsrahmen (natives JSON-Format)
- Erkennung und Ansteuerung von GUI-Elementen
- Dokumenten-/PDF-Analyse und Diagrammverständnis
- Verständnis von Bildschirmoberflächen/UI
- Interleaved-Eingabe von Text und Bild (beliebige Reihenfolge)
Native Funktionsaufrufe und Agenten-Fähigkeiten
Gemma 4 verfügt bereits ab der Trainingsphase über integrierte Fähigkeiten für Funktionsaufrufe, diese wurden nicht erst nachträglich durch Fine-Tuning hinzugefügt:
- Native Funktionsaufrufe: Direkt während des Trainings optimiert, unterstützt die Orchestrierung mehrerer Werkzeuge.
- Extended Thinking: Über
enable_thinking=Truekann mehrstufiges Schlussfolgern aktiviert werden. - Strukturierte Ausgabe: Natives JSON-Format, ideal für die API-Integration.
- Multi-Turn-Agenten-Prozesse: Unterstützt autonome Agenten-Zyklen (Planen-Ausführen-Beobachten).
# Beispiel für Gemma 4 Funktionsaufrufe (über die einheitliche APIYI-Schnittstelle)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Ruft das Wetter für eine bestimmte Stadt ab",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string"}
},
"required": ["city"]
}
}
}
]
response = client.chat.completions.create(
model="gemma-4-31b-it",
messages=[{"role": "user", "content": "Wie ist das Wetter heute in Peking?"}],
tools=tools,
tool_choice="auto",
)
🚀 Schnellstart: Die nativen Funktionsaufrufe von Gemma 4 machen es zur idealen Wahl für den Aufbau von KI-Agenten. Wir empfehlen die Plattform APIYI (apiyi.com) für eine schnelle Anbindung; sie unterstützt OpenAI-kompatible Schnittstellen, sodass keine zusätzliche Anpassung erforderlich ist.
Hardware-Leitfaden für die lokale Bereitstellung von Gemma 4
Dank der Apache 2.0-Lizenz können Sie Gemma 4 auf jeder Hardware frei bereitstellen. Hier sind die Hardwareanforderungen für die verschiedenen Modelle.
Hardwareanforderungen im Überblick
| Modell | Mindesthardware | Typisches Einsatzszenario |
|---|---|---|
| E2B (2,3B) | <1,5 GB RAM | Raspberry Pi 5 (133 Tok/s Pre-fill, 7,6 Tok/s Decoding) |
| E4B (4,5B) | Mobil-NPU/GPU | Mobilgeräte, Apple Silicon (MLX) |
| 26B-A4B (MoE) | Einzelne Consumer-GPU (quantisiert) | Persönliche Workstations, kleine Server |
| 31B (Dense) | Einzelne 80GB H100 (FP16) | Cloud-Inferenz, Rechenzentren |
Unterstützte Hardware und Frameworks
| Hardware/Framework | Unterstützungsstatus |
|---|---|
| NVIDIA (H100/B200/RTX) | ✅ Volle Unterstützung |
| Google TPU (Trillium/Ironwood) | ✅ Native Optimierung |
| Apple Silicon (MLX) | ✅ mlx-community/gemma-4-* |
| AMD ROCm | ✅ Unterstützt |
| Qualcomm NPU (IQ8) | ✅ Mobile Inferenz |
| GGUF (llama.cpp/Ollama) | ✅ 2-Bit/4-Bit Quantisierung |
| ONNX (WebGPU/Browser) | ✅ onnx-community/gemma-4-* |
| NVIDIA NIM | ✅ Containerisierte Bereitstellung |
E2B kann auf einem Raspberry Pi 5 mit einer Dekodiergeschwindigkeit von 7,6 Tokens pro Sekunde ausgeführt werden, was völlig neue Möglichkeiten für Edge-KI-Anwendungen eröffnet.
Apache 2.0-Lizenz: Warum diesmal alles anders ist
Gemma 4 setzt erstmals auf die Apache 2.0-Lizenz – ein bedeutender Schritt. Bisher unterlagen alle Gemma-Modelle den proprietären Lizenzvereinbarungen von Google, die spezifische Nutzungsbeschränkungen und Kündigungsrechte enthielten.
Lizenzvergleich
| Dimension | Gemma 3 (Google-Lizenz) | Gemma 4 (Apache 2.0) |
|---|---|---|
| Kommerzielle Nutzung | Eingeschränkt | ✅ Vollständig frei |
| Änderung & Verbreitung | Zusätzliche Bedingungen | ✅ Vollständig frei |
| Abgeleitete Modelle | Eingeschränkt | ✅ Vollständig frei |
| Kündigungsrecht | Google behält sich Rechte vor | ❌ Unwiderruflich |
| Patentlizenzierung | Begrenzt | ✅ Explizit erteilt |
Apache 2.0 bedeutet:
- Unternehmen können das Modell bedenkenlos in kommerziellen Produkten einsetzen, ohne rechtliche Risiken.
- Abgeleitete Modelle können frei angepasst und verbreitet werden.
- Angleichung an die Open-Source-Strategien von Meta Llama und DeepSeek.
- Deutliche Senkung der Compliance-Hürden für Unternehmen.
💰 Kostenoptimierung: Apache 2.0 + lokale Bereitstellung = Null Kosten für Modellaufrufe. Bei Szenarien mit hohem Inferenzvolumen kann die lokale Bereitstellung von Gemma 4 wirtschaftlicher sein als ein API-Aufruf. Wenn Sie die Kosteneffizienz zwischen lokaler Bereitstellung und API-Aufrufen vergleichen möchten, können Sie über die Plattform APIYI (apiyi.com) zunächst die Ergebnisse per API validieren, bevor Sie sich für eine lokale Installation entscheiden.
Bezugsquellen und Schnelleinstieg für Gemma 4
Kanäle für den Modellbezug
| Plattform | Verfügbare Modelle | Verwendungszweck |
|---|---|---|
| Hugging Face | Alle 4 Varianten (Base + IT) | Allgemeiner Download, Forschung |
| Google AI Studio | 31B, 26B MoE | Kostenloses Online-Erlebnis |
| Vertex AI | Alle 4 Varianten | Bereitstellung auf Unternehmensebene |
| Ollama / llama.cpp | GGUF-quantisierte Versionen | Schnelle lokale Bereitstellung |
| Google AI Edge Gallery | E4B, E2B | Bereitstellung auf Mobilgeräten |
Bereitstellung mit Ollama
# Bereitstellung von Gemma 4 31B (empfohlen)
ollama run gemma4:31b
# Bereitstellung der MoE-Version (hohes Preis-Leistungs-Verhältnis)
ollama run gemma4:26b-a4b
# Bereitstellung der Leichtgewicht-Version (für Edge-Geräte)
ollama run gemma4:e4b
Unterstützung für Feinabstimmung
Gemma 4 bietet ein vollständiges Ökosystem für die Feinabstimmung:
| Framework | Unterstützte Methoden |
|---|---|
| TRL | SFT, DPO, Reinforcement Learning (inkl. multimodal) |
| PEFT | LoRA, QLoRA (via bitsandbytes) |
| Vertex AI | Verwaltetes Training |
| Unsloth Studio | UI-basierte Feinabstimmung |
Die Vision- und Audio-Encoder können eingefroren werden, sodass nur der Textteil feinabgestimmt wird – dies senkt die Kosten für die Feinabstimmung erheblich.
🎯 Technischer Rat: Wir empfehlen, die Leistung von Gemma 4 zunächst über die API-Schnittstelle der Plattform APIYI (apiyi.com) zu testen. Sobald Sie sicher sind, dass das Modell Ihre Anforderungen erfüllt, können Sie mit der lokalen Bereitstellung oder Feinabstimmung fortfahren, um Ressourcenverschwendung zu vermeiden.
Häufig gestellte Fragen
Q1: In welcher Beziehung stehen Gemma 4 und Gemini 3?
Gemma 4 basiert auf der gleichen Forschung wie Gemini 3 und kann als Open-Source-Version der Gemini 3-Technologie betrachtet werden. Das Modell von Gemma 4 ist kleiner (maximal 31B im Vergleich zu den hunderten Milliarden Parametern von Gemini), nutzt jedoch dieselben architektonischen Innovationen. Über die Plattform APIYI (apiyi.com) können Sie sowohl Gemma 4 als auch die Gemini-Modellreihe für Vergleichsanalysen nutzen.
Q2: Wie entscheide ich mich zwischen 26B MoE und 31B Dense?
Wenn Ihre Hardware begrenzt ist oder Sie einen hohen Durchsatz benötigen, wählen Sie das 26B-A4B MoE – es erreicht mit nur 3,8B aktivierten Parametern etwa 97 % der Leistung des 31B-Modells. Wenn Sie jedoch maximale Leistung anstreben und über eine 80-GB-GPU verfügen, ist das 31B Dense die bessere Wahl. Die Inferenzkosten der MoE-Version betragen etwa 1/8 der Dense-Version.
Q3: Für welche Szenarien eignen sich E2B und E4B?
E2B eignet sich für extreme Edge-Szenarien (Raspberry Pi, IoT-Geräte, Mobilgeräte), während E4B für mobile Endgeräte und leichtgewichtige PC-Bereitstellungen optimiert ist. Beide unterstützen Audioeingaben, was bei den 31B- und 26B-Modellen nicht der Fall ist. Wenn Ihre Anwendung Sprachverständnis erfordert, müssen Sie E2B oder E4B wählen.
Q4: Welche Auswirkungen hat die Apache 2.0-Lizenz auf die kommerzielle Nutzung?
Apache 2.0 ist eine der freizügigsten Open-Source-Lizenzen und erlaubt die uneingeschränkte kommerzielle Nutzung, Modifikation und Verbreitung. Im Gegensatz zur proprietären Google-Lizenz von Gemma 3 müssen sich Unternehmen hier keine Sorgen um Compliance-Risiken machen. Sie können die Modelle zunächst über die Plattform APIYI (apiyi.com) per API testen und nach Bestätigung der Ergebnisse lokal für kommerzielle Produkte bereitstellen.
Zusammenfassung
Gemma 4 stellt ein bedeutendes Upgrade der Open-Source-KI-Strategie von Google dar. Die Apache 2.0-Lizenz beseitigt bisherige Nutzungsbarrieren; die vier Modelle decken alle Rechenleistungsszenarien vom Raspberry Pi bis zur H100 ab. Mit einem Leistungssprung von 4,3-fach bei AIME und 2,7-fach bei LiveCodeBench sowie nativer multimodaler Unterstützung und Funktionsaufrufen ist es das bevorzugte Basismodell für die Entwicklung von Open-Source-Agenten.
Die wichtigsten Punkte im Überblick:
- Lizenz: Erstmals Apache 2.0, vollständig frei für kommerzielle Zwecke
- Modelle: 4 Varianten von 2B bis 31B, inklusive der ersten MoE-Variante
- Leistung: AIME +68 Punkte (4,3x), LiveCodeBench +51 Punkte (2,7x)
- Multimodal: Native Integration von Text, Bild, Video und Audio
- Agenten: Native Funktionsaufrufe + Extended Thinking
- Bereitstellung: Vollständige Abdeckung von Raspberry Pi bis H100, Unterstützung für GGUF/ONNX/MLX
Wir empfehlen den schnellen Zugriff auf die Gemma 4-Modellreihe über APIYI (apiyi.com), um die tatsächliche Leistung der verschiedenen Modelle unter einer einheitlichen Schnittstelle zu vergleichen.
Referenzen
- Offizieller Google-Blog – Veröffentlichung von Gemma 4:
blog.google/innovation-and-ai/technology/developers-tools/gemma-4/ - Hugging Face – Gemma 4 Modell:
huggingface.co/blog/gemma4 - Google AI – Gemma 4 Modellkarte:
ai.google.dev/gemma/docs/core/model_card_4
Dieser Artikel wurde vom technischen Team von APIYI verfasst. Weitere Tutorials zur Nutzung von KI-Modellen finden Sie auf APIYI unter apiyi.com.