Anmerkung des Autors: Ein neutraler Vergleich der Programmierfähigkeiten, Codequalität, des Kontextfensters, des Preises und der Entwicklererfahrung von Claude Code und GPT-5.4, um Ihnen bei der Entscheidung zu helfen, ob sich ein Wechsel lohnt.
Am Tag der Veröffentlichung von GPT-5.4 verbreitete sich in den sozialen Medien schnell eine Meinung: "Kündigt euer Claude Code-Abo!" Die Gründe klangen plausibel – 1M Kontextfenster, führende Fähigkeiten in allen Bereichen und das Problem, dass die KI "nicht wie ein Mensch spricht", wurde endlich gemildert.
Doch die Realität ist nicht so einfach. Benchmark-Daten zeigen, dass Claude Opus 4.6 im SWE-Bench-Programmier-Benchmark mit 80,8 % immer noch vor GPT-5.4 mit 77,2 % liegt. Das tatsächliche Feedback aus der Entwickler-Community ist zudem sehr geteilt.
Kernbotschaft: Dieser Artikel vergleicht objektiv die Programmierfähigkeiten von Claude Code und GPT-5.4 in 6 Dimensionen, um Ihnen bei der Entscheidung zu helfen, ob Sie wechseln sollten – oder ob die klügere Wahl darin besteht, beide parallel zu nutzen.
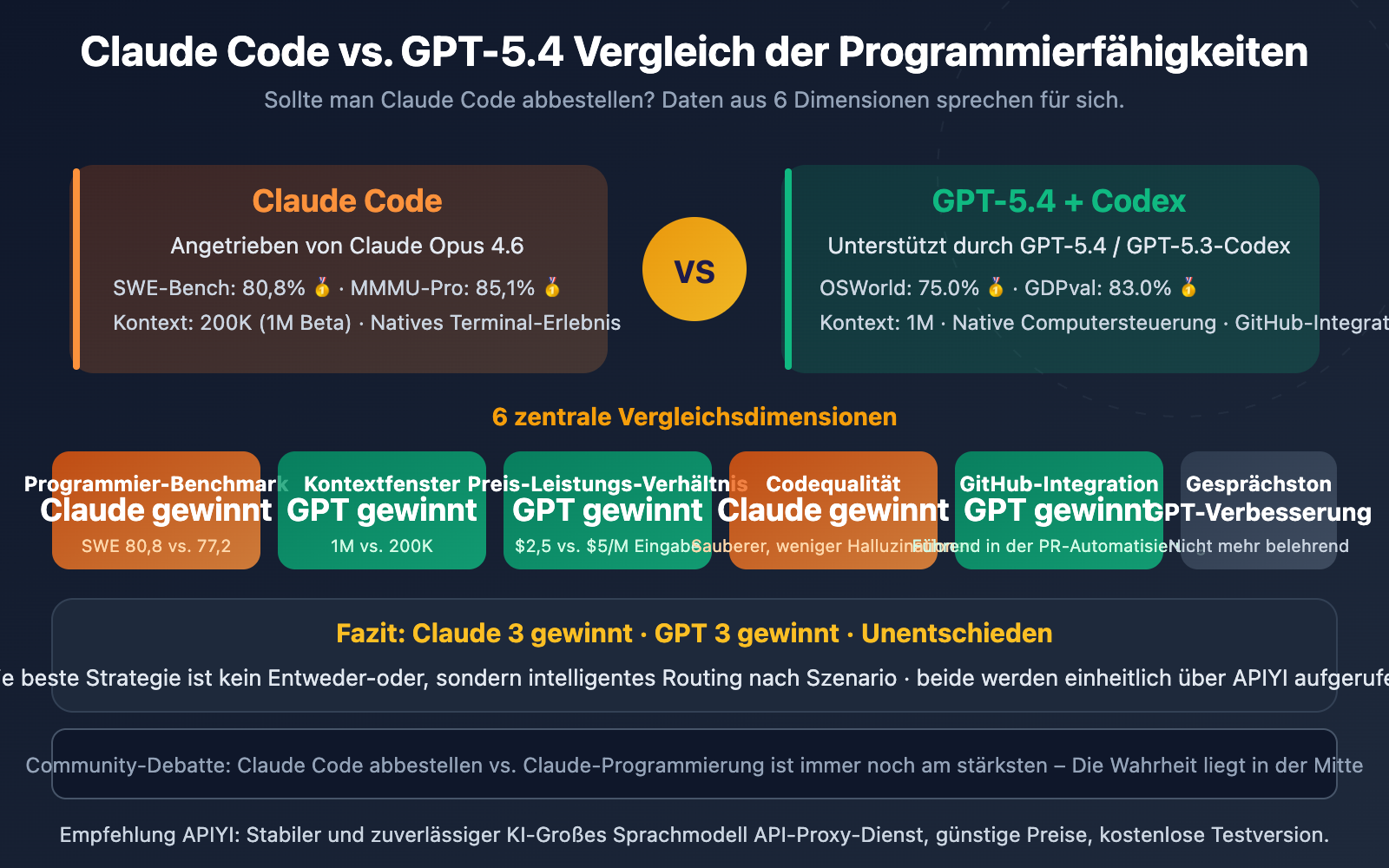
Claude Code vs. GPT-5.4: Vergleich der Kerndaten
| Vergleichsdimension | Claude Code (Opus 4.6) | GPT-5.4 / Codex | Gewinner |
|---|---|---|---|
| SWE-Bench Programmierung | 80,8 % | 77,2 % | Claude |
| MMMU-Pro Visuelles Denken | 85,1 % | 81,2 % | Claude |
| GDPval Wissensarbeit | 78,0 % | 83,0 % | GPT |
| OSWorld Computersteuerung | 72,7 % | 75,0 % | GPT |
| FrontierMath Mathematik | 27,2 % | 47,6 % | GPT |
| Terminal-Bench Terminal | 65,4 % | 75,1 % | GPT |
| Kontextfenster | 200K (1M Beta) | 1.000K | GPT |
| API-Eingabepreis | $5.00/M | $2.50/M | GPT |
| API-Ausgabepreis | $25.00/M | $15.00/M | GPT |
| Code-Sauberkeit | Sauberer, standardisierter | Standard | Claude |
| Refactoring und Debugging | Führend | Standard | Claude |
| GitHub PR-Automatisierung | Durchschnittlich | Tiefe Integration | GPT |
Spielstand: 4 Siege für Claude, 8 Siege für GPT – aber ziehen Sie noch keine voreiligen Schlüsse. In Programmierszenarien wiegen SWE-Bench, Codequalität und Refactoring-Fähigkeiten weitaus schwerer als Wissensarbeit oder Computersteuerung. Lassen Sie uns das Ganze im Detail aufschlüsseln.
Tiefenanalyse der Programmierfähigkeiten: Claude Code vs. GPT-5.4
Dimension 1: Programmier-Benchmarks — Claude Code liegt vorn
Im meistbeachteten Programmier-Benchmark SWE-Bench Verified (Fähigkeit zur Behebung echter GitHub-Issues):
| Modell | SWE-Bench Verified | SWE-Bench Pro |
|---|---|---|
| Claude Opus 4.6 | 80,8 % 🥇 | — |
| Gemini 3.1 Pro | 80,6 % | — |
| GPT-5.4 | 77,2 % | 57,7 % |
Claude Opus 4.6 liegt mit 3,6 Prozentpunkten vor GPT-5.4. In Szenarien der Code-Behebung auf Produktionsniveau – Verständnis von Multi-File-Architekturen, Verfolgung komplexer Abhängigkeitsketten – zeigt Claude ein stärkeres Verständnis für Codestrukturen.
GPT-5.4 führt jedoch bei Terminal-Bench 2.0 (terminalintensive Aufgaben) mit 75,1 % deutlich vor Claudes 65,4 %. Wenn Ihr Workflow stark auf Terminal-Operationen basiert, hat GPT Vorteile.
Dimension 2: Codequalität und Entwicklererfahrung — Claude Code ist sauberer
Das Feedback aus zahlreichen Entwickler-Communities deutet einhellig auf denselben Schluss hin: Der von Claude generierte Code ist sauberer, nutzt bessere Entwurfsmuster und weist weniger Halluzinationen auf.
Konkret zeigt sich das in:
- Refactoring-Aufgaben: Claude schneidet bei komplexen Umstrukturierungen und beim Debugging besser ab.
- Architekturverständnis: Bei der Analyse großer Repositories und mehrschichtiger Architekturen ist die Argumentationskette von Claude stabiler, mit weniger Kontextverlust.
- Generierungsgeschwindigkeit: Die initiale Generierungsgeschwindigkeit von Claude Code ist höher (ca. 1200 Zeilen in 5 Minuten vs. ca. 200 Zeilen in 10 Minuten bei Codex).
Die Stärken von GPT-5.4 liegen eher in der Dokumentationserstellung und dem Schreiben von Boilerplate-Code – Aufgaben, die kein tiefes Verständnis der Projektarchitektur erfordern.
Dimension 3: Kontextfenster — GPT-5.4 dominiert
Dies ist der größte strukturelle Vorteil von GPT-5.4:
| Fähigkeit | Claude Code | GPT-5.4 |
|---|---|---|
| Standard-Kontext | 200K | 1.000K |
| Beta-Kontext | 1M | — |
| Maximaler Output | 32K | 128K |
Ein Kontextfenster von 1 Mio. Token bedeutet, dass eine gesamte Codebasis auf Produktionsniveau auf einmal eingegeben werden kann. Beachten Sie jedoch: Anfragen über 272K Token werden mit dem doppelten Eingabepreis und dem 1,5-fachen Ausgabepreis berechnet. In der Praxis benötigen die meisten Programmieraufgaben keinen Kontext von mehr als 200K.
🎯 Praxistipp: Das Kontextfenster ist der Killer-Vorteil von GPT-5.4, spielt seine Stärken aber erst bei extrem großen Codebasen voll aus. In kleinen bis mittleren Projekten ist Claude mit seinem 200K-Kontext und dem besseren Architekturverständnis oft die bessere Wahl. Beide Modelle können einheitlich über den API-Proxy-Dienst von APIYI (apiyi.com) aufgerufen werden.
Claude Code vs. GPT-5.4: Preis- und Ökosystem-Vergleich

Dimension 4: Preis – GPT-5.4 bietet das bessere Preis-Leistungs-Verhältnis
GPT-5.4 liegt bei der API-Preisgestaltung durchweg unter Claude Opus 4.6:
- Eingabe: $2,50 vs. $5,00/M (50 % günstiger)
- Ausgabe: $15,00 vs. $25,00/M (40 % günstiger)
- Cache-Eingabe: $0,25 vs. $0,50/M (50 % günstiger)
Auf der Abonnement-Ebene spiegelt das Feedback der Entwickler-Community wider, dass Claude deutlich strengere Nutzungslimits hat. Der Codex-Plan für $20/Monat bietet großzügigere Kontingente als der Claude Pro-Plan für $17/Monat. Viele Entwickler berichten, dass sie bei Codex Pro fast nie an die Grenzen stoßen, während Claude-Nutzer selbst in teureren Tarifen häufig mit Ratenbegrenzungen konfrontiert sind.
Dimension 5: GitHub-Integration – GPT Codex liegt klar vorn
Dies ist ein oft übersehener Unterschied, der jedoch massive Auswirkungen auf den Workflow von Entwicklern hat.
Laut Entwickler-Feedback: Claude Codes GitHub PR-Reviews liefern zwar „ausführliche Kommentare, übersehen aber offensichtliche Bugs“, während Codex „wirklich schwer zu findende Fehler“ erkennt – inklusive Inline-Kommentaren und direkt umsetzbaren Fix-Workflows. Die GitHub-App von Codex sorgt zudem für eine konsistente Erfahrung zwischen CLI und Web-Interface.
Dimension 6: Gesprächston – Das Problem, dass GPT-5.x „nicht wie ein Mensch klingt“, wurde entschärft
Dies ist der dritte Punkt, der in den sozialen Medien häufig diskutiert wird. Die GPT-5-Serie hat tatsächlich eine Entwicklung durchgemacht – weg vom „unnatürlichen Roboter-Stil“ hin zu einer schrittweisen Verbesserung:
- GPT-5.0: Wurde als „kalter Roboter“ kritisiert.
- GPT-5.1: Mehr Wärme und Dialogfähigkeit hinzugefügt.
- GPT-5.3 Instant: Fokus auf „less cringe“, Halluzinationen um 26,8 % reduziert.
- GPT-5.4: Übernimmt die tonalen Verbesserungen von 5.3 und stärkt gleichzeitig die Fachkompetenz.
Objektiv betrachtet wird Claude jedoch nach wie vor für seine natürlichere Gesprächsführung und die bessere Lesbarkeit von Code-Erklärungen bevorzugt. GPT-5.4 hat hier zwar aufgeholt, aber es besteht immer noch ein gewisser Abstand.
🎯 Kostenoptimierung: Egal für welches Modell Sie sich entscheiden – über den API-Proxy-Dienst APIYI (apiyi.com) erhalten Sie einen einheitlichen Zugang und profitieren von flexibleren Abrechnungsmodellen. Die Preise für GPT-5.4 sind mit der offiziellen Website synchronisiert ($2,50/$15,00), und ab einer Aufladung von 100 USD gibt es 10 % Bonus oben drauf.
Claude Code vs GPT-5.4 Szenarien-Empfehlungen

Claude Code vs. GPT-5.4 API-Aufruf-Beispiel
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Komplexe Refaktorisierung → Claude Opus 4.6 nutzen (höhere Codequalität)
refactor_result = client.chat.completions.create(
model="claude-opus-4-6",
messages=[{"role": "user", "content": "Refaktoriere die Dependency-Injection-Architektur dieses Moduls"}]
)
# Analyse großer Codebasen → GPT-5.4 nutzen (1M Kontextfenster)
analysis_result = client.chat.completions.create(
model="gpt-5.4",
messages=[{"role": "user", "content": "Analysiere das gesamte Projekt auf Sicherheitslücken"}]
)
Empfehlung: Registrieren Sie ein Konto über APIYI (apiyi.com), um gleichzeitig auf Claude und GPT-5.4 zuzugreifen. Die Preise für GPT-5.4 entsprechen der offiziellen Website, und ab einer Aufladung von 100 USD erhalten Sie 10 % Bonus. Der Modellaufruf erfolgt einfach durch Ändern eines Parameters.
Häufig gestellte Fragen
Q1: Sollte ich Claude Code kündigen?
Das hängt von Ihrem Haupt-Workflow ab. Wenn Ihr Fokus auf komplexer Code-Refaktorisierung und Bugfixes auf Produktionsniveau liegt, bleibt Claude die stärkste Wahl (führend mit 80,8 % im SWE-Bench). Wenn Sie ein riesiges Kontextfenster, GitHub-Integration und geringere Kosten benötigen, haben GPT-5.4 / Codex Vorteile. Die beste Strategie ist kein Entweder-oder, sondern die Nutzung beider Modelle je nach Szenario via API.
Q2: Ist die Programmierfähigkeit von GPT-5.4 wirklich überall führend?
Nein. GPT-5.4 führt in Dimensionen wie GDPval (Wissensarbeit), OSWorld (Computersteuerung) und FrontierMath (Mathematik). Aber im wichtigsten Programmier-Benchmark, dem SWE-Bench, behält Claude Opus 4.6 mit 80,8 % gegenüber 77,2 % die Nase vorn. Bei Codequalität, Refaktorisierung und Architekturverständnis bevorzugt die Entwickler-Community weiterhin Claude. Beide können über APIYI (apiyi.com) einheitlich aufgerufen und verglichen werden.
Q3: Wie verwende ich Claude und GPT-5.4 gleichzeitig?
Registrieren Sie ein Konto bei APIYI (apiyi.com):
- Erhalten Sie einen einheitlichen API-Schlüssel.
- Setzen Sie die
base_urlaufhttps://vip.apiyi.com/v1. - Nutzen Sie
model="claude-opus-4-6"für Refaktorisierungsaufgaben. - Nutzen Sie
model="gpt-5.4"für Analysen großer Projekte. - Nutzen Sie
model="gpt-5.3-chat-latest"für Alltagsaufgaben (am kosteneffizientesten).
Ab einer Aufladung von 100 USD gibt es 10 % Bonus – ein Konto deckt alle gängigen Modelle ab.
Zusammenfassung
Kernfazit: Claude Code vs. GPT-5.4:
- Claude führt weiterhin bei Programmier-Benchmarks: Mit 80,8 % gegenüber 77,2 % im SWE-Bench liefert Claude sauberere Codequalität sowie stärkeres Refactoring und Debugging – daher ist die Aussage „Claude Code kündigen“ zu voreilig.
- GPT-5.4 dominiert bei Kontext und Preis-Leistung: Ein Kontextfenster von 1 Mio. Token (5-mal größer als bei Claude), API-Preise, die 40–50 % günstiger sind, und eine tiefere GitHub-Integration machen es ideal für Großprojekte und kostensensible Szenarien.
- Die optimale Strategie ist die kombinierte Nutzung: Nutzen Sie Claude für Refactoring und Bugfixes, GPT-5.4 für die Analyse riesiger Codebasen und Terminal-Operationen sowie GPT-5.3 Instant für alltägliche Aufgaben, um Kosten zu sparen.
Lassen Sie sich nicht von Clickbait-Titeln wie „Claude Code kündigen“ mitreißen. Kluge Entwickler wählen das am besten geeignete Werkzeug für das jeweilige Szenario – anstatt nur einer Marke treu zu bleiben.
Wir empfehlen den einheitlichen Zugriff auf Claude und GPT-5.4 über APIYI (apiyi.com). Ein API-Schlüssel für alle Modelle, und ab einer Aufladung von 100 USD erhalten Sie 10 % Bonus.
📚 Referenzen
-
Tiefgehender Vergleich: Claude Code vs. Codex: Detaillierter Vergleich aus Entwicklerperspektive vom Builder.io-Team.
- Link:
builder.io/blog/codex-vs-claude-code - Beschreibung: Enthält praktische Vergleiche zu Preis, Codequalität, GitHub-Integration usw.
- Link:
-
Wettbewerbsanalyse: GPT-5.4 nimmt Claude ins Visier: Wie GPT-5.4 sich im Wettbewerb mit Claude positioniert.
- Link:
trendingtopics.eu/gpt-5-4-targets-anthropics-claude-with-premium-pricing-and-coding-muscle/ - Beschreibung: Eingehende Analyse der Premium-Preisstrategie und der Programmier-Ambitionen von GPT-5.4 Pro.
- Link:
-
Umfassender Vergleich: GPT-5.4 vs. Opus 4.6 vs. Gemini 3.1 Pro: Daten aus 12 Benchmark-Tests.
- Link:
digitalapplied.com/blog/gpt-5-4-vs-opus-4-6-vs-gemini-3-1-pro-best-frontier-model - Beschreibung: Der umfassendste Vergleich der drei Top-Modelle inklusive Wettbewerbsanalyse und Auswahlberatung.
- Link:
-
Entwickler-Benchmark: Claude Sonnet 4.6 vs. GPT-5: Praxistests in realen Entwicklungsszenarien von SitePoint.
- Link:
sitepoint.com/claude-sonnet-4-6-vs-gpt-5-the-2026-developer-benchmark/ - Beschreibung: Vergleichsdaten für spezifische Aufgaben wie Refactoring, Debugging und Dokumentationserstellung.
- Link:
Autor: APIYI-Technikteam
Technischer Austausch: Diskutieren Sie gerne im Kommentarbereich mit. Weitere Materialien finden Sie im APIYI Dokumentationszentrum unter docs.apiyi.com.