In letzter Zeit sind viele Entwickler beim Aufruf der Gemini API auf folgende Fehlermeldung gestoßen:
{
"error": {
"code": 503,
"message": "This model is currently experiencing high demand. Spikes in demand are usually temporary. Please try again later.",
"status": "UNAVAILABLE"
}
}
Einfach ausgedrückt bedeutet das: Das Modell ist gerade zu beliebt, die Server sind überlastet, bitte versuchen Sie es später noch einmal.
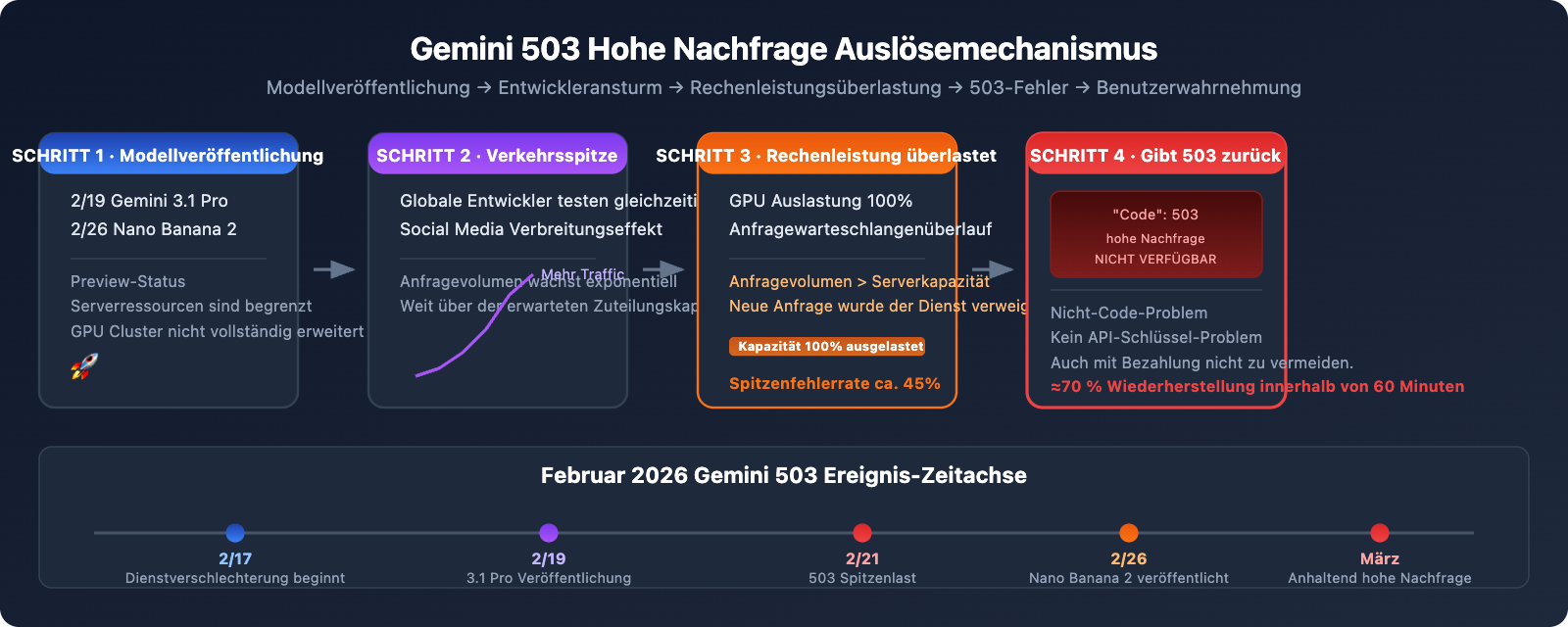
Dieses Problem tritt besonders häufig bei den neuen Modellen Gemini 3.1 Pro Preview und Gemini 3.1 Flash Image Preview (Nano Banana 2) auf. Dieser Artikel wird die Ursache dieses Fehlers, seine Unterschiede zu anderen gängigen Fehlern sowie 5 praxiserprobte und effektive Lösungen umfassend erläutern.
Kernnutzen: Nach dem Lesen dieses Artikels werden Sie die Grundursache des 503 High Demand Fehlers genau verstehen, 5 direkt umsetzbare Lösungen beherrschen und nicht mehr durch diesen Fehler in Ihrem Entwicklungsfortschritt blockiert werden.
Was bedeutet der Gemini API 503 High Demand Fehler wirklich?
Um das Problem zu verstehen, stellen wir es uns zunächst mit einem einfachen Vergleich vor:
Stellen Sie sich Googles Gemini-Server als ein angesagtes Restaurant vor. Normalerweise läuft das Geschäft gut und es gibt genügend Plätze. Plötzlich geht es viral (ein neues Modell wird veröffentlicht), und die ganze Stadt strömt herbei, um sich anzustellen. Die Kapazität des Restaurants ist begrenzt, und wenn es voll ist, ist es voll. Wenn Sie dann an der Tür ankommen, sagt Ihnen der Kellner: „Entschuldigung, es sind gerade zu viele Leute hier. Die Stoßzeit ist normalerweise vorübergehend, bitte versuchen Sie es später noch einmal.“
Das ist die Essenz von This model is currently experiencing high demand – es liegt nicht an Ihrem Code, nicht an Ihrem API-Schlüssel, sondern daran, dass die Serverkapazität von Google nicht ausreicht.
3 wichtige Fakten zum Gemini 503 Fehler
| Fakt | Erklärung | Auswirkung |
|---|---|---|
| Serverseitiges Problem | 503 bedeutet unzureichende Serverkapazität bei Google, unabhängig von Ihrem Code und Ihrer Konfiguration | Ein Upgrade auf ein kostenpflichtiges Paket löst das Problem nicht |
| Alle Nutzer betroffen | Kostenlose Nutzer, zahlende Nutzer und Unternehmenskunden sind alle betroffen | Kein Problem, das sich durch "mehr Geld" lösen lässt |
| Meistens vorübergehend | Etwa 70 % der 503-Fehler während Spitzenzeiten beheben sich innerhalb von 60 Minuten von selbst | Erfordert einen Wiederholungsmechanismus, keine Code-Korrektur |
Warum Gemini 3.1 Pro und Nano Banana 2 besonders anfällig für 503-Fehler sind
Der Ausbruch der 503-Fehler im Februar 2026 hat eine klare Zeitachse:
- 19. Februar: Google veröffentlicht Gemini 3.1 Pro Preview, viele Entwickler strömen zum Testen herbei
- 26. Februar: Nano Banana 2 (
gemini-3.1-flash-image-preview) wird veröffentlicht, die Nachfrage nach Bilderzeugung steigt stark an - 17.-21. Februar: StatusGator verzeichnet eine ganze Woche lang Warnungen vor einer Dienstverschlechterung bei Gemini
- Fehlerrate in Spitzenzeiten ca. 45 %: Community-Daten zeigen, dass die Fehlerrate bei Anfragen in Spitzenzeiten fast die Hälfte beträgt
Grundursache: Die neuen Modelle sind gerade erst gestartet, und die von Google zugewiesene Rechenleistung (GPU-Cluster) wurde noch nicht bedarfsgerecht skaliert. Die Serverressourcen für Modelle im "Preview"-Status sind ohnehin begrenzt, und wenn dann noch globale Entwickler gleichzeitig zum Testen strömen, entsteht eine Situation, in der die Nachfrage das Angebot übersteigt.
Gemini 503 High Demand und 429 Rate Limit: Der grundlegende Unterschied
Viele Entwickler verwechseln 503 und 429, aber die Ursachen dieser Fehler sind völlig unterschiedlich und die Lösungen ebenso. Eine falsche Herangehensweise führt nur zu unnötigem Aufwand.
| Vergleichskriterium | 503 High Demand | 429 Rate Limit |
|---|---|---|
| Fehlermeldung | "This model is currently experiencing high demand" | "Resource has been exhausted" |
| Grundursache | Unzureichende Rechenleistung der Google-Server | Ihre persönliche Anfragerate überschritten |
| Betroffener Bereich | Alle Benutzer betroffen | Nur Sie selbst betroffen |
| Upgrade als Lösung? | ❌ Upgrade des kostenpflichtigen Tarifs löst das Problem nicht | ✅ Upgrade auf Tier 1 kann das Problem lösen |
| Wiederholung effektiv? | ✅ Nach einer Weile erholt es sich normalerweise | ❌ Ohne Reduzierung der Frequenz treten weiterhin Fehler auf |
| Merkmale der Spitzenzeit | Häufig während der nordamerikanischen Arbeitszeiten (9AM-5PM PT) | Unabhängig von der Uhrzeit, Fehler bei Überschreitung des Limits |
| Grundlegende Lösung | Wiederholung + Ersatzmodell + Stoßzeiten vermeiden | Anfragerate reduzieren oder Tarif upgraden |
Kurzdiagnose
- 503 gesehen → Googles Problem, warten Sie oder wechseln Sie das Modell
- 429 gesehen → Sie fragen zu schnell an, verlangsamen Sie oder upgraden Sie Ihren Tarif
🎯 Technischer Hinweis: Die gleichzeitige Behandlung von 503- und 429-Fehlern in einer Produktionsumgebung ist eine grundlegende Fähigkeit der API-Integration. Durch den Aufruf von Gemini-Modellen über die APIYI apiyi.com Plattform, die über integrierte intelligente Wiederholungsversuche und Lastverteilungsmechanismen verfügt, kann die von Endbenutzern wahrgenommene Häufigkeit von 503-Fehlern erheblich reduziert werden.
Lösung eins: Exponentieller Backoff bei Wiederholungsversuchen (die Grundlage)
Da 503 bedeutet "versuchen Sie es später noch einmal", ist die direkteste Reaktion ein automatischer Wiederholungsversuch. Aber nicht blind wiederholen – es muss eine "exponentielle Backoff"-Strategie verwendet werden, bei der das Wiederholungsintervall jedes Mal verdoppelt wird, um eine zusätzliche Belastung des Servers zu vermeiden.
Gemini 503 Exponentieller Backoff-Wiederholungsversuch-Code
import openai
import time
import random
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI vereinheitlichte Schnittstelle
)
def call_gemini_with_retry(messages, model="gemini-3.1-pro-preview", max_retries=5):
"""Gemini API-Aufruf mit exponentiellem Backoff"""
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model=model,
messages=messages
)
return response
except openai.APIStatusError as e:
if e.status_code == 503:
# Exponentieller Backoff: 2s, 4s, 8s, 16s, 32s + zufälliger Jitter
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"⏳ 503 High Demand - {attempt+1}. Wiederholungsversuch, warte {wait_time:.1f}s...")
time.sleep(wait_time)
elif e.status_code == 429:
# 429 Rate Limit: Länger warten
wait_time = 60 + random.uniform(0, 10)
print(f"🚫 429 Rate Limit - Warte {wait_time:.1f}s...")
time.sleep(wait_time)
else:
raise # Andere Fehler direkt auslösen
raise Exception(f"Nach {max_retries} Wiederholungsversuchen immer noch fehlgeschlagen")
# Anwendungsbeispiel
response = call_gemini_with_retry(
messages=[{"role": "user", "content": "Hello, Gemini!"}]
)
print(response.choices[0].message.content)
Kernparameter für exponentiellen Backoff bei Wiederholungsversuchen
| Parameter | Empfohlener Wert | Beschreibung |
|---|---|---|
| Maximale Wiederholungsversuche | 5 Mal | Mehr als 5 Versuche deuten im Grunde darauf hin, dass es sich nicht um ein temporäres Problem handelt |
| Anfängliche Wartezeit | 2 Sekunden | Zu kurz würde den Serverdruck erhöhen |
| Backoff-Multiplikator | 2x | Jedes Mal verdoppelt: 2s → 4s → 8s → 16s → 32s |
| Zufälliger Jitter | 0-1 Sekunden | Vermeidet, dass viele Clients gleichzeitig wiederholen |
| Maximale Wartezeit | 32 Sekunden | Nach über 32 Sekunden sollte auf eine alternative Lösung umgeschaltet werden |
💡 Praktischer Tipp: Zufälliger Jitter ist sehr wichtig. Wenn alle Clients genau nach 2 Sekunden erneut versuchen, entsteht ein "Herden-Effekt" – alle Anfragen strömen gleichzeitig wieder auf den Server, was zu einer weiteren 503-Meldung in der nächsten Runde führt. Durch Hinzufügen von zufälligem Jitter können die Wiederholungsanfragen verteilt werden.
Lösung zwei: Modell-Downgrade / Automatische Umschaltung auf Ersatzmodell
Wenn Gemini 3.1 Pro Preview dauerhaft 503 zurückgibt, ist die praktischste Lösung die automatische Umschaltung auf ein stabileres Ersatzmodell.
Gemini 503 Modell-Downgrade-Strategie
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# Modell-Downgrade-Kette: Zuerst das stärkste verwenden, bei Misserfolg downgraden
FALLBACK_MODELS = [
"gemini-3.1-pro-preview", # Erste Wahl: Neuestes und stärkstes
"gemini-3.0-pro", # Alternative 1: Pro der vorherigen Generation, stabiler
"gemini-2.5-flash-image-preview", # Alternative 2: Flash-Version, schnell
"gemini-2.5-flash", # Fallback: Stabilstes Flash
]
def call_with_fallback(messages):
"""API-Aufruf mit Modell-Downgrade"""
for model in FALLBACK_MODELS:
try:
response = client.chat.completions.create(
model=model,
messages=messages
)
if model != FALLBACK_MODELS[0]:
print(f"⚠️ Auf Ersatzmodell heruntergestuft: {model}")
return response
except openai.APIStatusError as e:
if e.status_code in (503, 429):
print(f"❌ {model} gibt {e.status_code} zurück, versuche nächstes Modell...")
continue
raise
raise Exception("Alle Modelle sind nicht verfügbar")
response = call_with_fallback(
messages=[{"role": "user", "content": "Analysiere die Leistungsengpässe dieses Codes"}]
)
Gemini Modell-Stabilitäts-Ranking
| Modell | Stabilität | 503-Häufigkeit | Geeignete Szenarien |
|---|---|---|---|
gemini-2.5-flash |
⭐⭐⭐⭐⭐ | Sehr niedrig | Fallback für hochverfügbare Produktionsumgebungen |
gemini-3.0-pro |
⭐⭐⭐⭐ | Niedrig | Stabile Szenarien, die Pro-Funktionen erfordern |
gemini-2.5-flash-image-preview |
⭐⭐⭐ | Mittel | Alternative für Bilderzeugung |
gemini-3.1-pro-preview |
⭐⭐ | Ziemlich hoch | Erfordert neueste Funktionen, akzeptiert aber gelegentliche Ausfälle |
gemini-3.1-flash-image-preview |
⭐⭐ | Ziemlich hoch | Nano Banana 2 Bilderzeugung |
🚀 Schnellstart: Über die APIYI apiyi.com Plattform können Sie mit einem einzigen API-Schlüssel alle Modelle der obigen Tabelle aufrufen. Der Modellwechsel erfordert lediglich die Anpassung des
model-Parameters, ohne die Authentifizierung neu konfigurieren zu müssen. Die Implementierung einer Modell-Downgrade-Kette im Code ist sehr praktisch.
Lösung drei: Aufruf außerhalb der Spitzenzeiten (kostenlose Lösung)
503 High Demand zeigt deutliche zeitliche Muster. Community-Daten zeigen:
- Spitzenzeiten (9AM-5PM PT): Ausfallrate ca. 45%
- Nebenzeiten (2AM-7AM PT): Ausfallrate unter 5%
Umrechnung in Pekinger Zeit:
| Zeitraum (Pekinger Zeit) | Entsprechende Pazifische Zeit | Gemini 503-Häufigkeit | Empfehlung |
|---|---|---|---|
| 1:00 Uhr morgens – 10:00 Uhr vormittags | 9AM-6PM PT (Vortag) | 🔴 Spitzenzeit | Vermeiden oder Ersatzmodell verwenden |
| 10:00 Uhr vormittags – 15:00 Uhr nachmittags | 6PM-11PM PT (Vortag) | 🟡 Mittel | Aufruf mit Wiederholungsmechanismus |
| 15:00 Uhr nachmittags – 23:00 Uhr abends | 11PM-7AM PT | 🟢 Nebenzeiten | Optimales Aufruffenster |
| 23:00 Uhr abends – 1:00 Uhr morgens | 7AM-9AM PT | 🟡 Mittel | Beginn der Zunahme |
Geeignete Szenarien für Aufrufe außerhalb der Spitzenzeiten
- Batch-Datenverarbeitung: Aufgaben, die keine Echtzeitantwort erfordern, in Nebenzeiten ausführen
- Geplante Aufgaben: Cron-Jobs für die Ausführung in Nebenzeiten einrichten
- Inhaltsgenerierung: Szenarien, in denen Artikel, Bilder usw. im Voraus generiert und verzögert veröffentlicht werden können
Lösung Vier: Kombinierte Strategie (Empfohlen für Produktionsumgebungen)
In realen Produktionsumgebungen reicht eine einzelne Lösung oft nicht aus. Es wird empfohlen, die ersten 3 Lösungen zu kombinieren:
Produktionsreife Gemini API-Aufrufstrategie
import openai
import time
import random
from datetime import datetime
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
FALLBACK_MODELS = [
"gemini-3.1-pro-preview",
"gemini-3.0-pro",
"gemini-2.5-flash",
]
def smart_gemini_call(messages, max_retries=3):
"""
Produktionsreifer Gemini API-Aufruf
Strategie: Exponentieller Backoff-Retry + Modell-Downgrade + Fehlerklassifizierung
"""
for model in FALLBACK_MODELS:
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model=model,
messages=messages,
timeout=30
)
return response, model
except openai.APIStatusError as e:
if e.status_code == 503:
if attempt < max_retries - 1:
wait = (2 ** attempt) + random.uniform(0, 1)
print(f"⏳ {model} 503 - Wiederholung {attempt+1}/{max_retries}, warte {wait:.1f}s")
time.sleep(wait)
else:
print(f"⚠️ {model} weiterhin 503, Downgrade auf das nächste Modell")
break # Schleife für Wiederholungen verlassen, Modell wechseln
elif e.status_code == 429:
wait = 60
print(f"🚫 {model} 429 Ratenbegrenzung - warte {wait}s")
time.sleep(wait)
else:
raise
except openai.APITimeoutError:
print(f"⏰ {model} Anfrage-Timeout, versuche nächstes Modell")
break
raise Exception("Alle Modelle und Wiederholungen fehlgeschlagen, bitte Netzwerk prüfen oder später erneut versuchen")
# Verwendung
response, used_model = smart_gemini_call(
messages=[{"role": "user", "content": "你好"}]
)
print(f"✅ Verwendetes Modell: {used_model}")
print(response.choices[0].message.content)
Vollständige produktionsreife Kapselung anzeigen (inkl. Logging, Monitoring, Caching)
import openai
import time
import random
import hashlib
import json
import logging
from datetime import datetime
from functools import lru_cache
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger("gemini_client")
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# Einfacher Anfrage-Cache
_cache = {}
def get_cache_key(messages, model):
"""Generiert den Cache-Schlüssel für die Anfrage"""
content = json.dumps(messages, sort_keys=True) + model
return hashlib.md5(content.encode()).hexdigest()
def gemini_call_production(
messages,
models=None,
max_retries=3,
cache_ttl=3600,
enable_cache=True
):
"""
Produktionsreife Gemini API-Aufruf-Kapselung
Eigenschaften:
- Exponentieller Backoff-Retry (behandelt 503)
- Automatisches Modell-Downgrade
- Antwort-Caching (reduziert redundante Anfragen)
- Strukturierte Protokollierung
"""
if models is None:
models = ["gemini-3.1-pro-preview", "gemini-3.0-pro", "gemini-2.5-flash"]
# Cache prüfen
if enable_cache:
cache_key = get_cache_key(messages, models[0])
if cache_key in _cache:
cached_time, cached_response = _cache[cache_key]
if time.time() - cached_time < cache_ttl:
logger.info("Cache-Treffer, API-Aufruf übersprungen")
return cached_response, "cache"
errors = []
for model in models:
for attempt in range(max_retries):
try:
start_time = time.time()
response = client.chat.completions.create(
model=model,
messages=messages,
timeout=30
)
elapsed = time.time() - start_time
logger.info(f"Erfolg | model={model} | Dauer={elapsed:.2f}s")
# In den Cache schreiben
if enable_cache:
_cache[cache_key] = (time.time(), response)
return response, model
except openai.APIStatusError as e:
errors.append(f"{model}:{e.status_code}")
if e.status_code == 503:
if attempt < max_retries - 1:
wait = (2 ** attempt) + random.uniform(0, 1)
logger.warning(f"503 | model={model} | retry={attempt+1} | wait={wait:.1f}s")
time.sleep(wait)
else:
logger.warning(f"503 anhaltend | model={model} | Downgrade auf nächstes Modell")
break
elif e.status_code == 429:
logger.warning(f"429 Ratenbegrenzung | model={model}")
time.sleep(60)
else:
raise
except Exception as e:
logger.error(f"Ausnahme | model={model} | error={e}")
break
raise Exception(f"Alle Versuche fehlgeschlagen: {errors}")

Lösung Fünf: Intelligentes Routing über eine API-Proxy-Plattform
Wenn Sie die oben genannten komplexen Wiederholungs- und Fallback-Logiken nicht selbst implementieren möchten, gibt es eine noch einfachere Option: die Nutzung einer API-Proxy-Plattform mit integrierten intelligenten Routing-Funktionen.
Wie eine API-Proxy-Plattform Gemini 503-Probleme löst
Professionelle API-Proxy-Dienste verfügen typischerweise über:
- Multi-Key-Round-Robin: Die Plattform verwaltet mehrere Google API-Schlüssel und wechselt automatisch, wenn ein einzelner Schlüssel ratenbegrenzt wird.
- Intelligente Wiederholung: Die Plattform implementiert auf ihrer Ebene exponentielles Backoff für Wiederholungsversuche, was für Entwickler transparent ist.
- Lastverteilung: Verteilt Anfragen auf mehrere Google-Konten und Regionen.
- Fehlererkennung: Erkennt die Plattform eine erhöhte Häufigkeit von 503-Fehlern für ein bestimmtes Modell, reduziert sie automatisch den Anteil der diesem Modell zugewiesenen Anfragen.
🎯 Technischer Hinweis: Die APIYI-Plattform (apiyi.com) bietet die oben genannten intelligenten Routing-Funktionen für Gemini-Modelle. Bei der Verwendung von OpenAI-kompatiblen Schnittstellen übernimmt die Plattform im Backend automatisch die 503-Wiederholungsversuche und die Multi-Key-Lastverteilung, sodass Entwickler keine komplexe Fehlertoleranzlogik selbst implementieren müssen.
Minimales Codebeispiel für die API-Proxy-Plattform-Lösung
import openai
# APIYI API-Proxy-Dienst verwenden, 503-Fehlerbehandlung wird von der Plattform übernommen
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# So einfach ist das, keine manuelle 503-Behandlung erforderlich
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": "你好"}]
)
print(response.choices[0].message.content)
Vollständiger Fehlerbehebungsprozess für Gemini API-Fehler
Wenn Sie auf Gemini API-Fehler stoßen, befolgen Sie diesen Prozess, um das Problem schnell zu lokalisieren:
Schritt Eins: Fehlercode prüfen
| Fehlercode | Fehlermeldung | Typ | Sofortige Maßnahme |
|---|---|---|---|
| 503 | "high demand" / "overloaded" | Serverkapazität unzureichend | Auf Wiederholung warten oder Modell wechseln |
| 429 | "resource exhausted" | Persönliche Ratenbegrenzung | Anfragerate reduzieren oder Plan upgraden |
| 400 | "invalid request" | Fehlerhafte Anfrageparameter | Anfrageformat und Parameter prüfen |
| 401 | "unauthorized" | Authentifizierung fehlgeschlagen | API-Schlüssel prüfen |
| 500 | "internal error" | Interner Serverfehler | Auf Wiederholung warten |
Schritt Zwei: Unterscheidung zwischen 503 und 429
- Mehrere API-Schlüssel melden Fehler → 503, dies ist ein Problem mit den Google-Servern.
- Nur Ihr Schlüssel meldet Fehler → 429, dies ist ein Problem mit Ihrem persönlichen Limit.
Schritt Drei: Die entsprechende Lösung wählen
- 503: Exponentielles Backoff für Wiederholungsversuche → Modell-Fallback → Aufrufe außerhalb der Spitzenzeiten
- 429: Anfragerate reduzieren → Abrechnung aktivieren und auf Tier 1 upgraden (kostenlose Stufe 5-15 RPM, Tier 1 ist 150-300 RPM)
Häufig gestellte Fragen
Q1: Warum erhalte ich trotz Bezahlung immer noch 503 High Demand?
503 hat absolut nichts damit zu tun, ob Sie bezahlt haben oder nicht. 503 ist ein Problem der unzureichenden Serverkapazität von Google, das sowohl kostenlose Nutzer als auch Unternehmenskunden betrifft. Dies unterscheidet sich von der 429-Ratenbegrenzung – 429 kann durch ein Upgrade des Tarifs gelöst werden, 503 jedoch nicht. Bei einem 503-Fehler wird empfohlen, exponentielles Backoff für Wiederholungsversuche zu verwenden oder zu einer stabileren Modellversion zu wechseln. Durch den Modellaufruf über die APIYI apiyi.com Plattform kann die wahrgenommene Häufigkeit von 503-Fehlern durch Multi-Key-Lastverteilung reduziert werden.
Q2: Wann wird der 503-Fehler bei Gemini 3.1 Pro Preview behoben sein?
Historischen Erfahrungen zufolge dauert die Hochphase der 503-Fehler nach der Veröffentlichung eines neuen Modells typischerweise 1-3 Wochen und verbessert sich deutlich, sobald Google die Kapazität schrittweise erweitert. Auch Gemini 3.0 Pro erlebte bei seiner Veröffentlichung eine ähnliche 503-Welle und ist jetzt sehr stabil. Während der Wartezeit wird empfohlen, eine Modell-Downgrade-Strategie zu implementieren, die bei einem 503-Fehler automatisch auf gemini-3.0-pro oder gemini-2.5-flash zurückfällt.
Q3: Sind „high demand“ und „model is overloaded“ derselbe Fehler?
Im Wesentlichen sind es unterschiedliche Formulierungen für dasselbe Problem. "This model is currently experiencing high demand" und "The model is overloaded" sind beides 503-Statuscodes, die beide auf eine unzureichende Serverkapazität von Google hinweisen. Ersteres ist in neueren API-Versionen häufiger, letzteres trat in früheren Versionen häufiger auf. Die Handhabung ist identisch.
Q4: Gibt es eine Möglichkeit, im Voraus zu wissen, ob die Gemini API einen 503-Fehler zurückgibt?
Es gibt keine offizielle Vorwarnung. Sie können jedoch auf einige Signale achten: (1) Die ersten 1-2 Wochen nach der Veröffentlichung eines neuen Google-Modells sind eine Hochrisikophase; (2) Während der nordamerikanischen Arbeitszeiten (Pekinger Zeit: frühe Morgenstunden bis Vormittag) treten 503-Fehler häufiger auf; (3) Das Community-Forum discuss.ai.google.dev bietet in der Regel Echtzeit-Feedback. Es wird empfohlen, die Wiederholungs- und Downgrade-Logik immer im Code zu behalten, anstatt sie erst bei Problemen ad-hoc hinzuzufügen. Die APIYI apiyi.com Plattform bietet eine Überwachung des Modellverfügbarkeitsstatus, die Ihnen helfen kann, dies frühzeitig zu erkennen.
Q5: Sollte ich 503 und 429 gleichzeitig im Code behandeln?
Unbedingt. In Produktionsumgebungen treten sowohl 503 als auch 429 auf, und die Behandlungsstrategien sind unterschiedlich, aber gleichermaßen wichtig. Für 503 wird exponentielles Backoff für Wiederholungsversuche + Modell-Downgrade verwendet, für 429 eine Reduzierung der Anfrägefrequenz + Ratenbegrenzung mit Warteschlange. Der Code unter „Lösung vier: Kombinierte Strategie“ in diesem Artikel behandelt beide Fehlertypen gleichzeitig und kann direkt in Produktionsumgebungen eingesetzt werden.
Zusammenfassung
Die Essenz des 503-Fehlers This model is currently experiencing high demand ist sehr einfach: Googles Serverkapazität ist vorübergehend nicht ausreichend. Insbesondere bei neuen Modellen wie Gemini 3.1 Pro Preview oder Nano Banana 2 ist dies in der Einführungsphase fast unvermeidlich.
5 Lösungsansätze nach empfohlener Priorität:
- Exponentielles Backoff für Wiederholungsversuche — Die Grundlage, die jedes Projekt haben sollte
- Modell-Downgrade-Kette — Bei 503-Fehlern automatisch zu einem stabileren Modell wechseln
- Zeitversetzte Aufrufe — Nicht-Echtzeit-Aufgaben in Zeiten geringer Auslastung planen
- Kombinierte Strategie — Empfohlen für Produktionsumgebungen: Wiederholungsversuche + Downgrade + Fehlerklassifizierung
- Intelligentes Routing über API-Proxy-Dienst — Der einfachste Weg, die Plattform übernimmt die Fehlertoleranzlogik
Unabhängig davon, welche Lösung Sie wählen, lautet das Kernprinzip: 503 ist nicht Ihr Fehler, aber Sie müssen ihn elegant behandeln. Es wird empfohlen, die Gemini-Modellreihe schnell über APIYI apiyi.com zu integrieren, um die Vorteile des integrierten intelligenten Routings und der Wiederholungsfunktionen zu nutzen.
Referenzen
-
Google AI Developers Forum – 503 Error Discussions
- Link:
discuss.ai.google.dev - Beschreibung: Community-Diskussionen und offizielle Antworten zum Gemini API 503 Fehler
- Link:
-
Google Gemini API – Rate Limits Documentation
- Link:
ai.google.dev/gemini-api/docs/rate-limits - Beschreibung: Offizielle Ratenbegrenzungsregeln und Quotenbeschreibungen für die verschiedenen Tiers
- Link:
-
Google Gemini API – Troubleshooting Guide
- Link:
ai.google.dev/gemini-api/docs/troubleshooting - Beschreibung: Offizieller Leitfaden zur Fehlerbehebung
- Link:
📝 Autor: APIYI Team | Für technischen Austausch und API-Integration besuchen Sie apiyi.com