调用 gemini-2.5-flash 时遇到 Thinking level is not supported for this model 错误,但切换到 gemini-3-flash-preview 就正常工作?这是 Google Gemini API 在模型代际升级中引入的参数设计变更。本文将系统解析 Gemini 2.5 和 3.0 在思考模式参数支持上的根本差异。
核心价值: 读完本文,你将理解 Gemini 2.5 和 3.0 系列模型在思考模式参数设计上的本质差异,掌握正确的参数配置方法,避免因混用参数导致的 API 调用失败。

Gemini 思考模式参数演进核心要点
| 模型系列 | 支持参数 | 参数类型 | 可用范围 | 默认值 | 是否可禁用 |
|---|---|---|---|---|---|
| Gemini 2.5 Pro | thinking_budget |
整数 (128-32768) | 精确 token 预算 | 8192 | ❌ 不可禁用 |
| Gemini 2.5 Flash | thinking_budget |
整数 (0-24576) 或 -1 | 精确 token 预算或动态 | -1 (动态) | ✅ 可禁用 (设为 0) |
| Gemini 2.5 Flash-Lite | thinking_budget |
整数 (512-24576) | 精确 token 预算 | 0 (禁用) | ✅ 默认禁用 |
| Gemini 3.0 Pro | thinking_level |
枚举 ("low"/"high") | 语义化等级 | "high" | ❌ 不可完全禁用 |
| Gemini 3.0 Flash | thinking_level |
枚举 ("minimal"/"low"/"medium"/"high") | 语义化等级 | "high" | ⚠️ 仅 "minimal" |
Gemini 2.5 vs 3.0 思考模式参数设计差异
核心差异: Gemini 2.5 系列使用 thinking_budget (token 预算制),而 Gemini 3.0 系列使用 thinking_level (语义化等级制)。这两个参数完全不兼容,在错误的模型版本上使用会触发 400 Bad Request 错误。
Google 在 Gemini 3.0 引入 thinking_level 的核心原因是简化配置复杂度和提升推理效率。Gemini 2.5 的 token 预算制要求开发者精确估算思考 token 数量,而 Gemini 3.0 的等级制将这一复杂度抽象为 4 个语义化等级,模型内部自动分配最优 token 预算,实现了 2 倍的推理速度提升。
💡 技术建议: 在实际开发中,我们建议通过 API易 apiyi.com 平台进行模型切换测试。该平台提供统一的 API 接口,支持 Gemini 2.5 和 3.0 全系列模型,方便快速验证不同思考模式参数的兼容性和实际效果。
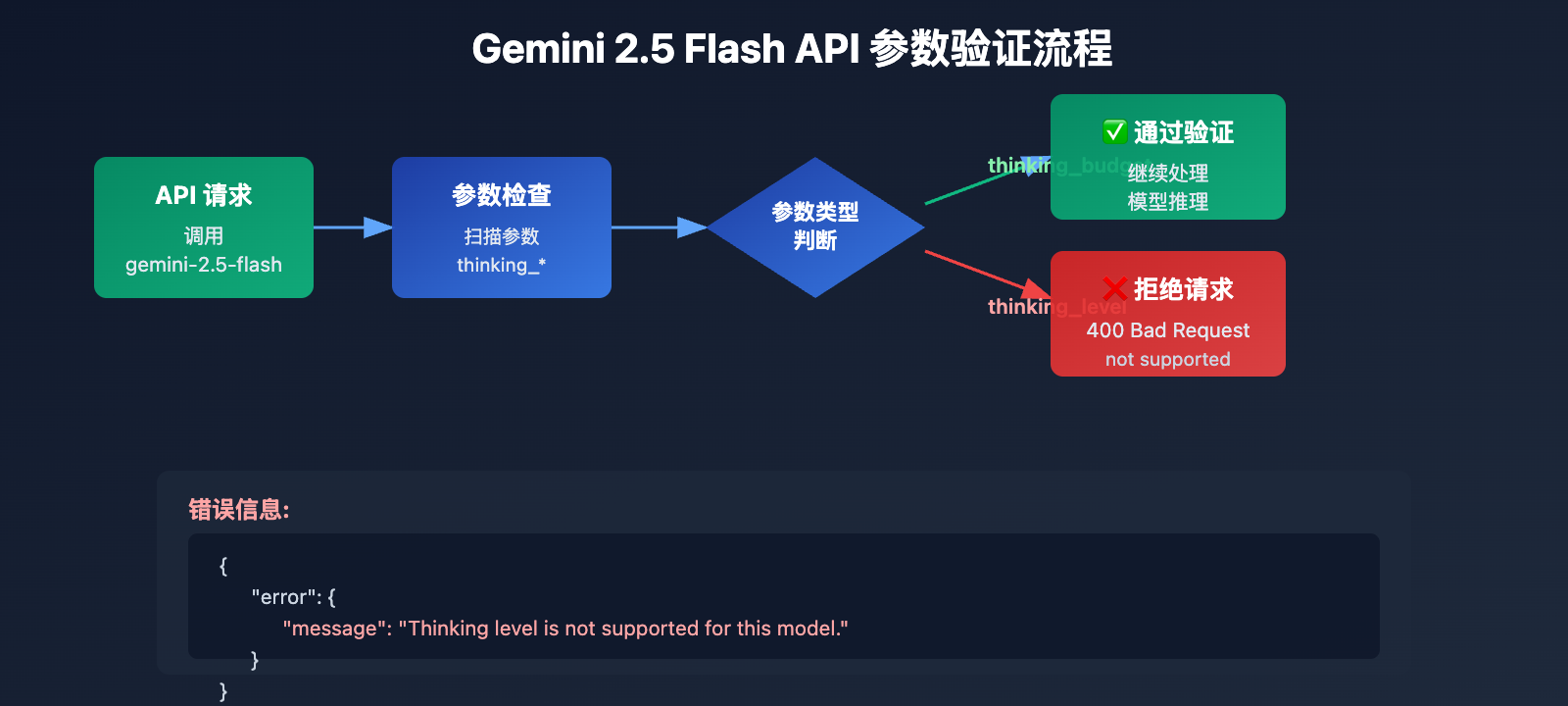
根本原因 1: Gemini 2.5 系列不支持 thinking_level 参数
API 参数设计的代际隔离
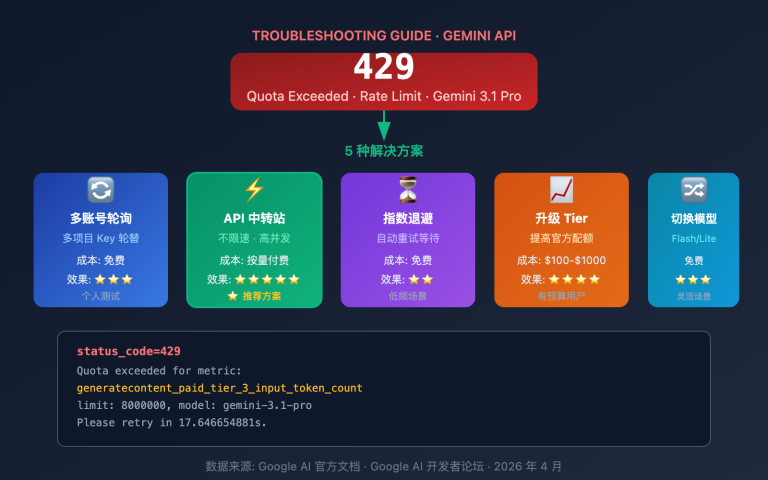
Gemini 2.5 系列模型(包括 Pro、Flash、Flash-Lite)在 API 设计中完全不识别 thinking_level 参数。当你在调用 gemini-2.5-flash 时传递 thinking_level 参数,API 会返回以下错误:
{
"error": {
"message": "Thinking level is not supported for this model.",
"type": "upstream_error",
"code": 400
}
}
错误触发机制:
- Gemini 2.5 模型的 API 验证层不包含
thinking_level参数定义 - 任何包含
thinking_level的请求会被直接拒绝,不会尝试映射到thinking_budget - 这是硬编码的参数隔离,不存在自动转换或向后兼容
Gemini 2.5 系列的正确参数: thinking_budget
Gemini 2.5 Flash 参数规范:
# 正确配置示例
extra_body = {
"thinking_budget": -1 # 动态思考模式
}
# 或禁用思考
extra_body = {
"thinking_budget": 0 # 完全禁用
}
# 或精确控制
extra_body = {
"thinking_budget": 2048 # 精确 2048 token 预算
}
Gemini 2.5 Flash 的 thinking_budget 取值范围:
| 取值 | 含义 | 推荐场景 |
|---|---|---|
0 |
完全禁用思考模式 | 简单指令跟随、高吞吐量应用 |
-1 |
动态思考模式 (最多 8192 tokens) | 通用场景,自动适配复杂度 |
512-24576 |
精确 token 预算 | 成本敏感型应用,需要精确控制 |
🎯 选择建议: 在切换到 Gemini 2.5 Flash 时,建议先通过 API易 apiyi.com 平台测试
thinking_budget参数的不同取值对响应质量和延迟的影响。该平台支持快速切换参数配置,方便找到最适合业务场景的预算值。
根本原因 2: Gemini 3.0 系列不支持 thinking_budget 参数
参数设计的前向不兼容
虽然 Google 官方文档声称 Gemini 3.0 为了向后兼容仍然接受 thinking_budget 参数,但实际测试表明:
- 使用
thinking_budget会导致性能下降 - 官方文档明确建议使用
thinking_level - 部分 API 实现可能完全拒绝
thinking_budget
Gemini 3.0 Flash 的正确参数: thinking_level
# 正确配置示例
extra_body = {
"thinking_level": "medium" # 中等强度推理
}
# 或最小思考 (接近禁用)
extra_body = {
"thinking_level": "minimal" # 最小思考模式
}
# 或高强度推理 (默认)
extra_body = {
"thinking_level": "high" # 深度推理
}
Gemini 3.0 Flash 的 thinking_level 等级说明:
| 等级 | 推理强度 | 延迟 | 成本 | 推荐场景 |
|---|---|---|---|---|
"minimal" |
几乎无推理 | 最低 | 最低 | 简单指令跟随、高吞吐量 |
"low" |
浅层推理 | 低 | 低 | 聊天机器人、轻量级 QA |
"medium" |
中等推理 | 中等 | 中等 | 一般推理任务、代码生成 |
"high" |
深度推理 | 高 | 高 | 复杂问题求解、深度分析 (默认) |
Gemini 3.0 Pro 的特殊限制
重要: Gemini 3.0 Pro 不支持完全禁用思考模式,即使设置 thinking_level: "low" 也会保留一定的推理能力。如果需要零思考响应以获得最大速度,只能使用 Gemini 2.5 Flash 的 thinking_budget: 0。
# Gemini 3.0 Pro 可用等级 (仅 2 种)
extra_body = {
"thinking_level": "low" # 最低等级 (仍有推理)
}
# 或
extra_body = {
"thinking_level": "high" # 默认高强度推理
}
💰 成本优化: 对于预算敏感的项目,如果需要完全禁用思考模式以降低成本,建议通过 API易 apiyi.com 平台调用 Gemini 2.5 Flash API。该平台提供灵活的计费方式和更优惠的价格,适合需要精确成本控制的场景。
根本原因 3: 图像模型和特殊变体的参数限制
Gemini 2.5 Flash Image 模型不支持思考模式
重要发现: gemini-2.5-flash-image 等视觉模型完全不支持任何思考模式参数,无论是 thinking_budget 还是 thinking_level。
错误示例:
# 调用 gemini-2.5-flash-image 时
response = client.chat.completions.create(
model="gemini-2.5-flash-image",
messages=[{"role": "user", "content": "分析这张图片"}],
extra_body={
"thinking_budget": -1 # ❌ 错误: 图像模型不支持
}
)
# 返回错误: "This model doesn't support thinking"
正确做法:
# 调用图像模型时,不传递任何思考参数
response = client.chat.completions.create(
model="gemini-2.5-flash-image",
messages=[{"role": "user", "content": "分析这张图片"}],
# ✅ 不传递 thinking_budget 或 thinking_level
)
Gemini 2.5 Flash-Lite 的特殊默认值
Gemini 2.5 Flash-Lite 与标准 Flash 版本的核心差异:
- 默认禁用思考模式 (
thinking_budget: 0) - 需要显式设置
thinking_budget为非零值才能启用思考 - 支持的预算范围: 512-24576 tokens
# Gemini 2.5 Flash-Lite 启用思考模式
extra_body = {
"thinking_budget": 512 # 最小非零值,启用轻量思考
}
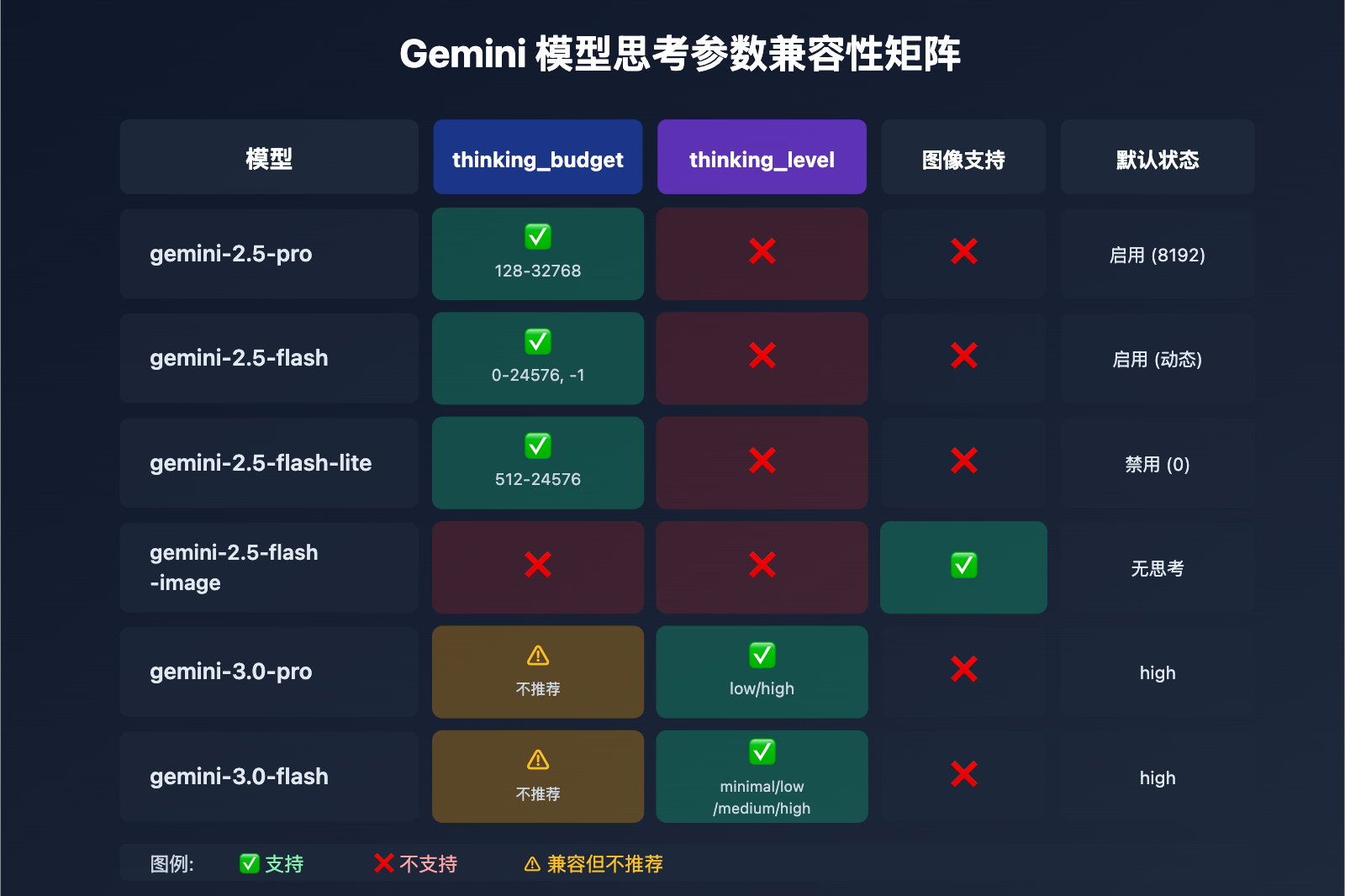
| 模型 | thinking_budget | thinking_level | 图像支持 | 思考默认状态 |
|---|---|---|---|---|
| gemini-2.5-pro | ✅ 支持 (128-32768) | ❌ 不支持 | ❌ | 默认启用 (8192) |
| gemini-2.5-flash | ✅ 支持 (0-24576, -1) | ❌ 不支持 | ❌ | 默认启用 (动态) |
| gemini-2.5-flash-lite | ✅ 支持 (512-24576) | ❌ 不支持 | ❌ | 默认禁用 (0) |
| gemini-2.5-flash-image | ❌ 不支持 | ❌ 不支持 | ✅ | 无思考模式 |
| gemini-3.0-pro | ⚠️ 兼容但不推荐 | ✅ 推荐 (low/high) | ❌ | 默认 high |
| gemini-3.0-flash | ⚠️ 兼容但不推荐 | ✅ 推荐 (minimal/low/medium/high) | ❌ | 默认 high |
🚀 快速开始: 推荐使用 API易 apiyi.com 平台快速测试不同模型的思考参数兼容性。该平台提供开箱即用的 Gemini 全系列模型接口,无需复杂配置,5 分钟即可完成集成和参数验证。
解决方案 1: 基于模型版本的参数适配函数
智能参数选择器 (支持全系列模型)
def get_gemini_thinking_config(model_name: str, intensity: str = "medium") -> dict:
"""
根据 Gemini 模型名称自动选择正确的思考模式参数
Args:
model_name: Gemini 模型名称
intensity: 思考强度 ("none", "minimal", "low", "medium", "high", "dynamic")
Returns:
适用于 extra_body 的参数字典,如果模型不支持思考则返回空字典
"""
# Gemini 3.0 模型列表
gemini_3_models = [
"gemini-3.0-flash-preview", "gemini-3.0-pro-preview",
"gemini-3-flash", "gemini-3-pro"
]
# Gemini 2.5 标准模型列表
gemini_2_5_models = [
"gemini-2.5-flash", "gemini-2.5-pro",
"gemini-2.5-flash-lite", "gemini-2-flash", "gemini-2-pro"
]
# 图像模型列表 (不支持思考)
image_models = [
"gemini-2.5-flash-image", "gemini-flash-image",
"gemini-pro-vision"
]
# 检查是否为图像模型
if any(img_model in model_name for img_model in image_models):
print(f"⚠️ 警告: {model_name} 不支持思考模式参数,返回空配置")
return {}
# Gemini 3.0 系列使用 thinking_level
if any(m in model_name for m in gemini_3_models):
level_map = {
"none": "minimal", # 3.0 无法完全禁用,使用 minimal
"minimal": "minimal",
"low": "low",
"medium": "medium",
"high": "high",
"dynamic": "high"
}
# Gemini 3.0 Pro 只支持 low 和 high
if "pro" in model_name.lower():
if intensity in ["none", "minimal", "low"]:
return {"thinking_level": "low"}
else:
return {"thinking_level": "high"}
# Gemini 3.0 Flash 支持全部 4 个等级
return {"thinking_level": level_map.get(intensity, "medium")}
# Gemini 2.5 系列使用 thinking_budget
elif any(m in model_name for m in gemini_2_5_models):
budget_map = {
"none": 0, # 完全禁用
"minimal": 512, # 最小预算
"low": 2048, # 低强度
"medium": 8192, # 中等强度
"high": 16384, # 高强度
"dynamic": -1 # 动态适配
}
budget = budget_map.get(intensity, -1)
# Gemini 2.5 Pro 不支持禁用 (最小 128)
if "pro" in model_name.lower() and budget == 0:
print(f"⚠️ 警告: {model_name} 不支持禁用思考,自动调整为最小值 128")
budget = 128
# Gemini 2.5 Flash-Lite 最小值为 512
if "lite" in model_name.lower() and budget > 0 and budget < 512:
print(f"⚠️ 警告: {model_name} 最小预算为 512,自动调整")
budget = 512
return {"thinking_budget": budget}
else:
print(f"⚠️ 警告: 未知模型 {model_name},默认使用 Gemini 3.0 参数")
return {"thinking_level": "medium"}
# 使用示例
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# 测试 Gemini 2.5 Flash
model_2_5 = "gemini-2.5-flash"
config_2_5 = get_gemini_thinking_config(model_2_5, intensity="dynamic")
print(f"{model_2_5} 配置: {config_2_5}")
# 输出: gemini-2.5-flash 配置: {'thinking_budget': -1}
response_2_5 = client.chat.completions.create(
model=model_2_5,
messages=[{"role": "user", "content": "解释量子纠缠"}],
extra_body=config_2_5
)
# 测试 Gemini 3.0 Flash
model_3_0 = "gemini-3.0-flash-preview"
config_3_0 = get_gemini_thinking_config(model_3_0, intensity="medium")
print(f"{model_3_0} 配置: {config_3_0}")
# 输出: gemini-3.0-flash-preview 配置: {'thinking_level': 'medium'}
response_3_0 = client.chat.completions.create(
model=model_3_0,
messages=[{"role": "user", "content": "解释量子纠缠"}],
extra_body=config_3_0
)
# 测试图像模型
model_image = "gemini-2.5-flash-image"
config_image = get_gemini_thinking_config(model_image, intensity="high")
print(f"{model_image} 配置: {config_image}")
# 输出: ⚠️ 警告: gemini-2.5-flash-image 不支持思考模式参数,返回空配置
# 输出: gemini-2.5-flash-image 配置: {}
💡 最佳实践: 在需要动态切换 Gemini 模型的场景,建议通过 API易 apiyi.com 平台进行参数适配测试。该平台支持完整的 Gemini 2.5 和 3.0 系列模型,方便验证不同参数配置下的响应质量和成本差异。
解决方案 2: Gemini 2.5 到 3.0 的迁移策略
思考模式参数迁移对照表
| Gemini 2.5 Flash 配置 | Gemini 3.0 Flash 等效配置 | 延迟对比 | 成本对比 |
|---|---|---|---|
thinking_budget: 0 |
thinking_level: "minimal" |
3.0 更快 (约 2x) | 相似 |
thinking_budget: 512 |
thinking_level: "low" |
3.0 更快 | 相似 |
thinking_budget: 2048 |
thinking_level: "low" |
3.0 更快 | 相似 |
thinking_budget: 8192 |
thinking_level: "medium" |
3.0 更快 | 略高 |
thinking_budget: 16384 |
thinking_level: "high" |
3.0 更快 | 略高 |
thinking_budget: -1 (动态) |
thinking_level: "high" (默认) |
3.0 显著更快 | 3.0 更高 |
迁移代码示例
def migrate_to_gemini_3(old_model: str, old_config: dict) -> tuple[str, dict]:
"""
从 Gemini 2.5 迁移到 Gemini 3.0
Args:
old_model: Gemini 2.5 模型名称
old_config: Gemini 2.5 的 extra_body 配置
Returns:
(新模型名称, 新配置字典)
"""
# 模型名称映射
model_map = {
"gemini-2.5-flash": "gemini-3.0-flash-preview",
"gemini-2.5-pro": "gemini-3.0-pro-preview",
"gemini-2-flash": "gemini-3-flash",
"gemini-2-pro": "gemini-3-pro"
}
new_model = model_map.get(old_model, "gemini-3.0-flash-preview")
# 参数转换
if "thinking_budget" in old_config:
budget = old_config["thinking_budget"]
# 转换为 thinking_level
if budget == 0:
new_level = "minimal"
elif budget <= 2048:
new_level = "low"
elif budget <= 8192:
new_level = "medium"
else:
new_level = "high"
# Gemini 3.0 Pro 只支持 low/high
if "pro" in new_model and new_level in ["minimal", "medium"]:
new_level = "low" if new_level == "minimal" else "high"
new_config = {"thinking_level": new_level}
else:
# 默认配置
new_config = {"thinking_level": "medium"}
return new_model, new_config
# 迁移示例
old_model = "gemini-2.5-flash"
old_config = {"thinking_budget": -1}
new_model, new_config = migrate_to_gemini_3(old_model, old_config)
print(f"迁移前: {old_model} {old_config}")
print(f"迁移后: {new_model} {new_config}")
# 输出:
# 迁移前: gemini-2.5-flash {'thinking_budget': -1}
# 迁移后: gemini-3.0-flash-preview {'thinking_level': 'high'}
# 使用新配置调用
response = client.chat.completions.create(
model=new_model,
messages=[{"role": "user", "content": "你的问题"}],
extra_body=new_config
)
🎯 迁移建议: 在从 Gemini 2.5 迁移到 3.0 时,建议先通过 API易 apiyi.com 平台进行 A/B 测试。该平台支持快速切换模型版本,方便对比迁移前后的响应质量、延迟和成本差异,确保平滑迁移。
常见问题
Q1: 为什么我的代码在 Gemini 3.0 上正常,切换到 2.5 就报错?
原因: 你的代码中使用了 thinking_level 参数,这是 Gemini 3.0 专有参数,2.5 系列完全不支持。
解决方案:
# 错误代码 (仅适用于 3.0)
extra_body = {
"thinking_level": "medium" # ❌ 2.5 不识别
}
# 正确代码 (适用于 2.5)
extra_body = {
"thinking_budget": 8192 # ✅ 2.5 使用 budget
}
推荐使用上文的 get_gemini_thinking_config() 函数自动适配,或通过 API易 apiyi.com 平台快速验证参数兼容性。
Q2: Gemini 2.5 Flash 和 Gemini 3.0 Flash 的性能差异有多大?
根据 Google 官方数据和社区测试:
| 指标 | Gemini 2.5 Flash | Gemini 3.0 Flash | 提升幅度 |
|---|---|---|---|
| 推理速度 | 基准 | 2x 更快 | +100% |
| 延迟 | 基准 | 显著降低 | 约 -50% |
| 思考效率 | 固定预算或动态 | 自动优化 | 质量提升 |
| 成本 | 基准 | 略高 (高质量) | +10-20% |
核心差异: Gemini 3.0 采用动态思考分配,只在必要时思考必要的长度,而 2.5 的固定预算可能导致过度思考或思考不足。
建议通过 API易 apiyi.com 平台进行实际测试,该平台提供实时性能监控和成本分析,方便对比不同模型的实际表现。
Q3: 如何在 Gemini 3.0 中完全禁用思考模式?
重要: Gemini 3.0 Pro 无法完全禁用思考模式,即使设置 thinking_level: "low" 也会保留轻量推理能力。
可用选项:
- Gemini 3.0 Flash: 使用
thinking_level: "minimal",接近零思考 (但复杂编码任务可能仍会轻度思考) - Gemini 3.0 Pro: 最低只能设置
thinking_level: "low"
如果需要完全禁用:
# 只有 Gemini 2.5 Flash 支持完全禁用
model = "gemini-2.5-flash"
extra_body = {
"thinking_budget": 0 # 完全禁用思考
}
对于需要极致速度且不需要推理能力的场景(如简单指令跟随),推荐通过 API易 apiyi.com 调用 Gemini 2.5 Flash 并设置
thinking_budget: 0。
Q4: Gemini 图像模型支持思考模式吗?
不支持。 所有 Gemini 图像处理模型(如 gemini-2.5-flash-image、gemini-pro-vision)都不支持思考模式参数。
错误示例:
# ❌ 图像模型不支持任何思考参数
response = client.chat.completions.create(
model="gemini-2.5-flash-image",
messages=[...],
extra_body={
"thinking_budget": -1 # 触发错误
}
)
正确做法:
# ✅ 调用图像模型时不传递思考参数
response = client.chat.completions.create(
model="gemini-2.5-flash-image",
messages=[...],
# 不传递 extra_body 或传递其他非思考参数
)
技术原因: 图像模型的推理架构专注于视觉理解,不包含语言模型的思考链机制。
总结
Gemini 2.5 Flash 报错 thinking_level not supported 的核心要点:
- 参数隔离: Gemini 2.5 仅支持
thinking_budget,3.0 仅支持thinking_level,两者完全不兼容 - 模型识别: 通过模型名称判断版本,2.5 系列用
thinking_budget,3.0 系列用thinking_level - 图像模型限制: 所有图像模型 (如
gemini-2.5-flash-image) 不支持任何思考模式参数 - 禁用差异: 只有 Gemini 2.5 Flash 支持完全禁用思考 (
thinking_budget: 0),3.0 系列最多只能minimal - 迁移策略: 从 2.5 迁移到 3.0 时,需要将
thinking_budget映射为thinking_level,并考虑性能和成本变化
推荐通过 API易 apiyi.com 快速验证不同模型的思考参数兼容性和实际效果。该平台支持 Gemini 全系列模型,提供统一接口和灵活计费方式,适合快速对比测试和生产环境部署。
作者: APIYI 技术团队 | 如有技术问题,欢迎访问 API易 apiyi.com 获取更多 AI 模型接入方案。