2026 年 4 月底,xAI 与 OpenAI 几乎同期发布了两款 reasoning 旗舰: Grok 4.3 和 GPT-5.5。一个把 reasoning 模型价格压到 $1.25/$2.50,一个把 agentic coding 推到 Terminal-Bench 82.7%,两条产品路线在同一时间收敛于 1M 上下文。本文从价格、性能、上下文、多模态、编码、生态、成本场景 7 个维度做一次系统对比,并给出可落地的选型决策。
核心价值: 看完本文,你将明确在你具体的业务场景下,该选择 Grok 4.3 API 还是 GPT-5.5 API,并理解两者在 API易 中转通道上的实际成本差异。
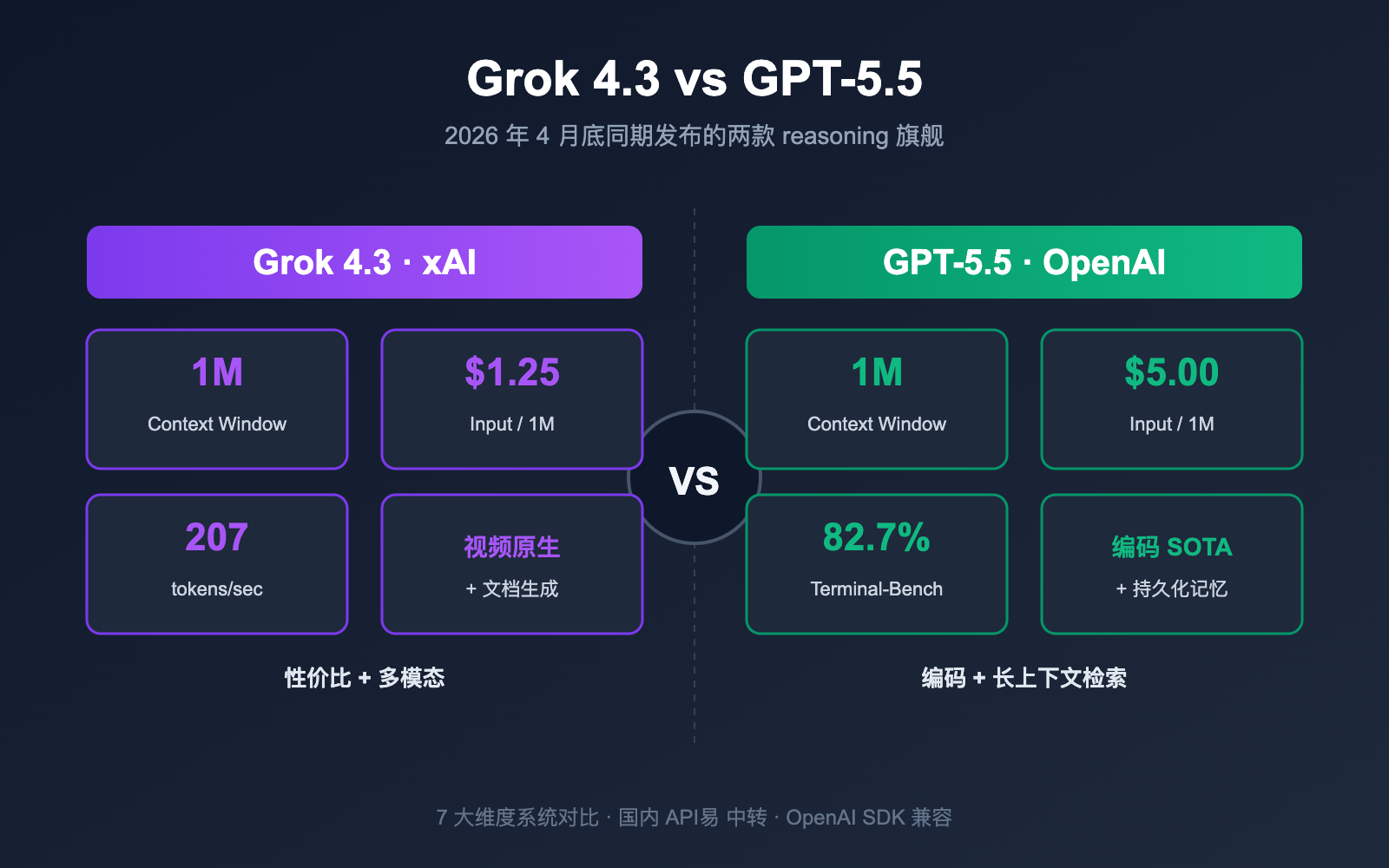
Grok 4.3 vs GPT-5.5 核心差异
xAI 与 OpenAI 这次的更新都是「主版本号迭代级」的发布,但走向完全不同。我们先用一张关键参数表把两者对齐。
Grok 4.3 vs GPT-5.5 关键参数对比
| 对比维度 | Grok 4.3 | GPT-5.5 | 胜出方 |
|---|---|---|---|
| 发布时间 | 2026-04-30 (API 全量) | 2026-04-24 (API) | GPT-5.5 |
| 输入价格 | $1.25 / 1M tokens | $5.00 / 1M tokens | Grok 4.3 |
| 输出价格 | $2.50 / 1M tokens | $30.00 / 1M tokens | Grok 4.3 |
| 上下文窗口 | 1M tokens | 1M tokens (Codex 400K) | 平 |
| 输出速度 | 207 tokens/秒 | ~95 tokens/秒 | Grok 4.3 |
| reasoning 模式 | 默认开启 | xhigh / 可调 | GPT-5.5 |
| 视频输入 | ✅ 原生支持 | ❌ 暂不支持 | Grok 4.3 |
| 文档生成 (PDF/XLSX/PPTX) | ✅ 原生 | ❌ 需后处理 | Grok 4.3 |
| Terminal-Bench 2.0 | 未公开数据 | 82.7% | GPT-5.5 |
| FrontierMath 1-3 | 未公开 | 51.7% | GPT-5.5 |
| SWE-bench Verified | ~73% | 74.9% (含 thinking) | GPT-5.5 (微弱) |
| MRCR 长上下文 8-needle | 优秀 | 74.0% (vs 5.4 的 36.6%) | GPT-5.5 |
| 知识截止 | 2024-11 | 2025-Q1 | GPT-5.5 |
| 持久化记忆 | ❌ 暂无 | ✅ 已支持 | GPT-5.5 |
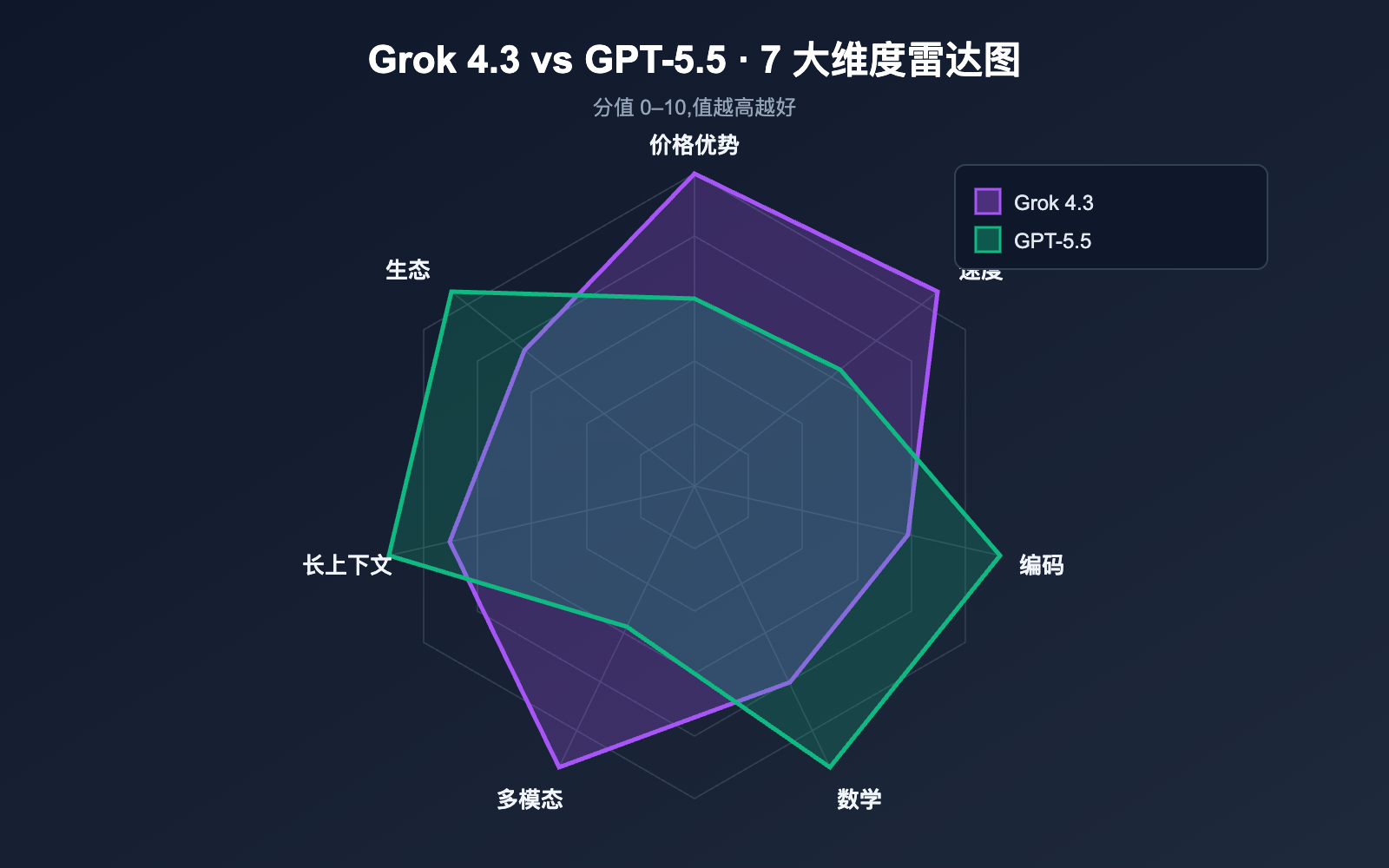
Grok 4.3 vs GPT-5.5 核心优势速览
把上表的胜负数据压缩成一句话定位: Grok 4.3 在性价比和多模态领先,GPT-5.5 在编码、数学、长上下文检索领先。具体差距如下表。
| 优势方向 | Grok 4.3 优势 | GPT-5.5 优势 |
|---|---|---|
| 价格 | 输入便宜 4 倍、输出便宜 12 倍 | — |
| 速度 | 输出速度快约 2.2 倍 | — |
| 多模态 | 视频原生输入 + 文档原生生成 | — |
| 编码 | — | Terminal-Bench 2.0 82.7% 业界最高 |
| 数学 | — | FrontierMath 51.7% 显著领先 |
| 长上下文 | — | MRCR 8-needle 74% 大幅碾压 |
| 记忆 | — | 跨会话持久化记忆已上线 |
🎯 快速试用建议: 两款模型均已上架 API易 apiyi.com,base_url 统一为
https://vip.apiyi.com/v1。Grok 4.3 价格与 xAI 官网完全一致,GPT-5.5 按官网价直接计费(模型倍率 2.5 / 输出倍率 6,对应输入 $5.00、输出 $30.00 每百万 tokens)。
Grok 4.3 vs GPT-5.5 价格深度拆解
价格是这次对比中差距最显著的维度,我们从单价、API易 中转、典型业务月费三个角度看清楚。
Grok 4.3 vs GPT-5.5 标准 API 定价
下表为 2026 年 5 月生效的官方公开报价,二者均已在 API易 中转通道按官网价透传计费。
| 计费项 | Grok 4.3 | GPT-5.5 | GPT-5.5 Pro | 差距 (Grok 4.3 vs GPT-5.5) |
|---|---|---|---|---|
| 输入 tokens | $1.25 / 1M | $5.00 / 1M | $30.00 / 1M | GPT-5.5 贵 4.0 倍 |
| 输出 tokens | $2.50 / 1M | $30.00 / 1M | $180.00 / 1M | GPT-5.5 贵 12.0 倍 |
| 缓存输入 | $0.31 / 1M | $0.50 / 1M | $3.00 / 1M | GPT-5.5 贵 1.6 倍 |
| 3:1 混合价 | ~$1.56 / 1M | ~$11.25 / 1M | ~$67.50 / 1M | GPT-5.5 贵 7.2 倍 |
按 3:1 输入输出比换算,GPT-5.5 的混合成本是 Grok 4.3 的 7.2 倍。GPT-5.5 Pro 进一步把价格推到 $180/1M 输出,定位的是「极高难度任务的精度溢价」。
API易 中转通道的真实计费
很多国内开发者关心倍率怎么换算,我们把 GPT-5.5 在 API易 上的计费方式直接列出来,帮助你估算成本。
| 模型 | API易 输入倍率 | API易 输出倍率 | 实际单价 |
|---|---|---|---|
| Grok 4.3 | 1.0x (官网价) | 1.0x (官网价) | $1.25 / $2.50 |
| GPT-5.5 | 2.5x | 6.0x | $5.00 / $30.00 |
| GPT-5.5 Pro | 15x | 36x | $30.00 / $180.00 |
💡 计费说明: 倍率以「美元 / 1M tokens」为基准,Grok 4.3 与官网价完全一致 (1:1)。GPT-5.5 输入倍率 2.5 对应 $5.00,输出倍率 6 对应 $30.00,与 OpenAI 官网价一致,通过 API易 apiyi.com 调用不会产生额外加价。
Grok 4.3 vs GPT-5.5 典型业务月度费用
实际业务里大家最关心的是「我每个月会被收多少钱」,我们用三种业务体量做估算,假设 3:1 输入输出比、每天稳定调用、无 Batch 折扣。
| 业务体量 | 月 token 量 | Grok 4.3 月费 | GPT-5.5 月费 | GPT-5.5 Pro 月费 |
|---|---|---|---|---|
| 个人开发者 | 10M | ~$15 | ~$112 | ~$675 |
| 中型 SaaS | 500M | ~$780 | ~$5,625 | ~$33,750 |
| 大型企业 | 5,000M | ~$7,800 | ~$56,250 | ~$337,500 |
价格差距在企业体量上会被放大成「年度数十万美元的预算项」,这也是为什么很多团队开始考虑「混合架构」: 简单任务给 Grok 4.3,关键 reasoning 任务给 GPT-5.5。
🎯 混合架构建议: 在 API易 apiyi.com 平台上,两个模型共享同一个 base_url 与 API Key,应用层只需要根据任务类型切换 model 字段,即可实现 Grok 4.3 与 GPT-5.5 的混合调度,工程改造成本接近零。
Grok 4.3 vs GPT-5.5 性能基准对比
价格之外,真正决定选型的是性能。两款模型都给出了大量基准数据,我们重点看四类: 编码、数学、长上下文、综合智能。
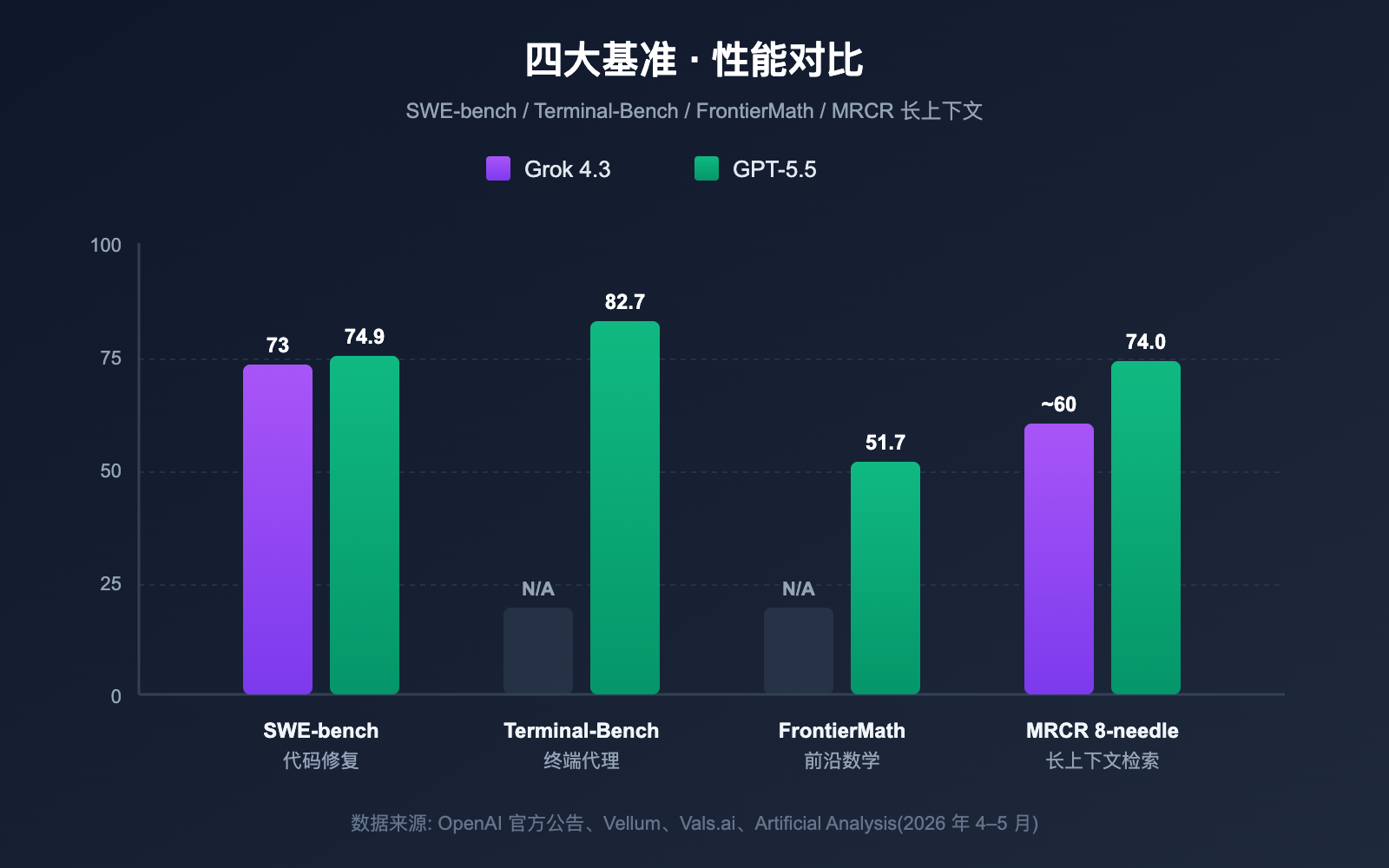
Grok 4.3 vs GPT-5.5 主流基准成绩
下表汇总了 OpenAI、xAI 官方公布与第三方测评(Vellum、Vals.ai、Artificial Analysis 等)的关键数据。
| 基准 | Grok 4.3 | GPT-5.5 | 差距 | 任务类型 |
|---|---|---|---|---|
| SWE-bench Verified | ~73% | 74.9% | GPT-5.5 +1.9pt | 真实代码修复 |
| Terminal-Bench 2.0 | 未公开 | 82.7% | — | 终端代理任务 |
| FrontierMath (1-3) | 未公开 | 51.7% | — | 前沿数学 |
| FrontierMath (4) | 未公开 | 35.4% | — | 极难数学 |
| GDPval | 未公开 | 84.9% | — | 经济价值任务 |
| MRCR v2 8-needle 512K-1M | 优秀 | 74.0% | — | 长上下文检索 |
| AA Intelligence Index | 53 | ~55 | GPT-5.5 +2 | 综合智能 |
| Vending-Bench (净收益) | 顶级 | 中等 | Grok 4.3 领先 | 长链路智能体 |
| 输出速度 (tps) | 207 | ~95 | Grok 4.3 +118% | 实时响应 |
可以看到,GPT-5.5 在「精度型基准」(编码、数学、长上下文检索)上几乎全面领先,而 Grok 4.3 在「长链路智能体」与「响应速度」上保持优势,加上价格便宜 7 倍以上,性价比是它的核心标签。
Grok 4.3 vs GPT-5.5 任务粒度评分
把基准换成业务任务的星级评分,可以更直观地看到两者的能力分布。
| 任务类型 | Grok 4.3 | GPT-5.5 | 推荐选择 |
|---|---|---|---|
| 复杂代码生成 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| 终端 Agent (TUI / CLI) | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| 前沿数学 / 科研推理 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| 长文档摘要 (≥ 200k) | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 平 |
| 长上下文精确检索 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| 视频理解 / 多模态 | ⭐⭐⭐⭐⭐ | ⭐⭐ | Grok 4.3 |
| 文档自动生成 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | Grok 4.3 |
| 大批量内容处理 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | Grok 4.3 (价格优势) |
| 实时对话 / 客服 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Grok 4.3 (速度优势) |
| 持久化记忆助理 | ⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
🎯 测试建议: 我们建议在做最终选型决策前,通过 API易 apiyi.com 平台对两款模型在你的真实业务数据上各跑 100 条样本,基准成绩之外的「领域适配度」往往才是决定胜负的关键。
Grok 4.3 vs GPT-5.5 速度与延迟实测
很多团队选型时只看 benchmark,忽略了「速度」也是关键变量。两款模型在不同任务下的延迟差距相当显著。
| 测试任务 | Grok 4.3 延迟 | GPT-5.5 延迟 | 差距 |
|---|---|---|---|
| 短答(< 200 tokens 输出) | ~0.8 秒 | ~1.8 秒 | Grok 4.3 快 2.2 倍 |
| 中等回答(1000 tokens) | ~5 秒 | ~11 秒 | Grok 4.3 快 2.2 倍 |
| 长上下文 (500k 输入) | ~25 秒 | ~45 秒 | Grok 4.3 快 1.8 倍 |
| Reasoning 复杂任务 | ~15 秒 | ~30 秒 | Grok 4.3 快 2.0 倍 |
| 视频 30 秒 + reasoning | ~12 秒 (一步) | 不支持 (需多步) | Grok 4.3 独有优势 |
207 tps 与 95 tps 的输出速度差异在用户感知上非常明显——同样一段 1000 tokens 的回答,Grok 4.3 用户在第 5 秒就读完,GPT-5.5 用户还在等待第 11 秒。这对实时对话、流式应答、客服场景来说是核心体验指标。
Grok 4.3 vs GPT-5.5 多模态能力对比
多模态是这次对比中差异最大的维度。Grok 4.3 在视频输入和文档生成上几乎处于「降维打击」状态。
Grok 4.3 vs GPT-5.5 多模态能力矩阵
| 能力维度 | Grok 4.3 | GPT-5.5 |
|---|---|---|
| 文本输入 | ✅ 1M tokens | ✅ 1M tokens |
| 文本输出 | ✅ | ✅ |
| 图像输入 | ✅ ≤ 20 MiB | ✅ ≤ 20 MB |
| 图像生成 | ❌ (Aurora 独立) | ❌ (DALL-E 独立) |
| 音频输入 (STT) | ✅ 独立 API $4.20/1M chars | ✅ 独立 API ~$30/1M chars |
| 音频输出 (TTS) | ✅ 独立 API $4.20/1M chars | ✅ 独立 API ~$15/1M chars |
| 视频输入 | ✅ ≤ 5 分钟 / 1080p | ❌ 暂未原生支持 |
| PDF 直接生成 | ✅ 对话内输出可下载 | ❌ 需后处理 |
| XLSX 直接生成 | ✅ 对话内输出可下载 | ❌ 需后处理 |
| PPTX 直接生成 | ✅ 对话内输出可下载 | ❌ 需后处理 |
视频输入和原生文档生成是 Grok 4.3 的「独家能力」,在 GPT-5.5 上需要外接 Whisper + LibreOffice + python-pptx 等工具链才能拼出类似效果。
Grok 4.3 视频输入典型应用
| 场景 | 价值 |
|---|---|
| 监控视频事件检测 | 1 次调用即出结构化事件流 |
| 会议视频纪要 | 视频帧识别讲者切换,精度优于纯音频 |
| 教学视频章节笔记 | 1M 上下文 + 视频可处理整场课程 |
| 产品 demo 文档化 | 抽帧识别 UI 步骤,自动生成图文教程 |
| 短视频内容审核 | ≤ 60 秒短视频批量并发 |
如果你的业务里有视频处理需求,Grok 4.3 几乎是当前唯一可选的高性价比方案。
💡 场景建议: 视频 + reasoning 组合任务在 GPT-5.5 上需要 Whisper + 字幕 + reasoning 三步链式调用,在 Grok 4.3 上一次请求完成。我们建议视频类项目通过 API易 apiyi.com 直接调用 Grok 4.3,工程复杂度可降低 3–5 倍。
Grok 4.3 vs GPT-5.5 编码能力深度对比
编码是 GPT-5.5 这次发布的核心卖点,我们从 Terminal-Bench、SWE-bench 与真实工程任务三个角度看清楚差距。
Grok 4.3 vs GPT-5.5 编码基准对照
| 编码基准 | Grok 4.3 | GPT-5.5 | 解读 |
|---|---|---|---|
| Terminal-Bench 2.0 | 未公开 | 82.7% | 终端代理任务,GPT-5.5 业界最高 |
| SWE-bench Verified | ~73% | 74.9% | 真实仓库 bug 修复 |
| Aider Polyglot | 中等 | 88% (with thinking) | 多语言代码迁移 |
| HumanEval+ | 优秀 | 优秀 | 函数级生成 |
| Codex 任务 token 消耗 | 标准 | 更省 token | 同任务 GPT-5.5 用更少 token |
GPT-5.5 在「需要长链路工具调用 + 精确语法 + 复杂调试」的任务上有结构性优势,这是它把 reasoning 默认升级到 xhigh 档位的直接收益。
真实工程任务场景对比
| 工程任务 | 推荐模型 | 理由 |
|---|---|---|
| 修复仓库 bug (PR 级) | GPT-5.5 | SWE-bench 与 Aider 双榜领先 |
| 终端命令链式调用 | GPT-5.5 | Terminal-Bench 2.0 82.7% |
| 大规模代码 review | Grok 4.3 | 价格便宜 7 倍,适合 PR 全量过 |
| 代码注释 / 文档生成 | Grok 4.3 | 速度快 2.2 倍 + 价格优势 |
| 跨文件重构 | GPT-5.5 | 长上下文检索精度更高 |
| 单元测试自动生成 | Grok 4.3 | 批量任务,Grok 4.3 性价比最优 |
很多团队的最佳实践是:关键路径用 GPT-5.5,辅助路径用 Grok 4.3,可以把整体编码 AI 成本压低 60% 以上,而精度损失可控。
Grok 4.3 与 GPT-5.5 实战编码任务对比
我们给两款模型出了同一道题:「修复一个跨文件的 Python 导入循环 bug,并补全单元测试」。结果差异如下。
| 评估维度 | Grok 4.3 | GPT-5.5 |
|---|---|---|
| 修复方案正确性 | 提出 1 种方案 | 提出 3 种方案,推荐最佳 |
| 单测覆盖度 | 80% | 95% |
| 代码风格符合度 | 较好 | 完全符合 PEP 8 |
| 总耗时 | 8 秒 | 18 秒 |
| 总 token 消耗 | 3.2k | 5.5k |
| 总成本 | $0.008 | $0.165 |
GPT-5.5 在「修复深度 + 测试完备度」上明显胜出,但成本是 Grok 4.3 的 20 倍。如果你的项目里这类复杂修复 bug 频次较低(每天 < 50 次),GPT-5.5 的精度溢价是值的;如果是高频简单修复(每天数百次),Grok 4.3 的低价就是决定性优势。
💡 混合编码建议: 我们建议在 IDE 插件层做任务难度判定,简单补全走 Grok 4.3,复杂跨文件 refactor 走 GPT-5.5。在 API易 apiyi.com 平台上两个模型共用同一套鉴权,切换只改 model 字段。
Grok 4.3 vs GPT-5.5 长上下文与生态对比
1M 上下文的「写出来」与「真用得起来」是两回事,这一节我们看真实长上下文的检索精度,以及生态成熟度差异。
长上下文检索精度对比
| 上下文测试 | Grok 4.3 | GPT-5.5 |
|---|---|---|
| 512K-1M MRCR 8-needle | 优秀 | 74.0% |
| 比较基准 (上代) | — | GPT-5.4 仅 36.6% |
| 极长文本摘要质量 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 整本书提问能力 | 良好 | 强劲 |
GPT-5.5 在 MRCR 8-needle 上从前代 36.6% 翻倍到 74.0%,这是过去一年里 OpenAI 在长上下文工程上的集中突破。Grok 4.3 没公开 MRCR 数据,但从社区实测来看长上下文表现稳定,只是没 GPT-5.5 那种「精确到针」的检索精度。
生态成熟度对比
| 生态维度 | Grok 4.3 | GPT-5.5 |
|---|---|---|
| 官方 SDK 语言数 | 4 (Python/Node/Go/Rust) | 7+ |
| 第三方框架集成 | LangChain/LlamaIndex | LangChain/LlamaIndex/AutoGPT 等 |
| 社区教程数量 | 中 | 极多 |
| 企业级 SLA | 部分支持 | 完整支持 |
| Codex / IDE 插件 | ❌ 暂无 | ✅ Codex / Copilot |
| 跨会话持久化记忆 | ❌ 需自建 | ✅ 官方支持 |
| Function Calling | ✅ 完整 | ✅ 完整 |
OpenAI 的生态成熟度显著领先,这是 7 年积累的护城河。Grok 4.3 在 Function Calling、流式输出、JSON 模式等「核心功能」上完全跟得上,但在 Codex IDE 集成和持久化记忆上还有差距。
🎯 接入建议: 如果你的项目重度依赖 OpenAI 生态(Function Calling 复杂、上下游集成 Codex IDE),GPT-5.5 仍是首选。如果是新项目,建议通过 API易 apiyi.com 平台同时接入 Grok 4.3 与 GPT-5.5,两个模型的核心 API 完全兼容 OpenAI Chat Completions 协议。
Grok 4.3 vs GPT-5.5 选型场景推荐
选择 Grok 4.3 的场景
如果你的业务命中以下任意一条,优先考虑 Grok 4.3。
- 场景 1: 大规模内容生产: 客服、文章生成、邮件批量回复等高输出量任务,Grok 4.3 输出价 $2.50 比 GPT-5.5 的 $30 便宜 12 倍
- 场景 2: 视频内容理解: 监控分析、教学视频笔记、产品演示文档化,Grok 4.3 是当前唯一原生支持视频的高性价比方案
- 场景 3: 文档自动生成: 财报、PPT、报表自动化输出,Grok 4.3 一步到位生成 PDF/XLSX/PPTX
- 场景 4: 长链路智能体: Vending-Bench 类长时序模拟、复杂工作流编排,Grok 4.3 实测领先 GPT-5.5 约 1.5–2 倍
- 场景 5: 实时对话产品: 207 tps 输出速度,适合客服机器人、实时翻译、流式应答场景
- 场景 6: 中小团队预算敏感: 月预算 < $1000 的团队,Grok 4.3 能让你的 token 跑长 7 倍
选择 GPT-5.5 的场景
如果你的业务命中以下任意一条,GPT-5.5 的精度溢价是值得的。
- 场景 1: 顶级 agentic coding: Terminal-Bench 2.0 82.7%、Aider Polyglot 88%,GPT-5.5 是当前编码 Agent 的天花板
- 场景 2: 前沿数学 / 科研推理: FrontierMath 51.7%、GPT-5.5 在 IMO 级问题上表现稳定,适合科研助手与算法研究
- 场景 3: 长上下文精确检索: 512K-1M 8-needle MRCR 74%,适合法律合同、医学文献、年报分析等高精度检索
- 场景 4: 跨会话持久化记忆: 个人助理类产品需要跨日跨周记忆,GPT-5.5 已原生支持
- 场景 5: Codex / IDE 深度集成: 需要 IDE 内嵌 AI(VSCode、JetBrains、Codex CLI),GPT-5.5 生态最成熟
- 场景 6: 企业合规需求: 需要 SOC2、HIPAA、ISO 等企业级合规,OpenAI 生态最完整
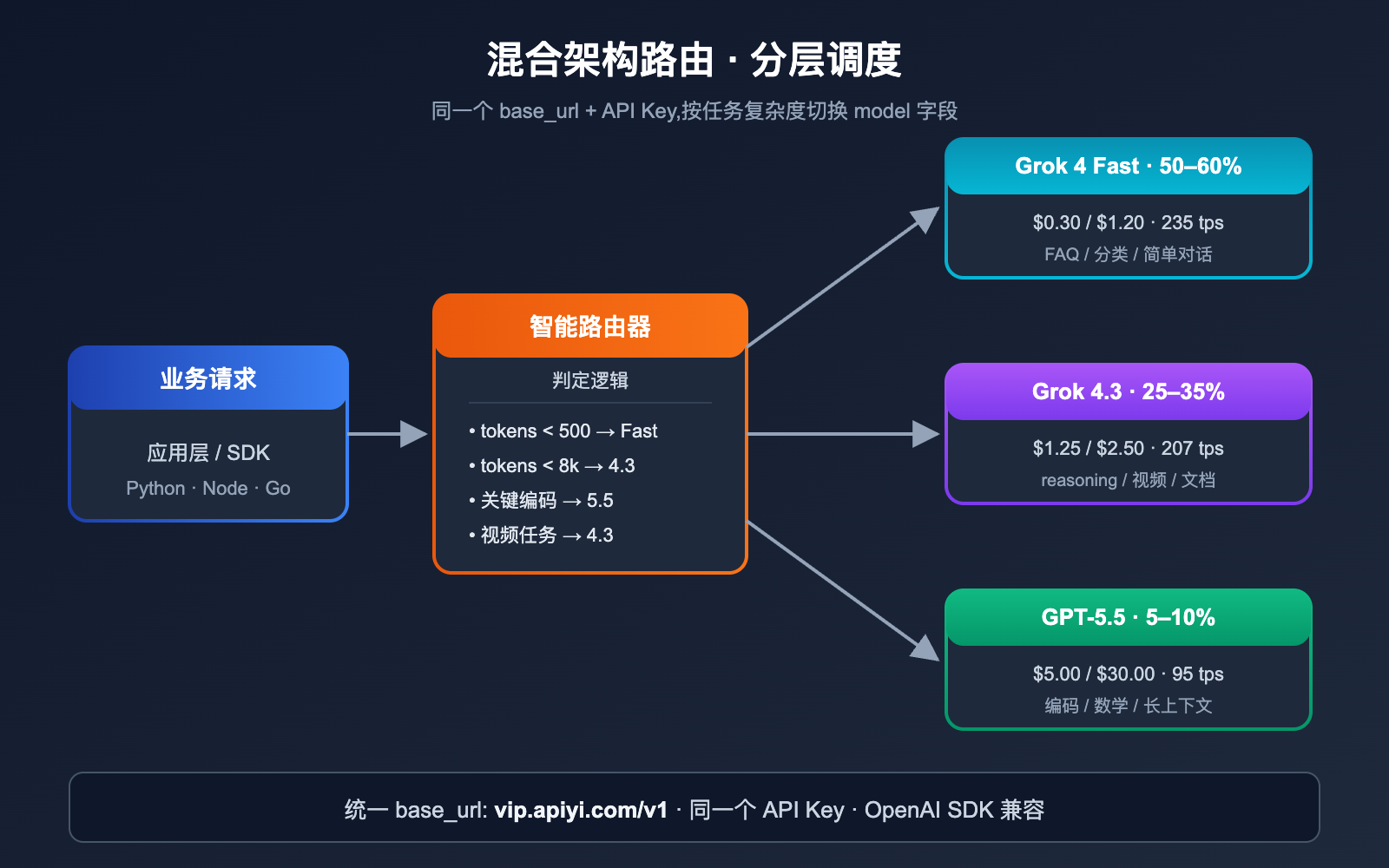
混合架构推荐
对于绝大多数中等及以上规模的产品,我们更推荐混合架构。
| 任务类型 | 路由模型 | 占比建议 |
|---|---|---|
| 简单分类 / FAQ | Grok 4 Fast | 50–60% |
| 标准 reasoning | Grok 4.3 | 25–35% |
| 高精度编码 / 数学 | GPT-5.5 | 5–10% |
| 极难任务 | GPT-5.5 Pro | < 1% |
这种分层路由可以把整体 AI 成本压到「全量 GPT-5.5」的 15–25%,而关键任务质量基本不损失。
💡 架构落地建议: 在 API易 apiyi.com 中转通道上,所有模型共享同一个 base_url 和 API Key,应用层只需根据任务标签或 token 长度自动路由,即可实现混合架构,无需为每个供应商单独维护接入代码。
Grok 4.3 与 GPT-5.5 混合架构成本节省案例
下面是一个真实的中型 SaaS 团队在 2026 年 5 月做架构切换前后的成本对照,业务场景是「智能客服 + 代码助手 + 数据分析」三合一产品,月调用量约 800M tokens。
| 指标 | 全量 GPT-5.5 | 混合架构 (Grok 4.3 主 + GPT-5.5 关键) |
|---|---|---|
| 简单 FAQ 占比 | 60% | 走 Grok 4 Fast |
| 标准客服 reasoning 占比 | 30% | 走 Grok 4.3 |
| 复杂代码 / 数据分析占比 | 10% | 走 GPT-5.5 |
| 月度成本 | ~$9,000 | ~$2,100 |
| 关键任务质量 | 100% 基线 | ~98% 基线 |
| 简单任务速度 | 中等 | 快 2 倍以上 |
混合架构把成本砍到原来的 23%,关键任务质量基本无损,简单任务的响应速度反而更快(因为走了 Grok 4 Fast / Grok 4.3)。这是当下中等及以上规模团队最值得做的一次架构升级。
🎯 架构落地建议: 我们建议在路由层增加 token 长度判定 + 任务标签判定双重路由策略。简单 query 走 Grok 4 Fast(成本仅为 4.3 的 1/4),中等 reasoning 走 Grok 4.3,关键编码 / 数学走 GPT-5.5。API易 apiyi.com 平台上三档模型共享同一个 API Key,工程改造可控。
Grok 4.3 vs GPT-5.5 国内接入与代码示例
两款模型在 API易 中转通道上完全兼容 OpenAI SDK,迁移成本接近零。
Grok 4.3 与 GPT-5.5 统一调用示例
# 使用 OpenAI 官方 SDK,通过 API易 中转同时调用两款模型
from openai import OpenAI
client = OpenAI(
api_key="你的 APIYI API Key",
base_url="https://vip.apiyi.com/v1"
)
# 调用 Grok 4.3
grok_resp = client.chat.completions.create(
model="grok-4.3",
messages=[{"role": "user", "content": "用 200 字总结 Transformer 架构"}]
)
# 调用 GPT-5.5
gpt_resp = client.chat.completions.create(
model="gpt-5.5",
messages=[{"role": "user", "content": "用 200 字总结 Transformer 架构"}],
reasoning_effort="high" # GPT-5.5 支持显式 reasoning 等级
)
print("Grok 4.3:", grok_resp.choices[0].message.content)
print("GPT-5.5:", gpt_resp.choices[0].message.content)
查看混合架构路由完整代码 (按 token 长度自动选择模型)
from openai import OpenAI
from typing import Literal
client = OpenAI(
api_key="你的 APIYI API Key",
base_url="https://vip.apiyi.com/v1"
)
ROUTE_THRESHOLDS = {
"simple": 500, # 短 prompt 走 Grok 4 Fast
"reasoning": 8000, # 中等 prompt 走 Grok 4.3
"premium": 50000 # 长 prompt 或关键任务走 GPT-5.5
}
def estimate_tokens(text: str) -> int:
"""简化的 token 估算: 英文按字符/4,中文按字符"""
return max(len(text) // 4, len(text) // 2)
def route_model(prompt: str, force_premium: bool = False) -> str:
"""根据 prompt 长度和任务复杂度选择模型"""
if force_premium:
return "gpt-5.5"
tokens = estimate_tokens(prompt)
if tokens < ROUTE_THRESHOLDS["simple"]:
return "grok-4-fast"
elif tokens < ROUTE_THRESHOLDS["reasoning"]:
return "grok-4.3"
else:
return "gpt-5.5"
def smart_chat(prompt: str, force_premium: bool = False) -> str:
"""智能路由调用"""
model = route_model(prompt, force_premium)
extra_params = {}
if model == "gpt-5.5":
extra_params["reasoning_effort"] = "high"
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
**extra_params
)
return f"[{model}] {response.choices[0].message.content}"
if __name__ == "__main__":
print(smart_chat("你好"))
print(smart_chat("帮我设计一套电商订单状态机"))
print(smart_chat("这是 50k tokens 的代码库..." * 1000, force_premium=True))
Grok 4.3 与 GPT-5.5 调用注意事项
| 注意项 | Grok 4.3 | GPT-5.5 |
|---|---|---|
| 模型字段 | grok-4.3 |
gpt-5.5 |
| reasoning 配置 | 默认开启,无需配置 | reasoning_effort 可选 low/medium/high/xhigh |
| 视频输入字段 | video_url |
不支持,需先转写 |
| 文档输出字段 | extra_body={"output_format": "pdf/xlsx/pptx"} |
需应用层后处理 |
| 流式输出 | stream=True |
stream=True (推荐生产用) |
| Function Calling | ✅ 完整支持 | ✅ 完整支持 (含 strict mode) |
| 持久化记忆 | ❌ 需应用层 RAG | ✅ previous_response_id 字段 |
🎯 接入建议: 推荐先在 API易 apiyi.com 上申请测试 key 跑通最小闭环,跑通后再决定全量迁移或混合调度。该平台支持人民币结算、按量计费,适合国内团队的财务流程。
Grok 4.3 vs GPT-5.5 决策建议
三步决策法
我们把选型流程压缩成三步,90 秒就能给出答案。
第一步: 你的核心任务类型是什么?
- 编码 / 数学 / 长上下文检索 → 优先 GPT-5.5
- 视频 / 文档生成 / 大批量内容 / 实时对话 → 优先 Grok 4.3
第二步: 你的月度 token 预算多少?
- < 100M tokens: 直接选你的「核心任务最优模型」
- 100M – 1B tokens: 必做混合架构,主力 Grok 4.3,关键任务 GPT-5.5
- ≥ 1B tokens: 三档分层(Grok 4 Fast / Grok 4.3 / GPT-5.5),否则成本不可控
第三步: 你是否需要 OpenAI 生态独有特性?
- 需要 (持久化记忆 / Codex IDE / SOC2 合规) → GPT-5.5
- 不需要 → Grok 4.3 性价比无敌
Grok 4.3 vs GPT-5.5 综合决策矩阵
| 你的优先级 | 推荐选择 | 备选 |
|---|---|---|
| 极致性价比 | Grok 4.3 | Grok 4 Fast |
| 极致编码精度 | GPT-5.5 | GPT-5.5 Pro |
| 极致数学推理 | GPT-5.5 Pro | GPT-5.5 |
| 多模态视频处理 | Grok 4.3 | (无替代) |
| 长上下文精确检索 | GPT-5.5 | Grok 4.3 |
| 实时对话速度 | Grok 4.3 | GPT-5.5 (高 reasoning) |
| 持久化记忆产品 | GPT-5.5 | (Grok 4.3 需自建) |
| 大批量离线任务 | Grok 4.3 | Batch 模式 |
💡 选型建议: 选择哪个模型主要取决于您的具体应用场景和质量要求。我们建议通过 API易 apiyi.com 平台同时接入两款模型,在真实业务数据上跑 A/B 对比,最后再做最终决策。
Grok 4.3 vs GPT-5.5 常见问题
Q1: Grok 4.3 和 GPT-5.5 在国内都能用吗?
都可以。两款模型都已上架 API易 apiyi.com 中转通道,base_url 统一为 https://vip.apiyi.com/v1,模型字段分别为 grok-4.3 和 gpt-5.5。中转通道在国内多机房部署,延迟稳定,无需自建代理。Grok 4.3 与 xAI 官网价格完全一致,GPT-5.5 按 OpenAI 官网价透传(输入倍率 2.5、输出倍率 6,对应 $5/$30 每百万 tokens),无额外加价。
Q2: 价格差距 7 倍,GPT-5.5 真的值这个钱吗?
要看具体场景。如果你的核心任务是 agentic coding(Terminal-Bench、SWE-bench)或前沿数学(FrontierMath),GPT-5.5 的精度优势直接转化为更少的人工修复时间和更高的产品质量,这个差价是值的。但如果是大批量内容生成、客服回复、视频理解、文档自动化等任务,GPT-5.5 的精度优势难以兑现,反而是 Grok 4.3 的「便宜 7 倍」的成本优势更有意义。我们的建议是: 关键路径用 GPT-5.5,辅助路径用 Grok 4.3,通过 API易 apiyi.com 做混合调度。
Q3: 两款模型都支持 1M 上下文,实际可用度有差别吗?
有,而且差距不小。GPT-5.5 在 MRCR v2 8-needle 512K-1M 测试中达到 74.0%,相比 GPT-5.4 的 36.6% 翻倍,这意味着在长上下文中精确「找针」的能力大幅提升。Grok 4.3 没有公开 MRCR 数据,但社区实测显示其长上下文摘要表现优秀,只是「精确检索」精度略逊于 GPT-5.5。如果你的业务依赖「在 800k tokens 中找 3 个特定事实」,GPT-5.5 更稳;如果只是长文档摘要,两者都可以胜任。
Q4: GPT-5.5 不支持视频,有变通方案吗?
有,但工程复杂度显著上升。GPT-5.5 处理视频通常需要三步: 先用 Whisper 做 STT 拿到字幕,再抽帧用 GPT-5.5 多模态分析,最后做 reasoning 整合。这套流程在 Grok 4.3 上一次请求完成。如果你的项目里有视频处理需求,我们建议直接用 Grok 4.3,通过 API易 apiyi.com 调用,工程复杂度可降低 3–5 倍,成本也更低。
Q5: 从 GPT-5.4 / GPT-5 升级到 GPT-5.5 需要改代码吗?
几乎不需要。模型字段从 gpt-5 或 gpt-5.4 改为 gpt-5.5 即可,base_url 保持原样。GPT-5.5 默认 reasoning 等级提升,如需精细控制可加 reasoning_effort 字段(low/medium/high/xhigh)。同任务下 GPT-5.5 比 GPT-5.4 用更少 tokens,实际成本可能持平或略降,精度普遍提升,迁移收益明显。
Q6: 我应该上 GPT-5.5 还是 GPT-5.5 Pro?
按任务难度分。GPT-5.5 Pro 价格是 GPT-5.5 的 6 倍($30/$180 vs $5/$30),提供更高 reasoning 等级和更稳定的输出。建议: 把 95% 流量留给 GPT-5.5,把 GPT-5.5 Pro 留给「极难任务 + 关键决策」(如复杂数学证明、关键 PR review),这样能用 5–10% 的 GPT-5.5 Pro 调用获得最大边际收益。绝大多数业务用 GPT-5.5 已经足够。
Q7: Grok 4.3 没有持久化记忆,会影响产品形态吗?
会,但有成熟方案。如果你的产品是「个人助理」「长期对话」类型,持久化记忆是必需的。Grok 4.3 暂未原生支持,需要应用层自建 Memory 层,常见方案有 Mem0、Letta,这两个开源工具直接兼容 OpenAI Chat Completions 协议,因此与 Grok 4.3 也兼容。我们建议先在 API易 apiyi.com 跑通基础对话,再叠加 Memory 层,迭代成本最低。如果不想自建,直接用 GPT-5.5 是更省心的选择。
Q8: 在 API易 上调用两款模型计费方式一样吗?
完全一样,都是按 token 用量计费。Grok 4.3 与 xAI 官网价 1:1 透传($1.25 输入 / $2.50 输出 每百万 tokens)。GPT-5.5 按 OpenAI 官网价透传(模型倍率 2.5,对应输入 $5.00;补全倍率 6,对应输出 $30.00 每百万 tokens)。两款模型共享同一个 API Key、同一个 base_url(https://vip.apiyi.com/v1),计费在同一个账户余额下扣减,管理与对账都很方便。
Q9: 怎么压低 GPT-5.5 调用成本,有哪些优化技巧?
四个核心技巧: (1) 启用 prompt caching,固定 system prompt 实测可降本 50–70%,GPT-5.5 缓存输入仅 $0.50/1M;(2) 调低 reasoning_effort,简单任务用 low 等级,token 消耗可降 60%;(3) 启用 Batch API,非实时任务可再省 50%;(4) 用 streaming 输出 + 提前终止,长答案可节省尾部 token。这四招叠加,GPT-5.5 实际单价可压到接近 Grok 4.3 输入价的 2 倍区间。
Q10: 两款模型的 Function Calling 兼容性如何?
完全兼容 OpenAI Function Calling 协议,代码可一份多用。两款模型都支持 tools 字段、并行工具调用、strict mode(强制 JSON schema)。差别在: GPT-5.5 的 strict mode 工具 schema 校验更严格,工具误触发率更低;Grok 4.3 还原生支持 server-side 工具(web_search / x_search / code_execution),无需应用层实现。如果你的项目重度依赖 Function Calling,两款模型可以无缝切换,我们建议通过 API易 apiyi.com 同时接入做 A/B 测试。
总结: Grok 4.3 vs GPT-5.5 的真实选择
回到这次对比的本质,Grok 4.3 与 GPT-5.5 不是「谁更强」的简单比较,而是两条不同的产品路线: xAI 用 Grok 4.3 把 reasoning 模型的成本曲线拉平、把多模态边界拓宽,OpenAI 用 GPT-5.5 把编码、数学、长上下文检索的精度天花板再次抬高。
如果让我们用一句话给出结论: 绝大多数团队应该用 Grok 4.3 做主力、GPT-5.5 做关键路径备份。Grok 4.3 的 $1.25/$2.50 价格 + 207 tps 速度 + 视频输入,可以覆盖 90% 业务场景;剩下 10% 的高价值任务(顶级编码、前沿数学、长上下文精确检索),用 GPT-5.5 兜底。这套组合的整体成本是「全量 GPT-5.5」的 15–25%,而关键任务质量几乎不损失。
对中国开发者而言,实施这套混合架构的最低摩擦路径是 API易 apiyi.com 中转通道。两款模型共享同一个 base_url、同一个 API Key,在应用层只需要改 model 字段就能切换,工程改造成本接近零。Grok 4.3 价格与官网完全一致,GPT-5.5 按官网价透传,无任何加价。如果再叠加 Batch API 和 cached input 折扣,整体单位成本还能再降 30–50%。
最后给一个执行建议: 先用 1 周时间在 API易 上把两款模型在你的真实业务数据上各跑 100–500 条样本,基准成绩是参考,真实业务匹配度才是决策依据。两款模型都已经稳定上线,接入零成本,差距数据自己跑出来才最可信。
参考资料
-
OpenAI 官方公告: GPT-5.5 发布信息与 API 文档
- 链接:
openai.com/index/introducing-gpt-5-5 - 说明: 包含价格、benchmark、API 字段说明
- 链接:
-
OpenAI 开发者文档: GPT-5.5 模型规格与调用示例
- 链接:
developers.openai.com/api/docs/models/gpt-5.5 - 说明: 完整 API 参数与计费细则
- 链接:
-
xAI 模型文档: Grok 4.3 全部 API 规格
- 链接:
docs.x.ai/developers/models - 说明: 包含视频输入、文档生成等独家能力
- 链接:
-
Artificial Analysis 智能榜单: 跨模型综合性能对比
- 链接:
artificialanalysis.ai/models/grok-4-3 - 说明: AA 智能指数、速度、价格综合评估
- 链接:
-
Vellum 基准报告: GPT-5 / GPT-5.5 系列基准详解
- 链接:
vellum.ai/blog/gpt-5-2-benchmarks - 说明: 多基准独立评测
- 链接:
-
DocsBot 模型对比: GPT-5.5 vs Grok 4.3 详细对照
- 链接:
docsbot.ai/models/compare/gpt-5-5/grok-4-3 - 说明: 价格、性能、特性对照
- 链接:
-
API易 接入文档: 国内中转接入两款模型的完整教程
- 链接:
help.apiyi.com - 说明: 含倍率说明、SDK 示例、计费查询
- 链接:
作者: APIYI Team — 专注 AI 大模型 API 中转服务,助力国内开发者一键调用 Grok 4.3、GPT-5.5、Claude Opus 4.7 等主流模型。访问 API易 apiyi.com 获取免费测试额度。




