作者注:基于 SWE-bench Pro、Terminal-Bench 2.0、LiveCodeBench 等 6 项核心基准测试,深度对比 GPT-5.5 与 Claude Opus 4.7 在真实编程场景下的能力差异,给出明确选型建议。
GPT-5.5 与 Claude Opus 4.7 的编程能力之争,是 2026 年 4 月 AI 编程领域最受关注的话题。本文对比 OpenAI GPT-5.5(代号 Spud) 和 Anthropic Claude Opus 4.7,从 SWE-bench Pro、Terminal-Bench 2.0、长上下文检索、Token 效率、API 定价等多个维度给出明确选型建议。
这不是一份"看起来各有千秋"的折中分析,我们会基于官方公布的 Benchmark 数据,直接给出在不同场景下的明确推荐。Anthropic 在 2026 年 4 月 16 日发布 Claude Opus 4.7,OpenAI 紧接着在 4 月 23 日发布 GPT-5.5,两个顶级模型相隔仅 7 天登场,编程能力对决就此拉开。
核心价值:看完本文,你将明确在 GitHub issue 修复、Agentic 编程、长上下文重构、交互式编码这 4 类典型场景下,应该选择 GPT-5.5 还是 Claude Opus 4.7。

GPT-5.5 与 Claude Opus 4.7 核心差异速览
两个模型的核心定位不同,导致编程能力的强项也截然不同。下表汇总了它们在编程相关维度的关键差异:
| 对比维度 | GPT-5.5 | Claude Opus 4.7 |
|---|---|---|
| 发布日期 | 2026-04-23 | 2026-04-16 |
| 代号 | Spud | – |
| 上下文窗口 | 1M tokens | 1M tokens |
| 最大输出 | 128K tokens | 128K tokens |
| 核心强项 | Agentic 编程、长上下文检索 | 真实 GitHub issue 修复、架构推理 |
| 典型 TTFT | ~3 秒 | ~0.5 秒 |
| Token 效率 | 输出 Token 比 Opus 少 72% | Token 消耗较高,但精度高 |
| API 输入 | $5/M tokens | $5/M tokens |
| API 输出 | $30/M tokens | $25/M tokens |
| 大 Prompt 加价 | >200K 仍保持原价 | >200K 翻倍至 $10/$37.50 |
GPT-5.5 编程能力定位
GPT-5.5 是 OpenAI 截至目前最强的 Agentic 编程模型。它在终端工作流、长上下文检索、跨工具协调上表现出色,特别适合多步骤、需要工具调用的自动化编程流程。OpenAI 官方将其定位为"长程编程任务"的首选,在 Expert-SWE 内部基准上展现出处理 20 小时人类工作量任务的能力。
Claude Opus 4.7 编程能力定位
Claude Opus 4.7 在真实软件工程任务上重新夺回王座。它在 SWE-bench Verified 上达到 87.6%,在 SWE-bench Pro 上达到 64.3%,显著领先所有现有竞品。Anthropic 在 Rakuten-SWE-Bench 上的实测显示,Opus 4.7 解决的生产任务量是 Opus 4.6 的 3 倍,特别适合修复 GitHub issue、重构大型代码库这类需要架构推理的工作。
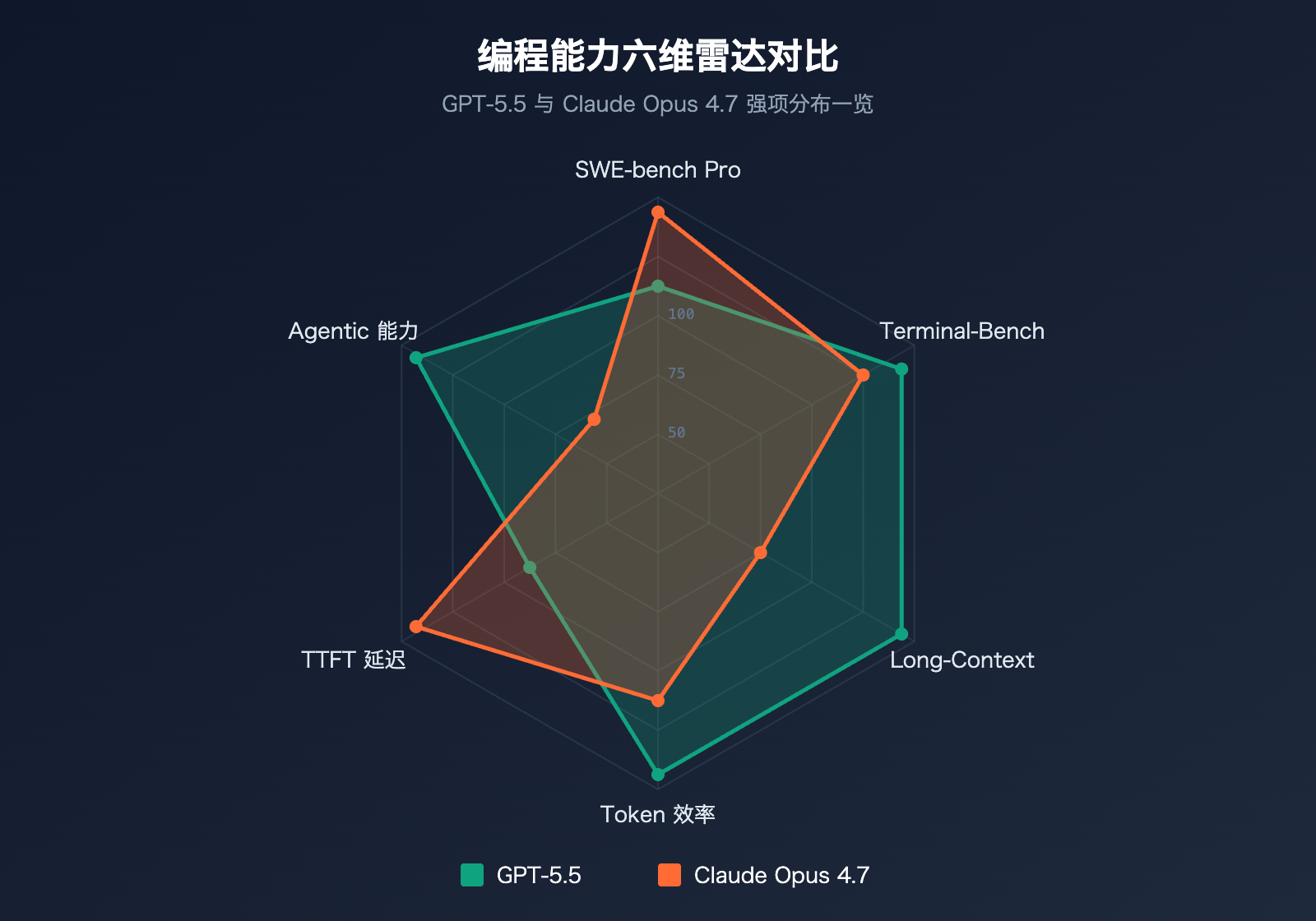
GPT-5.5 与 Claude Opus 4.7 Benchmark 实测对比
Benchmark 是判断编程能力最客观的标尺。我们汇总了两个模型在 6 项主流编程基准上的官方数据:
| 基准测试 | 测试内容 | GPT-5.5 | Claude Opus 4.7 | 胜出方 |
|---|---|---|---|---|
| SWE-bench Verified | 已验证的 GitHub issue 修复 | 84.2% | 87.6% | Opus 4.7 |
| SWE-bench Pro | 多文件复杂 issue 修复 | 58.6% | 64.3% | Opus 4.7 |
| Terminal-Bench 2.0 | 终端命令工作流 | 82.7% | 69.4% | GPT-5.5 |
| Expert-SWE | 长程编程(中位数 20 小时) | 73.1% | – | GPT-5.5 |
| OSWorld-Verified | 桌面 Agent 任务 | 78.7% | 78.0% | GPT-5.5(微弱) |
| MRCR v2 (512K-1M) | 长上下文 8-needle 检索 | 74.0% | 32.2% | GPT-5.5 |
SWE-bench Pro 实战分析
SWE-bench Pro 是评估模型修复真实 GitHub issue 能力的金标准。Claude Opus 4.7 以 64.3% 领先 GPT-5.5 的 58.6%,这意味着在每 100 个真实代码库 bug 修复任务中,Opus 4.7 能多解决约 6 个。
更关键的是,Opus 4.7 相比上一代 Opus 4.6(53.4%)提升了整整 10.9 个百分点,这是单次版本迭代中罕见的大幅跃迁。对于以 GitHub issue 修复为主要工作流的团队,Claude Opus 4.7 是当前的最优选。
测试建议:想验证两个模型在你自己代码库上的表现差异?可以通过 API易 apiyi.com 平台并行测试,平台支持 GPT-5.5 和 Claude Opus 4.7 的统一接口调用,便于快速对比。
Terminal-Bench 2.0 实战分析
Terminal-Bench 2.0 测试模型在终端环境下完成复杂任务的能力,包括规划、迭代、工具协调三大维度。GPT-5.5 以 82.7% 大幅领先 Opus 4.7 的 69.4%,差距高达 13 个百分点。
这一差距源于 GPT-5.5 在 Agentic 工作流上的优化:它能够更精准地选择工具、更稳定地处理多步骤任务、更可靠地从错误中恢复。如果你的工作流涉及大量 shell 命令、文件操作、CI/CD 集成,GPT-5.5 是更稳妥的选择。
长上下文检索能力差距
MRCR v2 在 512K-1M tokens 范围的 8-needle 检索测试中,GPT-5.5 以 74.0% 大幅领先 Opus 4.7 的 32.2%——这是一个 41.8 个百分点的鸿沟。
这意味着如果你需要让模型理解整个代码仓库(500K+ tokens),GPT-5.5 对深层上下文的回忆精度显著更高。对于"基于完整 monorepo 重构"这类场景,GPT-5.5 不只是更好,而是能用与不能用的差距。
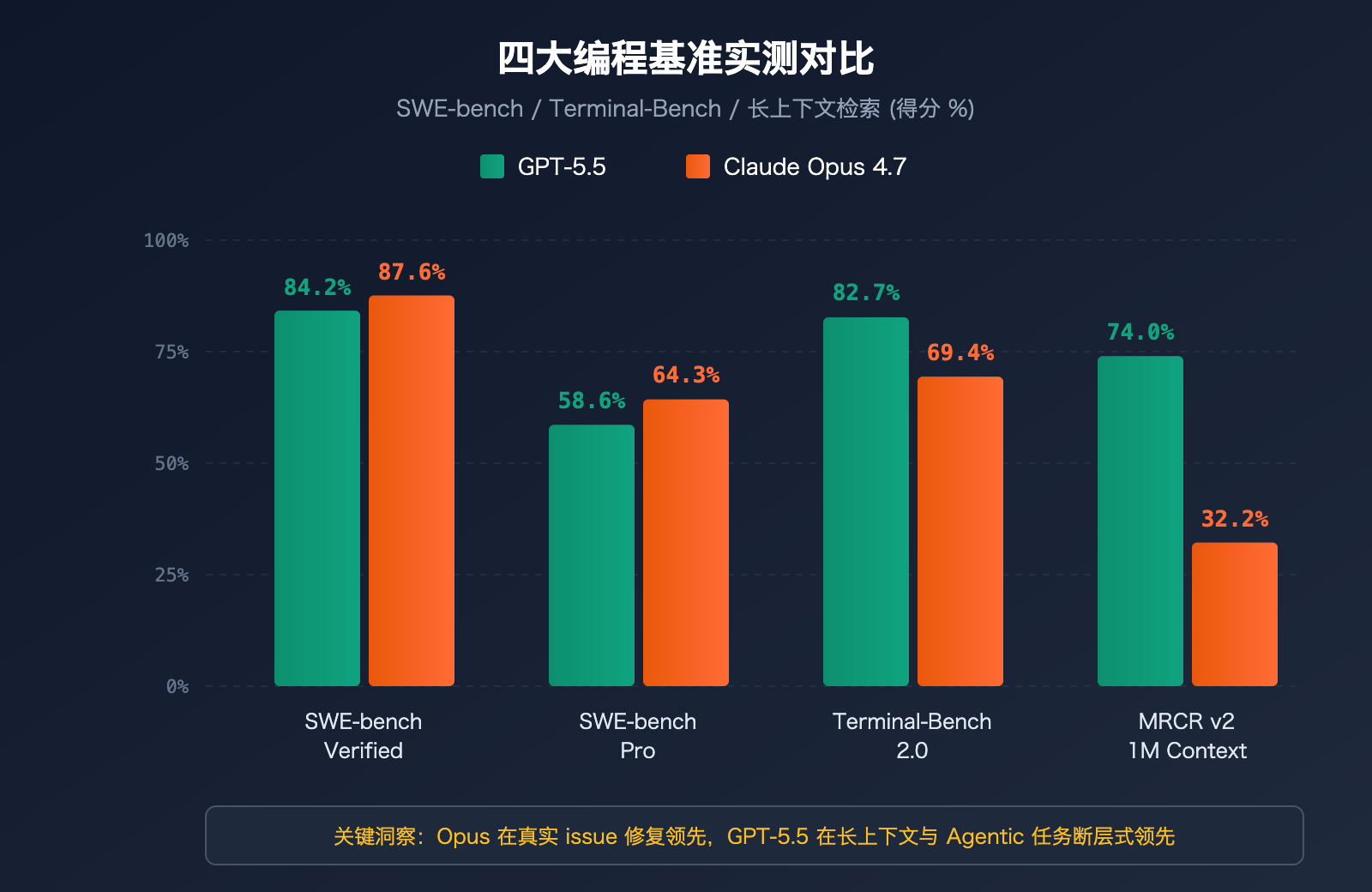
GPT-5.5 与 Claude Opus 4.7 编程场景实战推荐
Benchmark 数据需要落到具体场景才有意义。下表给出 5 类典型编程场景的明确推荐:
| 编程场景 | 推荐模型 | 核心理由 | 预期收益 |
|---|---|---|---|
| GitHub Issue 修复 | Claude Opus 4.7 | SWE-bench Pro 领先 5.7 个百分点 | 修复成功率提升 10% |
| 大型 Codebase 重构 | Claude Opus 4.7 | 跨文件架构推理能力更强 | 减少架构破坏风险 |
| Agentic 自动化流程 | GPT-5.5 | Terminal-Bench 领先 13.3 个百分点 | 多步任务稳定性更高 |
| 长上下文(>500K)理解 | GPT-5.5 | MRCR v2 领先 41.8 个百分点 | 深层上下文检索可靠 |
| 交互式 Pair Programming | Claude Opus 4.7 | TTFT 仅 0.5 秒,响应更快 | 编码节奏更流畅 |
| 大批量代码生成 | GPT-5.5 | Token 效率高 72%,成本更低 | 综合成本更优 |
场景一:修复真实 GitHub Issue → 选 Claude Opus 4.7
如果你的核心需求是"接到一个 issue 描述,让 AI 给出可合并的 PR",Claude Opus 4.7 是无可争议的最优选。它在 SWE-bench Verified 上 87.6% 的得分意味着大约九成的良好定义 bug 修复任务能直接交付。
需要注意的是,87.6% 不等于你 87.6% 的工程工作能被自动化——这是基于"完美任务规范"的理想测试。在实际工作流中,issue 描述质量会显著影响成功率。
场景二:长上下文代码理解 → 选 GPT-5.5
当你需要让模型读完整个 monorepo(通常 500K-1M tokens)再做决策时,GPT-5.5 是当前唯一可靠的选择。Opus 4.7 在 1M 上下文区间的 8-needle 检索精度只有 32.2%,意味着模型很可能"看不见"代码库深处的关键定义。
这个差距是架构级别的——如果你的工作流依赖完整代码库视图(例如全局重命名、API 兼容性检查),用 Opus 4.7 可能根本跑不通流程。
场景三:Agentic 编程工作流 → 选 GPT-5.5
Agentic 编程是指 AI 自主规划、调用工具、迭代修正的工作流。GPT-5.5 在 Terminal-Bench 2.0 的 82.7% 得分远超 Opus 4.7,特别在以下任务中表现稳定:
- 自动化部署脚本编写与执行
- 多服务调试与日志分析
- CI/CD 流水线问题排查
- 数据管道构建与监控
集成建议:构建 Agentic 编程流程时,建议通过 API易 apiyi.com 这类聚合平台调用 GPT-5.5,便于统一管理 API Key、监控调用成本、按需切换备用模型。
场景四:交互式 Pair Programming → 选 Claude Opus 4.7
交互式编码体验对延迟极度敏感。Opus 4.7 的 TTFT(首 token 延迟)约 0.5 秒,而 GPT-5.5 约 3 秒,6 倍的差距在频繁交互场景下感知非常明显。
如果你使用 Cursor、Claude Code、Continue 等 IDE 集成工具进行频繁的小段代码补全,Opus 4.7 的低延迟会带来更流畅的编码节奏。

GPT-5.5 与 Claude Opus 4.7 API 调用示例
下面给出两个模型的极简调用示例,方便你快速验证。两者都兼容 OpenAI SDK 格式,迁移成本极低。
GPT-5.5 极简调用
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-5.5",
messages=[{"role": "user", "content": "用 Python 实现快速排序"}]
)
print(response.choices[0].message.content)
Claude Opus 4.7 极简调用
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "用 Python 实现快速排序"}]
)
print(response.choices[0].message.content)
查看双模型并行对比测试代码
import openai
import time
from typing import Dict
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def benchmark_model(model: str, prompt: str) -> Dict:
"""测试单个模型的响应时间和输出长度"""
start = time.time()
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=2000
)
elapsed = time.time() - start
return {
"model": model,
"elapsed_seconds": round(elapsed, 2),
"output_tokens": response.usage.completion_tokens,
"content_preview": response.choices[0].message.content[:200]
}
# 编程能力对比测试
test_prompt = """
请用 Python 实现一个 LRU 缓存类,要求:
1. 支持 get(key) 和 put(key, value) 方法
2. 容量满时自动淘汰最久未使用的项
3. 所有操作时间复杂度 O(1)
4. 包含完整的单元测试
"""
# 并行测试两个模型
gpt_result = benchmark_model("gpt-5.5", test_prompt)
claude_result = benchmark_model("claude-opus-4-7", test_prompt)
print(f"GPT-5.5: {gpt_result['elapsed_seconds']}s, {gpt_result['output_tokens']} tokens")
print(f"Claude Opus 4.7: {claude_result['elapsed_seconds']}s, {claude_result['output_tokens']} tokens")
测试建议:通过 API易 apiyi.com 获取免费测试额度,可在同一账号下并行测试 GPT-5.5 和 Claude Opus 4.7,使用统一的 base_url 和 API Key,无需分别申请 OpenAI 和 Anthropic 账号。
GPT-5.5 与 Claude Opus 4.7 综合成本分析
API 定价是选型必须考虑的硬指标。表面上看 Opus 4.7 输出 Token 便宜 17%,但综合分析后真相会反转:
| 成本维度 | GPT-5.5 | Claude Opus 4.7 | 实际影响 |
|---|---|---|---|
| 输入定价 | $5/M tokens | $5/M tokens | 持平 |
| 输出定价 | $30/M tokens | $25/M tokens | Opus 便宜 17% |
| >200K Prompt | 保持原价 | 翻倍至 $10/$37.50 | 长上下文 GPT 优势大 |
| 同任务输出 Token | 100% 基线 | 比 GPT 多 72% | GPT 综合便宜 |
| TTFT 延迟 | ~3 秒 | ~0.5 秒 | Opus 体验好 |
| 大批量任务实际成本 | 1.0x 基准 | 1.4-1.5x 基准 | GPT 更省钱 |
成本对比的关键发现
Token 效率改变了价格比较的本质。在同等编程任务下,GPT-5.5 平均消耗的输出 Token 比 Opus 4.7 少 72%。即使 Opus 单价便宜 17%,乘以 1.72 倍的 Token 用量后,GPT-5.5 的实际任务成本反而更低。
长上下文场景差距进一步拉大。当 Prompt 超过 200K tokens 时,Opus 4.7 的输入和输出价格双双翻倍至 $10 和 $37.50,而 GPT-5.5 保持原价。对于需要长上下文理解的工作流(如完整 monorepo 分析),GPT-5.5 的成本优势可能达到 2-3 倍。
对比解读
Claude Opus 4.7 成本特点:单 Token 价格在主流前沿模型中具有竞争力。但在大批量生成场景下,其较高的 Token 消耗会拉高总成本;在长上下文场景下,>200K 翻倍机制会显著增加预算压力。
GPT-5.5 成本特点:单 Token 价格略高,但出色的 Token 效率和长上下文不加价机制让它在大规模、长上下文场景下综合成本反而更低。OpenAI 显然在设计定价时考虑了 Agentic 工作流的成本结构。
成本测算建议:实际项目成本受 Prompt 长度、输出长度、调用频率多重因素影响。建议通过 API易 apiyi.com 平台接入两个模型,平台提供细粒度的调用账单,便于做出基于真实数据的选型决策。
常见问题 FAQ
Q1: GPT-5.5 和 Claude Opus 4.7 哪个编程能力更强?
没有绝对的"更强",要看具体任务。Claude Opus 4.7 在 SWE-bench Pro(64.3% vs 58.6%)和 Verified(87.6%)上领先,更适合修复真实 GitHub issue 和大型代码库重构。GPT-5.5 在 Terminal-Bench 2.0(82.7% vs 69.4%)和长上下文检索(74.0% vs 32.2%)上领先,更适合 Agentic 编程流程和跨整个 monorepo 的代码理解。
Q2: GPT-5.5 和 Claude Opus 4.7 的 API 定价区别在哪里?
两者输入 Token 都是 $5/M。输出 Token 上 Opus 4.7($25/M)比 GPT-5.5($30/M)便宜 17%。但 Opus 4.7 在 Prompt 超过 200K 时价格翻倍,而 GPT-5.5 保持原价。再考虑到 GPT-5.5 输出 Token 比 Opus 少 72%,大批量任务下 GPT-5.5 综合成本更低。
Q3: GPT-5.5 和 Claude Opus 4.7 何时发布?
Claude Opus 4.7 由 Anthropic 在 2026 年 4 月 16 日发布,已在 Claude API、Amazon Bedrock、Google Cloud Vertex AI、Microsoft Foundry 全面上线。GPT-5.5(内部代号 Spud)由 OpenAI 在 2026 年 4 月 23 日发布,两个顶级编程模型相隔仅 7 天登场,竞争激烈。
Q4: 哪些编程场景应该选择 Claude Opus 4.7?
以下场景优先选择 Opus 4.7:
- 修复 GitHub issue:SWE-bench Pro 领先 5.7 个百分点
- 大型代码库重构:跨文件架构推理能力更强
- 交互式 Pair Programming:TTFT 仅 0.5 秒,响应快 6 倍
- 代码质量审查:Rakuten-SWE-Bench 实测代码质量得分更高
Q5: 如何快速通过 API 调用 GPT-5.5 和 Claude Opus 4.7?
推荐使用支持双模型的 API 聚合平台进行测试:
- 访问 API易 apiyi.com 注册账号
- 获取统一 API Key 和免费测试额度
- 使用本文示例代码(base_url 替换为
https://vip.apiyi.com/v1),分别指定 model 为gpt-5.5或claude-opus-4-7即可调用
API易支持 OpenAI、Anthropic、Google 等主流模型的统一接口接入,无需分别申请多个账号即可快速对比 GPT-5.5 和 Claude Opus 4.7 的实际表现。
Q6: GPT-5.5 和 Claude Opus 4.7 各有哪些已知限制?
GPT-5.5 限制:
- TTFT 延迟约 3 秒,交互式场景体验较慢
- SWE-bench 修复真实 issue 上不及 Opus 4.7
Claude Opus 4.7 限制:
- 长上下文检索能力薄弱(1M 范围 32.2%)
- Prompt >200K 时价格翻倍,长上下文成本压力大
- 输出 Token 消耗较高,大批量任务综合成本偏高
- Terminal-Bench 等 Agentic 任务表现不及 GPT-5.5
Q7: 是否有必要同时使用 GPT-5.5 和 Claude Opus 4.7?
对于专业开发团队,强烈建议两者并用。典型分工策略:用 Opus 4.7 处理 GitHub issue 修复、代码 review、关键架构决策;用 GPT-5.5 处理长上下文分析、Agentic 自动化流程、大批量代码生成。这种混用模式既能享受各自的能力优势,又能在成本和体验间取得平衡。
GPT-5.5 与 Claude Opus 4.7 核心要点 Key Takeaways
- 真实 Issue 修复看 Opus:Claude Opus 4.7 在 SWE-bench Pro/Verified 双双领先,是修复真实 GitHub issue 的首选
- Agentic 编程看 GPT:GPT-5.5 在 Terminal-Bench 2.0 上领先 13 个百分点,多步工具调用更稳定
- 长上下文看 GPT:MRCR v2 测试中 GPT-5.5(74%)远超 Opus(32.2%),1M 上下文唯一可靠选择
- 延迟敏感看 Opus:Opus TTFT 仅 0.5 秒,比 GPT 快 6 倍,交互式编码体验更流畅
- 成本敏感看 GPT:GPT-5.5 输出 Token 比 Opus 少 72%,综合任务成本更低
- 快速并行测试:通过 API易 apiyi.com 一个账号即可统一调用两个模型,便于真实场景对比
总结
GPT-5.5 与 Claude Opus 4.7 编程能力对比的核心结论:
- 没有全能冠军:两个模型各有清晰的强项领域,盲目追求"最好的模型"是错误思路
- 任务驱动选型:先明确你的核心编程场景(issue 修复 / Agentic / 长上下文 / 交互式),再决定主力模型
- 建议双模型并行:专业开发团队应同时接入两个模型,按场景路由到最优选择,最大化产出
如果你只能选一个:日常以 GitHub issue 修复和代码 review 为主,选 Claude Opus 4.7;以 Agentic 自动化和长上下文分析为主,选 GPT-5.5。
推荐通过 API易 apiyi.com 快速验证选型,平台提供 GPT-5.5 和 Claude Opus 4.7 的统一接口、免费测试额度和细粒度账单,是做出数据驱动选型决策的最便捷路径。
延伸阅读 Related Articles
如果你对 GPT-5.5 与 Claude Opus 4.7 编程对比感兴趣,推荐继续阅读:
- 📘 Claude Opus 4.7 完整评测:SWE-bench 87.6% 背后的工程实力 – 深度解析 Opus 4.7 的能力来源
- 📊 GPT-5.5 Spud 实测指南:Agentic 编程新王者的 8 个使用技巧 – 掌握 GPT-5.5 的进阶用法
- 🚀 AI 编程模型选型指南 2026:从 GPT 到 Claude 的全景对比 – 探索更宏观的模型选型方法论
📚 参考资料
-
OpenAI 官方 GPT-5.5 介绍:核心 Benchmark 和能力说明
- 链接:
openai.com/index/introducing-gpt-5-5 - 说明: GPT-5.5 官方发布文档,包含 SWE-bench、Terminal-Bench 等核心基准
- 链接:
-
Anthropic 官方 Claude Opus 4.7 发布说明:模型定位和性能数据
- 链接:
anthropic.com/news/claude-opus-4-7 - 说明: Opus 4.7 官方发布文档,含 SWE-bench Verified/Pro 详细数据
- 链接:
-
SWE-Bench Pro 公开排行榜:第三方独立验证
- 链接:
labs.scale.com/leaderboard/swe_bench_pro_public - 说明: Scale AI 维护的 SWE-Bench Pro 公开排行榜,可验证两个模型的真实排名
- 链接:
-
Vellum LLM Leaderboard 2026:综合性 AI 模型对比
- 链接:
vellum.ai/llm-leaderboard - 说明: 涵盖编程、推理、长上下文等多维度的综合对比平台
- 链接:
-
Artificial Analysis 模型对比:性能与成本分析
- 链接:
artificialanalysis.ai/models/comparisons/gpt-5-5-vs-claude-opus-4-7-non-reasoning - 说明: 提供 TTFT、Throughput、综合成本的细粒度对比数据
- 链接:
作者:APIYI 技术团队
技术交流:欢迎在评论区讨论,更多资料可访问 API易 docs.apiyi.com 文档中心