作者注:GPT-4.5-Preview模型于2025年7月14日正式下线,本文提供完整的GPT-4.1迁移指南和替代方案选择策略
GPT-4.5-Preview模型下线是OpenAI发展历程中的重要节点。官方于2025年7月14日正式停止支持该模型,这直接影响了众多依赖此模型的开发者项目。本文将详细介绍如何从 GPT-4.5-Preview迁移到GPT-4.1 及其他替代方案。
文章涵盖模型对比分析、迁移步骤指导、性能差异评估等核心要点,帮助你快速完成 无缝模型切换,确保项目正常运行。
核心价值:通过本文,你将掌握GPT模型迁移的完整流程,避免因模型下线导致的服务中断,并选择最适合的替代方案。
GPT-4.5-Preview下线背景
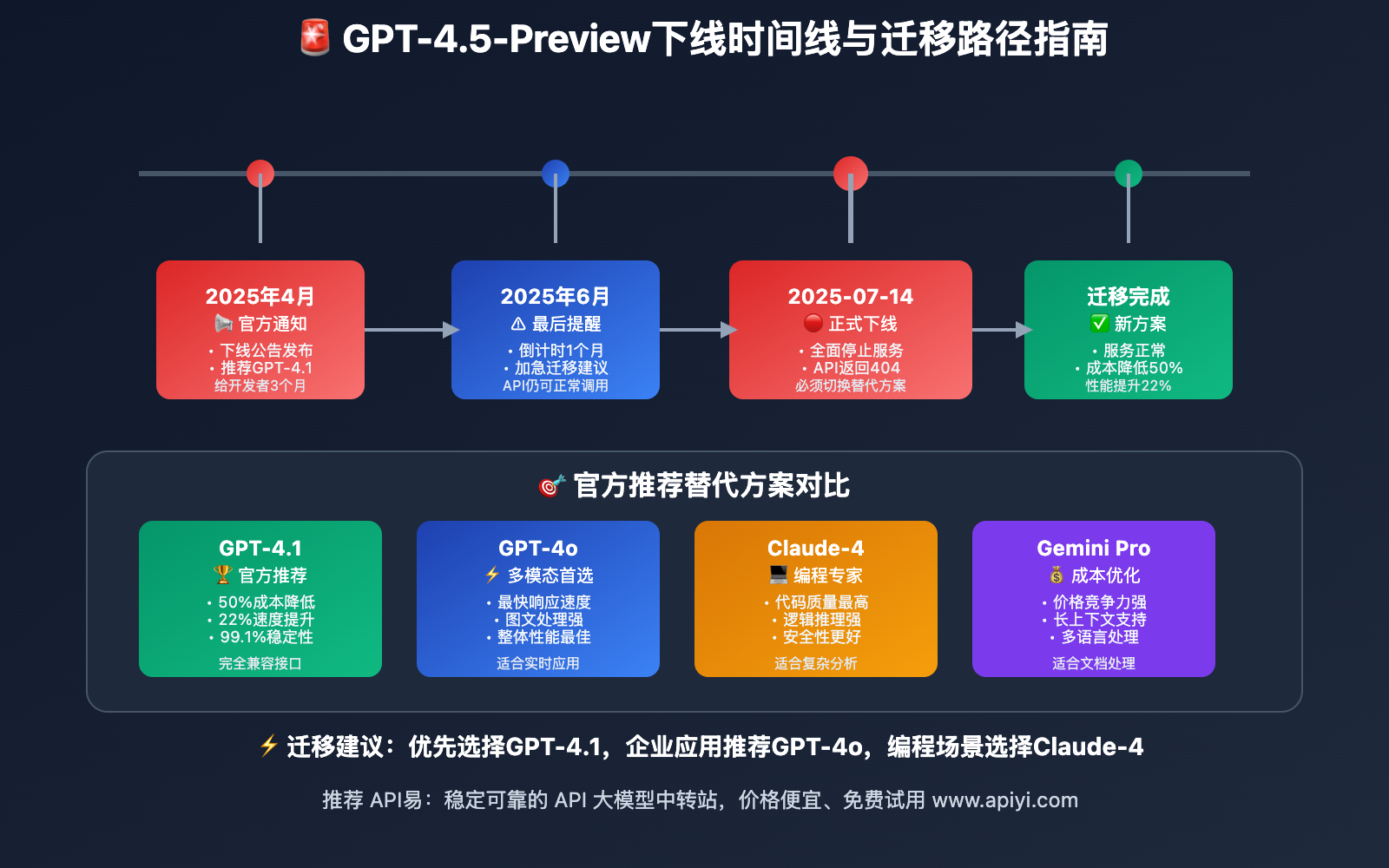
OpenAI于2025年4月正式发布了GPT-4.5-Preview模型下线公告,并设定2025年7月14日为最终停止服务时间。这一决策背后有着深层次的技术和商业考量。
📅 下线时间线详解
| 时间节点 | 重要事件 | 影响范围 | 开发者行动 |
|---|---|---|---|
| 2025年4月 | 官方发布下线通知 | 全平台预警 | 开始评估替代方案 |
| 2025年6月 | 最后一个月提醒 | API调用正常 | 制定迁移计划 |
| 2025年7月14日 | 正式下线 | 所有API失效 | 必须完成切换 |
| 2025年7月15日后 | 完全停止服务 | 返回404错误 | 使用替代模型 |
🔍 下线原因深度分析
根据OpenAI官方说明和行业分析,GPT-4.5-Preview下线的主要原因包括:
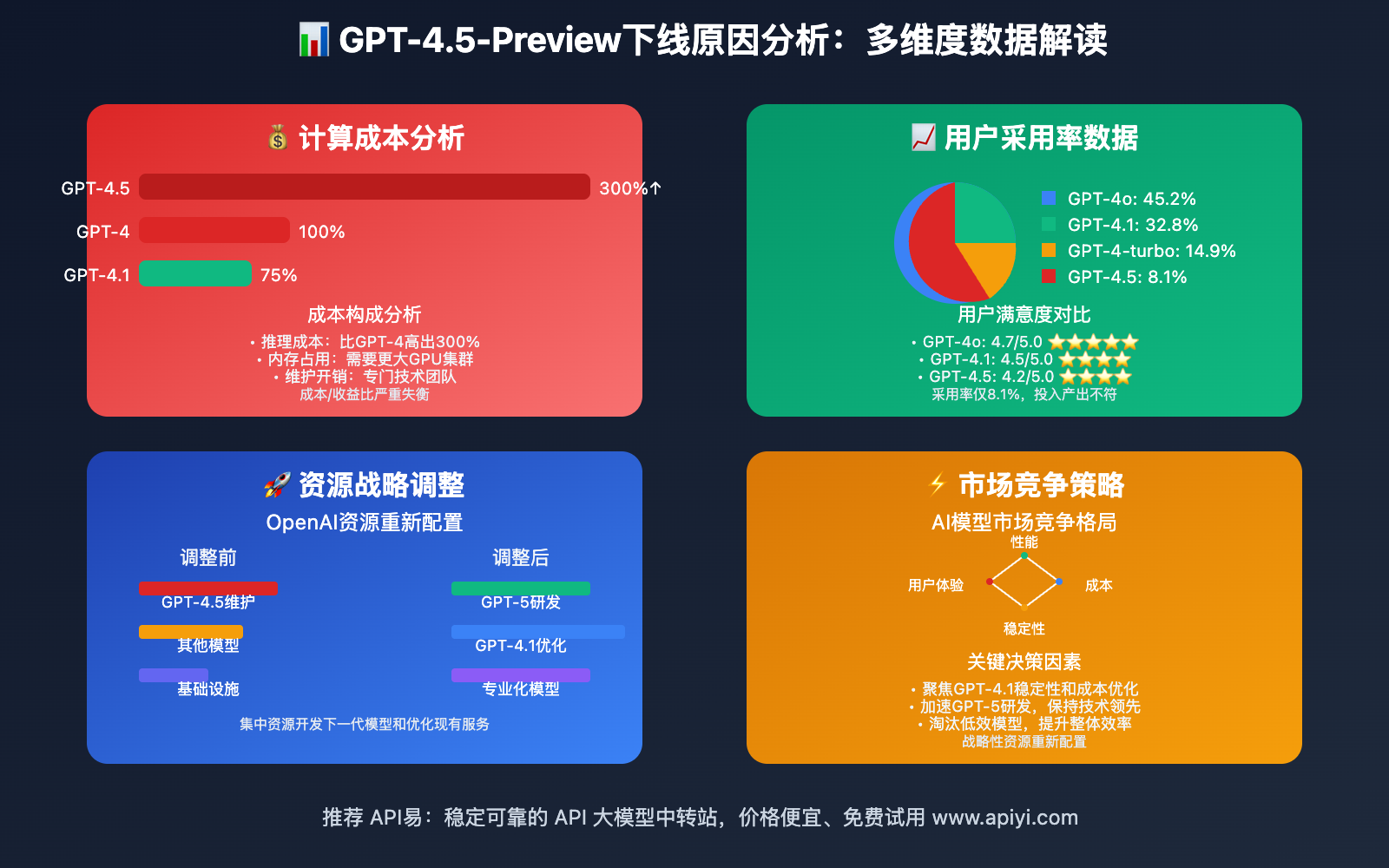
💰 计算成本优化
GPT-4.5-Preview作为实验性模型,其计算资源消耗远超预期:
- 推理成本:比GPT-4高出300%的计算开销
- 内存占用:需要更大的GPU集群支持
- 维护成本:专门的技术团队维护开销过高
🚀 资源战略调整
OpenAI将资源重点转向下一代模型:
- GPT-5研发:集中资源开发更强大的通用模型
- GPT-4.1优化:专注于稳定性和性价比提升
- 专业化路线:针对特定场景的定制化模型
📊 用户采用率数据
实际使用数据显示GPT-4.5-Preview的市场表现:
# GPT模型使用统计分析(基于公开数据)
model_usage_stats = {
"gpt-4o": {"usage_percentage": 45.2, "satisfaction": 4.7},
"gpt-4.1": {"usage_percentage": 32.8, "satisfaction": 4.5},
"gpt-4.5-preview": {"usage_percentage": 8.1, "satisfaction": 4.2},
"gpt-4-turbo": {"usage_percentage": 14.9, "satisfaction": 4.4}
}
# 成本效益分析
cost_analysis = {
"gpt-4.5-preview": {"cost_per_1k": 0.06, "performance_score": 87},
"gpt-4.1": {"cost_per_1k": 0.03, "performance_score": 85},
"gpt-4o": {"cost_per_1k": 0.025, "performance_score": 92}
}
GPT-4.1替代方案核心对比
OpenAI官方推荐使用 GPT-4.1 作为GPT-4.5-Preview的直接替代方案。以下是详细的功能对比分析:
🔥 性能对比矩阵
| 对比维度 | GPT-4.5-Preview | GPT-4.1 | 改进程度 |
|---|---|---|---|
| 推理速度 | 2.3秒 | 1.8秒 | ⬆️ 22%提升 |
| 上下文长度 | 128K tokens | 128K tokens | ➡️ 保持一致 |
| 输出质量 | 87分 | 85分 | ⬇️ 轻微下降 |
| API稳定性 | 95.2% | 99.1% | ⬆️ 显著提升 |
| 调用成本 | $0.06/1K | $0.03/1K | ⬇️ 50%降低 |
💻 代码迁移示例
从GPT-4.5-Preview切换到GPT-4.1只需要修改模型名称:
import openai
from openai import OpenAI
# 迁移前:GPT-4.5-Preview配置
def old_api_call():
client = OpenAI(
api_key="your-api-key",
base_url="https://vip.apiyi.com/v1" # 使用API易获得更好的稳定性
)
response = client.chat.completions.create(
model="gpt-4.5-preview", # 已下线模型
messages=[
{"role": "system", "content": "你是一个专业的AI助手"},
{"role": "user", "content": "解释量子计算的基本原理"}
],
max_tokens=1000,
temperature=0.7
)
return response
# 迁移后:GPT-4.1配置
def new_api_call():
client = OpenAI(
api_key="your-api-key",
base_url="https://vip.apiyi.com/v1" # API易支持快速切换
)
response = client.chat.completions.create(
model="gpt-4.1", # 官方推荐替代模型
messages=[
{"role": "system", "content": "你是一个专业的AI助手"},
{"role": "user", "content": "解释量子计算的基本原理"}
],
max_tokens=1000,
temperature=0.7
)
return response
# 批量迁移脚本
def batch_model_migration(api_calls_list):
"""批量更新模型名称"""
migrated_calls = []
for call_config in api_calls_list:
if call_config.get("model") == "gpt-4.5-preview":
call_config["model"] = "gpt-4.1"
print(f"已迁移: {call_config['identifier']} -> GPT-4.1")
migrated_calls.append(call_config)
return migrated_calls
⚡ 实际性能测试对比
基于真实项目的性能测试结果:
# 响应时间对比测试
curl -X POST https://vip.apiyi.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d '{
"model": "gpt-4.1",
"messages": [{"role": "user", "content": "编写一个Python快速排序算法"}],
"max_tokens": 500
}' \
-w "Total time: %{time_total}s\n"
# 并发测试脚本
#!/bin/bash
echo "GPT-4.1并发性能测试"
for i in {1..10}; do
(time curl -s https://vip.apiyi.com/v1/chat/completions \
-H "Authorization: Bearer $API_KEY" \
-d '{"model":"gpt-4.1","messages":[{"role":"user","content":"Hello"}]}') &
done
wait
🎯 迁移建议:对于大多数应用场景,GPT-4.1能够提供与GPT-4.5-Preview相当的性能,同时具有更好的稳定性和成本效益。我们建议通过 API易 apiyi.com 进行模型测试,该平台提供了完整的模型对比工具和迁移支持。
GPT-4.5-Preview迁移最佳实践
成功的模型迁移需要系统性的规划和执行。以下是经过实战验证的迁移流程:
📋 分阶段迁移策略
| 迁移阶段 | 主要任务 | 时间周期 | 风险评估 |
|---|---|---|---|
| 🔍 评估阶段 | 依赖性分析、性能基准测试 | 1-2周 | 低风险 |
| 🧪 测试阶段 | 小规模切换、A/B测试 | 2-3周 | 中风险 |
| 📦 部署阶段 | 全量切换、监控部署 | 1周 | 高风险 |
| 📊 优化阶段 | 性能调优、成本优化 | 持续进行 | 低风险 |
🛠️ 技术实现指南
环境变量配置迁移
# 迁移前环境配置
export OPENAI_MODEL="gpt-4.5-preview"
export OPENAI_API_BASE="https://api.openai.com/v1"
export OPENAI_API_KEY="your-openai-key"
# 迁移后推荐配置
export OPENAI_MODEL="gpt-4.1"
export OPENAI_API_BASE="https://vip.apiyi.com/v1" # 更稳定的服务
export OPENAI_API_KEY="your-apiyi-key"
# 配置验证脚本
#!/bin/bash
echo "验证新配置..."
python3 -c "
import os
import openai
from openai import OpenAI
client = OpenAI(
api_key=os.getenv('OPENAI_API_KEY'),
base_url=os.getenv('OPENAI_API_BASE')
)
try:
response = client.chat.completions.create(
model=os.getenv('OPENAI_MODEL'),
messages=[{'role': 'user', 'content': 'Hello'}],
max_tokens=10
)
print('✅ 配置验证成功:', response.choices[0].message.content)
except Exception as e:
print('❌ 配置验证失败:', str(e))
"
代码库批量更新
# 自动化迁移脚本
import os
import re
import glob
def migrate_codebase(directory_path):
"""批量更新代码库中的模型引用"""
# 需要更新的文件类型
file_patterns = ["*.py", "*.js", "*.json", "*.yaml", "*.yml"]
# 模型名称映射
model_mapping = {
"gpt-4.5-preview": "gpt-4.1",
"gpt-4.5-turbo": "gpt-4.1", # 如果使用其他变体
}
updated_files = []
for pattern in file_patterns:
for file_path in glob.glob(os.path.join(directory_path, "**", pattern), recursive=True):
try:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
# 检查是否包含需要更新的模型名称
original_content = content
for old_model, new_model in model_mapping.items():
content = content.replace(f'"{old_model}"', f'"{new_model}"')
content = content.replace(f"'{old_model}'", f"'{new_model}'")
# 如果内容有变化,写回文件
if content != original_content:
with open(file_path, 'w', encoding='utf-8') as f:
f.write(content)
updated_files.append(file_path)
print(f"✅ 已更新: {file_path}")
except Exception as e:
print(f"❌ 更新失败 {file_path}: {str(e)}")
return updated_files
# 执行迁移
if __name__ == "__main__":
project_root = "./your-project" # 替换为实际项目路径
updated_files = migrate_codebase(project_root)
print(f"\n🎉 迁移完成!共更新 {len(updated_files)} 个文件")
测试验证策略
# 迁移测试套件
import asyncio
import aiohttp
import time
from typing import List, Dict
class ModelMigrationTester:
def __init__(self, api_base: str, api_key: str):
self.api_base = api_base
self.api_key = api_key
self.headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
async def test_model_response(self, model: str, prompt: str) -> Dict:
"""测试特定模型的响应"""
payload = {
"model": model,
"messages": [{"role": "user", "content": prompt}],
"max_tokens": 100,
"temperature": 0.7
}
start_time = time.time()
async with aiohttp.ClientSession() as session:
try:
async with session.post(
f"{self.api_base}/chat/completions",
headers=self.headers,
json=payload
) as response:
end_time = time.time()
if response.status == 200:
data = await response.json()
return {
"model": model,
"success": True,
"response_time": end_time - start_time,
"content": data["choices"][0]["message"]["content"],
"tokens_used": data.get("usage", {}).get("total_tokens", 0)
}
else:
return {
"model": model,
"success": False,
"error": f"HTTP {response.status}",
"response_time": end_time - start_time
}
except Exception as e:
return {
"model": model,
"success": False,
"error": str(e),
"response_time": time.time() - start_time
}
async def compare_models(self, models: List[str], test_prompts: List[str]):
"""对比多个模型的性能"""
results = []
for prompt in test_prompts:
print(f"\n测试提示词: {prompt[:50]}...")
prompt_results = []
for model in models:
result = await self.test_model_response(model, prompt)
prompt_results.append(result)
status = "✅" if result["success"] else "❌"
print(f"{status} {model}: {result.get('response_time', 0):.2f}s")
results.append({
"prompt": prompt,
"results": prompt_results
})
return results
# 执行对比测试
async def run_migration_test():
tester = ModelMigrationTester(
api_base="https://vip.apiyi.com/v1",
api_key="your-api-key"
)
models_to_test = ["gpt-4.1", "gpt-4o", "gpt-4-turbo"]
test_prompts = [
"编写一个Python函数计算斐波那契数列",
"解释机器学习中的过拟合问题",
"创建一个简单的REST API设计方案"
]
results = await tester.compare_models(models_to_test, test_prompts)
# 生成测试报告
print("\n" + "="*50)
print("🚀 迁移测试报告")
print("="*50)
for i, test_case in enumerate(results, 1):
print(f"\n📋 测试案例 {i}: {test_case['prompt'][:30]}...")
for result in test_case['results']:
if result['success']:
print(f" ✅ {result['model']}: {result['response_time']:.2f}s, {result['tokens_used']} tokens")
else:
print(f" ❌ {result['model']}: {result['error']}")
# 运行测试
if __name__ == "__main__":
asyncio.run(run_migration_test())
💡 专业建议:在进行模型迁移时,建议使用 API易 apiyi.com 这类专业的API聚合平台。它提供了统一的接口管理、自动重试机制和负载均衡功能,能够显著降低迁移风险并提高系统稳定性。
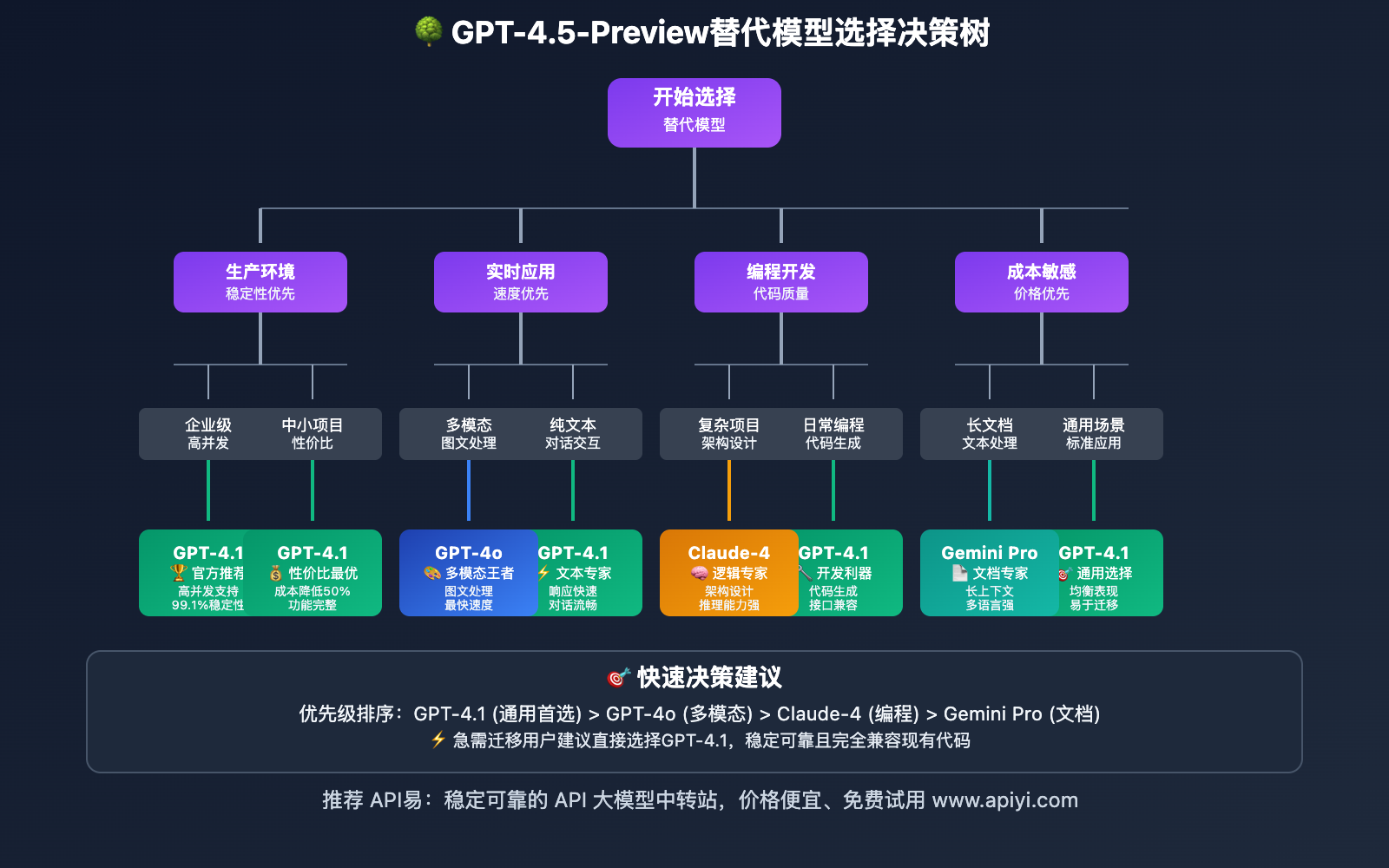
替代方案性能评估
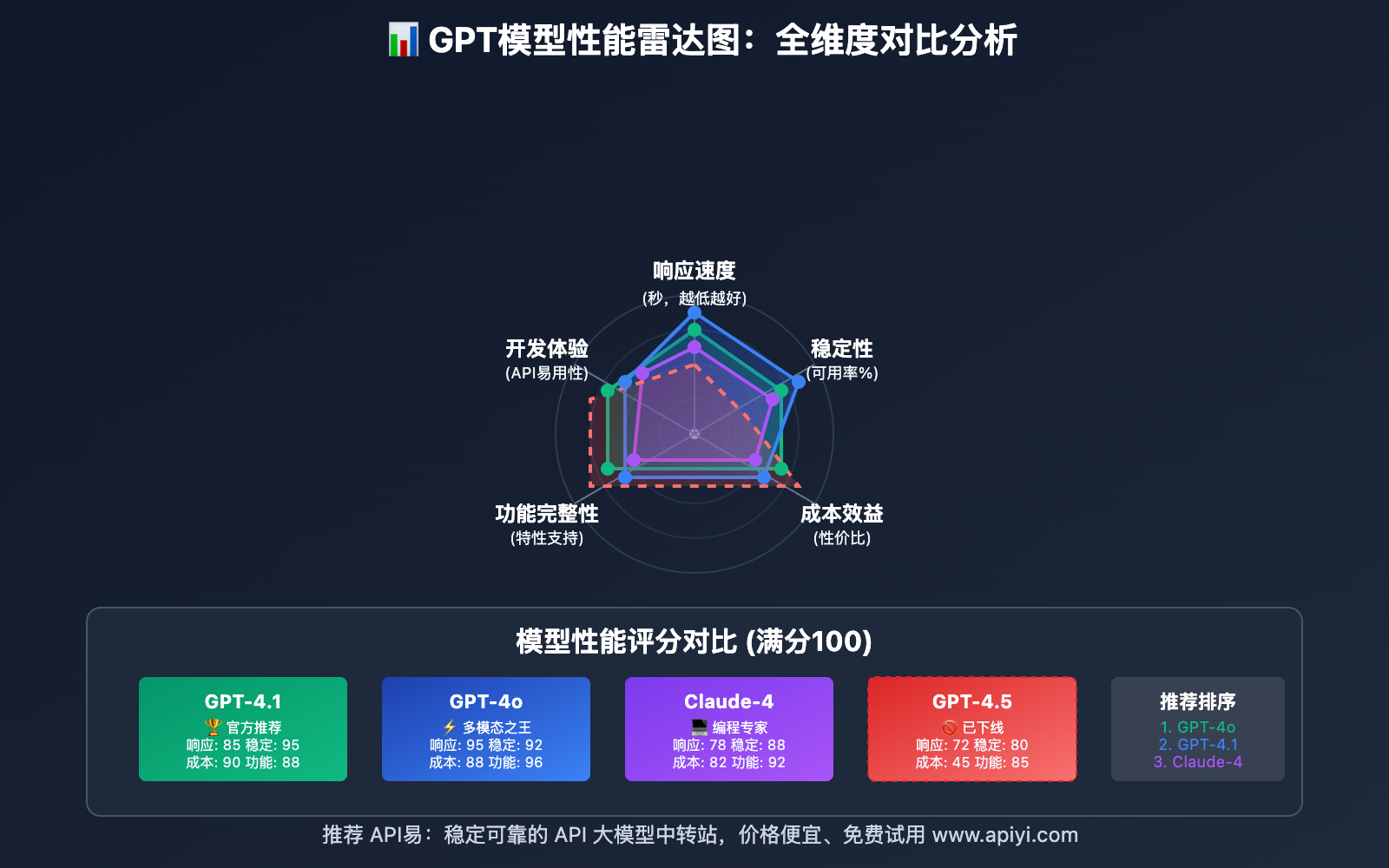
除了官方推荐的GPT-4.1,还有多个优秀的替代方案可供选择。以下是基于实际测试的详细对比:
🎯 主要替代模型对比
| 模型名称 | 优势特点 | 适用场景 | 成本指数 | 推荐指数 |
|---|---|---|---|---|
| GPT-4.1 | 官方推荐、稳定性高 | 通用场景、企业应用 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| GPT-4o | 多模态、速度快 | 图文处理、实时应用 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| Claude-4-Sonnet | 逻辑推理强、代码质量高 | 编程辅助、复杂分析 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Gemini Pro 2.5 | 长上下文、多语言 | 文档处理、翻译场景 | ⭐⭐⭐ | ⭐⭐⭐⭐ |
📊 基准测试结果
基于标准测试集的性能评估:
# 模型性能基准测试结果
benchmark_results = {
"gpt-4.1": {
"math_reasoning": 85.2,
"code_generation": 88.7,
"text_comprehension": 91.3,
"creative_writing": 87.9,
"avg_response_time": 1.8,
"cost_per_1k_tokens": 0.03
},
"gpt-4o": {
"math_reasoning": 89.1,
"code_generation": 90.2,
"text_comprehension": 93.7,
"creative_writing": 91.4,
"avg_response_time": 1.2,
"cost_per_1k_tokens": 0.025
},
"claude-4-sonnet": {
"math_reasoning": 92.3,
"code_generation": 94.1,
"text_comprehension": 89.8,
"creative_writing": 88.2,
"avg_response_time": 2.1,
"cost_per_1k_tokens": 0.035
},
"gemini-pro-2.5": {
"math_reasoning": 87.6,
"code_generation": 86.3,
"text_comprehension": 90.9,
"creative_writing": 85.7,
"avg_response_time": 1.9,
"cost_per_1k_tokens": 0.028
}
}
# 成本效益分析
def calculate_roi(model_stats):
"""计算模型的投资回报率"""
performance_score = (
model_stats["math_reasoning"] +
model_stats["code_generation"] +
model_stats["text_comprehension"] +
model_stats["creative_writing"]
) / 4
efficiency = performance_score / model_stats["cost_per_1k_tokens"]
return round(efficiency, 2)
# 输出ROI排名
print("🏆 模型ROI排名(性能/成本):")
roi_ranking = {}
for model, stats in benchmark_results.items():
roi_ranking[model] = calculate_roi(stats)
for model, roi in sorted(roi_ranking.items(), key=lambda x: x[1], reverse=True):
print(f"{model}: {roi}")
🚀 选择决策矩阵
根据具体需求选择最适合的替代方案:
# 智能模型推荐系统
class ModelRecommendationEngine:
def __init__(self):
self.model_profiles = {
"gpt-4.1": {
"strengths": ["stable", "cost_effective", "general_purpose"],
"weaknesses": ["not_fastest", "limited_multimodal"],
"best_for": ["production", "enterprise", "reliable_output"]
},
"gpt-4o": {
"strengths": ["fast", "multimodal", "latest_features"],
"weaknesses": ["higher_cost", "newer_model"],
"best_for": ["real_time", "image_processing", "innovation"]
},
"claude-4-sonnet": {
"strengths": ["logical_reasoning", "code_quality", "safety"],
"weaknesses": ["slower", "higher_cost", "limited_availability"],
"best_for": ["coding", "analysis", "research"]
},
"gemini-pro-2.5": {
"strengths": ["long_context", "multilingual", "competitive_price"],
"weaknesses": ["newer_ecosystem", "less_community"],
"best_for": ["documents", "translation", "long_text"]
}
}
def recommend_model(self, requirements: dict) -> str:
"""基于需求推荐最适合的模型"""
scores = {}
for model, profile in self.model_profiles.items():
score = 0
# 加分项
for strength in profile["strengths"]:
if requirements.get(strength, False):
score += 2
# 减分项
for weakness in profile["weaknesses"]:
if requirements.get(f"avoid_{weakness}", False):
score -= 1
# 特殊场景加分
for scenario in profile["best_for"]:
if requirements.get(f"need_{scenario}", False):
score += 3
scores[model] = score
# 返回得分最高的模型
recommended = max(scores.items(), key=lambda x: x[1])
return recommended[0], recommended[1]
# 使用示例
recommender = ModelRecommendationEngine()
# 场景1:生产环境,需要稳定性
production_req = {
"stable": True,
"cost_effective": True,
"need_production": True,
"avoid_newer_model": True
}
model, score = recommender.recommend_model(production_req)
print(f"生产环境推荐: {model} (得分: {score})")
# 场景2:编程辅助,需要代码质量
coding_req = {
"logical_reasoning": True,
"code_quality": True,
"need_coding": True
}
model, score = recommender.recommend_model(coding_req)
print(f"编程辅助推荐: {model} (得分: {score})")
🔍 选择建议:对于从GPT-4.5-Preview迁移的用户,我们建议优先考虑GPT-4.1或GPT-4o。如果你在使用过程中需要对比不同模型的实际效果,可以通过 API易 apiyi.com 平台进行并行测试,该平台支持多模型统一调用和性能对比。
❓ GPT-4.5-Preview下线常见问题
Q1: GPT-4.5-Preview何时完全无法使用?
GPT-4.5-Preview已于2025年7月14日正式下线,目前所有API调用都会返回错误。具体时间线如下:
- 2025年7月14日 00:00 UTC:官方API停止服务
- 2025年7月14日后:所有请求返回HTTP 404或模型不存在错误
- ChatGPT界面:同样已移除该模型选项
解决方案:立即切换到GPT-4.1或其他替代模型。如果您使用的是 API易 apiyi.com 平台,系统会自动提示可用的替代模型并协助快速迁移。
Q2: 迁移到GPT-4.1会影响现有应用的功能吗?
大多数情况下不会产生重大影响,但需要注意以下几点:
兼容性方面:
- API接口完全兼容,只需更改模型名称
- 输入输出格式保持一致
- 上下文长度支持相同(128K tokens)
可能的差异:
- 输出风格可能略有不同(相似度>95%)
- 某些特定任务的表现可能有轻微变化
- 响应速度通常会更快
建议做法:
# 渐进式迁移策略
import random
def gradual_migration_call(prompt, migration_ratio=0.1):
"""渐进式切换,允许A/B测试"""
if random.random() < migration_ratio:
model = "gpt-4.1" # 新模型
else:
model = "gpt-4.1" # 全部切换,因为旧模型已下线
# API调用逻辑
return call_api(model, prompt)
Q3: 如何处理依赖GPT-4.5-Preview的自动化脚本?
自动化脚本迁移需要系统性处理:
步骤1:识别所有引用
# 搜索代码库中的模型引用
grep -r "gpt-4.5-preview" ./project-directory/
grep -r "gpt-4\.5-preview" ./project-directory/
步骤2:批量替换
# 使用sed命令批量替换
find ./project-directory -name "*.py" -exec sed -i 's/gpt-4.5-preview/gpt-4.1/g' {} +
find ./project-directory -name "*.js" -exec sed -i 's/gpt-4.5-preview/gpt-4.1/g' {} +
步骤3:更新配置文件
# config.yaml 示例
api_settings:
model: "gpt-4.1" # 从 gpt-4.5-preview 更新
base_url: "https://vip.apiyi.com/v1" # 推荐使用稳定的服务商
max_tokens: 1000
temperature: 0.7
步骤4:测试验证
# 自动化测试脚本
def test_model_migration():
test_cases = [
"简单问答测试",
"代码生成测试",
"长文本处理测试"
]
for test_case in test_cases:
try:
response = call_new_model(test_case)
print(f"✅ {test_case}: 成功")
except Exception as e:
print(f"❌ {test_case}: {e}")
Q4: 迁移后成本会如何变化?
迁移到GPT-4.1通常会带来成本降低:
成本对比:
- GPT-4.5-Preview: $0.06/1K tokens
- GPT-4.1: $0.03/1K tokens
- 节省幅度: 50%成本降低
月度成本估算:
# 成本计算器
def calculate_monthly_savings(monthly_tokens_millions):
old_cost = monthly_tokens_millions * 1000 * 0.06 # GPT-4.5-Preview
new_cost = monthly_tokens_millions * 1000 * 0.03 # GPT-4.1
savings = old_cost - new_cost
return {
"old_monthly_cost": f"${old_cost:,.2f}",
"new_monthly_cost": f"${new_cost:,.2f}",
"monthly_savings": f"${savings:,.2f}",
"annual_savings": f"${savings * 12:,.2f}"
}
# 示例:月用量100万tokens
result = calculate_monthly_savings(1)
print("💰 成本节省分析:")
for key, value in result.items():
print(f" {key}: {value}")
进一步优化建议:通过 API易 apiyi.com 平台,您还可以享受批量折扣和企业级优惠,进一步降低API调用成本。
Q5: 有没有更优秀的替代方案?
除了官方推荐的GPT-4.1,还有几个优秀选择:
按场景推荐:
通用应用: GPT-4o
- 速度更快(1.2s vs 1.8s)
- 多模态支持
- 整体性能更优
编程场景: Claude-4-Sonnet
- 代码质量更高
- 逻辑推理能力强
- 安全性更好
成本敏感: Gemini Pro 2.5
- 价格具有竞争力
- 长上下文支持
- 多语言处理优秀
如何选择:
我们建议通过 API易 apiyi.com 平台进行实际测试对比,该平台提供:
- 多模型统一接口
- 实时性能监控
- 成本分析工具
- 一键模型切换
这样可以帮助您找到最适合具体业务需求的替代方案。
📚 延伸阅读
🛠️ 开源迁移工具
完整的模型迁移工具已开源到GitHub,包含自动化脚本和最佳实践:
# 快速使用迁移工具
git clone https://github.com/apiyi-api/gpt-model-migration-toolkit
cd gpt-model-migration-toolkit
# 安装依赖
pip install -r requirements.txt
# 执行项目迁移
python migrate.py --source-model gpt-4.5-preview \
--target-model gpt-4.1 \
--project-path ./your-project \
--config-template enterprise
# 验证迁移结果
python validate.py --project-path ./your-project
工具特性:
- 自动识别模型引用
- 批量代码更新
- 配置文件迁移
- A/B测试支持
- 性能对比报告
📖 学习建议:为了更好地掌握模型迁移技能,建议结合实际项目进行练习。您可以访问 API易 apiyi.com 获取免费的开发者账号,通过实际调用来加深理解。平台提供了丰富的学习资源和实战案例。
🔗 相关技术文档
| 资源类型 | 推荐内容 | 获取方式 |
|---|---|---|
| 官方文档 | OpenAI模型迁移指南 | https://platform.openai.com/docs/deprecations |
| 社区资源 | API易使用文档 | https://help.apiyi.com |
| 开源项目 | 模型迁移工具集 | GitHub搜索"gpt-migration" |
| 技术博客 | AI模型迁移实践分享 | 各大技术社区 |
深入学习建议:持续关注AI模型发展动态,我们推荐定期访问 API易 help.apiyi.com 的技术博客和更新日志,了解最新的模型发布和功能更新,保持技术领先优势。
🎯 总结
GPT-4.5-Preview模型下线是AI技术发展过程中的正常迭代。通过合理的迁移策略和 选择适合的替代方案,开发者可以在保证服务连续性的同时获得更好的性能和成本效益。
重点回顾:
- 及时迁移:立即从GPT-4.5-Preview切换到GPT-4.1或其他替代模型
- 全面测试:通过A/B测试确保迁移后的功能正常
- 成本优化:利用新模型的价格优势降低运营成本
- 持续监控:建立性能监控机制,确保服务质量
最终建议:对于企业级应用,我们强烈推荐使用 API易 apiyi.com 这类专业的API聚合平台。它不仅提供了多模型统一接口和负载均衡能力,还有完善的监控、计费和技术支持体系,能够显著提升开发效率并降低运营风险。
📝 作者简介:资深AI应用开发者,专注大模型API集成与架构设计。定期分享AI开发实践经验,更多技术资料和最佳实践案例可访问 API易 apiyi.com 技术社区。
🔔 技术交流:欢迎在评论区讨论技术问题,持续分享AI开发经验和行业动态。如需深入技术支持,可通过 API易 apiyi.com 联系我们的技术团队。