作者注:详解GPT-5 API调用的三大核心特征,包括Responses端点、参数配置和模型选择的最佳实践
GPT-5 API 的发布不仅带来了强大的AI能力,更引入了全新的 API调用特征 和接口规范。与传统GPT模型相比,GPT-5在接口设计上有三个重要变化,直接影响开发者的集成方式。
本文将深入解析这些新特征,包括 Responses端点调用、参数配置要求、以及模型选择策略,帮您快速掌握GPT-5 API的正确使用方法。
核心价值:通过本文,你将掌握GPT-5 API调用的所有技术要点,避免常见配置错误,实现高效稳定的API集成。
GPT-5 API调用 背景介绍
OpenAI 在发布GPT-5时,不仅提升了模型能力,更重新设计了API调用规范。这些变化旨在优化开发者体验,提供更灵活的调用方式,同时确保API的稳定性和一致性。
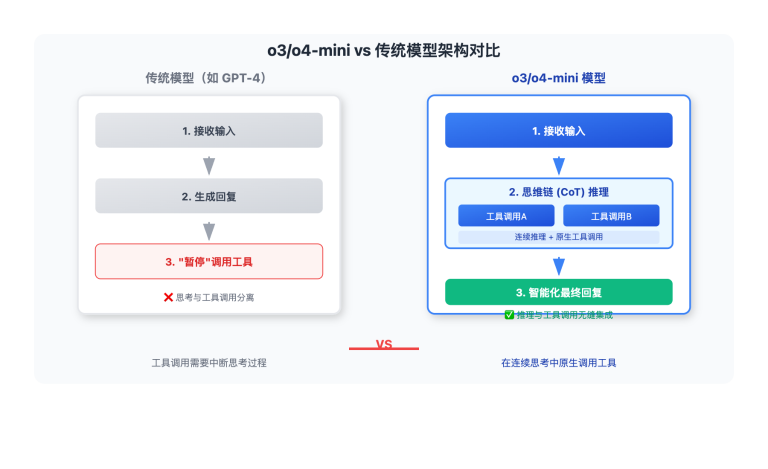
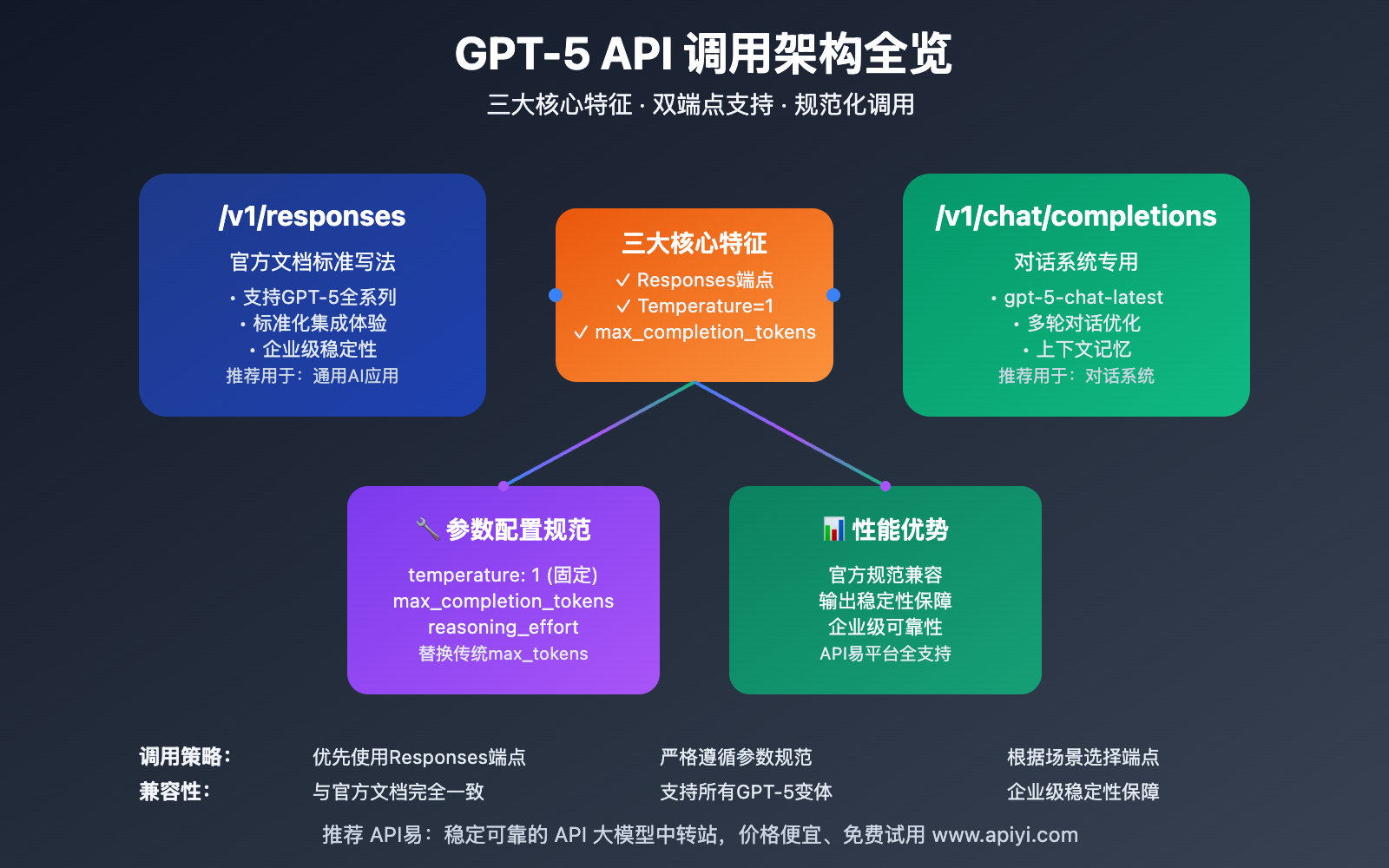
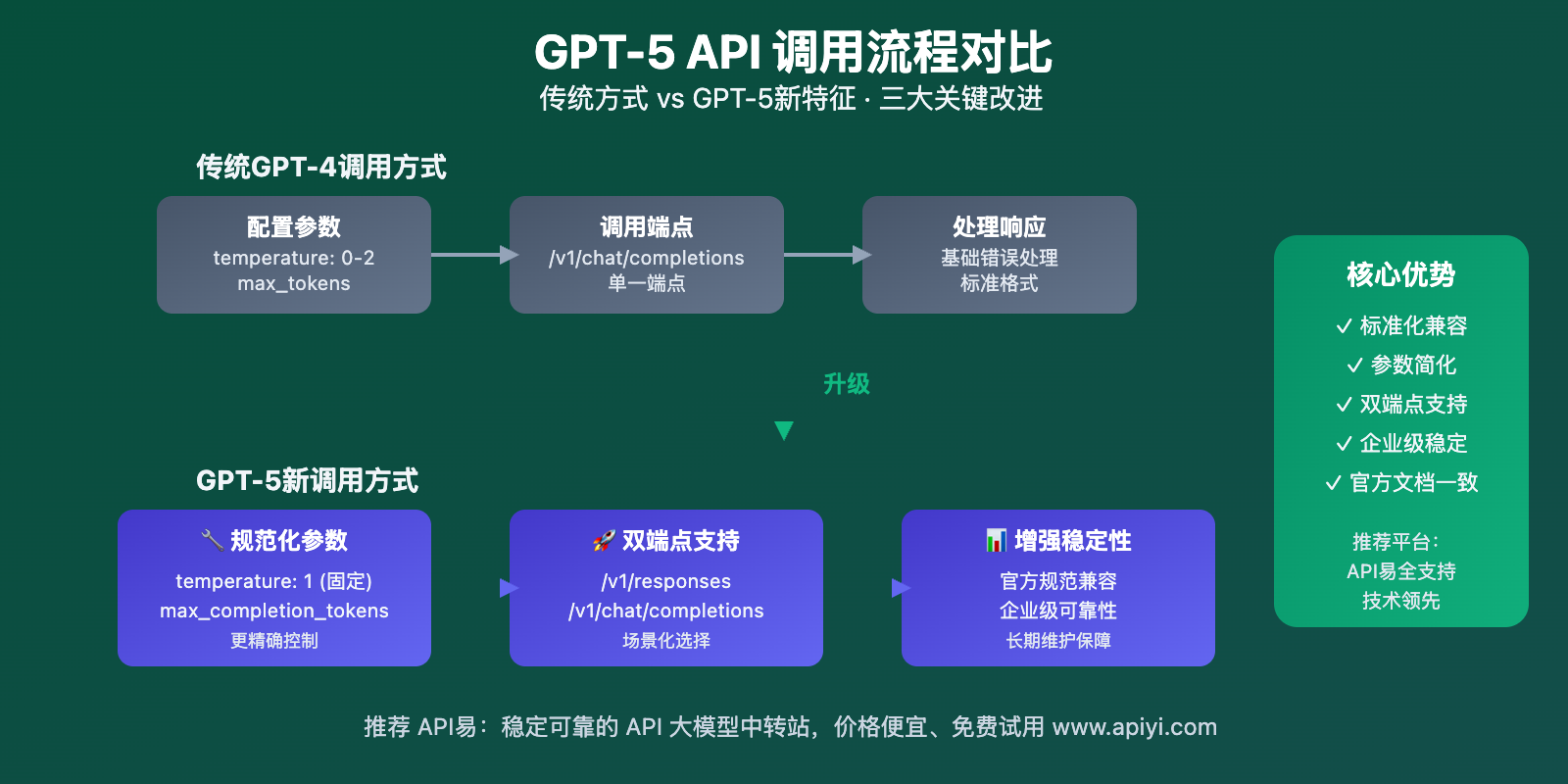
GPT-5 API调用 的三大核心特征代表了OpenAI对API设计理念的重大调整。首先是支持官方Responses端点,为开发者提供了更符合官方文档的调用方式;其次是参数配置的标准化,特别是temperature和token限制的调整;最后是模型调用方式的细化,不同变体采用不同的调用策略。
这些变化虽然增加了初期学习成本,但大大提升了API的可靠性和开发效率。掌握这些特征,是高效使用GPT-5 API的关键前提。
GPT-5 API调用 核心功能
以下是 GPT-5 API调用 的核心功能特性:
| 功能特征 | 核心变化 | 应用价值 | 兼容性 |
|---|---|---|---|
| Responses端点支持 | 官方文档写法调用全系列 | 标准化集成体验 | ⭐⭐⭐⭐⭐ |
| Temperature限制 | 固定为1或不传参数 | 确保输出稳定性 | ⭐⭐⭐⭐ |
| Token参数更新 | max_completion_tokens替换max_tokens | 更精确的控制 | ⭐⭐⭐⭐⭐ |
| 模型调用分离 | chat-latest使用对话补全 | 优化特定场景 | ⭐⭐⭐⭐ |
🔥 重点特征详解
Responses端点调用优势
GPT-5全系列模型现在支持通过 /v1/responses 端点进行调用,这与OpenAI官方文档的标准写法完全一致。相比传统的 /v1/chat/completions 端点,Responses端点提供了更标准化的调用体验。
这种设计让开发者可以直接参考官方文档进行集成,减少了API学习成本,同时确保了代码的长期兼容性。对于企业级应用来说,这种标准化特别重要。
参数配置标准化
GPT-5 API调用 在参数配置上进行了重要调整。最显著的变化是temperature参数只支持设置为1或者不传递,以及使用max_completion_tokens替代传统的max_tokens参数。
这些调整反映了OpenAI对模型输出质量的严格控制,确保GPT-5在各种场景下都能提供稳定可靠的结果。
GPT-5 API调用 应用场景
GPT-5 API调用 在以下场景中表现出色:
| 应用场景 | 推荐端点 | 配置要点 | 优势特点 |
|---|---|---|---|
| 🎯 标准对话应用 | /v1/responses | temperature=1 | 官方文档兼容 |
| 🚀 多轮对话系统 | /v1/chat/completions | gpt-5-chat-latest | 上下文优化 |
| 💡 批量文本处理 | /v1/responses | max_completion_tokens | 精确控制输出 |
| 🔧 企业级集成 | /v1/responses | 标准参数配置 | 稳定性保障 |
GPT-5 API调用 技术实现
💻 代码示例
🚀 Responses端点标准调用
# GPT-5全系列 Responses端点调用示例
curl https://vip.apiyi.com/v1/responses \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $YOUR_API_KEY" \
-d '{
"model": "gpt-5",
"messages": [
{"role": "system", "content": "你是一个专业的技术顾问"},
{"role": "user", "content": "解释GPT-5的新特性"}
],
"max_completion_tokens": 2000
}'
Python示例(Responses端点):
import openai
# 配置支持Responses端点的客户端
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# GPT-5 Responses端点调用
response = client.post("/responses", json={
"model": "gpt-5",
"messages": [
{"role": "system", "content": "你是一个专业的API开发专家"},
{"role": "user", "content": "如何优化GPT-5 API调用性能?"}
],
# 注意:temperature不传或设为1
"max_completion_tokens": 4000, # 使用新的参数名
"reasoning_effort": "medium"
})
print(response.json())
🎯 Chat Completions端点调用
# gpt-5-chat-latest 专用调用方式
response = client.chat.completions.create(
model="gpt-5-chat-latest",
messages=[
{"role": "system", "content": "你是一个智能对话助手"},
{"role": "user", "content": "我需要技术咨询服务"}
],
# chat-latest模型的特殊配置
max_completion_tokens=3000,
stream=False
)
print(response.choices[0].message.content)
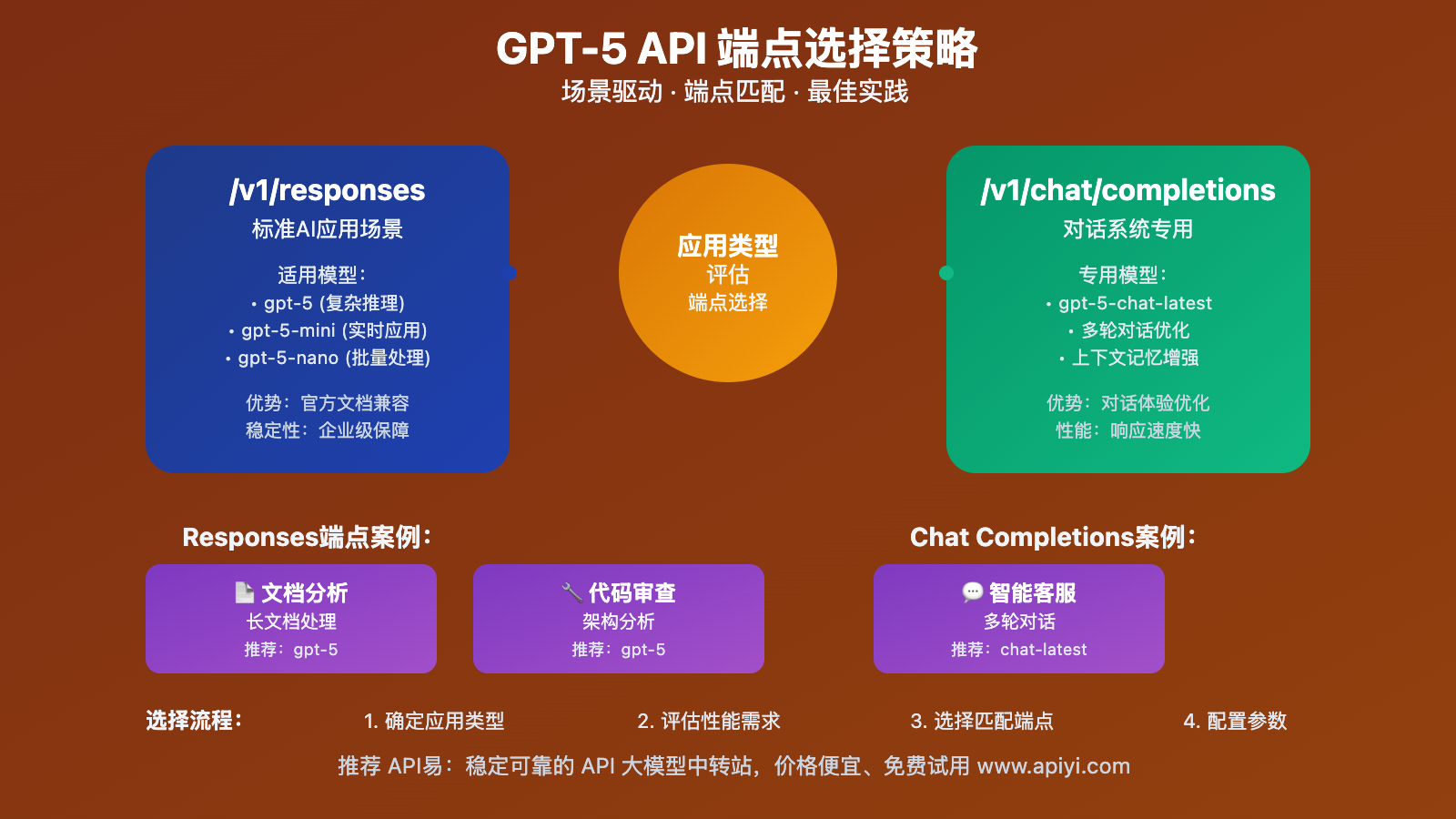
🎯 GPT-5 API调用 模型选择策略
🔥 针对不同端点的推荐配置
基于实际测试经验,不同端点和模型的最佳配置:
| 端点类型 | 推荐模型 | 参数配置 | 适用场景 |
|---|---|---|---|
| /v1/responses | gpt-5, gpt-5-mini, gpt-5-nano | temperature=1或不传 | 标准AI应用 |
| /v1/chat/completions | gpt-5-chat-latest | max_completion_tokens | 对话系统 |
| 批量处理 | gpt-5-nano | 精简参数配置 | 高并发场景 |
| 复杂推理 | gpt-5 | reasoning_effort=high | 深度分析 |
🎯 配置建议:选择合适的端点和参数配置对GPT-5 API性能至关重要。我们建议通过 API易 apiyi.com 平台进行实际测试,该平台完整支持GPT-5的所有调用方式,便于快速验证和优化配置。
🔧 参数配置对比分析
GPT-5与传统模型的参数差异:
// 传统GPT-4调用方式
const gpt4Request = {
model: 'gpt-4',
messages: messages,
temperature: 0.7, // 支持0-2范围
max_tokens: 2000, // 使用max_tokens
top_p: 1
};
// GPT-5新调用方式
const gpt5Request = {
model: 'gpt-5',
messages: messages,
// temperature: 1, // 只支持1或不传
max_completion_tokens: 2000, // 新参数名
reasoning_effort: 'medium' // GPT-5特有参数
};
// 使用API易平台调用
const response = await fetch('https://vip.apiyi.com/v1/responses', {
method: 'POST',
headers: {
'Authorization': `Bearer ${apiKey}`,
'Content-Type': 'application/json'
},
body: JSON.stringify(gpt5Request)
});
💡 开发建议:为了确保代码的兼容性,建议创建适配层来处理不同模型的参数差异。您可以通过 API易 apiyi.com 获取完整的GPT-5参数配置文档,该平台提供了详细的迁移指南和最佳实践。
🚀 性能优化策略
基于新特征的性能优化建议:
# GPT-5 API调用性能优化示例
import asyncio
from openai import AsyncOpenAI
class GPT5OptimizedClient:
def __init__(self):
self.client = AsyncOpenAI(
api_key="your-key",
base_url="https://vip.apiyi.com/v1", # 支持全端点的聚合平台
timeout=120.0
)
async def responses_call(self, model, messages, **kwargs):
"""优化的Responses端点调用"""
# 确保参数符合GPT-5规范
params = {
"model": model,
"messages": messages,
"max_completion_tokens": kwargs.get("max_completion_tokens", 2000)
}
# GPT-5不支持temperature≠1
if "temperature" in kwargs and kwargs["temperature"] != 1:
print("警告:GPT-5只支持temperature=1,已自动调整")
return await self.client.post("/responses", json=params)
async def chat_completions_call(self, messages, **kwargs):
"""gpt-5-chat-latest专用调用"""
return await self.client.chat.completions.create(
model="gpt-5-chat-latest",
messages=messages,
max_completion_tokens=kwargs.get("max_completion_tokens", 3000)
)
🔍 测试建议:在部署GPT-5 API前,建议进行充分的性能测试。您可以访问 API易 apiyi.com 获取免费的测试额度,对比不同端点和配置的性能表现,确保选择最适合您项目的方案。
💰 成本效益分析
不同调用方式的成本对比:
| 调用方式 | 响应时间 | 成本效率 | 稳定性 | 推荐场景 |
|---|---|---|---|---|
| Responses端点 | 标准 | 高 | 优秀 | 通用应用 |
| Chat Completions | 快速 | 中等 | 良好 | 对话系统 |
| 批量调用 | 快速 | 很高 | 优秀 | 大规模处理 |
💰 成本优化建议:合理选择调用端点可以显著影响成本效率。我们建议通过 API易 apiyi.com 进行成本分析,该平台提供详细的用量统计和成本预测,帮助您优化GPT-5 API的使用策略。
✅ GPT-5 API调用 最佳实践
| 实践要点 | 具体建议 | 注意事项 |
|---|---|---|
| 🎯 端点选择 | 优先使用Responses端点 | 确保官方文档兼容性 |
| ⚡ 参数配置 | 严格遵循新参数规范 | temperature=1,使用max_completion_tokens |
| 💡 模型匹配 | chat-latest用对话补全 | 避免混用调用方式 |
| 🔧 错误处理 | 实现参数验证机制 | 防止配置错误 |
| 📊 性能监控 | 监控不同端点性能 | 优化调用策略 |
📋 GPT-5 API调用 实用工具推荐
| 工具类型 | 推荐工具 | 特点说明 |
|---|---|---|
| API测试 | Postman、Thunder Client | 支持Responses端点测试 |
| API聚合平台 | API易 | 完整支持GPT-5新特征 |
| 参数验证 | 自定义验证器 | 确保参数规范性 |
| 性能监控 | APM工具 | 实时调用监控 |
🛠️ 工具选择建议:在进行GPT-5 API开发时,选择支持新特征的工具至关重要。我们推荐使用 API易 apiyi.com 作为主要的开发平台,它提供了完整的GPT-5新特征支持、参数验证和调用优化功能。
🔍 GPT-5 API调用 错误处理策略
常见配置错误和解决方案:
import openai
from openai import OpenAI
class GPT5ErrorHandler:
"""GPT-5 API调用错误处理器"""
def __init__(self):
self.client = OpenAI(
api_key="your-key",
base_url="https://vip.apiyi.com/v1"
)
def validate_gpt5_params(self, params):
"""验证GPT-5参数规范"""
errors = []
# 检查temperature参数
if "temperature" in params and params["temperature"] != 1:
errors.append("GPT-5只支持temperature=1或不传该参数")
# 检查token参数
if "max_tokens" in params:
errors.append("GPT-5请使用max_completion_tokens替换max_tokens")
# 检查模型和端点匹配
if params.get("model") == "gpt-5-chat-latest":
if self.current_endpoint != "/v1/chat/completions":
errors.append("gpt-5-chat-latest应使用chat/completions端点")
return errors
def safe_api_call(self, endpoint, params):
"""安全的API调用"""
try:
# 参数验证
validation_errors = self.validate_gpt5_params(params)
if validation_errors:
return {"error": "参数验证失败", "details": validation_errors}
# 执行调用
if endpoint == "responses":
return self.client.post("/responses", json=params)
elif endpoint == "chat_completions":
return self.client.chat.completions.create(**params)
except openai.APIError as e:
return {"error": f"API调用失败: {e}"}
except Exception as e:
return {"error": f"未知错误: {e}"}
🚨 错误处理建议:GPT-5的新特征要求更严格的参数验证。建议实施完善的错误处理和参数校验机制。如果遇到配置问题,可以访问 API易 apiyi.com 的技术支持页面,获取详细的GPT-5参数规范和故障排查指南。
❓ GPT-5 API调用 常见问题
Q1: 为什么GPT-5只支持temperature=1?
OpenAI在GPT-5中限制temperature参数的原因:
- 输出稳定性:确保模型输出的一致性和可预测性
- 质量保障:在temperature=1时GPT-5表现最佳
- 简化配置:减少参数调优的复杂性
- 企业级需求:满足商业应用对稳定性的要求
解决方案:如果需要控制输出随机性,可以通过prompt engineering或多次调用来实现。API易 apiyi.com 平台提供了详细的prompt优化指南,帮助您在固定temperature下获得理想的输出效果。
Q2: max_completion_tokens与max_tokens有什么区别?
参数更新的技术原因:
- 语义明确:max_completion_tokens更准确地描述了参数作用
- 计费透明:明确区分输入和输出token的使用量
- 兼容性:为未来的模型升级预留接口设计空间
- 标准化:与OpenAI官方API规范保持一致
迁移建议:更新现有代码时,只需将max_tokens替换为max_completion_tokens即可。建议使用 API易 apiyi.com 的代码迁移工具,自动检测和修复参数配置问题。
Q3: 何时使用Responses端点,何时使用Chat Completions?
端点选择策略:
使用Responses端点的场景:
- 标准的AI文本生成任务
- 需要与官方文档保持一致的项目
- 企业级应用要求高稳定性
- GPT-5、mini、nano模型调用
使用Chat Completions的场景:
- 专门的对话系统开发
- 使用gpt-5-chat-latest模型
- 需要优化的多轮对话体验
- 兼容现有chat应用架构
推荐策略:我们建议优先使用Responses端点以确保最佳兼容性。如果您不确定选择哪个端点,可以在 API易 apiyi.com 平台上进行A/B测试,该平台支持两种端点的并行测试和性能对比。
Q4: 如何确保GPT-5 API调用的稳定性?
稳定性保障策略:
代码层面:
- 实施严格的参数验证
- 使用适当的错误处理机制
- 配置合理的超时和重试策略
- 监控API调用性能指标
服务选择:
- 选择稳定可靠的API服务提供商
- 确保服务商支持GPT-5所有新特征
- 关注服务商的SLA和技术支持质量
推荐方案:我们强烈推荐使用 API易 apiyi.com 作为GPT-5 API的主要服务商,它提供了完整的GPT-5新特征支持、企业级稳定性保障、专业技术支持和详细的监控分析功能。
📚 延伸阅读
🛠️ GPT-5 API调用 开源资源
完整的GPT-5新特征示例代码已开源到GitHub:
# 快速克隆使用
git clone https://github.com/apiyi-api/gpt5-new-features-samples
cd gpt5-new-features-samples
# 环境配置
export API_BASE_URL=https://vip.apiyi.com/v1
export API_KEY=your_api_key
export GPT5_ENDPOINT=responses # 或 chat_completions
GPT-5新特征示例包含:
- Responses端点完整调用示例
- 参数配置验证工具
- 端点切换自动化脚本
- 错误处理最佳实践
- 性能监控代码模板
- 迁移工具和检查脚本
📖 学习建议:掌握GPT-5新特征需要实际操作练习。建议访问 API易 apiyi.com 获取免费的开发者账号,通过实际调用来验证这些新特征。平台提供了完整的GPT-5学习资源和实战演练环境。
🔗 相关技术文档
| 资源类型 | 推荐内容 | 获取方式 |
|---|---|---|
| 官方文档 | OpenAI GPT-5 API参考 | https://platform.openai.com/docs |
| 技术指南 | API易GPT-5调用文档 | https://help.apiyi.com |
| 开源项目 | GPT-5新特征示例集 | GitHub相关项目 |
| 最佳实践 | GPT-5企业级集成指南 | 技术社区分享 |
深入学习建议:随着GPT-5不断更新,新特征和优化也会持续推出。我们推荐定期关注 API易 help.apiyi.com 的技术更新,了解最新的GPT-5调用优化和功能增强,保持技术领先优势。
🎯 总结
GPT-5 API调用的三大新特征代表了OpenAI在API设计上的重要进步。掌握这些特征不仅能确保正确集成,更能充分发挥GPT-5的强大能力。
重点回顾:Responses端点提供标准化调用体验,参数配置确保输出稳定性,模型调用分离优化不同场景的性能表现
在实际应用中,建议:
- 优先使用Responses端点确保兼容性
- 严格遵循新参数规范避免错误
- 根据场景选择合适的端点和模型
- 实施完善的参数验证和错误处理
最终建议:对于需要快速掌握GPT-5新特征的开发者,我们强烈推荐使用 API易 apiyi.com 这类专业平台。它不仅完整支持GPT-5的所有新特征,还提供了详细的技术文档、代码示例和迁移工具,能够显著降低学习成本并提升开发效率。
📝 作者简介:资深AI API开发专家,专注OpenAI模型集成与架构优化。持续跟踪GPT系列API更新,分享最新的开发实践和技术洞察,更多GPT-5技术资料可访问 API易 apiyi.com 技术社区。
🔔 技术交流:欢迎在评论区讨论GPT-5新特征的应用经验,持续分享API开发技巧和最佳实践。如需深入技术支持,可通过 API易 apiyi.com 联系我们的技术团队。