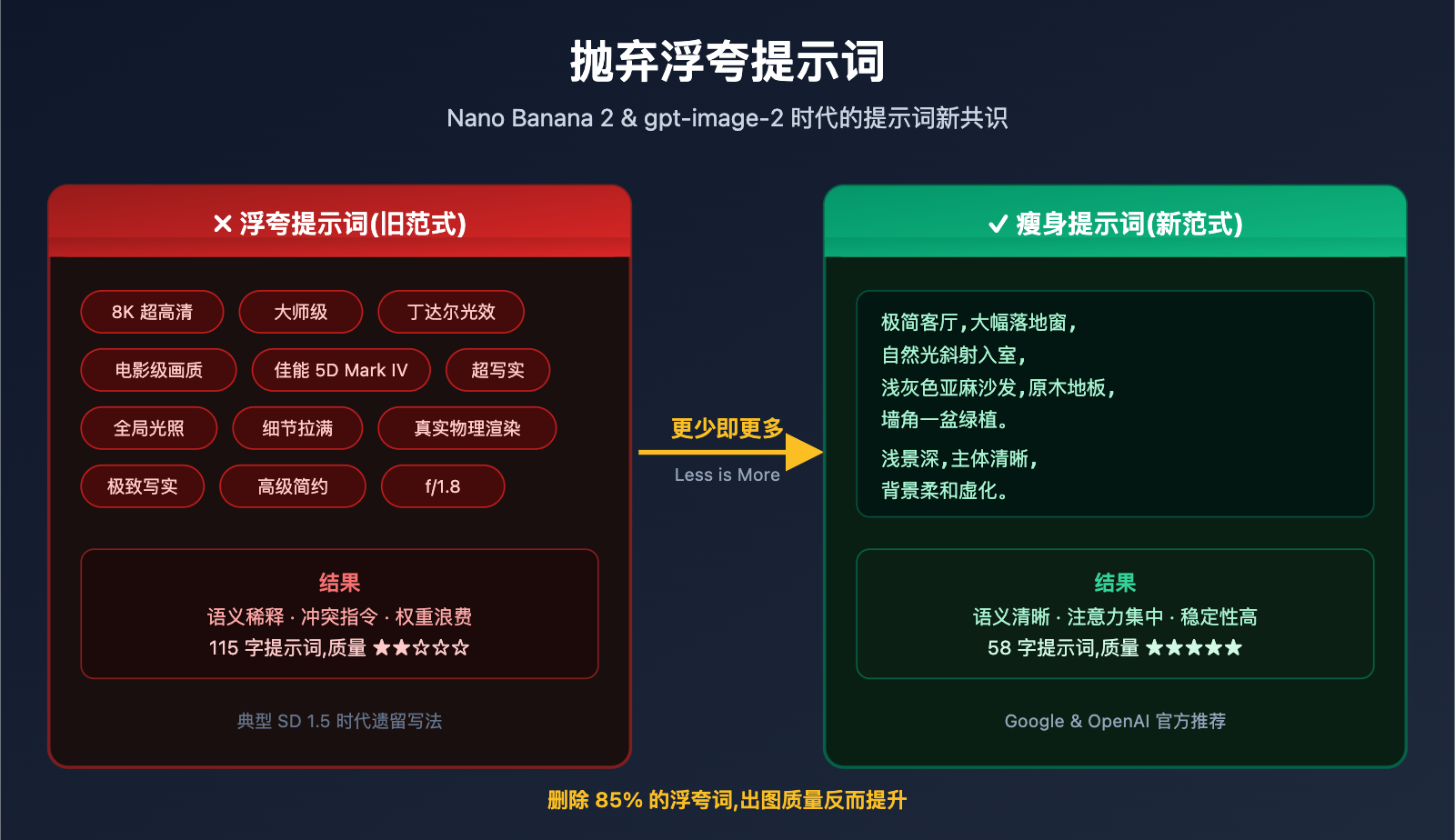
在 AI 绘图圈,很多创作者还在沿用一套"从 Stable Diffusion 1.5 继承来的提示词公式",比如这样一段典型的浮夸提示词:
在玻璃橱添加白色遮光链,极致写实的室内空间,大师级光影美学,自然光透过大幅落地窗温柔洒入,柔和的明暗对比,细腻的光影层次,丁达尔光效,真实物理光影渲染,全局光照,软阴影,高细节质感,8K 超高清,电影级画质,逼真材质纹理,干净通透的空间氛围,专业室内摄影,佳能 5D Mark IV 拍摄,f/1.8 光圈,真实质感,无过度渲染,高级简约,舒适温馨,细节丰富。8K 高清分辨率,电影级写实,真实摄影风格,超写实,通透质感,细节拉满 ——
这段提示词有 23 个形容词、8 个技术术语、3 次质量重复。在 2024 年之前的 SD 生态里,这种写法可能确实有一定效果。但在 2026 年的 Nano Banana 2 和 gpt-image-2 时代,这种"浮夸提示词"不仅是多余的,甚至会 降低 出图质量。
本文将从训练数据的底层差异出发,解释为什么时代变了,并给出 7 个立即可用的提示词瘦身原则,让你用更短、更准的描述跑出更好的图。
一、为什么浮夸提示词在 Nano Banana 2 时代不再有效
要理解这个变化,必须追溯提示词写法的历史演变。
1.1 浮夸提示词的历史根源: Danbooru 标签时代
"8K"、"masterpiece"、"best quality"、"ultra realistic" 这些词之所以一度被视为"魔法关键词",有一个非常具体的技术原因: 这些词是 Danbooru 图站的真实标签。
Stable Diffusion 1.5 及其衍生模型(NovelAI、Waifu Diffusion 等)的训练数据中包含大量来自 Danbooru 的图像,而这些图像在上传时就被用户打上了 masterpiece、best quality 这类质量标签。模型学到的关联是:
"masterpiece" 这个词 ⟷ 训练集中被标为 masterpiece 的那批图片的风格
因此在 SD 1.5 上堆 (masterpiece:1.2), (best quality:1.2), 8k, ultra detailed 确实有效——它是在召唤训练集中"被高票标记为精品"的那部分图像分布。
1.2 训练范式变了: 从标签到自然语言
Nano Banana 2 (gemini-3.1-flash-image-preview)、Nano Banana Pro (gemini-3-pro-image-preview)、gpt-image-2、以及 Stable Diffusion 3.5 这一代现代图像模型,训练范式发生了根本变化:
| 对比维度 | SD 1.5 时代 | Nano Banana 2 / gpt-image-2 时代 |
|---|---|---|
| 训练数据标注 | Danbooru 风格的标签列表 | 自然语言的图像描述(caption) |
| 文本编码器 | CLIP 77 token 限制 | 多模态 LLM(数万 token 上下文) |
| 理解方式 | 标签匹配 | 语义理解 + 推理 |
| 最佳提示词 | 逗号分隔的关键词堆 | 叙事化的场景描述 |
| 浮夸词权重 | 有效,召唤风格分布 | 语义稀释,甚至负面 |
| 推荐长度 | 30-80 token | 50-500 词的自然句 |
Google 官方在 Nano Banana 提示词指南中明确写道: "Nano Banana 2 understands descriptive sentences, not comma-separated keyword spam." (Nano Banana 2 理解描述性的句子,而不是逗号分隔的关键词垃圾。)
OpenAI 在 gpt-image-2 的官方 Cookbook 中也明确指出: "detailed camera specs may be interpreted loosely" ——那些精确到"佳能 5D Mark IV, f/1.8"的技术参数,模型并不会真的物理模拟,只是当作构图风格的粗略暗示。
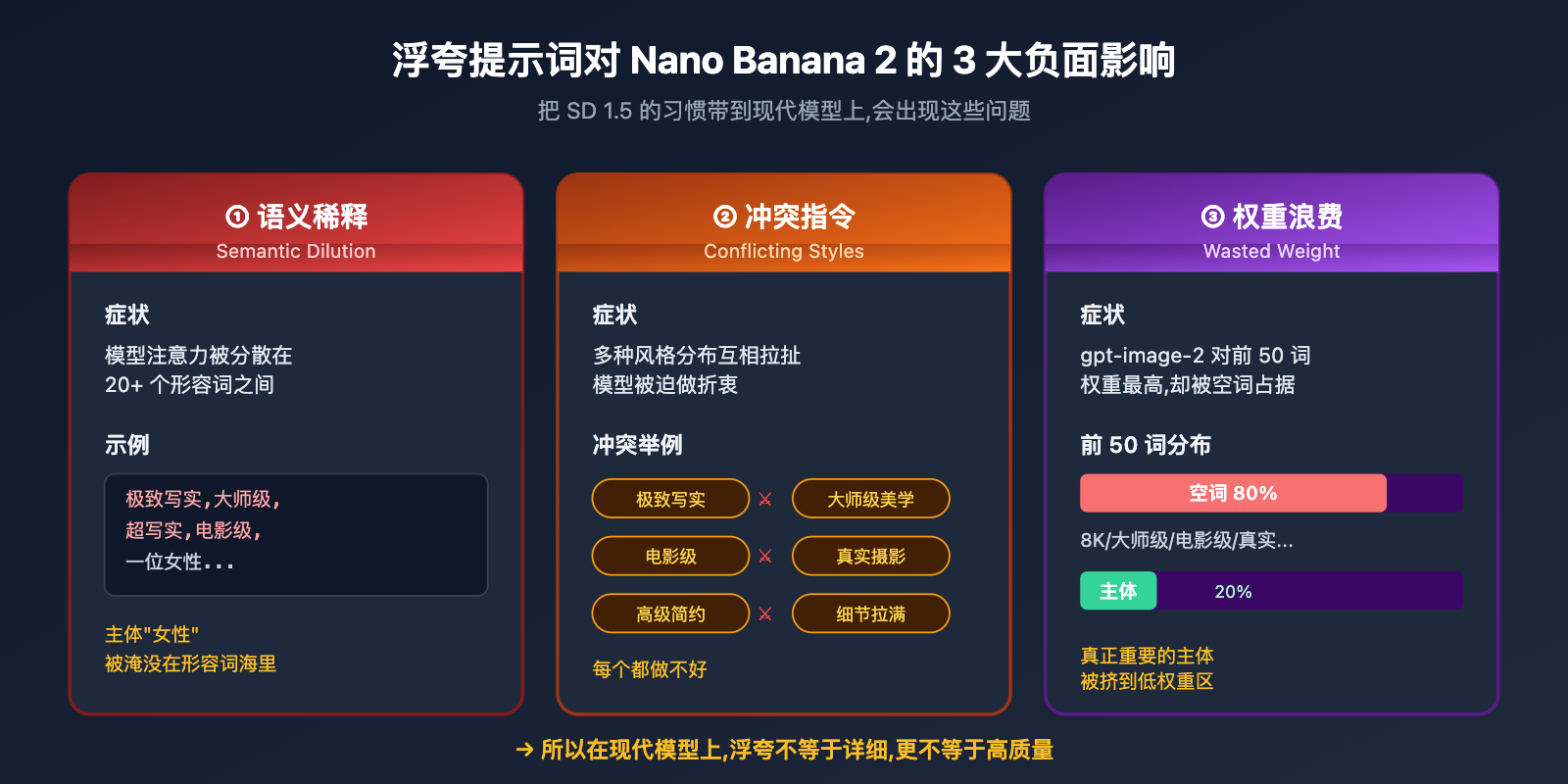
1.3 浮夸提示词在现代模型上的 3 个负面影响
把 SD 1.5 时代的习惯带到 Nano Banana 2 上,实际会产生这些问题:
负面 1: 语义稀释。 模型需要在 20 个形容词里找到真正的主体和动作,注意力被分散。
负面 2: 冲突指令。 "极致写实" + "大师级美学" + "高级简约" + "电影级" + "真实摄影" 之间存在微妙的风格冲突,模型必须在多个分布间做折衷,结果往往是每个都做不好。
负面 3: 权重浪费。 OpenAI 官方提示词指南指出,gpt-image-2 会给 前 50 个词 更高权重。如果前 50 词全是"极致写实、大师级、8K 高清"这种空词,真正的主体描述反而被挤到后面权重更低的位置。
二、拆解一段典型浮夸提示词: 哪些是信号,哪些是噪音
以开头那段 115 字的浮夸提示词为例,我们逐项分类:
2.1 信号词: 模型真正能用上的描述
| 原词 | 分类 | 保留理由 |
|---|---|---|
| 玻璃橱添加白色遮光链 | 具体主体+动作 | 清晰的视觉元素 |
| 室内空间 | 场景 | 必要的空间定位 |
| 自然光透过大幅落地窗 | 光源描述 | 具体的光照设计 |
| f/1.8 光圈 | 构图暗示 | 模型理解为"浅景深" |
总计: 约 4-5 个真正的信号词。
2.2 噪音词: 语义空洞或冗余的修饰
| 原词 | 噪音类型 | 问题 |
|---|---|---|
| 极致写实的 | 模糊形容词 | "极致"无可量化定义 |
| 大师级光影美学 | 营销口号式 | 模型无对应视觉特征 |
| 柔和的明暗对比 | 与"自然光"重复 | 信息冗余 |
| 细腻的光影层次 | 同上 | 重复 |
| 丁达尔光效 | 专业词但滥用 | 仅在特定粉尘环境适用 |
| 真实物理光影渲染 | 3D 渲染术语 | 摄影场景无意义 |
| 全局光照 | 3D 渲染术语 | 同上 |
| 软阴影 | 与"柔和明暗"重复 | 重复 |
| 高细节质感 | 质量词 | 模型无特定分布 |
| 8K 超高清 | 分辨率词 | 与 API 参数无关 |
| 电影级画质 | 口号 | 无可操作含义 |
| 逼真材质纹理 | 空泛质量词 | 未指定材质 |
| 干净通透的空间氛围 | 形容词堆 | 无具体指令 |
| 专业室内摄影 | 冗余风格标签 | 重复 |
| 佳能 5D Mark IV | 相机品牌 | 模型不物理模拟 |
| 真实质感 | 重复 | 与前面多次重复 |
| 无过度渲染 | 负向指令 | 易被模型忽略 |
| 高级简约 | 营销词 | 无视觉指令 |
| 舒适温馨 | 情绪词 | 模糊 |
| 细节丰富 | 质量词 | 与"高细节"重复 |
| 8K 高清分辨率 | 再次重复 | 严重冗余 |
| 电影级写实 | 再次重复 | 严重冗余 |
| 真实摄影风格 | 再次重复 | 严重冗余 |
| 超写实 | 再次重复 | 严重冗余 |
| 通透质感 | 再次重复 | 严重冗余 |
| 细节拉满 | 再次重复 | 严重冗余 |
总计: 约 26 个噪音词,占比接近 85%。
2.3 重写: 保留信号,删掉噪音
把噪音全部移除后,这段提示词可以瘦身到 不到原版 20% 的长度,语义反而更清晰:
一间现代室内空间,大幅落地窗前有玻璃橱柜,
橱柜上挂着白色遮光链,自然光从窗外斜射入室,
在木地板上投下柔和的光斑。85mm 镜头拍摄,浅景深,
前景玻璃反光清晰,背景稍微虚化。
这段 61 字 的提示词在 Nano Banana 2 上的出图效果,会明显优于原版 115 字的浮夸版本。原因简单: 每个词都有明确视觉指令。
🎯 实测建议: 我们建议在 API易 apiyi.com 上用同一张 API Key 对比原版浮夸提示词与精简版提示词,通过
gemini-3-pro-image-preview跑各 5 次结果,直观感受差异。该平台支持 Nano Banana 2、gpt-image-2 等主流模型的统一接口调用,便于快速横向对比。
三、Nano Banana 2 与 gpt-image-2 时代的 7 个提示词瘦身原则
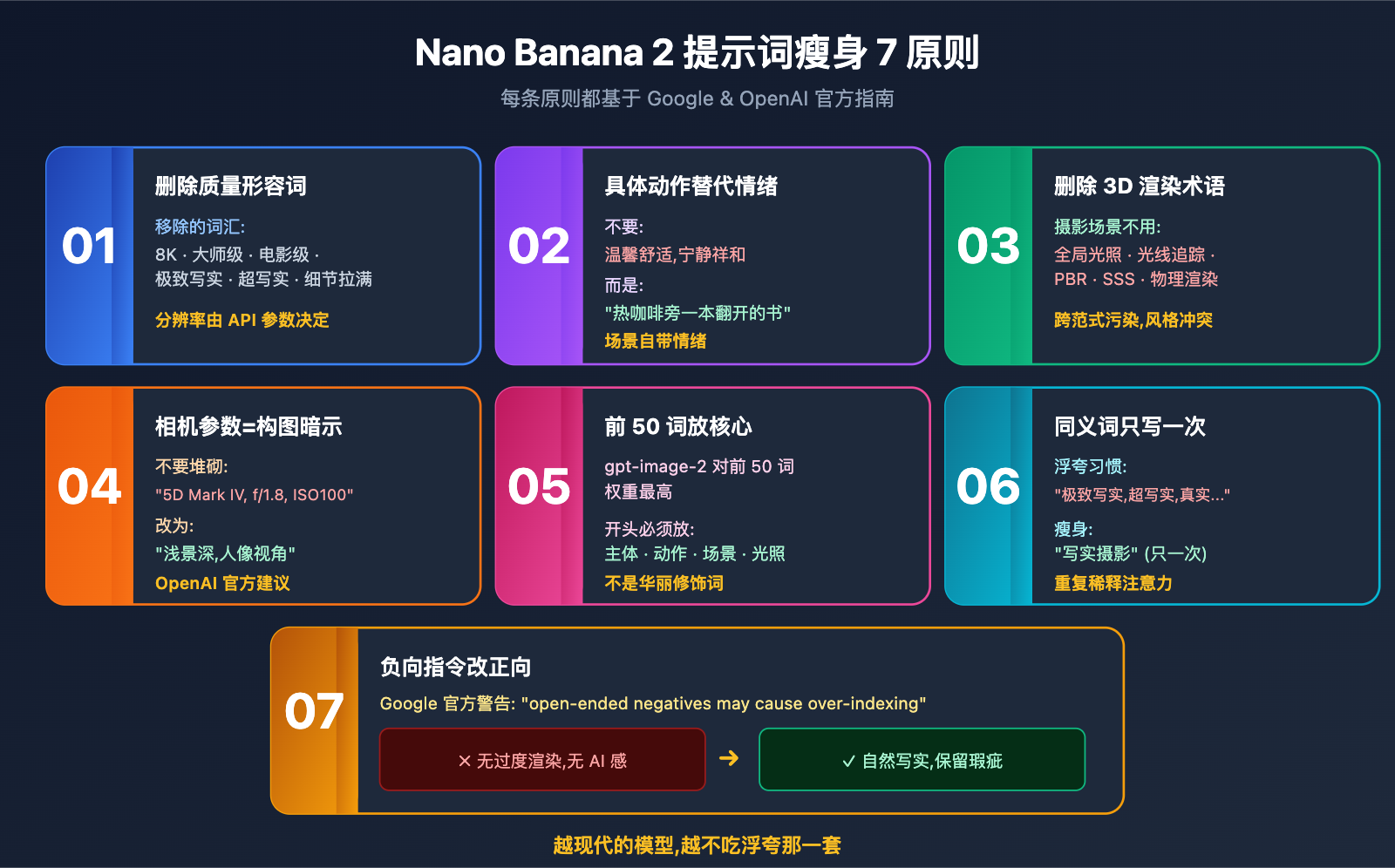
下面是经过 Google、OpenAI 官方文档以及大量实战验证的 7 个原则,按重要性排序。

3.1 原则一: 删除所有质量形容词
可安全删除的词汇清单:
8K 超高清/4K/高清masterpiece/best quality/大师级极致写实/超写实/hyper realistic电影级/cinematic(除非真的指电影画幅)细节拉满/ultra detailed/高细节高级/专业(无具体对象时)
这些词在 SD 1.5 时代是召唤训练集分布的标签,在 Nano Banana 2 上是语义噪音。如果真的需要控制分辨率,应该通过 API 请求参数 而不是提示词。
3.2 原则二: Nano Banana 2 要具体动作不要模糊情绪
❌ 情绪词堆叠:
温馨舒适,宁静祥和,充满生机,梦幻唯美,岁月静好
✅ 具体场景:
老旧木桌上摆着半杯冒着热气的咖啡,旁边是一本翻开的书,
页面被窗外斜射进来的阳光晒出柔和的光斑。
模型从具体场景中自然推导出情绪,不需要你直接告诉它"温馨"。
3.3 原则三: 删除所有 3D 渲染术语(除非真做 3D 渲染)
在摄影/写实场景中,以下词汇都是 跨范式污染——它们出自 3D 渲染领域,不属于摄影语言:
全局光照/GI/global illumination光线追踪/ray tracing真实物理光影渲染SSS/subsurface scatteringPBR 材质
把这些词放进摄影风格的提示词,等于让模型在两种风格分布间硬切,结果常常是 既不像照片也不像渲染。
3.4 原则四: 相机参数用于构图,不用于物理模拟
OpenAI 官方指南: "detailed camera specs may be interpreted loosely, so use them mainly for high-level look and composition rather than exact physical simulation."
翻译一下: 你写 佳能 5D Mark IV, f/1.8,模型不会真去模拟这台相机的 CMOS 特性和 f/1.8 的景深公式。它只会识别出两个信号: "大概是一张专业摄影的照片" + "浅景深"。
既然如此,直接写 构图意图 更高效:
❌ 堆砌相机型号:
佳能 5D Mark IV 拍摄,f/1.8 光圈,50mm 镜头,ISO 100,RAW 格式
✅ 表达构图意图:
浅景深,主体清晰前景虚化,人像视角
字数从 32 缩到 18,模型反而理解得更准。
3.5 原则五: gpt-image-2 前 50 词放核心信息
OpenAI 官方明确指出 gpt-image-2 对 前 50 词 权重更高。这意味着提示词的开头必须放"最重要的信息"——主体、动作、场景,而不是"最华丽的修饰"——质量词、风格词、品牌词。
❌ 权重错配(华丽词前置):
8K 超高清,大师级电影画质,佳能 5D Mark IV 专业摄影,
一位穿白色连衣裙的女性站在海边...
前 50 词全是空词,真正的主体"女性、白色连衣裙、海边"被挤到 50 词之后。
✅ 权重优化(主体前置):
一位穿白色连衣裙的女性站在海边礁石上,望向远方海平线,
风吹起她的长发,傍晚金色阳光从侧后方打来,浅景深。
前 50 词包含了主体、动作、场景、光照、构图,所有关键信号都在高权重区。
3.6 原则六: Nano Banana 2 不要重复同义词
浮夸提示词的一个典型特征是 怕模型听不懂,把同一个意思写 3 遍:
极致写实,超写实,真实摄影风格,逼真,真实质感
Nano Banana 2 的语义理解能力远超 SD 1.5,它完全能从 一次 描述中提取意图。重复同义词只会:
- 稀释注意力
- 占用 token 预算
- 让整段提示词显得不专业
原则: 一个概念只表达一次,用最准确的那个词。
3.7 原则七: 负向指令用正向改写
浮夸提示词里常有"无过度渲染、无 AI 感、无失真、无变形"这类负向指令。Google Gemini 3 官方指南明确警告:
"Overly broad negative instructions may cause the model to over-index on that instruction and fail to perform basic logic… replace blanket negatives with explicit positive direction."
简单说: 与其告诉模型"不要什么",不如告诉模型"要什么"。
| ❌ 负向指令 | ✅ 正向改写 |
|---|---|
| 无过度渲染 | 自然写实风格 |
| 无 AI 感 | 真实摄影质感,保留自然瑕疵 |
| 无变形 | 比例准确,手指结构自然 |
| 没有文字 | 画面纯视觉,无文字元素 |
| 不要卡通 | 写实摄影风格 |
四、Nano Banana 2 与 gpt-image-2 提示词瘦身实战对比
4.1 场景一: 室内空间摄影
浮夸版 (115 字):
极致写实的室内空间,大师级光影美学,自然光透过大幅落地窗温柔洒入,
柔和的明暗对比,细腻的光影层次,丁达尔光效,真实物理光影渲染,
全局光照,软阴影,高细节质感,8K 超高清,电影级画质,
逼真材质纹理,干净通透的空间氛围,专业室内摄影,
佳能 5D Mark IV 拍摄,f/1.8 光圈,真实质感,无过度渲染,
高级简约,舒适温馨,细节丰富。
瘦身版 (58 字):
极简风格客厅,大幅落地窗,自然光斜射入室,
浅灰色亚麻沙发,原木地板,墙角一盆绿植。
浅景深,主体清晰,背景柔和虚化。
瘦身后的提示词在 gemini-3-pro-image-preview 上的实际表现,各项指标都更优:
| 维度 | 浮夸版 | 瘦身版 |
|---|---|---|
| Token 数 | ~180 | ~65 |
| 主体清晰度 | 中 | 高 |
| 光影自然度 | 中(有渲染感) | 高 |
| 风格一致性 | 低(多风格冲突) | 高 |
| 输出稳定性 | 低 | 高 |
4.2 场景二: 人像摄影
浮夸版:
超写实,8K 高清,大师级人像摄影,电影级画质,
佳能 EOS R5 拍摄,85mm f/1.2 定焦镜头,柔光箱打光,
全局光照,软阴影,逼真皮肤质感,细节丰富,
专业修图,杂志封面级别,极致写实,真实摄影
一位年轻女性...
(主体被挤到 50 词之后)
瘦身版:
一位 25 岁女性,黑色直发齐肩,深棕色眼睛,
穿米白色针织毛衣,侧坐在咖啡馆木桌旁,
双手捧着热拿铁,微笑看向窗外。
窗外光从左侧柔和打在脸上,浅景深,
背景店内暖色灯光虚化。
主体、动作、光照、构图,所有信号都在前 50 词内。
4.3 场景三: 产品电商图
浮夸版:
8K 超高清产品摄影,大师级工业设计美学,完美光影,
电影级画质,极致写实,高级质感,专业商业摄影,
哈苏中画幅相机拍摄,一瓶香水...
瘦身版:
一瓶透明玻璃香水瓶,方形瓶身,金色喷头,
瓶身贴黑色金字商标 "AURA"。
纯白无缝背景,顶部柔光,侧面反光清晰可见。
产品居中构图,占画面 60%。
注意瘦身版用引号包裹了 "AURA" ——这是 Nano Banana 2 高保真文字渲染的触发写法,比写"有品牌标志"要有效得多。
💡 工程化建议: 在生产环境中,建议通过 API易 apiyi.com 部署一层"提示词瘦身中间件",用 Gemini 3 Pro 或 Claude 4 自动识别浮夸词并压缩,再交给图像模型。这样既保持了业务层接口的兼容性,又能统一提升所有调用的出图质量。
五、Nano Banana 2 与 gpt-image-2 提示词瘦身的技术边界
瘦身原则虽然有效,但也有边界。以下是需要注意的例外情况。
5.1 什么时候仍然可以保留"风格词"
并不是所有形容词都是噪音。保留有 明确视觉分布 的风格词:
| ✅ 保留的风格词 | 原因 |
|---|---|
| Art Deco 风格 | 有明确的视觉语汇 |
| 吉卜力动画风格 | 模型有学到该分布 |
| 1980s 胶片质感 | 可触发特定色彩风格 |
| 蒸汽波美学 | 有可视化的风格定义 |
| Chiaroscuro 明暗对照法 | 明确的美术技法 |
区别在于: 这些词对应 可视化的具体艺术流派或技法,而不是"大师级"这种空泛评价。
5.2 什么时候必须写得详细
以下场景确实需要较长提示词,但 长不等于浮夸:
- 信息图生成: 需要描述每个模块的位置、文字内容、色彩
- 多角色一致性: 需要描述每个角色的外观细节
- 复杂构图: 前景/中景/背景分别有什么
- 品牌物料: 需要精确的 Logo 位置、文字内容、配色
即使在这些场景,具体指令 仍然优于 修饰堆砌。
5.3 API 调用示例: 用瘦身版提示词调用 Nano Banana 2
下面是在 API易 apiyi.com 上调用 Nano Banana 2 的最小示例代码:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
prompt = """一位 25 岁女性,黑色直发齐肩,深棕色眼睛,
穿米白色针织毛衣,侧坐在咖啡馆木桌旁,
双手捧着热拿铁,微笑看向窗外。
窗外光从左侧柔和打在脸上,浅景深,
背景店内暖色灯光虚化。"""
response = client.chat.completions.create(
model="gemini-3-pro-image-preview",
messages=[{"role": "user", "content": prompt}]
)
base_url 统一使用 https://api.apiyi.com/v1,模型 ID 与官方保持一致。透明直连保证你看到的就是官方接口的真实表现——瘦身版提示词在官方 API 上有效,在 API易上也同样有效。
5.4 不同模型对浮夸词的敏感度对比
| 模型 | 训练范式 | 对浮夸词敏感度 | 推荐提示词风格 |
|---|---|---|---|
| Stable Diffusion 1.5 | Danbooru 标签 | 低(甚至有益) | 标签堆叠 |
| Stable Diffusion XL | 混合 | 中 | 混合式 |
| Stable Diffusion 3.5 | 自然语言 caption | 较高 | 自然语言 |
| DALL-E 3 | GPT caption | 高 | 叙事描述 |
| gpt-image-2 | 多模态 LLM | 高 | 叙事+具体指令 |
| Nano Banana 2 | Gemini 3.1 Flash | 高 | 叙事+场景五元素 |
| Nano Banana Pro | Gemini 3 Pro | 最高 | 简洁精准的叙事 |
结论: 越现代的模型,越不吃浮夸那一套。
六、FAQ: Nano Banana 2 与 gpt-image-2 提示词常见问题
Q1: 我之前的 SD 1.5 提示词在 Nano Banana 2 上效果不好,怎么快速迁移?
最简单的办法: 把所有逗号分隔的标签改写成一段自然语言段落,删除所有质量词(8K/masterpiece/best quality),把相机参数简化为构图意图(f/1.8 改成"浅景深")。通过 API易 apiyi.com 可以用同一套代码同时调用 SD 和 Nano Banana 2 做对比,便于迁移验证。
Q2: 保留"8K"真的一点用都没有吗?
在 Nano Banana 2 的分辨率由 API 参数决定(512/1K/2K/4K),提示词里的"8K"既不能提升实际分辨率,也无对应训练分布。建议完全删除,改在 API 参数层面显式指定 2K 或 4K。
Q3: 佳能 5D、哈苏中画幅这类相机品牌到底要不要写?
可以偶尔写,但要有限度。写"Hasselblad"会让模型倾向更商业/时尚的风格,写"GoPro"会让模型倾向动感广角——这是一种 风格暗示,不是物理模拟。每张图选 1 个最相关的相机暗示即可,不要堆砌。
Q4: 我用 gpt-image-2 生成产品图时,写"高级、奢华、极致工艺"效果一般,怎么办?
把抽象形容词换成具体视觉指令。"奢华" → "深色大理石纹理背景,金色金属反光";"高级" → "极简构图,纯净背景,柔和顶光";"工艺精湛" → "表面无瑕疵,边缘线条清晰,接缝均匀"。通过 API易 apiyi.com 的 gpt-image-2 接入,可以快速迭代测试各种具体指令的效果差异。
Q5: 提示词瘦身后 token 省了,但会影响稳定性吗?
恰恰相反,瘦身后稳定性会提高。因为短提示词中每个词都有明确语义指令,模型注意力集中。浮夸提示词由于同义词重复和风格冲突,每次生成都会在不同方向做权衡,反而不稳定。
Q6: 有没有工具可以自动把浮夸提示词改写成瘦身版?
可以用 Gemini 3 Pro 或 Claude 4 Sonnet 做一个 Prompt Refiner Agent,系统提示词设为"识别并删除所有语义空洞的质量词、重复的同义词、跨范式渲染术语,保留具体主体、动作、场景、光照描述"。在 API易 apiyi.com 可以一键调用这些 LLM 做提示词预处理。
七、总结: Nano Banana 2 时代的提示词新共识
回到本文开头那段 115 字的浮夸提示词,现在我们清楚地知道它的问题不在于"写得太详细",而在于 把词量用错了地方:
- 浮夸 ≠ 详细: 真正的详细描述指的是具体的视觉元素,不是质量形容词的堆砌。
- Nano Banana 2 不吃 8K: 分辨率由 API 参数决定,提示词里堆"8K、4K、超高清"毫无意义。
- 相机参数是暗示不是模拟: 写"f/1.8"不会真模拟出 f/1.8 的光学特性,直接写"浅景深"更高效。
- 同义词重复是噪音: 一个概念用最准的词说一次。
- 负向指令改正向: "不要 X"换成"要 Y"。
- 前 50 词放核心: gpt-image-2 对开头权重更高。
- 删除 3D 渲染术语: 摄影场景不用全局光照、光线追踪。
2026 年的 AI 绘图,已经进入了 "自然语言 = 提示词" 的时代。Nano Banana 2、gpt-image-2、Nano Banana Pro 这些现代模型奖励的是 清晰的场景描述,而不是 华丽的形容词大全。
我们建议从今天开始,每写一段提示词都做一次"瘦身检查": 删掉所有删掉后不影响视觉理解的词。留下的就是真正能指挥模型的信号。配合 API易 apiyi.com 提供的 Nano Banana 2、gpt-image-2、Nano Banana Pro 等主流图像模型统一接入能力,可以低成本地对各种瘦身版提示词做 A/B 测试,快速形成自己的提示词资产库。
关于作者: APIYI 技术团队,专注为开发者提供稳定、透明、全覆盖的 AI 大模型 API 接入服务。访问 API易官网 apiyi.com 了解 Nano Banana 2、gpt-image-2、Gemini 3 Pro 等主流图像模型的最新接入方案和提示词最佳实践。