2026 年 4 月初,一个名为 HappyHorse 的神秘 AI 视频模型悄无声息地出现在 Artificial Analysis Video Arena 的盲测榜单上,V1 与 V2 两个版本几乎同时刷新了文本到视频(Text-to-Video)与图像到视频(Image-to-Video)双榜的 Elo 分数,把 Seedance 2.0、Kling 3.0、PixVerse V6 等一线选手全部甩在身后。然而仅仅几天之后,HappyHorse 1.0 又突然从榜单上消失,只留下少量截图和一份语焉不详的官方页面。
围绕 HappyHorse 模型 的猜测瞬间在英文 AI 圈炸开:它是 Wan 2.7 的伪装马甲?是 ByteDance Seedance 团队的下一代实验?还是某家未公开的亚洲实验室突然亮剑?本文基于公开可验证的资料,对 HappyHorse 1.0 的架构、性能、开源状态和潜在出身做一次完整梳理,帮助你判断这匹黑马值不值得纳入你的视频生成工具栈。

HappyHorse 模型核心信息一览
在拆解技术细节之前,我们先用一张表把已知信息浓缩到一屏之内,方便快速建立认知。
| 维度 | HappyHorse 1.0 已知信息 |
|---|---|
| 模型类型 | 文本+图像到视频生成模型(联合生成画面与音频) |
| 架构 | 40 层单流 Self-Attention Transformer,无 Cross-Attention |
| 推理步数 | 仅需 8 步去噪,无需 CFG(Classifier-Free Guidance) |
| 多语言支持 | 中文、英文、日文、韩文、德文、法文 |
| 发布物 | 基础模型 / 蒸馏模型 / 超分模型 / 推理代码(官方声称全部开源) |
| 出现位置 | Artificial Analysis Video Arena(部分资料也提到 LMArena 视频赛道) |
| 当前状态 | V1/V2 已从公开榜单消失,官网仍在线但 GitHub/Model Hub 标注为 "Coming Soon" |
| 疑似出身 | 来自亚洲团队,社区猜测与 Wan 2.7 / Seedance 体系有关,但未被官方确认 |
🎯 快速测试建议:由于 HappyHorse 模型 的官方权重尚未在主流推理平台开放,如果你想第一时间在生产环境对比同档位的视频模型(如 Seedance 2.0、Kling 3.0、Veo 3.1),我们建议先通过 API易 apiyi.com 这样的统一中转平台并行调用多家视频模型,等待 HappyHorse 正式发布后再无缝切换,避免重复改造工程。
HappyHorse 模型横空出世的时间线
为了理解这匹"快乐的马"为什么能让海外 AI 圈集体震动,我们需要把时间线拉直看一遍。
Year of the Horse 与命名巧合
2026 年正好是中国农历的马年(Year of the Horse),从 2 月春节开始,海外媒体、UX Tigers 等专栏就反复提到中国 AI 圈正在围绕"马"做一波集中发布。"HappyHorse"这一命名既呼应了生肖,又与同期出现的另一款被简称为 "The Horse" 的模型形成系列联想,这是社区第一时间认定它来自亚洲团队的核心线索之一。
Arena 上的爆发与消失
根据 X(原 Twitter)上 Brent Lynch 等 AI 视频测评人在 4 月初发布的截图与后续报道,HappyHorse 1.0 的出现节奏大致如下:
- 首次出现:V1 版本以匿名条目形式登陆 Artificial Analysis Video Arena,几个小时内在文本到视频盲测中冲上前三;
- V2 版本上线:几乎同时出现 V2 变体,两个版本一度同时占据图像到视频榜单的第一与第二;
- 登顶:在不开启音频的赛道,HappyHorse 1.0 把 Seedance 2.0 720p、Kling 3.0、PixVerse V6 等一线模型全部压在身后;
- 消失:几天之内,V1/V2 同时从公开榜单移除,只留下截图与第三方记录,官方页面随后才上线"基础模型即将开源"的说明。
这种"突然上榜→霸榜→悄然下架"的节奏,在过去通常意味着两件事:要么是某家实验室在做匿名 A/B 测试,要么是模型背后的厂商还在准备正式发布,提前被流量曝光后主动撤下。两种解释都让 HappyHorse 模型 的神秘感再上一个台阶。

HappyHorse 模型架构解析:40 层单流 Transformer 是怎么打榜的
虽然官方尚未公开论文,但通过 happyhorse-ai.com 与镜像站 happy-horse.net 的描述,可以拼出 HappyHorse 1.0 在架构层面的几个关键设计选择。
单流 Self-Attention 替代多流复杂结构
传统的视频生成模型(尤其是同时处理音频、文本、画面的多模态模型)通常采用多流(multi-stream)架构,文本、视频、音频各自有自己的 Encoder,再通过 Cross-Attention 互相交互。这种结构灵活但参数浪费严重,推理时需要在多个分支之间来回搬运张量。
HappyHorse 1.0 把这一切简化成一条流水线:一颗 40 层 Self-Attention Transformer 同时处理文本、视频与音频 Token,中间没有任何 Cross-Attention,也没有为某个模态专门设计的子网络。所有模态被统一编码成 Token 序列,直接在同一个注意力空间里相互建模。这种设计在理论上有几个好处:
- 参数利用率高:不再需要为模态隔离而准备的冗余参数;
- 推理路径短:没有跨模态的额外搬运,Kernel 更连续;
- 训练目标统一:文本、画面、音频共享同一套损失,容易做端到端优化;
- 天然支持音视频联合:声音和画面是同一个序列里的 Token,自带同步约束。
8 步去噪 + 无 CFG 的极致推理
对于使用过 Stable Video Diffusion、Sora、Kling 等模型的开发者而言,"几十步去噪 + Classifier-Free Guidance"几乎是肌肉记忆。HappyHorse 1.0 的官方描述则写得相当激进:仅需 8 步去噪,且不使用 CFG,就能产出当前 Arena 排名第一的画质。
这背后通常意味着模型在训练阶段做了类似 Consistency Distillation / Rectified Flow / Progressive Distillation 的工作,把多步采样压缩成几步直接预测。配合官方同时放出的"蒸馏模型"和"超分模型",整套推理栈非常贴近"端侧友好 + 服务端高吞吐"的双重目标。
可能的参数规模与显存需求
由于权重尚未公开,无法直接验证 HappyHorse 模型 的参数量。但结合 40 层、单流、支持 6 种语言的描述,以及它在 Arena 上的表现,合理推测它的体量与 Wan 2.x、Seedance 1.x、Hunyuan Video 等公开模型属于同一量级,大概率落在 10B~30B 参数区间。这意味着真正本地部署需要至少一张高显存的专业卡,普通消费级 GPU 仍要等待 INT8/FP8 量化版本。
🎯 架构选型建议:如果你正在为团队评估"下一代视频生成基础设施",我们建议把 HappyHorse 1.0 这种"单流 Transformer + 极少步推理"的范式作为重点观察对象;在它完全开源之前,可以先用 API易 apiyi.com 上的 Seedance、Kling、Veo 等模型做工程联调,把 Prompt、镜头脚本、后期流水线打磨到位,等 HappyHorse 权重就绪后再切换。
HappyHorse 模型实测数据:Arena 双榜怎么打下来的
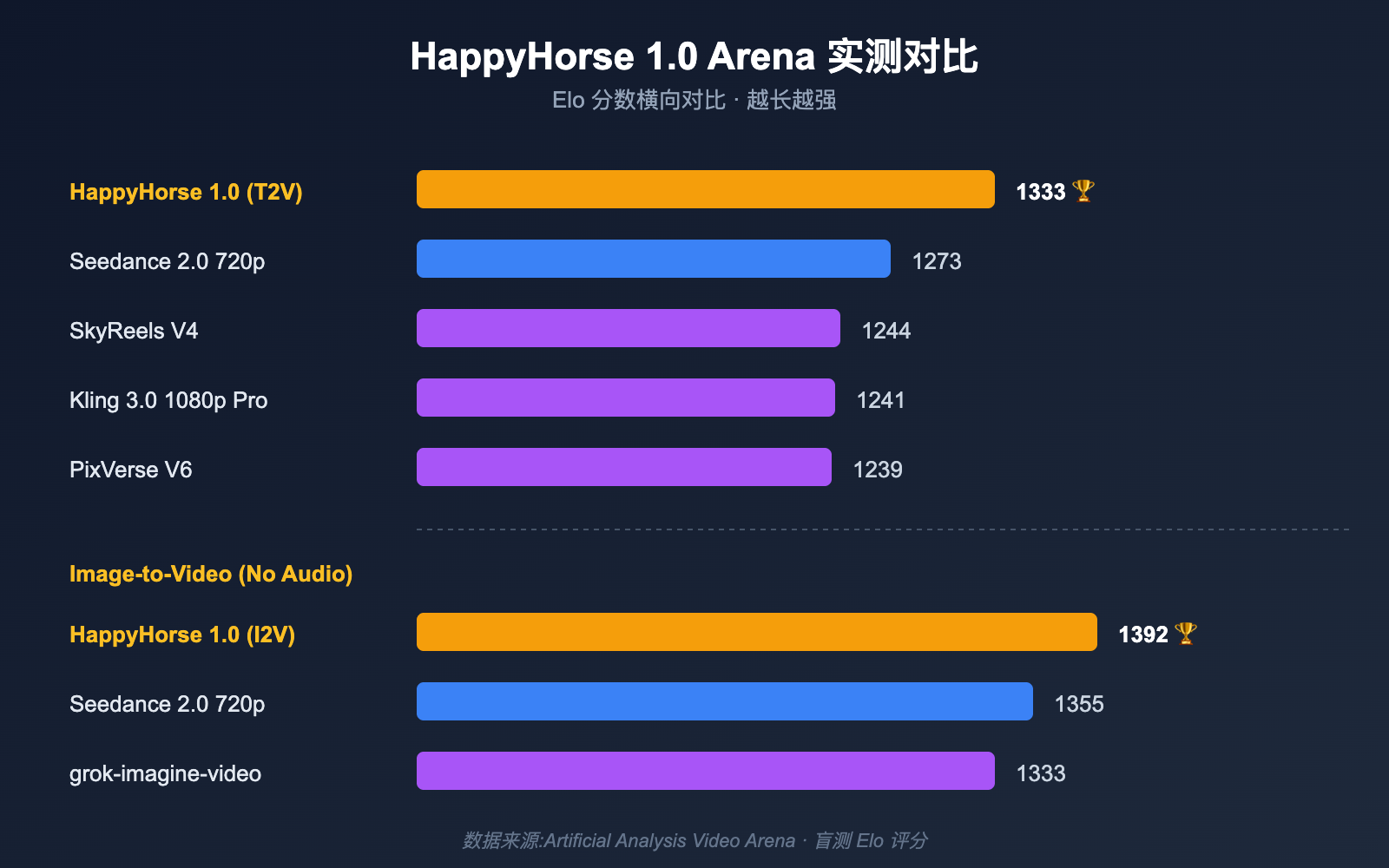
把架构讲完,真正能说服一线团队的还是数字。下面这张表汇总了第三方公开记录中 HappyHorse 1.0 在 Artificial Analysis Video Arena 上的盲测 Elo 分数,以及主要竞争对手的位置。
文本到视频 / 图像到视频 Elo 对比
| 赛道 | 排名 | 模型 | Elo 分数 |
|---|---|---|---|
| 文本到视频(无音频) | 1 | HappyHorse-1.0 | 1333 |
| 文本到视频(无音频) | 2 | Dreamina Seedance 2.0 720p | 1273 |
| 文本到视频(无音频) | 3 | SkyReels V4 | 1244 |
| 文本到视频(无音频) | 4 | Kling 3.0 1080p (Pro) | 1241 |
| 文本到视频(无音频) | 5 | PixVerse V6 | 1239 |
| 文本到视频(含音频) | 1 | Dreamina Seedance 2.0 720p | 1219 |
| 文本到视频(含音频) | 2 | HappyHorse-1.0 | 1205 |
| 图像到视频(无音频) | 1 | HappyHorse-1.0 | 1392 |
| 图像到视频(无音频) | 2 | Dreamina Seedance 2.0 720p | 1355 |
| 图像到视频(无音频) | 3 | PixVerse V6 | 1338 |
| 图像到视频(无音频) | 4 | grok-imagine-video | 1333 |
| 图像到视频(无音频) | 5 | Kling 3.0 Omni 1080p (Pro) | 1297 |
几个关键观察:
- 图像到视频赛道领先优势最大:1392 vs 1355,Elo 差距接近 40 分,在盲测体系里属于"用户能稳定感觉到差异"的级别;
- 纯文本到视频也是第一:1333 vs 1273,领先 60 分,意味着即使没有参考图,HappyHorse 模型 在镜头构图、人物动作等基础能力上已经超过 Seedance 2.0;
- 音频赛道暂时第二:Seedance 2.0 在音画同步上仍然领先,这与它针对"AI 导演"长叙事所做的工程化打磨有关;
- V2 变体:V2 在部分截图中也出现过短暂领跑,但官方目前只对外释出 1.0 的描述,V2 是否就是后来"消失"的版本仍未确认。
多语言支持与人本场景
官方明确写出 HappyHorse 1.0 原生支持 6 种语言:中文、英文、日文、韩文、德文、法文,并且强调模型在"人本(human-centric)"场景下表现尤为突出,包括:
- 细腻的面部表演(facial performance);
- 自然的语音协调(speech coordination);
- 真实的肢体动作(body motion);
- 准确的口型同步(lip sync)。
这套描述非常明显地把 HappyHorse 模型 定位在"虚拟人 / 数字内容 / 短剧"赛道,而不仅仅是"风景宣传片"。这也解释了为什么它在图像到视频(给一张人物照片做动起来)的赛道上领先优势最大——这是数字人的核心需求。
HappyHorse 模型出身猜想:WAN 2.7?Seedance?还是黑马新军?
当 HappyHorse 1.0 的截图开始在英文 AI 圈传播,最热闹的讨论就是"它到底是谁家的"。综合社区线索,我们可以把猜测整理成下面这张表。
三种主流猜测对比
| 猜测出处 | 核心论据 | 反驳论据 |
|---|---|---|
| Alibaba Wan 2.7 马甲 | Wan 2.7 同期发布,Alibaba Tongyi Lab 在视频赛道一贯激进;命名带"Horse"呼应马年 | Wan 2.7 的官方描述更偏图像 / 思考模式,与 HappyHorse 强调的单流 40 层架构对不上 |
| ByteDance Seedance 团队实验版 | Seedance 2.0 是当前盘踞 Arena 前列的中国选手,字节有充足匿名测试动机 | Seedance 2.0 官方在音频赛道仍领先 HappyHorse,字节没有理由把"更强的版本"换名上传 |
| 未公开实验室 / 学术联合体 | "全部开源 + 蒸馏模型 + 超分模型"打包发布更像研究风格;命名古怪、官网极简 | 模型质量已经达到一线商用水平,纯学术团队很难独立训练出如此规模 |
我们个人倾向于第三种假设的概率正在上升:HappyHorse 1.0 更可能来自一支希望通过开源策略一夜出圈的新团队,选择匿名上 Arena 是为了先用盲测数据建立信誉,再正式发布。 这种"先打榜、再开源、后发产品"的玩法,在过去 18 个月里已经被多家亚洲实验室验证有效。
不过这只是猜测。在 GitHub 仓库与 Model Hub 正式上线之前,任何"它就是 X"的说法都不应被当成事实。对开发者更务实的态度是:先关注它的能力曲线,而不是它的姓氏。
🎯 谨慎建议:在 HappyHorse 模型 权重尚未对外开放、来源未被官方确认之前,不建议把生产业务直接押注在它身上。可以先通过 API易 apiyi.com 等成熟平台调用 Seedance 2.0、Kling 3.0、Veo 3.1 等已商用化的视频模型完成项目交付,再在内部并行评估 HappyHorse 的开源进度。
HappyHorse 模型对行业的三层影响
即使 HappyHorse 1.0 最终被证明只是一次精心策划的预热活动,它已经对整个 AI 视频生成赛道留下了三个值得记录的影响。
第一层:架构范式的信号
过去两年,主流视频模型仍然在多流 Diffusion + Cross-Attention 的路径上做精细化打磨。HappyHorse 模型 用 Arena 第一名直接证明了"单流 Self-Attention + 极少步推理"这条路同样可以走到 SOTA,而且工程上更干净。这会促使更多团队重新审视:是不是该把 Cross-Attention 这层"复杂性税"省下来?
第二层:开源策略的演变
HappyHorse 选择"匿名上榜 → 公开宣告将开源 → 发布权重"的节奏,而不是传统的"先发论文 → 再发权重"。这是一种更接近消费级产品发布的玩法,把"用户感知数据"放在论文之前。如果它最终如约开源,HappyHorse 1.0 可能成为继 Wan、Hunyuan Video、Open-Sora 之后又一个被大量二次开发的视频基础模型。
第三层:盲测榜单的可信度
从另一个角度看,HappyHorse 的"瞬间登顶又消失"也给 Artificial Analysis、LMArena 这些盲测平台敲了一记警钟。匿名条目越来越多,如何区分"真新模型"与"已有模型的某个 Checkpoint"将成为榜单维护方必须面对的难题。 对开发者而言,这意味着我们在阅读 Elo 排行时,需要更多结合"模型卡 + 推理示例 + 真实业务数据",而不是只看一个数字。

开发者如何应对 HappyHorse 模型这类"突袭"事件
对于一线工程团队和内容创作者,与其陷入"它是谁、它什么时候开源"的猜测,不如建立一套面对此类突袭事件的标准应对动作。
推荐的四步应对流程
| 步骤 | 动作 | 目的 |
|---|---|---|
| 1 | 用统一接口先把现有视频生成业务跑顺 | 确保任何新模型出现时都能无缝切换 |
| 2 | 收集典型业务 Prompt 与参考素材 | 形成内部"基准测试集",独立于公开 Arena |
| 3 | 在新模型可用的第一时间跑内部基准 | 用自己的数据验证 Arena 分数是否能复现 |
| 4 | 评估总成本(API 价格 / 推理延迟 / 合规) | 决定是否替换主力模型 |
这个流程的核心是:不要被任何单一模型的发布节奏绑架,而是把"快速接入新模型"本身做成一种基础能力。HappyHorse 1.0 这次只是开了个头,可以预见 2026 年下半年还会有更多类似的匿名模型出现在各类视频 Arena 上。
🎯 工程化建议:对于希望长期跟进 HappyHorse 模型 与 Seedance、Kling、Veo 等竞品的团队,我们建议把视频生成统一接入 API易 apiyi.com 这样支持多模型并行调用的中转平台;这样无论后续上榜的是谁,业务侧只需切换一个 model 参数,就能完成对比与灰度发布。
HappyHorse 模型常见问题 FAQ
Q1:HappyHorse 1.0 已经可以下载使用了吗?
目前(2026 年 4 月初)HappyHorse 1.0 的官方页面仍然把 GitHub 仓库与 Model Hub 链接标注为 "Coming Soon"。也就是说,权重和推理代码尚未对外公开,任何宣称"已经能下载部署"的渠道都需要非常谨慎。建议持续关注官方网站,在权重正式释出前,先在 API易 apiyi.com 等平台调用 Seedance 2.0、Kling 3.0 等已商用化的模型完成项目。
Q2:HappyHorse 模型为什么会从 Arena 榜单上消失?
公开资料里并没有对消失原因给出确切解释。结合社区讨论,主流解释有两种:其一,模型作者主动撤回,准备重新整理结果后正式发布;其二,平台方因匿名条目身份未明而暂时下架。无论哪种,都不能简单解读为"模型不行"——它在消失前的 Elo 分数是真实存在的盲测数据。
Q3:HappyHorse 1.0 和 Wan 2.7 是同一个模型吗?
没有任何官方信息确认这一点。Wan 2.7 是阿里通义实验室在 2026 年 4 月正式发布的图像/视频模型,主打"思考模式"和长文本渲染;而 HappyHorse 模型 强调的是 40 层单流 Transformer 和 8 步去噪推理,两者的技术叙述并不一致。社区有人猜测两者同源,但目前更像是"同期同赛道的两个产品",而非同一个模型的不同包装。
Q4:HappyHorse 模型能做音视频联合生成吗?
可以。官方明确指出 HappyHorse 1.0 在同一颗 40 层 Transformer 内联合处理文本、视频和音频 Token,因此天然支持"输入文本 → 输出有声短片"。在 Arena 含音频赛道上它目前排名第二,落后于 Seedance 2.0,但仍属于第一梯队。
Q5:作为开发者,我现在应该怎么准备?
最划算的做法是保持工具链中立:把视频生成业务接入像 API易 apiyi.com 这样支持多模型并行调用的统一平台,提前把 Prompt、镜头脚本、审核流程跑通;一旦 HappyHorse 模型 正式开源或上线 API,你只需要切换 model 参数,就能在不重写代码的前提下接入这匹新黑马。
Q6:HappyHorse 1.0 适合哪些业务场景?
从官方对"人本场景、面部表演、口型同步、多语言"的强调来看,HappyHorse 模型 最合适的方向包括:虚拟主播 / 数字人短视频、AI 短剧、跨语种宣传片、广告中的人物片段。如果你的业务以风景、产品镜头为主,Seedance 2.0、Veo 3.1、Kling 3.0 等仍然是更稳妥的现成选择。
总结:HappyHorse 模型留给我们的启示
把所有线索拼在一起,HappyHorse 1.0 之所以值得写一篇完整的解析,不只是因为它在 Artificial Analysis Video Arena 上的 Elo 分数足够漂亮,更是因为它代表了 2026 年视频生成模型发布范式的一次集中体现:单流 Transformer 替代多流复杂结构、极少步推理替代几十步去噪、匿名上榜替代论文先行、开源承诺替代闭源 API。这四个变化任何一个单独出现都不算颠覆,但叠加在一起,就意味着我们正在迎来一波新的视频模型迭代节奏。
对一线团队的建议是简单而直接的:不要陷在"它是谁"的猜谜里,而是把它当成一次工程化压力测试——你的视频生成流水线,能不能在新模型出现的当天就完成接入和评估?如果答案是肯定的,那么无论 HappyHorse 模型 接下来是真正开源、被证实是某家厂商的马甲,还是悄无声息地永远沉默,你都能从中获益。
🎯 最终建议:想要第一时间体验 HappyHorse 1.0 之外的所有主流 AI 视频模型(Seedance 2.0 / Kling 3.0 / Veo 3.1 / PixVerse V6 等),并保留未来一键切换到 HappyHorse 的能力,我们建议通过 API易 apiyi.com 这样的统一中转平台进行接入,既能避免重复对接每一家厂商的 SDK,也能在新模型上线时把迁移成本降到最低。
作者:APIYI Team | 关注 AI 大模型落地与工程实践,更多视频与多模态模型评测请访问 API易 apiyi.com。