用过 Qwen3.6-Plus 的开发者大概都有同感:在 OpenRouter 上调用这个模型,429 Too Many Requests 错误几乎成了家常便饭。明明充了钱、明明不是免费用户,结果还是被限流到怀疑人生。
核心价值: 本文将深入分析 Qwen3.6-Plus 429 错误的根本原因,提供 3 种切实可行的解决方案,并分享如何通过阿里云官方直转通道实现稳定、低价的 API 调用。
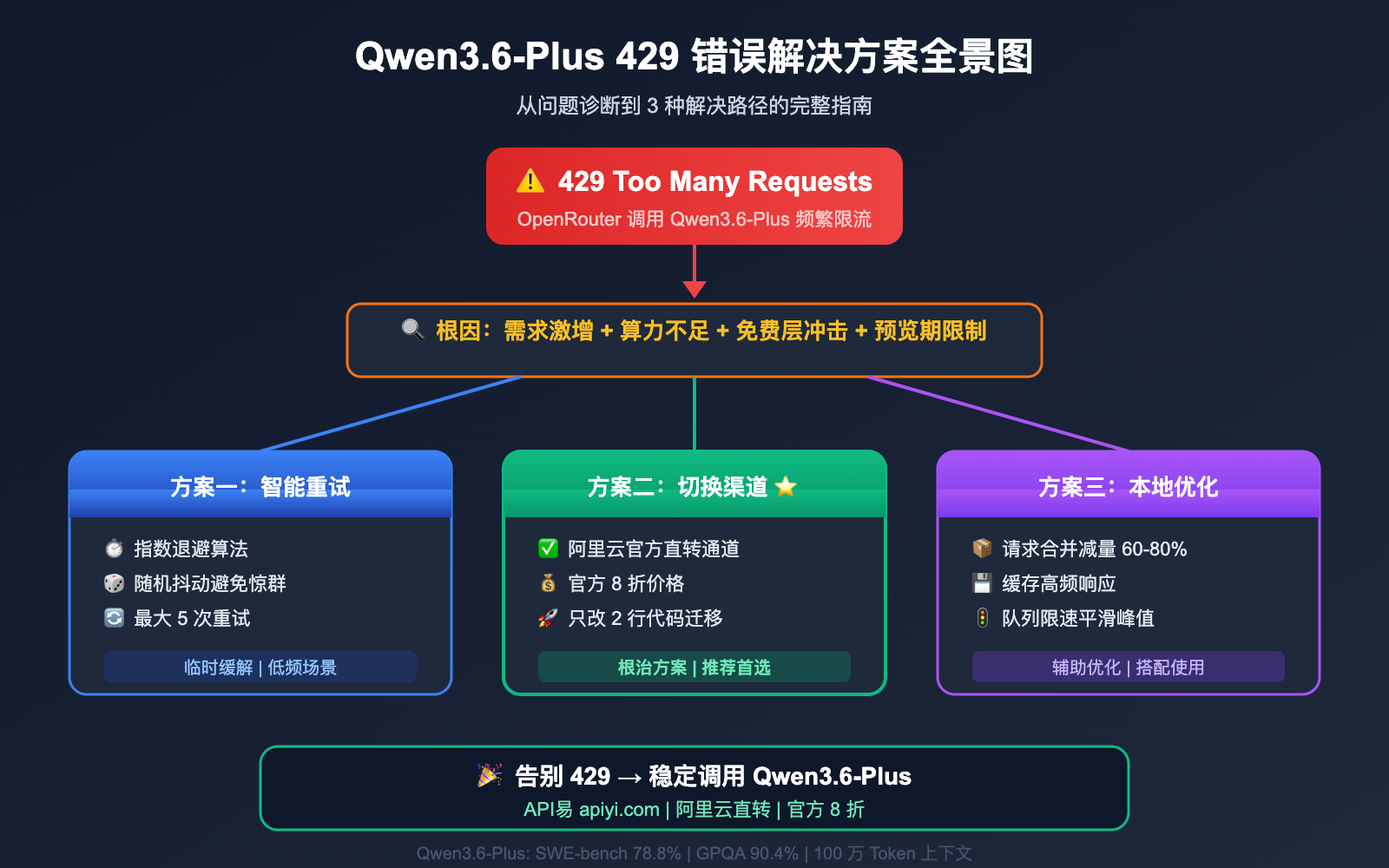
Qwen3.6-Plus 429 错误核心要点
| 要点 | 说明 | 开发者收益 |
|---|---|---|
| 429 根因分析 | 供不应求 + 免费层滥用 + 算力分配策略 | 理解问题本质,不再盲目重试 |
| 3 种解决方案 | 重试策略 / 切换渠道 / 官方直转 | 根据场景选择最优路径 |
| 性能实测 | Qwen3.6-Plus 各渠道延迟对比 | 选择最稳定的接入方式 |
| 代码示例 | Python/Node.js 可直接运行 | 5 分钟完成迁移 |
Qwen3.6-Plus 为什么这么火
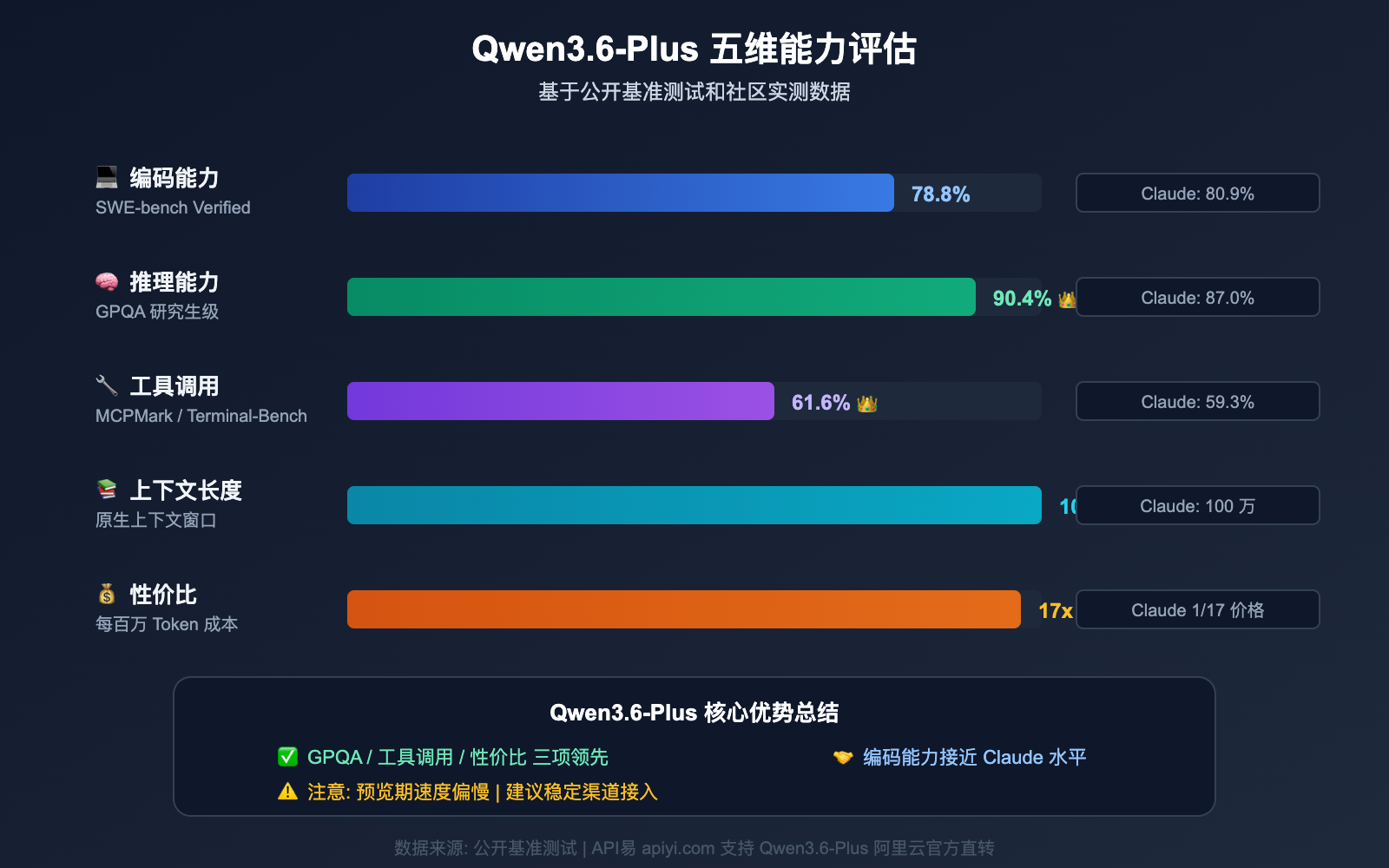
Qwen3.6-Plus 是阿里巴巴通义千问团队于 2026 年 4 月发布的旗舰模型,直接对标 Claude Opus 4.5 和 GPT-5.4。它火爆的原因很简单——性能强、价格低:
| 基准测试 | Qwen3.6-Plus | Claude Opus 4.5 | GPT-5.4 |
|---|---|---|---|
| SWE-bench Verified | 78.8% | 80.9% | 76.2% |
| Terminal-Bench 2.0 | 61.6% | 59.3% | 57.8% |
| GPQA (研究生级科学) | 90.4% | 87.0% | 88.1% |
| MCPMark (工具调用) | 48.2% | 45.6% | 43.9% |
| 上下文窗口 | 100 万 Token | 100 万 Token | 25.6 万 Token |
| 最大输出 | 65,536 Token | 32,000 Token | 16,384 Token |
在 Terminal-Bench 和 GPQA 这两个关键基准上,Qwen3.6-Plus 甚至超过了 Claude Opus 4.5,而官方 API 价格仅为 Claude 的约 1/17。这个性价比直接引爆了开发者的使用需求——也正是 429 问题的根源。
Qwen3.6-Plus 429 错误深度分析
什么是 429 错误
HTTP 429 状态码的含义很明确:Too Many Requests(请求过多)。当服务器在单位时间内收到的请求超过了其处理能力或预设限制时,就会返回这个错误。
典型的 429 错误响应:
{
"error": {
"code": 429,
"message": "Rate limit exceeded. Please slow down your requests.",
"metadata": {
"provider_name": "Qwen",
"raw": "{\"error\":{\"message\":\"Rate limit reached\",\"type\":\"rate_limit_error\"}}"
}
}
}
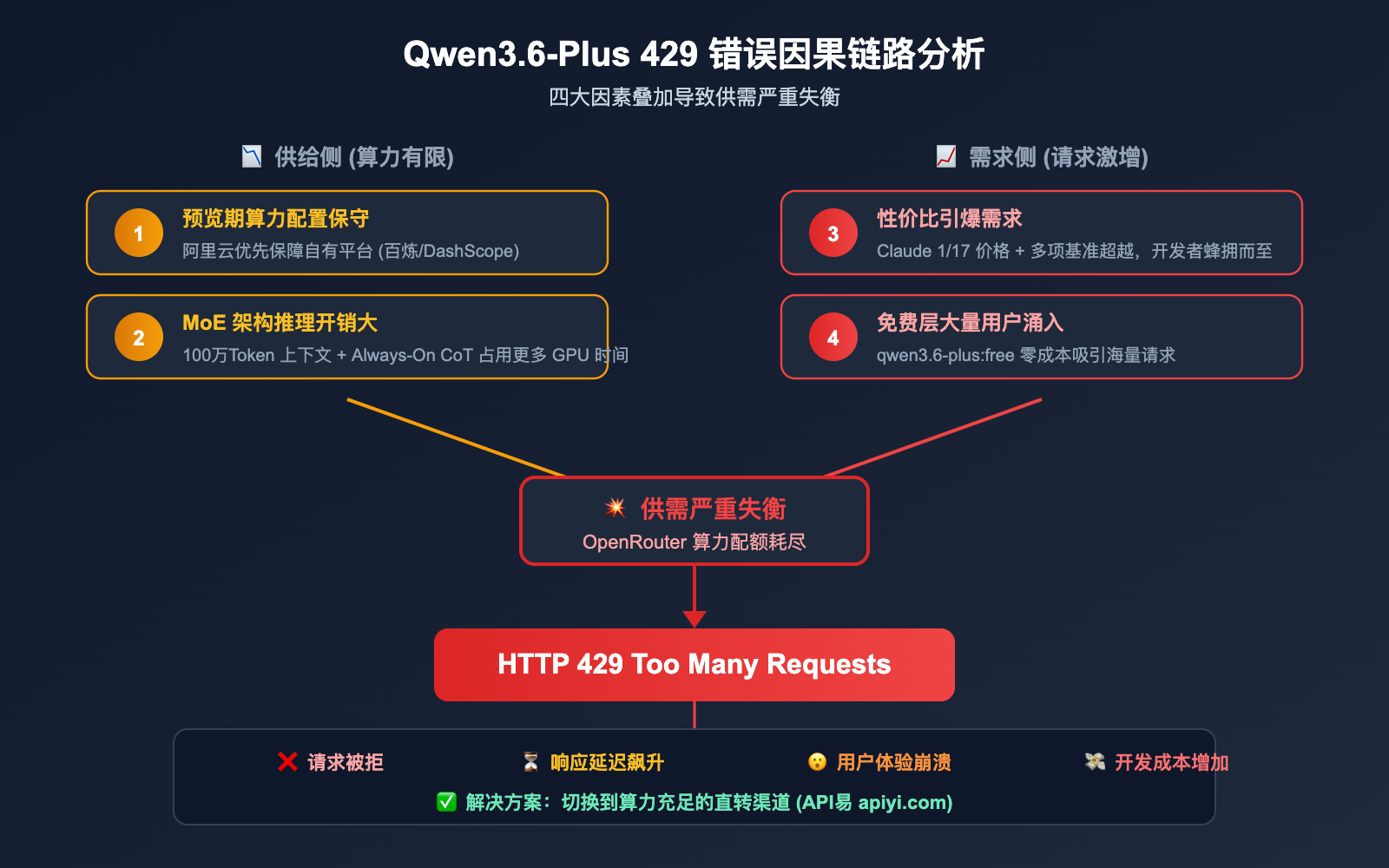
Qwen3.6-Plus 在 OpenRouter 上 429 频发的 4 大原因
原因一:需求远超供给
Qwen3.6-Plus 的性价比太高了。官方 API 入门级定价约 $0.29/百万输入 Token,是 Claude Opus 4.5 的 1/17。大量开发者涌入,而 OpenRouter 作为中转平台,其从阿里云获取的算力配额是有限的。
原因二:免费层用户大量占用
OpenRouter 提供了 qwen/qwen3.6-plus:free 免费模型,吸引了大量零成本用户。这些免费请求和付费请求共享同一套后端资源池,导致付费用户也被「殃及池鱼」。
原因三:预览期算力分配保守
Qwen3.6-Plus 目前仍处于 Preview 阶段(3 月 30 日发布预览版,4 月 2 日正式发布)。阿里云在预览期对第三方平台的算力分配通常比较保守,优先保障自有平台(DashScope / 百炼)的服务质量。
原因四:模型本身推理速度的瓶颈
虽然社区测试显示 Qwen3.6-Plus 的吞吐量约为 Claude Opus 4.6 的 3 倍,但在实际使用中,其 100 万 Token 上下文窗口和 MoE 架构在处理复杂 Agent 任务时,响应延迟仍然偏高。这意味着每个请求占用 GPU 的时间更长,单位时间内能处理的请求总量就更少。
🎯 核心洞察: 429 不是你的代码有问题,而是供需失衡。解决思路应该是换一个供给充足的渠道,而不是无限重试。通过 API易 apiyi.com 接入阿里云官方直转通道,可以有效避开 OpenRouter 的限流问题。
Qwen3.6-Plus 429 错误解决方案一:智能重试策略
指数退避重试
当你暂时无法切换渠道时,合理的重试策略可以缓解(但无法根治)429 问题:
import openai
import time
import random
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # API易 统一接口,阿里云官方直转
)
def call_qwen36_with_retry(messages, max_retries=5):
"""带指数退避的 Qwen3.6-Plus 调用"""
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=messages,
max_tokens=4096
)
return response.choices[0].message.content
except openai.RateLimitError as e:
if attempt == max_retries - 1:
raise
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"429 限流,第 {attempt+1} 次重试,等待 {wait_time:.1f}s...")
time.sleep(wait_time)
# 使用示例
result = call_qwen36_with_retry([
{"role": "user", "content": "分析这段代码的性能瓶颈"}
])
print(result)
重试策略参数建议
| 参数 | 推荐值 | 说明 |
|---|---|---|
| 最大重试次数 | 3-5 次 | 超过 5 次说明渠道本身不稳定 |
| 初始等待时间 | 1-2 秒 | 太短没效果,太长浪费时间 |
| 退避倍数 | 2x | 指数退避是行业标准 |
| 随机抖动 | 0-1 秒 | 避免「惊群效应」 |
| 超时上限 | 30 秒 | 单次等待不超过 30 秒 |
重试策略的局限性
需要明确的是:重试只是止痛药,不是治疗方案。当 OpenRouter 的 Qwen3.6-Plus 后端持续过载时,重试策略的成功率会急剧下降。更根本的解决方案是切换到一个供给充足的 API 渠道。
Qwen3.6-Plus 429 错误解决方案二:切换 API 渠道
为什么切换渠道比重试更有效
OpenRouter 429 频发的本质是该渠道的 Qwen3.6-Plus 算力配额不足。切换到直接对接阿里云算力的渠道,可以从根源上解决问题。
Qwen3.6-Plus API 渠道对比
| 渠道 | 稳定性 | 价格 (输入/百万Token) | 429 频率 | 数据收集 |
|---|---|---|---|---|
| OpenRouter Free | 差 | 免费 | 极高 | 是 (训练数据) |
| OpenRouter Paid | 一般 | ~$0.29 | 频繁 | 是 (预览期) |
| 阿里云百炼 | 好 | ¥2.00 | 低 | 需看协议 |
| API易 (阿里云直转) | 好 | 官方 8 折 | 低 | 否 |
💡 选择建议: 如果你的应用对稳定性有要求,我们建议通过 API易 apiyi.com 接入 Qwen3.6-Plus。该平台采用阿里云官方直转通道,价格仅为官方的 8 折(分组价格 0.88 折扣 + 充值 100 美金送 10 美金),同时避免了 OpenRouter 的限流问题。
从 OpenRouter 迁移到 API易 只需改 2 行代码
迁移成本极低,只需修改 base_url 和 api_key:
import openai
# ❌ 之前: OpenRouter (经常 429)
# client = openai.OpenAI(
# api_key="sk-or-v1-xxxx",
# base_url="https://openrouter.ai/api/v1"
# )
# ✅ 现在: API易 阿里云直转 (稳定无 429)
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[
{"role": "system", "content": "你是一个专业的代码审查助手"},
{"role": "user", "content": "帮我优化这个 SQL 查询的性能"}
],
max_tokens=8192
)
print(response.choices[0].message.content)
Node.js 版本:
import OpenAI from 'openai';
const client = new OpenAI({
apiKey: 'YOUR_APIYI_KEY',
baseURL: 'https://api.apiyi.com/v1' // API易 统一接口
});
const response = await client.chat.completions.create({
model: 'qwen3.6-plus',
messages: [
{ role: 'user', content: '分析这段代码的时间复杂度' }
],
max_tokens: 4096
});
console.log(response.choices[0].message.content);

Qwen3.6-Plus 429 错误解决方案三:本地请求优化
减少不必要的 API 调用
除了切换渠道,优化你的请求模式也能降低触发 429 的概率:
1. 合并请求
# ❌ 低效: 逐条发送
for item in data_list:
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[{"role": "user", "content": f"分析: {item}"}]
)
# ✅ 高效: 批量合并
batch_content = "\n".join([f"{i+1}. {item}" for i, item in enumerate(data_list)])
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[{"role": "user", "content": f"依次分析以下内容:\n{batch_content}"}],
max_tokens=16384
)
2. 缓存高频响应
import hashlib
import json
_cache = {}
def cached_qwen_call(prompt, model="qwen3.6-plus"):
cache_key = hashlib.md5(f"{model}:{prompt}".encode()).hexdigest()
if cache_key in _cache:
return _cache[cache_key]
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
result = response.choices[0].message.content
_cache[cache_key] = result
return result
3. 请求队列限速
| 优化策略 | 效果 | 适用场景 |
|---|---|---|
| 请求合并 | 减少 60-80% 请求量 | 批量数据处理 |
| 响应缓存 | 相同请求零 API 调用 | 重复查询场景 |
| 队列限速 | 平滑请求峰值 | 高并发应用 |
| 降级策略 | 429 时自动切换小模型 | 对延迟敏感的服务 |
🔧 技术建议: 以上本地优化策略搭配稳定的 API 渠道效果最佳。通过 API易 apiyi.com 接入 Qwen3.6-Plus,结合请求合并和缓存策略,可以在保证稳定性的同时进一步降低成本。
Qwen3.6-Plus 模型速度慢的原因分析
为什么 Qwen3.6-Plus 响应有时很慢
很多开发者反馈,即使没有遇到 429 错误,Qwen3.6-Plus 的响应速度也「莫名其妙地慢」。这并非个例,而是有技术层面的原因:
1. MoE 架构的推理开销
Qwen3.6-Plus 采用混合专家(MoE)架构。虽然 MoE 能显著降低训练成本,但在推理阶段,路由决策和专家切换会带来额外开销。特别是在处理长上下文时,MoE 架构的推理效率低于同参数量的 Dense 模型。
2. 100 万 Token 上下文的内存压力
100 万 Token 的上下文窗口是 Qwen3.6-Plus 的核心卖点,但也意味着 KV Cache 占用的 GPU 显存极大。当多个用户同时发起长上下文请求时,GPU 显存成为瓶颈,推理速度会显著下降。
3. 预览期算力资源有限
Qwen3.6-Plus 仍处于预览期。阿里云在这个阶段通常不会投入与正式发布时同等规模的算力。官方可能在观察实际使用模式后,再逐步扩容。
4. Always-On 推理链的额外 Token 消耗
Qwen3.6-Plus 默认开启了 Always-On Chain-of-Thought 推理模式。这意味着模型会在每次响应中生成内部思考过程,实际生成的 Token 数量远多于最终输出。这些「隐藏 Token」会占用额外的推理时间。
不同渠道的延迟实测参考
| 渠道 | 首 Token 延迟 | 吞吐量 (Token/s) | 备注 |
|---|---|---|---|
| OpenRouter (高峰) | 8-15s | 15-25 | 经常 429 |
| OpenRouter (低谷) | 3-5s | 30-50 | 凌晨时段 |
| 阿里云百炼 | 2-4s | 40-60 | 国内直连 |
| API易 (直转) | 2-5s | 35-55 | 海外稳定访问 |
💰 成本提示: Qwen3.6-Plus 的速度在不同渠道和负载下差异较大。如果你对延迟敏感,建议通过 API易 apiyi.com 进行实际测试。平台提供阿里云官方直转通道,既能享受 8 折优惠价格,又能获得更稳定的响应速度。
Qwen3.6-Plus 快速上手实战
使用 API易 调用 Qwen3.6-Plus 的完整示例
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
# 基础对话
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[
{"role": "system", "content": "你是一个资深 Python 开发专家"},
{"role": "user", "content": "帮我写一个高性能的异步爬虫框架"}
],
max_tokens=8192,
temperature=0.7
)
print(response.choices[0].message.content)
查看流式输出完整代码
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
# 流式输出 - 适合需要实时反馈的场景
stream = client.chat.completions.create(
model="qwen3.6-plus",
messages=[
{"role": "system", "content": "你是一个资深架构师"},
{"role": "user", "content": "设计一个支持百万并发的消息队列系统"}
],
max_tokens=16384,
temperature=0.7,
stream=True
)
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="", flush=True)
print() # 换行
🚀 快速开始: 推荐通过 API易 apiyi.com 平台获取 API Key 来调用 Qwen3.6-Plus。注册即可体验,充值 100 美金送 10 美金,Qwen3.6-Plus 享受官方 8 折价格。
Qwen3.6-Plus 适用场景与选型建议
什么场景特别适合 Qwen3.6-Plus
| 应用场景 | 推荐理由 | 替代方案 |
|---|---|---|
| Agent 自动化 | Terminal-Bench 61.6% 领先,原生工具调用 | Claude Opus 4.5 |
| 代码审查/修复 | SWE-bench 78.8%,接近 Claude 水平 | Claude Opus 4.5 |
| 科学推理 | GPQA 90.4% 全场最高 | GPT-5.4 |
| 长文档处理 | 100 万 Token 上下文 | Gemini 2.5 Pro |
| 成本敏感项目 | 约 Claude 1/17 的价格 | DeepSeek V3 |
什么场景需要谨慎使用
- 对延迟极度敏感的实时应用: Qwen3.6-Plus 的 MoE 架构在长上下文下延迟偏高
- 生产环境关键路径: 预览期模型可能有不可预见的行为变更
- 需要严格 SLA 保障的场景: 预览期无正式 SLA
🎯 选型建议: 对于需要同时使用多个模型的项目,我们建议通过 API易 apiyi.com 平台统一接入。平台支持 Qwen3.6-Plus、Claude、GPT 等主流模型的 OpenAI 兼容接口,一个 API Key 即可切换不同模型,便于在不同场景下灵活调度。
Qwen3.6-Plus 429 错误常见问题
Q1: 在 OpenRouter 充了钱为什么还是 429?
这是因为 OpenRouter 的付费用户和免费用户共享后端算力池。即使你是付费用户,当整体请求量超过 OpenRouter 从阿里云获取的算力配额时,付费用户也会被限流。解决方案是切换到供给更充足的渠道,比如通过 API易 apiyi.com 直接使用阿里云官方直转通道。
Q2: Qwen3.6-Plus 的 429 错误会好转吗?
随着阿里云扩容和模型正式 GA(General Availability),429 问题预计会有所缓解。但 OpenRouter 作为多方中转平台,其算力分配始终受限于上游供给。如果你的业务对稳定性有要求,建议长期使用直连阿里云算力的渠道,而非依赖中转平台。
Q3: API易的 Qwen3.6-Plus 和 OpenRouter 的有什么区别?
核心区别在于算力来源。API易 apiyi.com 平台采用阿里云官方直转通道,算力来自阿里云百炼平台而非中转。这意味着更低的 429 发生率和更稳定的响应速度。价格方面,API易 提供官方 8 折优惠(分组 0.88 折扣 + 充值返赠),且兼容 OpenAI SDK 接口格式,迁移成本几乎为零。
Q4: Qwen3.6-Plus 速度慢是正常的吗?
Qwen3.6-Plus 的 MoE 架构和 100 万 Token 上下文确实在推理时比 Dense 模型开销更大。加上预览期算力配置保守,速度偏慢是当前阶段的普遍现象。不过其绝对吞吐量仍然可观,建议通过流式输出(stream=True)改善用户体验。
Q5: 如何在 Claude Code 中使用 Qwen3.6-Plus?
Qwen3.6-Plus 支持 Anthropic 协议和 OpenAI 协议双兼容。你可以通过修改 Claude Code 的 API 端点配置来使用 Qwen3.6-Plus。通过 API易 apiyi.com 平台接入时,使用标准的 OpenAI SDK 格式即可,具体配置可参考平台文档。
Qwen3.6-Plus 429 错误解决方案总结
Qwen3.6-Plus 的 429 问题本质上是一个供需失衡的问题:模型太强、价格太低、需求太大,而 OpenRouter 的算力配额无法满足所有用户。
三种解决方案的适用场景:
- 智能重试: 临时方案,适合低频调用场景
- 本地优化: 减少请求量,适合所有场景
- 切换渠道: 根本解决方案,适合对稳定性有要求的项目
对于需要稳定调用 Qwen3.6-Plus 的开发者,推荐通过 API易 apiyi.com 平台接入阿里云官方直转通道。享受官方 8 折价格的同时,告别 429 限流困扰,让你的应用专注于业务逻辑而非错误处理。
📝 作者: APIYI Team | 更多 AI 模型 API 接入教程和避坑指南,请访问 API易帮助中心: help.apiyi.com