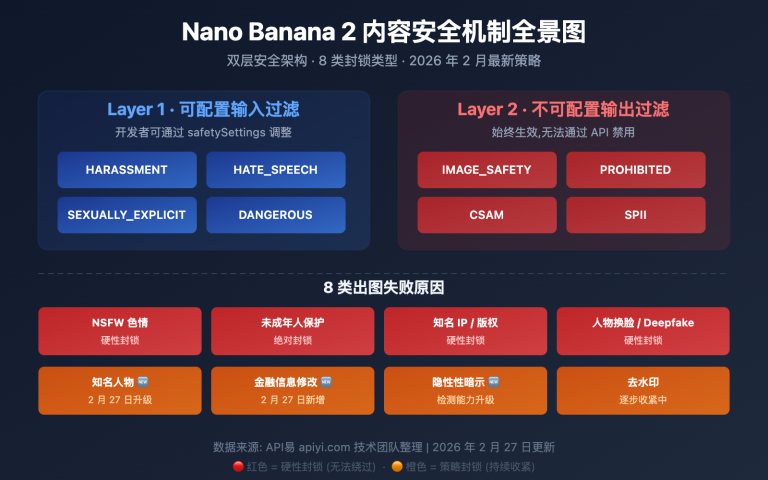
Google 在 2026 年 3 月发布了一个重要模型——Gemini Embedding 2 Preview,业界首个原生多模态嵌入模型。它能将文本、图片、视频、音频和 PDF 文档统一映射到同一个向量空间中,在 MTEB 多语言基准测试中排名第 1,领先第二名 5 个百分点以上。
核心价值: 读完本文,你将了解 Gemini Embedding 2 Preview 的 5 大技术突破、与竞品的定价和性能对比,以及如何通过 API 快速接入使用。
Gemini Embedding 2 Preview 是什么
Gemini Embedding 2 Preview 是 Google 于 2026 年 3 月 10 日发布的最新嵌入模型。它基于 Gemini 架构初始化,采用双向注意力 Transformer 结构,是 Google 第一个原生支持多模态输入的嵌入模型。
| 规格 | 详情 |
|---|---|
| 模型 ID | gemini-embedding-2-preview |
| 发布时间 | 2026 年 3 月 10 日 |
| 状态 | Preview(预览版,正式版待定) |
| 默认输出维度 | 3,072 |
| 可选维度范围 | 128 — 3,072 |
| 最大输入 Token | 8,192(是上代的 4 倍) |
| 多模态支持 | 文本、图片、视频、音频、PDF |
| 语言支持 | 100+ 种语言 |
| Matryoshka 训练 | 支持(可截断维度保持语义质量) |
| 可用平台 | Gemini API、Vertex AI、API易 apiyi.com |
与上代模型的关键差异
| 特性 | text-embedding-004 | gemini-embedding-001 | gemini-embedding-2-preview |
|---|---|---|---|
| 最大输入 Token | 2,048 | 2,048 | 8,192 |
| 输出维度 | 最高 768 | 128-3,072 | 128-3,072 |
| 多模态 | 仅文本 | 仅文本 | 文本+图片+视频+音频+PDF |
| 任务类型指定 | task_type 字段 |
task_type 字段 |
Prompt 内嵌指令 |
| MRL 支持 | 不支持 | 支持 | 支持 |
| 价格/百万 Token | 已停服 | $0.15 | $0.20 |
🎯 接入提示: API易 apiyi.com 已支持 gemini-embedding-2-preview 模型调用,
通过 OpenAI 兼容接口即可接入,无需单独配置 Google API Key。
5 大技术突破详解
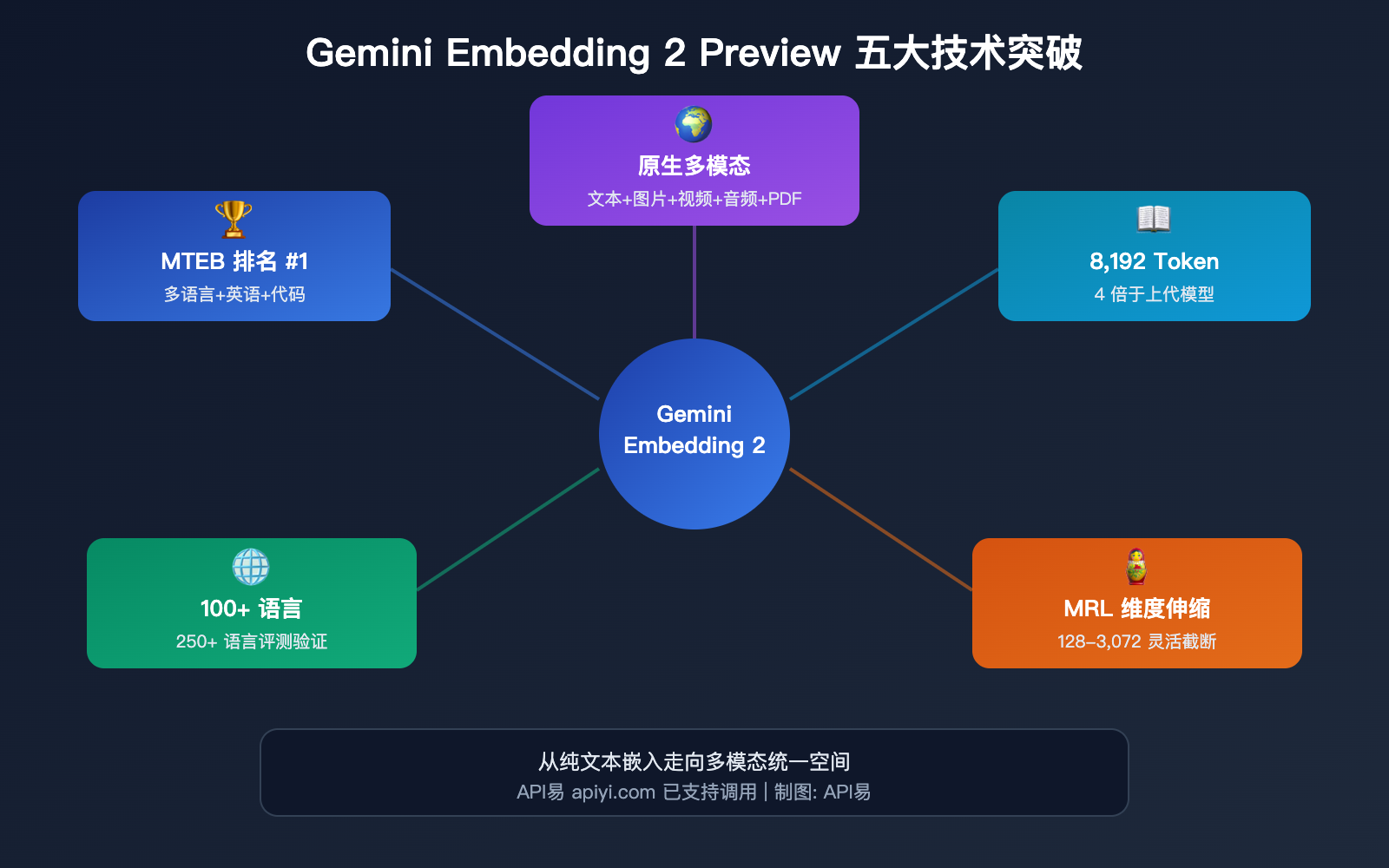
突破一:原生多模态统一嵌入空间
这是 Gemini Embedding 2 最大的差异化优势——5 种模态的内容被映射到同一个向量空间。
| 模态 | 格式要求 | 单次限制 | 说明 |
|---|---|---|---|
| 文本 | 纯文本 | 8,192 Token | 支持 100+ 语言 |
| 图片 | PNG, JPEG | 每请求最多 6 张 | 直接处理像素 |
| 视频 | MP4, MOV | 最长 120 秒 | 自动采样最多 32 帧 |
| 音频 | MP3, WAV | 最长 80 秒 | 原生处理,无需转录 |
| PDF 文档 | 每请求最多 6 页 | 含 OCR 能力 |
实际应用场景:
- 用文本搜索图片("红色跑车在赛道上"→ 返回匹配的图片)
- 用图片搜索相似视频片段
- 用语音描述搜索相关文档
- 构建跨模态的统一知识库
这在之前的嵌入模型中是不可能的——OpenAI 的 text-embedding-3 系列只支持文本,如果需要图片搜索,你必须先用视觉模型提取描述再嵌入,多了一步且损失信息。
突破二:8,192 Token 上下文窗口
输入窗口从 2,048 提升到 8,192 Token,意味着一次可以嵌入更长的文档段落。
对 RAG(检索增强生成)系统来说,这个提升非常实用:
- 之前需要将文档切成 500-1000 Token 的小段
- 现在可以用 2000-4000 Token 的大段,保留更多上下文
- 更大的文档段 = 更少的切分 = 检索结果更完整
突破三:Matryoshka 维度伸缩
Gemini Embedding 2 使用 Matryoshka Representation Learning (MRL) 训练,模型会将最重要的语义信息集中在向量的前几个维度中。
这意味着你可以根据场景灵活选择维度:
| 维度 | 向量大小 | 适用场景 | 质量损失 |
|---|---|---|---|
| 3,072 (默认) | 12.3 KB | 最高精度检索 | 无 |
| 1,536 | 6.1 KB | 平衡精度与存储 | 极小 |
| 768 | 3.1 KB | 大规模部署首选 | 小 |
| 256 | 1.0 KB | 实时推荐系统 | 中等 |
| 128 | 0.5 KB | 极限压缩场景 | 较大 |
注意: 当使用低于 3,072 的维度时,需要手动对向量进行归一化后再计算相似度。
突破四:100+ 语言支持
在 MTEB 多语言基准测试中,Gemini Embedding 2 在 250+ 种语言上进行了评测,覆盖范围远超竞品。
关键语言性能指标:
- 双文本挖掘 (Bitext Mining): 79.32 分
- 跨语言检索 (XOR-Retrieve): Recall@5kt 90.42 分
- 多语言理解 (XTREME-UP): MRR@10 64.33 分
突破五:MTEB 多项排名第 1
| 基准测试 | 得分 | 排名 | 领先幅度 |
|---|---|---|---|
| MTEB 多语言 (Mean Task) | 68.32 | 第 1 | +5.09 |
| MTEB 多语言 (Mean Type) | 59.64 | 第 1 | — |
| MTEB 英语 v2 (Mean Task) | 73.30 | 第 1 | — |
| MTEB 英语 v2 (Mean Type) | 67.67 | 第 1 | — |
| MTEB 代码 (Mean All) | 74.66 | 第 1 | — |
作为对比,第二名模型 gte-Qwen2-7B-instruct 在多语言 MTEB 上的得分为 62.51——Gemini Embedding 2 领先近 6 分,这在嵌入模型领域是非常大的差距。
💡 开发建议: 如果你正在构建 RAG 系统或语义搜索应用,
Gemini Embedding 2 在多语言和代码场景中都是当前最强的选择。
通过 API易 apiyi.com 可以一键接入该模型,同时支持 OpenAI embedding 模型,
方便快速对比效果。
与竞品的定价和性能对比
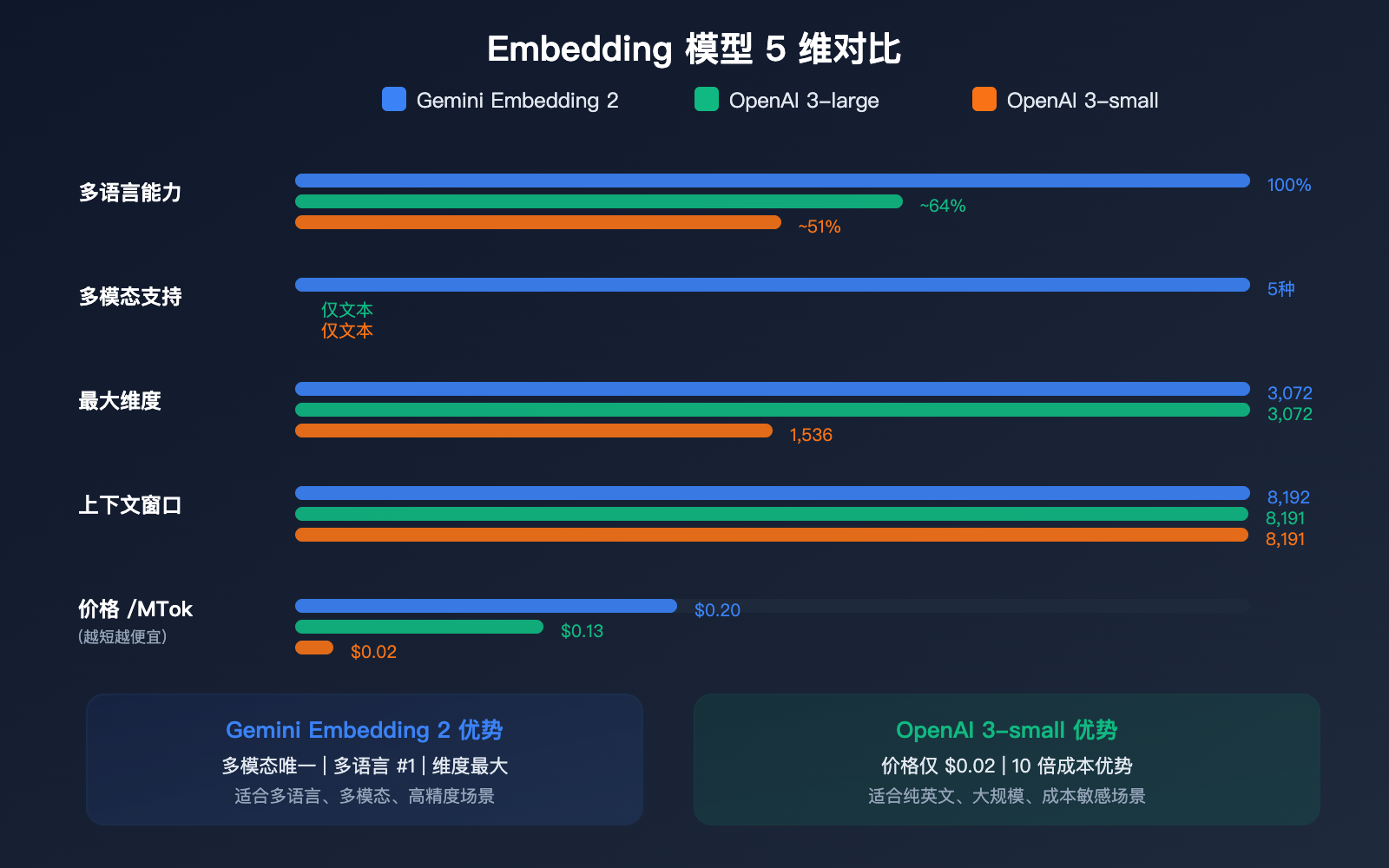
文本嵌入定价对比
| 模型 | 价格/百万 Token | 最大维度 | 最大输入 | 多模态 | 多语言排名 |
|---|---|---|---|---|---|
| Gemini Embedding 2 | $0.20 | 3,072 | 8,192 | ✅ 五模态 | #1 |
| gemini-embedding-001 | $0.15 | 3,072 | 2,048 | ❌ | — |
| OpenAI text-embedding-3-large | $0.13 | 3,072 | 8,191 | ❌ | — |
| OpenAI text-embedding-3-small | $0.02 | 1,536 | 8,191 | ❌ | — |
多模态内容定价(Gemini Embedding 2 独有):
| 输入类型 | 付费价格/百万 Token | 批量价格/百万 Token |
|---|---|---|
| 文本 | $0.20 | $0.10 |
| 图片 | $0.45 (~$0.00012/张) | $0.225 |
| 音频 | $6.50 (~$0.00016/秒) | $3.25 |
| 视频 | $12.00 (~$0.00079/帧) | $6.00 |
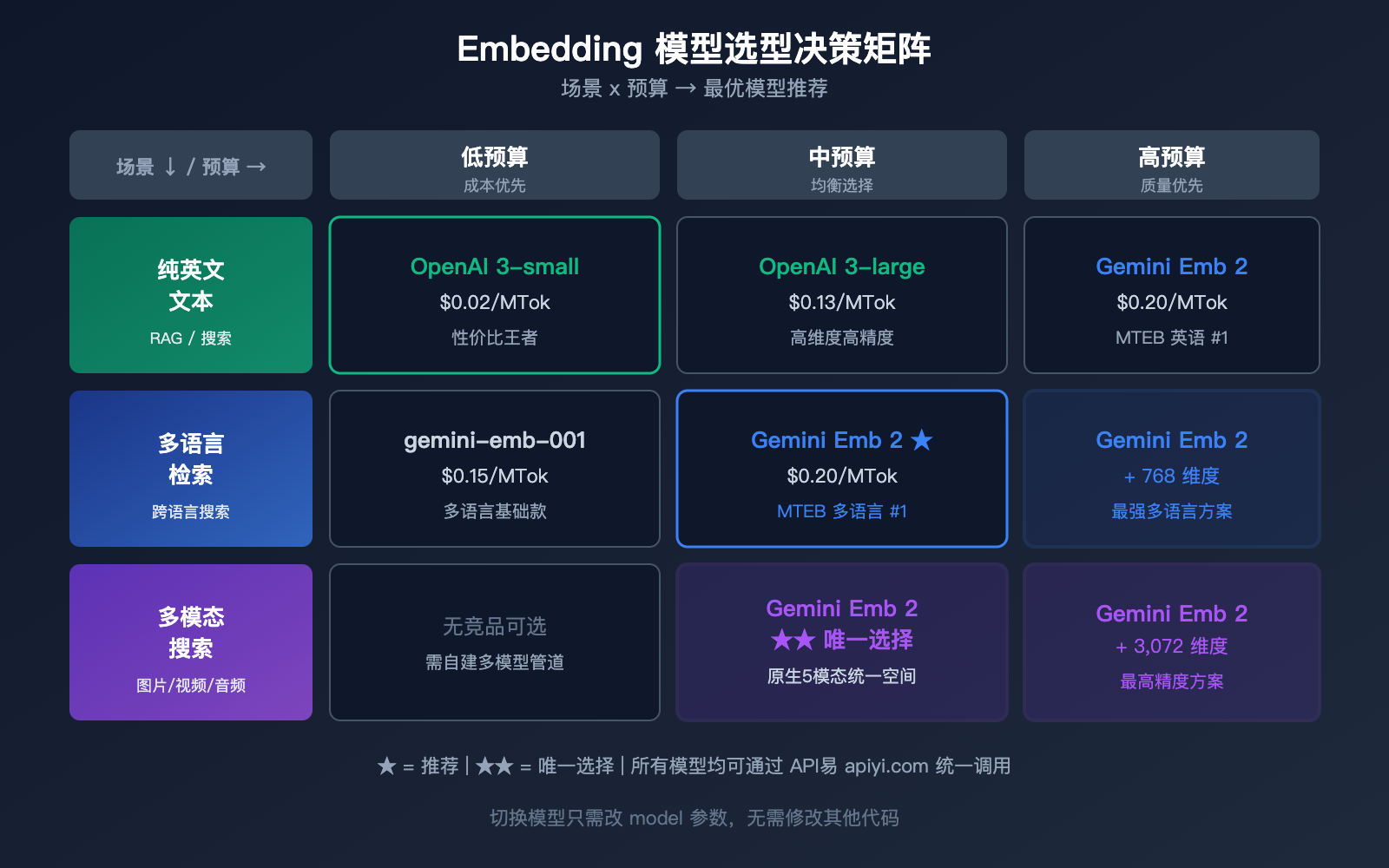
选型建议
| 需求场景 | 推荐模型 | 原因 |
|---|---|---|
| 纯文本、成本敏感 | OpenAI text-embedding-3-small | 最便宜 ($0.02) |
| 纯文本、高精度 | Gemini Embedding 2 或 OpenAI 3-large | 精度接近,Gemini 多语言更强 |
| 多模态搜索 | Gemini Embedding 2 | 唯一的原生多模态方案 |
| 多语言检索 | Gemini Embedding 2 | MTEB 多语言 #1 |
| 代码搜索 | Gemini Embedding 2 | MTEB 代码 #1 |
| 大规模低成本 | OpenAI 3-small + 批量 API | 10x 价格优势 |
🎯 选择建议: 选择哪个 embedding 模型取决于你的具体场景。
我们建议通过 API易 apiyi.com 平台同时接入 Gemini 和 OpenAI 的 embedding 模型,
用真实数据对比检索效果后再做决策。该平台支持统一接口调用,切换模型无需改代码。
API 调用方式详解
任务类型指定方式(重要变化)
与 gemini-embedding-001 不同,Gemini Embedding 2 不再使用 task_type 参数,而是通过在输入内容中嵌入任务指令来指定任务类型。
8 种支持的任务类型:
| 任务类型 | 查询端格式 | 文档端格式 |
|---|---|---|
| 搜索/检索 | task: search result | query: {内容} |
title: {标题} | text: {内容} |
| 问答 | task: question answering | query: {问题} |
title: {标题} | text: {内容} |
| 事实核查 | task: fact checking | query: {声明} |
title: {标题} | text: {内容} |
| 代码检索 | task: code retrieval | query: {描述} |
title: {标题} | text: {代码} |
| 分类 | task: classification | query: {内容} |
同格式 |
| 聚类 | task: clustering | query: {内容} |
同格式 |
| 句子相似度 | task: sentence similarity | query: {句子} |
同格式 |
对于文档端,如果没有标题,使用 title: none。
Python 调用示例
import openai
# 通过 API易 统一接口调用
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
# 文本嵌入 - 搜索场景
response = client.embeddings.create(
model="gemini-embedding-2-preview",
input="task: search result | query: 什么是向量数据库",
dimensions=768 # 可选维度:128-3072
)
embedding = response.data[0].embedding
print(f"向量维度: {len(embedding)}")
print(f"前5个值: {embedding[:5]}")
查看完整的 RAG 检索流程代码
import openai
import numpy as np
from typing import List
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
def get_embedding(text: str, task: str = "search result", dim: int = 768) -> List[float]:
"""获取文本嵌入向量"""
formatted = f"task: {task} | query: {text}"
response = client.embeddings.create(
model="gemini-embedding-2-preview",
input=formatted,
dimensions=dim
)
vec = response.data[0].embedding
# MRL 截断维度需要手动归一化
if dim < 3072:
norm = np.linalg.norm(vec)
vec = (np.array(vec) / norm).tolist()
return vec
def get_doc_embedding(title: str, text: str, dim: int = 768) -> List[float]:
"""获取文档嵌入向量"""
formatted = f"title: {title} | text: {text}"
response = client.embeddings.create(
model="gemini-embedding-2-preview",
input=formatted,
dimensions=dim
)
vec = response.data[0].embedding
if dim < 3072:
norm = np.linalg.norm(vec)
vec = (np.array(vec) / norm).tolist()
return vec
def cosine_similarity(a: List[float], b: List[float]) -> float:
"""计算余弦相似度"""
a, b = np.array(a), np.array(b)
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# 使用示例
query_vec = get_embedding("如何优化 RAG 检索效果")
doc_vec = get_doc_embedding(
"RAG 优化指南",
"本文介绍了 5 种优化 RAG 检索质量的方法..."
)
similarity = cosine_similarity(query_vec, doc_vec)
print(f"相似度: {similarity:.4f}")
🚀 快速开始: 推荐使用 API易 apiyi.com 平台快速接入 Gemini Embedding 2。
该平台提供 OpenAI 兼容的 embedding 接口,5 分钟即可完成集成,
同时支持 OpenAI、Gemini、Cohere 等主流 embedding 模型的统一调用。
使用注意事项
Preview 状态的限制
| 限制项 | 说明 | 影响 |
|---|---|---|
| 版本可能变更 | Preview 阶段规格和定价可能调整 | 生产环境建议做好降级方案 |
| 向量空间不兼容 | 不能与旧模型的向量混用 | 升级需要全量重新索引 |
| 低维度需归一化 | 使用 <3,072 维度时需手动归一化 | 代码中需增加归一化步骤 |
| 速率限制较严 | Preview 模型配额低于 GA 模型 | 大规模使用需申请提额 |
| 免费层数据使用 | 免费层的数据会被用于产品改进 | 敏感数据建议使用付费层 |
从旧模型迁移的注意事项
- 必须重建索引: 不同模型的向量空间不兼容,不能在同一个数据库中混用
- 任务类型格式变化: 从
task_type参数改为 Prompt 内嵌指令 - 归一化处理: 如果使用非默认维度,需要在代码中增加归一化逻辑
- 测试效果再迁移: 建议在测试环境中对比新旧模型的检索效果后再决定迁移
常见问题
Q1: Gemini Embedding 2 Preview 比 OpenAI text-embedding-3-large 好在哪?
主要优势在三个方面:原生多模态支持(OpenAI 只支持文本)、MTEB 多语言排名第 1(领先幅度大)、以及代码嵌入质量更高。但 OpenAI text-embedding-3-large 价格更低($0.13 vs $0.20),且如果你只需要英文文本嵌入,两者质量非常接近。通过 API易 apiyi.com 可以同时调用两个模型用真实数据对比。
Q2: 多模态嵌入到底有什么实际用途?
最直接的应用是跨模态搜索:用户输入文本,搜索返回相关的图片、视频或文档。比如电商场景中用"红色连衣裙"搜索商品图片,或者企业知识库中用文字描述搜索培训视频中的相关片段。传统做法需要先用视觉模型提取描述再嵌入文本,Gemini Embedding 2 直接处理原始图片/视频,信息损失更小。
Q3: 维度选多少合适?768 和 3072 差别大吗?
对于大多数应用,768 维是最佳平衡点——存储成本仅为 3072 维的 1/4,但检索质量损失极小(得益于 Matryoshka 训练)。如果你的数据集较小(<100 万条)且对精度要求极高,用 3072 维。如果数据量大或需要实时检索,768 维甚至 256 维都是合理选择。
Q4: API易 如何支持 Gemini Embedding 2?需要额外配置吗?
API易 apiyi.com 已支持 gemini-embedding-2-preview 模型,通过标准的 OpenAI 兼容 embedding 接口即可调用,无需额外配置 Google API Key。只需在 model 参数中指定 gemini-embedding-2-preview,其他参数(dimensions 等)与 OpenAI embedding 接口完全一致。
总结:多模态嵌入的新标杆
Gemini Embedding 2 Preview 代表了嵌入模型的一个重要里程碑——从纯文本走向真正的多模态统一空间。在 MTEB 多语言、英语、代码三个维度同时拿下第 1 名,加上 8K 上下文窗口和 MRL 维度伸缩,它为 RAG 系统、语义搜索和知识库构建提供了当前最强的基础能力。
关键要点回顾:
- 业界首个原生五模态嵌入模型(文本+图片+视频+音频+PDF)
- MTEB 多语言基准测试第 1 名,领先 5+ 分
- 8,192 Token 上下文窗口,4 倍于上代
- MRL 训练支持 128-3,072 灵活维度伸缩
- 价格 $0.20/百万 Token,多模态场景性价比极高
推荐通过 API易 apiyi.com 快速接入 Gemini Embedding 2 Preview,一个 Key 同时支持 Gemini、OpenAI 等主流 embedding 模型,便于对比和切换。
📝 本文作者: APIYI 技术团队 | API易 apiyi.com – 300+ AI 大模型 API 统一接入平台
参考资料
-
Google 官方博客: Gemini Embedding 2 发布公告
- 链接:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-embedding-2/ - 说明: 包含模型设计理念和多模态能力介绍
- 链接:
-
Gemini API 嵌入文档: 官方 API 使用指南
- 链接:
ai.google.dev/gemini-api/docs/embeddings - 说明: 完整的 API 参数和调用示例
- 链接:
-
Gemini Embedding 研究论文: 技术细节和基准测试
- 链接:
arxiv.org/html/2503.07891v1 - 说明: MTEB 详细测试数据和模型架构分析
- 链接:
-
Gemini API 定价: 各模态的详细定价信息
- 链接:
ai.google.dev/gemini-api/docs/pricing - 说明: 文本、图片、音频、视频的分项定价
- 链接: