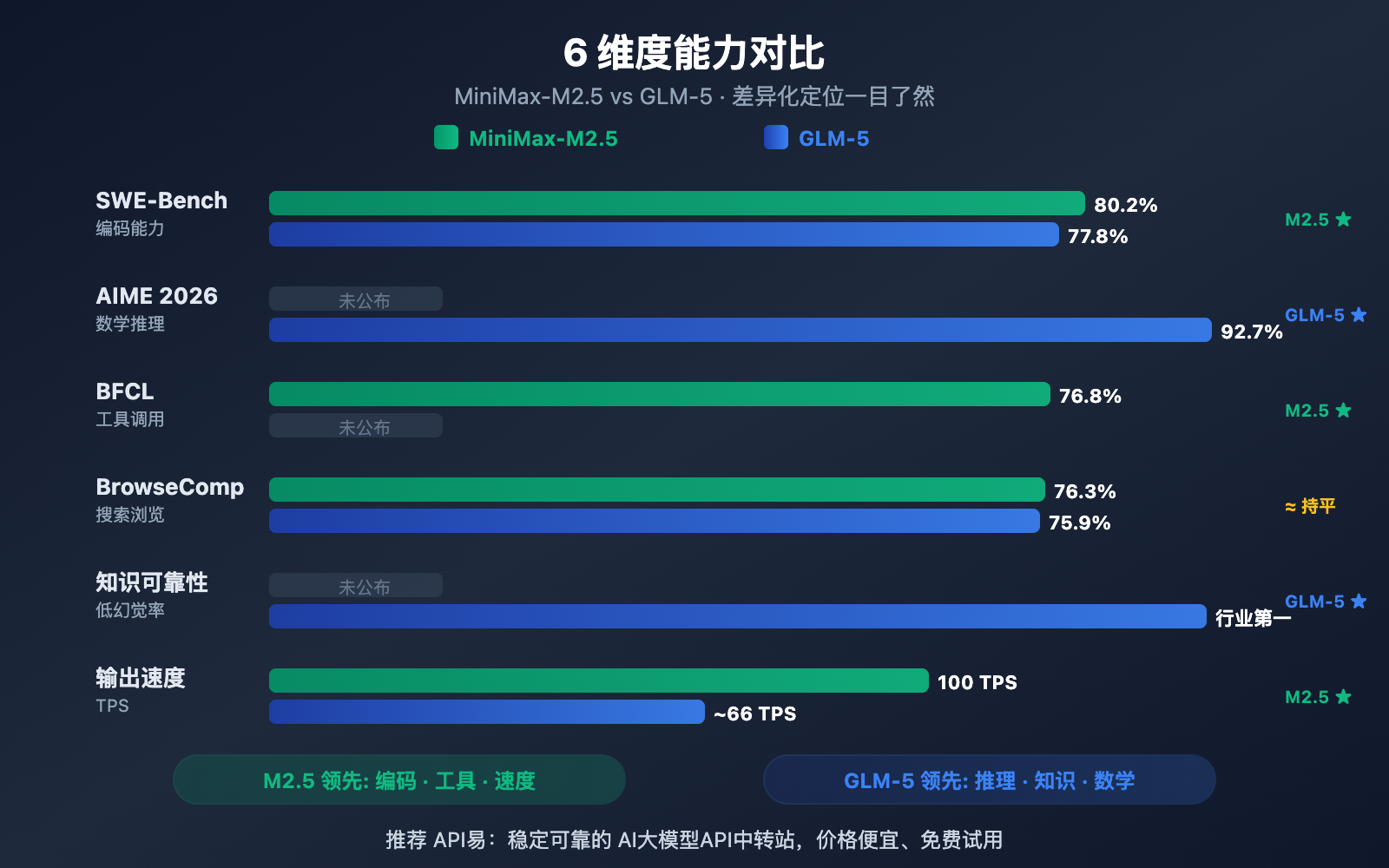
作者注:深度对比 2026 年 2 月同期发布的 MiniMax-M2.5 和 GLM-5 两大开源模型,从编码、推理、智能体、速度、价格和架构 6 个维度解析各自擅长领域
2026 年 2 月 11-12 日,两大中国 AI 公司几乎同时发布了各自的旗舰模型:智谱 GLM-5(744B 参数)和 MiniMax-M2.5(230B 参数)。两者都采用 MoE 架构、MIT 开源协议,但在能力侧重上形成了鲜明的差异化定位。
核心价值: 看完本文,你将清楚了解 GLM-5 擅长推理和知识可靠性,MiniMax-M2.5 擅长编码和智能体工具调用,从而在具体场景中做出最优选择。

MiniMax-M2.5 与 GLM-5 核心差异总览
| 对比维度 | MiniMax-M2.5 | GLM-5 | 优势方 |
|---|---|---|---|
| SWE-Bench 编码 | 80.2% | 77.8% | M2.5 领先 2.4% |
| AIME 数学推理 | — | 92.7% | GLM-5 擅长 |
| BFCL 工具调用 | 76.8% | — | M2.5 擅长 |
| BrowseComp 搜索 | 76.3% | 75.9% | 基本持平 |
| 输出价格/M tokens | $1.20 | $3.20 | M2.5 便宜 2.7 倍 |
| 输出速度 | 50-100 TPS | ~66 TPS | M2.5 Lightning 更快 |
| 总参数量 | 230B | 744B | GLM-5 更大 |
| 激活参数量 | 10B | 40B | M2.5 更轻量 |
MiniMax-M2.5 的核心优势:编码与智能体
MiniMax-M2.5 在编码基准测试上表现突出。SWE-Bench Verified 80.2% 的得分不仅领先 GLM-5 的 77.8%,更超越了 GPT-5.2 的 80.0%,仅落后 Claude Opus 4.6 的 80.8%。在多文件协作的 Multi-SWE-Bench 中得分 51.3%,在工具调用的 BFCL Multi-Turn 中更是达到了 76.8%。
M2.5 的 MoE 架构仅激活 10B 参数(总量 230B 的 4.3%),使其成为 Tier 1 模型中"最轻量"的选择,推理效率极高。Lightning 版本可达 100 TPS,是当前最快的前沿模型之一。
GLM-5 的核心优势:推理与知识可靠性
GLM-5 在推理和知识类任务上拥有显著优势。AIME 2026 数学推理得分 92.7%,GPQA-Diamond 科学推理 86.0%,Humanity's Last Exam(带工具)50.4 分领先于 Claude Opus 4.5 的 43.4 分。
GLM-5 最突出的能力是知识可靠性——在 AA-Omniscience 幻觉评测中取得行业领先水平,比前代提升了 35 分。对于需要高精度事实输出的场景,如技术文档撰写、学术研究辅助、知识库构建,GLM-5 是更可靠的选择。此外,GLM-5 的 744B 参数量和 28.5 万亿 Token 训练数据赋予了它更深厚的知识储备。
MiniMax-M2.5 对比 GLM-5 编码能力详细对比
编码能力是当前开发者选择 AI 模型时最关注的维度之一。两个模型在这方面差距明显。
| 编码基准 | MiniMax-M2.5 | GLM-5 | Claude Opus 4.6 (参考) |
|---|---|---|---|
| SWE-Bench Verified | 80.2% | 77.8% | 80.8% |
| Multi-SWE-Bench | 51.3% | — | 50.3% |
| SWE-Bench Multilingual | — | 73.3% | 77.5% |
| Terminal-Bench 2.0 | — | 56.2% | 65.4% |
| BFCL Multi-Turn | 76.8% | — | 63.3% |
MiniMax-M2.5 在 SWE-Bench Verified 上领先 GLM-5 达 2.4 个百分点(80.2% vs 77.8%)。这个差距在编码基准上已经属于显著差异——M2.5 的编码能力处于 Opus 4.6 级别,而 GLM-5 更接近 Gemini 3 Pro 级别。
GLM-5 在多语言编码(SWE-Bench Multilingual 73.3%)和终端环境编码(Terminal-Bench 56.2%)上有数据,展现了不同角度的编码能力。但在最核心的 SWE-Bench Verified 上,M2.5 的优势明确。
M2.5 在编码效率上也有突出表现:完成 SWE-Bench 单任务仅需 22.8 分钟,比前代 M2.1 提升 37%。这得益于其独特的 "Spec-writing" 编码风格——先进行架构分解,再高效实现,减少了无效的试错循环。
🎯 编码场景建议: 如果你的核心需求是 AI 辅助编码(Bug 修复、代码审查、功能实现),MiniMax-M2.5 是更优选择。通过 API易 apiyi.com 可以同时接入两个模型进行实际对比测试。
MiniMax-M2.5 对比 GLM-5 推理能力详细对比
推理能力是 GLM-5 的核心优势所在,尤其在数学和科学推理领域。
| 推理基准 | MiniMax-M2.5 | GLM-5 | 说明 |
|---|---|---|---|
| AIME 2026 | — | 92.7% | 奥林匹克级数学推理 |
| GPQA-Diamond | — | 86.0% | 博士级科学推理 |
| Humanity's Last Exam (w/tools) | — | 50.4 | 超越 Opus 4.5 的 43.4 |
| HMMT Nov. 2025 | — | 96.9% | 接近 GPT-5.2 的 97.1% |
| τ²-Bench | — | 89.7% | 电信领域推理 |
| AA-Omniscience 知识可靠性 | — | 行业领先 | 幻觉率最低 |
GLM-5 采用了名为 SLIME(异步强化学习基础设施)的新型训练方法,大幅提升了后训练效率。这使得 GLM-5 在推理任务上实现了质的飞跃:
- AIME 2026 得分 92.7%,接近 Claude Opus 4.5 的 93.3%,远超 GLM-4.5 时代的水平
- GPQA-Diamond 86.0% 的博士级科学推理能力,接近 Opus 4.5 的 87.0%
- Humanity's Last Exam 50.4 分(带工具),超越 Opus 4.5 的 43.4 分和 GPT-5.2 的 45.5 分
GLM-5 最独特的能力是知识可靠性。在 AA-Omniscience 幻觉评测中,GLM-5 比前代提升了 35 分,达到行业领先水平。这意味着 GLM-5 在回答事实性问题时更少"编造"内容,对于需要高精度信息输出的场景价值极大。
MiniMax-M2.5 在推理方面的数据较少公开,其核心强化学习训练集中在编码和智能体场景。M2.5 的 Forge RL 框架侧重于 20 万+真实环境中的任务分解和工具调用优化,而非纯推理能力。
对比说明: 如果你的核心需求是数学推理、科学分析或需要高可靠性的知识问答,GLM-5 更有优势。建议通过 API易 apiyi.com 平台实际测试两者在你的具体推理任务上的表现差异。
MiniMax-M2.5 对比 GLM-5 智能体与搜索能力

| 智能体基准 | MiniMax-M2.5 | GLM-5 | 优势方 |
|---|---|---|---|
| BFCL Multi-Turn | 76.8% | — | M2.5 工具调用领先 |
| BrowseComp (w/context) | 76.3% | 75.9% | 基本持平 |
| MCP Atlas | — | 67.8% | GLM-5 多工具协调 |
| Vending Bench 2 | — | $4,432 | GLM-5 长期规划 |
| τ²-Bench | — | 89.7% | GLM-5 领域推理 |
两个模型在智能体能力上呈现明显的差异化:
MiniMax-M2.5 擅长"执行型"智能体:在需要频繁调用工具、快速迭代、高效执行的场景中表现出色。BFCL 76.8% 意味着 M2.5 能够精准地进行函数调用、文件操作、API 交互等工具使用,且工具调用轮次比前代减少 20%。M2.5 在 MiniMax 内部已有 80% 的新代码由其生成,30% 的日常任务由其完成。
GLM-5 擅长"决策型"智能体:在需要深度推理、长期规划、复杂决策的场景中更有优势。MCP Atlas 67.8% 展现了大规模工具协调能力,Vending Bench 2 的 $4,432 模拟收入展现了长时间段业务规划能力,τ²-Bench 89.7% 展现了特定领域的深度推理。
两者在网页搜索浏览能力上几乎持平——BrowseComp 76.3% vs 75.9%,都是该领域的领先者。
🎯 智能体场景建议: 高频工具调用和自动编码选 M2.5;复杂决策和长期规划选 GLM-5。API易 apiyi.com 平台同时支持两个模型,可按场景灵活切换。
MiniMax-M2.5 对比 GLM-5 架构与成本对比
| 架构与成本 | MiniMax-M2.5 | GLM-5 |
|---|---|---|
| 总参数量 | 230B | 744B |
| 激活参数量 | 10B | 40B |
| 激活比例 | 4.3% | 5.4% |
| 训练数据 | — | 28.5 万亿 Token |
| 上下文窗口 | 205K | 200K |
| 最大输出 | — | 131K |
| 输入价格 | $0.15/M (标准版) | $1.00/M |
| 输出价格 | $1.20/M (标准版) | $3.20/M |
| 输出速度 | 50-100 TPS | ~66 TPS |
| 训练芯片 | — | 华为昇腾 910 |
| 训练框架 | Forge RL | SLIME 异步 RL |
| 注意力机制 | — | DeepSeek Sparse Attention |
| 开源协议 | MIT | MIT |
MiniMax-M2.5 架构优势分析
M2.5 的核心架构优势在于"极致轻量"——仅激活 10B 参数就实现了接近 Opus 4.6 的编码能力。这使得:
- 推理成本极低: 输出价格 $1.20/M,仅为 GLM-5 的 37%
- 推理速度极快: Lightning 版本 100 TPS,比 GLM-5 的 ~66 TPS 快 52%
- 部署门槛更低: 10B 激活参数在消费级 GPU 上也有部署可能性
GLM-5 架构优势分析
GLM-5 的 744B 总参数和 40B 激活参数赋予了它更强的知识容量和推理深度:
- 更大的知识储备: 28.5 万亿 Token 训练数据,远超前代
- 更深的推理能力: 40B 激活参数支持更复杂的推理链
- 国产算力自主: 全程使用华为昇腾芯片训练,实现算力独立
- DeepSeek Sparse Attention: 高效处理 200K 长上下文
建议: 对于成本敏感的高频调用场景,M2.5 的价格优势明显(输出价格仅为 GLM-5 的 37%)。建议通过 API易 apiyi.com 平台实际测试两者在你的任务上的性价比。
MiniMax-M2.5 对比 GLM-5 API 快速接入
通过 API易平台可以统一接口同时调用两个模型,方便快速对比:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# 编码任务测试 - M2.5 更擅长
code_task = "用 Rust 实现一个无锁并发队列"
m25_result = client.chat.completions.create(
model="MiniMax-M2.5",
messages=[{"role": "user", "content": code_task}]
)
# 推理任务测试 - GLM-5 更擅长
reason_task = "证明所有大于 2 的偶数都可以表示为两个素数之和(哥德巴赫猜想的验证思路)"
glm5_result = client.chat.completions.create(
model="glm-5",
messages=[{"role": "user", "content": reason_task}]
)
建议: 通过 API易 apiyi.com 获取免费测试额度,针对你的具体场景分别测试两个模型。编码任务试 M2.5,推理任务试 GLM-5,找到最适合你的方案。
常见问题
Q1: MiniMax-M2.5 和 GLM-5 各自最擅长什么?
MiniMax-M2.5 擅长编码和智能体工具调用——SWE-Bench 80.2% 接近 Opus 4.6,BFCL 76.8% 行业第一。GLM-5 擅长推理和知识可靠性——AIME 92.7%、GPQA 86.0%、幻觉率行业最低。简单记:写代码选 M2.5,做推理选 GLM-5。
Q2: 两个模型价格差多少?
MiniMax-M2.5 标准版输出价格 $1.20/M tokens,GLM-5 输出价格 $3.20/M tokens,M2.5 便宜约 2.7 倍。如果选 M2.5 Lightning 高速版($2.40/M),则与 GLM-5 价格接近但速度更快。通过 API易 apiyi.com 平台接入还可享受充值优惠。
Q3: 如何快速对比两个模型的实际效果?
推荐通过 API易 apiyi.com 平台统一接入:
- 注册账号获取 API Key 和免费额度
- 准备 2 类测试任务:编码类和推理类
- 同一任务分别调用 MiniMax-M2.5 和 GLM-5
- 对比输出质量、响应速度和 Token 消耗
- 统一 OpenAI 兼容接口,切换模型只需改 model 参数
总结
MiniMax-M2.5 对比 GLM-5 的核心结论:
- 编码首选 M2.5: SWE-Bench 80.2% vs 77.8%,M2.5 领先 2.4%,BFCL 工具调用 76.8% 行业第一
- 推理首选 GLM-5: AIME 92.7%、GPQA 86.0%、Humanity's Last Exam 50.4 分超越 Opus 4.5
- 知识可靠性 GLM-5 领先: AA-Omniscience 幻觉评测行业第一,事实性输出更可信
- 性价比 M2.5 更优: 输出价格仅为 GLM-5 的 37%,Lightning 版本速度更快
两个模型都是 MIT 开源、MoE 架构,但定位截然不同:M2.5 是"编码和执行型智能体之王",GLM-5 是"推理和知识可靠性先锋"。建议根据实际需求在 API易 apiyi.com 平台上灵活切换使用,参与充值活动享受更优惠的价格。
📚 参考资料
-
MiniMax M2.5 官方公告: M2.5 核心编码能力和 Forge RL 训练细节
- 链接:
minimax.io/news/minimax-m25 - 说明: SWE-Bench 80.2%、BFCL 76.8% 等完整基准数据
- 链接:
-
GLM-5 官方发布: 智谱 GLM-5 的 744B MoE 架构和 SLIME 训练技术
- 链接:
docs.z.ai/guides/llm/glm-5 - 说明: 包含 AIME 92.7%、GPQA 86.0% 等推理基准数据
- 链接:
-
Artificial Analysis 独立评测: 两个模型的标准化基准测试和排名
- 链接:
artificialanalysis.ai/models/glm-5 - 说明: Intelligence Index、速度实测、价格对比等独立数据
- 链接:
-
BuildFastWithAI 深度分析: GLM-5 全面基准测试和竞品对比
- 链接:
buildfastwithai.com/blogs/glm-5-released-open-source-model-2026 - 说明: 与 Opus 4.5、GPT-5.2 的详细对比表格
- 链接:
-
MiniMax HuggingFace: M2.5 开源模型权重
- 链接:
huggingface.co/MiniMaxAI - 说明: MIT 协议,支持 vLLM/SGLang 部署
- 链接:
作者: APIYI Team
技术交流: 欢迎在评论区分享你的模型对比测试结果,更多 AI 模型 API 接入教程可访问 API易 apiyi.com 技术社区