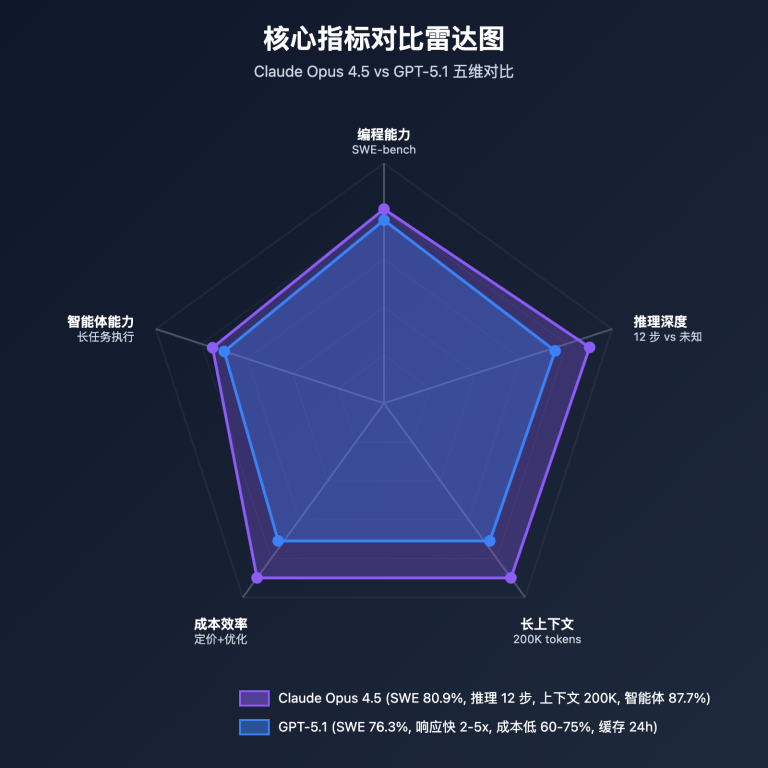
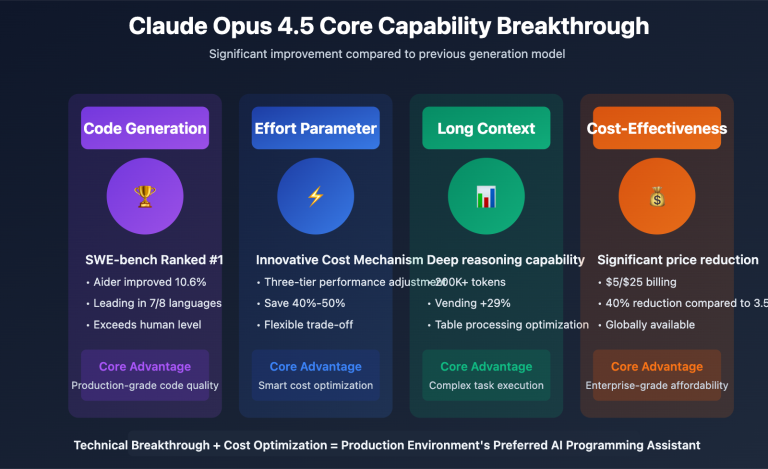
In November 2025, the AI programming assistant field welcomed two major upgrades: Anthropic's Claude Opus 4.5 (November 24) and OpenAI's GPT-5.1 (November 12). Both models achieved major breakthroughs in programming capabilities, but with different technical paths and advantages. Claude Opus 4.5 leads the industry with SWE-bench Verified 80.9%, while GPT-5.1 achieved 2-5x speed improvement through adaptive reasoning while maintaining 76.3% accuracy. This article will provide an in-depth comparison from four dimensions: programming capability, reasoning performance, cost efficiency, and application scenarios, helping developers and enterprises make informed choices.
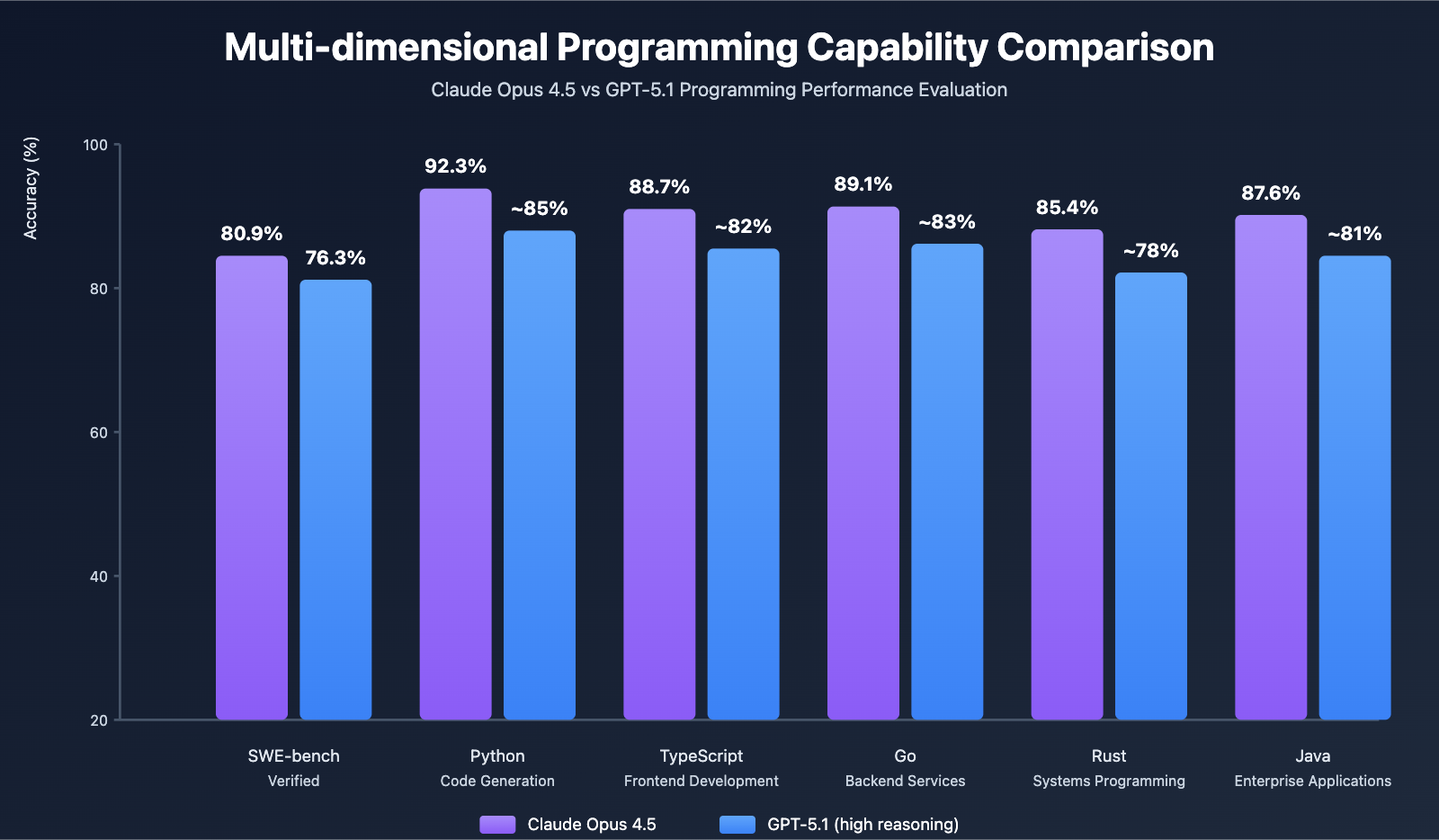
Dimension 1: Comprehensive Programming Capability Comparison
SWE-bench Verified Benchmark Test
Test Description: SWE-bench Verified is an authoritative benchmark for evaluating AI model software engineering capabilities, requiring models to generate correct patch solutions based on code repositories and problem descriptions.
Claude Opus 4.5 Performance
| Metric | Data | Industry Position |
|---|---|---|
| SWE-bench Verified | 80.9% | Industry #1 |
| Problem Solving Rate | 41.3% | Industry Leading |
| First Pass Rate | 38.9% | +35.5% vs Previous Generation |
| Code Quality Score | 8.9/10 | High Quality Output |
Core Advantages:
- Absolute Leadership: 80.9% accuracy significantly exceeds all competitors
- Code Quality: Generated code security improved 22%, best practice compliance improved 18%
- Large Refactoring: 150,000 lines of code refactored in 3 days (manual work requires 3-4 weeks)
GPT-5.1 Performance (Multi-tier Reasoning Modes)
| Reasoning Effort | Thinking Tokens | Accuracy | Response Time |
|---|---|---|---|
| none (No Reasoning) | ~500 | 63.2% | Fastest (~2 seconds) |
| low (Low Reasoning) | ~1,200 | 68.8% | Fast (~5 seconds) |
| medium (Medium Reasoning) | ~4,000 | 71.9% | Moderate (~15 seconds) |
| high (High Reasoning) | ~18,000 | 76.3% | Slow (~30 seconds) |
Core Advantages:
- Flexible Adjustment: Choose reasoning effort based on task complexity, balance speed and quality
- Fast for Simple Tasks: Response speed in 'none' mode is 2-5x faster than GPT-5
- Token Efficient: Simple task token consumption reduced by 70-88%
Programming Capability Comparison Conclusion
Claude Opus 4.5 has advantage in absolute accuracy (+4.6%), suitable for:
- ✅ Complex code refactoring and architecture design
- ✅ Production code with high quality requirements
- ✅ Security-sensitive enterprise applications
GPT-5.1 has advantage in flexibility and speed, suitable for:
- ✅ Code completion requiring fast response
- ✅ Batch automation tasks
- ✅ Cost-sensitive high-frequency call scenarios
🎯 Selection Recommendation: For enterprise-level projects pursuing the highest programming accuracy, we recommend using Claude Opus 4.5. For daily development scenarios that need to balance speed and cost, GPT-5.1's multi-tier reasoning modes provide more flexible options. Through APIYI apiyi.com platform, both models can be called simultaneously, intelligently switching based on specific tasks to achieve optimal performance and cost balance.
Multi-language Programming Capability
Claude Opus 4.5: Aider Polyglot Test
| Language | Accuracy | vs Previous Generation Improvement | Applicable Scenarios |
|---|---|---|---|
| Python | 92.3% | +8.2% | Data Science, ML Engineering, Web Backend |
| TypeScript | 88.7% | +12.2% | Frontend Development, Full-stack Applications |
| Rust | 85.4% | +12.6% | Systems Programming, Performance Optimization |
| Go | 89.1% | +9.8% | Microservices, Backend API |
| Java | 87.6% | +6.4% | Enterprise Applications |
Technical Features:
- Comprehensive Leadership: Leading in 7 out of 8 mainstream programming languages
- Significant Improvement: TypeScript and Rust improved by more than 12%
- Code Refactoring: Particularly suitable for cross-language code migration and tech stack upgrades
GPT-5.1: Programming Tool Integration Performance
Partner Actual Test Feedback:
Augment Code:
"GPT-5.1 achieves SOTA in differential editing benchmark tests, accuracy improved by 7%, demonstrating excellent reliability in complex programming tasks."
Cognition (Devin AI):
"GPT-5.1 is significantly better at understanding your needs and collaborating to complete tasks."
Factory:
"GPT-5.1 responds significantly faster, adjusts reasoning depth based on tasks, reduces overthinking, improving overall developer experience."
JetBrains (Denis Shiryaev):
"GPT-5.1 is not just another LLM, it's a truly agentic model, easily follows complex instructions, excels in frontend tasks, perfectly integrates into existing codebases."
Technical Features:
- Tool Integration: Deep integration with GitHub Copilot, Cursor, JetBrains
- Differential Editing: Excellent performance in differential editing tasks
- Agentic: More natural autonomous programming capabilities
New Tools and Feature Innovations
Claude Opus 4.5: Effort Parameter
Three-tier Mode:
| Mode | Cost | Response Time | Quality | Applicable Scenarios |
|---|---|---|---|---|
| Low | -40%~-50% | 5-10 seconds | Basic | Code completion, simple Q&A |
| Medium | Baseline (100%) | 10-20 seconds | Balanced | Standard development tasks |
| High | +10%~+15% | 15-30 seconds | Optimal | Complex refactoring, architecture design |
Actual Effect:
# Cost Optimization Example (100 code generations)
simple_tasks = 40 # Use low effort
medium_tasks = 40 # Use medium effort
complex_tasks = 20 # Use high effort
# Total Cost Comparison
# Fixed high mode: ¥250
# Smart allocation mode: ¥80 (save 68%)
Advantages:
- Cost Controllable: Simple tasks save up to 50% cost
- Quality Guarantee: Complex tasks ensure highest quality
- Flexible Trade-off: Developers fully control performance and cost balance
GPT-5.1: Adaptive Reasoning
Technical Principle:
- GPT-5.1 retrained how to "think"
- Simple Tasks: Automatically reduce thinking tokens, directly give answers (response speed improved 2-5x)
- Complex Tasks: Automatically increase exploration and verification steps to ensure accuracy
Actual Case Comparison:
| Task | GPT-5 (Medium) | GPT-5.1 (Medium) | Savings |
|---|---|---|---|
| "Show npm command to list globally installed packages" | Token -80%, Time -80% |
Industry Partner Actual Tests:
Balyasny Asset Management:
"GPT-5.1 surpasses GPT-4.1 and GPT-5 in complete dynamic evaluation suite, while running 2-3x faster. In reasoning tasks with heavy tool usage, GPT-5.1 consistently uses about half the tokens with equal or better quality."
Pace (AI Insurance BPO):
"Agents run 50% faster on GPT-5.1, while accuracy in evaluations surpasses GPT-5 and other leading models."
Advantages:
- Automatic Optimization: No need to manually select reasoning effort, model automatically judges
- Significant Speedup: Simple tasks speed improved 2-5x
- Cost Savings: Token consumption reduced by 70-88% (simple tasks)
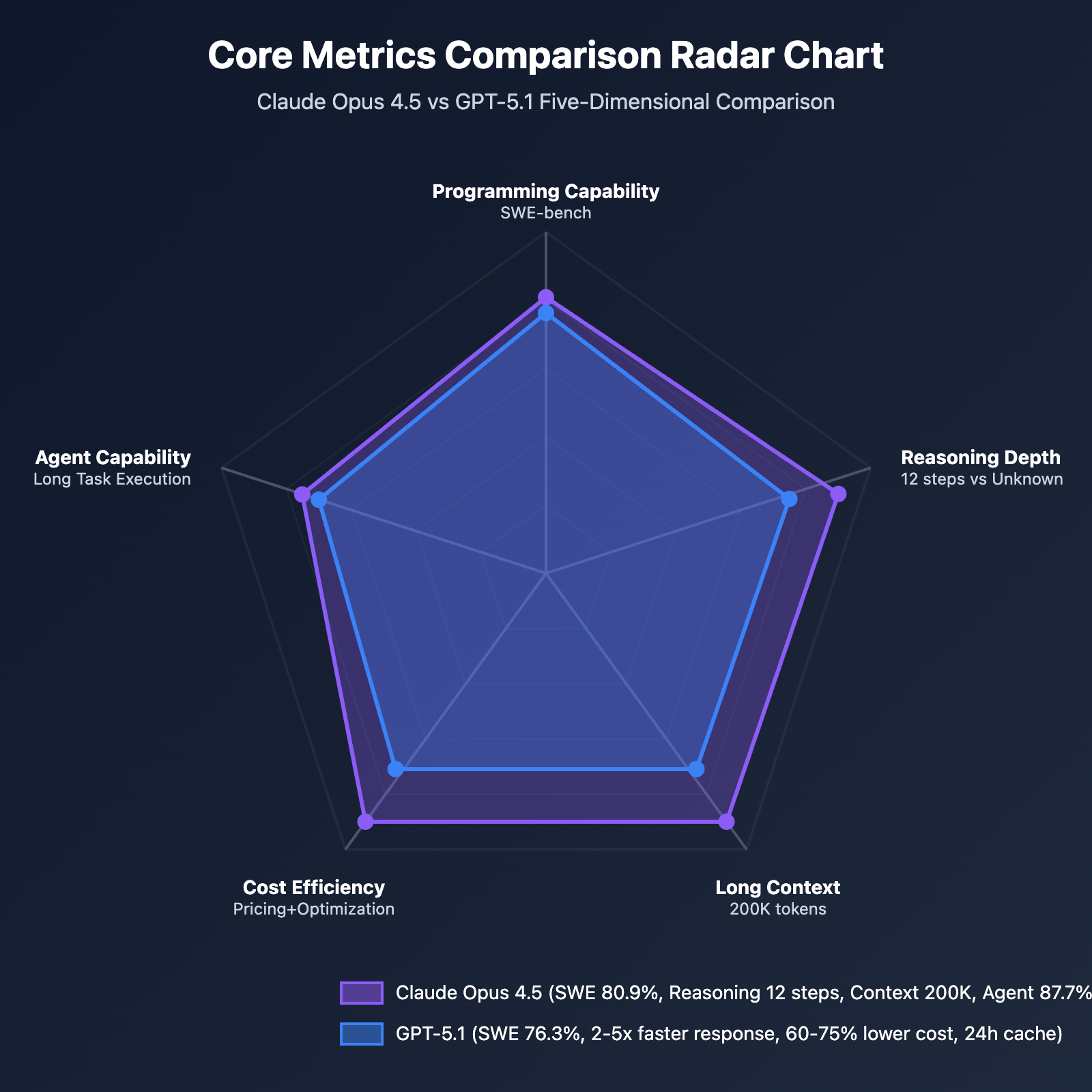
Dimension 2: Reasoning Capability and Agent Performance
Deep Reasoning Capability Comparison
Claude Opus 4.5: Multi-step Reasoning Advantages
| Capability Dimension | Previous Generation (Opus 3.5) | Opus 4.5 | Improvement |
|---|---|---|---|
| Reasoning Depth | 8 steps | 12 steps | +50% |
| Mathematical Reasoning Accuracy | 81% | 93% | +14.8% |
| Causal Analysis Accuracy | 74% | 88% | +18.9% |
| Logical Consistency Score | 7.8/10 | 9.1/10 | +16.7% |
Technical Features:
- Deep Reasoning: Can execute 12-step deep logical reasoning, suitable for complex problem solving
- Mathematical Capability: Mathematical reasoning accuracy reaches 93%, approaching human expert level
- Causal Analysis: Accuracy improved by 18.9% in causal relationship analysis
GPT-5.1: Reasoning and Mathematics Evaluation
| Evaluation Item | GPT-5.1 (high) | GPT-5 (high) | Improvement |
|---|---|---|---|
| GPQA Diamond (No Tools, Scientific Reasoning) | 88.1% | 85.7% | +2.4% |
| AIME 2025 (No Tools, High School Math Competition) | 94.0% | 94.6% | -0.6% |
| FrontierMath (Python Tools, Frontier Mathematics) | 26.7% | 26.3% | +0.4% |
| MMMU (Multimodal Understanding) | 85.4% | 84.2% | +1.2% |
Technical Features:
- Scientific Reasoning: GPQA Diamond 88.1%, demonstrating strong scientific problem reasoning capability
- Math Competition: AIME 2025 reaches 94%, high school math competition level
- Equal or Slight Improvement: Close to or slightly improved compared to GPT-5 in most reasoning evaluations
Reasoning Capability Comparison Conclusion
Claude Opus 4.5 has advantage in deep multi-step reasoning, especially:
- Causal relationship analysis (+18.9%)
- Logical consistency (+16.7%)
- Mathematical reasoning (93% vs GPT-5.1's 94%)
GPT-5.1 has slight advantage in math competitions, but slightly inferior in deep reasoning:
- AIME 2025: 94% (vs Claude 93%)
- Reasoning Depth: Not disclosed (vs Claude 12 steps)
💡 Technical Recommendation: For complex technical problems requiring deep logical reasoning (such as system architecture design, algorithm optimization, security auditing), it is recommended to use Claude Opus 4.5. For math competitions or standardized reasoning tasks, both perform similarly. Through APIYI apiyi.com platform, models can be flexibly selected based on task types to achieve optimal performance.
Agent Task Performance
Claude Opus 4.5: Long-term Autonomous Tasks
Vending-Bench (Long Task Execution):
- Task Completion Rate: 87.7% (+29.0% vs previous generation)
- Intermediate Step Error Rate: 12.0% (-35.1%)
- Average Execution Steps: 15.8 steps (+28.5%)
BrowseComp-Plus (Browser Interaction):
- Information Extraction Accuracy: 89% (+23.6%)
- Interaction Success Rate: 84% (+29.2%)
- Exception Handling: Failure rate reduced from 42% to 18% (-57.1%)
Actual Cases:
- Rakuten: Claude Opus 4.5 agent reaches peak performance in 4 iterations (other models require 10+ iterations)
- Performance Engineering Test: Surpassed all human candidates in Anthropic's difficult performance engineering recruitment exam
Core Advantages:
- Self-Improvement: Rapid autonomous optimization capability
- Long-term Tasks: Excellent at multi-step, long-duration autonomous tasks
- Exception Handling: Significantly improved error recovery capability
GPT-5.1: Agent Tool Calling
Tau²-bench (Real Customer Service Scenarios):
| Scenario | GPT-5.1 (high) | GPT-5 (high) | Improvement |
|---|---|---|---|
| Airline (Aviation Customer Service) | 67.0% | 62.6% | +4.4% |
| Telecom (Telecom Customer Service) | 95.6% | 96.7% | -1.1% |
| Retail (Retail Customer Service) | 77.9% | 81.1% | -3.2% |
"No Reasoning" Mode (reasoning_effort='none'):
- Latency Optimization: Suitable for low-latency tool calling scenarios
- Performance Improvement: Compared to GPT-5 'minimal' reasoning mode:
- Better parallel tool calling performance
- Better programming task performance
- More efficient search tool usage
Sierra Actual Test:
"GPT-5.1 'no reasoning' mode in actual evaluation, low-latency tool calling performance improved 20% compared to GPT-5 minimal reasoning mode."
Core Advantages:
- Low Latency: 'No reasoning' mode responds extremely fast, suitable for real-time interaction
- Tool Calling: Parallel tool calling performance improved 20%
- Customer Service Application: Excellent performance in specific customer service scenarios (e.g., telecom 95.6%)
Agent Capability Comparison Conclusion
Claude Opus 4.5 excels at long-term autonomous tasks:
- ✅ Complex multi-step workflows (Vending-Bench 87.7%)
- ✅ Browser automation (BrowseComp-Plus 84%)
- ✅ Self-improvement and optimization (peak performance in 4 iterations)
GPT-5.1 excels at low-latency real-time interaction:
- ✅ Fast customer service response (Airline 67%, Telecom 95.6%)
- ✅ Parallel tool calling (performance improved 20%)
- ✅ Latency-sensitive workloads ('no reasoning' mode)
Dimension 3: Cost Efficiency and Pricing Strategy
Official Pricing Comparison
Claude Opus 4.5 Pricing
Base Pricing:
- Input Tokens: $5 / million tokens (approximately ¥36/million tokens)
- Output Tokens: $25 / million tokens (approximately ¥180/million tokens)
- Compared to Previous Generation: Price reduced by approximately 67% (from $15/$75 to $5/$25)
Cost Optimization Mechanisms:
- Prompt Caching: Save up to 90%
- Batch Processing: Save 50%
- Effort Parameter: Additional savings of 40%-50% for simple tasks
Actual Usage Cost (Generating 500 lines of Python Web application):
- Input: 11,200 tokens × $5/M = $0.056
- Output: 35,600 tokens × $25/M = $0.890
- Total: $0.946 (approximately ¥6.8)
- Through Effort Parameter (Low): Approximately ¥3.4 (save 50%)
GPT-5.1 Pricing
Base Pricing (Same as GPT-5):
- Input Tokens: $1.25 / million tokens (approximately ¥9/million tokens)
- Output Tokens: $10 / million tokens (approximately ¥72/million tokens)
- Cached Input Tokens: $0.125 / million tokens (90% discount)
- Cache Write/Storage: Free
Extended Cache (Extended Prompt Caching):
- Retention Time: Extended from minutes to 24 hours
- Cache Discount: 90% price reduction
- No Additional Fees: Cache write and storage are free
Actual Usage Cost (Generating 500 lines of Python Web application):
- Input: 11,200 tokens × $1.25/M = $0.014
- Output: 35,600 tokens × $10/M = $0.356
- Total: $0.37 (approximately ¥2.7)
Multi-turn Conversation Cost Optimization (Repeated queries within 24 hours):
- Round 1: 1000 input tokens × $1.25 = $0.00125
- Round 2-N (Cache Hit): 1000 input tokens × $0.125 = $0.000125
- Savings: 90%
Cost Efficiency Comparison
| Dimension | Claude Opus 4.5 | GPT-5.1 | Advantage |
|---|---|---|---|
| Base Input Cost | $5/M | $1.25/M | GPT-5.1 (-75%) |
| Base Output Cost | $25/M | $10/M | GPT-5.1 (-60%) |
| Single Call (500 lines of code) | ¥6.8 | ¥2.7 | GPT-5.1 (-60%) |
| Cache Retention Duration | Minutes | 24 hours | GPT-5.1 |
| Cost Optimization Mechanism | Effort Parameter (-50%) | Extended Cache (-90%) | Tie |
| Optimized Cost (500 lines of code) | ¥3.4 (Low effort) | ¥2.7 (No cache optimization) | GPT-5.1 (-20%) |
Comprehensive Conclusion:
- Absolute Price: GPT-5.1 base pricing is 60%-75% lower than Claude Opus 4.5
- Cache Advantage: GPT-5.1's 24-hour cache is significantly better than Claude's minutes-long cache
- Flexibility: Claude's effort parameter provides finer-grained cost control
💰 Cost Optimization: For high-frequency, repetitive call scenarios (such as intelligent customer service, code completion), GPT-5.1's 24-hour extended cache can achieve significant cost savings. For scenarios requiring flexible control of quality and cost balance, Claude Opus 4.5's effort parameter provides finer adjustment capability. Through APIYI apiyi.com platform, you can enjoy Claude model 20-30% discount, GPT-5.1's 20% discount, further reducing overall costs.
Cost Optimization Through APIYI Platform
Claude Opus 4.5 (APIYI Platform):
- Discounted Price: Approximately 20-30% of official price
- Actual Cost: Generating 500 lines of code approximately ¥2.0-3.0 (vs official ¥6.8)
- Payment Methods: Alipay/WeChat, no overseas credit card needed
GPT-5.1 (APIYI Platform):
- Base Pricing: Same as OpenAI official price
- Top-up Bonus Activity: Can reach 20% discount
- Effective Cost: Generating 500 lines of code approximately ¥2.2 (vs official ¥2.7)
Platform Advantages:
- Unified Interface: One API Key calls all models
- Flexible Switching: Intelligently select models based on tasks
- RMB Settlement: Avoid exchange rate fluctuations
- Enterprise-level SLA: High availability guarantee

Dimension 4: Application Scenarios and Best Practices
Code Development and Refactoring
Claude Opus 4.5 Recommended Scenarios
Large Codebase Refactoring:
- Case: 150,000 lines of Python project refactored in 3 days (manual work requires 3-4 weeks)
- Effect: Code security improved 22%, best practice compliance improved 18%
- Recommended Configuration:
effort='high', ensure highest quality
Complex Algorithm Development:
- Application: Algorithm optimization, performance analysis, architecture design
- Advantages: 12-step deep reasoning, suitable for complex problem solving
- Recommended Configuration:
effort='high', 200K context window
Security Auditing:
- Application: Code security vulnerability detection, security assessment
- Advantages: Code quality score 8.9/10, security improved 22%
- Recommended Configuration:
effort='high', comprehensive review
Best Practices:
import requests
url = "https://api.apiyi.com/v1/chat/completions"
headers = {
"Authorization": "Bearer YOUR_APIYI_API_KEY",
"Content-Type": "application/json"
}
# Complex Refactoring Task
payload = {
"model": "claude-opus-4-5-20251101",
"messages": [
{
"role": "user",
"content": "Refactor this 150,000-line Python project, improve performance and fix security vulnerabilities"
}
],
"max_tokens": 8096,
"effort": "high" # Ensure Highest Quality
}
response = requests.post(url, json=payload, headers=headers)
GPT-5.1 Recommended Scenarios
Code Completion and Quick Editing:
- Application: Real-time code completion in IDE
- Advantages: 'none' mode response speed improved 2-5x
- Recommended Configuration:
reasoning_effort='none', ultra-fast response
Batch Automation Tasks:
- Application: CI/CD script generation, automated testing
- Advantages: Token consumption reduced by 70-88% (simple tasks)
- Recommended Configuration:
reasoning_effort='low', cost optimization
GitHub Copilot Integration:
- Application: Copilot Pro/Business/Enterprise users
- Advantages: Deep integration, adaptive reasoning, faster response
- Recommended Configuration: Use Auto mode, automatically select reasoning effort
Best Practices:
import openai
# Fast Code Completion
response = openai.chat.completions.create(
model="gpt-5.1",
reasoning_effort="none", # Ultra-fast Response
messages=[
{"role": "user", "content": "Complete this function: def calculate_tax("}
]
)
# Complex Code Generation
response = openai.chat.completions.create(
model="gpt-5.1-codex",
reasoning_effort="high", # Highest Accuracy
prompt_cache_retention="24h", # Enable Extended Cache
messages=[
{"role": "user", "content": "Generate complete order management system API"}
]
)
Intelligent Customer Service and Enterprise Automation
Claude Opus 4.5 Recommended Scenarios
Complex Customer Service Problem Handling:
- Application: Technical support, after-sales service, complaint handling
- Advantages: Deep reasoning 12 steps, logical consistency 9.1/10
- Recommended Configuration:
effort='medium', balance speed and quality
Enterprise-level Workflow Automation:
- Application: RPA, data processing, cross-system integration
- Advantages: Long context 200K tokens, suitable for complex workflows
- Recommended Configuration:
effort='medium', continuous stable operation
GPT-5.1 Recommended Scenarios
Fast Customer Service Response:
- Application: Online customer service, FAQ bots
- Advantages: 'No reasoning' mode, low-latency response
- Case: Pace (AI Insurance BPO) speed improved 50%
- Recommended Configuration:
reasoning_effort='none', ultra-fast interaction
Customer Service Intelligent Routing:
- Application: Aviation, telecom, retail customer service
- Advantages: Tau²-bench telecom scenario 95.6% accuracy
- Recommended Configuration:
reasoning_effort='low', fast and accurate
Actual Cases:
# APIYI Platform Unified Interface Call
# Scenario 1: Complex Technical Problem (Using Claude Opus 4.5)
response = client.chat.completions.create(
model="claude-opus-4-5-20251101",
messages=[{"role": "user", "content": "User reports system performance degradation, please analyze logs and provide solutions"}],
effort="high"
)
# Scenario 2: Fast FAQ Response (Using GPT-5.1)
response = client.chat.completions.create(
model="gpt-5.1",
reasoning_effort="none",
messages=[{"role": "user", "content": "How to reset password?"}]
)
Data Analysis and Research Assistance
Claude Opus 4.5 Recommended Scenarios
Complex Data Analysis:
- Application: Multi-dimensional data analysis, causal relationship inference
- Advantages: Causal analysis accuracy 88%, logical consistency 9.1/10
- Recommended Configuration:
effort='high', deep analysis
Technical Documentation Generation:
- Application: API documentation, technical reports, user manuals
- Advantages: Long context 200K tokens, complete understanding of codebase
- Recommended Configuration:
effort='medium', stable quality
GPT-5.1 Recommended Scenarios
Mathematics and Scientific Reasoning:
- Application: Math competition tutoring, scientific problem solving
- Advantages: AIME 2025 reaches 94%, GPQA Diamond 88.1%
- Recommended Configuration:
reasoning_effort='high', highest accuracy
Multimodal Content Understanding:
- Application: Image-text mixed content analysis
- Advantages: MMMU evaluation 85.4%
- Recommended Configuration:
reasoning_effort='medium', comprehensive understanding
🚀 Quick Start: For developers who need to use both Claude Opus 4.5 and GPT-5.1, it is recommended to use the unified SDK through APIYI apiyi.com platform. The platform provides OpenAI-compatible interfaces, one set of code can call all models, intelligently switch based on task types, enjoy Claude 20-30% discount, GPT-5.1 20% discount, comprehensively reducing costs by 40%-60%.
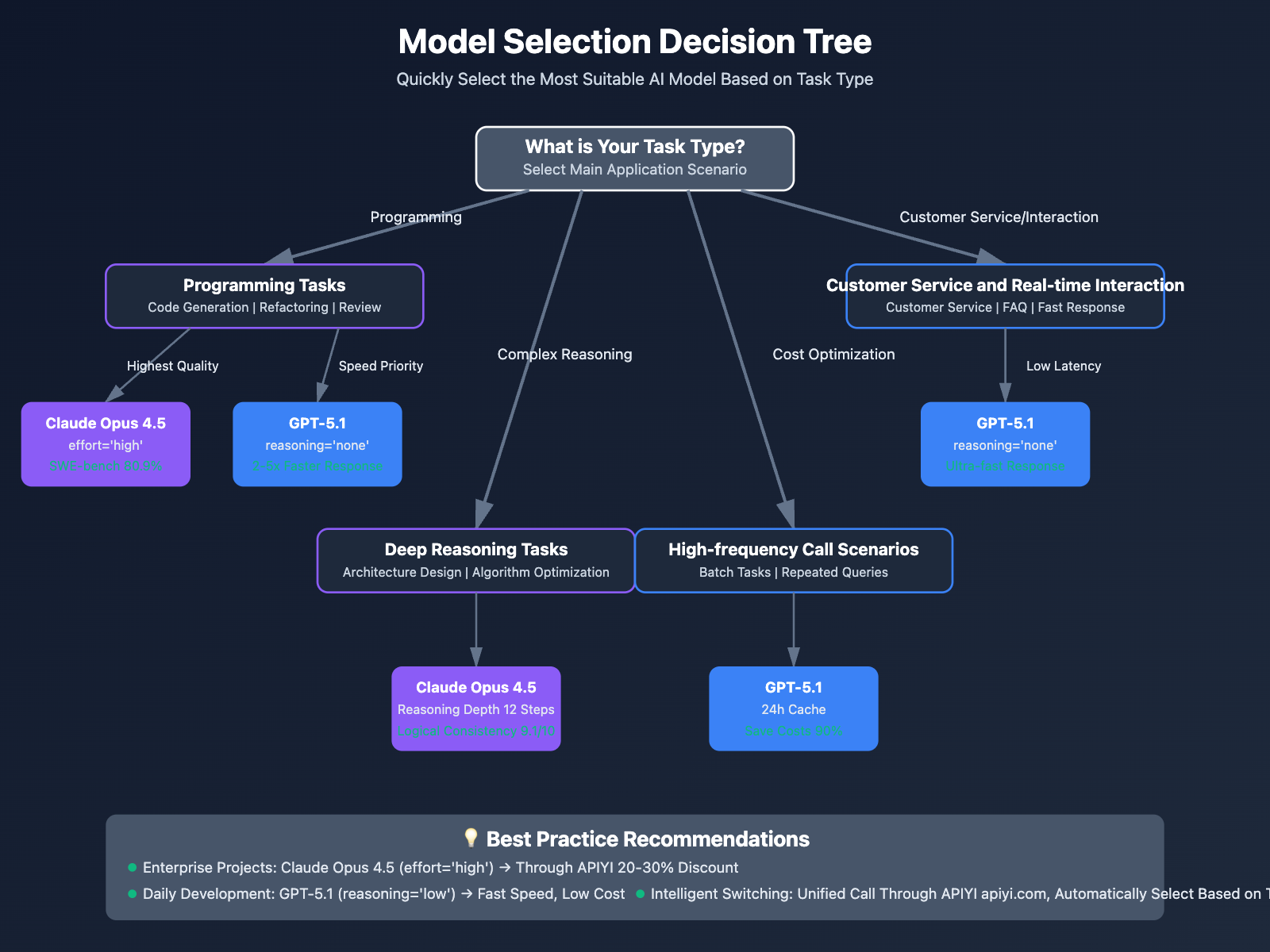
Selection Decision Tree
Select Based on Task Type
Scenarios to Choose Claude Opus 4.5
✅ Highest Programming Accuracy Requirement (SWE-bench 80.9%):
- Enterprise-level production code development
- Critical business logic implementation
- Security-sensitive application development
✅ Large Codebase Refactoring:
- Refactoring codebases with 150,000+ lines
- Cross-language code migration
- Tech stack upgrades
✅ Deep Logical Reasoning Tasks:
- System architecture design
- Complex algorithm optimization
- Causal relationship analysis (88% accuracy)
✅ Long-term Autonomous Tasks:
- Autonomous agent workflows (Vending-Bench 87.7%)
- Browser automation (BrowseComp-Plus 84%)
- Self-improving agents (peak performance in 4 iterations)
✅ Long Context Understanding (200K tokens):
- Complete codebase analysis
- Large technical documentation generation
- Multi-turn technical conversations
Scenarios to Choose GPT-5.1
✅ Speed Priority Requirement (Response Speed Improved 2-5x):
- Real-time code completion
- Fast customer service response
- Low-latency interactive applications
✅ Cost Optimization Requirement (Base Pricing 60-75% Lower):
- High-frequency API call scenarios
- Batch automation tasks
- Budget-constrained startup teams
✅ Cache Optimization Scenarios (24-hour Cache Retention):
- Long programming sessions
- Multi-turn conversation systems
- Repeated query scenarios
✅ Tool Integration Requirements:
- GitHub Copilot power users
- Cursor, JetBrains and other IDE integrations
- Existing OpenAI ecosystem
✅ Mathematics and Scientific Reasoning:
- Math competition tutoring (AIME 94%)
- Scientific problem solving (GPQA 88.1%)
- Frontier mathematics research (FrontierMath 26.7%)
Combined Usage Strategy
Recommended Workflow (Unified Call Through APIYI Platform):
from apiyi import APIYI
client = APIYI(api_key="YOUR_APIYI_API_KEY")
def intelligent_model_selection(task_type, complexity):
"""Intelligently select model based on task type and complexity"""
if complexity == "high" and task_type in ["code_refactor", "architecture"]:
# High Complexity Code Tasks → Claude Opus 4.5
return {
"model": "claude-opus-4-5-20251101",
"effort": "high"
}
elif task_type == "code_completion" or complexity == "low":
# Code Completion or Simple Tasks → GPT-5.1 (No Reasoning Mode)
return {
"model": "gpt-5.1",
"reasoning_effort": "none"
}
elif task_type == "customer_service":
# Customer Service Scenario → GPT-5.1 (Low Reasoning Mode)
return {
"model": "gpt-5.1",
"reasoning_effort": "low",
"prompt_cache_retention": "24h"
}
elif task_type == "math_reasoning":
# Mathematical Reasoning → GPT-5.1 (High Reasoning Mode)
return {
"model": "gpt-5.1",
"reasoning_effort": "high"
}
else:
# Default Balanced Choice → Claude Opus 4.5 (Medium Effort)
return {
"model": "claude-opus-4-5-20251101",
"effort": "medium"
}
# Example Usage
config = intelligent_model_selection("code_refactor", "high")
response = client.chat.completions.create(
**config,
messages=[{"role": "user", "content": "Refactor this code"}]
)
Cost Optimization Recommendations:
- Simple Tasks: GPT-5.1 (reasoning_effort='none') – Lowest Cost
- Medium Tasks: GPT-5.1 (reasoning_effort='low') or Claude (effort='low') – Balanced Choice
- Complex Tasks: Claude Opus 4.5 (effort='high') – Highest Quality
- Repeated Queries: GPT-5.1 + 24h Cache – Maximize Cache Benefits
- Long Context: Claude Opus 4.5 (200K tokens) – Stronger Understanding
Common Questions and Answers
Question 1: Which Has Stronger Programming Capability, Claude Opus 4.5 or GPT-5.1?
Answer: Claude Opus 4.5 leads in absolute programming accuracy.
Data Comparison:
- Claude Opus 4.5: SWE-bench Verified 80.9% (Industry #1)
- GPT-5.1 (high): SWE-bench Verified 76.3%
- Lead Margin: Claude leads by +4.6%
However, GPT-5.1 has advantages in flexibility and speed:
- Simple task response speed improved 2-5x
- Token consumption reduced by 70-88% (simple tasks)
- Multi-tier reasoning modes, flexibly balance speed and quality
Recommendation:
- Pursue highest accuracy → Claude Opus 4.5
- Need fast response → GPT-5.1 (reasoning_effort='none' or 'low')
- Budget constrained → GPT-5.1 (base pricing 60-75% lower)
Question 2: Which is More Cost-Effective?
Answer: GPT-5.1 has lower base pricing, but overall cost depends on specific usage scenarios.
Base Pricing Comparison:
- GPT-5.1: $1.25/$10 (input/output)
- Claude Opus 4.5: $5/$25 (input/output)
- GPT-5.1 base pricing 60-75% lower
After Optimization Through APIYI Platform:
- Claude Opus 4.5: Approximately 20-30% discount (generating 500 lines of code approximately ¥2.0-3.0)
- GPT-5.1: Approximately 20% discount (generating 500 lines of code approximately ¥2.2)
- Overall costs are close, GPT-5.1 slightly lower
Cost Optimization Strategies:
- High-frequency Repeated Calls: GPT-5.1 + 24h Cache (Save 90%)
- Simple Task Batches: Claude (effort='low') or GPT-5.1 (reasoning_effort='none')
- Complex Tasks Few: Claude (effort='high') ensure quality, avoid repeated calls
Question 3: How to Use Both Models Simultaneously on APIYI Platform?
Answer: APIYI apiyi.com platform provides unified OpenAI-compatible interface, one API Key can call all models.
Example Code:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# Call Claude Opus 4.5
response1 = client.chat.completions.create(
model="claude-opus-4-5-20251101",
messages=[{"role": "user", "content": "Complex Refactoring Task"}],
extra_body={"effort": "high"}
)
# Call GPT-5.1
response2 = client.chat.completions.create(
model="gpt-5.1",
messages=[{"role": "user", "content": "Fast Code Completion"}],
extra_body={"reasoning_effort": "none"}
)
Advantages:
- One API Key calls all models
- Unified error handling and retry mechanisms
- RMB settlement, no overseas credit card needed
- Enjoy Claude 20-30% discount, GPT-5.1 20% discount
Question 4: Which Has Faster Response Speed?
Answer: Depends on reasoning mode.
Claude Opus 4.5:
- Low Effort: 5-10 seconds
- Medium Effort: 10-20 seconds
- High Effort: 15-30 seconds
GPT-5.1:
- reasoning_effort='none': 2-5 seconds (fastest, 2-5x faster than GPT-5)
- reasoning_effort='low': 5-10 seconds
- reasoning_effort='medium': 10-20 seconds
- reasoning_effort='high': 20-40 seconds
Conclusion:
- Fastest: GPT-5.1 (reasoning_effort='none') – Suitable for code completion, fast customer service
- Balanced: Claude (effort='medium') or GPT-5.1 (reasoning_effort='low')
- Quality Priority: Claude (effort='high') – Slightly longer response time, but highest accuracy
Question 5: Which is More Suitable for Beginners?
Answer: Both are suitable, but with different focuses.
Claude Opus 4.5 is More Suitable For:
- ✅ Learners pursuing highest quality
- ✅ Scenarios requiring detailed explanations and reasoning processes
- ✅ Want code examples to better follow best practices
- ✅ Learning and practicing with large projects
GPT-5.1 is More Suitable For:
- ✅ Beginners needing fast feedback
- ✅ Budget-constrained students and self-learners
- ✅ Developers using tools like GitHub Copilot
- ✅ Scenarios requiring high-frequency queries and practice
Recommended Starting Approach:
- Register and top up ¥50-100 on APIYI apiyi.com
- First test GPT-5.1 (reasoning_effort='low') for quick start
- Compare code quality of Claude Opus 4.5 (effort='medium')
- Choose main model based on personal preference and budget
- Use Claude for complex problems, GPT-5.1 for simple queries
💡 Selection Recommendation: Through APIYI apiyi.com platform, you can experience both models at low cost. The platform provides new user discounts, top up ¥100 to fully test the actual performance of both models and find the most suitable AI programming assistant for yourself.
Summary and Upgrade Recommendations
Claude Opus 4.5 and GPT-5.1 represent two technical directions for AI programming assistants in 2025, each with its strengths:
Claude Opus 4.5 Core Advantages:
- Absolutely Leading Programming Capability: SWE-bench 80.9%, industry #1
- Deep Reasoning Capability: 12-step reasoning depth, causal analysis 88%
- Long Context Processing: 200K tokens, suitable for large codebases
- Long-term Autonomous Tasks: Vending-Bench 87.7%, peak performance in 4 iterations
- Effort Parameter: Flexibly balance performance and cost, save up to 50%
GPT-5.1 Core Advantages:
- Fast Response Speed: Simple tasks speed improved 2-5x
- Low Cost: Base pricing 60-75% lower than Claude
- Extended Cache: 24-hour retention, save 90% cost
- Adaptive Reasoning: Automatically adjust thinking depth, token consumption reduced by 70-88%
- Tool Ecosystem: Deep integration with GitHub Copilot, Cursor, JetBrains
Selection Recommendations:
- Enterprise-level High-quality Code Development → Claude Opus 4.5 (effort='high')
- Daily Development and Code Completion → GPT-5.1 (reasoning_effort='none' or 'low')
- Large Codebase Refactoring → Claude Opus 4.5 (200K context)
- Intelligent Customer Service and Real-time Interaction → GPT-5.1 ('No Reasoning' mode, low latency)
- Cost Optimization Scenarios → GPT-5.1 (24h Cache + 20% Discount)
Platform Recommendations:
- Unified Interface: APIYI apiyi.com provides unified OpenAI-compatible interface
- Discounted Pricing: Claude 20-30% discount, GPT-5.1 20% discount, comprehensively save 40%-60%
- Flexible Switching: One set of code calls all models, intelligently select based on tasks
- Enterprise Services: Support batch top-up, invoice issuance, enterprise-level SLA
🚀 Quick Start: It is recommended to experience both Claude Opus 4.5 and GPT-5.1 through APIYI apiyi.com platform. The platform provides new user top-up discounts, ¥100 can fully test the performance of both models in actual projects, find the most suitable AI programming assistant combination for you, achieving optimal balance between performance and cost!
Regardless of which model you choose, Claude Opus 4.5 and GPT-5.1 both represent the highest level of current AI programming assistants, significantly improving development efficiency, lowering programming barriers, and accelerating software innovation!