使用 Qwen3-Max 开发 AI 应用时频繁遇到 429 You exceeded your current quota 错误是许多开发者的痛点。本文将深入分析阿里云 Qwen3-Max 限速机制,并提供 5 种实用解决方案,帮助你彻底告别配额不足的困扰。
核心价值: 读完本文,你将理解 Qwen3-Max 限速原理,掌握多种解决方案,选择最适合你的方式稳定调用万亿参数大模型。
Qwen3-Max 限速问题概述
典型错误信息
当你的应用频繁调用 Qwen3-Max API 时,可能会遇到以下错误:
{
"error": {
"message": "You exceeded your current quota, please check your plan and billing details.",
"type": "insufficient_quota",
"code": "insufficient_quota"
},
"status": 429
}
这个错误意味着你已触发阿里云 Model Studio 的配额限制。
Qwen3-Max 限速问题影响范围
| 影响场景 | 具体表现 | 严重程度 |
|---|---|---|
| Agent 开发 | 多轮对话频繁中断 | 高 |
| 批量处理 | 任务无法完成 | 高 |
| 实时应用 | 用户体验受损 | 高 |
| 代码生成 | 长代码输出被截断 | 中 |
| 测试调试 | 开发效率降低 | 中 |
Qwen3-Max 限速机制详解
阿里云官方配额限制
根据阿里云 Model Studio 官方文档,Qwen3-Max 的配额限制如下:
| 模型版本 | RPM (请求/分钟) | TPM (Token/分钟) | RPS (请求/秒) |
|---|---|---|---|
| qwen3-max | 600 | 1,000,000 | 10 |
| qwen3-max-2025-09-23 | 60 | 100,000 | 1 |
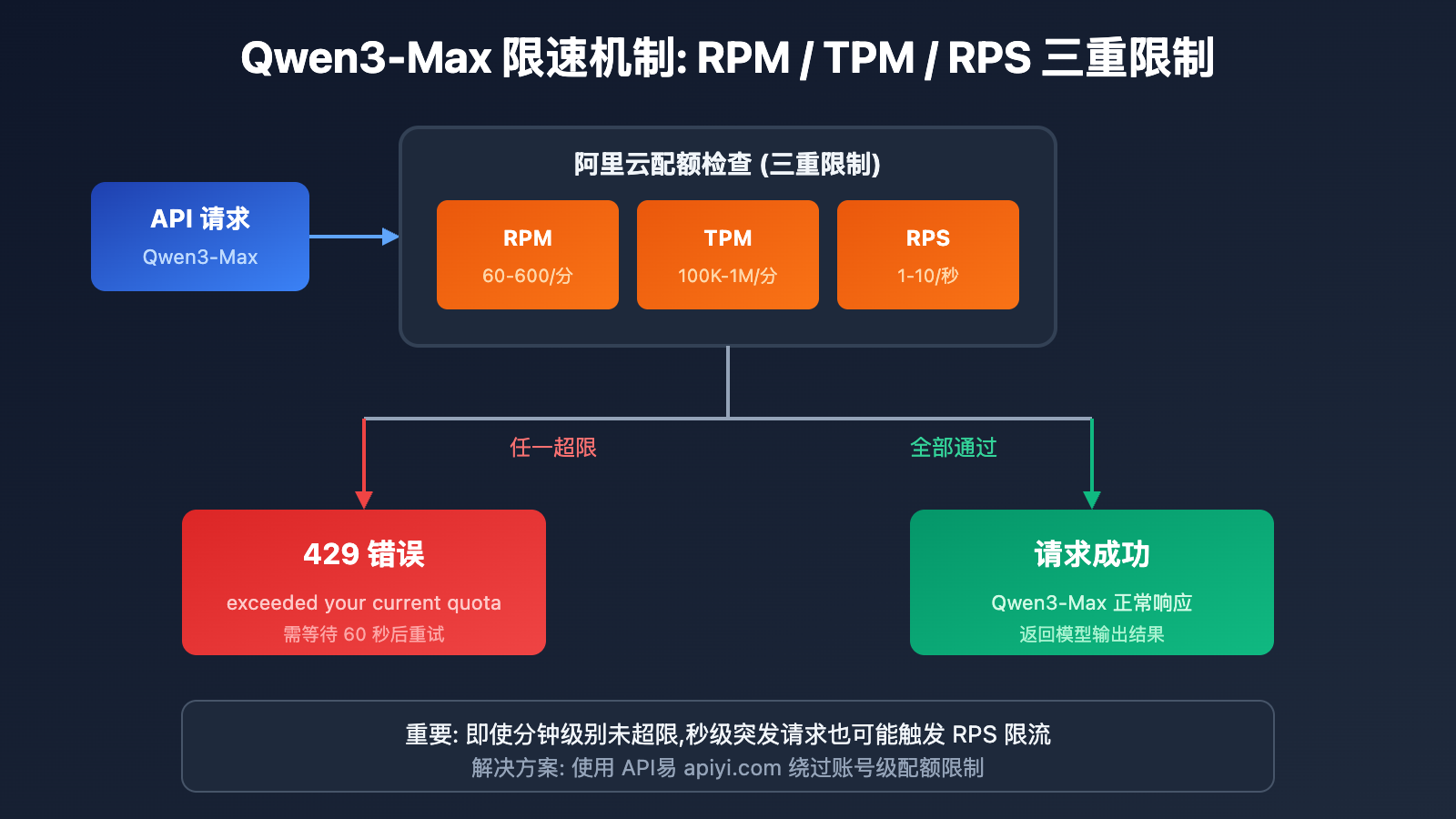
触发 Qwen3-Max 限速的 4 种情况
阿里云对 Qwen3-Max 实施 双重限制机制,任一条件触发都会返回 429 错误:
| 错误类型 | 错误信息 | 触发原因 |
|---|---|---|
| 请求频率超限 | Requests rate limit exceeded | RPM/RPS 超出限制 |
| Token 消耗超限 | You exceeded your current quota | TPM/TPS 超出限制 |
| 突发流量保护 | Request rate increased too quickly | 瞬时请求激增 |
| 免费额度耗尽 | Free allocated quota exceeded | 试用额度用完 |
限速计算公式
实际限制 = min(RPM 限制, RPS × 60)
= min(TPM 限制, TPS × 60)
重要提示: 即使分钟级别未超限,秒级别的突发请求也可能触发限流。
Qwen3-Max 限速问题 5 种解决方案
方案对比总览
| 方案 | 实施难度 | 效果 | 成本 | 推荐场景 |
|---|---|---|---|---|
| API 中转服务 | 低 | 彻底解决 | 更省 | 所有场景 |
| 请求平滑策略 | 中 | 缓解 | 无 | 轻度限速 |
| 多账号轮询 | 高 | 缓解 | 高 | 企业用户 |
| 备用模型降级 | 中 | 兜底 | 中 | 非核心任务 |
| 申请配额提升 | 低 | 有限 | 无 | 长期用户 |
方案一: 使用 API 中转服务 (推荐)
这是解决 Qwen3-Max 限速问题最直接有效的方案。通过 API 中转平台调用,可以绕过阿里云账号级别的配额限制。
为什么 API 中转能解决限速
| 对比项 | 直连阿里云 | 通过 API易 中转 |
|---|---|---|
| 配额限制 | 账号级 RPM/TPM 限制 | 平台级大池共享 |
| 限速频率 | 频繁触发 429 | 基本无限速 |
| 价格 | 官方原价 | 默认 0.88 折 |
| 稳定性 | 受账号配额影响 | 多通道保障 |
极简代码示例
from openai import OpenAI
# 使用 API易 中转服务,告别限速烦恼
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen3-max",
messages=[
{"role": "user", "content": "请解释 MoE 架构的工作原理"}
]
)
print(response.choices[0].message.content)
🎯 推荐方案: 通过 API易 apiyi.com 调用 Qwen3-Max,不仅彻底解决限速问题,还能享受 0.88 折优惠价格。API易与阿里云有渠道合作,能够提供更稳定的服务和更优惠的价格。
查看完整代码 (含重试和错误处理)
import time
from openai import OpenAI
from openai import APIError, RateLimitError
class Qwen3MaxClient:
"""Qwen3-Max 客户端,通过 API易 调用,无限速困扰"""
def __init__(self, api_key: str):
self.client = OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # API易 中转接口
)
self.model = "qwen3-max"
def chat(self, message: str, max_retries: int = 3) -> str:
"""
发送消息并获取回复
通过 API易 调用,基本不会遇到限速问题
"""
for attempt in range(max_retries):
try:
response = self.client.chat.completions.create(
model=self.model,
messages=[{"role": "user", "content": message}],
max_tokens=4096
)
return response.choices[0].message.content
except RateLimitError as e:
# 使用 API易 基本不会触发此异常
if attempt < max_retries - 1:
wait_time = 2 ** attempt
print(f"请求受限,{wait_time}秒后重试...")
time.sleep(wait_time)
else:
raise e
except APIError as e:
print(f"API 错误: {e}")
raise e
return ""
def batch_chat(self, messages: list[str]) -> list[str]:
"""批量处理消息,无需担心限速"""
results = []
for msg in messages:
result = self.chat(msg)
results.append(result)
return results
# 使用示例
if __name__ == "__main__":
client = Qwen3MaxClient(api_key="your-apiyi-key")
# 单次调用
response = client.chat("用 Python 写一个快速排序算法")
print(response)
# 批量调用 - 通过 API易 无限速困扰
questions = [
"解释什么是 MoE 架构",
"对比 Transformer 和 RNN",
"什么是注意力机制"
]
answers = client.batch_chat(questions)
for q, a in zip(questions, answers):
print(f"Q: {q}\nA: {a}\n")
方案二: 请求平滑策略
如果你坚持使用阿里云直连,可以通过请求平滑来缓解限速问题。
指数退避重试
import time
import random
def call_with_backoff(func, max_retries=5):
"""指数退避重试策略"""
for attempt in range(max_retries):
try:
return func()
except Exception as e:
if "429" in str(e) and attempt < max_retries - 1:
# 指数退避 + 随机抖动
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"触发限速,等待 {wait_time:.2f} 秒后重试...")
time.sleep(wait_time)
else:
raise e
请求队列缓冲
import asyncio
from collections import deque
class RequestQueue:
"""请求队列,平滑 Qwen3-Max 调用频率"""
def __init__(self, rpm_limit=60):
self.queue = deque()
self.interval = 60 / rpm_limit # 请求间隔
self.last_request = 0
async def throttled_request(self, request_func):
"""限速请求"""
now = time.time()
wait_time = self.interval - (now - self.last_request)
if wait_time > 0:
await asyncio.sleep(wait_time)
self.last_request = time.time()
return await request_func()
注意: 请求平滑只能缓解限速,无法彻底解决。对于高并发场景,建议使用 API易 中转服务。
方案三: 多账号轮询
企业用户可以通过多账号轮询来提升总体配额。

from itertools import cycle
class MultiAccountClient:
"""多账号轮询客户端"""
def __init__(self, api_keys: list[str]):
self.clients = cycle([
OpenAI(api_key=key, base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")
for key in api_keys
])
def chat(self, message: str) -> str:
client = next(self.clients)
response = client.chat.completions.create(
model="qwen3-max",
messages=[{"role": "user", "content": message}]
)
return response.choices[0].message.content
| 账号数量 | 等效 RPM | 等效 TPM | 管理复杂度 |
|---|---|---|---|
| 1 | 600 | 1,000,000 | 低 |
| 3 | 1,800 | 3,000,000 | 中 |
| 5 | 3,000 | 5,000,000 | 高 |
| 10 | 6,000 | 10,000,000 | 很高 |
💡 对比建议: 多账号管理复杂且成本高,不如直接使用 API易 apiyi.com 中转服务,无需管理多个账号,享受平台级大池配额。
方案四: 备用模型降级
当 Qwen3-Max 触发限速时,可以自动降级到备用模型。
class FallbackClient:
"""支持降级的 Qwen 客户端"""
MODEL_PRIORITY = [
"qwen3-max", # 首选
"qwen-plus", # 备用 1
"qwen-turbo", # 备用 2
]
def __init__(self, api_key: str):
self.client = OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # 使用 API易
)
def chat(self, message: str) -> tuple[str, str]:
"""返回 (回复内容, 实际使用的模型)"""
for model in self.MODEL_PRIORITY:
try:
response = self.client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": message}]
)
return response.choices[0].message.content, model
except Exception as e:
if "429" in str(e):
print(f"{model} 限速,尝试降级...")
continue
raise e
raise Exception("所有模型均不可用")
方案五: 申请配额提升
对于长期稳定使用的用户,可以向阿里云申请提升配额。
申请步骤:
- 登录阿里云控制台
- 进入 Model Studio 配额管理页面
- 提交配额提升申请
- 等待审核 (通常 1-3 个工作日)
申请要求:
- 账号实名认证
- 无欠费记录
- 提供使用场景说明
Qwen3-Max 限速问题成本对比
价格对比分析
| 服务商 | 输入价格 (0-32K) | 输出价格 | 限速情况 |
|---|---|---|---|
| 阿里云直连 | $1.20/M | $6.00/M | 严格 RPM/TPM 限制 |
| API易 (0.88折) | $1.06/M | $5.28/M | 基本无限速 |
| 差价 | 节省 12% | 节省 12% | – |
综合成本计算
假设月调用量 1000 万 Token (输入输出各半):
| 方案 | 月费用 | 限速影响 | 综合评价 |
|---|---|---|---|
| 阿里云直连 | $36.00 | 频繁中断,需重试 | 实际成本更高 |
| API易中转 | $31.68 | 稳定无中断 | 性价比最优 |
| 多账号方案 | $36.00+ | 管理成本高 | 不推荐 |
💰 成本优化: API易 apiyi.com 与阿里云有渠道合作,不仅价格默认 0.88 折,还能彻底解决限速问题。对于中高频使用场景,综合成本更低。
常见问题
Q1: 为什么我刚开始使用就遇到 Qwen3-Max 限速?
阿里云 Model Studio 对新账号的免费额度有限,且新版本 qwen3-max-2025-09-23 的配额更低 (RPM 60, TPM 100,000)。如果你使用的是快照版本,限速会更严格。
建议通过 API易 apiyi.com 调用,可以避开账号级别的配额限制。
Q2: 限速后多久可以恢复?
阿里云的限速是滑动窗口机制:
- RPM 限制: 等待约 60 秒后恢复
- TPM 限制: 等待约 60 秒后恢复
- 突发保护: 可能需要等待更长时间
使用 API易 平台调用可以避免频繁等待,提升开发效率。
Q3: API易 中转服务的稳定性如何保障?
API易与阿里云有渠道合作关系,采用平台级大池配额模式:
- 多通道负载均衡
- 自动故障转移
- 99.9% 可用性保障
相比个人账号的配额限制,平台级服务更加稳定可靠。
Q4: 使用 API易 需要修改很多代码吗?
几乎不需要。API易 完全兼容 OpenAI SDK 格式,你只需要修改两处:
# 修改前 (阿里云直连)
client = OpenAI(
api_key="sk-xxx",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# 修改后 (API易 中转)
client = OpenAI(
api_key="your-apiyi-key", # 换成 API易 的 key
base_url="https://api.apiyi.com/v1" # 换成 API易 地址
)
模型名称、参数格式完全一致,无需其他改动。
Q5: 除了 Qwen3-Max,API易 还支持哪些模型?
API易 平台支持 200+ 主流 AI 模型的统一调用,包括:
- Qwen 全系列: qwen3-max, qwen-plus, qwen-turbo, qwen-vl 等
- Claude 系列: claude-3-opus, claude-3-sonnet, claude-3-haiku
- GPT 系列: gpt-4o, gpt-4-turbo, gpt-3.5-turbo
- 其他: gemini, deepseek, moonshot 等
所有模型统一接口,一个 API Key 调用所有模型。
Qwen3-Max 限速问题解决方案总结
方案选择决策树
遇到 Qwen3-Max 429 错误
│
├─ 需要彻底解决 → 使用 API易 中转 (推荐)
│
├─ 轻度限速 → 请求平滑 + 指数退避
│
├─ 企业大规模调用 → 多账号轮询 或 API易 企业版
│
└─ 非核心任务 → 备用模型降级
核心要点回顾
| 要点 | 说明 |
|---|---|
| 限速原因 | 阿里云 RPM/TPM/RPS 三重限制 |
| 最优方案 | API易 中转服务,彻底解决 |
| 成本优势 | 0.88 折,比直连更省 |
| 迁移成本 | 仅需修改 base_url 和 api_key |
推荐通过 API易 apiyi.com 快速解决 Qwen3-Max 限速问题,享受稳定服务和优惠价格。
参考资料
-
阿里云 Rate Limits 文档: 官方限速说明
- 链接:
alibabacloud.com/help/en/model-studio/rate-limit
- 链接:
-
阿里云 Error Codes 文档: 错误码详解
- 链接:
alibabacloud.com/help/en/model-studio/error-code
- 链接:
-
Qwen3-Max 模型文档: 官方技术规格
- 链接:
alibabacloud.com/help/en/model-studio/what-is-qwen-llm
- 链接:
技术支持: 如有 Qwen3-Max 使用问题,欢迎通过 API易 apiyi.com 获取技术支持。