一個有意思的發現~ 最近不少開發者在試用 MiniMax 2026 年 3 月發佈的 M2.7 模型時,撞上了一個反直覺的問題:這款被稱爲"代碼與 Agent 工作流之王"的旗艦模型,居然不支持圖片輸入。要知道,在 Claude 4、GPT-5、Gemini 3 都標配多模態能力的當下,一個 230B 參數的旗艦大模型不能識圖確實讓人意外。本文基於 MiniMax 官方文檔、NVIDIA NIM 模型卡與 OpenRouter 公開規格,結合 API易 apiyi.com 在實際部署中的觀察,深度解析 M2.7 "純文本"定位背後的產品邏輯。

一、MiniMax M2.7 不支持圖片輸入是真的嗎
先回答最直接的問題:是真的。根據 MiniMax 官方平臺與 NVIDIA NIM 模型卡的公開規格,M2.7(包括 M2.7-highspeed 版本)目前僅支持文本輸入,無法直接處理圖像、音頻或視頻。這與上一代 M2.5 的純文本定位一致,但與同期發佈的 Claude 4 Opus、GPT-5、Gemini 3 系列"原生多模態"的主流形成鮮明對比。
1.1 MiniMax M2.7 的核心規格速覽
M2.7 在 2026 年 3 月 18 日正式開放接口,採用 MoE(混合專家)架構,總參數 230B,激活參數 10B,主打"高性能 + 低成本"。
| 規格項 | 具體參數 |
|---|---|
| 發佈日期 | 2026-03-18 |
| 架構類型 | MoE Transformer(256 專家,每 token 激活 8 個) |
| 總參數 / 激活參數 | 230B / 10B |
| 上下文窗口 | 204,800 tokens |
| 最大輸出 | 131,072 tokens |
| 輸入價格 | $0.279 / M tokens |
| 輸出價格 | $1.20 / M tokens |
| 多模態支持 | ❌ 僅支持文本 |
| API 兼容 | Anthropic API + OpenAI API |
1.2 哪些場景下會"踩坑"
如果你的應用涉及截圖問答、PDF 截圖解析、商品圖理解、UI 自動化視覺檢測、多模態 RAG 中的圖像檢索等場景,直接調用 M2.7 會失敗或得到無意義的輸出。建議在路由層(如 LiteLLM、One API 或 API易 apiyi.com 這類統一中轉網關)做模型類型判斷,把圖像類請求路由到 Claude、GPT-5 或 Gemini 3 系列再處理。
二、爲什麼 MiniMax M2.7 選擇"純文本"路線
M2.7 的純文本定位不是技術能力不足,而是一個非常清晰的產品決策。MiniMax 此前已經發布過具備多模態能力的 abab 系列模型,完全有能力在 M 系列上加入視覺模塊。但他們選擇把 M2.7 的訓練算力全部投入到"代碼 + Agent"兩個賽道,以換取在這兩個方向上的極致表現。
2.1 代碼與 Agent 是 M2.7 的核心戰場
根據官方 README 與 NVIDIA 技術博客描述,M2.7 專門爲"多文件編輯、代碼-運行-修復循環、測試驅動的修復、跨 Shell/瀏覽器/檢索/代碼運行器的長鏈工具調用"優化。在 SWE-bench、Aider Polyglot、Terminal Bench 等真實編碼任務上,M2.7 的成績接近 Claude 4 Sonnet,但激活參數只有 10B,推理成本僅爲後者的約 1/8。
2.2 純文本路線 vs 多模態路線的權衡
把訓練資源壓在單一方向上,帶來的是確定性的收益和損失。下表整理了兩條路線的核心權衡點:
| 維度 | 純文本路線(M2.7 / DeepSeek-R1) | 多模態路線(Claude/GPT/Gemini) |
|---|---|---|
| 訓練成本 | 集中,效率高 | 分散,數據成本高 |
| 單位 token 價格 | 較低($0.28-2 / M) | 較高($3-15 / M) |
| 文本/代碼推理深度 | 通常更強 | 略弱但夠用 |
| 圖像/視頻理解 | 不支持 | 原生支持 |
| 適用場景廣度 | 偏聚焦 | 更通用 |
| 工程接入複雜度 | 低 | 低-中 |
2.3 通過工具調用"補全"多模態能力
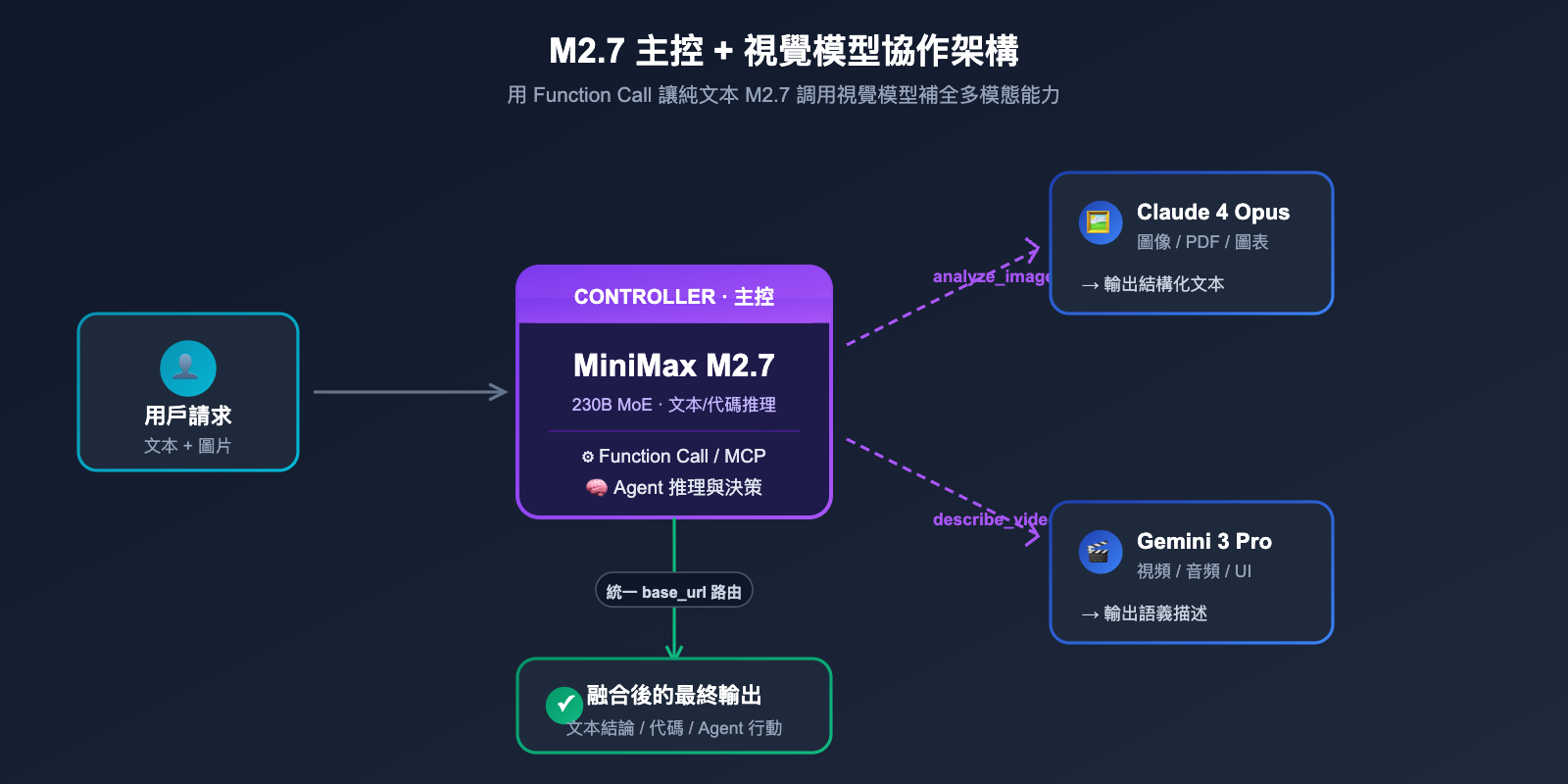
雖然 M2.7 本身不識圖,但它原生支持 MCP(Model Context Protocol)和 Function Calling。這意味着開發者可以讓 M2.7 把圖像理解任務"外包"給專門的視覺模型(如 Claude 4 Opus 或 Gemini 3 Vision),自己只負責調度與最終推理。這種"主控 + 視覺協作"的架構在 Agent 系統裏非常常見。
三、2026 年多模態 API 真的是行業標配嗎
直觀感受上,"多模態 = 標配"幾乎成了 2026 年的行業共識。但深入觀察主流模型陣營,會發現這個判斷需要分層理解。
3.1 主流閉源旗艦幾乎全部支持多模態
Anthropic 的 Claude 4 系列、OpenAI 的 GPT-5 系列、Google 的 Gemini 3 Pro/Ultra 都已經把圖像作爲基礎輸入能力。Gemini 3 在 ScreenSpot-Pro 測試上從前代 11.4% 一躍提升到 72.7%,可以直接"看懂"屏幕截圖並操作 UI;Claude 4 也強化了圖表識別與 PDF 解析能力。
3.2 開源/性價比陣營出現明顯分化
開源陣營則呈現明顯分化:一類是 Llama 3.2 Vision、Qwen3-VL、InternVL 等"全棧多模態"模型;另一類則是 DeepSeek-R1、MiniMax M2.7 等"專精文本/推理"的模型,通過聚焦獲得性價比優勢。這兩類模型並不是簡單的"高低之分",而是面向不同應用形態的差異化選擇。
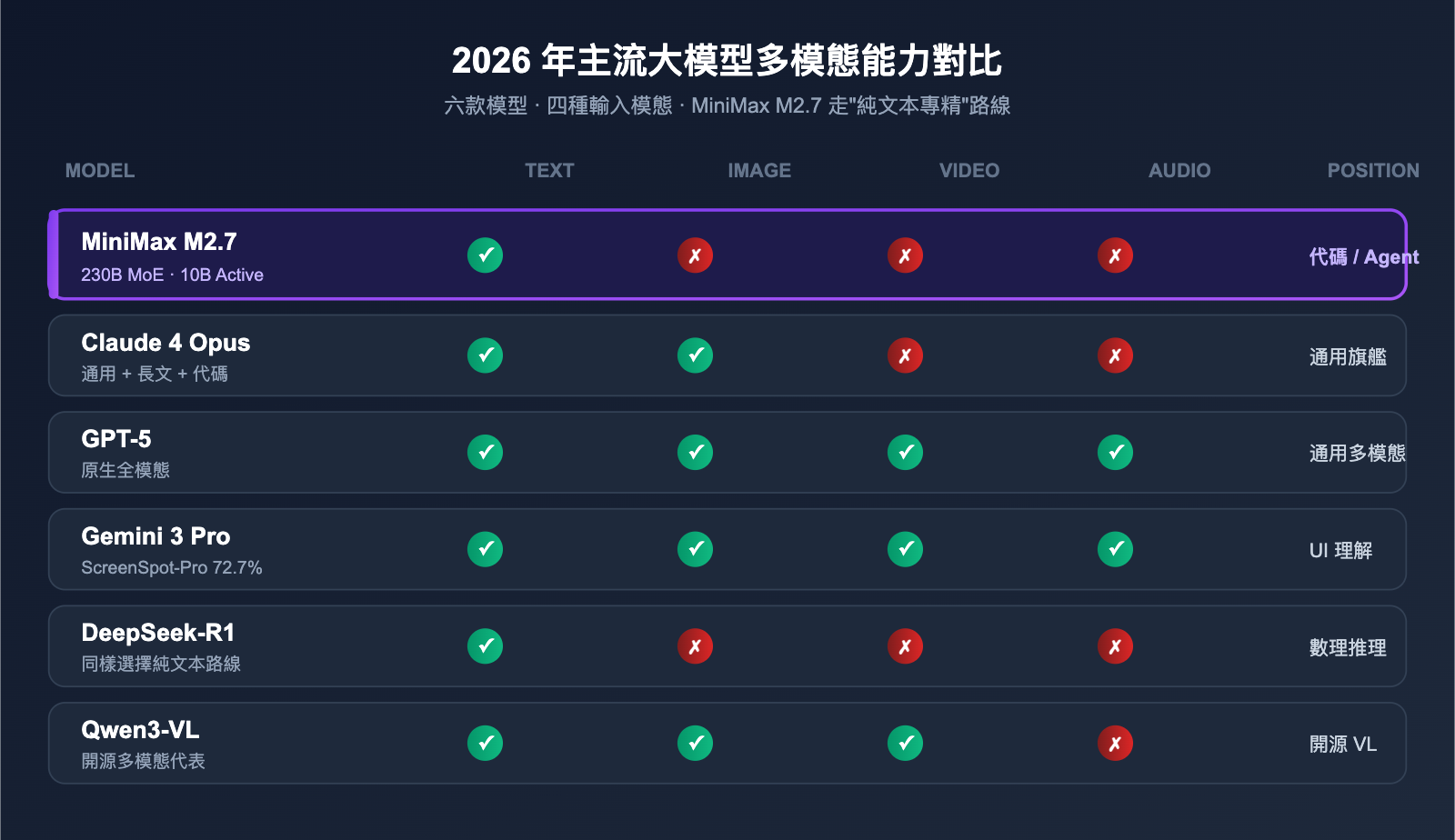
3.3 主流模型多模態能力對比
下表彙總了 2026 年 5 月主流大模型的多模態能力差異,可以快速看出 M2.7 在陣營中的定位:
| 模型 | 圖像輸入 | 視頻輸入 | 音頻輸入 | 主要定位 |
|---|---|---|---|---|
| MiniMax M2.7 | ❌ | ❌ | ❌ | 代碼/Agent 推理 |
| Claude 4 Opus | ✅ | ❌ | ❌ | 通用 + 長文 + 代碼 |
| GPT-5 | ✅ | ✅ | ✅ | 通用多模態 |
| Gemini 3 Pro | ✅ | ✅ | ✅ | 多模態 + UI 理解 |
| DeepSeek-R1 | ❌ | ❌ | ❌ | 數理推理 |
| Qwen3-VL | ✅ | ✅ | ❌ | 開源多模態 |
可以看出,"標配多模態"主要集中在閉源旗艦陣營。在開源與性價比陣營,專精文本仍然是一種有效的差異化路線。
四、沒有原生視覺,如何讓 MiniMax M2.7 處理圖像
雖然 M2.7 自身不讀圖,但通過工具調用 + 路由的方式,完全可以構建"M2.7 主控 + 視覺模型協作"的混合架構,既享受 M2.7 的低成本,又不損失多模態體驗。
4.1 推薦的混合調用架構
最常見的做法是:使用一個統一的網關(如 API易 apiyi.com 提供的多模型路由)把請求按內容類型分發。文本/代碼請求走 M2.7,圖像請求走 Claude 4 或 Gemini 3,再把視覺模型的輸出文本回傳給 M2.7 做最終推理與決策。這種架構對前端透明,無需修改業務側的 SDK 調用方式。
4.2 Function Calling 中接入視覺模型
如果你的應用使用 Function Calling,可以爲 M2.7 註冊一個 analyze_image 工具,內部調用 Claude/GPT/Gemini 的視覺接口,把識別結果以 JSON 返回。M2.7 會根據用戶請求自動判斷何時調用這個工具,無需在 Prompt 層顯式判斷。這種模式適合 Agent 框架(如 LangGraph、CrewAI、OpenAI Agents SDK)。
🎯 接入建議: 我們建議通過 API易 apiyi.com 一個 base_url 同時接入 M2.7 與多模態模型(如 Claude 4 Opus、Gemini 3 Pro),不再爲每個廠商維護單獨的 SDK 與密鑰,可以大幅降低混合架構的工程複雜度,也方便統一觀測 token 消耗與成本。
4.3 推薦的推理參數
MiniMax 官方推薦 M2.7 使用相對偏高的採樣參數:temperature=1.0、top_p=0.95、top_k=40。這與多數模型的低溫度建議不同,實測在編碼與 Agent 場景下,這套參數能產出質量更高、更具創造性的代碼補全。如果你之前的 Prompt 模板默認 temperature=0,在 M2.7 上反而可能拿到僵化、重複的輸出,需要重新調優。
五、MiniMax M2.7 vs 多模態模型的選型決策
到底什麼時候選 M2.7、什麼時候選多模態旗艦?核心要看你的應用是"文本/代碼主導"還是"多模態主導",而不是單純比誰的參數更大。
5.1 文本/代碼主導場景優選 M2.7
如果你的產品 90% 以上請求是文本類(代碼生成、文檔問答、Agent 編排、長文摘要),M2.7 是當下性價比最高的選擇之一。230B 總參數帶來的能力上限接近 Claude 4 Sonnet,但單位 token 價格只有後者的零頭,對高併發的 SaaS 後端尤爲友好。
5.2 多模態高頻場景優選 Claude / Gemini
如果你的核心場景是圖像理解(OCR、UI 自動化、商品識別、醫療影像輔助)、視頻分析或音頻處理,直接選 Claude 4 Opus、GPT-5 或 Gemini 3 Pro 會比"M2.7 + 視覺模型"的混合架構更簡潔可靠,減少跨模型調用的延遲與失敗率。
5.3 不同場景的選型建議
| 應用場景 | 優先模型 | 備選方案 |
|---|---|---|
| 代碼生成 / 重構 | MiniMax M2.7 | Claude 4 Sonnet |
| Agent 工具調用 | MiniMax M2.7 | GPT-5 |
| 長文檔問答(200K 以內) | MiniMax M2.7 | Claude 4 Opus |
| 圖像 OCR / 截圖問答 | Gemini 3 Pro | Claude 4 Opus |
| 視頻分析 | Gemini 3 Pro | GPT-5 |
| 多模態 RAG | Claude 4 Opus | Gemini 3 Pro |
| 混合任務(文本主導 + 少量圖像) | M2.7 + 視覺模型組合 | Claude 4 Opus 單模型 |
🎯 選型建議: 選哪個模型本質上不是"誰更強",而是"誰更匹配你的請求分佈"。建議通過 API易 apiyi.com 平臺用真實流量做 A/B 測試,對比相同任務下不同模型的成本與質量,再確定最終的主力模型組合。
六、MiniMax M2.7 常見問題解答
6.1 M2.7 真的完全不能處理圖片嗎
是的,直接把圖片文件(base64 或 URL)放進 messages,會被接口拒絕或返回錯誤。唯一可行的方式是先用其他視覺模型把圖片轉爲文本描述,再把描述傳給 M2.7 做後續推理。
6.2 M2.7 和 M2.7-highspeed 有什麼區別
兩者輸出結果一致,只是響應速度不同。M2.7-highspeed 適合對延遲敏感的場景(如 IDE 實時補全),M2.7 標準版適合大批量異步任務。兩個版本可以在 API易 apiyi.com 控制檯通過模型名稱切換,接口參數完全兼容。
6.3 M2.7 是開源模型嗎,能否本地部署
可以,M2.7 是開放權重模型,可在 HuggingFace 下載並自託管。但需要至少 8 張 A100 / H100 才能跑滿 200K 上下文,本地部署成本遠高於 API 調用,除非有嚴格的數據合規要求,否則不建議自建。
6.4 M2.7 是否兼容 Anthropic / OpenAI 的官方 SDK
完全兼容。可以直接使用 anthropic 或 openai 官方 SDK,只需把 base_url 指向中轉網關(如 API易 apiyi.com 的統一接入端點),並切換 model 名稱即可,無需重寫任何業務邏輯。這也是混合架構最省力的接入方式。
6.5 多模態需求多的團隊是否就不該考慮 M2.7
不一定。即使是多模態應用,文本推理與編排仍佔大量請求量。建議把多模態部分留給 Claude/Gemini,文本編排與決策部分交給 M2.7,可以顯著降低整體推理成本。如需定製混合方案,可以聯繫 API易 apiyi.com 商務團隊獲取架構建議。
七、總結:多模態是趨勢,但"專精"也仍是有效路線
MiniMax M2.7 不支持圖片輸入,既是事實,也是有意爲之的產品策略。在 2026 年這個多模態成爲閉源旗艦標配的節點上,MiniMax 選擇把所有訓練資源集中在代碼與 Agent 兩個最有差異化的賽道,換來了接近 Claude 4 Sonnet 的代碼能力和遠低於後者的推理成本。
對開發者來說,這意味着模型選型不再是"誰更全能"的簡單比較,而是"誰更匹配你的請求分佈"。文本/代碼主導的場景下,M2.7 仍然是當下最具性價比的選擇之一;多模態高頻場景則該交給 Claude 4 Opus、GPT-5 或 Gemini 3 等專業選手。兩者通過統一網關組合使用,往往能拿到最優的成本與效果平衡。
如需在同一個 base_url 下統一接入 M2.7 與各家多模態旗艦,可以訪問 API易 apiyi.com 官方文檔查看完整的模型列表與接入示例。
作者: APIYI Team — 持續爲全球 AI 開發者提供穩定、高效的 API 中轉與多模型路由服務,詳情訪問 apiyi.com