提示詞緩存(Prompt Caching)幾乎是 2026 年所有大模型 API 用戶都繞不開的成本話題。同樣跑一個 8K 系統提示詞的 RAG 應用,開了緩存和沒開緩存,月度賬單可能差出 10 倍以上。但很多開發者在 OpenAI 與 Anthropic 之間切換時,會被一個隱藏細節絆到——兩家的緩存計費模型完全不一樣。

最關鍵的差異其實只有一句話:GPT 系列的緩存寫入按基礎價 1x 計費、不收溢價,而 Claude 系列的緩存寫入會收 1.25x(5 分鐘)或 2x(1 小時)的溢價。這個差別看起來微小,但放進真實業務流量裏就會顯著影響盈虧平衡點。本文基於兩家官方文檔逐項覈對,把計費規則、觸發條件、讀取折扣、TTL 策略、回本測算講清楚,幫你做出更準確的成本預估。
GPT 與 Claude 提示詞緩存的 5 大核心差異
直接上結論。下面這張表是全文最值得收藏的一張表,它把兩家在緩存層最容易被忽視的 5 個關鍵點放在一起,方便對照。
| 維度 | OpenAI GPT | Anthropic Claude |
|---|---|---|
| 寫入計費 | 1x 基礎價,無溢價 | 5min: 1.25x;1h: 2x |
| 讀取計費 | 約 0.1x(最高 90% 折扣) | 0.1x(10% 折扣後價格) |
| 觸發方式 | 全自動,無需改代碼 | 顯式 opt-in,需 cache_control |
| 最小 token 閾值 | 統一 1024 tokens | 1024 / 2048 / 4096(按模型不同) |
| 緩存 TTL | 默認 5–10 分鐘空閒,最長 1 小時;擴展模式 24 小時 | 默認 5 分鐘,可選 1 小時(2x 寫入) |
讀懂這張表的關鍵在於"寫入計費"這一行。OpenAI 的邏輯是:緩存對你免費,第一次寫入就是按基礎價收費、第二次起的命中再給你打折,所以只要發生過一次命中,就立刻進入純收益區。Claude 的邏輯是:寫入要先付溢價,命中後再退還折扣,需要"夠多次命中"才能把溢價攤回來。
🎯 配置建議:如果你的業務流量不可預測、命中率不穩定,建議優先選 GPT 的自動緩存機制以降低風險。如果命中率非常穩定(如客服、Agent、長文檔分析),Claude 的顯式控制反而能榨出更高折扣。兩家模型 API易 apiyi.com 都已上線,可以同一把令牌內做對比測試,避免重複開賬號。
OpenAI GPT 提示詞緩存的計費機制詳解
OpenAI 官方文檔對 Prompt Caching 的措辭非常直白:"Caching happens automatically, with no explicit action needed or extra cost paid to use the caching feature." 翻譯過來就是:自動啓用、零額外費用、無需改一行代碼。
GPT 緩存的寫入與讀取計費
GPT 系列對緩存寫入不收任何溢價。你第一次發送一條 8K 的系統提示詞時,按 base 輸入價格收費——和不開緩存一模一樣。從第二次開始,如果系統識別到這段前綴已被緩存,就把命中部分以約基礎價 10% 的優惠價計費,節省 90%。
| 項目 | 計費方式 | 與基礎價比例 |
|---|---|---|
| 緩存首次寫入 | 按基礎輸入價 | 1x(無溢價) |
| 緩存命中讀取 | 緩存命中折扣 | 約 0.1x |
| 啓用費用 | 完全免費 | 0 |
| 配置代碼改動 | 零 | 無需 |
實際折扣幅度官方表述爲"up to 90%",按模型與計費表小有差別。例如 GPT-5.4 的基礎輸入價爲 $2/1M,緩存命中價爲 $0.20/1M,正好是 10%。GPT-4.1、GPT-4o 等已支持模型也基本遵循這個比例。
🎯 價格覈對:由於 OpenAI 模型迭代頻繁,實際命中折扣價以官方計費表爲準。建議在 API易 apiyi.com 後臺模型廣場直接查看當前生效價格,平臺會同步官方調整,不會另收中轉手續費,開發者按實際 Token 用量結算即可。
GPT 緩存的命中條件
要觸發緩存命中,必須同時滿足兩個條件:
- 提示詞長度 ≥ 1024 tokens(短於此數不進入緩存)。
- 提示詞的前綴需與歷史請求完全一致,命中以 128 token 增量切片。
OpenAI 把緩存命中的最小顆粒定在 128 tokens,意味着一段 1500 token 的穩定前綴,只要前 1024 tokens 完全一致,剩餘部分以 128 增量逐步命中。這種自動化設計的代價是控制力較弱——開發者無法顯式指定"哪段一定要緩存",必須把所有穩定內容前置。
GPT 緩存的 TTL 行爲
OpenAI 對 TTL 給了一段非常關鍵的描述:緩存前綴通常在 5–10 分鐘空閒後被回收,最長保留 1 小時。GPT-5、GPT-4.1 等較新模型還支持"extended retention",最長可至 24 小時。
🎯 使用提示:通過 API易 apiyi.com 接入 GPT 系列時,OpenAI 的自動緩存策略對中轉鏈路是透明的,命中率和直連官方端點一致。這意味着你可以在不增加任何成本的前提下,用 API易統一管理 OpenAI 與 Claude 的賬單與令牌。
Anthropic Claude 提示詞緩存的計費機制詳解
Claude 的設計哲學和 OpenAI 完全相反——它把緩存當成一項"可主動配置的優化能力",開發者必須顯式聲明哪些內容要緩存、緩存多久。代價是寫入要付溢價,回報是控制粒度極高。
Claude 緩存的寫入溢價與讀取折扣
| 項目 | 計費倍率 | 說明 |
|---|---|---|
| 5 分鐘寫入 | 1.25x 基礎輸入價 | 默認 TTL,覆蓋大多數場景 |
| 1 小時寫入 | 2x 基礎輸入價 | 適合長會話、Agent 等 |
| 緩存命中讀取 | 0.1x 基礎輸入價 | 折扣 90% |
| 啓用費用 | 0 | 無額外開通費 |
| 配置改動 | 必須加 cache_control |
顯式 opt-in |
舉一個直觀的例子:Claude Opus 4.7 基礎輸入價 $5/1M,5min 寫入即 $6.25/1M、1h 寫入即 $10/1M,命中讀取僅 $0.50/1M。這一價格表寫在 Anthropic 官方文檔裏,已穩定多個季度。
Claude 緩存的最小 token 閾值
Claude 的最小可緩存 token 數因模型而異,這是很多人踩的第一個坑。
| 模型 | 最小可緩存 tokens |
|---|---|
| Claude Opus 4.7 / 4.6 / 4.5 | 4096 |
| Claude Haiku 4.5 | 4096 |
| Claude Sonnet 4.6 | 2048 |
| Claude Sonnet 4.5 / Opus 4.1 / Sonnet 4 | 1024 |
如果你的穩定前綴不到該模型的最小閾值,即便加了 cache_control 也不會真正進入緩存層,請求會被靜默處理爲非緩存路徑——不會報錯,但你以爲開了緩存其實沒開。這點在 Opus 4.7 上尤其重要:4096 tokens 是個不低的門檻,簡短的對話場景幾乎用不上。
🎯 模型選型建議:如果業務上下文長度不穩定,建議優先選 Claude Sonnet 4.5 或 4.6,最小閾值更低、命中更容易。通過 API易 apiyi.com 可以一鍵切換 Sonnet 與 Opus,避免因爲模型閾值問題導致緩存形同虛設。
Claude 緩存的 breakpoint 與併發限制
Claude 允許在一條請求中設置最多 4 個 cache breakpoint,不同斷點可以指定不同 TTL。這是 Claude 區別於 GPT 的最強能力——你可以讓"系統提示詞"用 1 小時緩存、"知識庫片段"用 5 分鐘緩存、"用戶上下文"不緩存,三段獨立計費、獨立失效。
併發場景下要特別注意一點:Claude 的緩存條目只有在第一次響應開始返回後纔對其他請求生效。如果你並行發了 N 個相同前綴的請求,只有第一個會寫緩存,其餘 N-1 個仍按基礎價計費,沒有命中折扣。所以批量調用時需要先發一發觸發緩存寫入,再並行剩餘請求。
🎯 批量調用建議:通過 API易 apiyi.com 調用 Claude 時,建議在發起併發批次前,先單發一條"熱身"請求觸發緩存寫入,等其響應開始後再放併發,可避免重複寫入溢價,能省下不少預算。
寫入溢價對真實賬單的影響:盈虧平衡點測算
這一節把抽象的倍率換算成具體錢數。我們假設一段 10,000 tokens 的穩定系統提示詞,在 1 小時窗口內被請求 N 次,輸出統一爲 500 tokens,看兩家在不同 N 下的總成本。
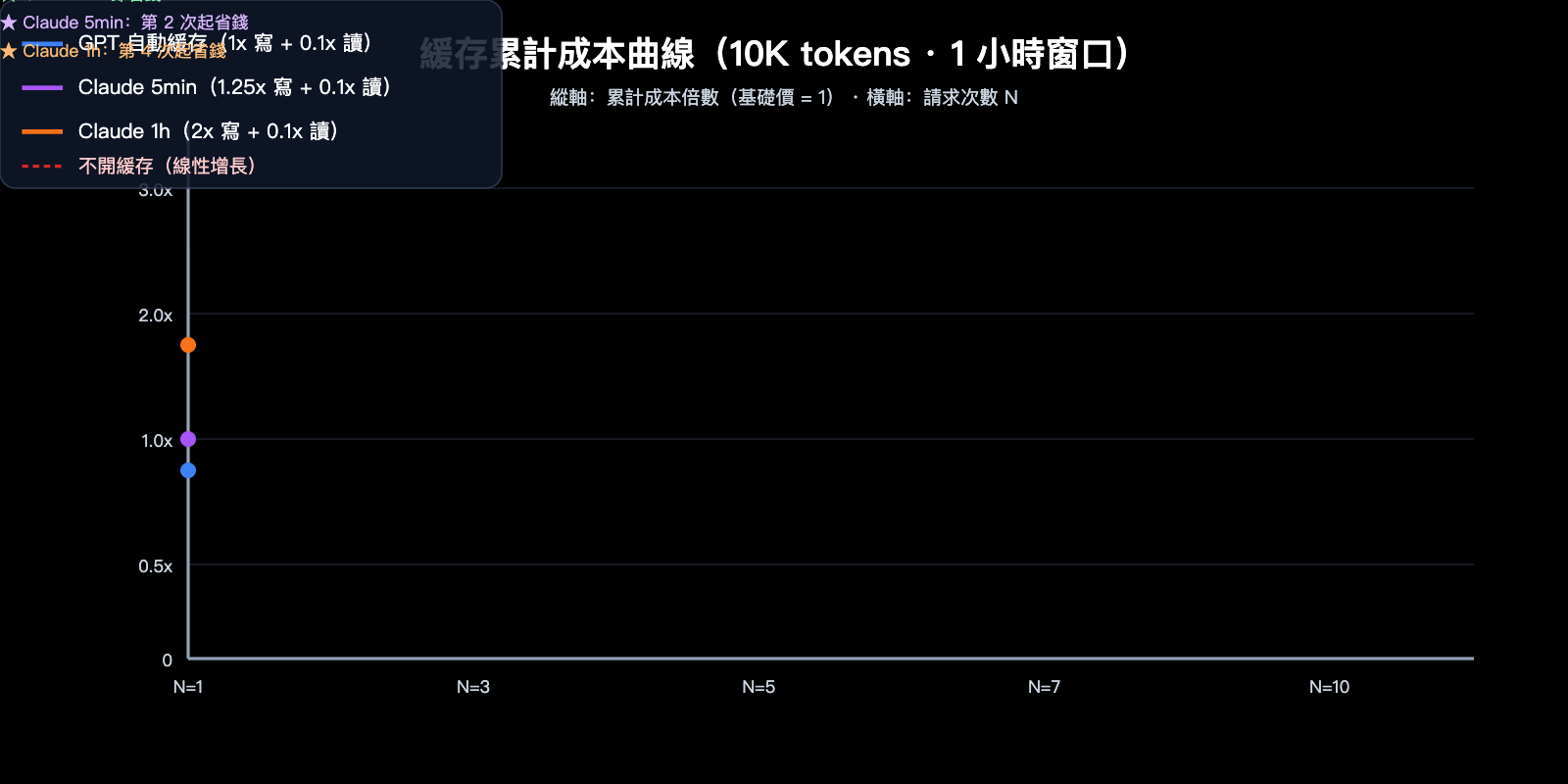
爲了便於對比,假設兩家基礎輸入價均歸一化爲 $X/1M tokens。10,000 tokens 單次基礎成本 = 10 × $X / 1000 = $0.01X。下面只看輸入端緩存計費部分,忽略輸出(輸出按各家自家價算)。
| 請求次數 N | GPT 自動緩存 | Claude 5min 緩存 | Claude 1h 緩存 |
|---|---|---|---|
| N=1(首次寫入) | $0.01X | $0.0125X | $0.02X |
| N=2 | $0.011X | $0.0135X | $0.021X |
| N=5 | $0.014X | $0.0165X | $0.024X |
| N=10 | $0.019X | $0.0215X | $0.029X |
| 不開緩存(參照) | $0.01X × N | $0.01X × N | $0.01X × N |
| 回本所需讀取次數 | 0 次(首次起省錢) | 1 次(第 2 次起省錢) | 3 次(第 4 次起省錢) |
可以看到一個關鍵事實:GPT 緩存在 N=1 就已經不虧了——因爲寫入按 1x 收費、命中時再打折,永遠都是賺的。Claude 5min 緩存需要至少 1 次命中才能把 0.25x 的寫入溢價攤回來,1h 緩存則要 3 次命中。如果你的某段穩定前綴一天內只命中 1 次,用 Claude 1h 緩存反而比不開緩存更貴。
真實業務裏如何選 TTL
這個測算給出的實操建議非常清晰:
- 頻次低、不規則:優先 GPT 自動緩存,無腦省。
- 頻次高、5 分鐘內多次命中(如客服會話、Web 應用):Claude 5min 緩存收益最大化,寫入溢價小、讀取折扣狠。
- 長任務、跨小時多次複用(如 Coding Agent、長文檔對話):Claude 1h 緩存值得,但要保證至少 3 次命中。
- 不確定命中率:永遠先按 5min 跑,跑通後再考慮切 1h。
🎯 測算建議:API易 apiyi.com 後臺提供按請求維度的 cached_tokens 字段統計,可以直接看出你的真實命中率。建議先跑一週生產流量,再決定是否激進地把 TTL 拉到 1 小時。
不同業務場景下的緩存策略推薦
理解了計費差異之後,落到具體業務上纔有意義。這裏把常見場景按推薦策略歸類。

場景一:高頻 RAG 與企業知識問答
這類場景的穩定前綴通常包含系統提示詞 + 知識庫片段,單次會話內多輪命中,5 分鐘內累計請求數輕鬆破 10。Claude 5min 緩存在這種場景下能壓低 80% 以上的輸入成本,最划算。如果是 1 小時長會話,可考慮 1h 緩存。
場景二:編程 Agent 與長任務工作流
像 Claude Code、OpenCode 這類編碼 Agent,單次任務可能持續半小時甚至幾小時,期間反覆讀取項目結構、CLAUDE.md、之前的工具調用結果。這種場景下 Claude 1h 緩存是最優解,因爲命中次數遠高於 3 次的盈虧平衡點。
場景三:低頻或不可預測請求
例如週期性腳本、批量 SEO 文章生成、一次性長文檔摘要,每次請求間隔可能遠超 5 分鐘。建議優先用 GPT 系列加自動緩存,命中就賺、不命中也不虧,比 Claude 顯式緩存的容錯性高得多。
場景四:成本敏感的純輸入壓縮
如果你的核心目標是把 10K+ token 的提示詞壓成最低成本,建議直接用 Claude Sonnet 4.6 + 5min 緩存:寫入溢價僅 25%,命中後只要 1 次即可回本,讀取價格壓到 $0.075/1M(基礎 $3 × 0.025)這種程度。
| 業務場景 | 推薦模型族 | 推薦 TTL | 原因 |
|---|---|---|---|
| 客服/RAG/即時問答 | Claude Sonnet | 5 分鐘 | 命中頻繁,回本快 |
| 編程/長 Agent 任務 | Claude Sonnet/Opus | 1 小時 | 跨小時命中超過 3 次 |
| 週期性腳本/批處理 | GPT-4.1 / GPT-5.x | 自動 | 命中不穩定,零寫入溢價 |
| 一次性長文檔分析 | GPT-5.x | 自動 | 單次任務,命中率低 |
| 純成本敏感場景 | Claude Sonnet 4.6 | 5 分鐘 | 最低有效緩存價 |
🎯 混合架構建議:在生產環境裏,GPT 與 Claude 不是二選一,而是按場景搭配。建議通過 API易 apiyi.com 單一入口同時接入兩家模型,前端按業務流量動態路由:高命中走 Claude 緩存,低命中走 GPT 自動緩存,整體賬單可壓低 40% 以上。
常見問題 FAQ
Q1:GPT 真的不收緩存寫入溢價嗎?是不是隱藏在某個費用裏?
是的,OpenAI 官方文檔原話:「No. Caching happens automatically, with no explicit action needed or extra cost paid to use the caching feature.」緩存寫入按基礎輸入價計費,沒有任何隱性溢價。你只爲命中部分付折扣價,未命中部分按基礎價付,相當於"白送"了緩存功能。
Q2:Claude 的 1.25x 與 2x 寫入溢價是按整段提示詞算還是隻算緩存部分?
只算被 cache_control 標記進緩存的部分。例如 10K 提示詞中只有 8K 被標記緩存,那 1.25x 溢價僅作用於這 8K,剩下 2K 仍按 1x 基礎價。所以建議精細化設置 breakpoint,避免把不必要的內容也捲入溢價。
Q3:APIYI 中轉站對兩家的緩存計費是否完全透傳?
API易 apiyi.com 對 GPT 與 Claude 的緩存計費保持原生透傳。GPT 自動緩存的命中折扣、Claude 顯式緩存的 1.25x/2x 寫入與 0.1x 讀取,賬單端均與官方一致。cache_control 字段也支持透傳,開發者可以直接複用官方 SDK 代碼。
Q4:什麼時候用 Claude 1h 緩存反而比不開緩存更虧?
當 1 小時窗口內的實際命中次數 < 3 次時,1h 緩存(2x 寫入)的溢價攤不回來。比如某段提示詞只在用戶首次和退出時各請求一次,全天就 2 次,開 1h 緩存比不開緩存還要多花 1x 的寫入溢價。這種場景下要麼改用 5min 緩存、要麼徹底關掉緩存。
Q5:GPT 的自動緩存是否會泄露我的提示詞數據?
OpenAI 文檔明確說明緩存按 organization 維度隔離,不會跨賬號共享。Claude 自 2026-02-05 起進一步收緊到 workspace-level 隔離。兩家在數據安全上的承諾基本一致,企業級用戶可以放心使用。通過 API易 apiyi.com 接入時,令牌維度的隔離也會進一步加強這一保護。
Q6:緩存命中率怎麼監控?兩家都有暴露字段嗎?
OpenAI 在 usage 對象裏返回 cached_tokens 字段,Claude 在 usage 裏返回 cache_creation_input_tokens 和 cache_read_input_tokens。前者表示緩存寫入量、後者是命中量。建議把這兩個字段寫入業務日誌,做命中率儀表盤後再調整 TTL 策略。
Q7:如果項目同時用 GPT 和 Claude,建議怎麼配置令牌?
推薦用 API易 apiyi.com 的統一令牌方案,一把 sk-xxx 同時覆蓋 GPT 與 Claude。後臺賬單可分模型查看,避免在兩家分別開賬號、分別管理餘額、分別對賬的麻煩。這種統一接入還方便做 A/B 切換,比較兩邊在同一業務上的實際成本。
總結:理解寫入溢價是緩存優化的第一步
回到本文的核心論點:GPT 與 Claude 緩存計費的本質差異是寫入側的溢價模型——GPT 選擇"零摩擦自動啓用、寫入不溢價",Claude 選擇"顯式控制、用寫入溢價換更細粒度的折扣空間"。兩種路線沒有絕對優劣,關鍵是匹配業務流量特徵。
如果你的應用屬於高命中、穩定流量、需要精細控制的場景,Claude 的 1.25x / 2x 寫入溢價可以靠高命中率輕鬆攤銷,5min/1h 雙 TTL 提供了 GPT 沒有的靈活性。如果你的應用屬於低命中、突發流量、追求開箱即用的場景,GPT 的自動緩存零溢價模型就是最穩妥的選擇。
🎯 最終建議:成本優化的最佳實踐是不要二選一。建議通過 API易 apiyi.com 同時接入兩家模型,按業務場景路由——高頻走 Claude 緩存擠折扣,低頻走 GPT 自動緩存防風險。一把令牌、一份賬單,輕鬆對比,是 2026 年技術團隊最高效的成本管理姿勢。
— APIYI 技術團隊 | 持續追蹤大模型計費動態,更多深度對比見 API易 apiyi.com 幫助中心