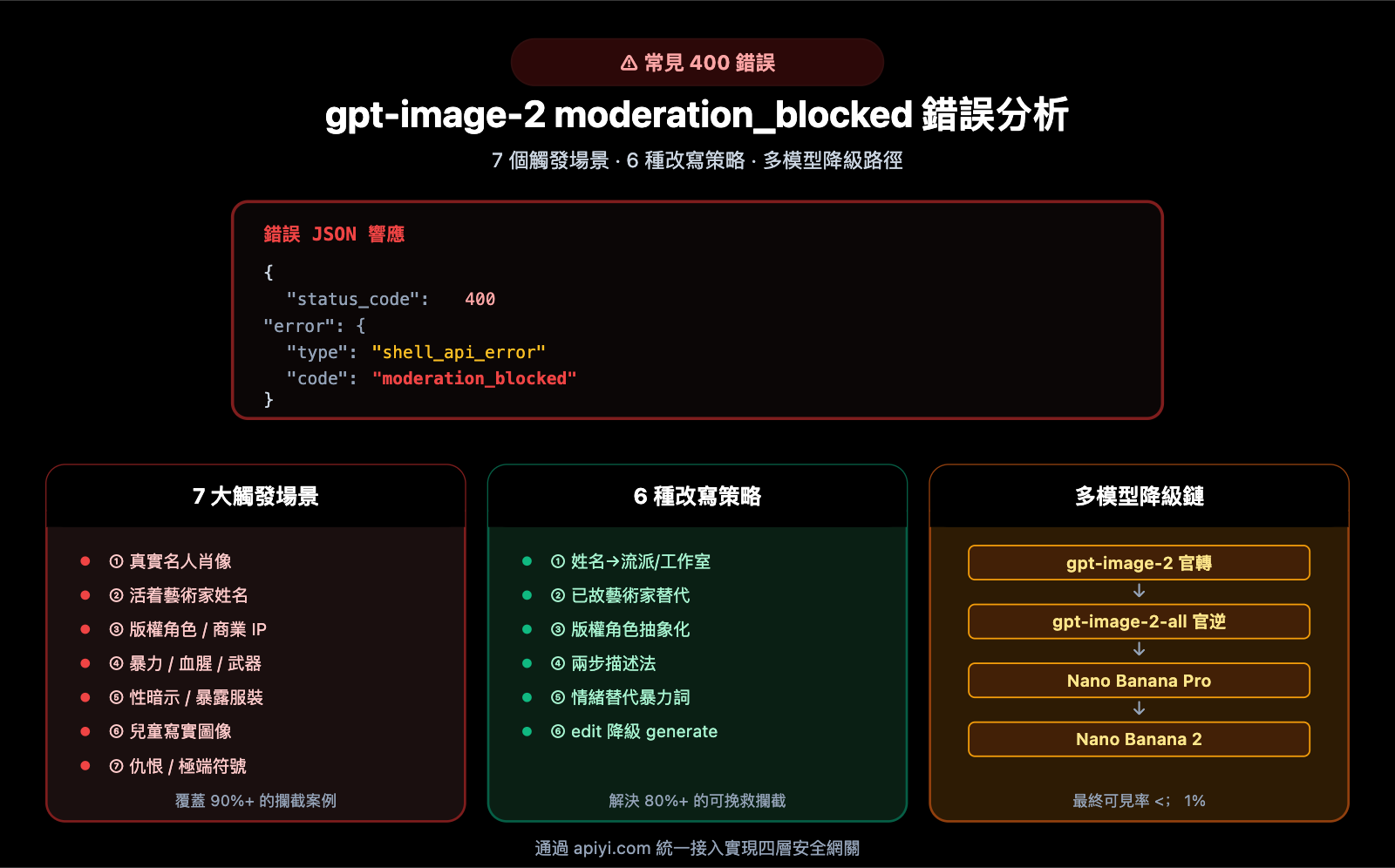
在使用 gpt-image-2 API 生產級出圖時,開發者經常會遭遇這樣一個令人困惑的 400 錯誤:
{
"status_code": 400,
"error": {
"message": "Your request was rejected by the safety system. If you believe this is an error, contact us at Azure support ticket and include the request ID 76fd2cbc-63ee-4e30-8bea-5fc2a2e1faa3.",
"type": "shell_api_error",
"code": "moderation_blocked"
}
}
這個 moderation_blocked 錯誤來自 OpenAI/Azure 的內容安全系統,它在模型推理之前或之後 主動攔截 認爲違反政策的請求。與普通的 429 限流或 500 服務錯誤不同,moderation_blocked 不會自動消失——不改 prompt,重試一萬次還是一樣被攔。
本文系統梳理 moderation_blocked 錯誤的技術原理、7 大常見觸發場景、診斷與復現方法,並給出 6 種提示詞改寫策略 + 多模型備用方案,幫助你把這類錯誤的發生率降到可接受水平。
一、gpt-image-2 moderation_blocked 400 錯誤的技術原理
1.1 錯誤結構拆解
上面那段錯誤體包含幾個關鍵字段:
| 字段 | 含義 |
|---|---|
status_code: 400 |
HTTP 400 Bad Request,說明客戶端請求被拒 |
type: shell_api_error |
API 網關層錯誤,而非模型推理錯誤 |
code: moderation_blocked |
核心錯誤碼: 被內容安全系統攔截 |
message |
人類可讀的說明,含 request id |
request id |
申訴或排查時的追蹤 ID |
注意 message 裏提到了 "Azure support ticket"——這是一個重要線索: 某些 gpt-image-2 部署鏈路最終由 Azure OpenAI 承載,所以安全系統是 Azure 的內容過濾器。Azure 的過濾規則比直連 OpenAI 更嚴格,這也是許多開發者在不同渠道下 moderation_blocked 觸發率差異很大的根本原因。
1.2 gpt-image-2 的兩階段內容過濾機制
根據 OpenAI 官方 ChatGPT Images 2.0 System Card 和 Azure OpenAI 文檔,gpt-image-2 的內容審查採用 兩階段過濾:
用戶請求
↓
【階段一: 輸入過濾 Input Filter】
↓ (通過)
模型推理生成圖片
↓
【階段二: 輸出過濾 Output Filter】
↓ (通過)
返回圖片給用戶
階段一 (Input Filter): 在模型推理之前,對 prompt 文本 + 參考圖像做分類檢測。使用神經多類分類器,檢測違反 OpenAI 政策的內容(仇恨、暴力、性、自殘、名人、版權等)。
階段二 (Output Filter): 圖像生成後再次掃描,即使 prompt 合法,如果生成出來的圖"看起來"違規,依然會被攔截。
關鍵差異:
- 如果報錯是
"Your request was rejected"→ 輸入階段被攔,改 prompt 可解 - 如果報錯是
"Generated image was filtered"→ 輸出階段被攔,需要重寫整個場景
本文討論的 moderation_blocked 屬於第一種——輸入階段被攔,意味着從 prompt 層面優化仍然是最有效的解決方式。
1.3 gpt-image-2 的 edit 端點過濾更嚴格
一個容易被忽視的事實: /v1/images/edits 端點的過濾策略比 /v1/images/generations 更嚴。
Azure 官方明確說明: 對圖像編輯,會在生成過濾基礎上增加額外安全檢查,意味着 同一個 prompt + 圖像,在 generation 端點能過,在 edits 端點卻可能被 moderation_blocked 攔。這是設計上的故意行爲,用於防止用戶對已有照片做違規修改(如 deepfake、去衣等)。

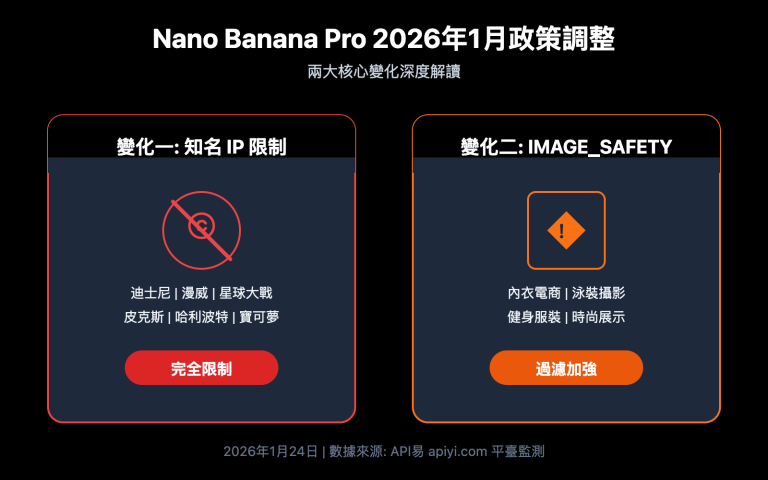
二、gpt-image-2 moderation_blocked 錯誤的 7 大觸發場景
以下 7 大場景按實際觸發頻率排序,覆蓋了 90%+ 的 moderation_blocked 案例。
2.1 觸發場景一: 真實人物肖像與名人姓名
這是最常見的觸發原因。任何以下形式的 prompt 都極易觸發:
❌ 高風險模式:
- 生成馬斯克在火星上的照片
- 一張特朗普和奧巴馬的合影
- Taylor Swift 演唱會的舞臺
- 模仿 Scarlett Johansson 的女演員
OpenAI 默認對 未 opt-out 的名人肖像 採取嚴格保護。2025 年 10 月 Bryan Cranston 事件後,這一策略進一步收緊。即使你要生成的是"長得像某人"而非直接用名字,只要 prompt 裏提到公衆人物名字,就會被攔。
2.2 觸發場景二: 名牌活着的藝術家與風格化表達
活着的藝術家/創作者的 姓名 是強攔截詞:
❌ 高風險:
- 宮崎駿 (Hayao Miyazaki) 風格插畫
- 新海誠 (Makoto Shinkai) 色調的城市夜景
- Banksy 風格的街頭塗鴉
✅ 低風險等價寫法:
- 吉卜力 (Ghibli) 風格 / 明亮的現代日式動畫風格
- 色彩飽和的日式青春動畫場景
- 現代城市街頭藝術風格
規則: 把"藝術家姓名"轉成"流派/工作室/風格名"。已故藝術家(Van Gogh, Monet)通常不會被攔。
2.3 觸發場景三: 版權角色與商業 IP
迪士尼、漫威、宮崎駿、皮克斯、任天堂等 IP 下的具名角色是硬攔截:
❌ 高風險:
- 蜘蛛俠在城市間盪漾
- 米奇老鼠的派對場景
- 一隻皮卡丘在森林裏
✅ 低風險等價寫法:
- 一位穿紅藍超級英雄裝、用絲線在霓虹都市中擺盪的原創義警角色
- 一隻卡通擬人鼠標主持的復古派對
- 一隻黃色電系卡通生物在森林裏
規則: "靈感來自"或"類似風格"而不是直接命名角色。
2.4 觸發場景四: 暴力、血腥、武器細節
❌ 高風險:
- 流血的傷口特寫
- 爆炸瞬間的血肉飛濺
- AK-47 的精細產品圖
✅ 規避寫法:
- 深紅色顏料飛濺的抽象畫面
- 明亮光芒迸發伴隨碎片的超級英雄場景
- 戰術遊戲中的武器概念圖 (風格化,非寫實)
規則: 用"藝術化、抽象化、風格化"替代"寫實、精細、臨牀式"描述。
2.5 觸發場景五: 性暗示與暴露服裝
這是 gpt-image-2 最嚴格的領域之一,任何可被解讀爲性暗示的內容 都會攔,包括看似無害的描述:
❌ 高風險 (看似無害但會攔):
- bikini 比基尼海灘場景
- 裸露肩膀的女性
- 緊身衣緊貼身材
- 誘人的姿態
✅ 規避寫法:
- 夏季海灘度假場景,人物遠景
- 穿優雅晚禮服的女性
- 時尚雜誌風格的運動裝寫真
- 自信的模特姿態
規則: 避開"緊身、裸露、性感、誘惑"等形容詞,改用"優雅、時尚、自信"等中性詞彙。
2.6 觸發場景六: 兒童相關的寫實圖像
OpenAI 對兒童的寫實化生成採取近乎零容忍政策。任何以下寫法都會攔:
❌ 高風險:
- 一個 8 歲小女孩的寫實照片
- 穿泳衣的兒童在游泳池邊
- 嬰兒的細節特寫寫真
✅ 安全寫法:
- 一幅卡通風格的童年場景插畫
- 寫實的家庭場景遠景,不聚焦任何個人
- 母親抱着嬰兒的藝術化插畫
規則: 兒童相關 儘量用插畫/卡通風格,避免"寫實、特寫、精細、照片級"等詞。
2.7 觸發場景七: 仇恨、極端政治、敏感符號
仇恨符號、極端政治圖騰、宗教衝突性描繪都是硬攔:
❌ 高風險:
- 納粹萬字符
- 極端政治對立場景
- 特定國家的衝突敘事
這類內容幾乎沒有 prompt 改寫的空間,建議 徹底繞開這個選題方向。
三、gpt-image-2 moderation_blocked 錯誤的診斷流程
3.1 診斷流程圖

當收到 moderation_blocked 錯誤時,按以下流程診斷:
Step 1. 記錄完整 error message + request id
↓
Step 2. 判斷是 "rejected" (輸入攔) 還是 "filtered" (輸出攔)
↓
Step 3. 對照 7 大觸發場景定位原因
↓
Step 4. 逐步刪減 prompt 關鍵詞做二分法復現
↓
Step 5. 選擇對應的改寫策略 (見第四章)
↓
Step 6. 改寫後重試,記錄成功率變化
3.2 prompt 二分法復現觸發詞
當不確定 prompt 中哪個詞觸發了攔截,可以用二分法:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
def binary_search_trigger(full_prompt: str):
"""用二分法找到觸發 moderation_blocked 的關鍵詞"""
words = full_prompt.split()
mid = len(words) // 2
left_half = " ".join(words[:mid])
right_half = " ".join(words[mid:])
for test_prompt in [left_half, right_half]:
try:
client.images.generate(
model="gpt-image-2",
prompt=test_prompt,
size="1024x1024",
quality="low",
n=1
)
print(f"✓ 通過: {test_prompt[:40]}...")
except Exception as e:
if "moderation_blocked" in str(e):
print(f"✗ 觸發: {test_prompt[:40]}...")
binary_search_trigger("原始的 prompt 內容 ...")
通過 API易 apiyi.com 運行這個腳本,用 quality="low" 把每次測試成本降到最低($0.006/張),快速定位觸發詞。
3.3 用 OpenAI Moderations API 預檢
OpenAI 提供了免費的 /v1/moderations 端點,可以在正式調用圖像生成前 預檢 prompt 文本 是否會被攔:
def pre_check_prompt(prompt: str):
result = client.moderations.create(
model="omni-moderation-latest",
input=prompt
)
categories = result.results[0].categories
scores = result.results[0].category_scores
flagged_categories = [
(cat, scores.model_dump()[cat])
for cat, flagged in categories.model_dump().items()
if flagged
]
if flagged_categories:
print(f"⚠️ Prompt 被標記: {flagged_categories}")
return False
return True
注意: 預檢 只能檢查文本維度,無法檢測版權名人等"語義判斷"類攔截。但對"暴力、性、仇恨"等明顯違規詞有高準確率。
四、gpt-image-2 moderation_blocked 錯誤的 6 種提示詞改寫策略
4.1 策略一: 姓名替換爲流派或工作室
| 原寫法 | 改寫 |
|---|---|
| 宮崎駿風格 | 吉卜力 / 明亮現代日式動畫風格 |
| 新海誠風格 | 飽和色彩日式青春動畫 |
| 迪士尼風格 | 經典美式卡通風格 |
| 安妮海瑟薇 | 一位 35 歲優雅的女演員 |
| 馬斯克 | 一位穿西裝的科技公司創始人 |
4.2 策略二: 已故藝術家替代活着藝術家
活着藝術家 → 同流派已故藝術家:
| 活着藝術家 (攔) | 已故藝術家 (不攔) |
|---|---|
| Banksy 風格塗鴉 | Basquiat 風格塗鴉 / 80 年代街頭藝術 |
| 新海誠風格 | (直接用"日式動畫風格") |
| Hayao Miyazaki | (用"吉卜力") |
| 村上隆 | 波普藝術風格 / Andy Warhol 風格 |
Van Gogh、Monet、Picasso、Rembrandt、Hokusai 等經典大師都是安全的參考。
4.3 策略三: 版權角色抽象化
把具名 IP 抽象成 "通用特徵 + 敘事描述":
原寫法: 蜘蛛俠在紐約上空蕩漾
改寫: 一位穿紅藍緊身超級英雄服、戴面具、用絲線在霓虹都市摩天大樓間擺盪的年輕人,充滿動感與活力
原寫法: 皮卡丘在森林裏
改寫: 一隻圓潤可愛的黃色電系卡通生物,有紅色臉頰,尖耳朵,在茂密的綠色森林中跳躍
核心技巧: 保留視覺特徵,移除名字。
4.4 策略四: 兩步描述法 (Two-Step Description)
對複雜的、可能踩線的場景,用兩步法:
Step 1: 先讓 Gemini Pro 或 Claude 4 Sonnet 把你的原始想法"翻譯"成 純視覺元素描述,主動剝離所有名人/IP/敏感詞。
Step 2: 把 Step 1 的輸出作爲 gpt-image-2 的實際 prompt。
def two_step_generate(raw_idea: str):
rewriter_response = client.chat.completions.create(
model="gemini-3-pro",
messages=[
{
"role": "system",
"content": (
"你是視覺描述專家。將用戶想法重寫爲純視覺元素描述:"
"移除所有真實人名、品牌名、版權角色名、敏感詞;"
"保留: 顏色、構圖、光照、動作、氛圍、材質、鏡頭。"
"輸出一段 150-250 字的連貫敘述,不要列表。"
)
},
{"role": "user", "content": raw_idea}
]
)
safe_prompt = rewriter_response.choices[0].message.content
return client.images.generate(
model="gpt-image-2",
prompt=safe_prompt,
size="1024x1024",
quality="medium"
)
這種方法藉助 API易 apiyi.com 的多模型統一接入,用文本 LLM 做前置"安全淨化層",大幅降低圖像 API 的 moderation_blocked 觸發率。
4.5 策略五: 情緒/氛圍替代暴力/性詞彙
| 原詞 | 中性替代 |
|---|---|
| 血腥 (bloody) | 深紅色調 / 戲劇性 |
| 暴力 (violent) | 激烈 / 富有張力 |
| 性感 (sexy) | 優雅 / 自信 / 有魅力 |
| 裸露 (naked/nude) | 古典雕塑風格 / 藝術人體 |
| 誘惑 (seductive) | 迷人的氣質 |
| 殺戮 (killing) | 戲劇性對抗 |
| 武器 (weapon) | 道具 / 工具 |
4.6 策略六: 改用 edit 端點時降級爲 generate 端點
前文提到 edits 端點過濾更嚴。如果你的任務是"在現有圖基礎上改",可以嘗試:
原流程: /v1/images/edits (被攔)
替代流程:
- 用 LLM 描述原圖的視覺元素
- 加上"修改點"
- 走
/v1/images/generations重新生成
雖然犧牲了像素級一致性,但能規避掉嚴格的編輯過濾。
五、gpt-image-2 moderation_blocked 錯誤的多模型備用方案
單一模型遇到硬攔截時,多模型路由 是企業級應用的標準做法。
5.1 圖像模型過濾嚴格度對比
| 模型 | 過濾嚴格度 | 名人允許度 | IP 允許度 | 藝術表現度 |
|---|---|---|---|---|
gpt-image-2 官轉 |
🔴 嚴格 | 極嚴 | 嚴 | 偏保守 |
gpt-image-2-all 官逆 |
🟡 中等 | 中等 | 中 | 較靈活 |
| Nano Banana Pro | 🟢 較寬鬆 | 中 | 中 | 靈活 |
| Nano Banana 2 | 🟢 較寬鬆 | 中 | 中 | 靈活 |
| Imagen 系列 | 🟡 中等 | 嚴 | 中 | 中 |
實務建議: 當 gpt-image-2 官轉攔截時,可以依次降級嘗試:
gpt-image-2 (官轉) [moderation_blocked]
↓
gpt-image-2-all (官逆) [可能通過]
↓
Nano Banana Pro [較大概率通過]
↓
Nano Banana 2 [最靈活,質量略低]
5.2 自動降級代碼示例
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
MODEL_FALLBACK_CHAIN = [
("gpt-image-2", "images"),
("gpt-image-2-all", "chat"),
("gemini-3-pro-image-preview", "images"),
("gemini-3.1-flash-image-preview", "images"),
]
def generate_with_fallback(prompt: str):
last_error = None
for model_id, endpoint in MODEL_FALLBACK_CHAIN:
try:
if endpoint == "images":
return client.images.generate(
model=model_id,
prompt=prompt,
size="1024x1024"
)
else:
return client.chat.completions.create(
model=model_id,
messages=[{"role": "user", "content": prompt}]
)
except Exception as e:
if "moderation_blocked" in str(e) or "content_policy" in str(e):
print(f"模型 {model_id} 攔截,嘗試下一個")
last_error = e
continue
raise
raise Exception(f"所有模型都攔截,最後錯誤: {last_error}")
這個模式的核心價值: 在同一個 API易 apiyi.com 賬號下,通過簡單改 model 參數就實現了多模型降級,無需註冊多家服務、無需管理多套 credentials。
5.3 按內容類型路由的高級策略
更精細的做法是 按內容類型預判最合適的模型:
| 內容類型 | 首選模型 | 理由 |
|---|---|---|
| 企業品牌物料 | gpt-image-2 官轉 | 穩定、合規 |
| 帶中文文字的海報 | gpt-image-2-all 官逆 | 中文原生優化 |
| 可能含 IP 的創意圖 | Nano Banana Pro | 過濾較寬鬆 |
| 批量快速出圖 | Nano Banana 2 | 速度快、成本低 |
| 特殊風格藝術圖 | Nano Banana Pro | 藝術表現靈活 |
六、gpt-image-2 moderation_blocked 企業級申訴流程
當確信 prompt 是合法的、不應該被攔(誤報)時,可以走申訴流程。
6.1 申訴必備信息清單
提交申訴前,收集以下信息:
- 完整 error response (含 request id)
- 觸發 moderation_blocked 的完整 prompt
- 調用時間戳
- 你的賬戶 ID
- 業務場景說明 (爲什麼需要這個 prompt)
- 復現步驟 (是否穩定復現)
6.2 申訴渠道

L1: 自助層 (最快)
先嚐試本文第四章的 6 種改寫策略,90%+ 的 moderation_blocked 可以在這一層解決,0 成本。
L2: API易 企業服務通道 (推薦)
對企業客戶,API易 apiyi.com 提供專屬技術對接,針對具體 moderation_blocked 案例提供:
- prompt 改寫建議
- 多模型降級方案設計
- 對接 OpenAI/Azure 的申訴流程
這一層響應快,且 API易 團隊在圖像模型的誤報申訴上積累了大量經驗,比自己對接官方工單效率高得多。
L3: 官方申訴 (最慢但最終有效)
通過 error message 中提到的 Azure support ticket 或 OpenAI 官方 Help Center 提交申訴,附上完整 request id。響應週期通常 3-10 個工作日。
6.3 系統性降低觸發率的工程實踐
對高頻調用的生產系統,建議構建一套 Prompt 安全網關:
用戶原始請求
↓
[1] 關鍵詞黑名單預篩 (秒級)
↓
[2] OpenAI Moderations API 預檢 (免費, 300ms)
↓
[3] 文本 LLM 改寫爲安全 prompt (可選, 1-2 秒)
↓
[4] 調用 gpt-image-2
↓
[5] 收到 moderation_blocked 時自動降級到備用模型
↓
返回結果
通過這 5 層防護,把 moderation_blocked 的 最終用戶可見率 降到 < 1%。
🎯 落地建議: 這套安全網關的所有外部調用(Moderations API、文本 LLM、多個圖像模型)都可以通過 API易 apiyi.com 單一接入點完成,統一計費、統一日誌,極大降低了工程複雜度。
七、gpt-image-2 moderation_blocked 常見問題 FAQ
Q1: 爲什麼同一個 prompt 今天能過,明天就被 moderation_blocked 了?
OpenAI 和 Azure 的安全分類器會 持續更新,尤其在有重大政策事件(如名人 opt-out)後會批量收緊。建議在生產系統裏記錄每次 moderation_blocked 的 prompt 快照,用於後續分析。
Q2: 我用 gpt-image-2-all (官逆) 能繞過 moderation_blocked 嗎?
部分場景可以,但不是萬能鑰匙。官逆鏈路也有自己的安全檢測,只是觸發閾值和規則略不同。對於特定類型的攔截(如名人姓名),兩個模型都會攔。推薦通過 API易 apiyi.com 在兩個模型間做 A/B 測試,找出對你的業務場景容忍度更高的那條路。
Q3: moderation_blocked 錯誤會扣費嗎?
不會。400 錯誤屬於客戶端錯誤,OpenAI 和 API易 都不會對被攔截的請求扣費。可以放心大膽地做 prompt 調試。
Q4: 爲什麼中文 prompt 觸發 moderation_blocked 的概率比英文高?
不是中文本身的問題,而是 中文 prompt 在翻譯成模型內部表徵時可能帶入意外的英文觸發詞。建議: (1) 在中文 prompt 裏避免直接命名名人/IP (2) 嘗試用 gpt-image-2-all,它對中文 prompt 有原生優化。
Q5: 我要生成自己員工的照片做內部使用,也會被攔嗎?
很可能會。OpenAI 的安全系統無法判斷"你是不是這個員工本人",只要識別爲真實人物肖像就會攔。建議走 edit 端點(上傳原圖 + mask 修改),或者用"風格化藝術處理"代替寫實照片。
Q6: 企業客戶可以申請降低過濾閾值嗎?
OpenAI 直連幾乎不可能,Azure OpenAI 部分企業合約可以申請調整 content filter 級別(需審批)。通過 API易 apiyi.com 的企業服務通道可以協助你對接 Azure 的審批流程,或者提供定製化的多模型方案來規避單點限制。
Q7: Nano Banana Pro 的過濾真的比 gpt-image-2 寬鬆嗎?
在大量實測中,Nano Banana Pro 對 藝術化表現 和 寬鬆 IP 指代 確實更寬容,但在兒童相關、性內容、極端暴力等核心禁區與 OpenAI 幾乎一致——沒有任何主流模型能繞過這些底線。
Q8: 錯誤信息裏的 Azure support ticket 是什麼意思?
說明底層鏈路經過 Azure OpenAI。不同中轉服務對接的後端不同,有的直連 OpenAI,有的走 Azure。不同後端的過濾嚴格度略有差異,這也是爲什麼同一 prompt 在不同服務商上表現不一致。
八、總結: gpt-image-2 moderation_blocked 錯誤的應對心法
回到開頭那段錯誤體,現在我們清楚地知道:
- 錯誤本質:
moderation_blocked不是模型能力問題,而是安全分類器在 模型推理之前 主動攔截。 - 錯誤不可重試: 不改 prompt,重試一萬次結果一樣。
- 7 大觸發場景: 名人 / 活着藝術家 / 版權 IP / 暴力 / 性暗示 / 兒童寫實 / 仇恨符號。
- 6 種改寫策略: 姓名替換 / 已故替活着 / 角色抽象化 / 兩步描述 / 情緒替暴力 / 降級 edit 端點。
- 多模型備用: gpt-image-2 → gpt-image-2-all → Nano Banana Pro → Nano Banana 2 的降級鏈。
- 工程化防護: 預檢 + 改寫 + 降級 + 申訴四層網關,把誤報可見率降到 < 1%。
對於正在用 gpt-image-2 做生產的團隊,推薦的 核心原則 是: 不要和安全系統硬剛,而是把 prompt 工程和多模型路由做成系統性能力。一個 moderation_blocked 錯誤,往往意味着你的 prompt 層或架構層還有 10 個類似錯誤在等着。
我們建議通過 API易 apiyi.com 的統一入口同時接入 gpt-image-2、gpt-image-2-all、Nano Banana Pro/2 等多個模型,在同一個賬號和代碼基下快速實現降級路由。這是把 moderation_blocked 從"業務中斷級故障"降維到"無感體驗優化"的最快路徑。
關於作者: APIYI 技術團隊,在圖像生成模型的企業級落地、內容安全申訴、多模型路由架構等領域積累了豐富經驗。訪問 API易官網 apiyi.com 獲取 gpt-image-2、gpt-image-2-all、Nano Banana Pro 等主流模型的接入方案,以及針對 moderation_blocked 等常見問題的企業級技術支持。