作者注:在模型正價不換廉價渠道的前提下,詳解 OpenClaw 如何通過控制輸入 Token 長度省錢:新對話隔離任務、精準檢索代碼塊代替全文塞入、上下文剪枝、QMD 本地搜索等 6 大策略
OpenClaw 費 Token 是出了名的——有用戶一天燒掉 2150 萬 Token,月賬單 $600+。很多人的第一反應是換廉價模型渠道,但這會犧牲質量。真正的省 Token 方法是控制輸入端——你餵給模型多少上下文,纔是成本的決定性因素。本文聚焦一個核心問題:在不換模型、不降質量的前提下,如何把輸入 Token 從"全文塞進去"降到"精準喂進去"。
核心價值: 讀完本文,你將掌握 6 個控制輸入 Token 的實戰策略,預期節省 50-90% 的 Token 成本。

OpenClaw 省 Token 核心要點
先明確一個前提:本文討論的是不換模型、不降質量的省 Token 方法。你用的是正價的 Claude Opus 4.6 或 GPT-5,模型不變,省的是輸入端。
| 策略 | 節省比例 | 實施難度 | 核心思路 |
|---|---|---|---|
| 新對話隔離任務 | 60-80% | 低 | 每個獨立任務開新對話,避免歷史積累 |
| 精準檢索代碼塊 | 40-95% | 中 | 只喂相關代碼片段,不塞全文 |
| 上下文剪枝 | 30-50% | 低 | 手動或自動清理無用對話歷史 |
| QMD 本地搜索 | 80-90% | 中 | 本地向量檢索,只發送相關片段 |
| Prompt Caching | 80-90%(輸入成本) | 低 | 利用緩存避免重複發送系統提示 |
| 關閉 Thinking 模式 | 10-50x | 低 | 非推理任務關閉思考模式 |
OpenClaw Token 消耗的底層機制
理解省 Token 的前提是理解 OpenClaw 爲什麼費 Token。
每一次你在 OpenClaw 中發送消息,它不是隻發送你這一條——而是把整個對話歷史全部重新發送給模型。對話越長,每次請求的輸入 Token 就越大。
具體來說,一次請求的輸入包含:
- 系統提示(System Prompt):OpenClaw 的核心指令,通常 2000-5000 Token
- AGENTS.md / SOUL.md:工作空間配置文件
- 加載的 Skills:每個啓用的 Skill 都佔 Token
- 完整對話歷史:從會話開始到現在的所有消息
- 工具調用結果:每次文件讀取、命令執行的輸出
- Memory 檢索結果:從記憶庫檢索的相關內容
一個持續 30 分鐘的 OpenClaw 會話,最後一條消息的輸入 Token 可能已經達到 10 萬甚至 100 萬——而前 29 分鐘的大部分內容對當前任務都不再有用。
策略一:OpenClaw 不同任務新開對話
這是最簡單也最有效的策略。
爲什麼新對話能省 Token
假設你在同一個會話裏做了 3 件事:修 Bug A → 寫功能 B → 重構模塊 C。到第三個任務時,模型的輸入包含了前兩個任務的所有對話歷史和文件讀取結果——但這些對重構模塊 C 完全沒用。
同一會話:
任務 A 對話歷史(20K Token)
+ 任務 A 文件內容(30K Token)
+ 任務 B 對話歷史(25K Token)
+ 任務 B 文件內容(40K Token)
+ 任務 C 當前消息(5K Token)
= 120K Token 輸入(其中 115K 都是歷史包袱)
新開會話:
任務 C 當前消息(5K Token)
+ 系統提示(3K Token)
= 8K Token 輸入(節省 93%)
在對話場景裏的最佳實踐
| 場景 | 是否新開會話 | 原因 |
|---|---|---|
| 切換到完全不同的任務 | 新開 | 前一個任務的上下文完全無用 |
| 同一功能的迭代調整 | 繼續 | 需要之前的討論上下文 |
| 修不同文件的不同 Bug | 新開 | 每個 Bug 獨立,不需要交叉上下文 |
| 同一模塊的連續修改 | 繼續 | 模型需要理解之前的修改意圖 |
| 對話超過 20 輪 | 新開或 compact | 歷史積累已經很多 |
🎯 實操建議: 一個簡單的判斷標準——如果你需要說"忘掉前面的,現在做另一件事",那就直接開新對話。
這個原則不僅適用於 OpenClaw,也適用於 Claude Code 和其他 AI 編碼工具。通過 API易 apiyi.com 調用的每次獨立 API 請求天然就是"新會話",不存在上下文積累問題。
策略二:OpenClaw 精準檢索代碼塊,不塞全文
這是本文的核心重點——如何只讓模型看到需要修改的代碼塊,而不是把整個文件甚至整個項目塞進去?
問題本質:"全文塞進去"爲什麼浪費
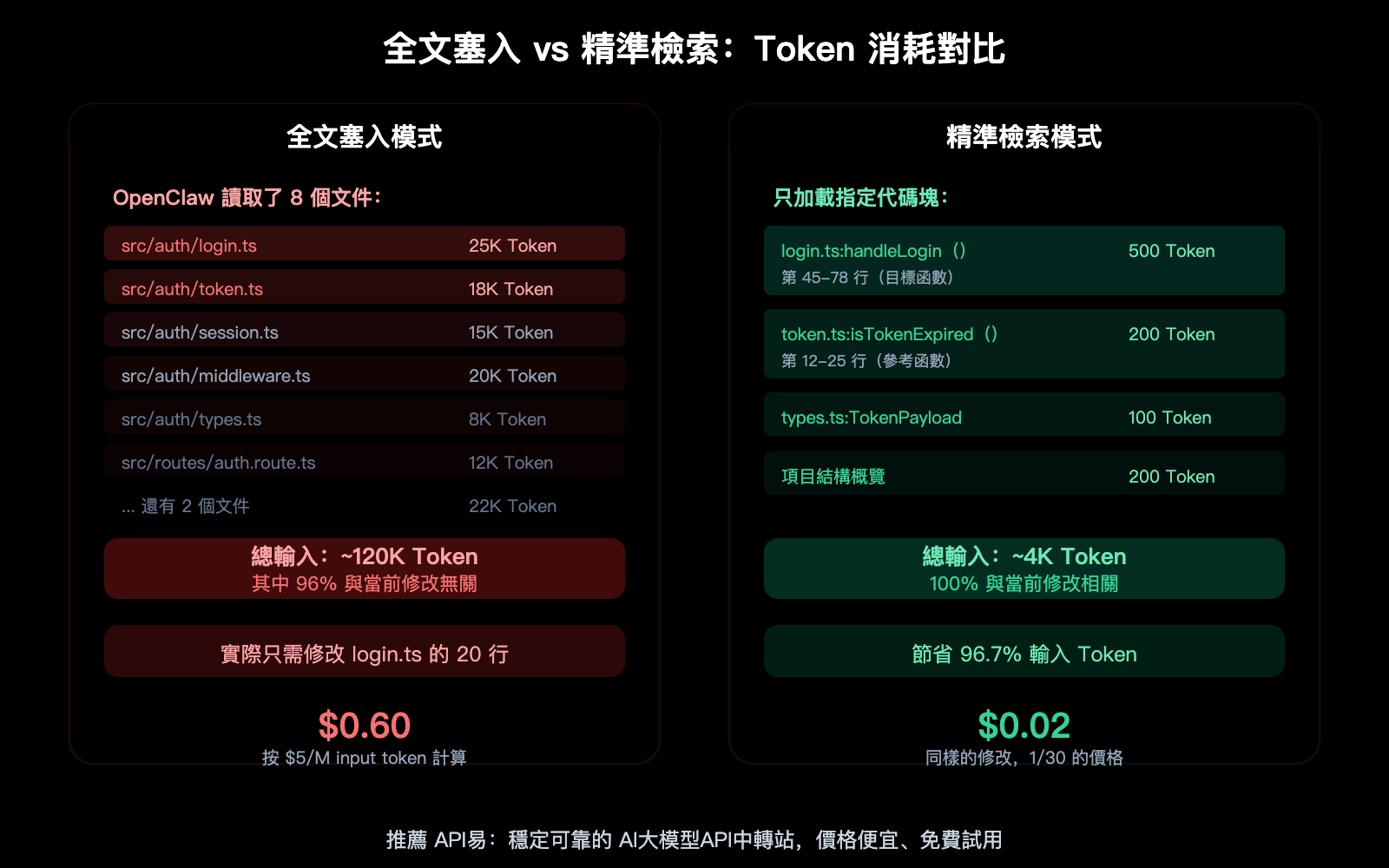
研究數據顯示,AI 編碼 Agent 有 80% 的 Token 浪費在"找東西"上。典型場景:你讓 OpenClaw 修改一個函數,它先讀了 25 個文件,只爲找到那 3 個真正相關的函數——讀取 25 個文件的 Token 成本全部算在你頭上。
一個 1000 行的文件大約 15,000-25,000 Token。如果你只需要修改其中的 20 行(約 300-500 Token),但整個文件都被餵給模型,那 96-98% 的輸入 Token 就浪費了。
OpenClaw 精準檢索代碼塊的 4 個方法
方法一:明確指定文件和行號
不要說"修改登錄功能",而是說"修改 src/auth/login.ts 的第 45-78 行 handleLogin 函數"。越精準的指令,OpenClaw 讀取的文件越少。
❌ "修復登錄 Bug"
→ OpenClaw 讀取 10+ 文件,消耗 200K+ Token
✅ "修復 src/auth/login.ts 第 52 行的空指針檢查"
→ OpenClaw 只讀 1 個文件的相關部分,消耗 ~20K Token
方法二:利用 QMD 本地語義搜索
OpenClaw 的 QMD(Quick Memory Database)可以在本地建立向量索引,檢索相關代碼片段後只發送最相關的內容給模型。
啓用方式:在 OpenClaw 設置中開啓 QMD,它會自動索引你的項目文件和對話歷史。後續查詢時,QMD 先在本地找到相關代碼塊,只把精準匹配的片段發送給模型。
方法三:使用 @file 語法定向引用
在 OpenClaw 中可以用 @file 語法精確引用文件,避免模型自行搜索:
修改 @src/auth/login.ts 中的 handleLogin 函數,
添加對 refreshToken 過期的處理邏輯。
參考 @src/auth/token.ts 中的 isTokenExpired 方法。
這樣 OpenClaw 只加載你指定的 2 個文件,而不是掃描整個 src/auth/ 目錄。
方法四:項目結構文件引導
在 AGENTS.md 或 SOUL.md 中寫明項目結構概覽,讓 OpenClaw 知道"哪個功能在哪個文件",減少探索式的文件掃描。
## 項目結構
- 認證相關: src/auth/ (login.ts, token.ts, session.ts)
- 用戶管理: src/user/ (profile.ts, settings.ts)
- API 路由: src/routes/ (auth.route.ts, user.route.ts)
這個概覽本身只佔幾百 Token,但能幫 OpenClaw 省掉數萬 Token 的盲目文件掃描。
策略三至六:OpenClaw 進階省 Token 技巧
策略三:上下文剪枝(Context Pruning)
OpenClaw 支持手動和自動的上下文剪枝。當對話過長時,可以清理掉不再需要的歷史消息。
OpenClaw 2026.3.7 引入了 Context Engine Plugins,允許第三方插件提供替代的上下文管理策略(之前這部分是硬編碼在覈心中的)。lossless-claw 插件可以在不丟失關鍵信息的前提下壓縮對話歷史。
實操建議:
- 每完成一個子任務後,手動清理無關的工具調用輸出
- 設置
contextTokens: 50000限制上下文窗口大小 - 使用 compact 功能壓縮對話歷史
策略四:QMD 本地語義搜索
QMD(Quick Memory Database)是 OpenClaw 的本地向量搜索功能。它在本地設備上建立向量數據庫,索引對話歷史和文檔。查詢時先在本地搜索相關內容,只把最相關的片段發送給模型。
效果:減少 80-90% 的輸入 Token 成本。
策略五:利用 Prompt Caching
Claude 和 GPT 模型家族都支持 Prompt Caching——當系統提示或常用上下文沒有變化時,API 自動使用緩存版本,輸入 Token 成本降低 80-90%。
但有一個關鍵限制: 通過 OpenAI 兼容格式(/v1/chat/completions)調用 Claude 時不支持 Prompt Caching,必須使用 Anthropic 原生格式(/v1/messages)。如果你通過 API易 apiyi.com 調用,平臺支持原生格式的 Prompt Caching。
策略六:非推理任務關閉 Thinking
Thinking/Reasoning 模式會讓 Token 消耗暴增 10-50 倍。如果當前任務不需要深度推理(比如簡單的格式化、文件移動、文本替換),關閉 Thinking 模式能大幅節省。
| 任務類型 | 是否需要 Thinking | Token 差異 |
|---|---|---|
| 複雜 Bug 分析 | 需要 | 正常消耗 |
| 架構設計 | 需要 | 正常消耗 |
| 簡單格式化 | 不需要 | 關閉後省 10-50x |
| 文件移動/重命名 | 不需要 | 關閉後省 10-50x |
| 生成樣板代碼 | 看情況 | 簡單模板可關閉 |
提示: Claude Code 的 Context Compaction 和 OpenClaw 的 Context Pruning 解決的是同一個問題——控制累積的輸入 Token。如果你同時使用兩個工具,可以通過 API易 apiyi.com 統一管理 API 調用額度。
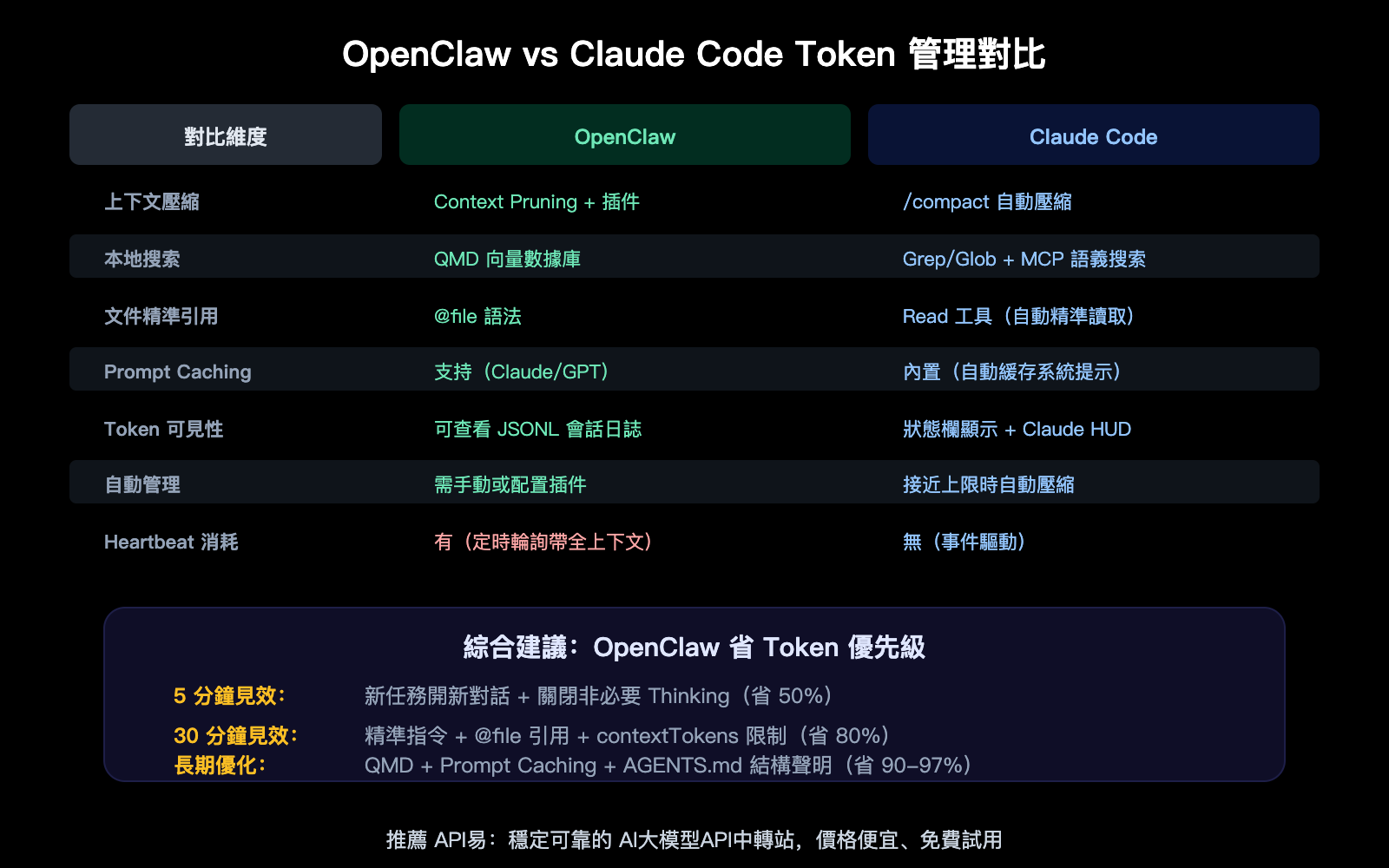
OpenClaw 與 Claude Code 省 Token 對比
兩個工具面對的問題一樣,但解決方案有差異。
常見問題
Q1: 新開對話後,模型不瞭解項目背景怎麼辦?
利用 OpenClaw 的 Memory 系統和 AGENTS.md 文件。Memory 會自動在新會話中檢索相關的項目背景信息(只發送最相關的片段,而不是全部歷史)。AGENTS.md 中寫好項目結構和關鍵約定,每次新會話自動加載——這比把 20 輪對話歷史全部帶入高效得多。
Q2: 怎麼知道當前會話的 Token 消耗了多少?
OpenClaw 的對話記錄保存在 .openclaw/agents.main/sessions/ 目錄下的 JSONL 文件中,你可以直接查看每次請求的 Token 數量。更方便的做法是使用 API 提供商的用量面板——通過 API易 apiyi.com 調用時,後臺可以看到每次請求的精確 Token 消耗和費用。
Q3: QMD 和直接用 grep 搜索有什麼區別?
grep 是精確匹配——你搜"handleLogin"只能找到包含這個字符串的地方。QMD 是語義搜索——你搜"用戶登錄的錯誤處理",它能找到所有語義相關的代碼塊,即使代碼中沒有"登錄"或"錯誤處理"這些字符串。語義搜索的精準度更高,送給模型的無關內容更少,省的 Token 更多。
Q4: Heartbeat 爲什麼會消耗大量 Token?
OpenClaw 的 Heartbeat(心跳)機制會定期檢查任務狀態。如果設置間隔太短(比如每 5 分鐘),每次心跳都會帶上完整的會話上下文發送給模型——有用戶發現自動郵件檢查功能一天燒掉了 $50。解決方法:延長心跳間隔,或者在不需要自動監控時暫停 Heartbeat。
總結
OpenClaw 省 Token 的核心要點(不換模型、不降質量):
- 輸入 Token 是成本大頭(70-85%): 每次請求都把全部對話歷史重發,對話越長越貴。最簡單的省法是不同任務新開對話
- 精準檢索代碼塊是最大槓桿: 從"全文塞進去"(120K Token)到"精準喂進去"(4K Token),同樣的修改節省 96%。方法:明確指定文件行號、@file 引用、QMD 語義搜索、AGENTS.md 結構聲明
- 三階段優化路徑: 5 分鐘見效(新對話 + 關 Thinking,省 50%)→ 30 分鐘見效(精準指令 + 限制上下文,省 80%)→ 長期(QMD + Caching,省 97%)
推薦通過 API易 apiyi.com 管理 OpenClaw 的 API 調用,平臺提供精確的 Token 用量統計和費用監控,幫你量化每次優化的實際效果。
📚 參考資料
-
OpenClaw Token 使用與成本控制指南: 官方的 Token 管理文檔
- 鏈接:
docs.openclaw.ai/reference/token-use - 說明: 包含 contextTokens 配置和 Heartbeat 優化
- 鏈接:
-
OpenClaw 省 Token 實戰:從 $600 降到 $20: 完整的三階段優化框架
- 鏈接:
blog.laozhang.ai/en/posts/openclaw-save-money-practical-guide - 說明: 包含具體的配置參數和預期節省比例
- 鏈接:
-
AI 編碼 Agent 80% Token 浪費在找東西: 上下文精準度研究
- 鏈接:
medium.com/@jakenesler/context-compression-to-reduce-llm-costs - 說明: 解釋了爲什麼精準檢索比加大上下文窗口更有效
- 鏈接:
-
API易文檔中心: Token 用量統計和費用監控
- 鏈接:
docs.apiyi.com - 說明: 支持 OpenClaw 和 Claude Code 的 API 調用管理
- 鏈接:
作者: APIYI 技術團隊
技術交流: 歡迎在評論區討論,更多資料可訪問 API易 docs.apiyi.com 文檔中心