作者注:深度對比 Kimi K2.5 與 Claude Opus 4.5 在編程、推理、Agent 能力等維度的表現,分析 9 倍價差背後的性價比差異,幫你做出最佳選擇
Kimi K2.5 對比 Claude Opus 4.5 到底怎麼樣?這是 2026 年開發者最關心的選型問題之一。本文從 基準測試、實際能力、價格成本、適用場景 四個維度進行深度對比,給出明確的選擇建議。
核心結論:Claude Opus 4.5 在代碼質量上略勝一籌 (SWE-Bench 80.9% vs 76.8%),但 Kimi K2.5 在 Agent 自動化、視覺編程、數學推理上更強,且成本僅爲 Claude 的 1/9。

Kimi K2.5 vs Claude Opus 4.5 核心對比
| 對比維度 | Kimi K2.5 | Claude Opus 4.5 | 勝出方 |
|---|---|---|---|
| SWE-Bench Verified | 76.8% | 80.9% | Claude +4.1% |
| AIME 2025 數學 | 96.1% | 92.8% | Kimi +3.3% |
| LiveCodeBench v6 | 83.1% | 64.0% | Kimi +19.1% |
| BrowseComp 網頁交互 | 60.2% | 24.1% | Kimi +36.1% |
| Agent Swarm | ✅ 100 並行 | ❌ 不支持 | Kimi |
| 視覺編程 | ✅ 原生支持 | ❌ 僅文本 | Kimi |
| 上下文窗口 | 256K | 200K | Kimi +28% |
| API 價格 | $0.60/$3.00 | $5.00/$25.00 | Kimi 便宜 ~9x |
一句話總結
- 追求極致代碼質量 → 選 Claude Opus 4.5
- 追求性價比和多功能 → 選 Kimi K2.5
- 需要 Agent 自動化 → 必選 Kimi K2.5
Kimi K2.5 vs Claude Opus 4.5 編程能力詳解
代碼修復能力 (SWE-Bench)
SWE-Bench Verified 是衡量模型修復真實 GitHub Issue 能力的權威基準:
| 模型 | SWE-Bench Verified | SWE-Bench Multi | Terminal-Bench |
|---|---|---|---|
| Claude Opus 4.5 | 80.9% | – | 59.3% |
| Kimi K2.5 | 76.8% | 73.0% | 50.8% |
| GPT-5.2 | 80.0% | – | 54.0% |
Claude Opus 4.5 在 SWE-Bench 上以 80.9% 的成績領先,這意味着在修復複雜代碼 Bug 時,Claude 的成功率更高,調試周期更短。
Claude 的優勢場景:
- 關鍵系統的代碼審查
- 複雜的重構任務
- 需要極低容錯率的生產代碼
實時交互編程 (LiveCodeBench)
LiveCodeBench v6 測試模型在實時交互環境下的編程能力:
| 模型 | LiveCodeBench v6 | 說明 |
|---|---|---|
| GPT-5.2 | 87.0% | 最強 |
| Kimi K2.5 | 83.1% | 開源最強 |
| Claude Opus 4.5 | 64.0% | 明顯落後 |
在實時編程對話場景中,Kimi K2.5 以 83.1% 大幅領先 Claude 的 64.0%,這說明 Kimi 更擅長在交互式開發中快速響應和迭代。
前端與視覺編程
| 能力 | Kimi K2.5 | Claude Opus 4.5 |
|---|---|---|
| UI 設計轉代碼 | ✅ 原生支持 | ❌ 不支持 |
| 視頻轉代碼 | ✅ 支持 | ❌ 不支持 |
| 複雜動畫生成 | ✅ 強 | ⚠️ 一般 |
Kimi K2.5 的 Vibe Coding 能力是 Claude 完全不具備的——直接從 Figma 設計稿或操作視頻生成完整前端代碼。
Kimi K2.5 vs Claude Opus 4.5 推理能力對比
數學推理 (AIME/GPQA)
| 基準 | Kimi K2.5 | Claude Opus 4.5 | GPT-5.2 |
|---|---|---|---|
| AIME 2025 | 96.1% | 92.8% | 100% |
| GPQA-Diamond | 87.6% | – | 92.4% |
| HMMT 2025 | 95.4% | – | 93.3% |
在數學競賽級別的推理任務中,Kimi K2.5 (96.1%) 超越了 Claude Opus 4.5 (92.8%),展現出更強的邏輯推理能力。
工具增強推理
當模型可以使用搜索和代碼執行工具時:
| 模型 | 無工具 | 有工具 | 提升幅度 |
|---|---|---|---|
| Kimi K2.5 | 31.5% | 51.8% | +20.1% |
| Claude Opus 4.5 | – | – | +12.4% |
| GPT-5.2 | – | – | +11.0% |
Kimi K2.5 在工具增強推理上的提升幅度 (+20.1%) 遠超 Claude (+12.4%),這得益於其 Agent Swarm 架構對工具調用的優化。
Kimi K2.5 vs Claude Opus 4.5 Agent 能力
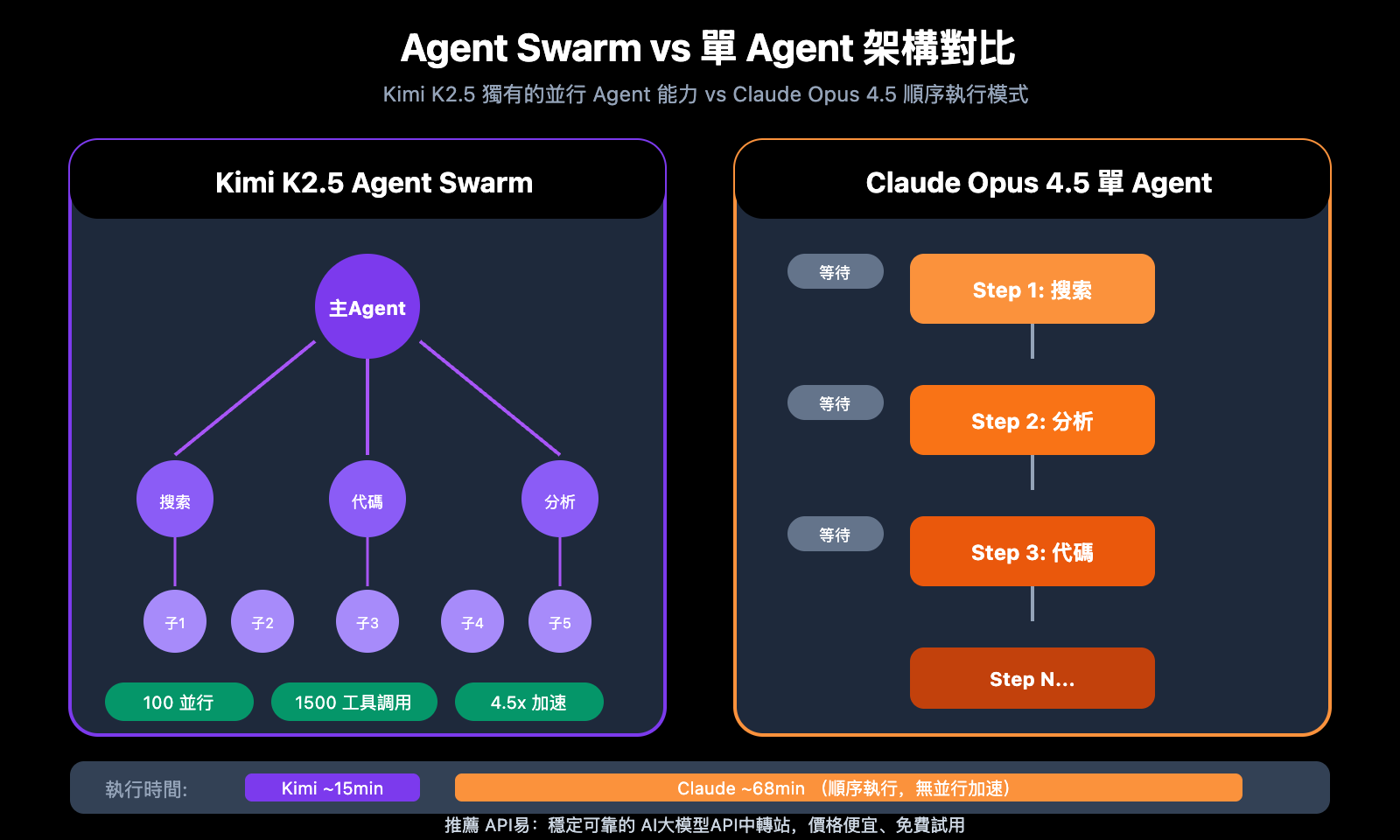
Agent Swarm:Kimi K2.5 獨有優勢
| 能力 | Kimi K2.5 | Claude Opus 4.5 |
|---|---|---|
| 並行 Agent | 最多 100 個 | 單 Agent |
| 工具調用 | 最多 1500 次/任務 | 受限 |
| 執行效率 | 4.5x 加速 | 基準 |
| 自動任務拆分 | ✅ 無需預設 | ❌ 需手動編排 |
Kimi K2.5 的 Agent Swarm 是其最大差異化優勢:
- 自動將複雜任務拆分爲並行子任務
- 動態實例化專業子 Agent
- 無需預定義角色或工作流
- 複雜研究任務完成時間縮短至 1/4.5
實際案例:一個需要數小時的跨領域市場調研任務,Kimi K2.5 可以在十幾分鍾內完成,而 Claude 需要順序執行多輪對話。
Kimi K2.5 vs Claude Opus 4.5 價格成本對比
API 定價對比
| 模型 | 輸入價格 | 輸出價格 | 相對成本 |
|---|---|---|---|
| Kimi K2.5 | $0.60/M | $3.00/M | 基準 |
| Claude Opus 4.5 | $5.00/M | $25.00/M | ~9x |
| GPT-5.2 | $0.90/M | $3.80/M | ~1.4x |
年度成本估算 (100 萬請求,5K 輸出/請求)
| 模型 | 年成本 | 對比 |
|---|---|---|
| Kimi K2.5 | ~$13,800 | 基準 |
| GPT-5.2 | ~$56,500 | 4.1x |
| Claude Opus 4.5 | ~$150,000 | 10.9x |
Claude Opus 4.5 的年成本是 Kimi K2.5 的 10 倍以上。對於預算有限的團隊,這個差距足以影響技術選型。
成本效益分析
| 場景 | 推薦模型 | 原因 |
|---|---|---|
| 初創公司 | Kimi K2.5 | 成本僅 $13,800/年,性能夠用 |
| 大型企業關鍵系統 | Claude Opus 4.5 | 代碼質量優先,成本可接受 |
| 高頻 Agent 任務 | Kimi K2.5 | Agent Swarm + 低成本 |
| 前端開發 | Kimi K2.5 | 視覺編程獨家優勢 |
成本建議:大多數場景下,Kimi K2.5 的 76.8% SWE-Bench 成績已經足夠優秀,4% 的差距不值得 9 倍的溢價。可通過 API易 apiyi.com 同時接入兩個模型,關鍵任務用 Claude,日常開發用 Kimi。
Kimi K2.5 vs Claude Opus 4.5 選擇指南
選擇 Kimi K2.5 的場景
| 場景 | 原因 |
|---|---|
| 預算敏感項目 | 成本僅爲 Claude 的 1/9 |
| Agent 自動化工作流 | Agent Swarm 獨家能力 |
| 前端開發、UI 還原 | 視覺編程原生支持 |
| 數學推理任務 | AIME 96.1% > Claude 92.8% |
| 需要超長上下文 | 256K > 200K |
| 高頻 API 調用 | 成本效益更高 |
選擇 Claude Opus 4.5 的場景
| 場景 | 原因 |
|---|---|
| 關鍵系統代碼審查 | SWE-Bench 80.9% 最高 |
| 複雜後端重構 | 代碼質量更穩定 |
| 企業級合規要求 | Anthropic 安全聲譽 |
| 對錯誤零容忍 | 調試周期更短 |
快速接入示例
通過 API易 同時接入兩個模型
import openai
# 創建客戶端 - 指向 API易
client = openai.OpenAI(
api_key="YOUR_API_KEY", # 在 apiyi.com 獲取
base_url="https://vip.apiyi.com/v1"
)
# 日常開發用 Kimi K2.5 (高性價比)
response_kimi = client.chat.completions.create(
model="kimi-k2.5",
messages=[{"role": "user", "content": "實現一個 React 購物車組件"}]
)
# 關鍵代碼審查用 Claude (高質量)
response_claude = client.chat.completions.create(
model="claude-opus-4-5-20251101",
messages=[{"role": "user", "content": "審查這段支付接口代碼的安全性..."}]
)
接入建議:通過 API易 apiyi.com 獲取免費測試額度,用同一個 API Key 同時調用 Kimi K2.5 和 Claude Opus 4.5,按需切換,靈活控制成本。
常見問題
Q1: Kimi K2.5 對比 Claude Opus 4.5,編程能力差多少?
在 SWE-Bench Verified 基準上,Claude (80.9%) 比 Kimi (76.8%) 高 4.1%。但在 LiveCodeBench 實時交互編程中,Kimi (83.1%) 大幅領先 Claude (64.0%)。結論:Claude 更適合複雜代碼修復,Kimi 更適合快速迭代開發。
Q2: 9 倍的價格差距,Claude Opus 4.5 值得嗎?
取決於場景。對於年薪 $200K+ 的工程師團隊,Claude 4% 更高的代碼質量可能減少調試時間,ROI 爲正。但對於預算敏感的初創公司或高頻 API 調用場景,Kimi K2.5 的性價比更優。建議:關鍵代碼用 Claude,日常開發用 Kimi。
Q3: 如何同時使用 Kimi K2.5 和 Claude Opus 4.5?
推薦通過 API易 apiyi.com 統一接入:
- 註冊獲取一個 API Key
- 設置 base_url 爲
https://vip.apiyi.com/v1 - 通過 model 參數切換:
kimi-k2.5或claude-opus-4-5-20251101 - 根據任務類型動態選擇,靈活控制成本
總結
Kimi K2.5 對比 Claude Opus 4.5 的核心結論:
- 代碼質量:Claude 略優 (SWE-Bench 80.9% vs 76.8%),但差距僅 4%
- 綜合性價比:Kimi K2.5 成本僅爲 Claude 的 1/9,大多數場景更划算
- 獨家能力:Kimi 擁有 Agent Swarm、視覺編程等 Claude 不具備的能力
- 推薦策略:日常開發用 Kimi K2.5,關鍵代碼審查用 Claude Opus 4.5
兩個模型均已上線 API易 apiyi.com,建議通過平臺獲取免費額度,實際測試後根據業務需求選擇。
參考資料
⚠️ 鏈接格式說明: 所有外鏈使用
資料名: domain.com格式,方便複製但不可點擊跳轉,避免 SEO 權重流失。
-
Kimi K2.5 官方技術報告: 完整基準測試數據
- 鏈接:
kimi.com/blog/kimi-k2-5.html - 說明: 獲取 SWE-Bench、AIME 等官方測試結果
- 鏈接:
-
Claude Opus 4.5 模型卡: Anthropic 官方性能數據
- 鏈接:
anthropic.com/claude - 說明: 查看 Claude 的官方基準成績
- 鏈接:
-
AI Model Benchmarks 2026: 第三方獨立評測
- 鏈接:
artificialanalysis.ai - 說明: 多模型橫向對比數據
- 鏈接:
-
Four Giants Comparison 深度評測: 詳細場景對比分析
- 鏈接:
medium.com(搜索 "Kimi K2.5 vs Claude Opus 4.5") - 說明: 實際使用體驗和成本分析
- 鏈接:
作者: 技術團隊
技術交流: 歡迎在評論區分享你的模型選型經驗,更多對比評測可訪問 API易 apiyi.com 技術社區